 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-Supervised Learning with Data Augmentation for End-to-End ASR
Jul 27, 2020
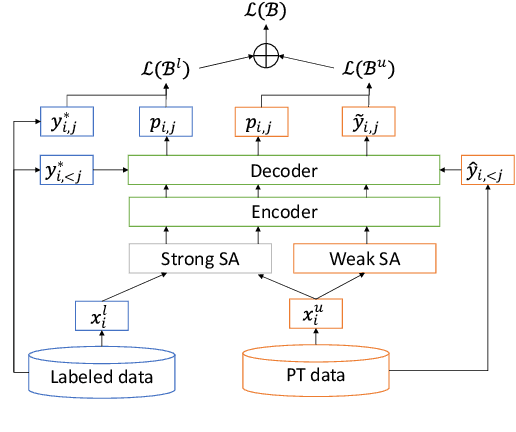

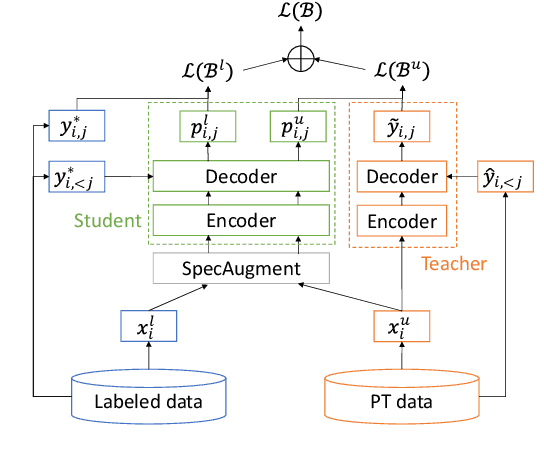
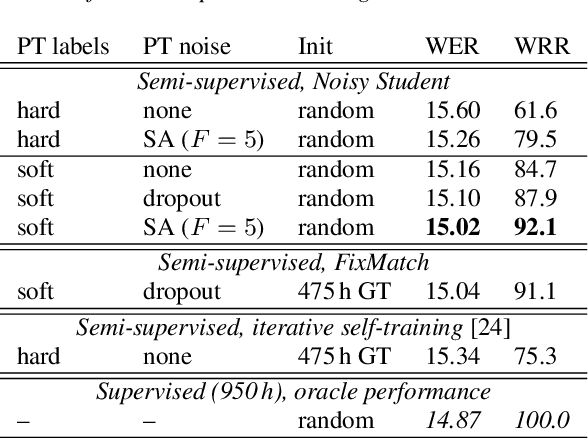
In this paper, we apply Semi-Supervised Learning (SSL) along with Data Augmentation (DA) for improving the accuracy of End-to-End ASR. We focus on the consistency regularization principle, which has been successfully applied to image classification tasks, and present sequence-to-sequence (seq2seq) versions of the FixMatch and Noisy Student algorithms. Specifically, we generate the pseudo labels for the unlabeled data on-the-fly with a seq2seq model after perturbing the input features with DA. We also propose soft label variants of both algorithms to cope with pseudo label errors, showing further performance improvements. We conduct SSL experiments on a conversational speech data set with 1.9kh manually transcribed training data, using only 25% of the original labels (475h labeled data). In the result, the Noisy Student algorithm with soft labels and consistency regularization achieves 10.4% word error rate (WER) reduction when adding 475h of unlabeled data, corresponding to a recovery rate of 92%. Furthermore, when iteratively adding 950h more unlabeled data, our best SSL performance is within 5% WER increase compared to using the full labeled training set (recovery rate: 78%).
Reducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder
Jul 13, 2020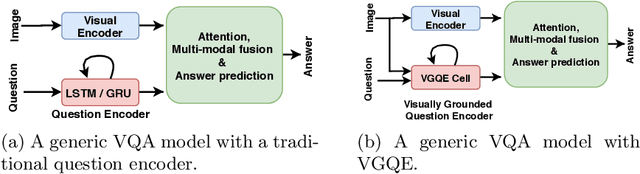
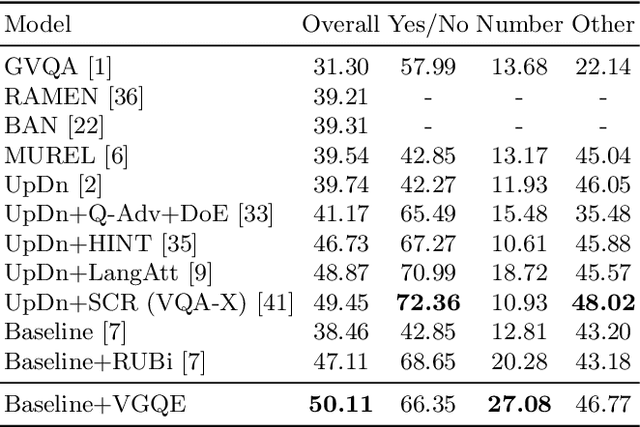
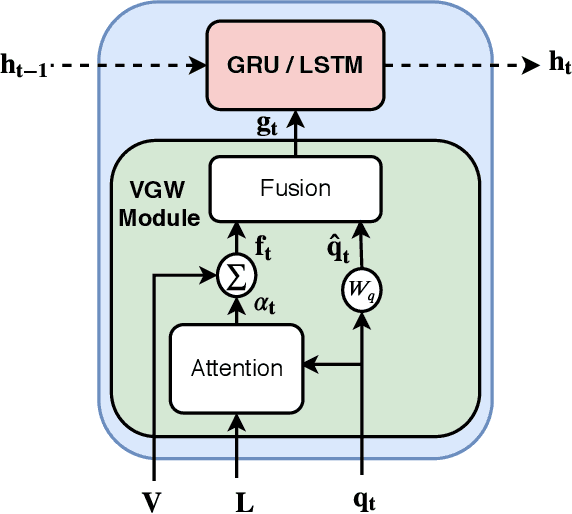
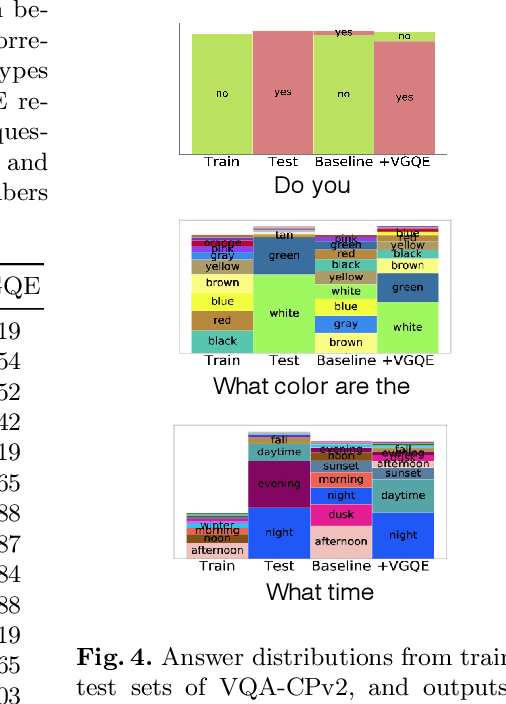
Recent studies have shown that current VQA models are heavily biased on the language priors in the train set to answer the question, irrespective of the image. E.g., overwhelmingly answer "what sport is" as "tennis" or "what color banana" as "yellow." This behavior restricts them from real-world application scenarios. In this work, we propose a novel model-agnostic question encoder, Visually-Grounded Question Encoder (VGQE), for VQA that reduces this effect. VGQE utilizes both visual and language modalities equally while encoding the question. Hence the question representation itself gets sufficient visual-grounding, and thus reduces the dependency of the model on the language priors. We demonstrate the effect of VGQE on three recent VQA models and achieve state-of-the-art results on the bias-sensitive split of the VQAv2 dataset; VQA-CPv2. Further, unlike the existing bias-reduction techniques, on the standard VQAv2 benchmark, our approach does not drop the accuracy; instead, it improves the performance.
