 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SemiSAM: Exploring SAM for Enhancing Semi-Supervised Medical Image Segmentation with Extremely Limited Annotations
Dec 11, 2023
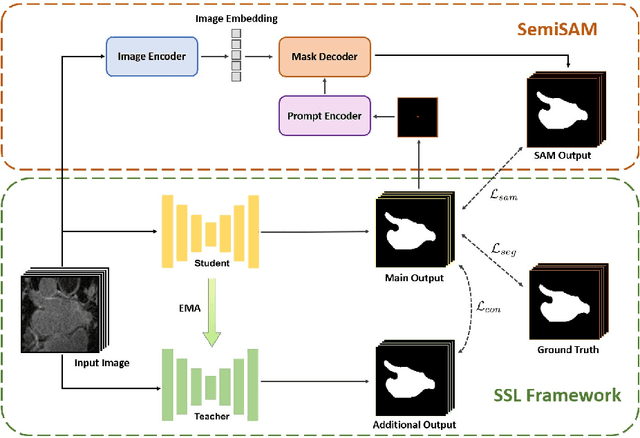
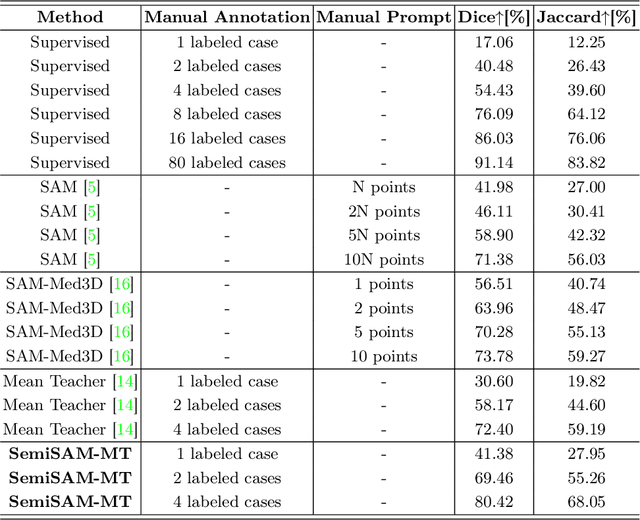
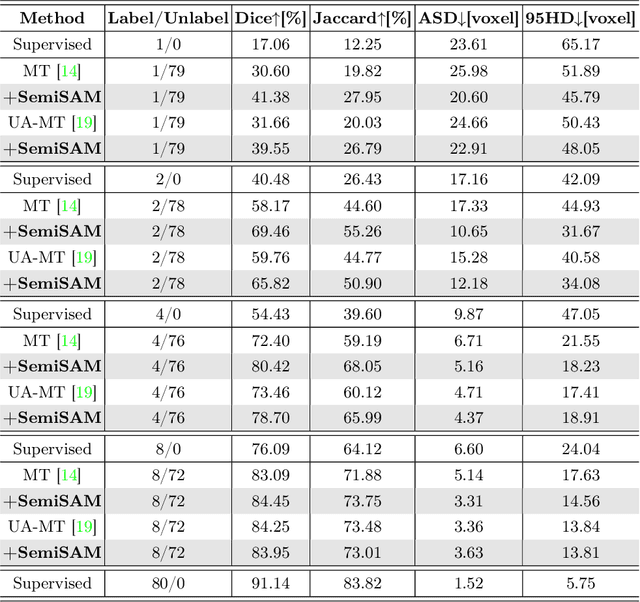
Semi-supervised learning has attracted much attention due to its less dependence on acquiring abundant annotations from experts compared to fully supervised methods, which is especially important for medical image segmentation which typically requires intensive pixel/voxel-wise labeling by domain experts. Although semi-supervised methods can improve the performance by utilizing unlabeled data, there are still gaps between fully supervised methods under extremely limited annotation scenarios. In this paper, we propose a simple yet efficient strategy to explore the usage of the Segment Anything Model (SAM) for enhancing semi-supervised medical image segmentation. Concretely, the segmentation model trained with domain knowledge provides information for localization and generating input prompts to the SAM. Then the generated pseudo-labels of SAM are utilized as additional supervision to assist in the learning procedure of the semi-supervised framework. Experimental results demonstrate that SAM's assistance significantly enhances the performance of existing semi-supervised frameworks, especially when only one or a few labeled images are available.
