 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision Meets Wireless Positioning: Effective Person Re-identification with Recurrent Context Propagation
Aug 10, 2020
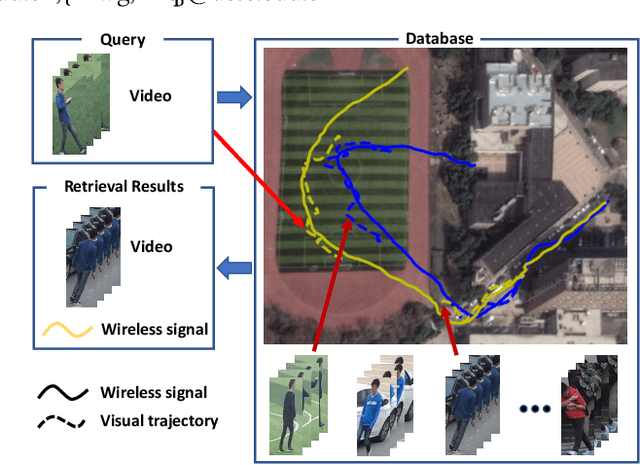


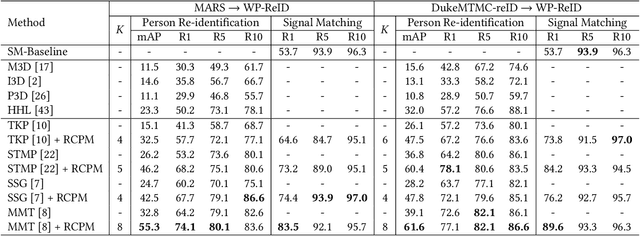
Existing person re-identification methods rely on the visual sensor to capture the pedestrians. The image or video data from visual sensor inevitably suffers the occlusion and dramatic variations of pedestrian postures, which degrades the re-identification performance and further limits its application to the open environment. On the other hand, for most people, one of the most important carry-on items is the mobile phone, which can be sensed by WiFi and cellular networks in the form of a wireless positioning signal. Such signal is robust to the pedestrian occlusion and visual appearance change, but suffers some positioning error. In this work, we approach person re-identification with the sensing data from both vision and wireless positioning. To take advantage of such cross-modality cues, we propose a novel recurrent context propagation module that enables information to propagate between visual data and wireless positioning data and finally improves the matching accuracy. To evaluate our approach, we contribute a new Wireless Positioning Person Re-identification (WP-ReID) dataset. Extensive experiments are conducted and demonstrate the effectiveness of the proposed algorithm. Code will be released at https://github.com/yolomax/WP-ReID.
Double Backpropagation for Training Autoencoders against Adversarial Attack
Mar 04, 2020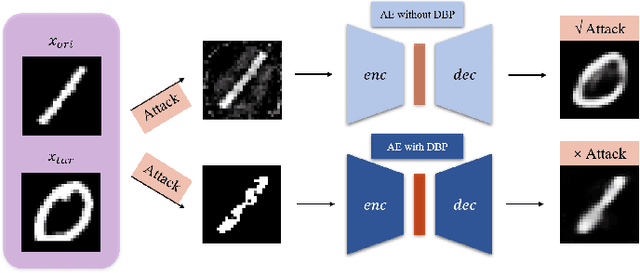

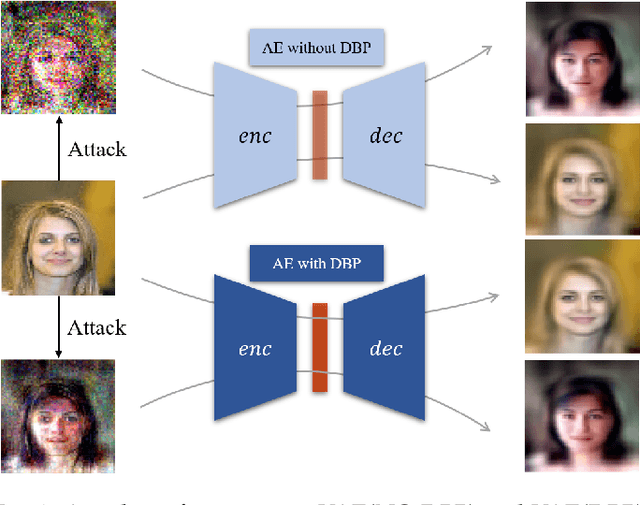

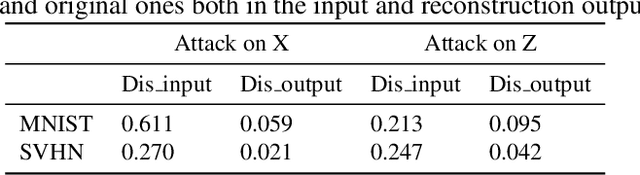
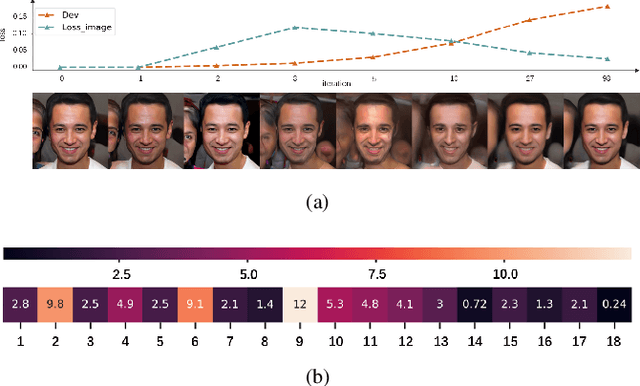
Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM.
Gated Convolutional Networks with Hybrid Connectivity for Image Classification
Sep 08, 2019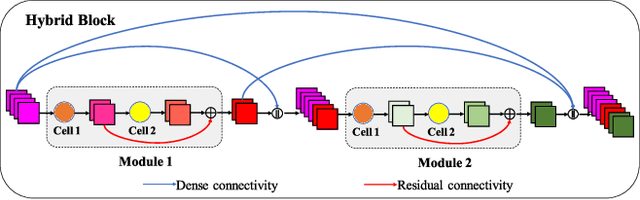
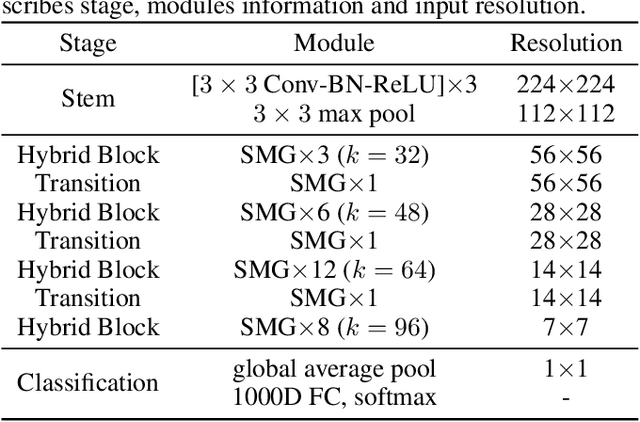
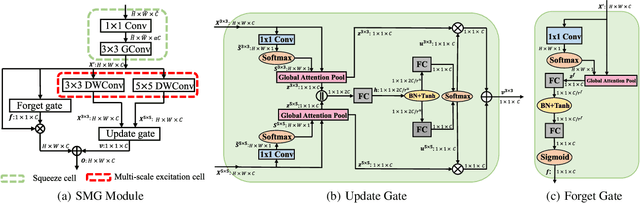
