 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Architecture Transfer
May 12, 2020
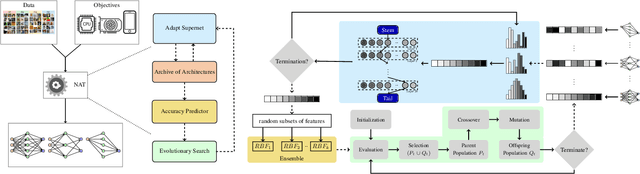
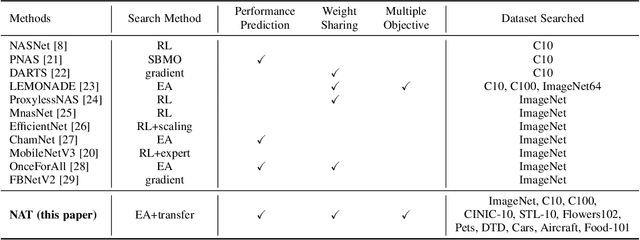
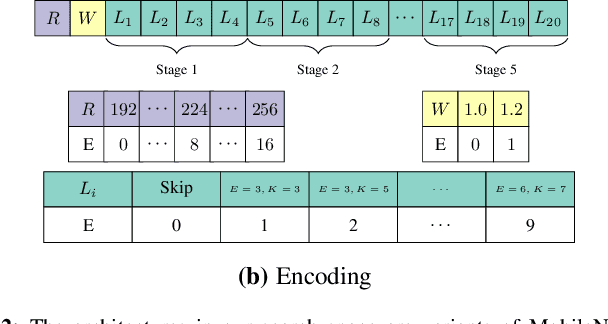
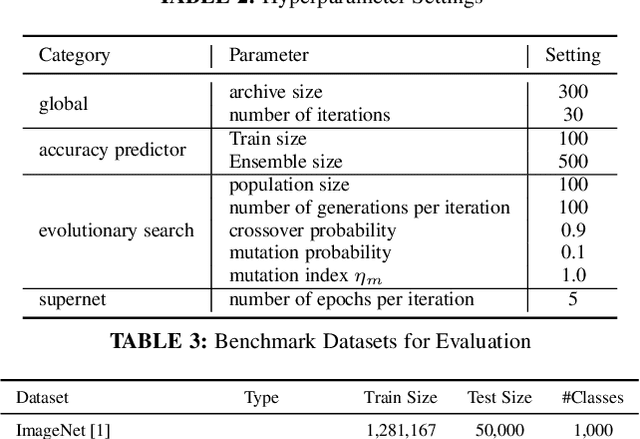
Neural architecture search (NAS) has emerged as a promising avenue for automatically designing task-specific neural networks. Most existing NAS approaches require one complete search for each deployment specification of hardware or objective. This is a computationally impractical endeavor given the potentially large number of application scenarios. In this paper, we propose Neural Architecture Transfer (NAT) to overcome this limitation. NAT is designed to efficiently generate task-specific custom models that are competitive even under multiple conflicting objectives. To realize this goal we learn task-specific supernets from which specialized subnets can be sampled without any additional training. The key to our approach is an integrated online transfer learning and many-objective evolutionary search procedure. A pre-trained supernet is iteratively adapted while simultaneously searching for task-specific subnets. We demonstrate the efficacy of NAT on 11 benchmark image classification tasks ranging from large-scale multi-class to small-scale fine-grained datasets. In all cases, including ImageNet, NATNets improve upon the state-of-the-art under mobile settings ($\leq$ 600M Multiply-Adds). Surprisingly, small-scale fine-grained datasets benefit the most from NAT. At the same time, the architecture search and transfer is orders of magnitude more efficient