 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UESegNet: Context Aware Unconstrained ROI Segmentation Networks for Ear Biometric
Oct 08, 2020
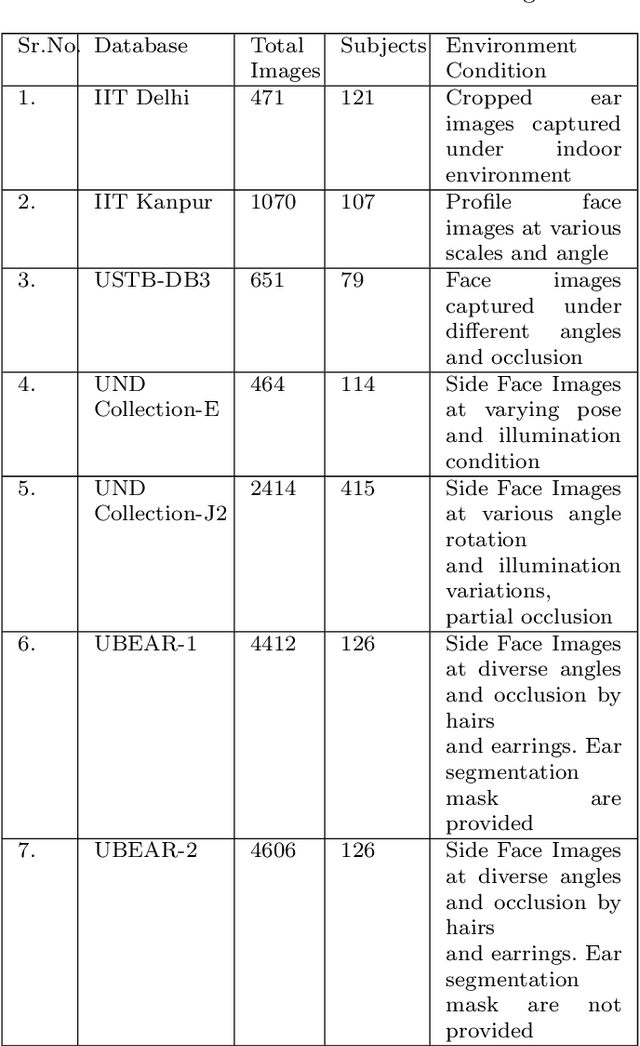
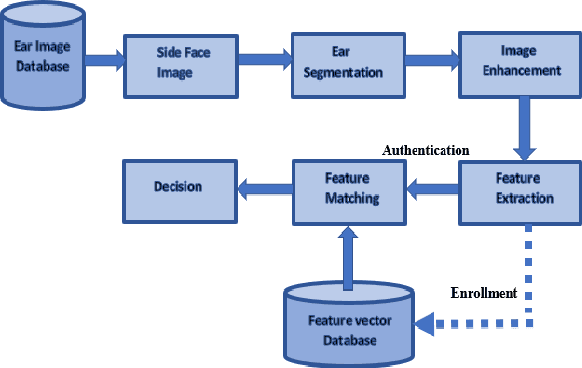
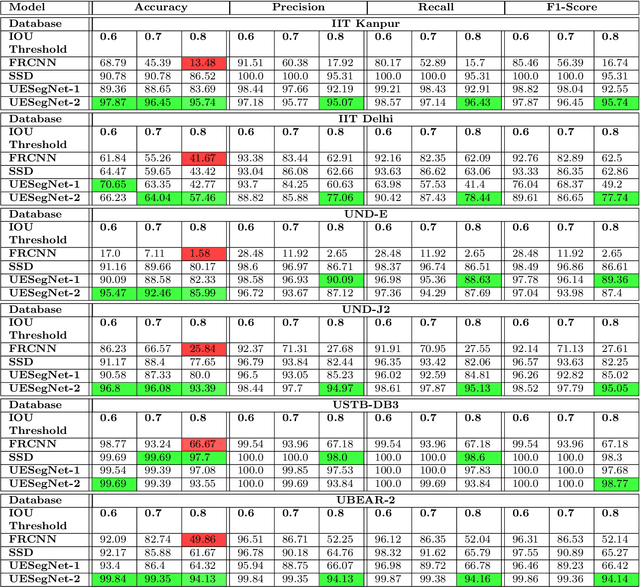
Biometric-based personal authentication systems have seen a strong demand mainly due to the increasing concern in various privacy and security applications. Although the use of each biometric trait is problem dependent, the human ear has been found to have enough discriminating characteristics to allow its use as a strong biometric measure. To locate an ear in a 2D side face image is a challenging task, numerous existing approaches have achieved significant performance, but the majority of studies are based on the constrained environment. However, ear biometrics possess a great level of difficulties in the unconstrained environment, where pose, scale, occlusion, illuminations, background clutter etc. varies to a great extent. To address the problem of ear localization in the wild, we have proposed two high-performance region of interest (ROI) segmentation models UESegNet-1 and UESegNet-2, which are fundamentally based on deep convolutional neural networks and primarily uses contextual information to localize ear in the unconstrained environment. Additionally, we have applied state-of-the-art deep learning