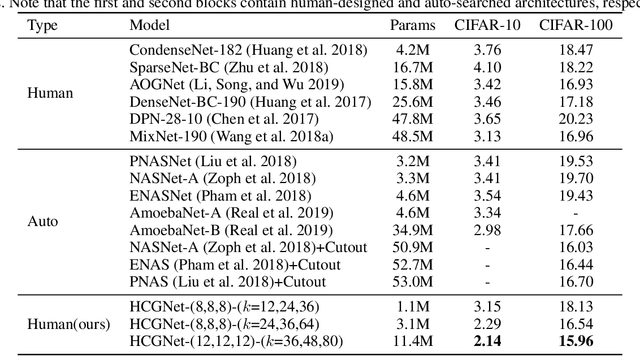
We design a highly efficient architecture called Gated Convolutional Network with Hybrid Connectivity (HCGNet), which is equipped with the combination of local residual and global dense connectivity to enjoy their individual superiorities as well as attention-based gate mechanism to assist feature recalibration. To adapt our hybrid connectivity, we further propose a novel module which includes a squeeze cell for obtaining the compact features from input and then a multi-scale excitation cell attached an update gate to model the global context features for capturing long-range dependency based on multi-scale information. We also locate a forget gate on residual connectivity to decay the reused features, which can be aggergated with newly global context features to form the output that can facilitate effective feature exploration as well as re-exploitation to some extent. Moreover, the number of our proposed modules under dense connectivity can be quite fewer than classical DenseNet thus reducing considerable redundancy but with empirically better performance. On CIFAR-10/100 datasets, HCGNets significantly outperform state-of-the-art both human-designed and auto-searched networks with much fewer parameters. It can also consistently obtain better performance and interpretability than widely applied networks in practice on ImageNet dataset.
Type I Attack for Generative Models
Mar 04, 2020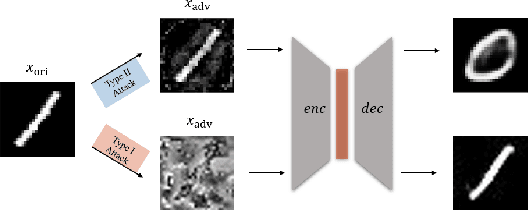

Generative models are popular tools with a wide range of applications. Nevertheless, it is as vulnerable to adversarial samples as classifiers. The existing attack methods mainly focus on generating adversarial examples by adding imperceptible perturbations to input, which leads to wrong result. However, we focus on another aspect of attack, i.e., cheating models by significant changes. The former induces Type II error and the latter causes Type I error. In this paper, we propose Type I attack to generative models such as VAE and GAN. One example given in VAE is that we can