 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Segmentation of Non-Tumor Tissues in Glioma MR Brain Images Using Deformable Registration with Partial Convolutional Networks
Jul 10, 2020
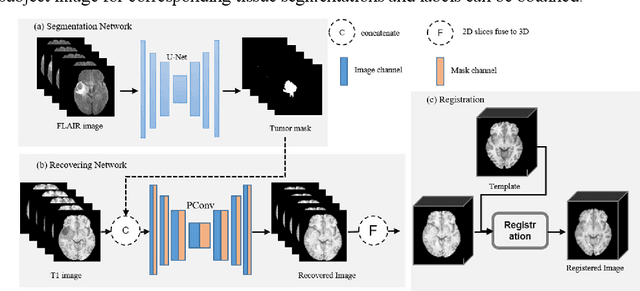

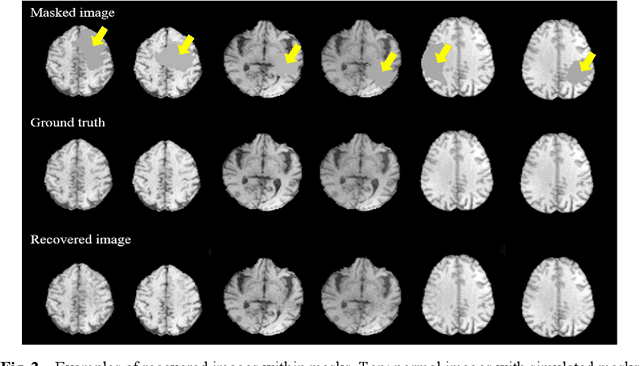
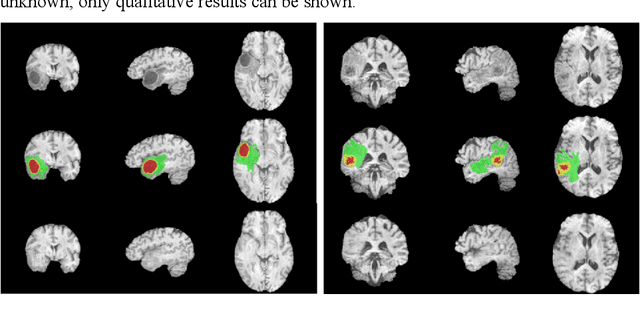
In brain tumor diagnosis and surgical planning, segmentation of tumor regions and accurate analysis of surrounding normal tissues are necessary for physicians. Pathological variability often renders difficulty to register a well-labeled normal atlas to such images and to automatic segment/label surrounding normal brain tissues. In this paper, we propose a new registration approach that first segments brain tumor using a U-Net and then simulates missed normal tissues within the tumor region using a partial convolutional network. Then, a standard normal brain atlas image is registered onto such tumor-removed images in order to segment/label the normal brain tissues. In this way, our new approach greatly reduces the effects of pathological variability in deformable registration and segments the normal tissues surrounding brain tumor well. In experiments, we used MICCAI BraTS2018 T1 tumor images to evaluate the proposed algorithm. By comparing direct registration with the proposed algorithm, the results showed that the Dice coefficient for gray matters was significantly improved for surrounding normal brain tissues.
