 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Output Embeddings in Structured Prediction
Jul 29, 2020
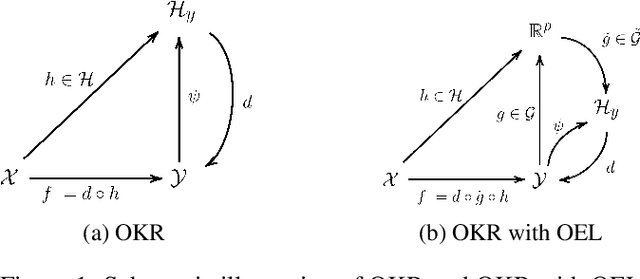

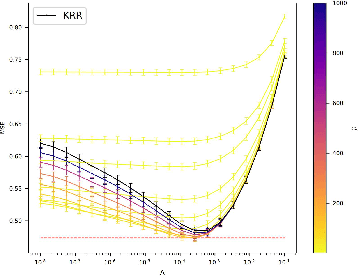

A powerful and flexible approach to structured prediction consists in embedding the structured objects to be predicted into a feature space of possibly infinite dimension, and then, solving a regression problem in this output space. A prediction in the original space is computed by solving a pre-image problem. In such an approach, the embedding, linked to the target loss, is defined prior to the learning phase. In this work, we propose to jointly learn an approximation of the output embedding and the regression function into the new feature space. Output Embedding Learning (OEL) allows to leverage a priori information on the outputs and also unexploited unsupervised output data, which are both often available in structured prediction problems. We give a general learning method that we theoretically study in the linear case, proving consistency and excess-risk bound. OEL is tested on various structured prediction problems, showing its versatility and reveals to be especially useful when the training dataset is small compared to the complexity of the task.
Interpreting CNN for Low Complexity Learned Sub-pixel Motion Compensation in Video Coding
Jun 11, 2020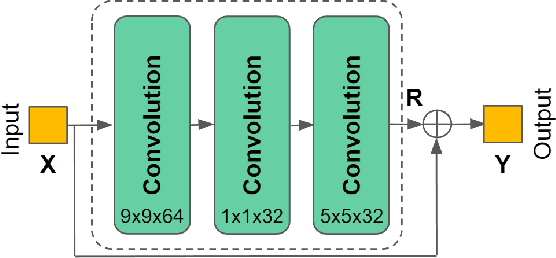
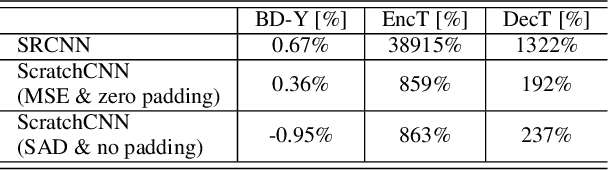
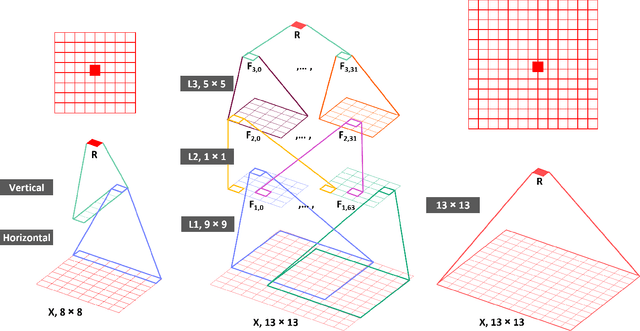
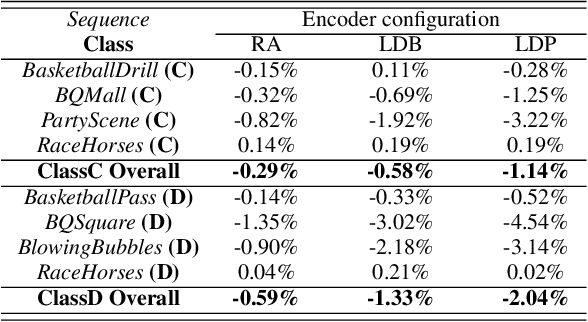
Deep learning has shown great potential in image and video compression tasks. However, it brings bit savings at the cost of significant increases in coding complexity, which limits its potential for implementation within practical applications. In this paper, a novel neural network-based tool is presented which improves the interpolation of reference samples needed for fractional precision motion compensation. Contrary to previous efforts, the proposed approach focuses on complexity reduction achieved by interpreting the interpolation filters learned by the networks. When the approach is implemented in the Versatile Video Coding (VVC) test model, up to 4.5% BD-rate saving for individual sequences is achieved compared with the baseline VVC, while the complexity of learned interpolation is significantly reduced compared to the application of full neural network.