SpoC: Spoofing Camera Fingerprints
Nov 27, 2019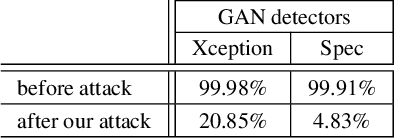
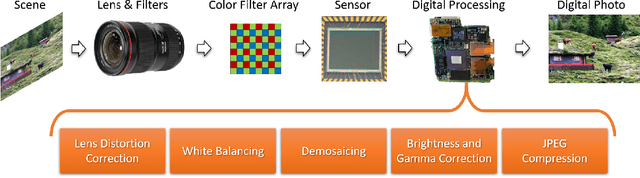
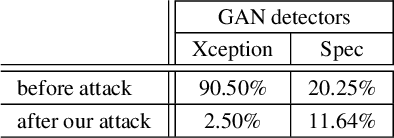
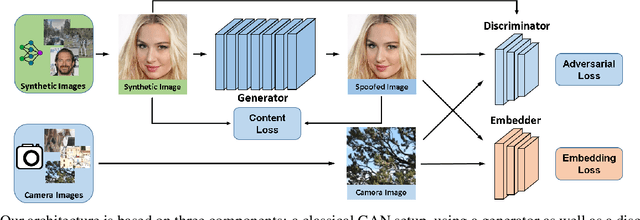
Thanks to the fast progress in synthetic media generation, creating realistic false images has become very easy. Such images can be used to wrap rich fake news with enhanced credibility, spawning a new wave of high-impact, high-risk misinformation campaigns. Therefore, there is a fast-growing interest in reliable detectors of manipulated media. The most powerful detectors, to date, rely on the subtle traces left by any device on all images acquired by it. In particular, due to proprietary in-camera processes, like demosaicing or compression, each camera model leaves trademark traces that can be exploited for forensic analyses. The absence or distortion of such traces in the target image is a strong hint of manipulation. In this paper, we challenge such detectors to gain better insight into their vulnerabilities. This is an important study in order to build better forgery detectors able to face malicious attacks. Our proposal consists of a GAN-based approach that injects camera traces into synthetic images. Given a GANgenerated image, we insert the traces of a specific camera model into it and deceive state-of-the-art detectors into believing the image was acquired by that model. Likewise, we deceive independent detectors of synthetic GAN images into believing the image is real. Experiments prove the effectiveness of the proposed method in a wide array of conditions. Moreover, no prior information on the attacked detectors is needed, but only sample images from the target camera.
Plug & Play Convolutional Regression Tracker for Video Object Detection
Mar 02, 2020
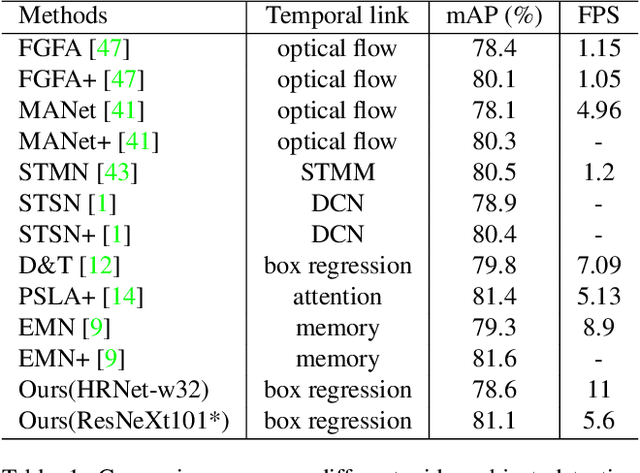
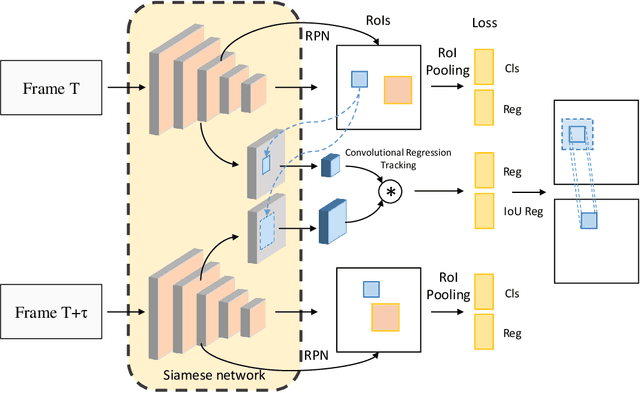

Video object detection targets to simultaneously localize the bounding boxes of the objects and identify their classes in a given video. One challenge for video object detection is to consistently detect all objects across the whole video. As the appearance of objects may deteriorate in some frames, features or detections from the other frames are commonly used to enhance the prediction. In this paper, we propose a Plug & Play scale-adaptive convolutional regression tracker for the video object detection task, which could be easily and compatibly implanted into the current state-of-the-art detection networks. As the tracker reuses the features from the detector, it is a very light-weighted increment to the detection network. The whole network performs at the speed close to a standard object detector. With our new video object detection pipeline design, image object detectors can be easily turned into efficient video object detectors without modifying any parameters. The performance is evaluated on the large-scale ImageNet VID dataset. Our Plug & Play design improves mAP score for the image detector by around 5% with only little speed drop.