On the training dynamics of deep networks with $L_2$ regularization
Jun 15, 2020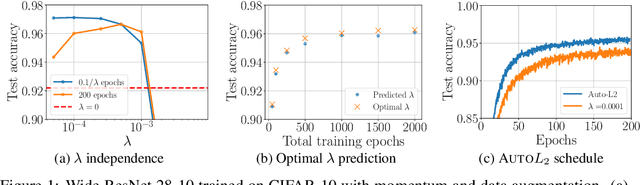
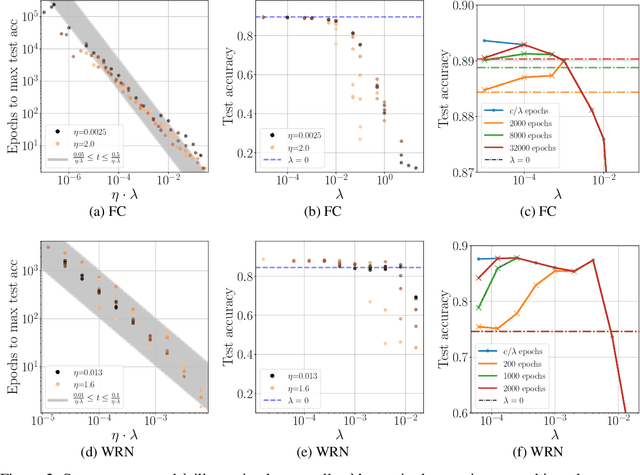
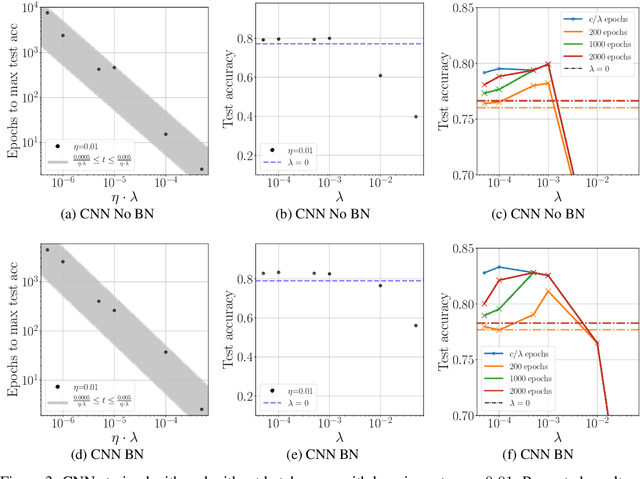
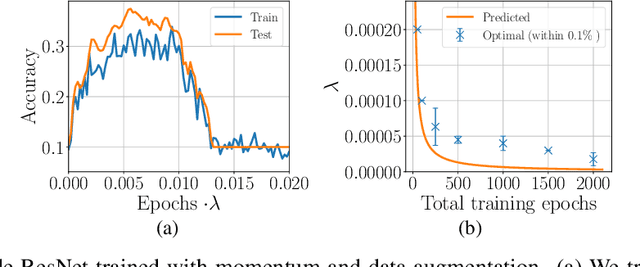
We study the role of $L_2$ regularization in deep learning, and uncover simple relations between the performance of the model, the $L_2$ coefficient, the learning rate, and the number of training steps. These empirical relations hold when the network is overparameterized. They can be used to predict the optimal regularization parameter of a given model. In addition, based on these observations we propose a dynamical schedule for the regularization parameter that improves performance and speeds up training. We test these proposals in modern image classification settings. Finally, we show that these empirical relations can be understood theoretically in the context of infinitely wide networks. We derive the gradient flow dynamics of such networks, and compare the role of $L_2$ regularization in this context with that of linear models.
A Parallel Framework for Parametric Maximum Flow Problems in Image Segmentation
Dec 07, 2015
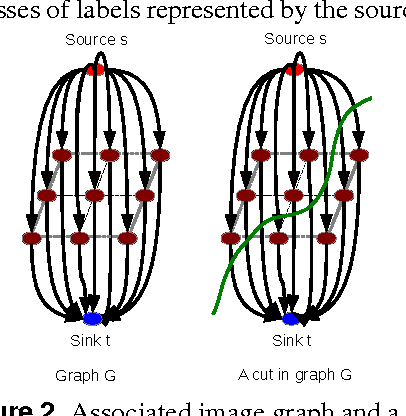
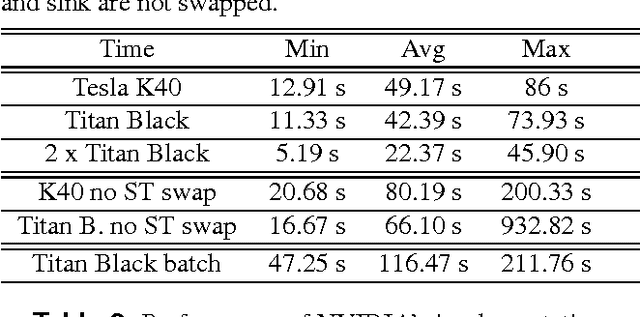
This paper presents a framework that supports the implementation of parallel solutions for the widespread parametric maximum flow computational routines used in image segmentation algorithms. The framework is based on supergraphs, a special construction combining several image graphs into a larger one, and works on various architectures (multi-core or GPU), either locally or remotely in a cluster of computing nodes. The framework can also be used for performance evaluation of parallel implementations of maximum flow algorithms. We present the case study of a state-of-the-art image segmentation algorithm based on graph cuts, Constrained Parametric Min-Cut (CPMC), that uses the parallel framework to solve parametric maximum flow problems, based on a GPU implementation of the well-known push-relabel algorithm. Our results indicate that real-time implementations based on the proposed techniques are possible.
