 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Accuracy-Fairness Paradox: Adversarial Example-based Data Augmentation for Visual Debiasing
Aug 13, 2020
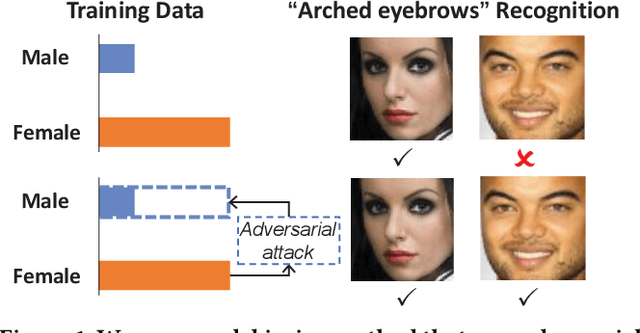
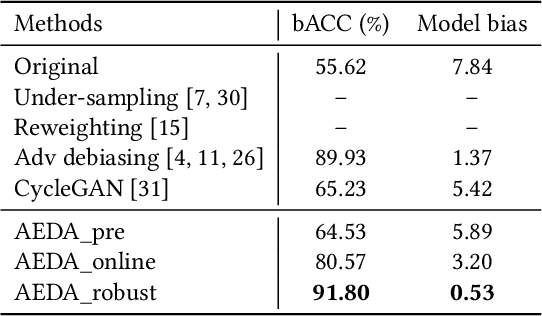
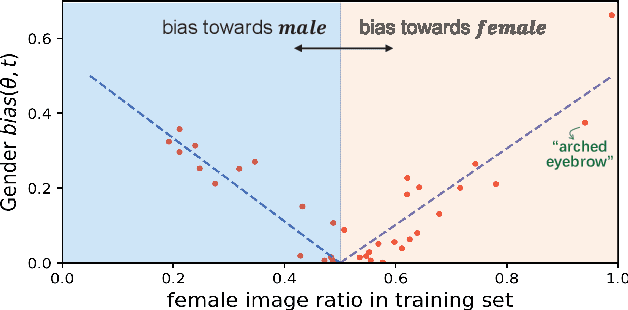
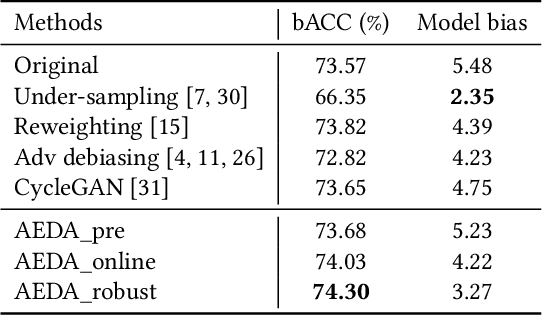
Machine learning fairness concerns about the biases towards certain protected or sensitive group of people when addressing the target tasks. This paper studies the debiasing problem in the context of image classification tasks. Our data analysis on facial attribute recognition demonstrates (1) the attribution of model bias from imbalanced training data distribution and (2) the potential of adversarial examples in balancing data distribution. We are thus motivated to employ adversarial example to augment the training data for visual debiasing. Specifically, to ensure the adversarial generalization as well as cross-task transferability, we propose to couple the operations of target task classifier training, bias task classifier training, and adversarial example generation. The generated adversarial examples supplement the target task training dataset via balancing the distribution over bias variables in an online fashion. Results on simulated and real-world debiasing experiments demonstrate the effectiveness of the proposed solution in simultaneously improving model accuracy and fairness. Preliminary experiment on few-shot learning further shows the potential of adversarial attack-based pseudo sample generation as alternative solution to make up for the training data lackage.
