 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Scale Residual Network for Multiple Tasks:Image Super-resolution, Denoising, and Deblocking
Nov 04, 2019
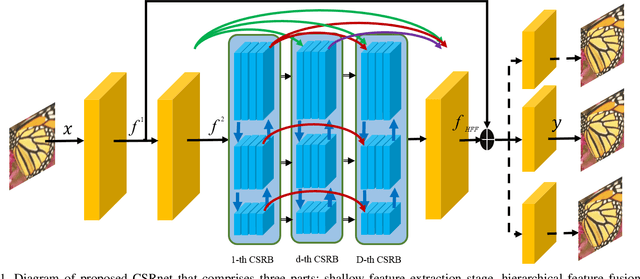


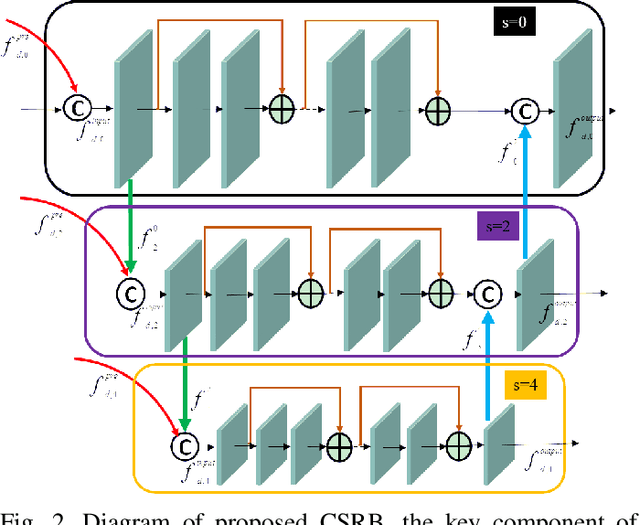
In general, image restoration involves mapping from low quality images to their high-quality counterparts. Such optimal mapping is usually non-linear and learnable by machine learning. Recently, deep convolutional neural networks have proven promising for such learning processing. It is desirable for an image processing network to support well with three vital tasks, namely, super-resolution, denoising, and deblocking. It is commonly recognized that these tasks have strong correlations. Therefore, it is imperative to harness the inter-task correlations. To this end, we propose the cross-scale residual network to exploit scale-related features and the inter-task correlations among the three tasks. The proposed network can extract multiple spatial scale features and establish multiple temporal feature reusage. Our experiments show that the proposed approach outperforms state-of-the-art methods in both quantitative and qualitative evaluations for multiple image restoration tasks.
A Comprehensive Overview and Survey of Recent Advances in Meta-Learning
May 08, 2020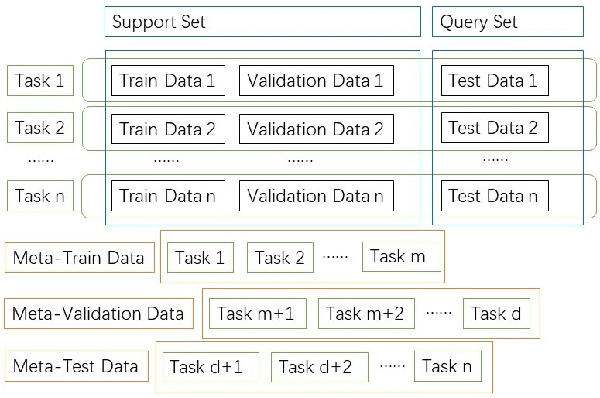

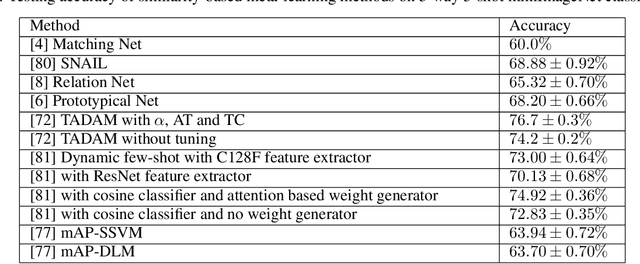
This article reviews meta-learning which seeks rapid and accurate model adaptation to unseen tasks with applications in image classification, natural language processing and robotics. Unlike deep learning, meta-learning uses few-shot datasets and concerns further improving model generalization to obtain higher prediction accuracy. We summarize meta-learning models in three categories: black-box adaptation, similarity based method and meta-learner procedure. Recent applications concentrate upon combination of meta-learning with Bayesian deep learning and reinforcement learning to provide feasible integrated problem solutions. We present performance comparison of recent meta-learning methods and discuss future research direction.
