 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Remote Sensing Image Registration with Accuracy Estimation at Local and Global Scales
May 25, 2016
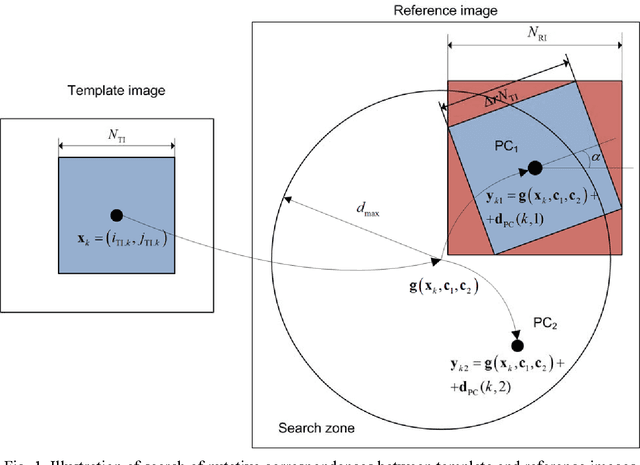
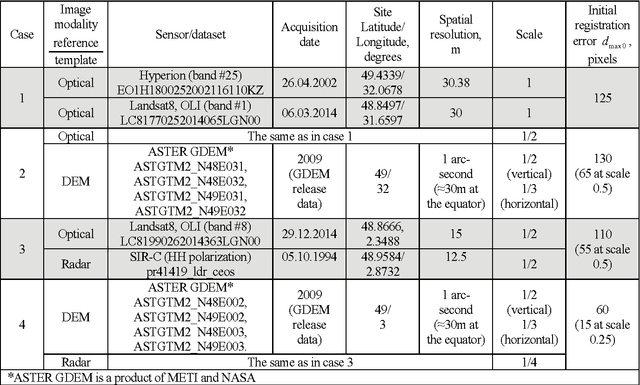
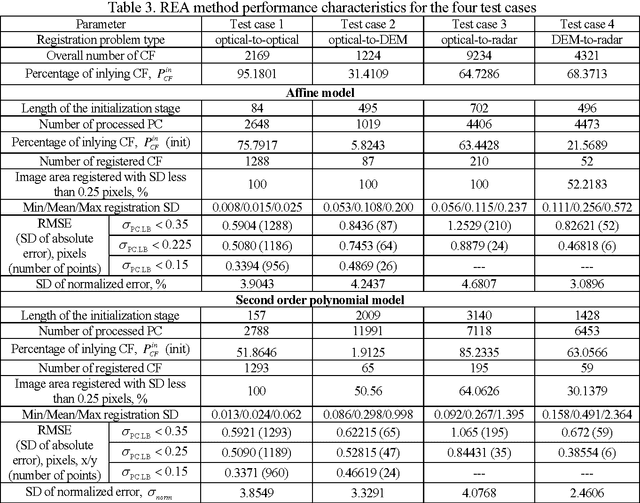

This paper focuses on potential accuracy of remote sensing images registration. We investigate how this accuracy can be estimated without ground truth available and used to improve registration quality of mono- and multi-modal pair of images. At the local scale of image fragments, the Cramer-Rao lower bound (CRLB) on registration error is estimated for each local correspondence between coarsely registered pair of images. This CRLB is defined by local image texture and noise properties. Opposite to the standard approach, where registration accuracy is only evaluated at the output of the registration process, such valuable information is used by us as an additional input knowledge. It greatly helps detecting and discarding outliers and refining the estimation of geometrical transformation model parameters. Based on these ideas, a new area-based registration method called RAE (Registration with Accuracy Estimation) is proposed. In addition to its ability to automatically register very complex multimodal image pairs with high accuracy, the RAE method provides registration accuracy at the global scale as covariance matrix of estimation error of geometrical transformation model parameters or as point-wise registration Standard Deviation. This accuracy does not depend on any ground truth availability and characterizes each pair of registered images individually. Thus, the RAE method can identify image areas for which a predefined registration accuracy is guaranteed. The RAE method is proved successful with reaching subpixel accuracy while registering eight complex mono/multimodal and multitemporal image pairs including optical to optical, optical to radar, optical to Digital Elevation Model (DEM) images and DEM to radar cases. Other methods employed in comparisons fail to provide in a stable manner accurate results on the same test cases.
