 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Bayesian Active Learning with Image Data
Mar 08, 2017
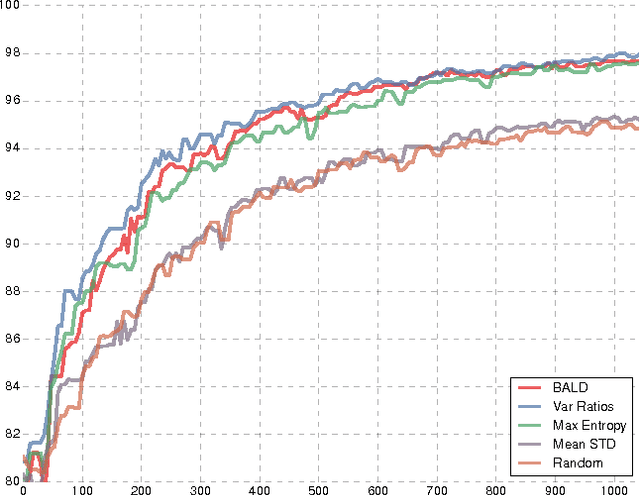


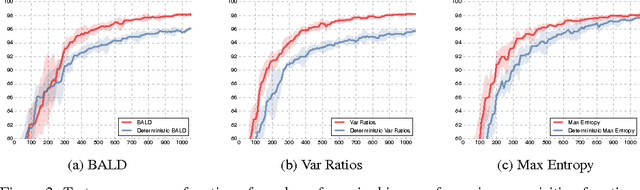
Even though active learning forms an important pillar of machine learning, deep learning tools are not prevalent within it. Deep learning poses several difficulties when used in an active learning setting. First, active learning (AL) methods generally rely on being able to learn and update models from small amounts of data. Recent advances in deep learning, on the other hand, are notorious for their dependence on large amounts of data. Second, many AL acquisition functions rely on model uncertainty, yet deep learning methods rarely represent such model uncertainty. In this paper we combine recent advances in Bayesian deep learning into the active learning framework in a practical way. We develop an active learning framework for high dimensional data, a task which has been extremely challenging so far, with very sparse existing literature. Taking advantage of specialised models such as Bayesian convolutional neural networks, we demonstrate our active learning techniques with image data, obtaining a significant improvement on existing active learning approaches. We demonstrate this on both the MNIST dataset, as well as for skin cancer diagnosis from lesion images (ISIC2016 task).
Taming Adversarial Domain Transfer with Structural Constraints for Image Enhancement
Dec 18, 2017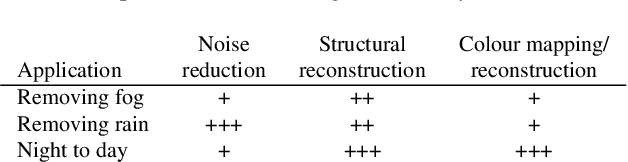

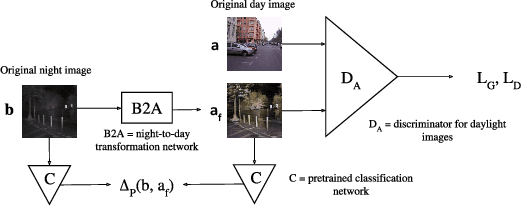
The goal of this work is to improve images of traffic scenes that are degraded by natural causes such as fog, rain and limited visibility during the night. For these applications, it is next to impossible to get pixel perfect pairs of the same scene, with and without the degrading conditions. This makes it unsuitable for conventional supervised learning approaches, however, it is easy to collect a dataset of unpaired images of the scenes in a perfect and in a degraded condition. To enhance the images taken in a poor visibility condition, domain transfer models can be trained to transform an image from the degraded to the clear domain. A well-known concept for unsupervised domain transfer are cycle-consistent generative adversarial models. Unfortunately, the resulting generators often change the structure of the scene. This causes an undesirable change in the semantics of the traffic situation. We propose three ways to cope with this problem depending on the type of degradation: forcing the same perception in both domains, forcing the same edges in both domains or guiding the generator to produce semantically sound transformations.