models viz; FRCNN (Faster Region Proposal Network) and SSD (Single Shot MultiBox Detecor) for ear localization task. To test the model's generalization, they are evaluated on six different benchmark datasets viz; IITD, IITK, USTB-DB3, UND-E, UND-J2 and UBEAR, all of which contain challenging images. The performance of the models is compared on the basis of object detection performance measure parameters such as IOU (Intersection Over Union), Accuracy, Precision, Recall, and F1-Score. It has been observed that the proposed models UESegNet-1 and UESegNet-2 outperformed the FRCNN and SSD at higher values of IOUs i.e. an accuracy of 100\% is achieved at IOU 0.5 on majority of the databases.
A Benchmark for Studying Diabetic Retinopathy: Segmentation, Grading, and Transferability
Aug 22, 2020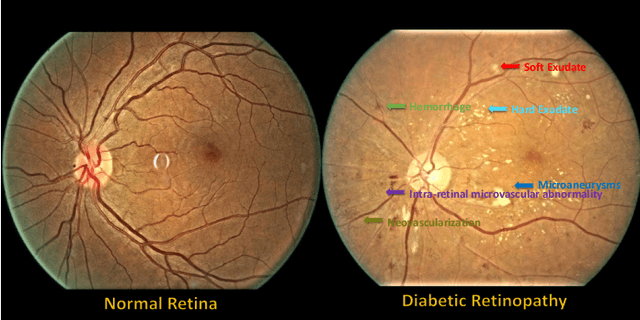
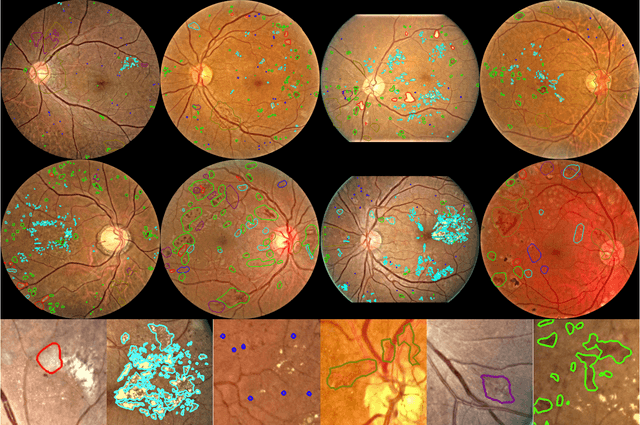
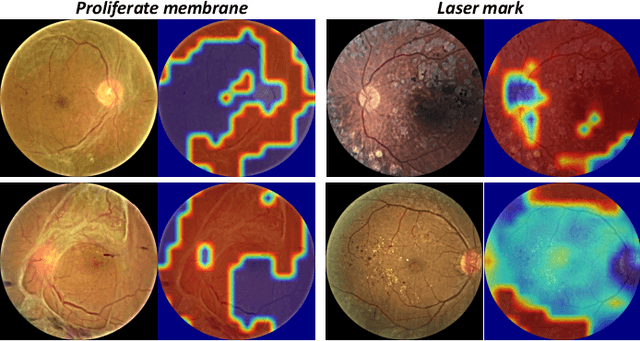
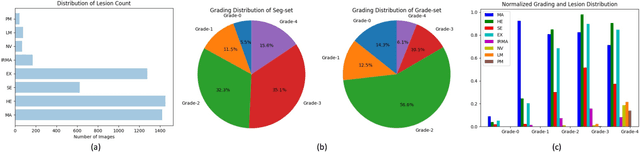
People with diabetes are at risk of developing an eye disease called diabetic retinopathy (DR). This disease occurs when high blood glucose levels cause damage to blood vessels in the retina. Computer-aided DR diagnosis is a promising tool for early detection of DR and severity grading, due to the great success of deep learning. However, most current DR diagnosis systems do not achieve satisfactory performance or interpretability for