R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
Dec 10, 2023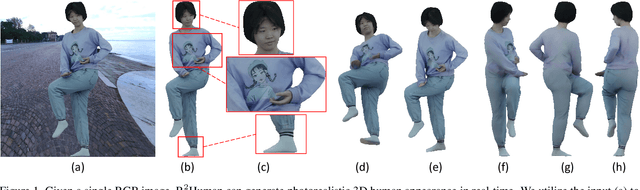
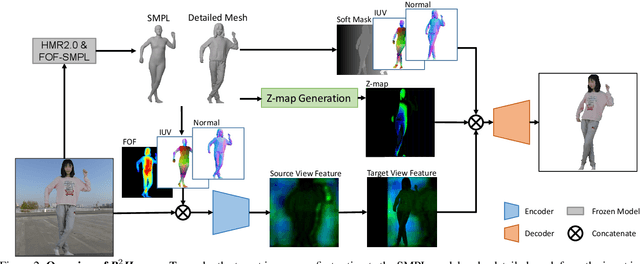
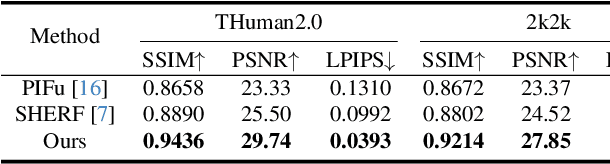
Reconstructing 3D human appearance from a single image is crucial for achieving holographic communication and immersive social experiences. However, this remains a challenge for existing methods, which typically rely on multi-camera setups or are limited to offline operations. In this paper, we propose R$^2$Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field to reconstruct a detailed 3D geometry, which serves as a prior for the texture field generation and provides a sampling surface in the rendering stage. Experiments show that our end-to-end method achieves state-of-the-art performance on both synthetic data and challenging real-world images and even outperforms many offline methods. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/R2Human.
Deep Radon Prior: A Fully Unsupervised Framework for Sparse-View CT Reconstruction
Dec 30, 2023Although sparse-view computed tomography (CT) has significantly reduced radiation dose, it also introduces severe artifacts which degrade the image quality. In recent years, deep learning-based methods for inverse problems have made remarkable progress and have become increasingly popular in CT reconstruction. However, most of these methods suffer several limitations: dependence on high-quality training data, weak interpretability, etc. In this study, we propose a fully unsupervised framework called Deep Radon Prior (DRP), inspired by Deep Image Prior (DIP), to address the aforementioned limitations. DRP introduces a neural network as an implicit prior into the iterative method, thereby realizing cross-domain gradient feedback. During the reconstruction process, the neural network is progressively optimized in multiple stages to narrow the solution space in radon domain for the under-constrained imaging protocol, and the convergence of the proposed method has been discussed in this work. Compared with the popular pre-trained method, the proposed framework requires no dataset and exhibits superior interpretability and generalization ability. The experimental results demonstrate that the proposed method can generate detailed images while effectively suppressing image artifacts.Meanwhile, DRP achieves comparable or better performance than the supervised methods.
SHARE: Single-view Human Adversarial REconstruction
Dec 30, 2023The accuracy of 3D Human Pose and Shape reconstruction (HPS) from an image is progressively improving. Yet, no known method is robust across all image distortion. To address issues due to variations of camera poses, we introduce SHARE, a novel fine-tuning method that utilizes adversarial data augmentation to enhance the robustness of existing HPS techniques. We perform a comprehensive analysis on the impact of camera poses on HPS reconstruction outcomes. We first generated large-scale image datasets captured systematically from diverse camera perspectives. We then established a mapping between camera poses and reconstruction errors as a continuous function that characterizes the relationship between camera poses and HPS quality. Leveraging this representation, we introduce RoME (Regions of Maximal Error), a novel sampling technique for our adversarial fine-tuning method. The SHARE framework is generalizable across various single-view HPS methods and we demonstrate its performance on HMR, SPIN, PARE, CLIFF and ExPose. Our results illustrate a reduction in mean joint errors across single-view HPS techniques, for images captured from multiple camera positions without compromising their baseline performance. In many challenging cases, our method surpasses the performance of existing models, highlighting its practical significance for diverse real-world applications.
FENet: Focusing Enhanced Network for Lane Detection
Jan 05, 2024Inspired by human driving focus, this research pioneers networks augmented with Focusing Sampling, Partial Field of View Evaluation, Enhanced FPN architecture and Directional IoU Loss - targeted innovations addressing obstacles to precise lane detection for autonomous driving. Experiments demonstrate our Focusing Sampling strategy, emphasizing vital distant details unlike uniform approaches, significantly boosts both benchmark and practical curved/distant lane recognition accuracy essential for safety. While FENetV1 achieves state-of-the-art conventional metric performance via enhancements isolating perspective-aware contexts mimicking driver vision, FENetV2 proves most reliable on the proposed Partial Field analysis. Hence we specifically recommend V2 for practical lane navigation despite fractional degradation on standard entire-image measures. Future directions include collecting on-road data and integrating complementary dual frameworks to further breakthroughs guided by human perception principles. The Code is available at https://github.com/HanyangZhong/FENet.