Robust Tracking against Adversarial Attacks
Jul 29, 2020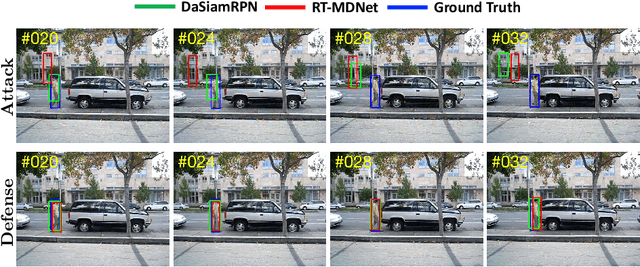
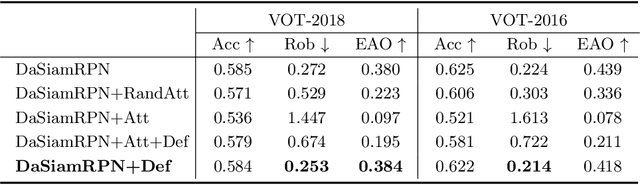
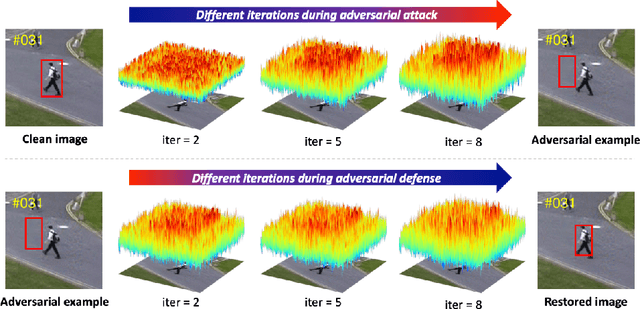
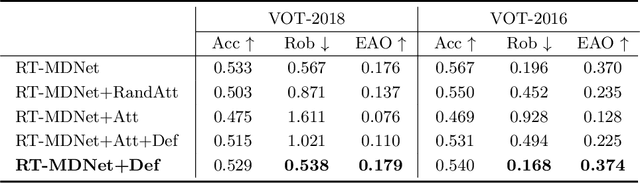
While deep convolutional neural networks (CNNs) are vulnerable to adversarial attacks, considerably few efforts have been paid to construct robust deep tracking algorithms against adversarial attacks. Current studies on adversarial attack and defense mainly reside in a single image. In this work, we first attempt to generate adversarial examples on top of video sequences to improve the tracking robustness against adversarial attacks. To this end, we take temporal motion into consideration when generating lightweight perturbations over the estimated tracking results frame-by-frame. On one hand, we add the temporal perturbations into the original video sequences as adversarial examples to greatly degrade the tracking performance. On the other hand, we sequentially estimate the perturbations from input sequences and learn to eliminate their effect for performance restoration. We apply the proposed adversarial attack and defense approaches to state-of-the-art deep tracking algorithms. Extensive evaluations on the benchmark datasets demonstrate that our defense method not only eliminates the large performance drops caused by adversarial attacks, but also achieves additional performance gains when deep trackers are not under adversarial attacks.