than existing NAS methods. Overall, experimental evaluation indicates that across diverse image classification tasks and computational objectives, NAT is an appreciably more effective alternative to fine-tuning based transfer learning. Code is available at https://github.com/human-analysis/neural-architecture-transfer
Deep Hashing with Hash-Consistent Large Margin Proxy Embeddings
Jul 27, 2020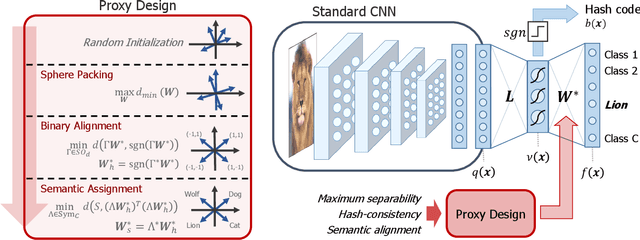
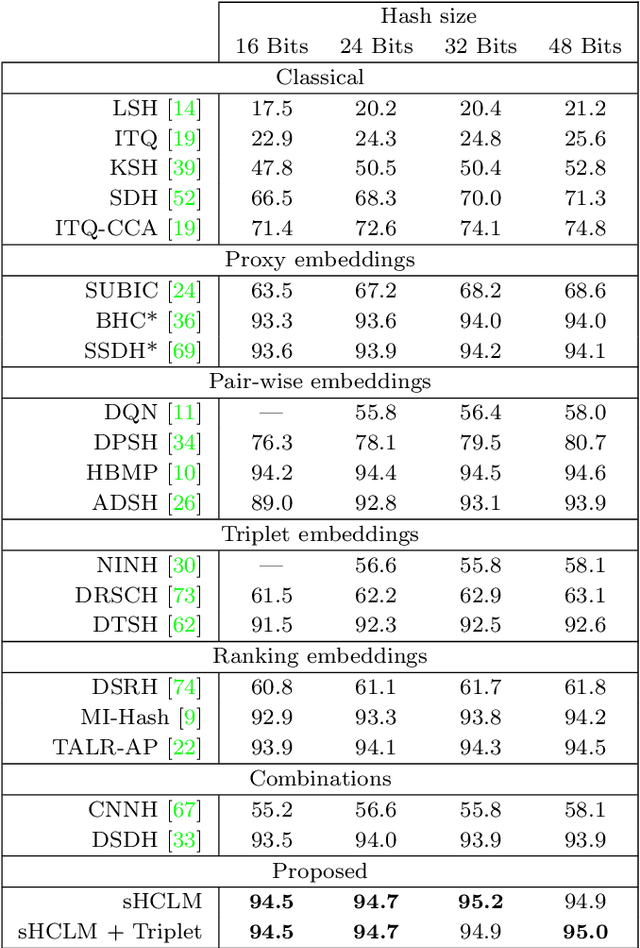
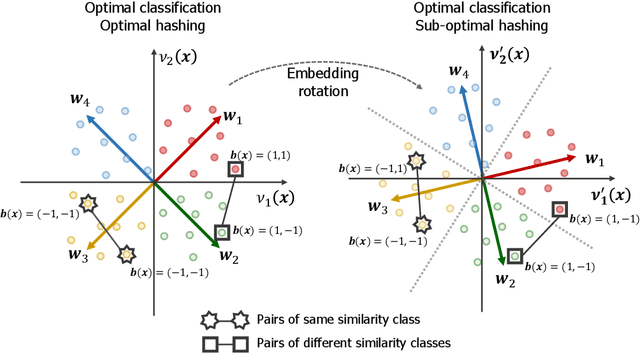
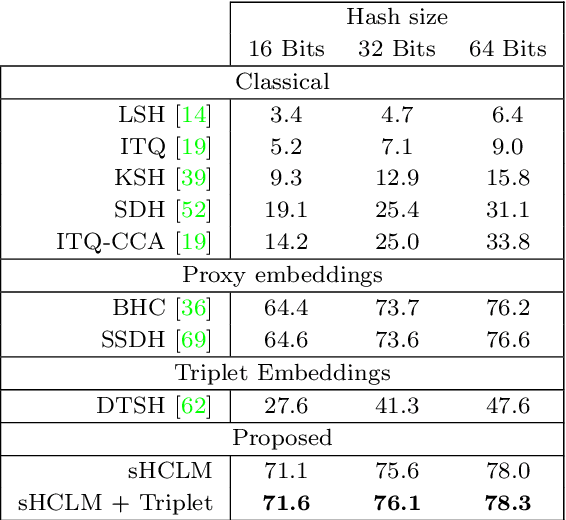
Image hash codes are produced by binarizing the embeddings of convolutional neural networks (CNN) trained for either classification or retrieval. While proxy embeddings achieve good performance on both tasks, they are non-trivial to binarize, due to a rotational ambiguity that encourages non-binary embeddings. The use of a fixed set of proxies (weights of the CNN classification layer) is proposed to eliminate this ambiguity, and a procedure to design proxy sets that are nearly optimal for both classification and hashing is introduced. The resulting hash-consistent large margin (HCLM) proxies are shown to encourage saturation of hashing units, thus guaranteeing a small binarization error, while producing highly discriminative hash-codes. A semantic extension (sHCLM), aimed to improve hashing performance in a transfer scenario, is also proposed. Extensive experiments show that sHCLM embeddings achieve significant improvements over state-of-the-art hashing procedures on several small and large datasets, both within and beyond the set of training classes.