Structure-Preserving Super Resolution with Gradient Guidance
Mar 29, 2020
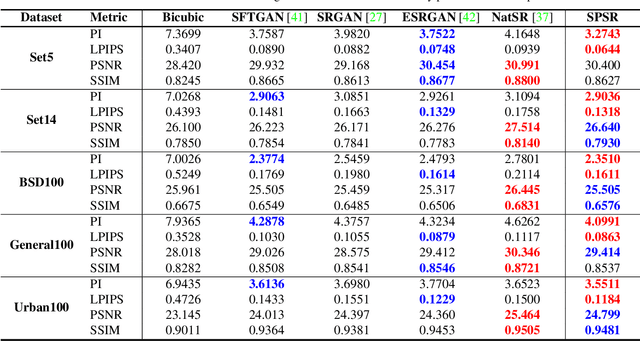
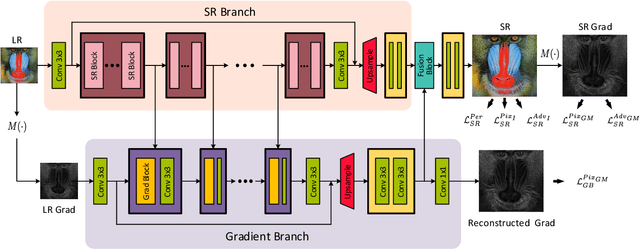

Structures matter in single image super resolution (SISR). Recent studies benefiting from generative adversarial network (GAN) have promoted the development of SISR by recovering photo-realistic images. However, there are always undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super resolution method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Specifically, we exploit gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss which imposes a second-order restriction on the super-resolved images. Along with the previous image-space loss functions, the gradient-space objectives help generative networks concentrate more on geometric structures. Moreover, our method is model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results show that we achieve the best PI and LPIPS performance and meanwhile comparable PSNR and SSIM compared with state-of-the-art perceptual-driven SR methods. Visual results demonstrate our superiority in restoring structures while generating natural SR images.
Heteroscedastic Uncertainty for Robust Generative Latent Dynamics
Aug 18, 2020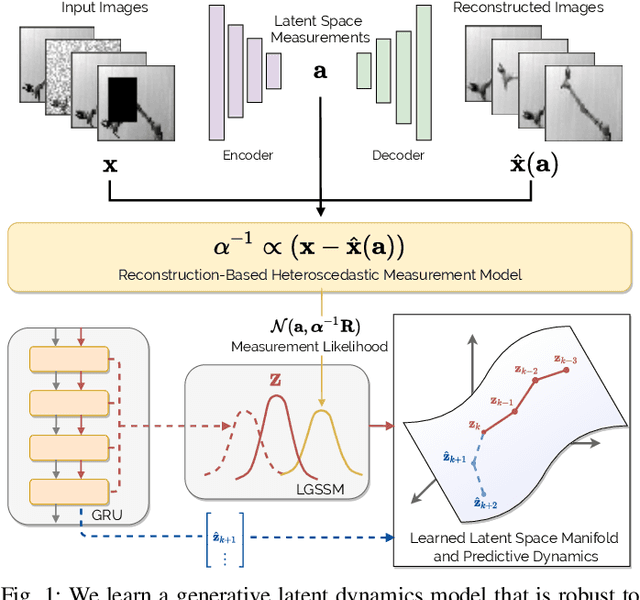

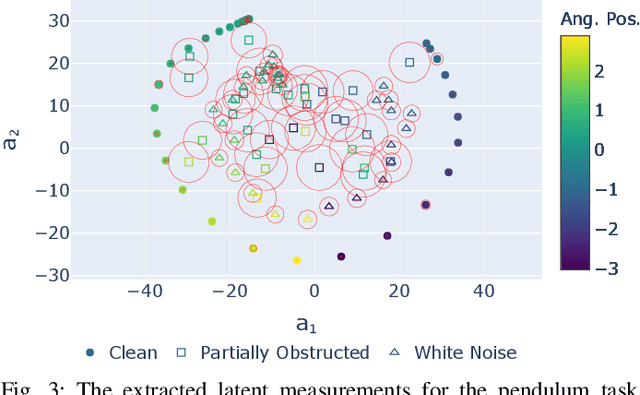

Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.