An Empirical Analysis of Backward Compatibility in Machine Learning Systems
Aug 11, 2020

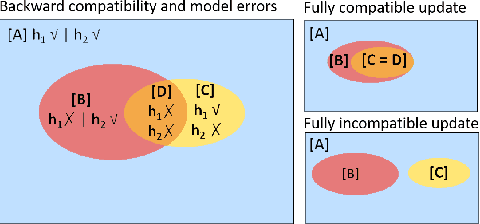

In many applications of machine learning (ML), updates are performed with the goal of enhancing model performance. However, current practices for updating models rely solely on isolated, aggregate performance analyses, overlooking important dependencies, expectations, and needs in real-world deployments. We consider how updates, intended to improve ML models, can introduce new errors that can significantly affect downstream systems and users. For example, updates in models used in cloud-based classification services, such as image recognition, can cause unexpected erroneous behavior in systems that make calls to the services. Prior work has shown the importance of "backward compatibility" for maintaining human trust. We study challenges with backward compatibility across different ML architectures and datasets, focusing on common settings including data shifts with structured noise and ML employed in inferential pipelines. Our results show that (i) compatibility issues arise even without data shift due to optimization stochasticity, (ii) training on large-scale noisy datasets often results in significant decreases in backward compatibility even when model accuracy increases, and (iii) distributions of incompatible points align with noise bias, motivating the need for compatibility aware de-noising and robustness methods.
A Diffractive Neural Network with Weight-Noise-Injection Training
Jun 20, 2020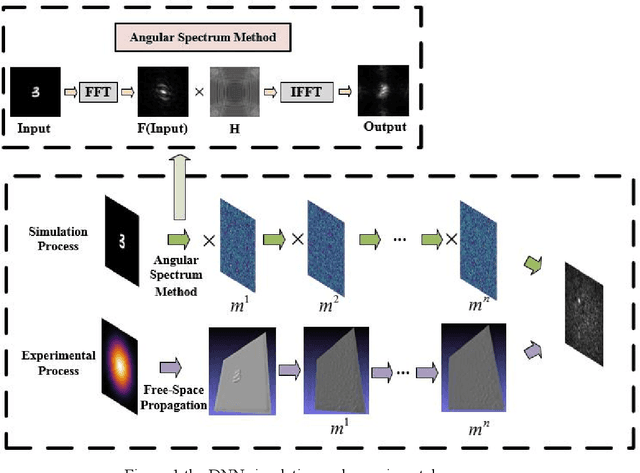
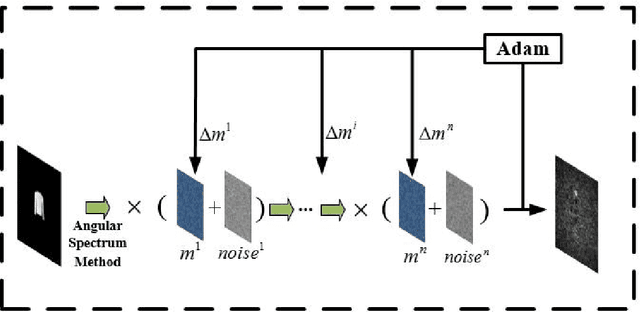
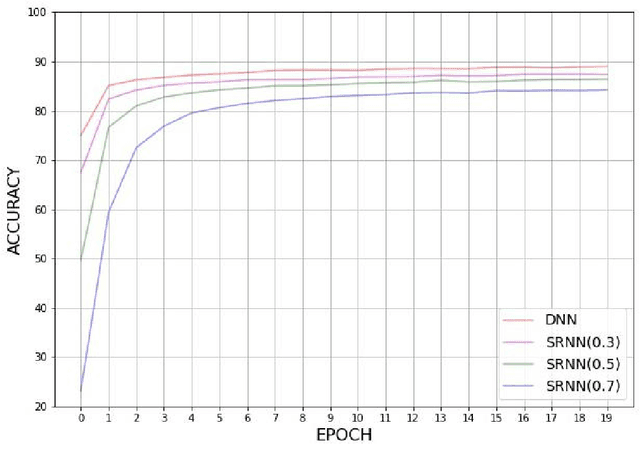

We propose a diffractive neural network with strong robustness based on Weight Noise Injection training, which achieves accurate and fast optical-based classification while diffraction layers have a certain amount of surface shape error. To the best of our knowledge, it is the first time that using injection weight noise during training to reduce the impact of external interference on deep learning inference results. In the proposed method, the diffractive neural network learns the mapping between the input image and the label in Weight Noise Injection mode, making the network's weight insensitive to modest changes, which improve the network's noise resistance at a lower cost. By comparing the accuracy of the network under different noise, it is verified that the proposed network (SRNN) still maintains a higher accuracy under serious noise.