ophthalmologists, due to the lack of training data with consistent and fine-grained annotations. To address this problem, we construct a large-scale fine-grained annotated DR dataset containing 2,842 images (FGADR). This dataset has 1,842 images with pixel-level DR-related lesion annotations, and 1,000 images with image-level labels graded by six board-certified ophthalmologists with intra-rater consistency. The proposed dataset will enable extensive studies on DR diagnosis. We set up three benchmark tasks for evaluation: 1. DR lesion segmentation; 2. DR grading by joint classification and segmentation; 3. Transfer learning for ocular multi-disease identification. Moreover, a novel inductive transfer learning method is introduced for the third task. Extensive experiments using different state-of-the-art methods are conducted on our FGADR dataset, which can serve as baselines for future research.
Weyl group orbit functions in image processing
Feb 17, 2014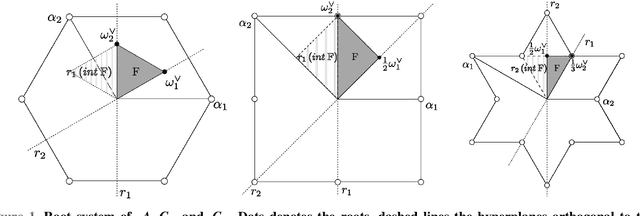


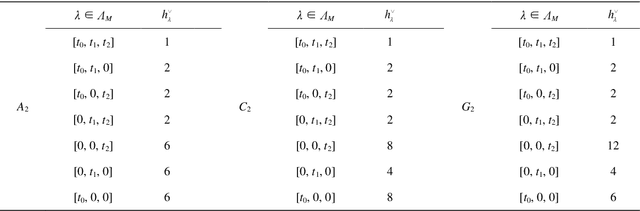
We deal with the Fourier-like analysis of functions on discrete grids in two-dimensional simplexes using $C-$ and $E-$ Weyl group orbit functions. For these cases we present the convolution theorem. We provide an example of application of image processing using the $C-$ functions and the convolutions for spatial filtering of the treated image.