Deep Convolutional Neural Network for 6-DOF Image Localization
Nov 08, 2016

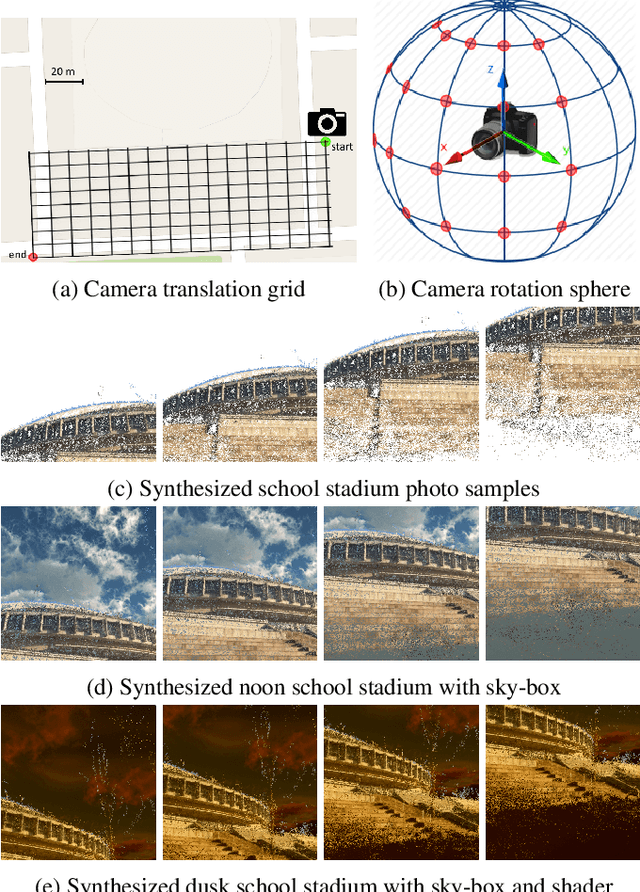

We present an accurate and robust method for six degree of freedom image localization. There are two key-points of our method, 1. automatic immense photo synthesis and labeling from point cloud model and, 2. pose estimation with deep convolutional neural networks regression. Our model can directly regresses 6-DOF camera poses from images, accurately describing where and how it was captured. We achieved an accuracy within 1 meters and 1 degree on our out-door dataset, which covers about 2 acres on our school campus.
Image Registration for Stability Testing of MEMS
Jan 09, 2013Image registration, or alignment of two or more images covering the same scenes or objects, is of great interest in many disciplines such as remote sensing, medical imaging, astronomy, and computer vision. In this paper, we introduce a new application of image registration algorithms. We demonstrate how through a wavelet based image registration algorithm, engineers can evaluate stability of Micro-Electro-Mechanical Systems (MEMS). In particular, we applied image registration algorithms to assess alignment stability of the MicroShutters Subsystem (MSS) of the Near Infrared Spectrograph (NIRSpec) instrument of the James Webb Space Telescope (JWST). This work introduces a new methodology for evaluating stability of MEMS devices to engineers as well as a new application of image registration algorithms to computer scientists.