Metamorphic Detection of Adversarial Examples in Deep Learning Models With Affine Transformations
Jul 10, 2019
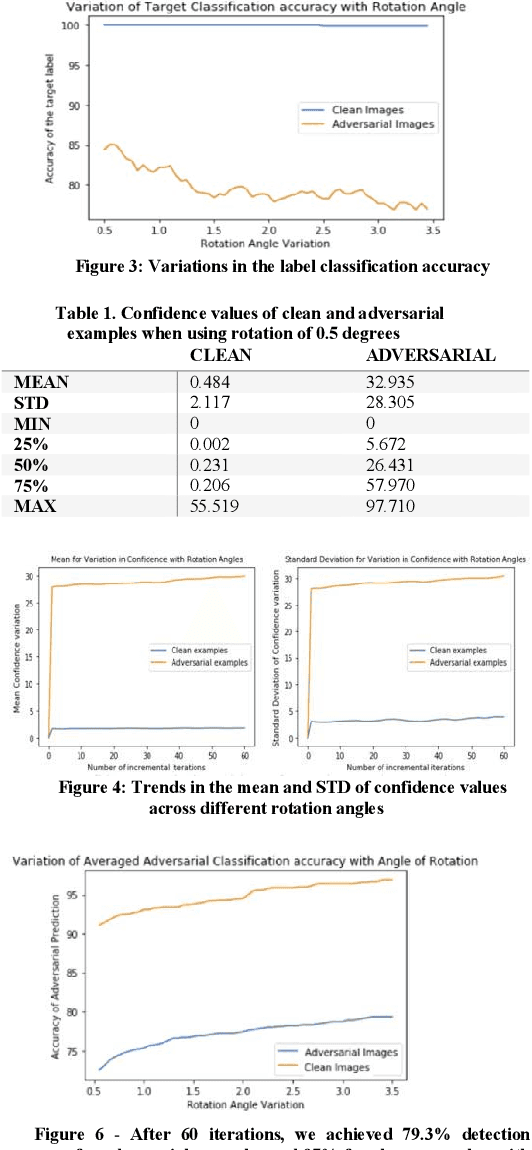
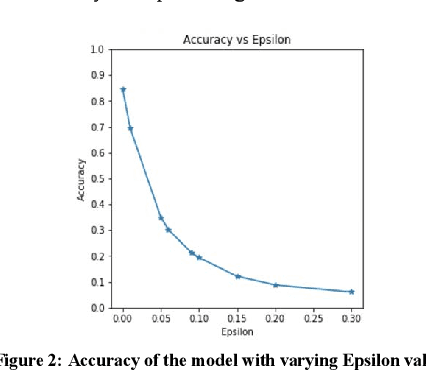

Adversarial attacks are small, carefully crafted perturbations, imperceptible to the naked eye; that when added to an image cause deep learning models to misclassify the image with potentially detrimental outcomes. With the rise of artificial intelligence models in consumer safety and security intensive industries such as self-driving cars, camera surveillance and face recognition, there is a growing need for guarding against adversarial attacks. In this paper, we present an approach that uses metamorphic testing principles to automatically detect such adversarial attacks. The approach can detect image manipulations that are so small, that they are impossible to detect by a human through visual inspection. By applying metamorphic relations based on distance ratio preserving affine image transformations which compare the behavior of the original and transformed image; we show that our proposed approach can determine whether or not the input image is adversarial with a high degree of accuracy.