* 12 pages, 5 figures
The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 13, 2020
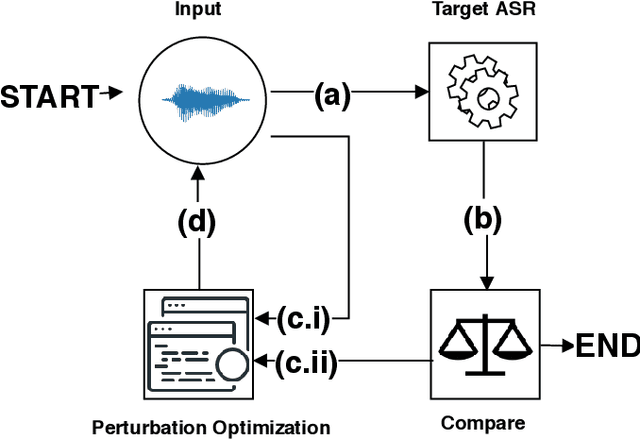
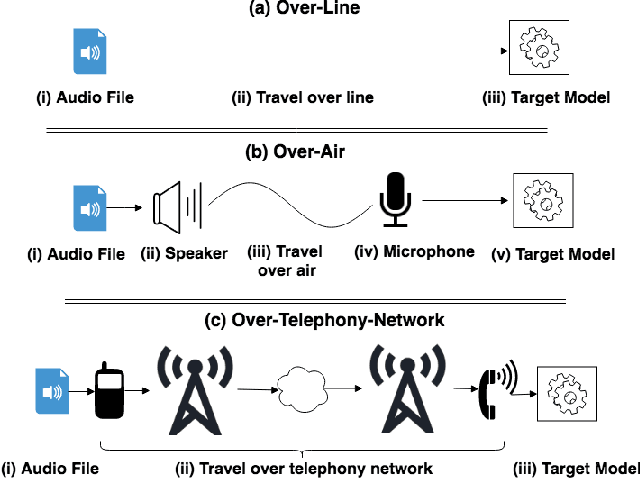
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.
Barcodes for Medical Image Retrieval Using Autoencoded Radon Transform
Sep 16, 2016
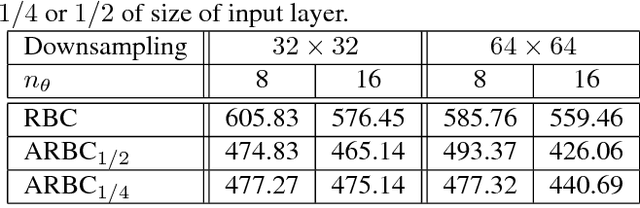
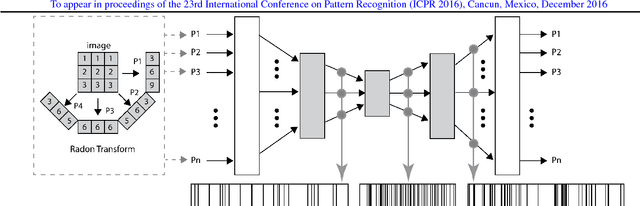

Using content-based binary codes to tag digital images has emerged as a promising retrieval technology. Recently, Radon barcodes (RBCs) have been introduced as a new binary descriptor for image search. RBCs are generated by binarization of Radon projections and by assembling them into a vector, namely the barcode. A simple local thresholding has been suggested for binarization. In this paper, we put forward the idea of "autoencoded Radon barcodes". Using images in a training dataset, we autoencode Radon projections to perform binarization on outputs of hidden layers. We employed the mini-batch stochastic gradient descent approach for the training. Each hidden layer of the autoencoder can produce a barcode using a threshold determined based on the range of the logistic function used. The compressing capability of autoencoders apparently reduces the redundancies inherent in Radon projections leading to more accurate retrieval results. The IRMA dataset with 14,410 x-ray images is used to validate the performance of the proposed method. The experimental results, containing comparison with RBCs, SURF and BRISK, show that autoencoded Radon barcode (ARBC) has the capacity to capture important information and to learn richer representations resulting in lower retrieval errors for image retrieval measured with the accuracy of the first hit only.