ProTuner: Tuning Programs with Monte Carlo Tree Search
May 27, 2020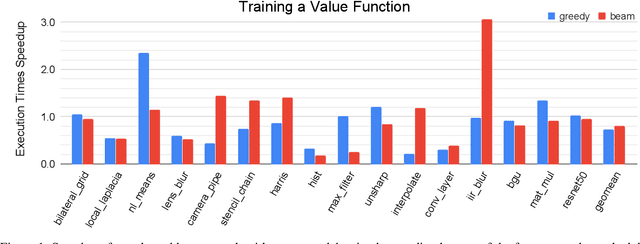

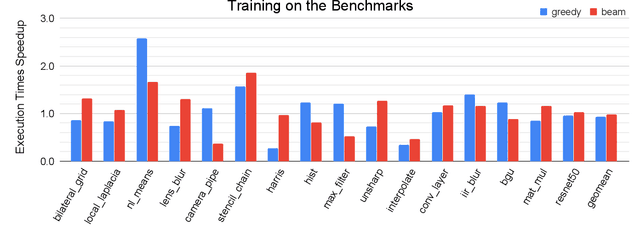
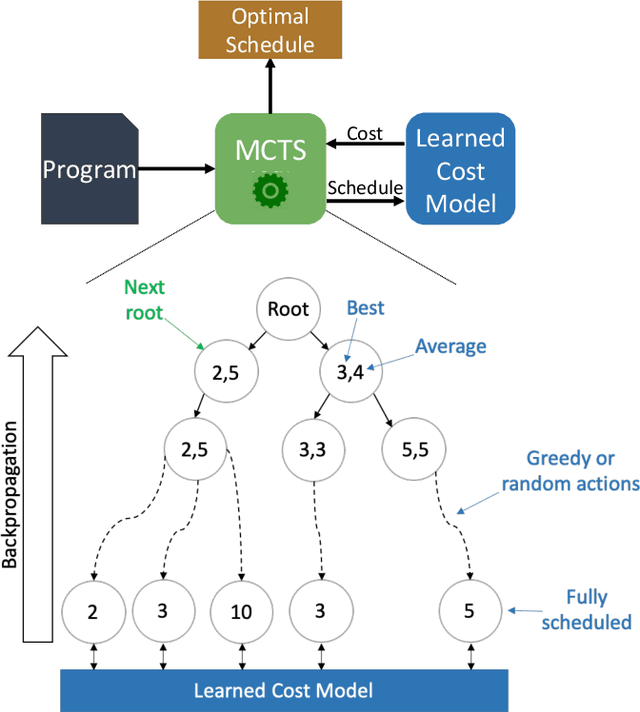
We explore applying the Monte Carlo Tree Search (MCTS) algorithm in a notoriously difficult task: tuning programs for high-performance deep learning and image processing. We build our framework on top of Halide and show that MCTS can outperform the state-of-the-art beam-search algorithm. Unlike beam search, which is guided by greedy intermediate performance comparisons between partial and less meaningful schedules, MCTS compares complete schedules and looks ahead before making any intermediate scheduling decision. We further explore modifications to the standard MCTS algorithm as well as combining real execution time measurements with the cost model. Our results show that MCTS can outperform beam search on a suite of 16 real benchmarks.