Towards Learning Convolutions from Scratch
Jul 27, 2020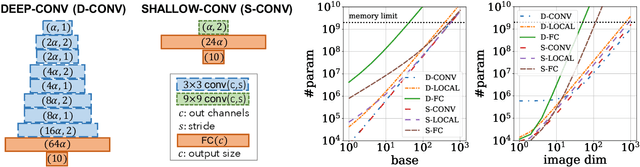
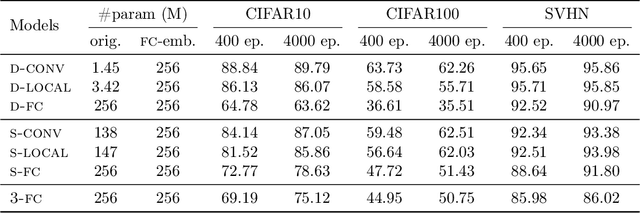
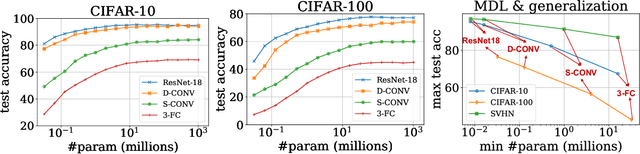
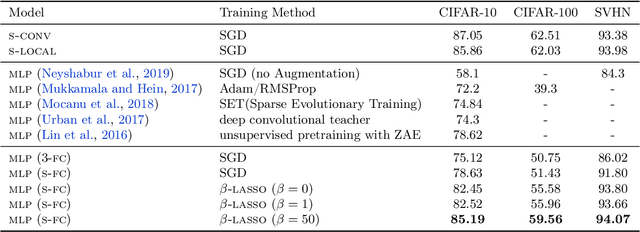
Convolution is one of the most essential components of architectures used in computer vision. As machine learning moves towards reducing the expert bias and learning it from data, a natural next step seems to be learning convolution-like structures from scratch. This, however, has proven elusive. For example, current state-of-the-art architecture search algorithms use convolution as one of the existing modules rather than learning it from data. In an attempt to understand the inductive bias that gives rise to convolutions, we investigate minimum description length as a guiding principle and show that in some settings, it can indeed be indicative of the performance of architectures. To find architectures with small description length, we propose $\beta$-LASSO, a simple variant of LASSO algorithm that, when applied on fully-connected networks for image classification tasks, learns architectures with local connections and achieves state-of-the-art accuracies for training fully-connected nets on CIFAR-10 (85.19%), CIFAR-100 (59.56%) and SVHN (94.07%) bridging the gap between fully-connected and convolutional nets.
AutoCLINT: The Winning Method in AutoCV Challenge 2019
May 09, 2020
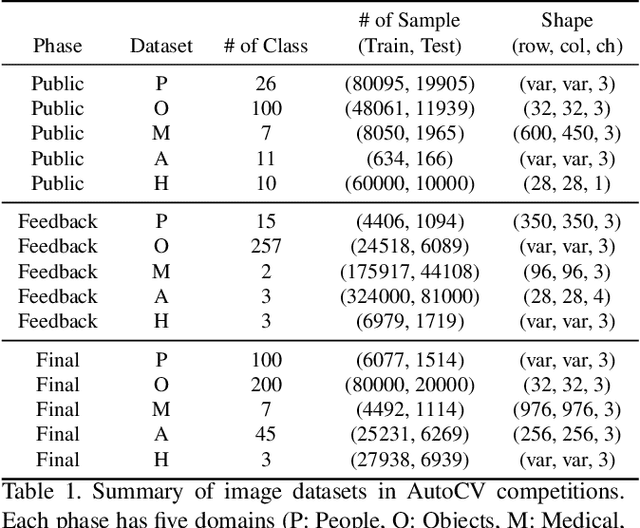
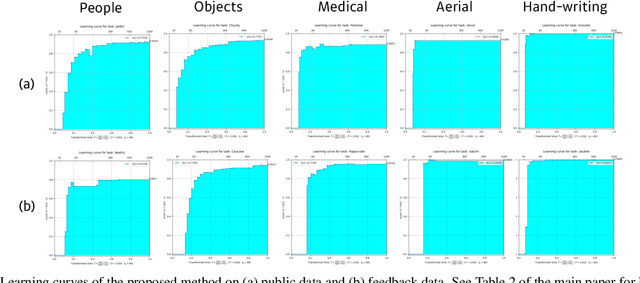

NeurIPS 2019 AutoDL challenge is a series of six automated machine learning competitions. Particularly, AutoCV challenges mainly focused on classification tasks on visual domain. In this paper, we introduce the winning method in the competition, AutoCLINT. The proposed method implements an autonomous training strategy, including efficient code optimization, and applies an automated data augmentation to achieve the fast adaptation of pretrained networks. We implement a light version of Fast AutoAugment to search for data augmentation policies efficiently for the arbitrarily given image domains. We also empirically analyze the components of the proposed method and provide ablation studies focusing on AutoCV datasets.