Learning Temporally Invariant and Localizable Features via Data Augmentation for Video Recognition
Aug 13, 2020



Deep-Learning-based video recognition has shown promising improvements along with the development of large-scale datasets and spatiotemporal network architectures. In image recognition, learning spatially invariant features is a key factor in improving recognition performance and robustness. Data augmentation based on visual inductive priors, such as cropping, flipping, rotating, or photometric jittering, is a representative approach to achieve these features. Recent state-of-the-art recognition solutions have relied on modern data augmentation strategies that exploit a mixture of augmentation operations. In this study, we extend these strategies to the temporal dimension for videos to learn temporally invariant or temporally localizable features to cover temporal perturbations or complex actions in videos. Based on our novel temporal data augmentation algorithms, video recognition performances are improved using only a limited amount of training data compared to the spatial-only data augmentation algorithms, including the 1st Visual Inductive Priors (VIPriors) for data-efficient action recognition challenge. Furthermore, learned features are temporally localizable that cannot be achieved using spatial augmentation algorithms. Our source code is available at https://github.com/taeoh-kim/temporal_data_augmentation.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020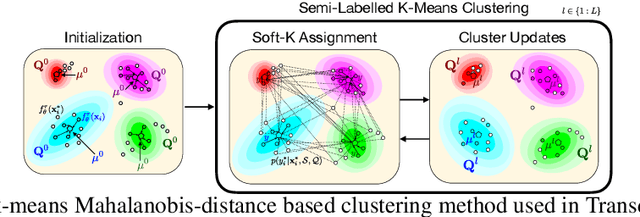
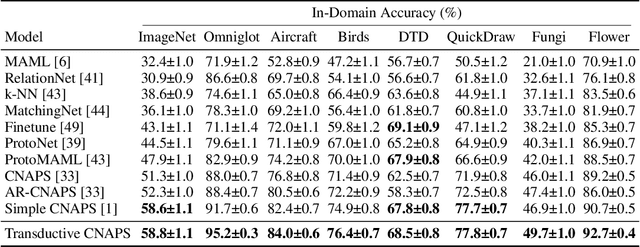
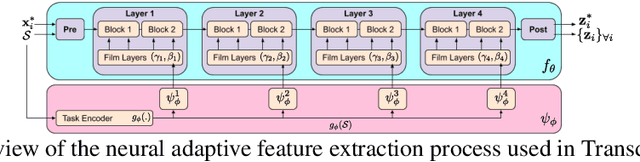
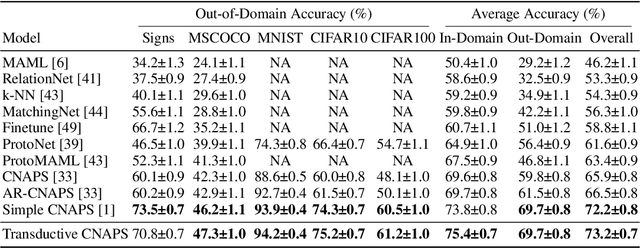
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
CAN: A Causal Adversarial Network for Learning Observational and Interventional Distributions
Aug 26, 2020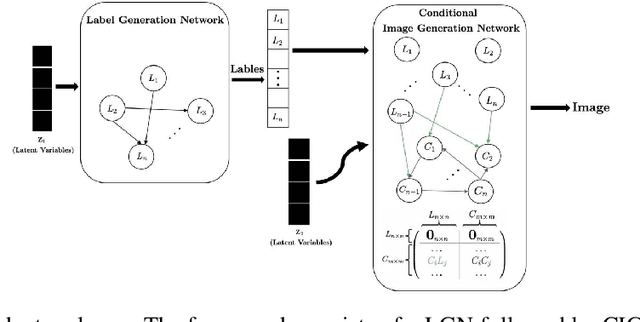
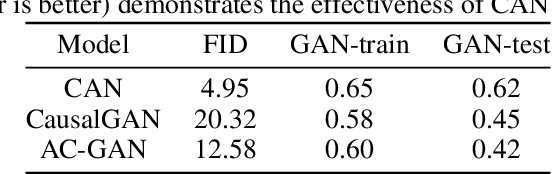


We propose a generative Causal Adversarial Network (CAN) for learning and sampling from observational (conditional) and interventional distributions. In contrast to the existing CausalGAN which requires the causal graph for the labels to be given, our proposed framework learns the causal relations from the data and generates samples accordingly. In addition to the relationships between labels, our model also learns the label-pixel and pixel-pixel dependencies and incorporate them in sample generation. The proposed CAN comprises a two-fold process namely Label Generation Network (LGN) and Conditional Image Generation Network (CIGN). The LGN is a novel GAN architecture which learns and samples from the causal graph over multi-categorical labels. The sampled labels are then fed to CIGN, a new conditional GAN architecture, which learns the relationships amongst labels and pixels and pixels themselves and generates samples based on them. This framework additionally provides an intervention mechanism which enables the model to generate samples from interventional distributions. We quantitatively and qualitatively assess the performance of CAN and empirically show that our model is able to generate both interventional and observational samples without having access to the causal graph for the application of face generation on CelebA data.