TensorShield: Tensor-based Defense Against Adversarial Attacks on Images
Feb 18, 2020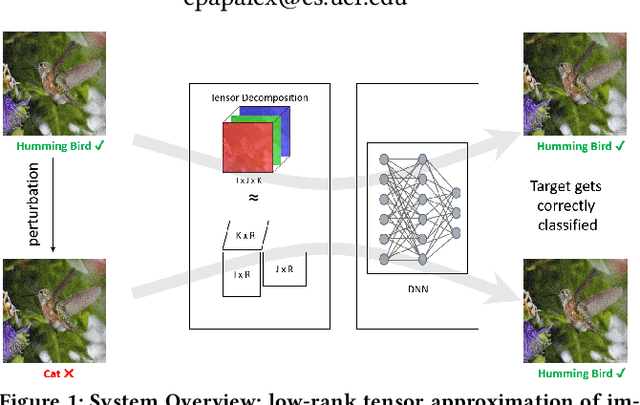
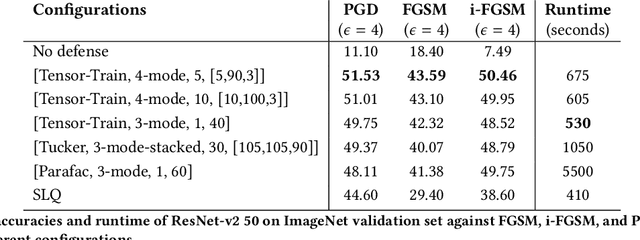
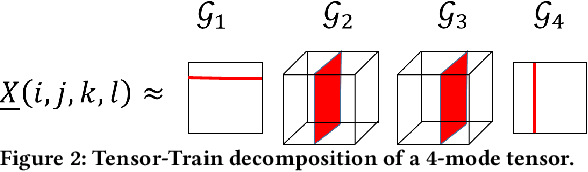
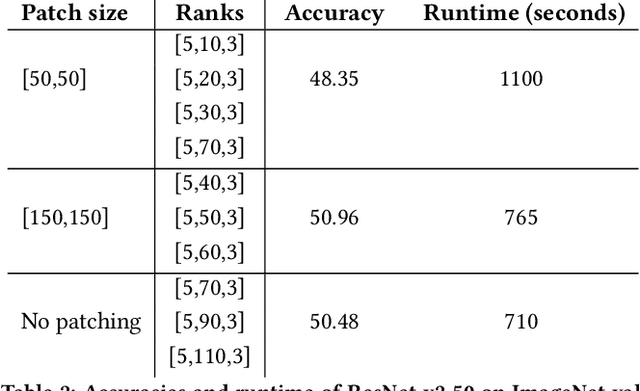
Recent studies have demonstrated that machine learning approaches like deep neural networks (DNNs) are easily fooled by adversarial attacks. Subtle and imperceptible perturbations of the data are able to change the result of deep neural networks. Leveraging vulnerable machine learning methods raises many concerns especially in domains where security is an important factor. Therefore, it is crucial to design defense mechanisms against adversarial attacks. For the task of image classification, unnoticeable perturbations mostly occur in the high-frequency spectrum of the image. In this paper, we utilize tensor decomposition techniques as a preprocessing step to find a low-rank approximation of images which can significantly discard high-frequency perturbations. Recently a defense framework called Shield could "vaccinate" Convolutional Neural Networks (CNN) against adversarial examples by performing random-quality JPEG compressions on local patches of images on the ImageNet dataset. Our tensor-based defense mechanism outperforms the SLQ method from Shield by 14% against FastGradient Descent (FGSM) adversarial attacks, while maintaining comparable speed.