Towards Accuracy-Fairness Paradox: Adversarial Example-based Data Augmentation for Visual Debiasing
Jul 27, 2020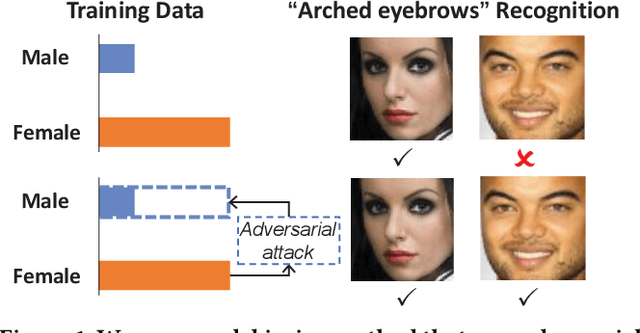
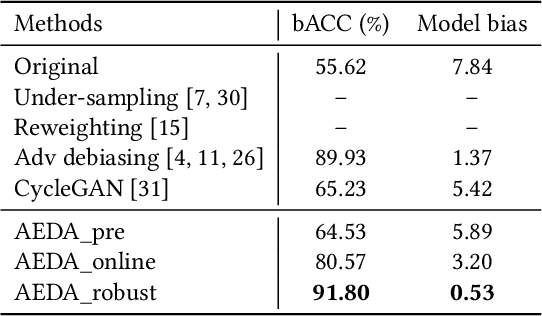
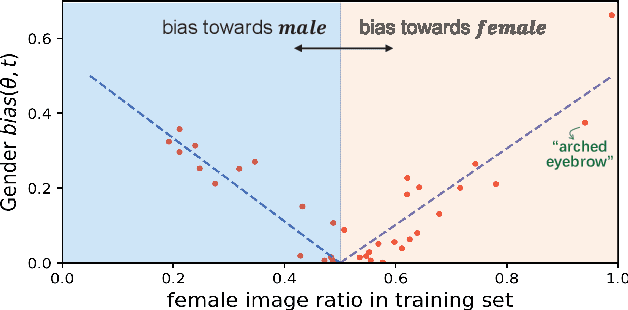
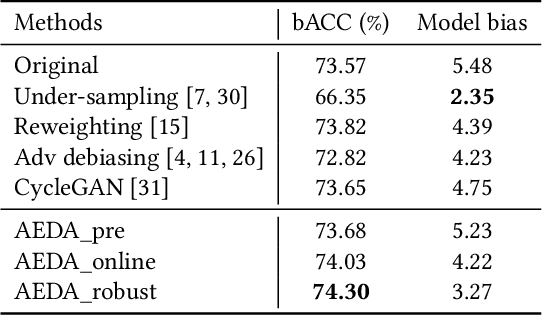
Machine learning fairness concerns about the biases towards certain protected or sensitive group of people when addressing the target tasks. This paper studies the debiasing problem in the context of image classification tasks. Our data analysis on facial attribute recognition demonstrates (1) the attribution of model bias from imbalanced training data distribution and (2) the potential of adversarial examples in balancing data distribution. We are thus motivated to employ adversarial example to augment the training data for visual debiasing. Specifically, to ensure the adversarial generalization as well as cross-task transferability, we propose to couple the operations of target task classifier training, bias task classifier training, and adversarial example generation. The generated adversarial examples supplement the target task training dataset via balancing the distribution over bias variables in an online fashion. Results on simulated and real-world debiasing experiments demonstrate the effectiveness of the proposed solution in simultaneously improving model accuracy and fairness. Preliminary experiment on few-shot learning further shows the potential of adversarial attack-based pseudo sample generation as alternative solution to make up for the training data lackage.