Grad-Cam Guided Progressive Feature CutMix for Classification
Jul 17, 2020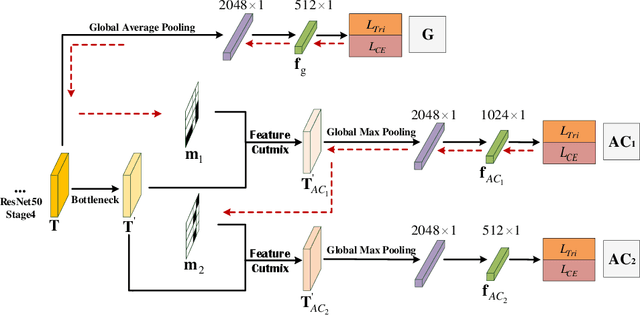
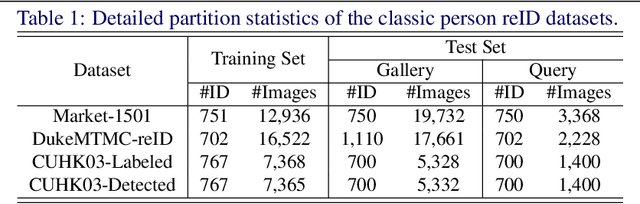
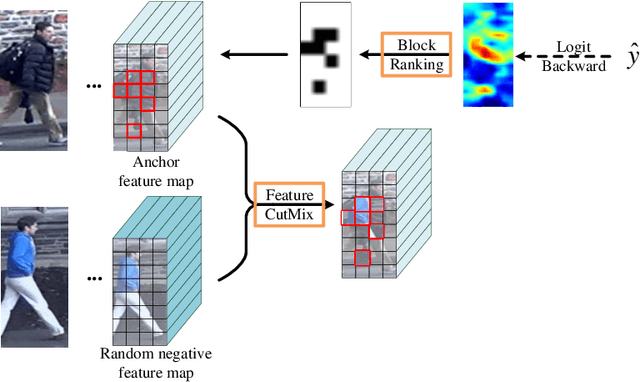
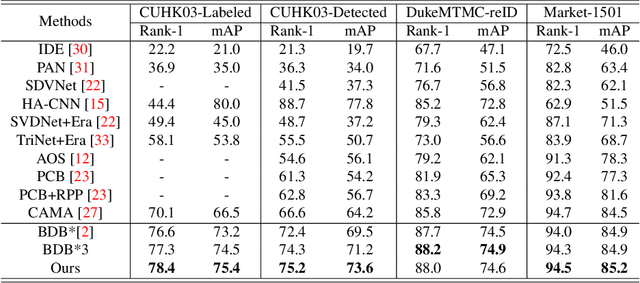
Image features from a small local region often give strong evidence in the classification task. However, CNN suffers from paying too much attention only on these local areas, thus ignoring other discriminative regions. This paper deals with this issue by performing the attentive feature cutmix in a progressive manner, among the multi-branch classifier trained on the same task. Specifically, we build the several sequential head branches, with the first global branch fed the original features without any constrains, and other following branches given the attentive cutmix features. The grad-CAM is employed to guide input features of them, so that discriminative region blocks in the current branch are intentionally cut and replaced by those from other images, hence preventing the model from relying on only the small regions and forcing it to gradually focus on large areas. Extensive experiments have been carried out on reID datasets such as the Market1501, DukeMTMC and CUHK03, showing that the proposed algorithm can boost the classification performance significantly.