NanoFlow: Scalable Normalizing Flows with Sublinear Parameter Complexity
Jun 15, 2020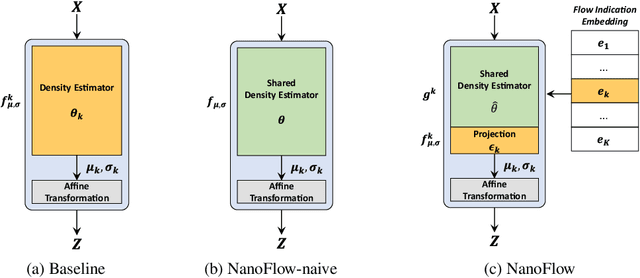
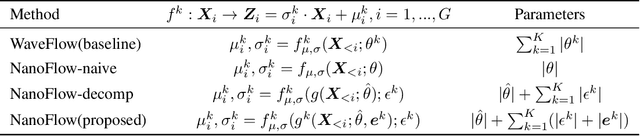
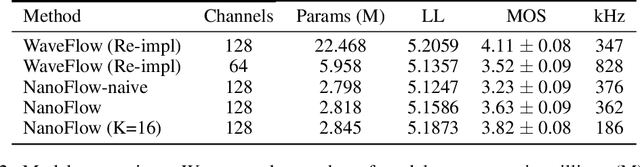
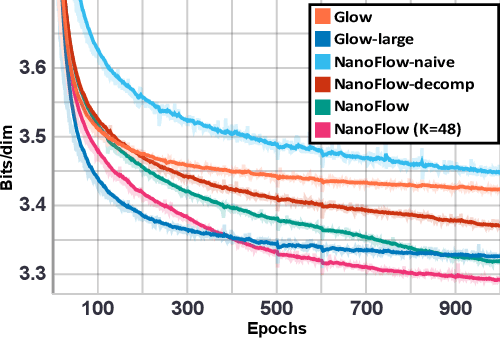
Normalizing flows (NFs) have become a prominent method for deep generative models that allow for an analytic probability density estimation and efficient synthesis. However, a flow-based network is considered to be inefficient in parameter complexity because of reduced expressiveness of bijective mapping, which renders the models prohibitively expensive in terms of parameters. We present an alternative of parameterization scheme, called NanoFlow, which uses a single neural density estimator to model multiple transformation stages. Hence, we propose an efficient parameter decomposition method and the concept of flow indication embedding, which are key missing components that enable density estimation from a single neural network. Experiments performed on audio and image models confirm that our method provides a new parameter-efficient solution for scalable NFs with significantly sublinear parameter complexity.
SCREENet: A Multi-view Deep Convolutional Neural Network for Classification of High-resolution Synthetic Mammographic Screening Scans
Sep 18, 2020
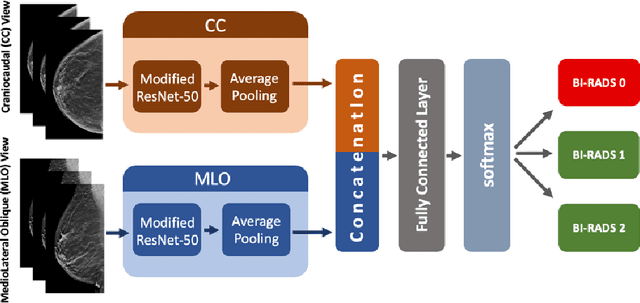
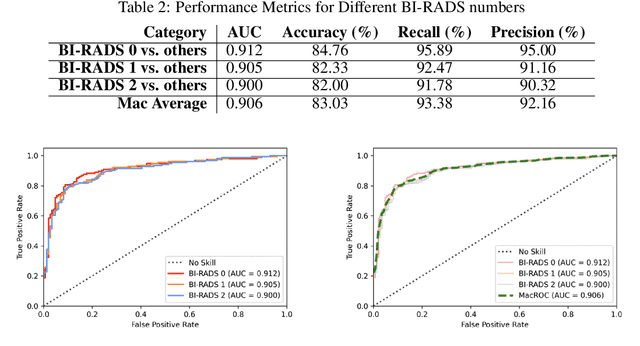
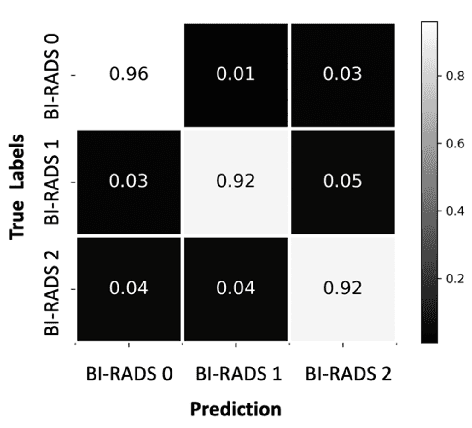
Purpose: To develop and evaluate the accuracy of a multi-view deep learning approach to the analysis of high-resolution synthetic mammograms from digital breast tomosynthesis screening cases, and to assess the effect on accuracy of image resolution and training set size. Materials and Methods: In a retrospective study, 21,264 screening digital breast tomosynthesis (DBT) exams obtained at our institution were collected along with associated radiology reports. The 2D synthetic mammographic images from these exams, with varying resolutions and data set sizes, were used to train a