 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Feature Replay For Class-Incremental Learning
Apr 20, 2020
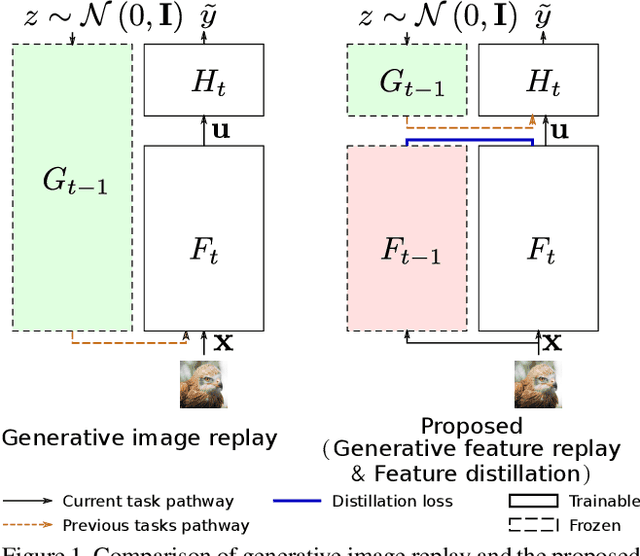

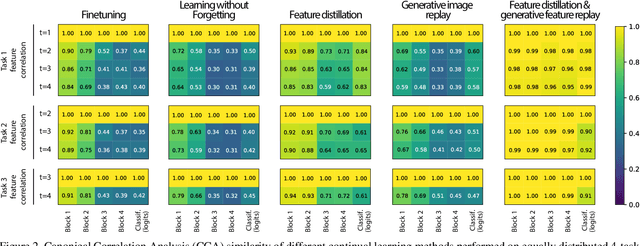
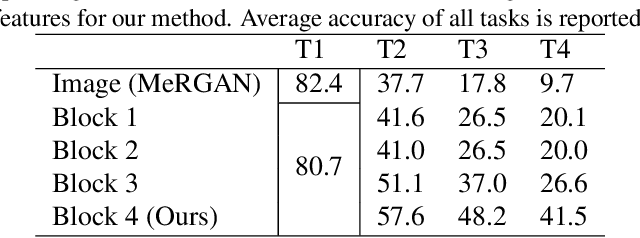
Humans are capable of learning new tasks without forgetting previous ones, while neural networks fail due to catastrophic forgetting between new and previously-learned tasks. We consider a class-incremental setting which means that the task-ID is unknown at inference time. The imbalance between old and new classes typically results in a bias of the network towards the newest ones. This imbalance problem can either be addressed by storing exemplars from previous tasks, or by using image replay methods. However, the latter can only be applied to toy datasets since image generation for complex datasets is a hard problem. We propose a solution to the imbalance problem based on generative feature replay which does not require any exemplars. To do this, we split the network into two parts: a feature extractor and a classifier. To prevent forgetting, we combine generative feature replay in the classifier with feature distillation in the feature extractor. Through feature generation, our method reduces the complexity of generative replay and prevents the imbalance problem. Our approach is computationally efficient and scalable to large datasets. Experiments confirm that our approach achieves state-of-the-art results on CIFAR-100 and ImageNet, while requiring only a fraction of the storage needed for exemplar-based continual learning. Code available at \url{https://github.com/xialeiliu/GFR-IL}.
Learning Multi-Scale Deep Features for High-Resolution Satellite Image Classification
Nov 11, 2016