Improved Consistency Regularization for GANs
Feb 11, 2020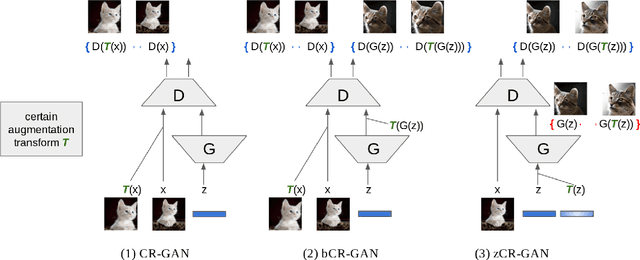
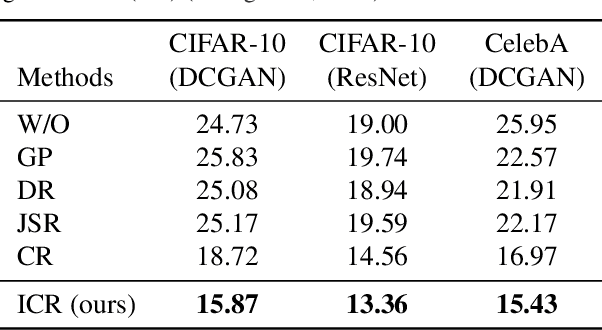


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
The Shape of an Image: A Study of Mapper on Images
Dec 07, 2017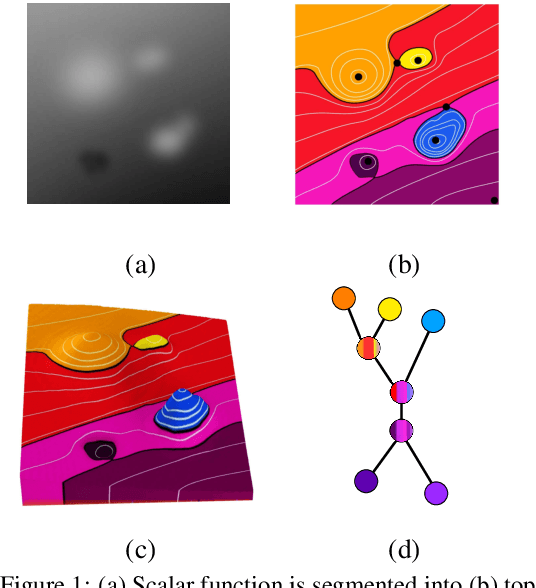
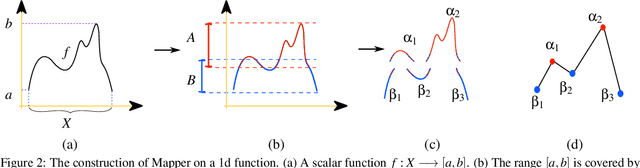
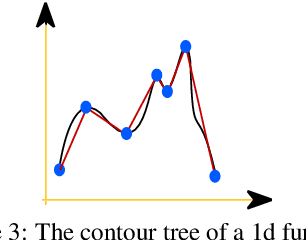
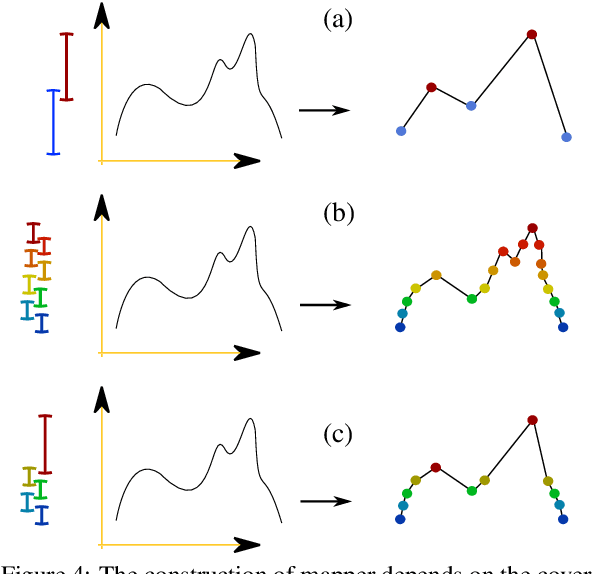
We study the topological construction called Mapper in the context of simply connected domains, in particular on images. The Mapper construction can be considered as a generalization for contour, split, and joint trees on simply connected domains. A contour tree on an image domain assumes the height function to be a piecewise linear Morse function. This is a rather restrictive class of functions and does not allow us to explore the topology for most real world images. The Mapper construction avoids this limitation by assuming only continuity on the height function allowing this construction to robustly deal with a significant larger set of images. We provide a customized construction for Mapper on images, give a fast algorithm to compute it, and show how to simplify the Mapper structure in this case. Finally, we provide a simple procedure that guarantees the equivalence of Mapper to contour, join, and split trees on a simply connected domain.
