 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Consistency Regularization for GANs
Feb 11, 2020
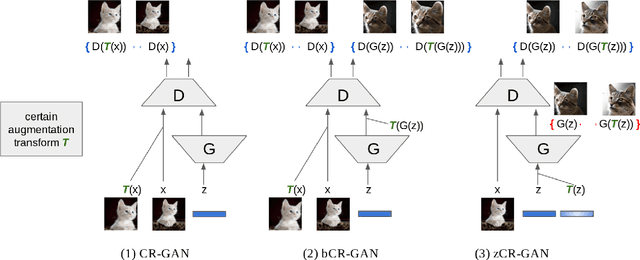
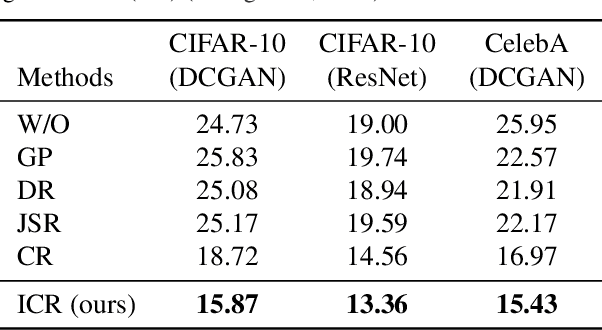


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
Variational Registration of Multiple Images with the SVD based SqN Distance Measure
Jul 23, 2019
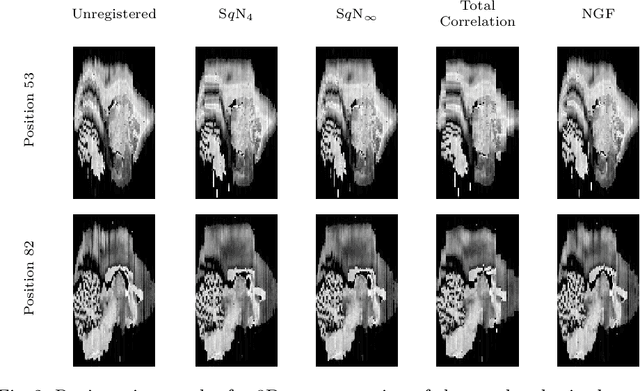
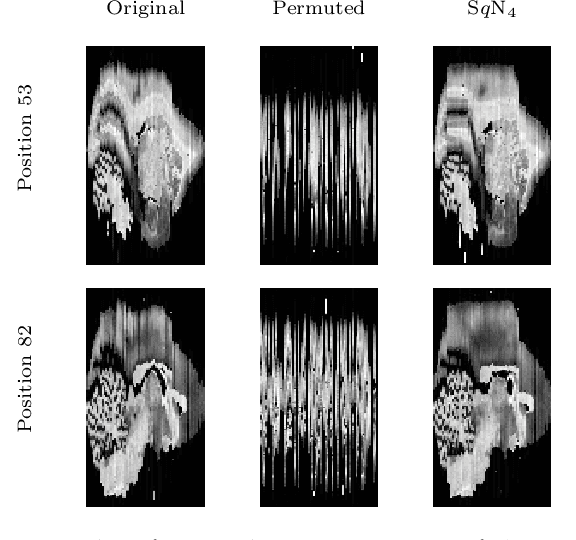
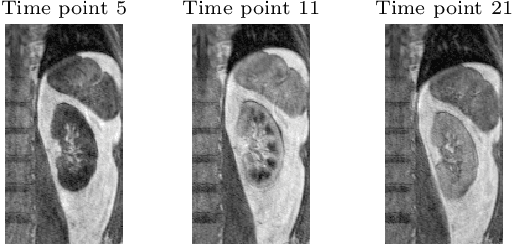
Image registration, especially the quantification of image similarity, is an important task in image processing. Various approaches for the comparison of two images are discussed in the literature. However, although most of these approaches perform very well in a two image scenario, an extension to a multiple images scenario deserves attention. In this article, we discuss and compare registration methods for multiple images. Our key assumption is, that information about the singular values of a feature matrix of images can be used for alignment. We introduce, discuss and relate three recent approaches from the literature: the Schatten q-norm based SqN distance measure, a rank based approach, and a feature volume based approach. We also present results for typical applications such as dynamic image sequences or stacks of histological sections. Our results indicate that the SqN approach is in fact a suitable distance measure for image registration. Moreover, our examples also indicate that the results obtained by SqN are superior to those obtained by its competitors.