Fabric Defect Detection Using Vision-Based Tactile Sensor
Mar 02, 2020


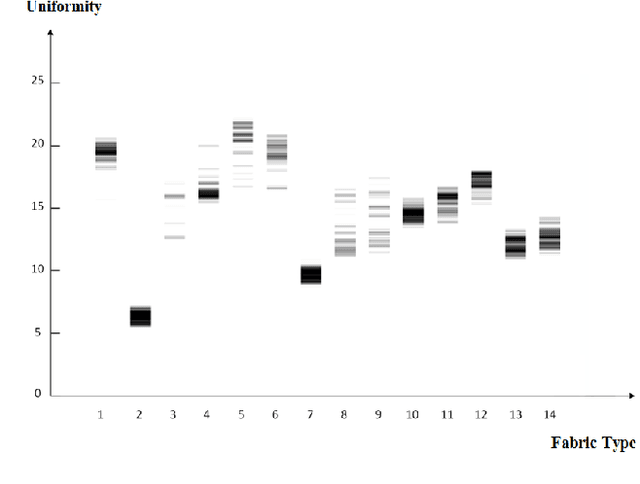
This paper introduces a new type of system for fabric defect detection with the tactile inspection system. Different from existed visual inspection systems, the proposed system implements a vision-based tactile sensor. The tactile sensor, which mainly consists of a camera, four LEDs, and an elastic sensing layer, captures detailed information about fabric surface structure and ignores the color and pattern. Thus, the ambiguity between a defect and image background related to fabric color and pattern is avoided. To utilize the tactile sensor for fabric inspection, we employ intensity adjustment for image preprocessing, Residual Network with ensemble learning for detecting defects, and uniformity measurement for selecting ideal dataset for model training. An experiment is conducted to verify the performance of the proposed tactile system. The experimental results have demonstrated the feasibility of the proposed system, which performs well in detecting structural defects for various types of fabrics. In addition, the system does not require external light sources, which skips the process of setting up and tuning a lighting environment.
Two-Stage Transfer Learning for Heterogeneous Robot Detection and 3D Joint Position Estimation in a 2D Camera Image using CNN
Feb 15, 2019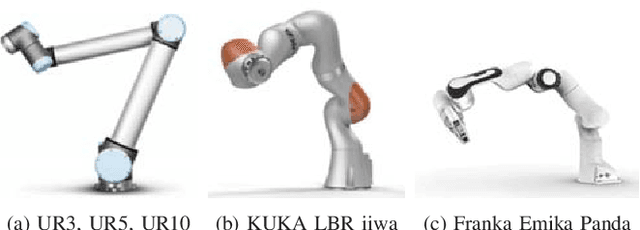


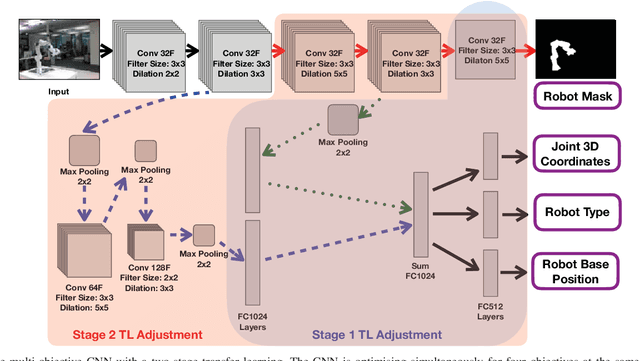
Collaborative robots are becoming more common on factory floors as well as regular environments, however, their safety still is not a fully solved issue. Collision detection does not always perform as expected and collision avoidance is still an active research area. Collision avoidance works well for fixed robot-camera setups, however, if they are shifted around, Eye-to-Hand calibration becomes invalid making it difficult to accurately run many of the existing collision avoidance algorithms. We approach the problem by presenting a stand-alone system capable of detecting the robot and estimating its position, including individual joints, by using a simple 2D colour image as an input, where no Eye-to-Hand calibration is needed. As an extension of previous work, a two-stage transfer learning approach is used to re-train a multi-objective convolutional neural network (CNN) to allow it to be used with heterogeneous robot arms. Our method is capable of detecting the robot in real-time and new robot types can be added by having significantly smaller training datasets compared to the requirements of a fully trained network. We present data collection approach, the structure of the multi-objective CNN, the two-stage transfer learning training and test results by using real robots from Universal Robots, Kuka, and Franka Emika. Eventually, we analyse possible application areas of our method together with the possible improvements.