multi-view deep convolutional neural network (MV-CNN) to classify screening images into BI-RADS classes (BI-RADS 0, 1 and 2) before evaluation on a held-out set of exams. Results: Area under the receiver operating characteristic curve (AUC) for BI-RADS 0 vs non-BI-RADS 0 class was 0.912 for the MV-CNN trained on the full dataset. The model obtained accuracy of 84.8%, recall of 95.9% and precision of 95.0%. This AUC value decreased when the same model was trained with 50% and 25% of images (AUC = 0.877, P=0.010 and 0.834, P=0.009 respectively). Also, the performance dropped when the same model was trained using images that were under-sampled by 1/2 and 1/4 (AUC = 0.870, P=0.011 and 0.813, P=0.009 respectively). Conclusion: This deep learning model classified high-resolution synthetic mammography scans into normal vs needing further workup using tens of thousands of high-resolution images. Smaller training data sets and lower resolution images both caused significant decrease in performance.
Quantitative and Qualitative Evaluation of Explainable Deep Learning Methods for Ophthalmic Diagnosis
Sep 26, 2020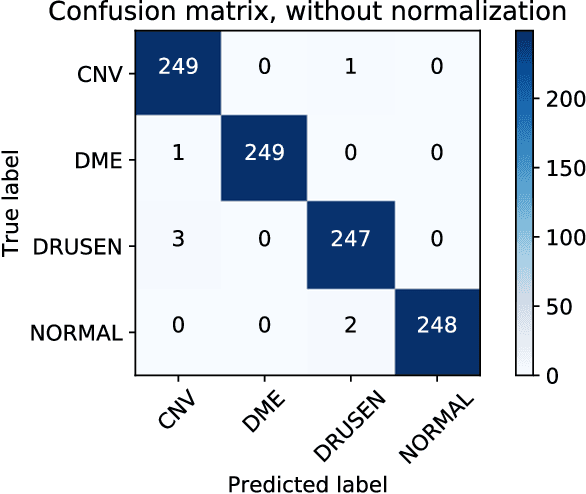
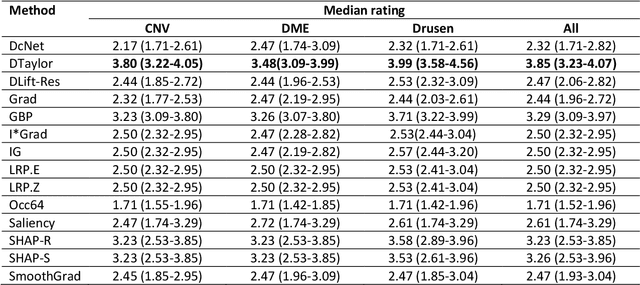
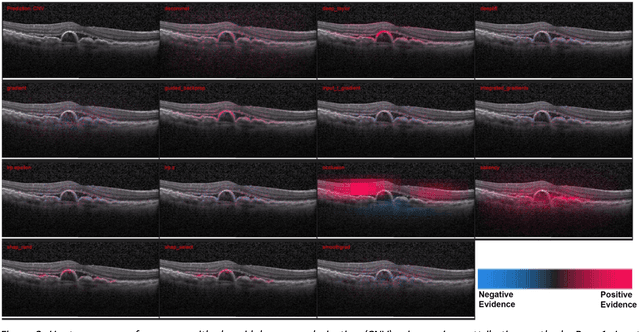
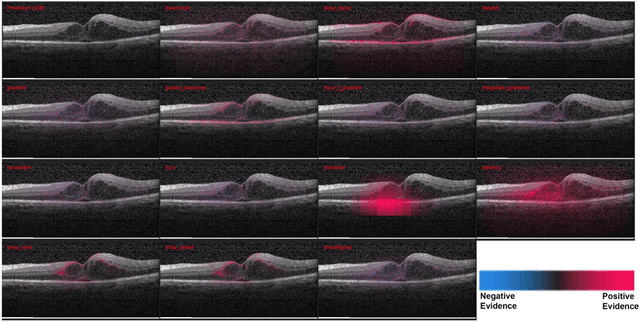
Background: The lack of explanations for the decisions made by algorithms such as deep learning has hampered their acceptance by the clinical community despite highly accurate results on multiple problems. Recently, attribution methods have emerged for explaining deep learning models, and they have been tested on medical imaging problems. The performance of attribution methods is compared on standard machine learning datasets and not on medical images. In this study, we perform a comparative analysis to determine the most suitable explainability method for retinal OCT diagnosis. Methods: A commonly used deep learning model known as Inception v3 was trained to diagnose 3 retinal diseases - choroidal neovascularization (CNV), diabetic