change an original image significantly to a meaningless one but their reconstruction results are similar. To implement the Type I attack, we destroy the original one by increasing the distance in input space while keeping the output similar because different inputs may correspond to similar features for the property of deep neural network. Experimental results show that our attack method is effective to generate Type I adversarial examples for generative models on large-scale image datasets.
Effect of Input Noise Dimension in GANs
Apr 15, 2020
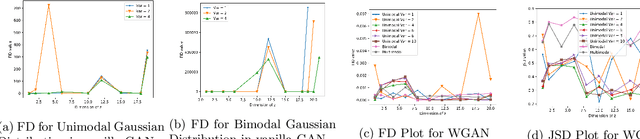


Generative Adversarial Networks (GANs) are by far the most successful generative models. Learning the transformation which maps a low dimensional input noise to the data distribution forms the foundation for GANs. Although they have been applied in various domains, they are prone to certain challenges like mode collapse and unstable training. To overcome the challenges, researchers have proposed novel loss functions, architectures, and optimization methods. In our work here, unlike the previous approaches, we focus on the input noise and its role in the generation. We aim to quantitatively and qualitatively study the effect of the dimension of the input noise on the performance of GANs. For quantitative measures, typically \emph{Fr\'{e}chet Inception Distance (FID)} and \emph{Inception Score (IS)} are used as performance measure on image data-sets. We compare the FID and IS values for DCGAN and WGAN-GP. We use three different image data-sets -- each consisting of different levels of complexity. Through our experiments, we show that the right dimension of input noise for optimal results depends on the data-set and architecture used. We also observe that the state of the art performance measures does not provide enough useful insights. Hence we conclude that we need further theoretical analysis for understanding the relationship between the low dimensional distribution and the generated images. We also require better performance measures.