Theory and investigation of acoustic multiple-input multiple-output systems based on spherical arrays in a room
Jan 07, 2024Spatial attributes of room acoustics have been widely studied using microphone and loudspeaker arrays. However, systems that combine both arrays, referred to as multiple-input multiple-output (MIMO) systems, have only been studied to a limited degree in this context. These systems can potentially provide a powerful tool for room acoustics analysis due to the ability to simultaneously control both arrays. This paper offers a theoretical framework for the spatial analysis of enclosed sound fields using a MIMO system comprising spherical loudspeaker and microphone arrays. A system transfer function is formulated in matrix form for free-field conditions, and its properties are studied using tools from linear algebra. The system is shown to have unit-rank, regardless of the array types, and its singular vectors are related to the directions of arrival and radiation at the microphone and loudspeaker arrays, respectively. The formulation is then generalized to apply to rooms, using an image source method. In this case, the rank of the system is related to the number of significant reflections. The paper ends with simulation studies, which support the developed theory, and with an extensive reflection analysis of a room impulse response, using the platform of a MIMO system.
conv_einsum: A Framework for Representation and Fast Evaluation of Multilinear Operations in Convolutional Tensorial Neural Networks
Jan 07, 2024Modern ConvNets continue to achieve state-of-the-art results over a vast array of vision and image classification tasks, but at the cost of increasing parameters. One strategy for compactifying a network without sacrificing much expressive power is to reshape it into a tensorial neural network (TNN), which is a higher-order tensorization of its layers, followed by a factorization, such as a CP-decomposition, which strips a weight down to its critical basis components. Passes through TNNs can be represented as sequences of multilinear operations (MLOs), where the evaluation path can greatly affect the number of floating point operations (FLOPs) incurred. While functions such as the popular einsum can evaluate simple MLOs such as contractions, existing implementations cannot process multi-way convolutions, resulting in scant assessments of how optimal evaluation paths through tensorized convolutional layers can improve training speed. In this paper, we develop a unifying framework for representing tensorial convolution layers as einsum-like strings and a meta-algorithm conv_einsum which is able to evaluate these strings in a FLOPs-minimizing manner. Comprehensive experiments, using our open-source implementation, over a wide range of models, tensor decompositions, and diverse tasks, demonstrate that conv_einsum significantly increases both computational and memory-efficiency of convolutional TNNs.
LivePhoto: Real Image Animation with Text-guided Motion Control
Dec 05, 2023Despite the recent progress in text-to-video generation, existing studies usually overlook the issue that only spatial contents but not temporal motions in synthesized videos are under the control of text. Towards such a challenge, this work presents a practical system, named LivePhoto, which allows users to animate an image of their interest with text descriptions. We first establish a strong baseline that helps a well-learned text-to-image generator (i.e., Stable Diffusion) take an image as a further input. We then equip the improved generator with a motion module for temporal modeling and propose a carefully designed training pipeline to better link texts and motions. In particular, considering the facts that (1) text can only describe motions roughly (e.g., regardless of the moving speed) and (2) text may include both content and motion descriptions, we introduce a motion intensity estimation module as well as a text re-weighting module to reduce the ambiguity of text-to-motion mapping. Empirical evidence suggests that our approach is capable of well decoding motion-related textual instructions into videos, such as actions, camera movements, or even conjuring new contents from thin air (e.g., pouring water into an empty glass). Interestingly, thanks to the proposed intensity learning mechanism, our system offers users an additional control signal (i.e., the motion intensity) besides text for video customization.
Reflected Schrödinger Bridge for Constrained Generative Modeling
Jan 06, 2024Diffusion models have become the go-to method for large-scale generative models in real-world applications. These applications often involve data distributions confined within bounded domains, typically requiring ad-hoc thresholding techniques for boundary enforcement. Reflected diffusion models (Lou23) aim to enhance generalizability by generating the data distribution through a backward process governed by reflected Brownian motion. However, reflected diffusion models may not easily adapt to diverse domains without the derivation of proper diffeomorphic mappings and do not guarantee optimal transport properties. To overcome these limitations, we introduce the Reflected Schrodinger Bridge algorithm: an entropy-regularized optimal transport approach tailored for generating data within diverse bounded domains. We derive elegant reflected forward-backward stochastic differential equations with Neumann and Robin boundary conditions, extend divergence-based likelihood training to bounded domains, and explore natural connections to entropic optimal transport for the study of approximate linear convergence - a valuable insight for practical training. Our algorithm yields robust generative modeling in diverse domains, and its scalability is demonstrated in real-world constrained generative modeling through standard image benchmarks.
A Physics-guided Generative AI Toolkit for Geophysical Monitoring
Jan 06, 2024Full-waveform inversion (FWI) plays a vital role in geoscience to explore the subsurface. It utilizes the seismic wave to image the subsurface velocity map. As the machine learning (ML) technique evolves, the data-driven approaches using ML for FWI tasks have emerged, offering enhanced accuracy and reduced computational cost compared to traditional physics-based methods. However, a common challenge in geoscience, the unprivileged data, severely limits ML effectiveness. The issue becomes even worse during model pruning, a step essential in geoscience due to environmental complexities. To tackle this, we introduce the EdGeo toolkit, which employs a diffusion-based model guided by physics principles to generate high-fidelity velocity maps. The toolkit uses the acoustic wave equation to generate corresponding seismic waveform data, facilitating the fine-tuning of pruned ML models. Our results demonstrate significant improvements in SSIM scores and reduction in both MAE and MSE across various pruning ratios. Notably, the ML model fine-tuned using data generated by EdGeo yields superior quality of velocity maps, especially in representing unprivileged features, outperforming other existing methods.