Crowdsampling the Plenoptic Function
Jul 30, 2020


Many popular tourist landmarks are captured in a multitude of online, public photos. These photos represent a sparse and unstructured sampling of the plenoptic function for a particular scene. In this paper,we present a new approach to novel view synthesis under time-varying illumination from such data. Our approach builds on the recent multi-plane image (MPI) format for representing local light fields under fixed viewing conditions. We introduce a new DeepMPI representation, motivated by observations on the sparsity structure of the plenoptic function, that allows for real-time synthesis of photorealistic views that are continuous in both space and across changes in lighting. Our method can synthesize the same compelling parallax and view-dependent effects as previous MPI methods, while simultaneously interpolating along changes in reflectance and illumination with time. We show how to learn a model of these effects in an unsupervised way from an unstructured collection of photos without temporal registration, demonstrating significant improvements over recent work in neural rendering. More information can be found crowdsampling.io.
FATNN: Fast and Accurate Ternary Neural Networks
Aug 12, 2020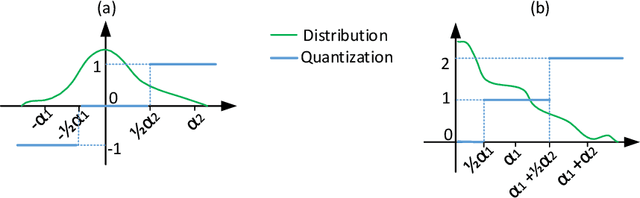

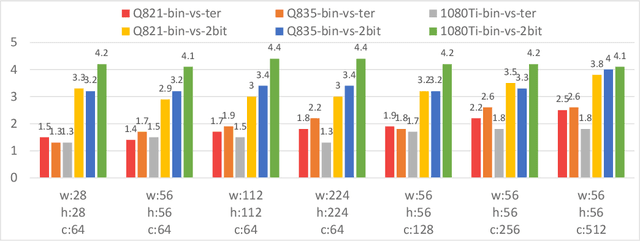

Ternary Neural Networks (TNNs) have received much attention due to being potentially orders of magnitude faster in inference, as well as more power efficient, than full-precision counterparts. However, 2 bits are required to encode the ternary representation with only 3 quantization levels leveraged. As a result, conventional TNNs have similar memory consumption and speed compared with the standard 2-bit models, but have worse representational capability. Moreover, there is still a significant gap in accuracy between TNNs and full-precision networks, hampering their deployment to real applications. To tackle these two challenges, in this work, we first show that, under some mild constraints, the computational complexity of ternary inner product can be reduced by 2x. Second, to mitigate the performance gap, we elaborately design an implementation-dependent ternary quantization algorithm. The proposed framework is termed Fast and Accurate Ternary Neural Networks (FATNN). Experiments on image classification demonstrate that our FATNN surpasses the state-of-the-arts by a significant margin in accuracy. More importantly, speedup evaluation comparing with various precisions is analyzed on several platforms, which serves as a strong benchmark for further research.
A Survey On 3D Inner Structure Prediction from its Outer Shape
Feb 11, 2020
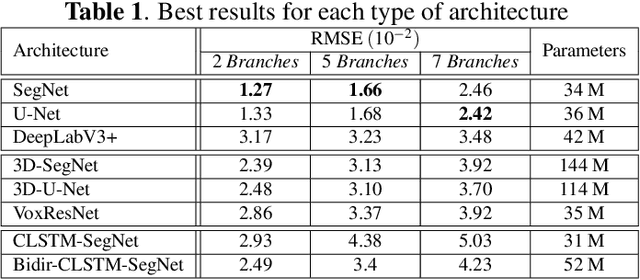
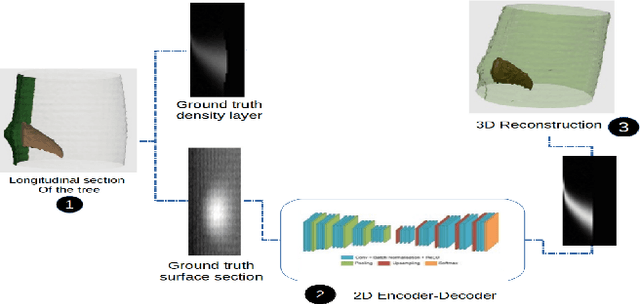

The analysis of the internal structure of trees is highly important for both forest experts, biological scientists, and the wood industry. Traditionally, CT-scanners are considered as the most efficient way to get an accurate inner representation of the tree. However, this method requires an important investment and reduces the cost-effectiveness of this operation. Our goal is to design neural-network-based methods to predict the internal density of the tree from its external bark shape. This paper compares different image-to-image(2D), volume-to-volume(3D) and Convolutional Long Short Term Memory based neural network architectures in the context of the prediction of the defect distribution inside trees from their external bark shape. Those models are trained on a synthetic dataset of 1800 CT-scanned look-like volumetric structures of the internal density of the trees and their corresponding external surface.