macular edema (DME), and drusen. The explanations from 13 different attribution methods were rated by a panel of 14 clinicians for clinical significance. Feedback was obtained from the clinicians regarding the current and future scope of such methods. Results: An attribution method based on a Taylor series expansion, called Deep Taylor was rated the highest by clinicians with a median rating of 3.85/5. It was followed by two other attribution methods, Guided backpropagation and SHAP (SHapley Additive exPlanations). Conclusion: Explanations of deep learning models can make them more transparent for clinical diagnosis. This study compared different explanations methods in the context of retinal OCT diagnosis and found that the best performing method may not be the one considered best for other deep learning tasks. Overall, there was a high degree of acceptance from the clinicians surveyed in the study. Keywords: explainable AI, deep learning, machine learning, image processing, Optical coherence tomography, retina, Diabetic macular edema, Choroidal Neovascularization, Drusen
Zero-Shot Multi-View Indoor Localization via Graph Location Networks
Aug 06, 2020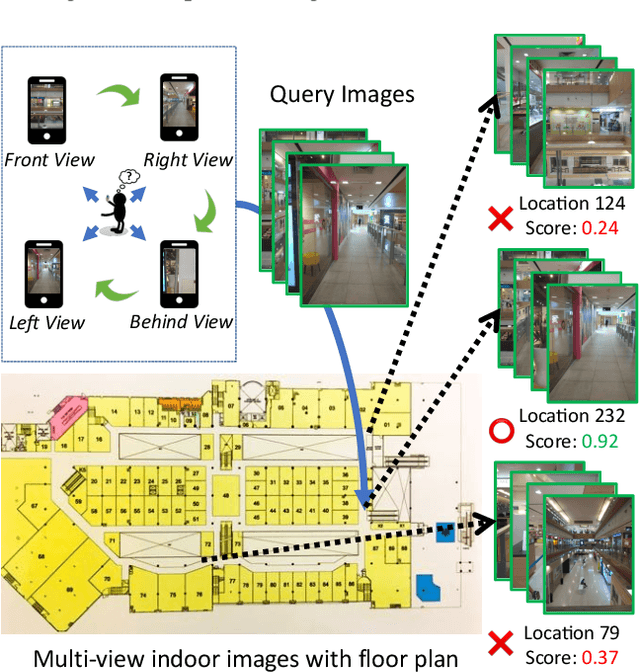
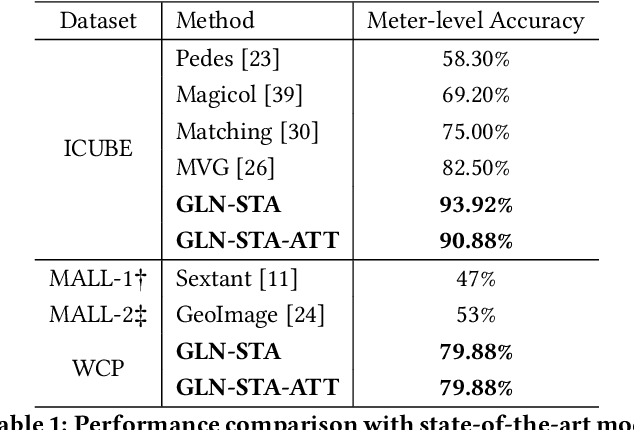
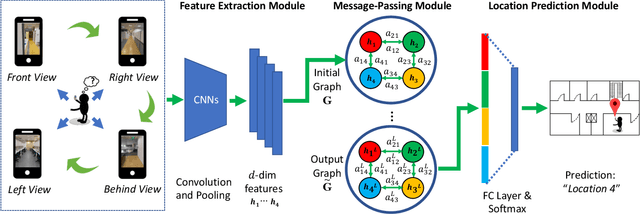
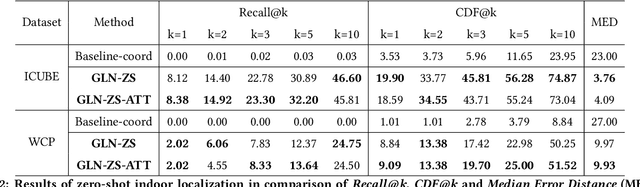
Indoor localization is a fundamental problem in location-based applications. Current approaches to this problem typically rely on Radio Frequency technology, which requires not only supporting infrastructures but human efforts to measure and calibrate the signal. Moreover, data collection for all locations is indispensable in existing methods, which in turn hinders their large-scale deployment. In this paper, we propose a novel neural network based architecture Graph Location Networks (GLN) to perform infrastructure-free, multi-view image based indoor localization. GLN makes location predictions based on robust location representations extracted from images through message-passing