Unsupervised Category Discovery via Looped Deep Pseudo-Task Optimization Using a Large Scale Radiology Image Database
Mar 25, 2016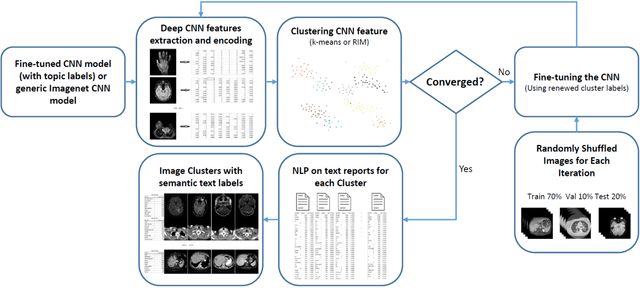
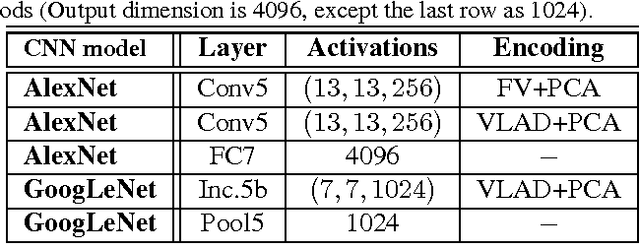
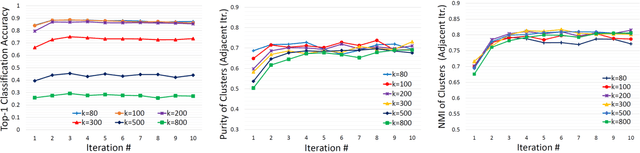
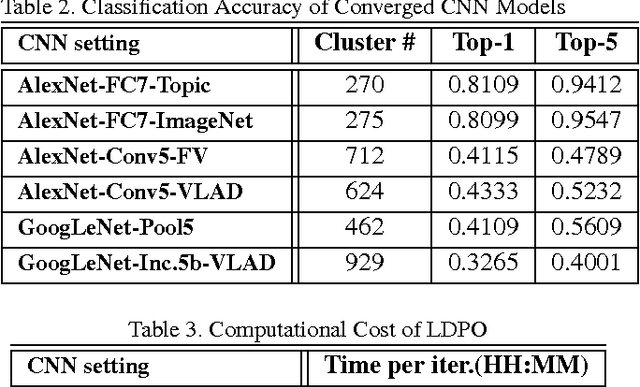
Obtaining semantic labels on a large scale radiology image database (215,786 key images from 61,845 unique patients) is a prerequisite yet bottleneck to train highly effective deep convolutional neural network (CNN) models for image recognition. Nevertheless, conventional methods for collecting image labels (e.g., Google search followed by crowd-sourcing) are not applicable due to the formidable difficulties of medical annotation tasks for those who are not clinically trained. This type of image labeling task remains non-trivial even for radiologists due to uncertainty and possible drastic inter-observer variation or inconsistency. In this paper, we present a looped deep pseudo-task optimization procedure for automatic category discovery of visually coherent and clinically semantic (concept) clusters. Our system can be initialized by domain-specific (CNN trained on radiology images and text report derived labels) or generic (ImageNet based) CNN models. Afterwards, a sequence of pseudo-tasks are exploited by the looped deep image feature clustering (to refine image labels) and deep CNN training/classification using new labels (to obtain more task representative deep features). Our method is conceptually simple and based on the hypothesized "convergence" of better labels leading to better trained CNN models which in turn feed more effective deep image features to facilitate more meaningful clustering/labels. We have empirically validated the convergence and demonstrated promising quantitative and qualitative results. Category labels of significantly higher quality than those in previous work are discovered. This allows for further investigation of the hierarchical semantic nature of the given large-scale radiology image database.