Training Object Detectors from Few Weakly-Labeled and Many Unlabeled Images
Dec 01, 2019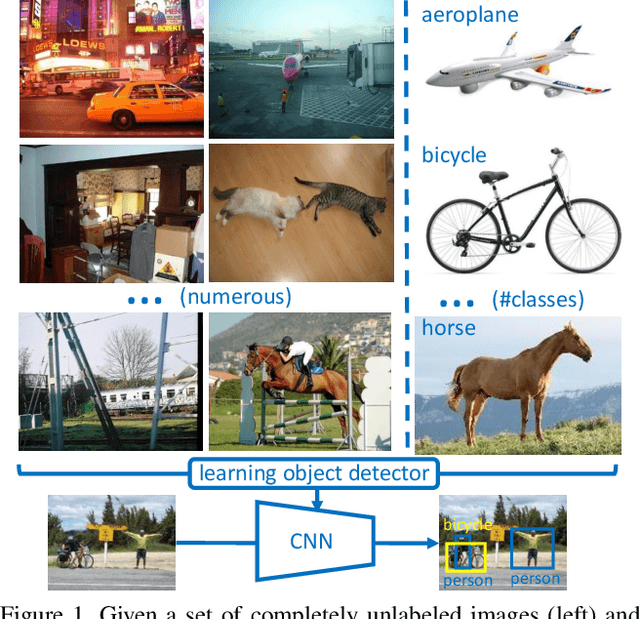


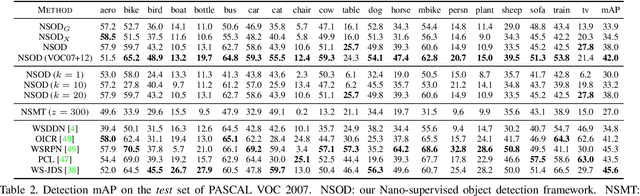
Weakly-supervised object detection attempts to limit the amount of supervision by dispensing the need for bounding boxes, but still assumes image-level labels on the entire training set are available. In this work, we study the problem of training an object detector from one or few clean images with image-level labels and a larger set of completely unlabeled images. This is an extreme case of semi-supervised learning where the labeled data are not enough to bootstrap the learning of a classifier or detector. Our solution is to use a standard weakly-supervised pipeline to train a student model from image-level pseudo-labels generated on the unlabeled set by a teacher model, bootstrapped by region-level similarities to clean labeled images. By using the recent pipeline of PCL and more unlabeled images, we achieve performance competitive or superior to many state of the art weakly-supervised detection solutions.