A Modified Perturbed Sampling Method for Local Interpretable Model-agnostic Explanation
Feb 18, 2020
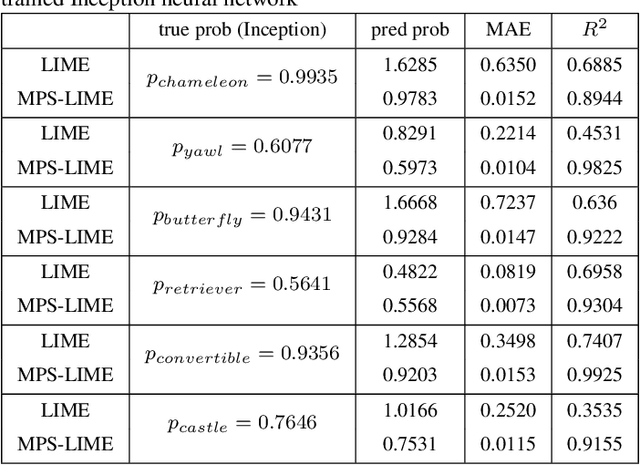
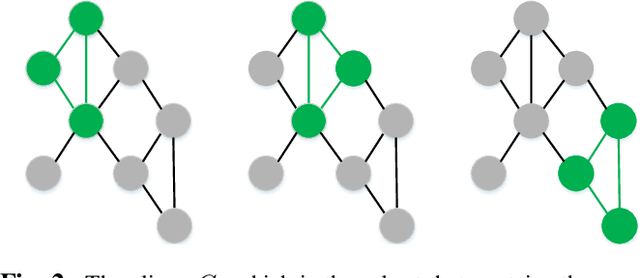
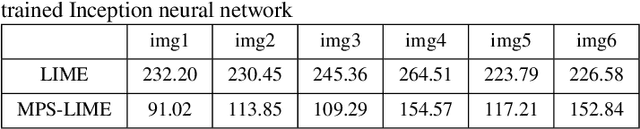
Explainability is a gateway between Artificial Intelligence and society as the current popular deep learning models are generally weak in explaining the reasoning process and prediction results. Local Interpretable Model-agnostic Explanation (LIME) is a recent technique that explains the predictions of any classifier faithfully by learning an interpretable model locally around the prediction. However, the sampling operation in the standard implementation of LIME is defective. Perturbed samples are generated from a uniform distribution, ignoring the complicated correlation between features. This paper proposes a novel Modified Perturbed Sampling operation for LIME (MPS-LIME), which is formalized as the clique set construction problem. In image classification, MPS-LIME converts the superpixel image into an undirected graph. Various experiments show that the MPS-LIME explanation of the black-box model achieves much better performance in terms of understandability, fidelity, and efficiency.