networks. Furthermore, we introduce a novel zero-shot indoor localization setting and tackle it by extending the proposed GLN to a dedicated zero-shot version, which exploits a novel mechanism Map2Vec to train location-aware embeddings and make predictions on novel unseen locations. Our extensive experiments show that the proposed approach outperforms state-of-the-art methods in the standard setting, and achieves promising accuracy even in the zero-shot setting where data for half of the locations are not available. The source code and datasets are publicly available at https://github.com/coldmanck/zero-shot-indoor-localization-release.
* Accepted at ACM MM 2020. 10 pages, 7 figures. Code and datasets available at https://github.com/coldmanck/zero-shot-indoor-localization-release
SegFix: Model-Agnostic Boundary Refinement for Segmentation
Jul 09, 2020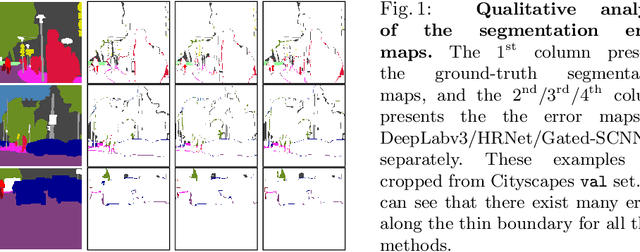
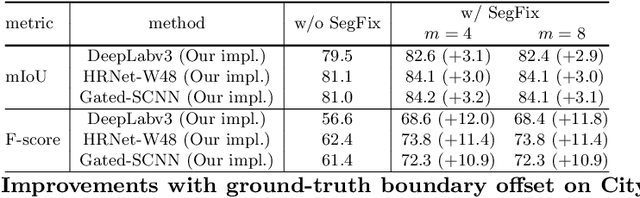
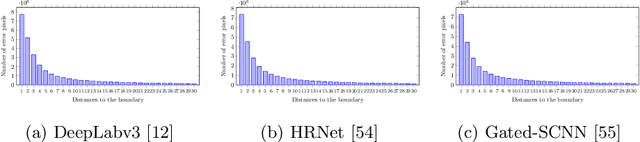
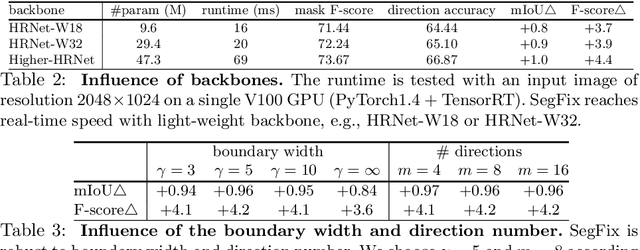
We present a model-agnostic post-processing scheme to improve the boundary quality for the segmentation result that is generated by any existing segmentation model. Motivated by the empirical observation that the label predictions of interior pixels are more reliable, we propose to replace the originally unreliable predictions of boundary pixels by the predictions of interior pixels. Our approach processes only the input image through two steps: (i) localize the boundary pixels and (ii) identify the corresponding interior pixel for each boundary pixel. We build the correspondence by learning a direction away from the boundary pixel to an interior pixel. Our method requires no prior information of the segmentation models and achieves nearly real-time speed. We empirically verify that our SegFix consistently reduces the boundary errors for segmentation results generated from various state-of-the-art models on Cityscapes, ADE20K and GTA5. Code is available at: https://github.com/openseg-group/openseg.pytorch.