To See in the Dark: N2DGAN for Background Modeling in Nighttime Scene
Dec 12, 2019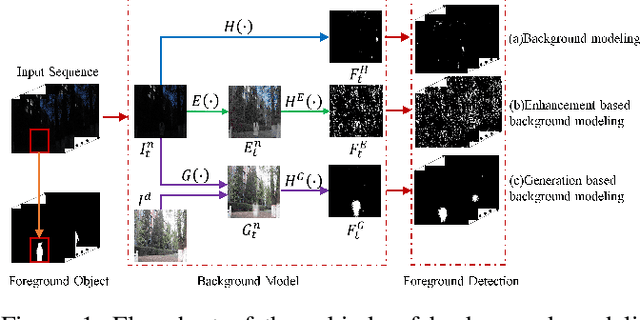
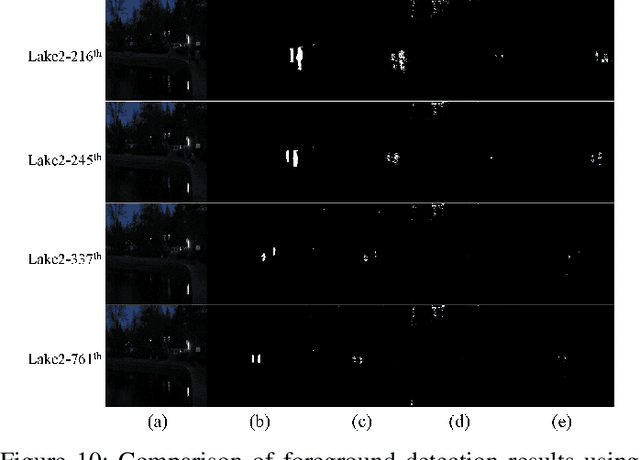
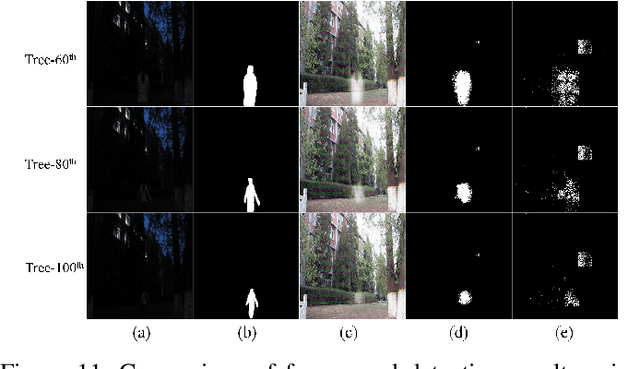
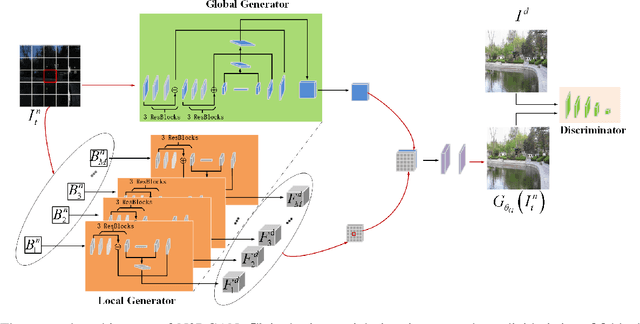
Due to the deteriorated conditions of \mbox{illumination} lack and uneven lighting, nighttime images have lower contrast and higher noise than their daytime counterparts of the same scene, which limits seriously the performances of conventional background modeling methods. For such a challenging problem of background modeling under nighttime scene, an innovative and reasonable solution is proposed in this paper, which paves a new way completely different from the existing ones. To make background modeling under nighttime scene performs as well as in daytime condition, we put forward a promising generation-based background modeling framework for foreground surveillance. With a pre-specified daytime reference image as background frame, the {\bfseries GAN} based generation model, called {\bfseries N2DGAN}, is trained to transfer each frame of {\bfseries n}ighttime video {\bfseries to} a virtual {\bfseries d}aytime image with the same scene to the reference image except for the foreground region. Specifically, to balance the preservation of background scene and the foreground object(s) in generating the virtual daytime image, we present a two-pathway generation model, in which the global and local sub-networks are well combined with spatial and temporal consistency constraints. For the sequence of generated virtual daytime images, a multi-scale Bayes model is further proposed to characterize pertinently the temporal variation of background. We evaluate on collected datasets with manually labeled ground truth, which provides a valuable resource for related research community. The impressive results illustrated in both the main paper and supplementary show efficacy of our proposed approach.