Information Bottleneck Constrained Latent Bidirectional Embedding for Zero-Shot Learning
Sep 16, 2020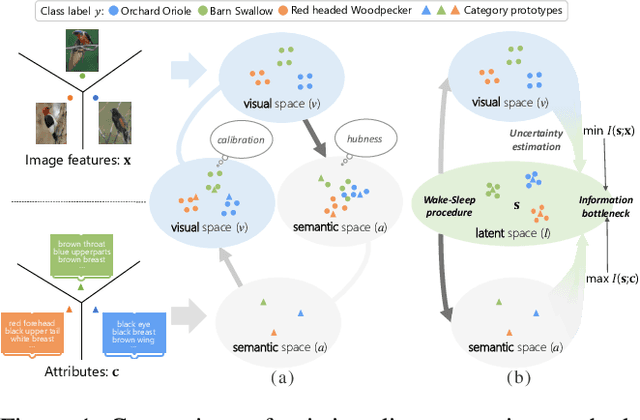
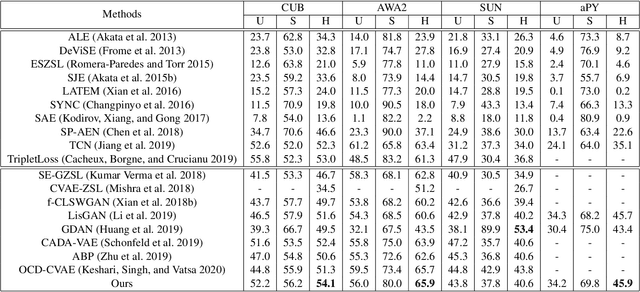
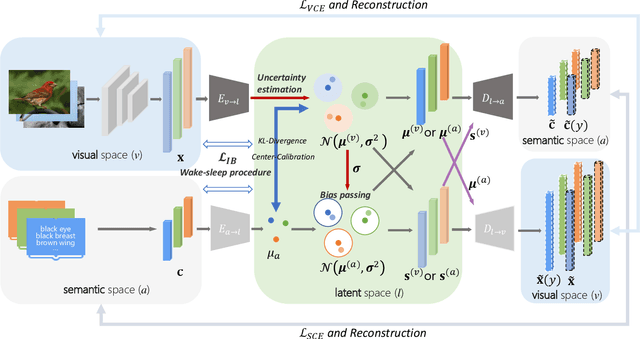
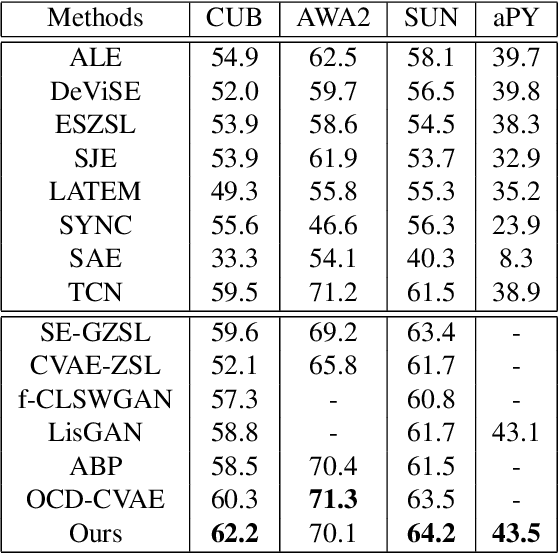
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Though many ZSL methods rely on a direct mapping between the visual and the semantic space, the calibration deviation and hubness problem limit the generalization capability to unseen classes. Recently emerged generative ZSL methods generate unseen image features to transform ZSL into a supervised classification problem. However, most generative models still suffer from the seen-unseen bias problem as only seen data is used for training. To address these issues, we propose a novel bidirectional embedding based generative model with a tight visual-semantic coupling constraint. We learn a unified latent space that calibrates the embedded parametric distributions of both visual and semantic spaces. Since the embedding from high-dimensional visual features comprise much non-semantic information, the alignment of visual and semantic in latent space would inevitably been deviated. Therefore, we introduce information bottleneck (IB) constraint to ZSL for the first time to preserve essential attribute information during the mapping. Specifically, we utilize the uncertainty estimation and the wake-sleep procedure to alleviate the noises and improve model abstraction capability. We evaluate the learned latent features on four benchmark datasets. Extensive experimental results show that our method outperforms the state-of-the-art methods in different ZSL settings on most benchmark datasets. The code will be available at https://github.com/osierboy/IBZSL.