An implementation of an imitation game with ASD children to learn nursery rhymes
Apr 10, 2020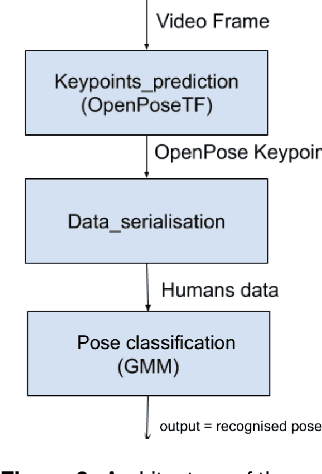
Previous studies have suggested that being imitated by an adult is an effective intervention with children with autism and developmental delay. The purpose of this study is to investigate if an imitation game with a robot can arise interest from children and constitute an effective tool to be used in clinical activities. In this paper, we describe the design of our nursery rhyme imitation game, its implementation based on RGB image pose recognition and the preliminary tests we performed.
The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 13, 2020
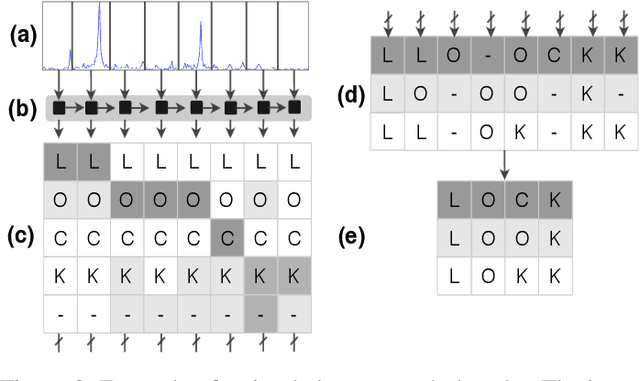
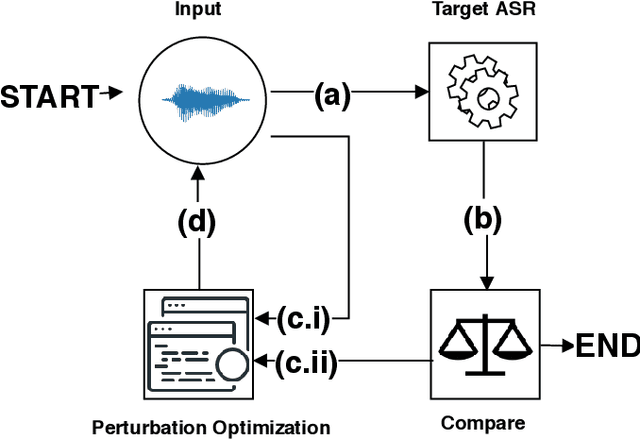
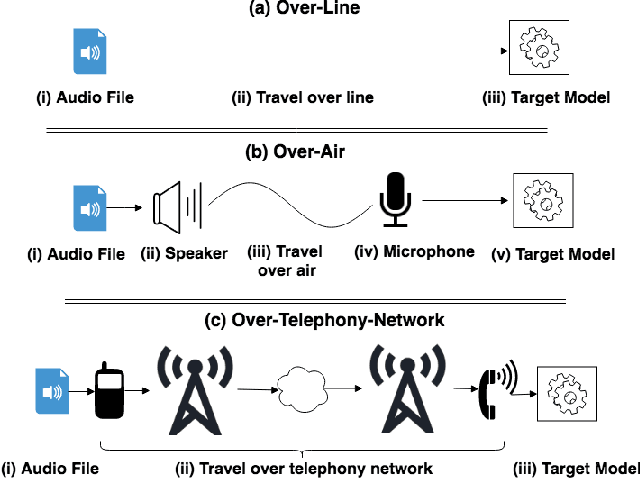
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.