A Low Complexity VLSI Architecture for Multi-Focus Image Fusion in DCT Domain
Sep 15, 2015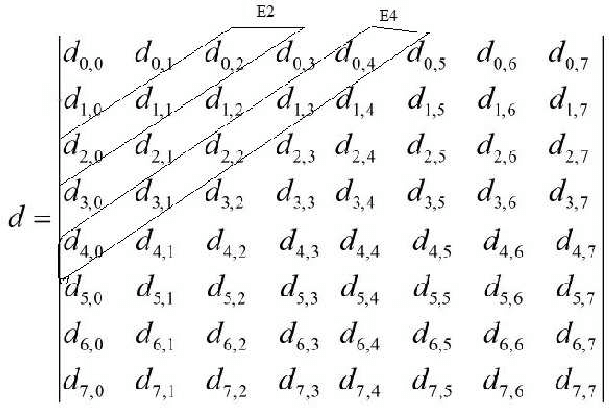
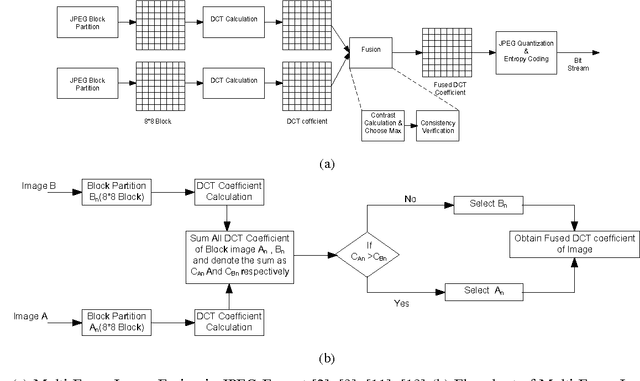
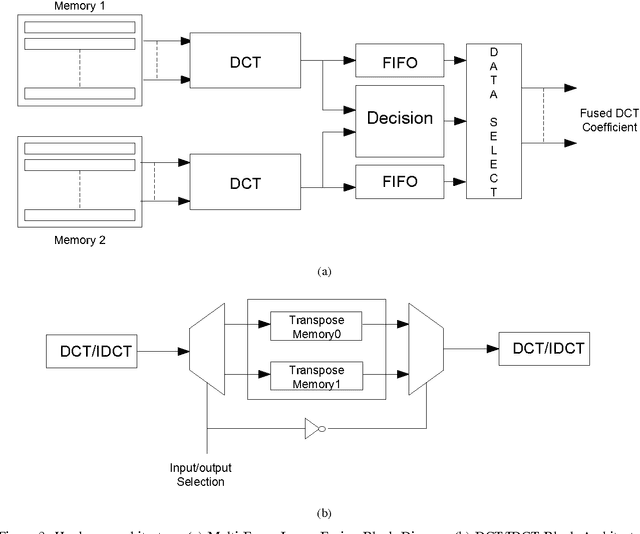
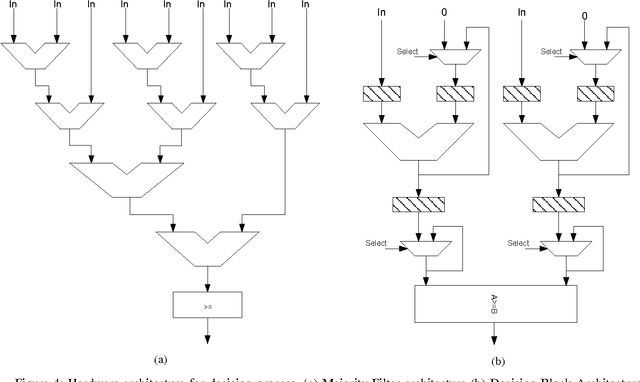
Due to the confined focal length of optical sensors, focusing all objects in a scene with a single sensor is a difficult task. To handle such a situation, image fusion methods are used in multi-focus environment. Discrete Cosine Transform (DCT) is a widely used image compression transform, image fusion in DCT domain is an efficient method. This paper presents a low complexity approach for multi-focus image fusion and its VLSI implementation using DCT. The proposed method is evaluated using reference/non-reference fusion measure criteria and the obtained results asserts it's effectiveness. The maximum synthesized frequency on FPGA is found to be 221 MHz and consumes 42% of FPGA resources. The proposed method consumes very less power and can process 4K resolution images at the rate of 60 frames per second which makes the hardware suitable for handheld portable devices such as camera module and wireless image sensors.