CLEAR: Covariant LEAst-square Re-fitting with applications to image restoration
Sep 14, 2016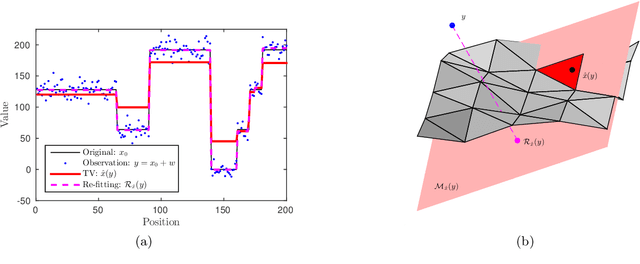
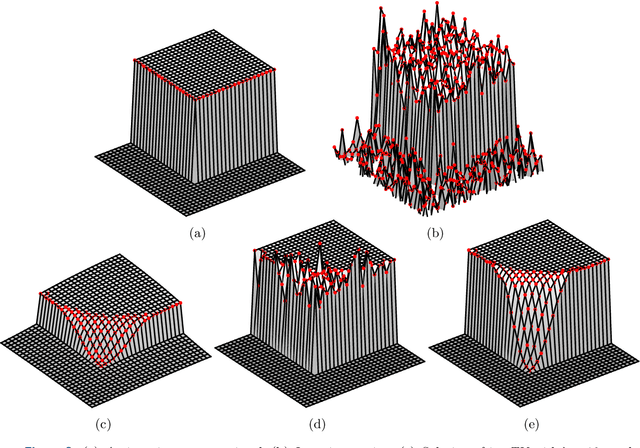


In this paper, we propose a new framework to remove parts of the systematic errors affecting popular restoration algorithms, with a special focus for image processing tasks. Generalizing ideas that emerged for $\ell_1$ regularization, we develop an approach re-fitting the results of standard methods towards the input data. Total variation regularizations and non-local means are special cases of interest. We identify important covariant information that should be preserved by the re-fitting method, and emphasize the importance of preserving the Jacobian (w.r.t. the observed signal) of the original estimator. Then, we provide an approach that has a "twicing" flavor and allows re-fitting the restored signal by adding back a local affine transformation of the residual term. We illustrate the benefits of our method on numerical simulations for image restoration tasks.
Additive Tensor Decomposition Considering Structural Data Information
Jul 27, 2020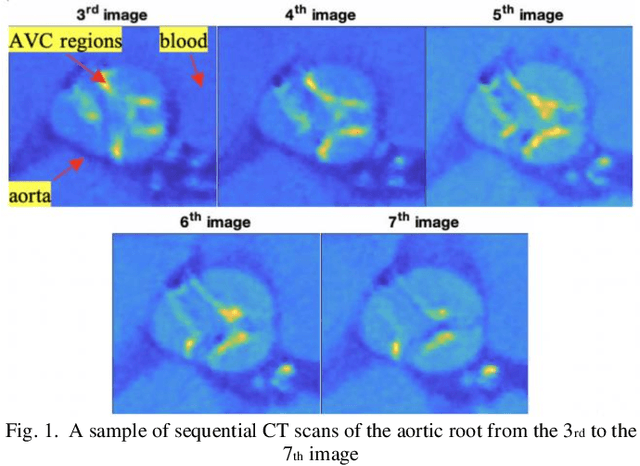
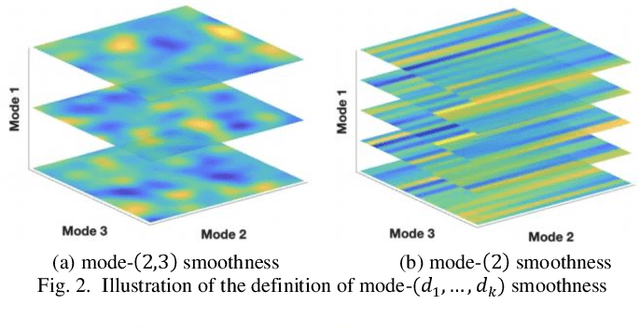

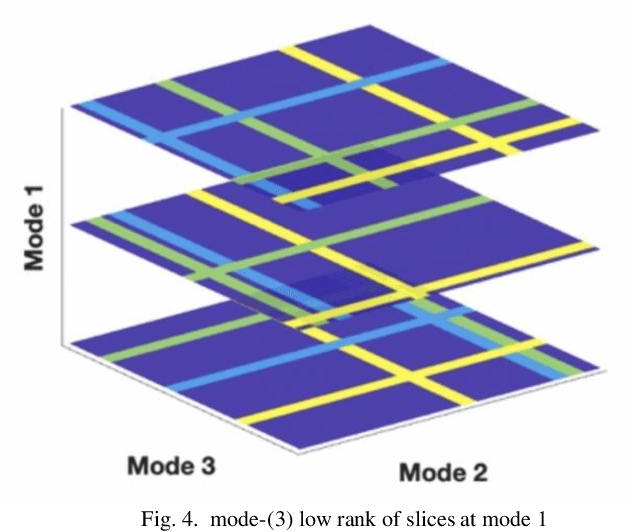
Tensor data with rich structural information becomes increasingly important in process modeling, monitoring, and diagnosis. Here structural information is referred to structural properties such as sparsity, smoothness, low-rank, and piecewise constancy. To reveal useful information from tensor data, we propose to decompose the tensor into the summation of multiple components based on different structural information of them. In this paper, we provide a new definition of structural information in tensor data. Based on it, we propose an additive tensor decomposition (ATD) framework to extract useful information from tensor data. This framework specifies a high dimensional optimization problem to obtain the components with distinct structural information. An alternating direction method of multipliers (ADMM) algorithm is proposed to solve it, which is highly parallelable and thus suitable for the proposed optimization problem. Two simulation examples and a real case study in medical image analysis illustrate the versatility and effectiveness of the ATD framework.