ALCN: Adaptive Local Contrast Normalization
Apr 15, 2020
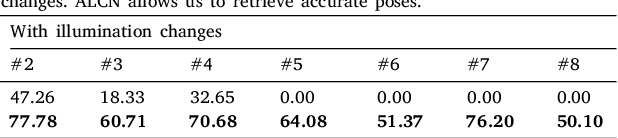
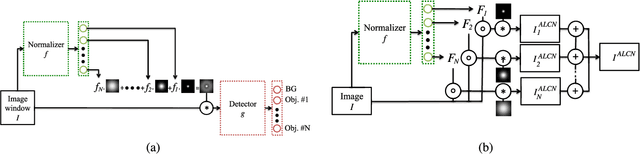

To make Robotics and Augmented Reality applications robust to illumination changes, the current trend is to train a Deep Network with training images captured under many different lighting conditions. Unfortunately, creating such a training set is a very unwieldy and complex task. We therefore propose a novel illumination normalization method that can easily be used for different problems with challenging illumination conditions. Our preliminary experiments show that among current normalization methods, the Difference-of Gaussians method remains a very good baseline, and we introduce a novel illumination normalization model that generalizes it. Our key insight is then that the normalization parameters should depend on the input image, and we aim to train a Convolutional Neural Network to predict these parameters from the input image. This, however, cannot be done in a supervised manner, as the optimal parameters are not known a priori. We thus designed a method to train this network jointly with another network that aims to recognize objects under different illuminations: The latter network performs well when the former network predicts good values for the normalization parameters. We show that our method significantly outperforms standard normalization methods and would also be appear to be universal since it does not have to be re-trained for each new application. Our method improves the robustness to light changes of state-of-the-art 3D object detection and face recognition methods.
A Novel Histogram Based Robust Image Registration Technique
Feb 23, 2014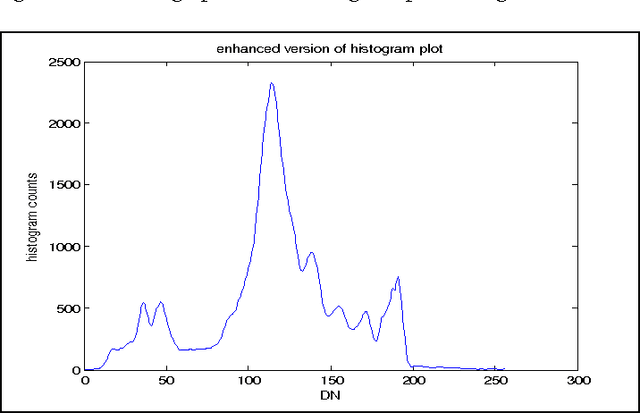
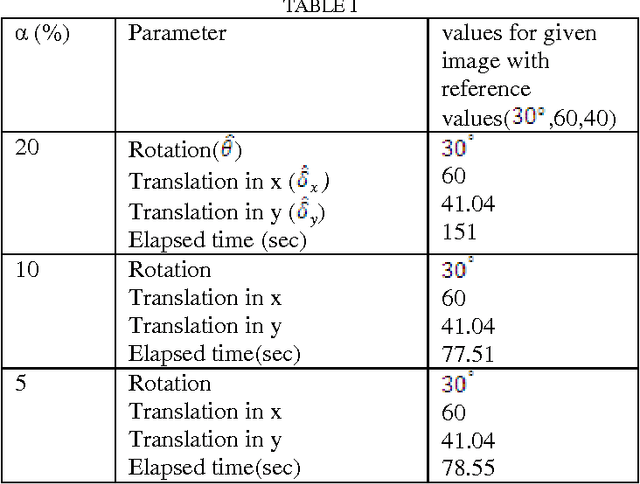
In this paper, a method for Automatic Image Registration (AIR) through histogram is proposed. Automatic image registration is one of the crucial steps in the analysis of remotely sensed data. A new acquired image must be transformed, using image registration techniques, to match the orientation and scale of previous related images. This new approach combines several segmentations of the pair of images to be registered. A relaxation parameter on the histogram modes delineation is introduced. It is followed by characterization of the extracted objects through the objects area, axis ratio, and perimeter and fractal dimension. The matched objects are used for rotation and translation estimation. It allows for the registration of pairs of images with differences in rotation and translation. This method contributes to subpixel accuracy.