Combining 3D Model Contour Energy and Keypoints for Object Tracking
Feb 04, 2020

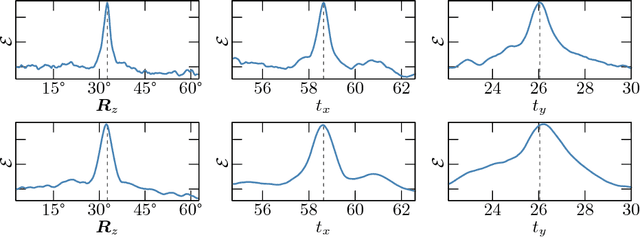

We present a new combined approach for monocular model-based 3D tracking. A preliminary object pose is estimated by using a keypoint-based technique. The pose is then refined by optimizing the contour energy function. The energy determines the degree of correspondence between the contour of the model projection and the image edges. It is calculated based on both the intensity and orientation of the raw image gradient. For optimization, we propose a technique and search area constraints that allow overcoming the local optima and taking into account information obtained through keypoint-based pose estimation. Owing to its combined nature, our method eliminates numerous issues of keypoint-based and edge-based approaches. We demonstrate the efficiency of our method by comparing it with state-of-the-art methods on a public benchmark dataset that includes videos with various lighting conditions, movement patterns, and speed.
Image retrieval with hierarchical matching pursuit
Jun 05, 2014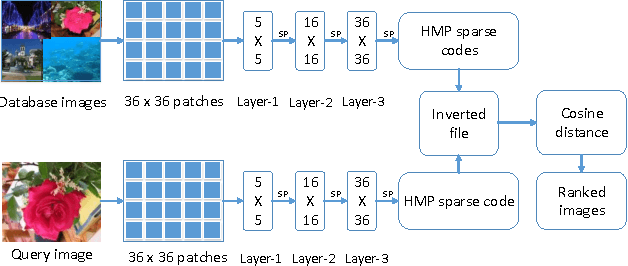
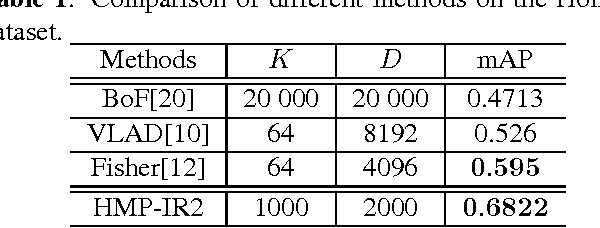
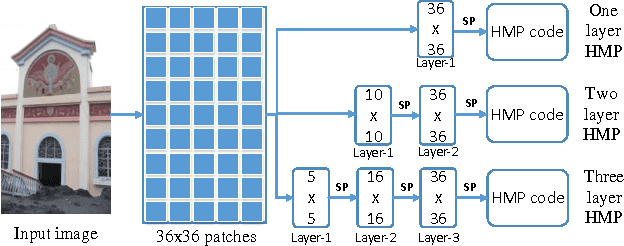
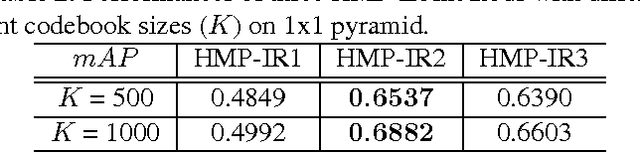
A novel representation of images for image retrieval is introduced in this paper, by using a new type of feature with remarkable discriminative power. Despite the multi-scale nature of objects, most existing models perform feature extraction on a fixed scale, which will inevitably degrade the performance of the whole system. Motivated by this, we introduce a hierarchical sparse coding architecture for image retrieval to explore multi-scale cues. Sparse codes extracted on lower layers are transmitted to higher layers recursively. With this mechanism, cues from different scales are fused. Experiments on the Holidays dataset show that the proposed method achieves an excellent retrieval performance with a small code length.