Subjective and Objective Quality Assessment of Image: A Survey
Jun 30, 2014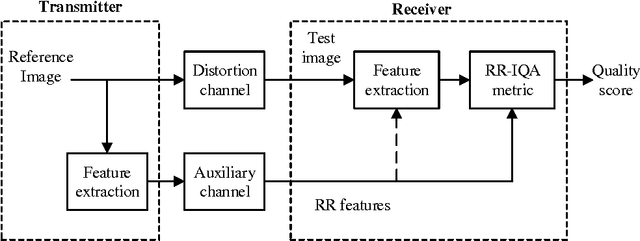
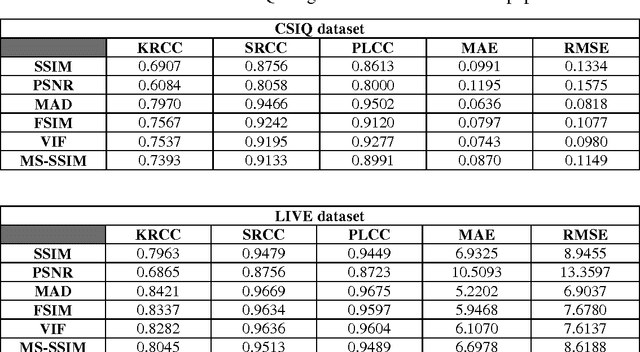

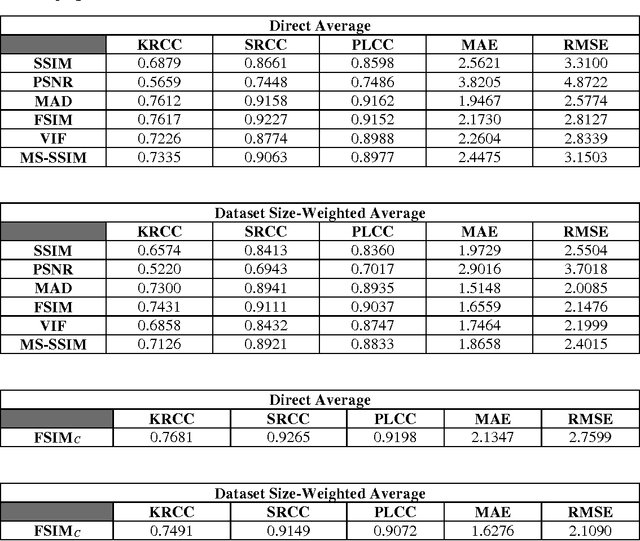
With the increasing demand for image-based applications, the efficient and reliable evaluation of image quality has increased in importance. Measuring the image quality is of fundamental importance for numerous image processing applications, where the goal of image quality assessment (IQA) methods is to automatically evaluate the quality of images in agreement with human quality judgments. Numerous IQA methods have been proposed over the past years to fulfill this goal. In this paper, a survey of the quality assessment methods for conventional image signals, as well as the newly emerged ones, which includes the high dynamic range (HDR) and 3-D images, is presented. A comprehensive explanation of the subjective and objective IQA and their classification is provided. Six widely used subjective quality datasets, and performance measures are reviewed. Emphasis is given to the full-reference image quality assessment (FR-IQA) methods, and 9 often-used quality measures (including mean squared error (MSE), structural similarity index (SSIM), multi-scale structural similarity index (MS-SSIM), visual information fidelity (VIF), most apparent distortion (MAD), feature similarity measure (FSIM), feature similarity measure for color images (FSIMC), dynamic range independent measure (DRIM), and tone-mapped images quality index (TMQI)) are carefully described, and their performance and computation time on four subjective quality datasets are evaluated. Furthermore, a brief introduction to 3-D IQA is provided and the issues related to this area of research are reviewed.