Total Deep Variation for Linear Inverse Problems
Jan 14, 2020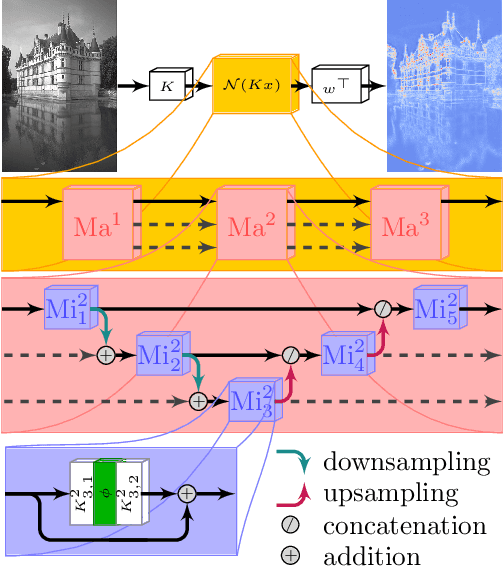
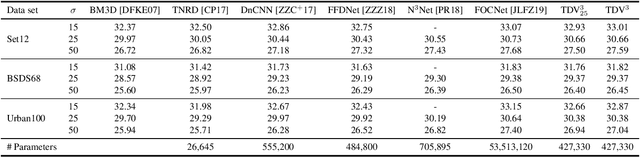
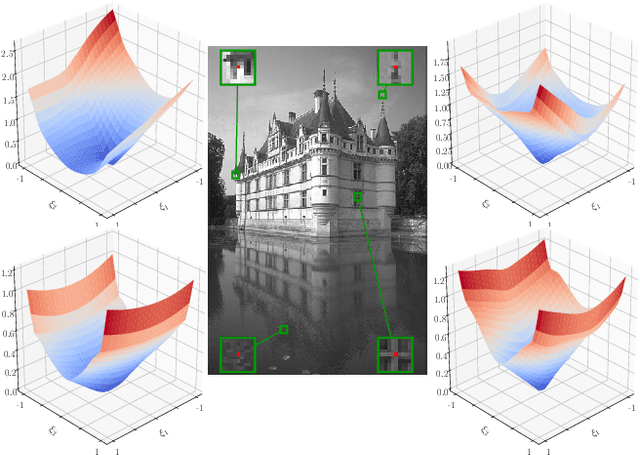
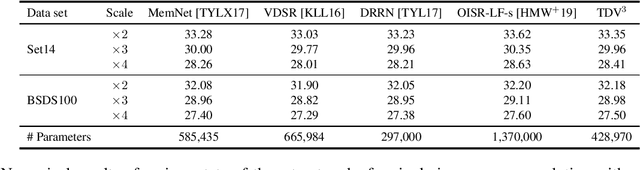
Diverse inverse problems in imaging can be cast as variational problems composed of a task-specific data fidelity term and a regularization term. In this paper, we propose a novel learnable general-purpose regularizer exploiting recent architectural design patterns from deep learning. We cast the learning problem as a discrete sampled optimal control problem, for which we derive the adjoint state equations and an optimality condition. By exploiting the variational structure of our approach, we perform a sensitivity analysis with respect to the learned parameters obtained from different training datasets. Moreover, we carry out a nonlinear eigenmode analysis, which reveals interesting properties of the learned regularizer. We show state-of-the-art performance for classical image restoration and medical image reconstruction problems.