Beyond Camera Motion Removing: How to Handle Outliers in Deblurring
Feb 24, 2020
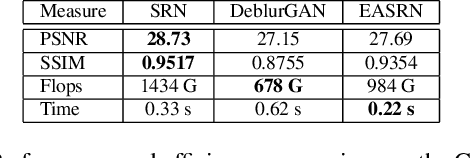
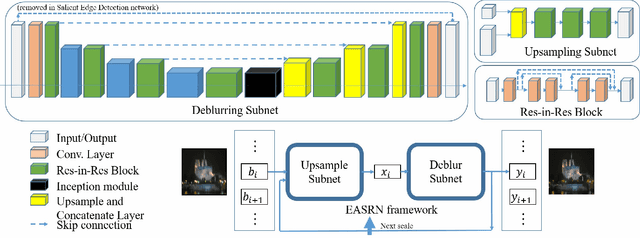

Performing camera motion deblurring is an important low-level vision task for achieving better imaging quality. When a scene has outliers such as saturated pixels and salt-and pepper noise, the image becomes more difficult to restore. In this paper, we propose an edge-aware scalerecurrent network (EASRN) to conduct camera motion deblurring. EASRN has a separate deblurring module that removes blur at multiple scales and an upsampling module that fuses different input scales. We propose a salient edge detection network to supervise the training process and solve the outlier problem by proposing a novel method of dataset generation. Light streaks are printed on the sharp image to simulate the cutoff effect from saturation. We evaluate our method on the standard deblurring datasets. Both objective evaluation indexes and subjective visualization show that our method results in better deblurring quality than the other state-of-the-art approaches.
Exploring the ability of CNNs to generalise to previously unseen scales over wide scale ranges
Apr 03, 2020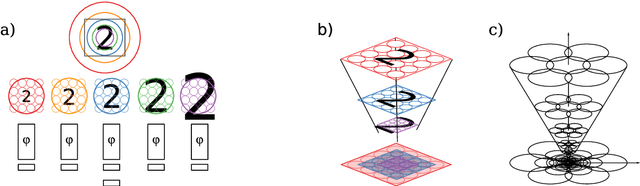
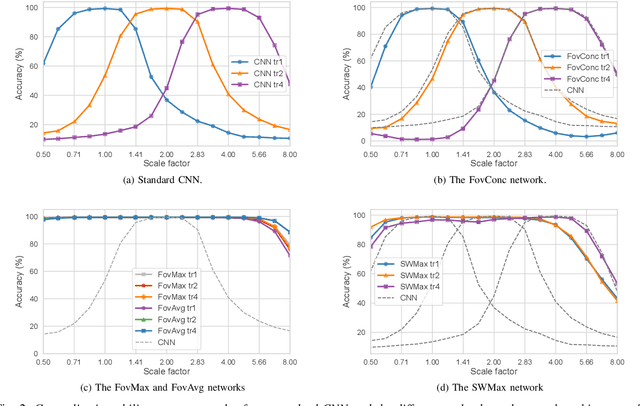
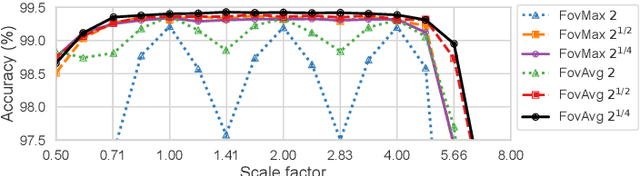

The ability to handle large scale variations is crucial for many real world visual tasks. A straightforward approach for handling scale in a deep network is to process an image at several scales simultaneously in a set of scale channels. Scale invariance can then, in principle, be achieved by using weight sharing between the scale channels together with max or average pooling over the