Decoding 5G-NR Communications via Deep Learning
Jul 15, 2020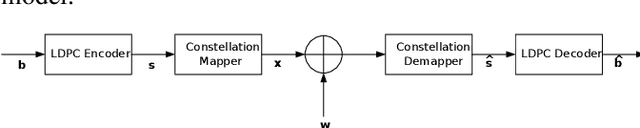
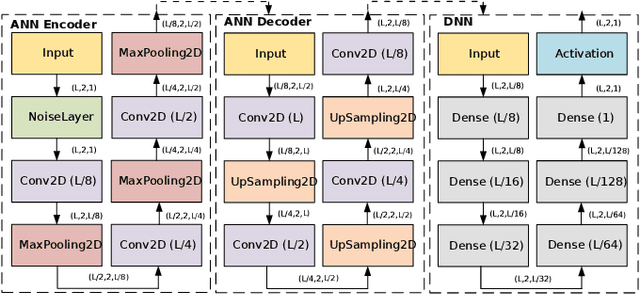
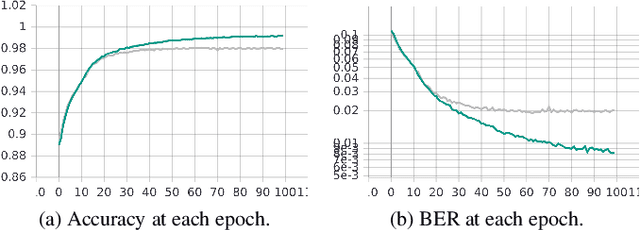
Upcoming modern communications are based on 5G specifications and aim at providing solutions for novel vertical industries. One of the major changes of the physical layer is the use of Low-Density Parity-Check (LDPC) code for channel coding. Although LDPC codes introduce additional computational complexity compared with the previous generation, where Turbocodes where used, LDPC codes provide a reasonable trade-off in terms of complexity-Bit Error Rate (BER). In parallel to this, Deep Learning algorithms are experiencing a new revolution, specially to image and video processing. In this context, there are some approaches that can be exploited in radio communications. In this paper we propose to use Autoencoding Neural Networks (ANN) jointly with a Deep Neural Network (DNN) to construct Autoencoding Deep Neural Networks (ADNN) for demapping and decoding. The results will unveil that, for a particular BER target, $3$ dB less of Signal to Noise Ratio (SNR) is required, in Additive White Gaussian Noise (AWGN) channels.
Long-term Human Motion Prediction with Scene Context
Jul 07, 2020
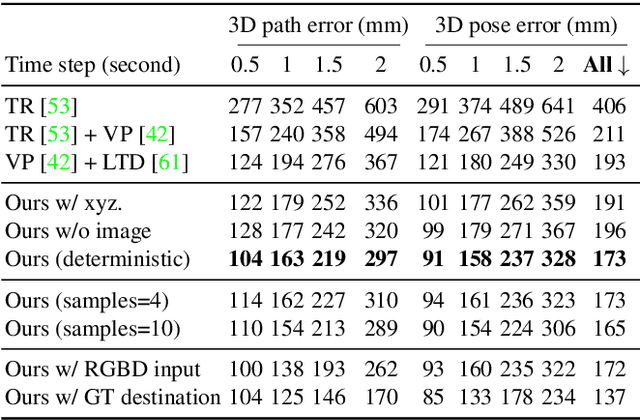
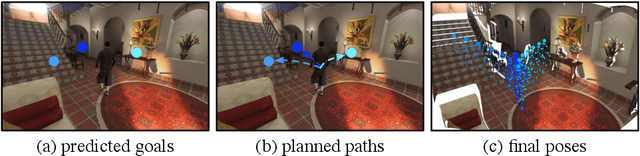
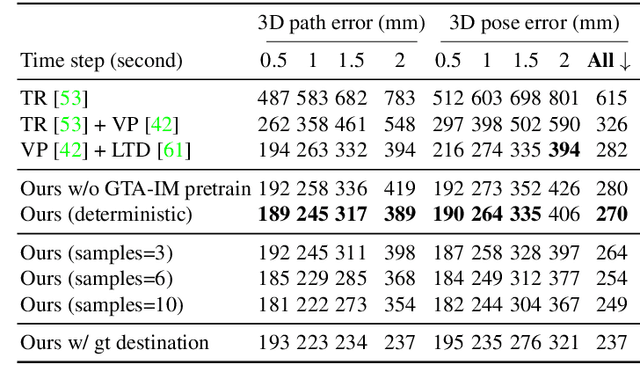
Human movement is goal-directed and influenced by the spatial layout of the objects in the scene. To plan future human motion, it is crucial to perceive the environment -- imagine how hard it is to navigate a new room with lights off. Existing works on predicting human motion do not pay attention to the scene context and thus struggle in long-term prediction. In this work, we propose a novel three-stage framework that exploits scene context to tackle this task. Given a single scene image and 2D pose histories, our method first samples multiple human motion goals, then plans 3D human paths towards each goal, and finally predicts 3D human pose sequences following each path. For stable training and rigorous evaluation, we contribute a diverse synthetic dataset with clean annotations. In both synthetic and real datasets, our method shows consistent quantitative and qualitative improvements over existing methods.