Subjective and Objective Quality Assessment of Image: A Survey
Jun 30, 2014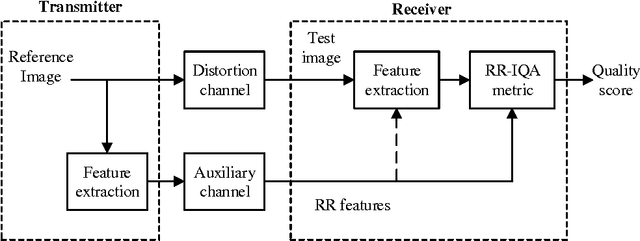
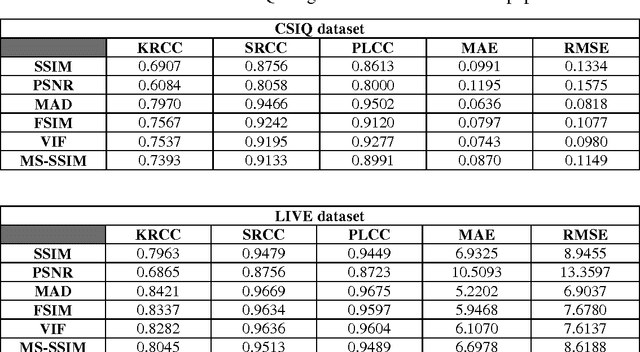

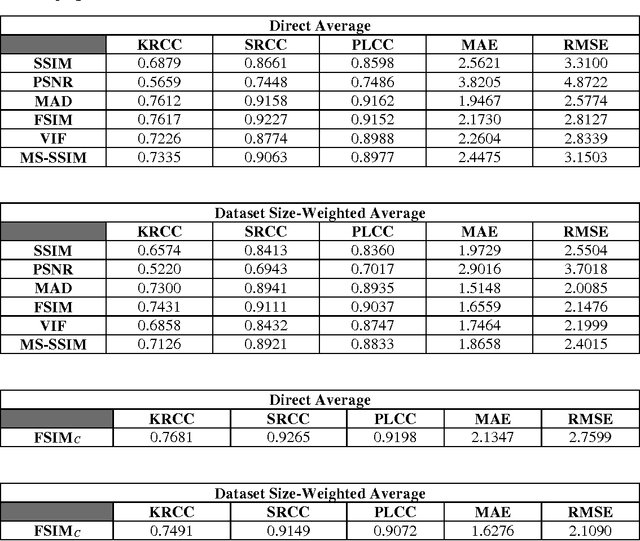
With the increasing demand for image-based applications, the efficient and reliable evaluation of image quality has increased in importance. Measuring the image quality is of fundamental importance for numerous image processing applications, where the goal of image quality assessment (IQA) methods is to automatically evaluate the quality of images in agreement with human quality judgments. Numerous IQA methods have been proposed over the past years to fulfill this goal. In this paper, a survey of the quality assessment methods for conventional image signals, as well as the newly emerged ones, which includes the high dynamic range (HDR) and 3-D images, is presented. A comprehensive explanation of the subjective and objective IQA and their classification is provided. Six widely used subjective quality datasets, and performance measures are reviewed. Emphasis is given to the full-reference image quality assessment (FR-IQA) methods, and 9 often-used quality measures (including mean squared error (MSE), structural similarity index (SSIM), multi-scale structural similarity index (MS-SSIM), visual information fidelity (VIF), most apparent distortion (MAD), feature similarity measure (FSIM), feature similarity measure for color images (FSIMC), dynamic range independent measure (DRIM), and tone-mapped images quality index (TMQI)) are carefully described, and their performance and computation time on four subjective quality datasets are evaluated. Furthermore, a brief introduction to 3-D IQA is provided and the issues related to this area of research are reviewed.