AutoTrajectory: Label-free Trajectory Extraction and Prediction from Videos using Dynamic Points
Jul 11, 2020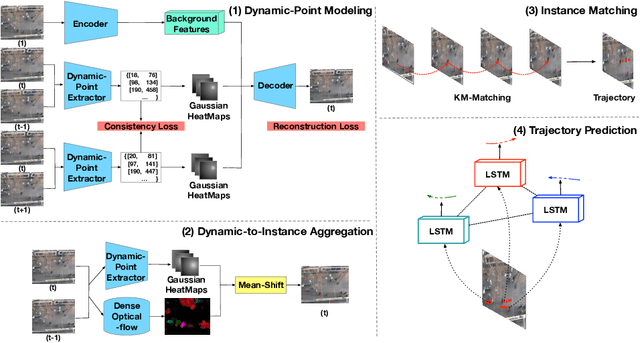
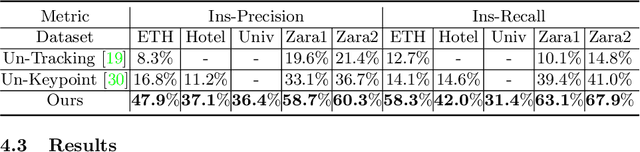
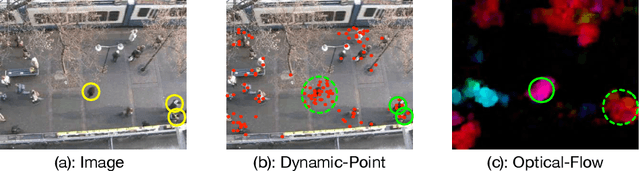
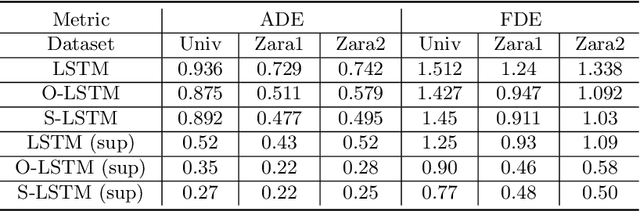
Current methods for trajectory prediction operate in supervised manners, and therefore require vast quantities of corresponding ground truth data for training. In this paper, we present a novel, label-free algorithm, AutoTrajectory, for trajectory extraction and prediction to use raw videos directly. To better capture the moving objects in videos, we introduce dynamic points. We use them to model dynamic motions by using a forward-backward extractor to keep temporal consistency and using image reconstruction to keep spatial consistency in an unsupervised manner. Then we aggregate dynamic points to instance points, which stand for moving objects such as pedestrians in videos. Finally, we extract trajectories by matching instance points for prediction training. To the best of our knowledge, our method is the first to achieve unsupervised learning of trajectory extraction and prediction. We evaluate the performance on well-known trajectory datasets and show that our method is effective for real-world videos and can use raw videos to further improve the performance of existing models.