Identify the cells' nuclei based on the deep learning neural network
Nov 22, 2019
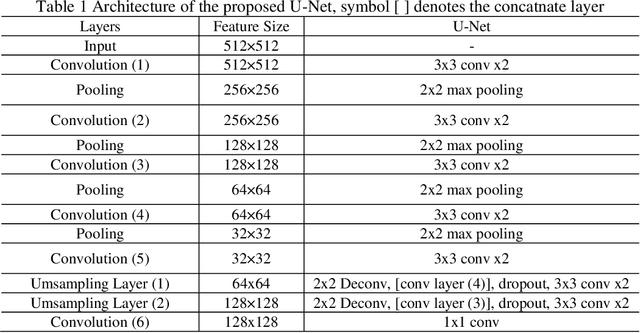

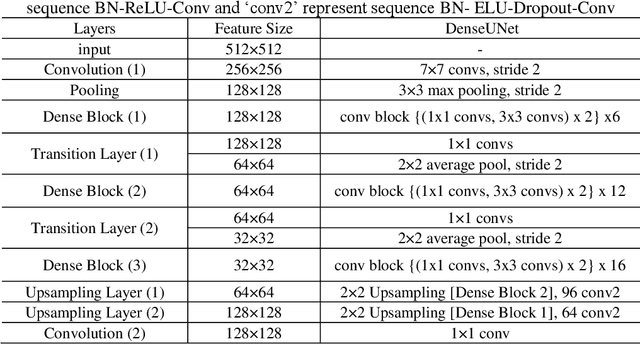
Identify the cells' nuclei is the important point for most medical analyses. To assist doctors finding the accurate cell' nuclei location automatically is highly demanded in the clinical practice. Recently, fully convolutional neural network (FCNs) serve as the back-bone in many image segmentation, like liver and tumer segmentation in medical field, human body block in technical filed. The cells' nuclei identification task is also kind of image segmentation. To achieve this, we prefer to use deep learning algorithms. we construct three general frameworks, one is Mask Region-based Convolutional Neural Network (Mask RCNN), which has the high performance in many image segmentations, one is U-net, which has the high generalization performance on small dataset and the other is DenseUNet, which is mixture network architecture with Dense Net and U-net. we compare the performance of these three frameworks. And we evaluated our method on the dataset of data science bowl 2018 challenge. For single model without any ensemble, they all have good performance.
Image Segmentation and Restoration Using Parametric Contours With Free Endpoints
Apr 27, 2015
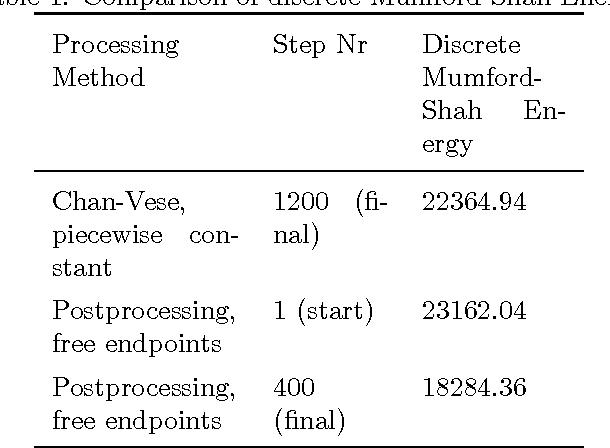
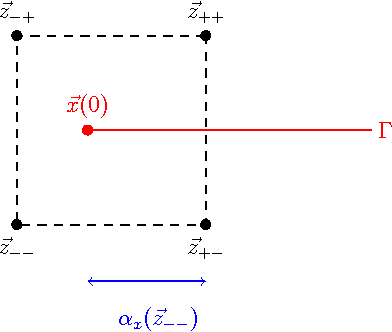
In this paper, we introduce a novel approach for active contours with free endpoints. A scheme is presented for image segmentation and restoration based on a discrete version of the Mumford-Shah functional where the contours can be both closed and open curves. Additional to a flow of the curves in normal direction, evolution laws for the tangential flow of the endpoints are derived. Using a parametric approach to describe the evolving contours together with an edge-preserving denoising, we obtain a fast method for image segmentation and restoration. The analytical and numerical schemes are presented followed by numerical experiments with artificial test images and with a real medical image.