Deep Heterogeneous Autoencoder for Subspace Clustering of Sequential Data
Jul 14, 2020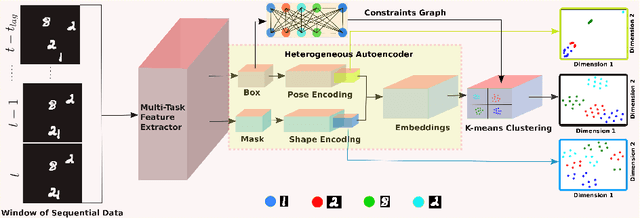
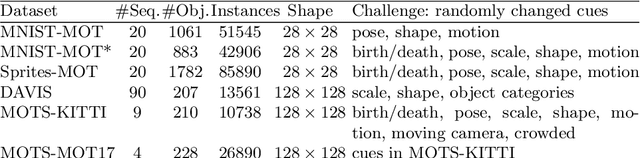
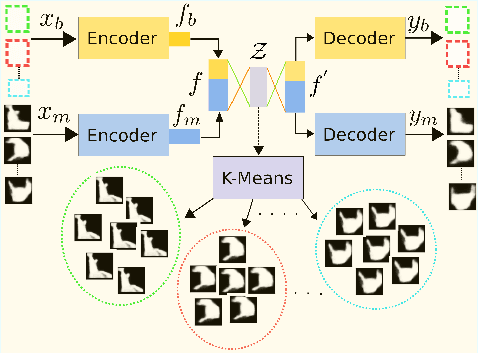
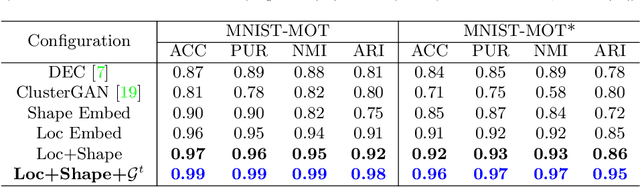
We propose an unsupervised learning approach using a convolutional and fully connected autoencoder, which we call deep heterogeneous autoencoder, to learn discriminative features from segmentation masks and detection bounding boxes. To learn the mask shape information and its corresponding location in an input image, we extract coarse masks from a pretrained semantic segmentation network as well as their corresponding bounding boxes. We train the autoencoders jointly using task-dependent uncertainty weights to generate common latent features. The feature vector is then fed to the k-means clustering algorithm to separate the data points in the latent space. Finally, we incorporate additional penalties in the form of a constraints graph based on prior knowledge of the sequential data to increase clustering robustness. We evaluate the performance of our method using both synthetic and real world multi-object video datasets to demonstrate the applicability of our proposed model. Our results show that the proposed technique outperforms several state-of-the-art methods on challenging video sequences.
Bespoke vs. Prêt-à-Porter Lottery Tickets: Exploiting Mask Similarity for Trainable Sub-Network Finding
Jul 06, 2020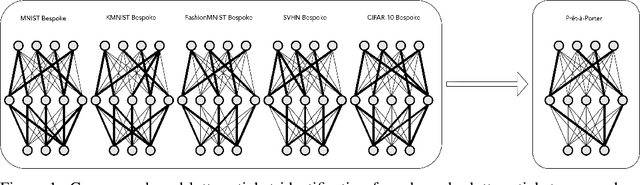
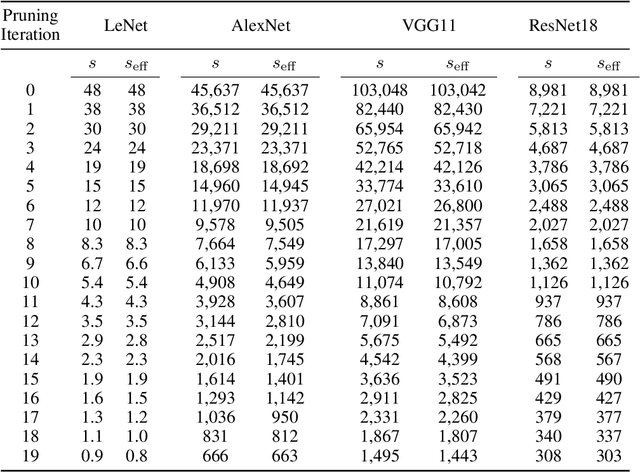
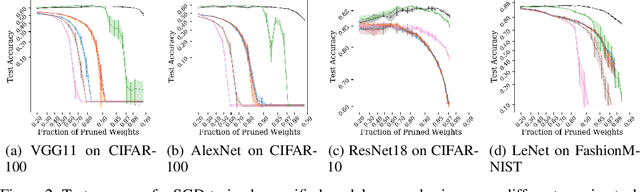
The observation of sparse trainable sub-networks within over-parametrized networks - also known as Lottery Tickets (LTs) - has prompted inquiries around their trainability, scaling, uniqueness, and generalization properties. Across 28 combinations of image classification tasks and architectures, we discover differences in the connectivity structure of LTs found through different iterative pruning techniques, thus disproving their uniqueness and connecting emergent mask structure to the choice of pruning. In addition, we propose a consensus-based method for generating refined lottery tickets. This lottery ticket denoising procedure, based on the principle that parameters that always go unpruned across different tasks more reliably identify important sub-networks, is capable of selecting a meaningful portion of the architecture in an embarrassingly parallel way, while quickly discarding extra parameters without the need for further pruning iterations. We successfully train these sub-networks to performance comparable to that of ordinary lottery tickets.