Image Registration for Stability Testing of MEMS
Jan 09, 2013Image registration, or alignment of two or more images covering the same scenes or objects, is of great interest in many disciplines such as remote sensing, medical imaging, astronomy, and computer vision. In this paper, we introduce a new application of image registration algorithms. We demonstrate how through a wavelet based image registration algorithm, engineers can evaluate stability of Micro-Electro-Mechanical Systems (MEMS). In particular, we applied image registration algorithms to assess alignment stability of the MicroShutters Subsystem (MSS) of the Near Infrared Spectrograph (NIRSpec) instrument of the James Webb Space Telescope (JWST). This work introduces a new methodology for evaluating stability of MEMS devices to engineers as well as a new application of image registration algorithms to computer scientists.
Inspect Transfer Learning Architecture with Dilated Convolution
Nov 20, 2019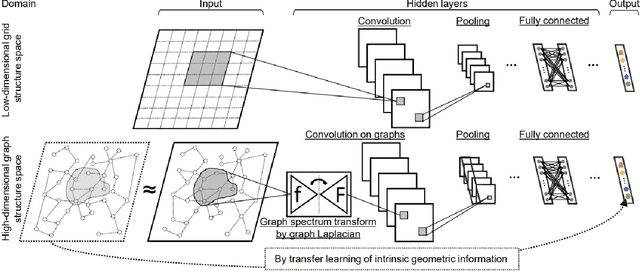
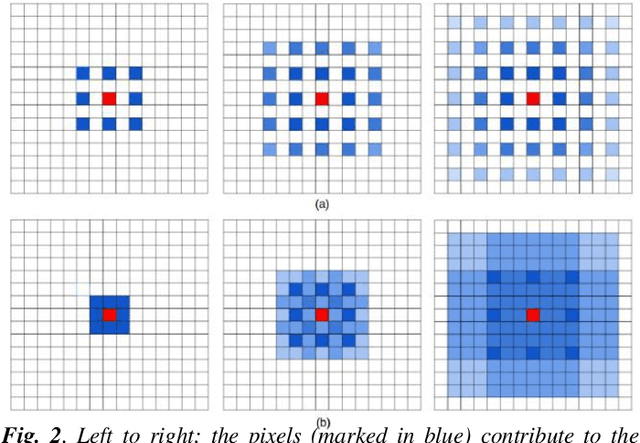
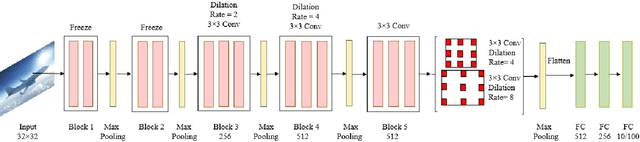
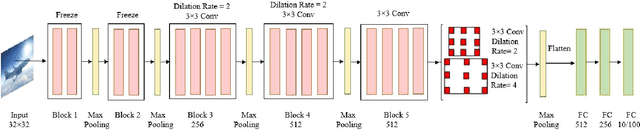
There are many award-winning pre-trained Convolutional Neural Network (CNN), which have a common phenomenon of increasing depth in convolutional layers. However, I inspect on VGG network, which is one of the famous model submitted to ILSVRC-2014, to show that slight modification in the basic architecture can enhance the accuracy result of the image classification task. In this paper, We present two improve architectures of pre-trained VGG-16 and VGG-19 networks that apply transfer learning when trained on a different dataset. I report a series of experimental result on various modification of the primary VGG networks and achieved significant out-performance on image classification task by: (1) freezing the first two blocks of the convolutional layers to prevent over-fitting and (2) applying different combination of dilation rate in the last three blocks of convolutional layer to reduce image resolution for feature extraction. Both the proposed architecture achieves a competitive result on CIFAR-10 and CIFAR-100 dataset.