DeepLiDARFlow: A Deep Learning Architecture For Scene Flow Estimation Using Monocular Camera and Sparse LiDAR
Aug 18, 2020
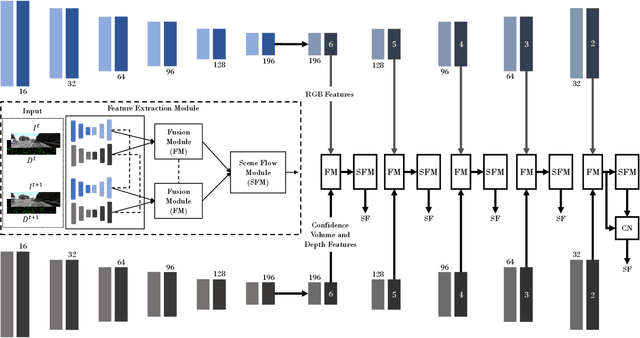
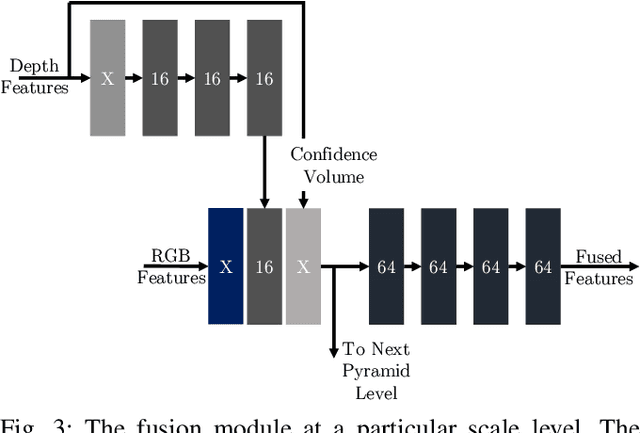
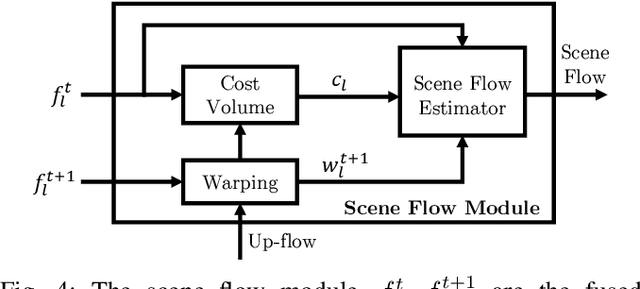
Scene flow is the dense 3D reconstruction of motion and geometry of a scene. Most state-of-the-art methods use a pair of stereo images as input for full scene reconstruction. These methods depend a lot on the quality of the RGB images and perform poorly in regions with reflective objects, shadows, ill-conditioned light environment and so on. LiDAR measurements are much less sensitive to the aforementioned conditions but LiDAR features are in general unsuitable for matching tasks due to their sparse nature. Hence, using both LiDAR and RGB can potentially overcome the individual disadvantages of each sensor by mutual improvement and yield robust features which can improve the matching process. In this paper, we present DeepLiDARFlow, a novel deep learning architecture which fuses high level RGB and LiDAR features at multiple scales in a monocular setup to predict dense scene flow. Its performance is much better in the critical regions where image-only and LiDAR-only methods are inaccurate. We verify our DeepLiDARFlow using the established data sets KITTI and FlyingThings3D and we show strong robustness compared to several state-of-the-art methods which used other input modalities. The code of our paper is available at https://github.com/dfki-av/DeepLiDARFlow.
Dual-reference Age Synthesis
Aug 07, 2019

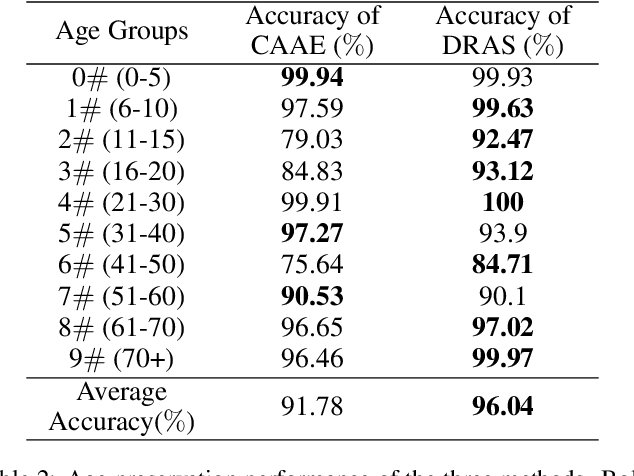
Age synthesis has received much attention in recent years. State-of-the-art methods typically take an input image and utilize a numeral to control the age of the generated image. In this paper, we revisit the age synthesis and ask: is a numeral capable enough to describe the human age? We propose a new framework Dual-reference Age Synthesis (DRAS) that takes two images as inputs to generate an image which shares the same personality of the first image and has the similar age with the second image. In the proposed framework, we employ a joint manifold feature which consists of disentangled age and identity information. The final images are generated by training a generative adversarial network which competes against an age agent and an identity agent. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.