LT-Net: Label Transfer by Learning Reversible Voxel-wise Correspondence for One-shot Medical Image Segmentation
Mar 19, 2020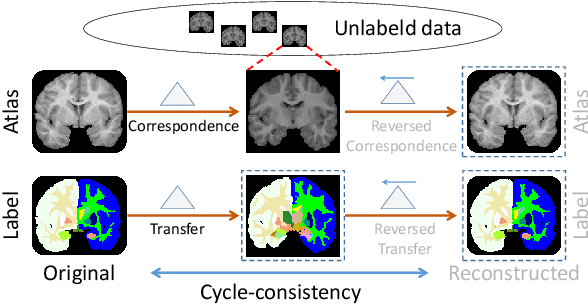
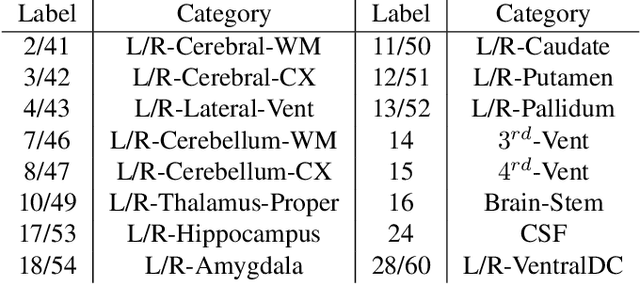
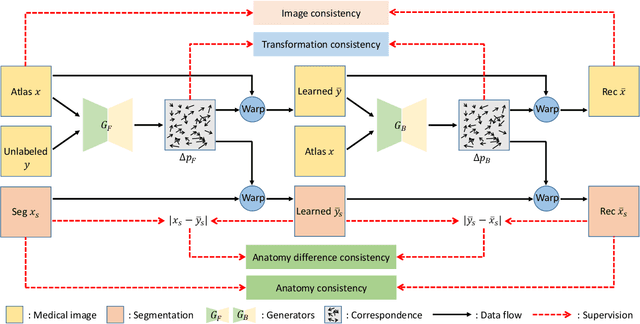
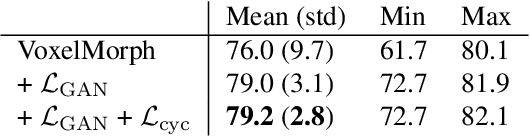
We introduce a one-shot segmentation method to alleviate the burden of manual annotation for medical images. The main idea is to treat one-shot segmentation as a classical atlas-based segmentation problem, where voxel-wise correspondence from the atlas to the unlabelled data is learned. Subsequently, segmentation label of the atlas can be transferred to the unlabelled data with the learned correspondence. However, since ground truth correspondence between images is usually unavailable, the learning system must be well-supervised to avoid mode collapse and convergence failure. To overcome this difficulty, we resort to the forward-backward consistency, which is widely used in correspondence problems, and additionally learn the backward correspondences from the warped atlases back to the original atlas. This cycle-correspondence learning design enables a variety of extra, cycle-consistency-based supervision signals to make the training process stable, while also boost the performance. We demonstrate the superiority of our method over both deep learning-based one-shot segmentation methods and a classical multi-atlas segmentation method via thorough experiments.