GoodPoint: unsupervised learning of keypoint detection and description
Jun 01, 2020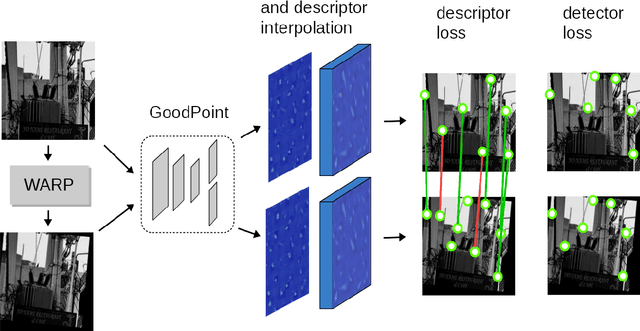
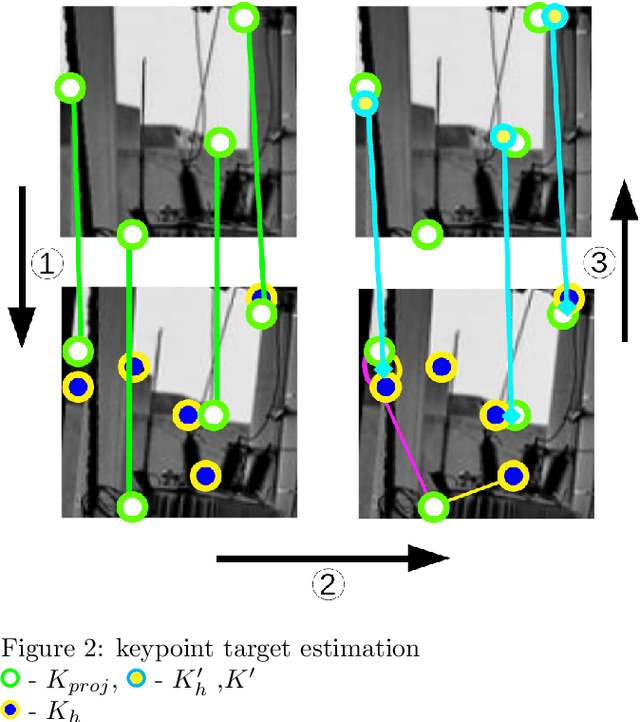
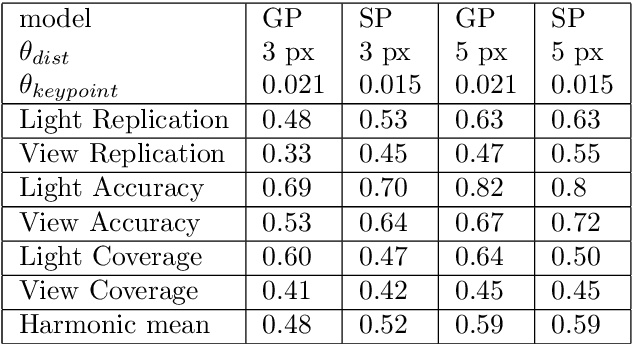
This paper introduces a new algorithm for unsupervised learning of keypoint detectors and descriptors, which demonstrates fast convergence and good performance across different datasets. The training procedure uses homographic transformation of images. The proposed model learns to detect points and generate descriptors on pairs of transformed images, which are easy for it to distinguish and repeatedly detect. The trained model follows SuperPoint architecture for ease of comparison, and demonstrates similar performance on natural images from HPatches dataset, and better performance on retina images from Fundus Image Registration Dataset, which contain low number of corner-like features. For HPatches and other datasets, coverage was also computed to provide better estimation of model quality.