Hierarchical Patch VAE-GAN: Generating Diverse Videos from a Single Sample
Jun 23, 2020

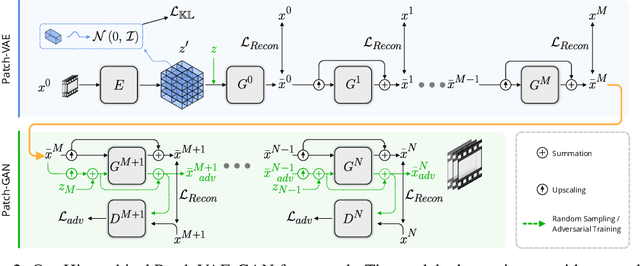

We consider the task of generating diverse and novel videos from a single video sample. Recently, new hierarchical patch-GAN based approaches were proposed for generating diverse images, given only a single sample at training time. Moving to videos, these approaches fail to generate diverse samples, and often collapse into generating samples similar to the training video. We introduce a novel patch-based variational autoencoder (VAE) which allows for a much greater diversity in generation. Using this tool, a new hierarchical video generation scheme is constructed: at coarse scales, our patch-VAE is employed, ensuring samples are of high diversity. Subsequently, at finer scales, a patch-GAN renders the fine details, resulting in high quality videos. Our experiments show that the proposed method produces diverse samples in both the image domain, and the more challenging video domain.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 01, 2020
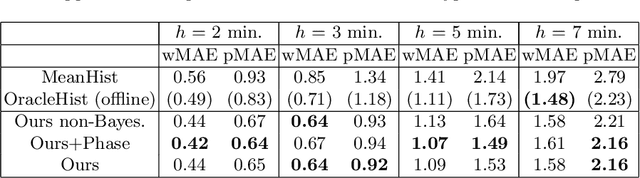
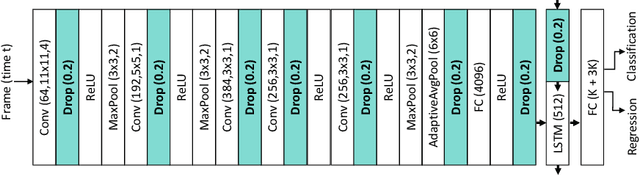
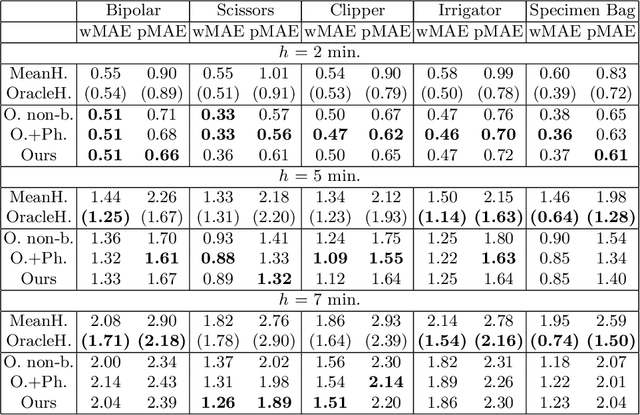
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.