outputs from the scale channels. The ability of such scale channel networks to generalise to scales not present in the training set over significant scale ranges has, however, not previously been explored. We, therefore, present a theoretical analysis of invariance and covariance properties of scale channel networks and perform an experimental evaluation of the ability of different types of scale channel networks to generalise to previously unseen scales. We identify limitations of previous approaches and propose a new type of foveated scale channel architecture, where the scale channels process increasingly larger parts of the image with decreasing resolution. Our proposed FovMax and FovAvg networks perform almost identically over a scale range of 8 also when training on single scale training data and give improvements in the small sample regime.
Dissimilarity Mixture Autoencoder for Deep Clustering
Jun 24, 2020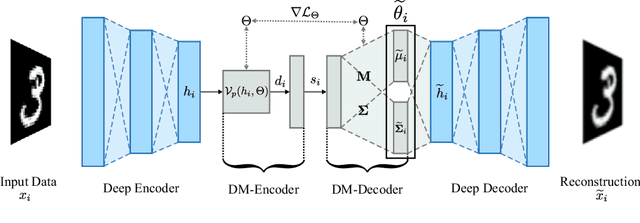
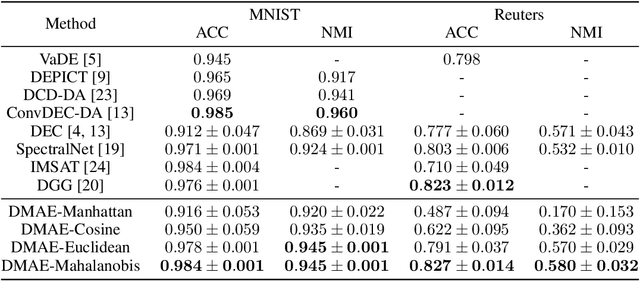
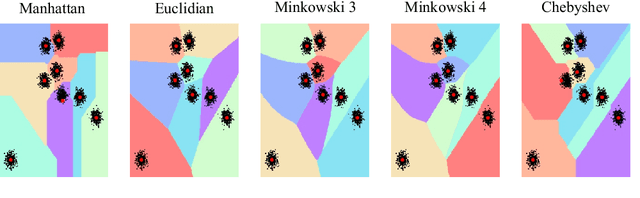
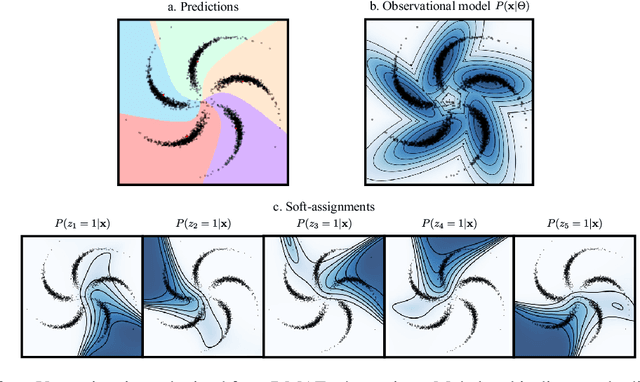
In this paper, we introduce the Dissimilarity Mixture Autoencoder (DMAE), a novel neural network model that uses a dissimilarity function to generalize a family of density estimation and clustering methods. It is formulated in such a way that it internally estimates the parameters of a probability distribution through gradient-based optimization. Also, the proposed model can leverage from deep representation learning due to its straightforward incorporation into deep learning architectures, because, it consists of an encoder-decoder network that computes a probabilistic representation. Experimental evaluation was performed on image and text clustering benchmark datasets showing that the method is competitive in terms of unsupervised classification accuracy and normalized mutual information. The source code to replicate the experiments is publicly available at https://github.com/larajuse/DMAE