Depth from a Single Image by Harmonizing Overcomplete Local Network Predictions
Sep 07, 2016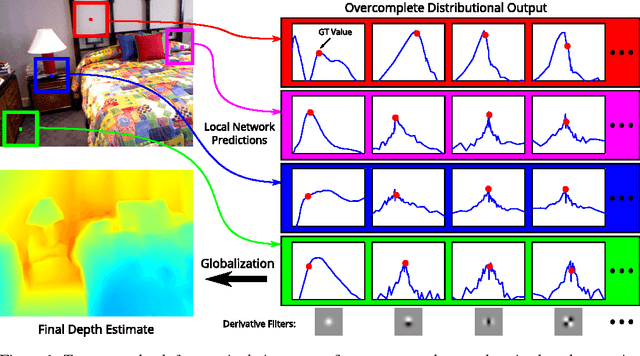
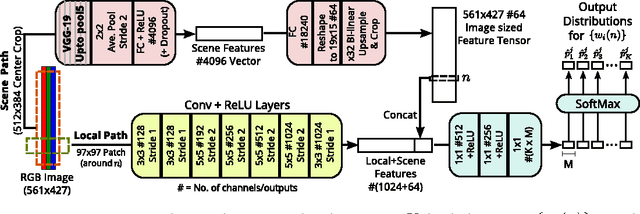
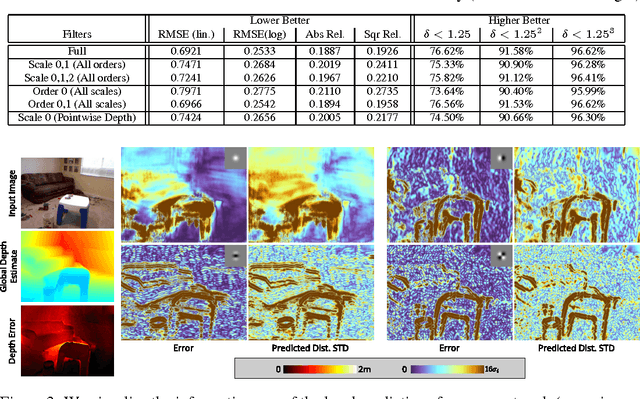
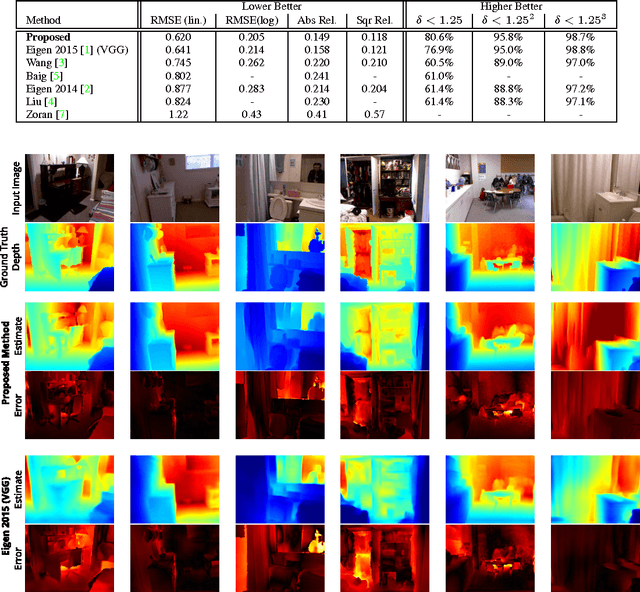
A single color image can contain many cues informative towards different aspects of local geometric structure. We approach the problem of monocular depth estimation by using a neural network to produce a mid-level representation that summarizes these cues. This network is trained to characterize local scene geometry by predicting, at every image location, depth derivatives of different orders, orientations and scales. However, instead of a single estimate for each derivative, the network outputs probability distributions that allow it to express confidence about some coefficients, and ambiguity about others. Scene depth is then estimated by harmonizing this overcomplete set of network predictions, using a globalization procedure that finds a single consistent depth map that best matches all the local derivative distributions. We demonstrate the efficacy of this approach through evaluation on the NYU v2 depth data set.