A Survey On 3D Inner Structure Prediction from its Outer Shape
Feb 11, 2020
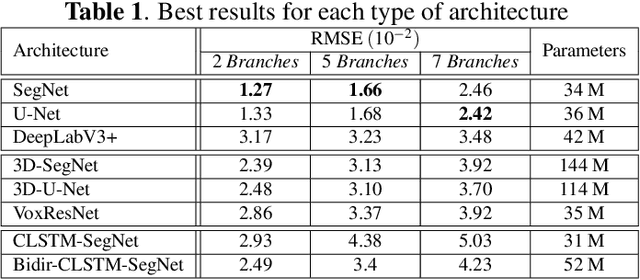
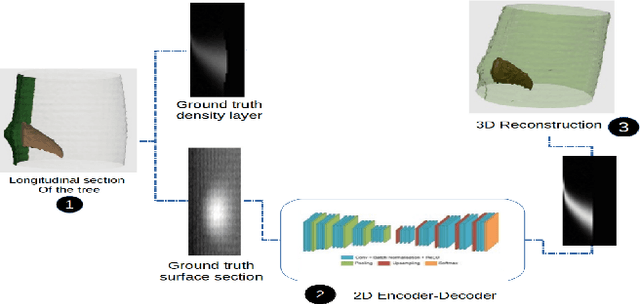

The analysis of the internal structure of trees is highly important for both forest experts, biological scientists, and the wood industry. Traditionally, CT-scanners are considered as the most efficient way to get an accurate inner representation of the tree. However, this method requires an important investment and reduces the cost-effectiveness of this operation. Our goal is to design neural-network-based methods to predict the internal density of the tree from its external bark shape. This paper compares different image-to-image(2D), volume-to-volume(3D) and Convolutional Long Short Term Memory based neural network architectures in the context of the prediction of the defect distribution inside trees from their external bark shape. Those models are trained on a synthetic dataset of 1800 CT-scanned look-like volumetric structures of the internal density of the trees and their corresponding external surface.
Relaxed Linearized Algorithms for Faster X-Ray CT Image Reconstruction
Dec 14, 2015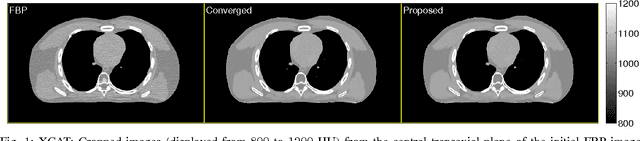
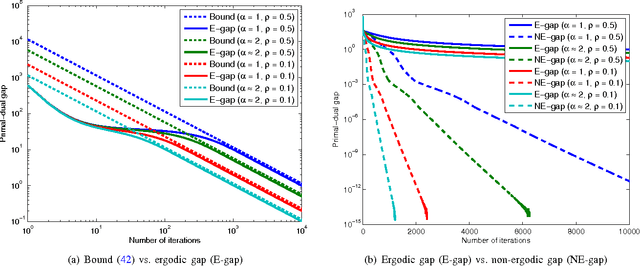
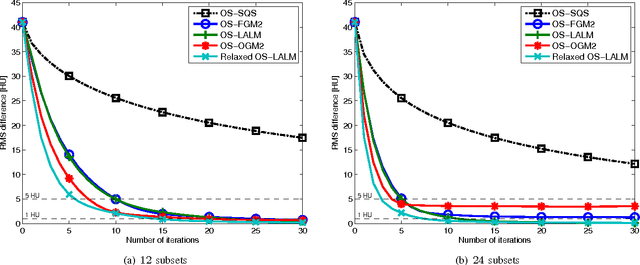
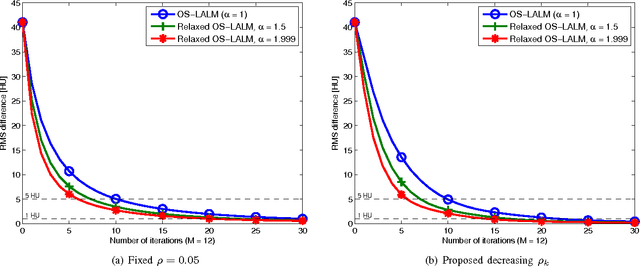
Statistical image reconstruction (SIR) methods are studied extensively for X-ray computed tomography (CT) due to the potential of acquiring CT scans with reduced X-ray dose while maintaining image quality. However, the longer reconstruction time of SIR methods hinders their use in X-ray CT in practice. To accelerate statistical methods, many optimization techniques have been investigated. Over-relaxation is a common technique to speed up convergence of iterative algorithms. For instance, using a relaxation parameter that is close to two in alternating direction method of multipliers (ADMM) has been shown to speed up convergence significantly. This paper proposes a relaxed linearized augmented Lagrangian (AL) method that shows theoretical faster convergence rate with over-relaxation and applies the proposed relaxed linearized AL method to X-ray CT image reconstruction problems. Experimental results with both simulated and real CT scan data show that the proposed relaxed algorithm (with ordered-subsets [OS] acceleration) is about twice as fast as the existing unrelaxed fast algorithms, with negligible computation and memory overhead.