DC-Al GAN: Pseudoprogression and True Tumor Progression of Glioblastoma multiform Image Classification Based On DCGAN and Alexnet
Feb 16, 2019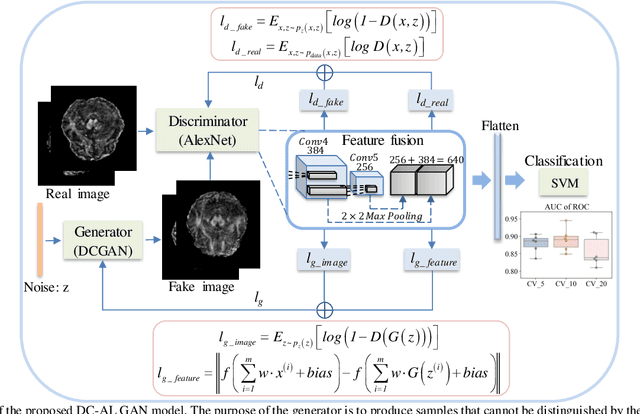
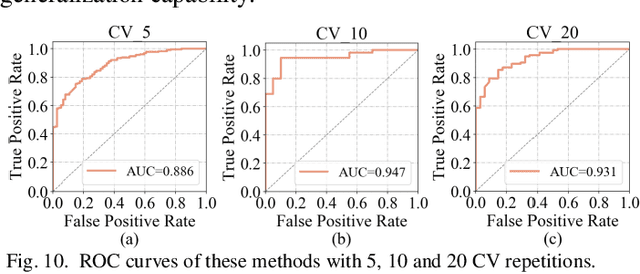
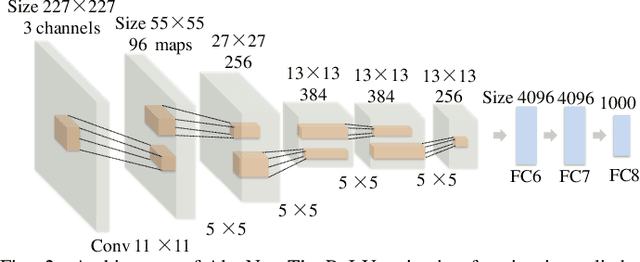
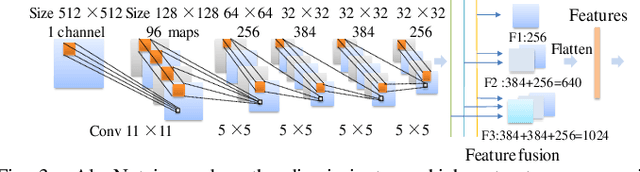
Glioblastoma multiform (GBM) is a kind of head tumor with an extraordinarily complex treatment process. The survival period is typically 14-16 months, and the 2 year survival rate is approximately 26%-33%. The clinical treatment strategies for the pseudoprogression (PsP) and true tumor progression (TTP) of GBM are different, so accurately distinguishing these two conditions is particularly significant.As PsP and TTP of GBM are similar in shape and other characteristics, it is hard to distinguish these two forms with precision. In order to differentiate them accurately, this paper introduces a feature learning method based on a generative adversarial network: DC-Al GAN. GAN consists of two architectures: generator and discriminator. Alexnet is used as the discriminator in this work. Owing to the adversarial and competitive relationship between generator and discriminator, the latter extracts highly concise features during training. In DC-Al GAN, features are extracted from Alexnet in the final classification phase, and the highly nature of them contributes positively to the classification accuracy.The generator in DC-Al GAN is modified by the deep convolutional generative adversarial network (DCGAN) by adding three convolutional layers. This effectively generates higher resolution sample images. Feature fusion is used to combine high layer features with low layer features, allowing for the creation and use of more precise features for classification. The experimental results confirm that DC-Al GAN achieves high accuracy on GBM datasets for PsP and TTP image classification, which is superior to other state-of-the-art methods.