Cross-Domain Collaborative Learning via Cluster Canonical Correlation Analysis and Random Walker for Hyperspectral Image Classification
Oct 30, 2018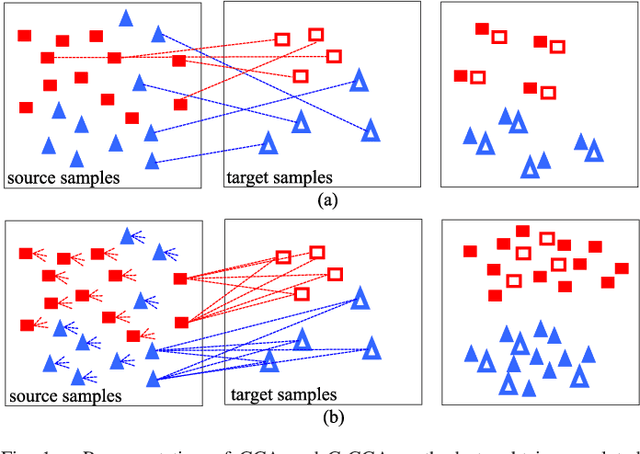
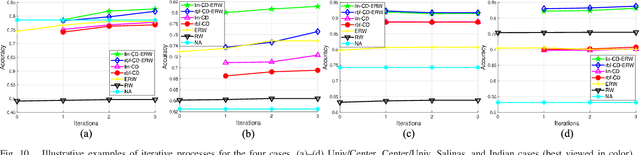
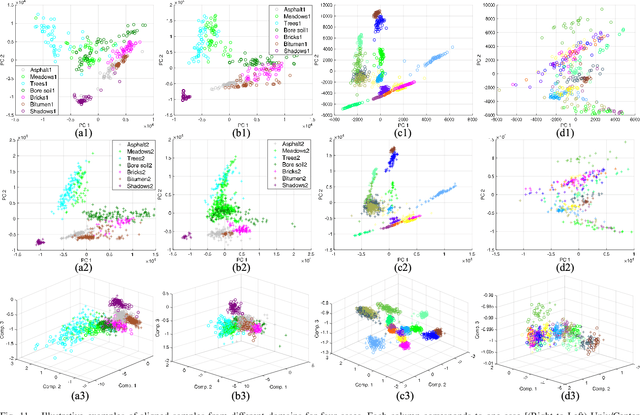
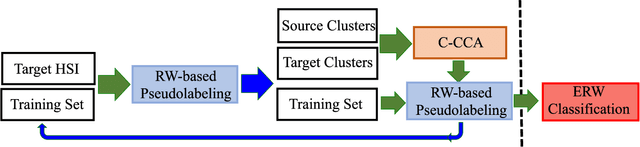
This paper introduces a novel heterogenous domain adaptation (HDA) method for hyperspectral image classification with a limited amount of labeled samples in both domains. The method is achieved in the way of cross-domain collaborative learning (CDCL), which is addressed via cluster canonical correlation analysis (C-CCA) and random walker (RW) algorithms. To be specific, the proposed CDCL method is an iterative process of three main stages, i.e. twice of RW-based pseudolabeling and cross domain learning via C-CCA. Firstly, given the initially labeled target samples as training set ($\mathbf{TS}$), the RW-based pseudolabeling is employed to update $\mathbf{TS}$ and extract target clusters ($\mathbf{TCs}$) by fusing the segmentation results obtained by RW and extended RW (ERW) classifiers. Secondly, cross domain learning via C-CCA is applied using labeled source samples and $\mathbf{TCs}$. The unlabeled target samples are then classified with the estimated probability maps using the model trained in the projected correlation subspace. Thirdly, both $\mathbf{TS}$ and estimated probability maps are used for updating $\mathbf{TS}$ again via RW-based pseudolabeling. When the iterative process finishes, the result obtained by the ERW classifier using the final $\mathbf{TS}$ and estimated probability maps is regarded as the final classification map. Experimental results on four real HSIs demonstrate that the proposed method can achieve better performance compared with the state-of-the-art HDA and ERW methods.