Black-Box Saliency Map Generation Using Bayesian Optimisation
Jan 30, 2020
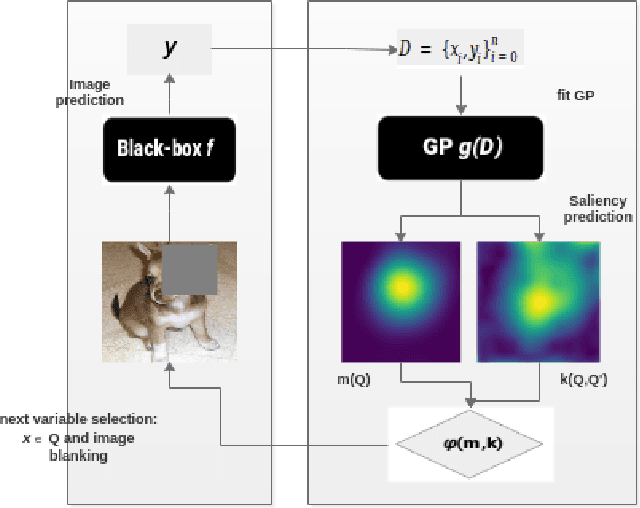
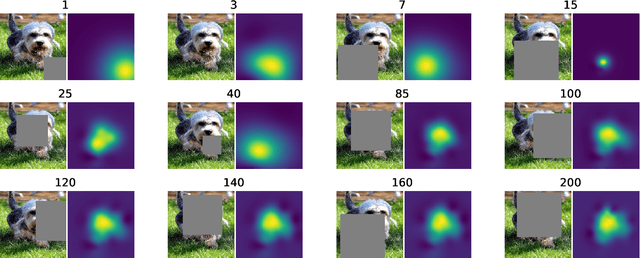
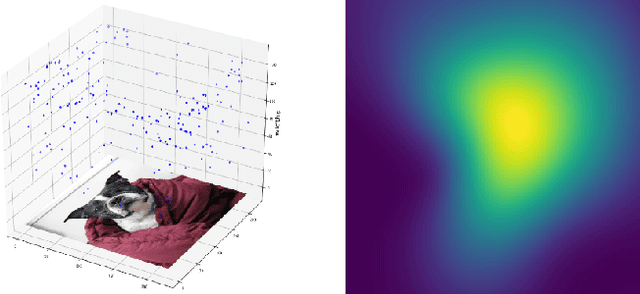
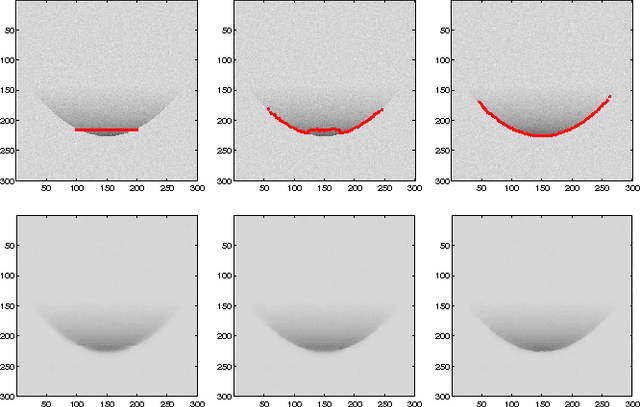
Saliency maps are often used in computer vision to provide intuitive interpretations of what input regions a model has used to produce a specific prediction. A number of approaches to saliency map generation are available, but most require access to model parameters. This work proposes an approach for saliency map generation for black-box models, where no access to model parameters is available, using a Bayesian optimisation sampling method. The approach aims to find the global salient image region responsible for a particular (black-box) model's prediction. This is achieved by a sampling-based approach to model perturbations that seeks to localise salient regions of an image to the black-box model. Results show that the proposed approach to saliency map generation outperforms grid-based perturbation approaches, and performs similarly to gradient-based approaches which require access to model parameters.