Multi-channel MRI Embedding: An EffectiveStrategy for Enhancement of Human Brain WholeTumor Segmentation
Sep 13, 2020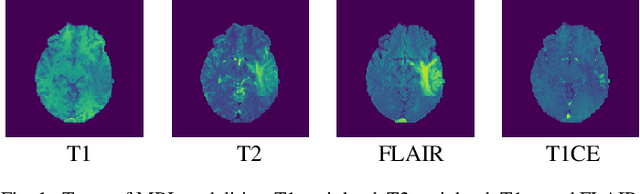
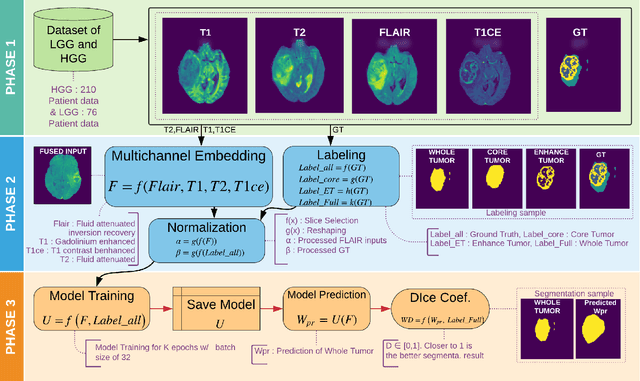
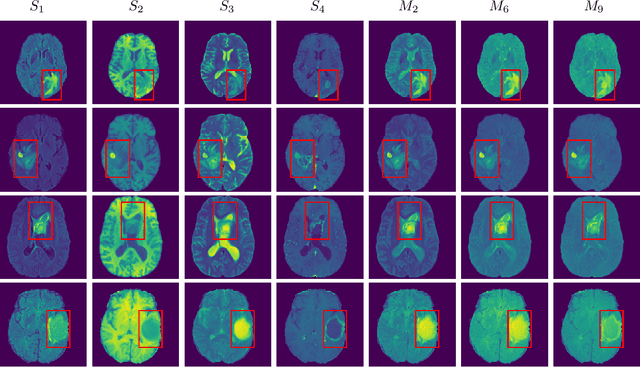
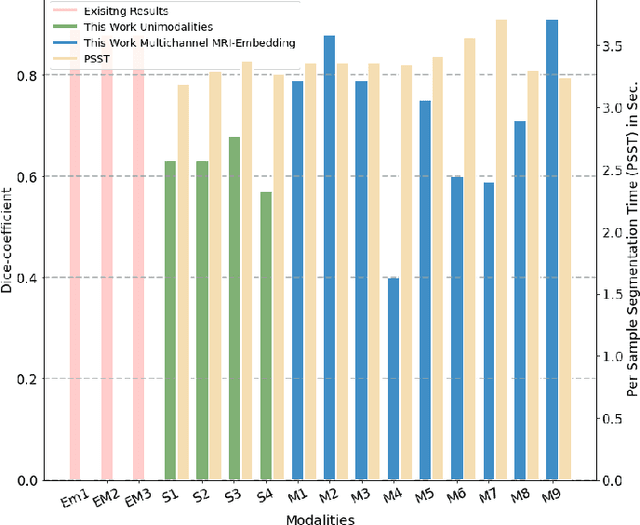
One of the most important tasks in medical image processing is the brain's whole tumor segmentation. It assists in quicker clinical assessment and early detection of brain tumors, which is crucial for lifesaving treatment procedures of patients. Because, brain tumors often can be malignant or benign, if they are detected at an early stage. A brain tumor is a collection or a mass of abnormal cells in the brain. The human skull encloses the brain very rigidly and any growth inside this restricted place can cause severe health issues. The detection of brain tumors requires careful and intricate analysis for surgical planning and treatment. Most physicians employ Magnetic Resonance Imaging (MRI) to diagnose such tumors. A manual diagnosis of the tumors using MRI is known to be time-consuming; approximately, it takes up to eighteen hours per sample. Thus, the automatic segmentation of tumors has become an optimal solution for this problem. Studies have shown that this technique provides better accuracy and it is faster than manual analysis resulting in patients receiving the treatment at the right time. Our research introduces an efficient strategy called Multi-channel MRI embedding to improve the result of deep learning-based tumor segmentation. The experimental analysis on the Brats-2019 dataset wrt the U-Net encoder-decoder (EnDec) model shows significant improvement. The embedding strategy surmounts the state-of-the-art approaches with an improvement of 2% without any timing overheads.