Image Sampling with Quasicrystals
Jul 21, 2009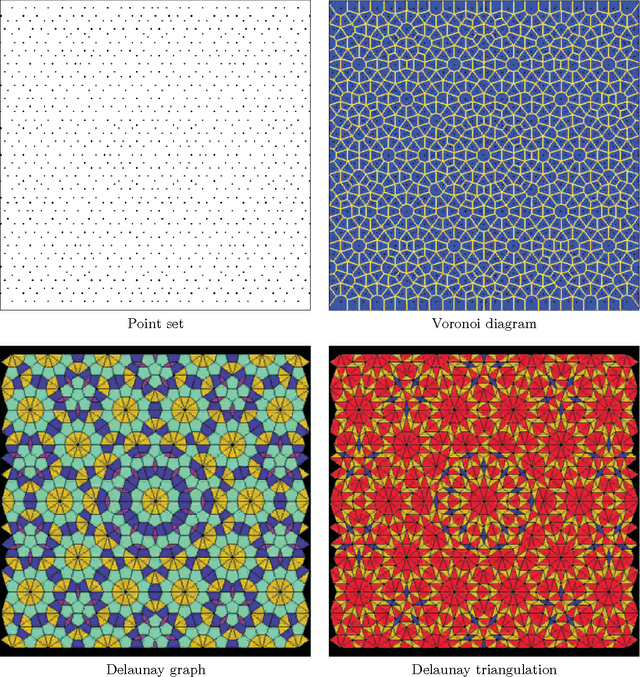
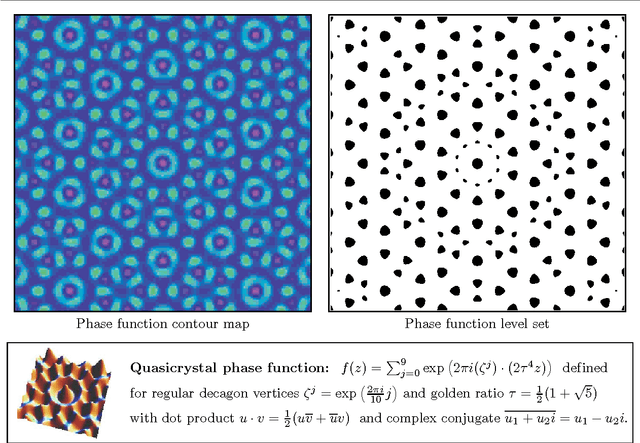
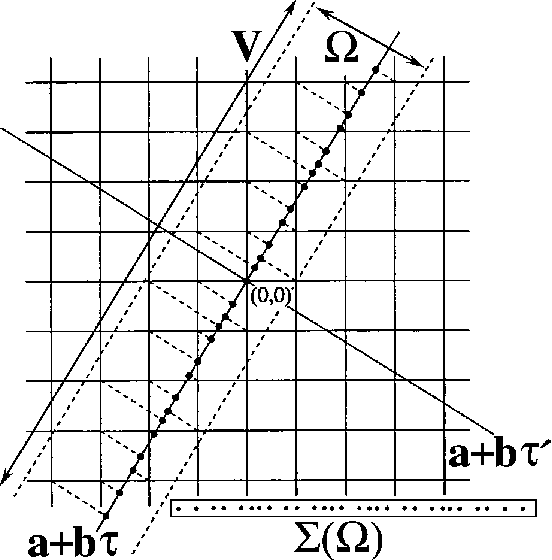

We investigate the use of quasicrystals in image sampling. Quasicrystals produce space-filling, non-periodic point sets that are uniformly discrete and relatively dense, thereby ensuring the sample sites are evenly spread out throughout the sampled image. Their self-similar structure can be attractive for creating sampling patterns endowed with a decorative symmetry. We present a brief general overview of the algebraic theory of cut-and-project quasicrystals based on the geometry of the golden ratio. To assess the practical utility of quasicrystal sampling, we evaluate the visual effects of a variety of non-adaptive image sampling strategies on photorealistic image reconstruction and non-photorealistic image rendering used in multiresolution image representations. For computer visualization of point sets used in image sampling, we introduce a mosaic rendering technique.