DeepFL-IQA: Weak Supervision for Deep IQA Feature Learning
Jan 20, 2020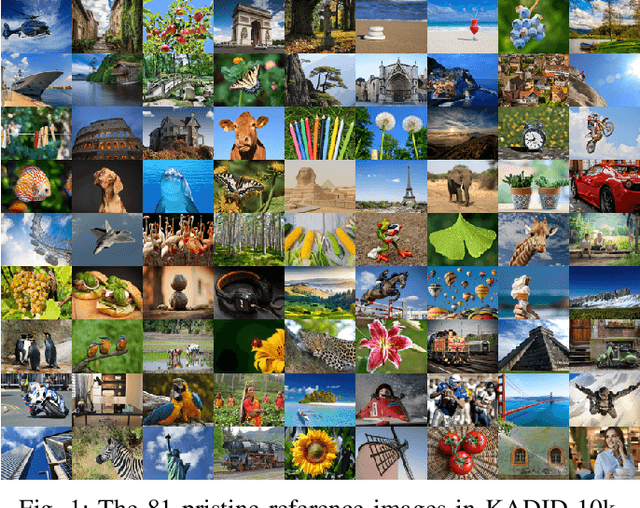
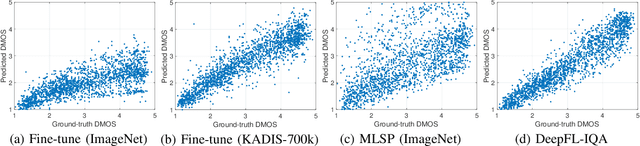

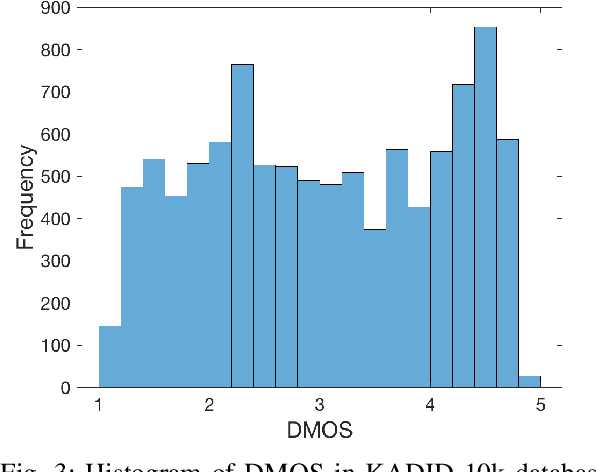
Multi-level deep-features have been driving state-of-the-art methods for aesthetics and image quality assessment (IQA). However, most IQA benchmarks are comprised of artificially distorted images, for which features derived from ImageNet under-perform. We propose a new IQA dataset and a weakly supervised feature learning approach to train features more suitable for IQA of artificially distorted images. The dataset, KADIS-700k, is far more extensive than similar works, consisting of 140,000 pristine images, 25 distortions types, totaling 700k distorted versions. Our weakly supervised feature learning is designed as a multi-task learning type training, using eleven existing full-reference IQA metrics as proxies for differential mean opinion scores. We also introduce a benchmark database, KADID-10k, of artificially degraded images, each subjectively annotated by 30 crowd workers. We make use of our derived image feature vectors for (no-reference) image quality assessment by training and testing a shallow regression network on this database and five other benchmark IQA databases. Our method, termed DeepFL-IQA, performs better than other feature-based no-reference IQA methods and also better than all tested full-reference IQA methods on KADID-10k. For the other five benchmark IQA databases, DeepFL-IQA matches the performance of the best existing end-to-end deep learning-based methods on average.