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
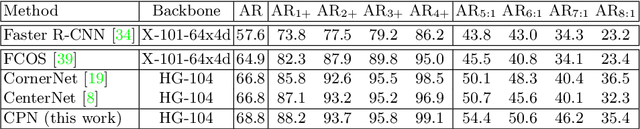

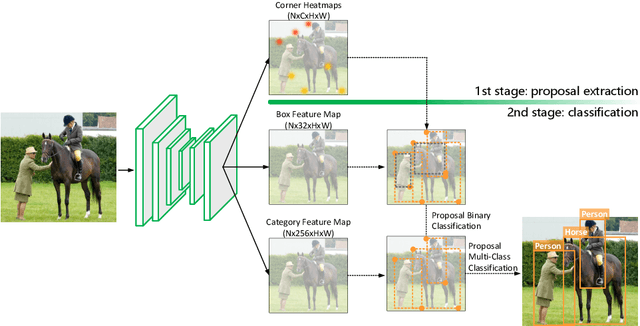
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
MaxDropout: Deep Neural Network Regularization Based on Maximum Output Values
Jul 27, 2020

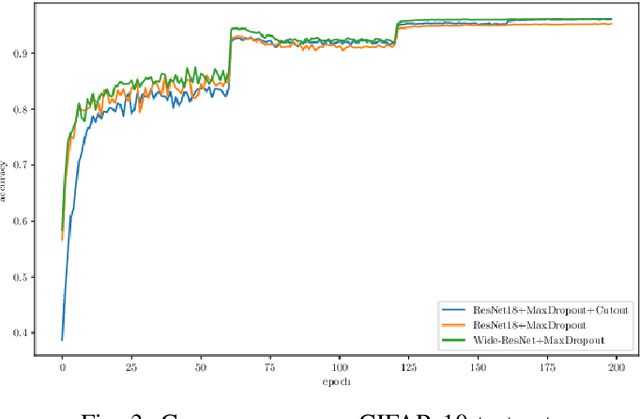
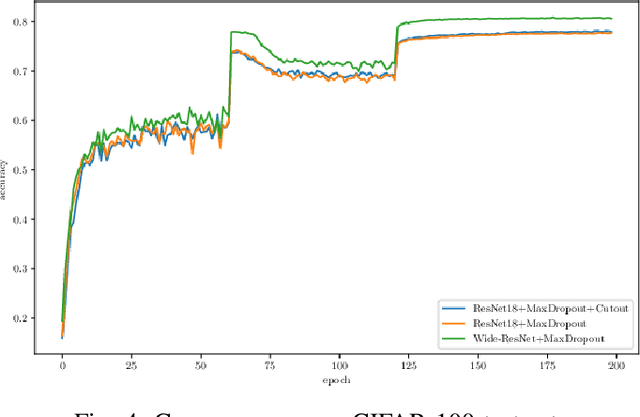
Different techniques have emerged in the deep learning scenario, such as Convolutional Neural Networks, Deep Belief Networks, and Long Short-Term Memory Networks, to cite a few. In lockstep, regularization methods, which aim to prevent overfitting by penalizing the weight connections, or turning off some units, have been widely studied either. In this paper, we present a novel approach called MaxDropout, a regularizer for deep neural network models that works in a supervised fashion by removing (shutting off) the prominent neurons (i.e., most active) in each hidden layer. The model forces fewer activated units to learn more representative information, thus providing sparsity. Regarding the experiments, we show that it is possible to improve existing neural networks and provide better results in neural networks when Dropout is replaced by MaxDropout. The proposed method was evaluated in image classification, achieving comparable results to existing regularizers, such as Cutout and RandomErasing, also improving the accuracy of neural networks that uses Dropout by replacing the existing layer by MaxDropout.