* For a full resolution version of this paper, along with supplementary materials, please visit at http://www.Eyemaginary.com/Portfolio/Publications.html
DeLTra: Deep Light Transport for Projector-Camera Systems
Mar 06, 2020
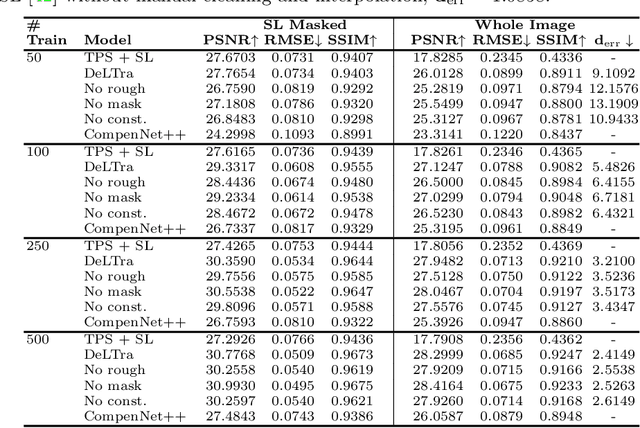
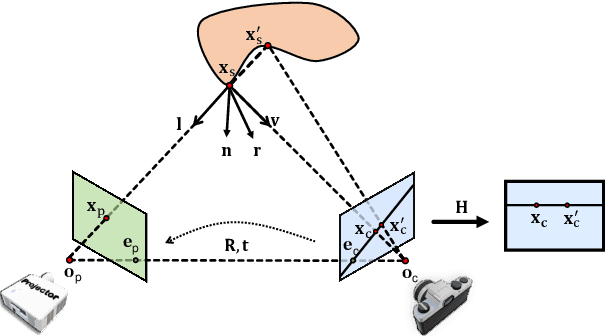

In projector-camera systems, light transport models the propagation from projector emitted radiance to camera-captured irradiance. In this paper, we propose the first end-to-end trainable solution named Deep Light Transport (DeLTra) that estimates radiometrically uncalibrated projector-camera light transport. DeLTra is designed to have two modules: DepthToAtrribute and ShadingNet. DepthToAtrribute explicitly learns rays, depth and normal, and then estimates rough Phong illuminations. Afterwards, the CNN-based ShadingNet renders photorealistic camera-captured image using estimated shading attributes and rough Phong illuminations. A particular challenge addressed by DeLTra is occlusion, for which we exploit epipolar constraint and propose a novel differentiable direct light mask. Thus, it can be learned end-to-end along with the other DeLTra modules. Once trained, DeLTra can be applied simultaneously to three projector-camera tasks: image-based relighting, projector compensation and depth/normal reconstruction. In our experiments, DeLTra shows clear advantages over previous arts with promising quality and meanwhile being practically convenient.
Dynamic Federated Learning Model for Identifying Adversarial Clients
Jul 29, 2020
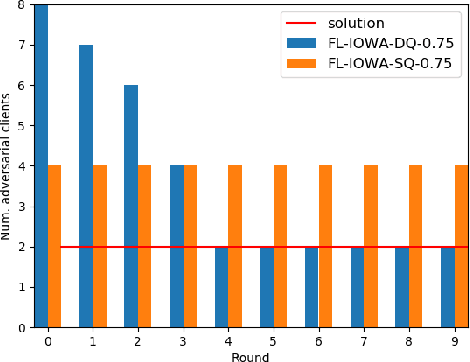
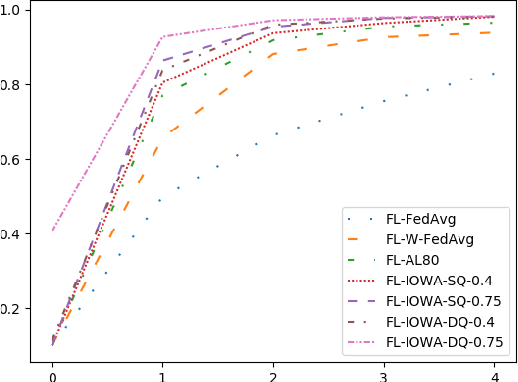
Federated learning, as a distributed learning that conducts the training on the local devices without accessing to the training data, is vulnerable to dirty-label data poisoning adversarial attacks. We claim that the federated learning model has to avoid those kind of adversarial attacks through filtering out the clients that manipulate the local data. We propose a dynamic federated learning model that dynamically discards those adversarial clients, which allows to prevent the corruption of the global learning model. We evaluate the dynamic discarding of adversarial clients deploying a deep learning classification model in a federated learning setting, and using the EMNIST Digits and Fashion MNIST image classification datasets. Likewise, we analyse the capacity of detecting clients with poor data distribution and reducing the number of rounds of learning by selecting the clients to aggregate. The results show that the dynamic selection of the clients to aggregate enhances the performance of the global learning model, discards the adversarial and poor clients and reduces the rounds of learning.