A Parallel Framework for Parametric Maximum Flow Problems in Image Segmentation
Dec 07, 2015
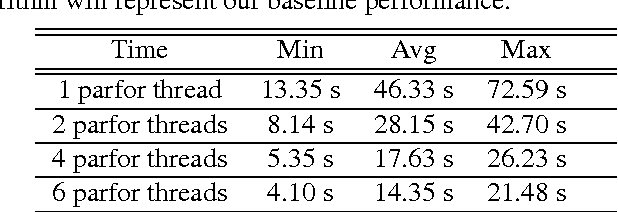
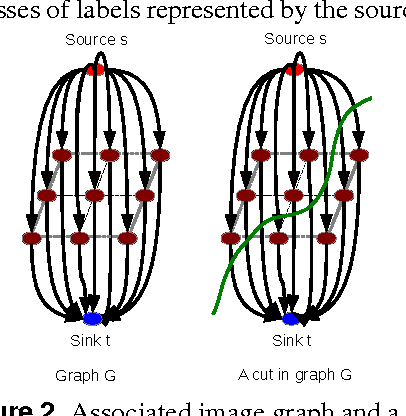
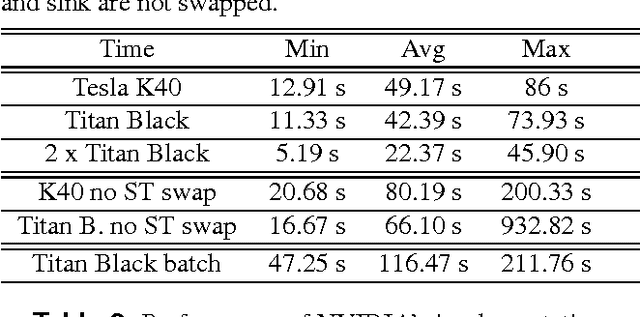
This paper presents a framework that supports the implementation of parallel solutions for the widespread parametric maximum flow computational routines used in image segmentation algorithms. The framework is based on supergraphs, a special construction combining several image graphs into a larger one, and works on various architectures (multi-core or GPU), either locally or remotely in a cluster of computing nodes. The framework can also be used for performance evaluation of parallel implementations of maximum flow algorithms. We present the case study of a state-of-the-art image segmentation algorithm based on graph cuts, Constrained Parametric Min-Cut (CPMC), that uses the parallel framework to solve parametric maximum flow problems, based on a GPU implementation of the well-known push-relabel algorithm. Our results indicate that real-time implementations based on the proposed techniques are possible.
Towards Feature Space Adversarial Attack
Apr 26, 2020

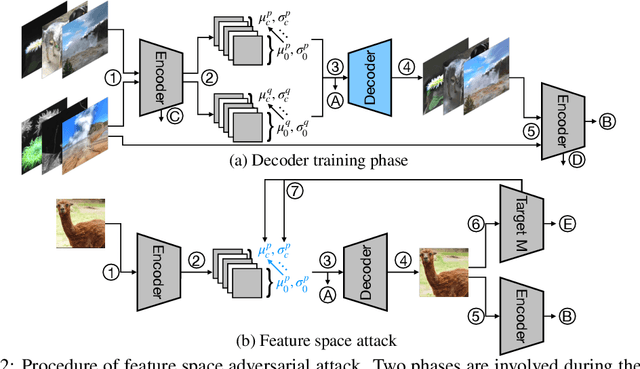
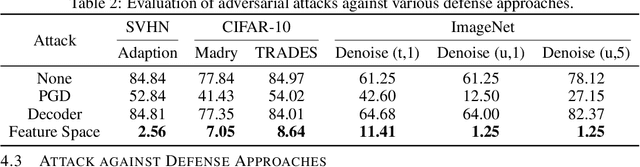
We propose a new type of adversarial attack to Deep Neural Networks (DNNs) for image classification. Different from most existing attacks that directly perturb input pixels. Our attack focuses on perturbing abstract features, more specifically, features that denote styles, including interpretable styles such as vivid colors and sharp outlines, and uninterpretable ones. It induces model misclassfication by injecting style changes insensitive for humans, through an optimization procedure. We show that state-of-the-art adversarial attack detection and defense techniques are ineffective in guarding against feature space attacks.