dMelodies: A Music Dataset for Disentanglement Learning
Jul 29, 2020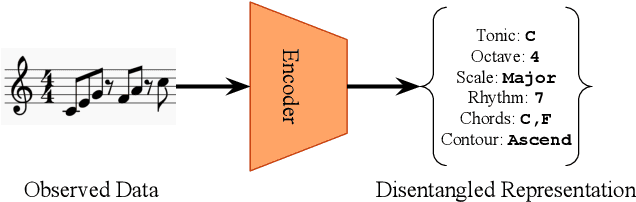
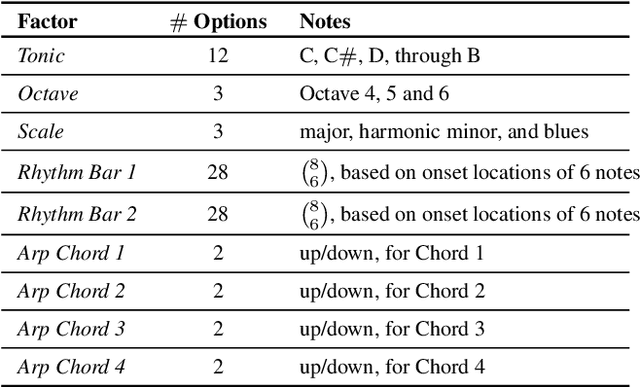
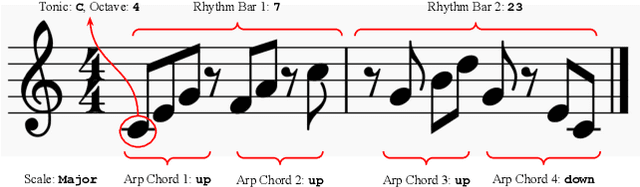
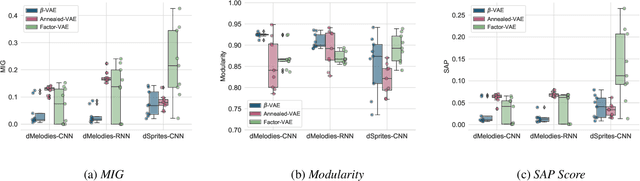
Representation learning focused on disentangling the underlying factors of variation in given data has become an important area of research in machine learning. However, most of the studies in this area have relied on datasets from the computer vision domain and thus, have not been readily extended to music. In this paper, we present a new symbolic music dataset that will help researchers working on disentanglement problems demonstrate the efficacy of their algorithms on diverse domains. This will also provide a means for evaluating algorithms specifically designed for music. To this end, we create a dataset comprising of 2-bar monophonic melodies where each melody is the result of a unique combination of nine latent factors that span ordinal, categorical, and binary types. The dataset is large enough (approx. 1.3 million data points) to train and test deep networks for disentanglement learning. In addition, we present benchmarking experiments using popular unsupervised disentanglement algorithms on this dataset and compare the results with those obtained on an image-based dataset.