Human-Object Interaction Detection:A Quick Survey and Examination of Methods
Sep 27, 2020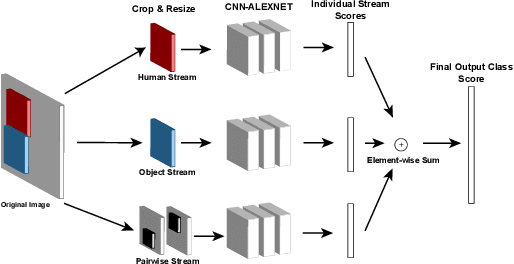
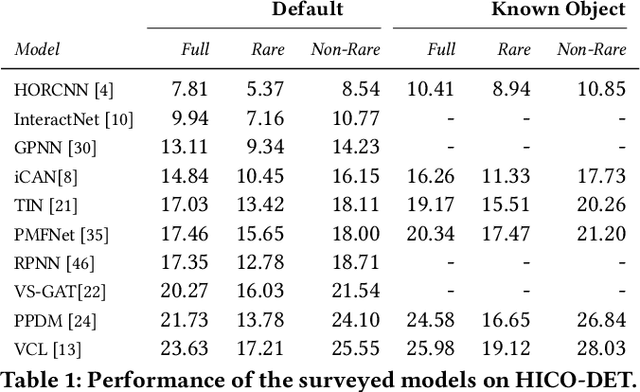
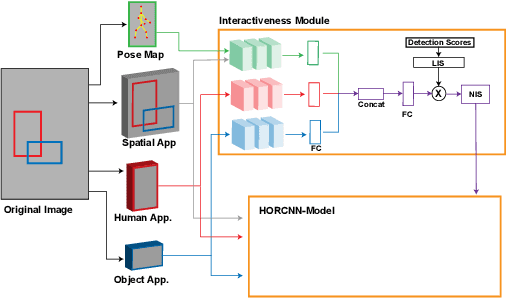

Human-object interaction detection is a relatively new task in the world of computer vision and visual semantic information extraction. With the goal of machines identifying interactions that humans perform on objects, there are many real-world use cases for the research in this field. To our knowledge, this is the first general survey of the state-of-the-art and milestone works in this field. We provide a basic survey of the developments in the field of human-object interaction detection. Many works in this field use multi-stream convolutional neural network architectures, which combine features from multiple sources in the input image. Most commonly these are the humans and objects in question, as well as the spatial quality of the two. As far as we are aware, there have not been in-depth studies performed that look into the performance of each component individually. In order to provide insight to future researchers, we perform an individualized study that examines the performance of each component of a multi-stream convolutional neural network architecture for human-object interaction detection. Specifically, we examine the HORCNN architecture as it is a foundational work in the field. In addition, we provide an in-depth look at the HICO-DET dataset, a popular benchmark in the field of human-object interaction detection. Code and papers can be found at https://github.com/SHI-Labs/Human-Object-Interaction-Detection.