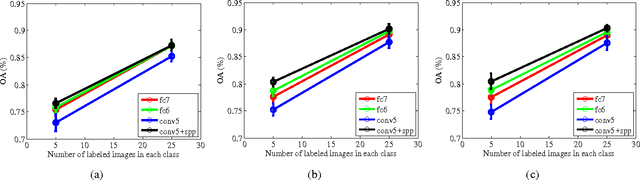
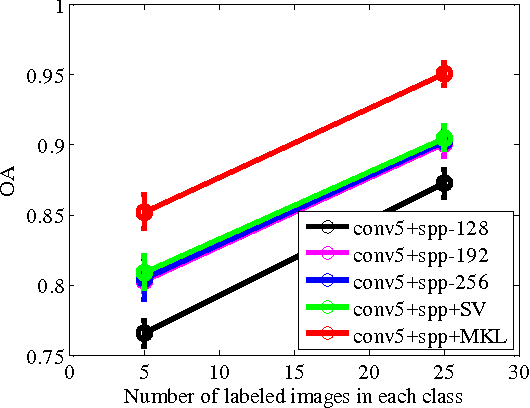
In this paper, we propose a multi-scale deep feature learning method for high-resolution satellite image classification. Specifically, we firstly warp the original satellite image into multiple different scales. The images in each scale are employed to train a deep convolutional neural network (DCNN). However, simultaneously training multiple DCNNs is time-consuming. To address this issue, we explore DCNN with spatial pyramid pooling (SPP-net). Since different SPP-nets have the same number of parameters, which share the identical initial values, and only fine-tuning the parameters in fully-connected layers ensures the effectiveness of each network, thereby greatly accelerating the training process. Then, the multi-scale satellite images are fed into their corresponding SPP-nets respectively to extract multi-scale deep features. Finally, a multiple kernel learning method is developed to automatically learn the optimal combination of such features. Experiments on two difficult datasets show that the proposed method achieves favorable performance compared to other state-of-the-art methods.
CURL: Co-trained Unsupervised Representation Learning for Image Classification
Sep 11, 2015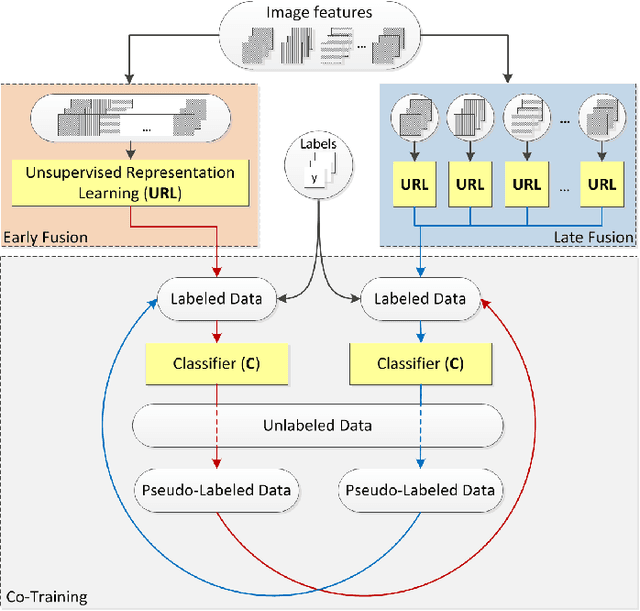

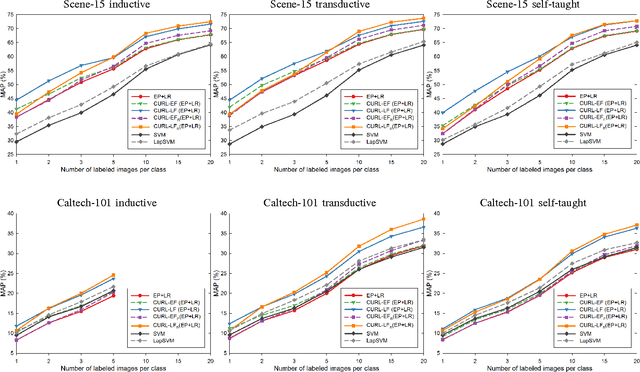

In this paper we propose a strategy for semi-supervised image classification that leverages unsupervised representation learning and co-training. The strategy, that is called CURL from Co-trained Unsupervised Representation Learning, iteratively builds two classifiers on two different views of the data. The two views correspond to different representations learned from both labeled and unlabeled data and differ in the fusion scheme used to combine the image features. To assess the performance of our proposal, we conducted several experiments on widely used data sets for scene and object recognition. We considered three scenarios (inductive, transductive and self-taught learning) that differ in the strategy followed to exploit the unlabeled data. As image features we considered a combination of GIST, PHOG, and LBP as well as features extracted from a Convolutional Neural Network. Moreover, two embodiments of CURL are investigated: one using Ensemble Projection as unsupervised representation learning coupled with Logistic Regression, and one based on LapSVM. The results show that CURL clearly outperforms other supervised and semi-supervised learning methods in the state of the art.
TIMELY: Improving Labeling Consistency in Medical Imaging for Cell Type Classification
Jul 10, 2020
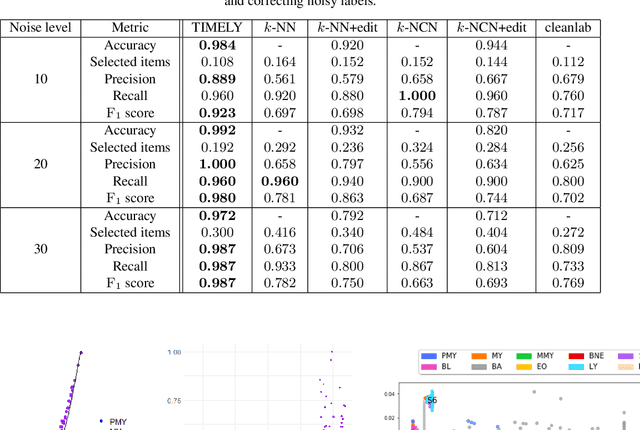
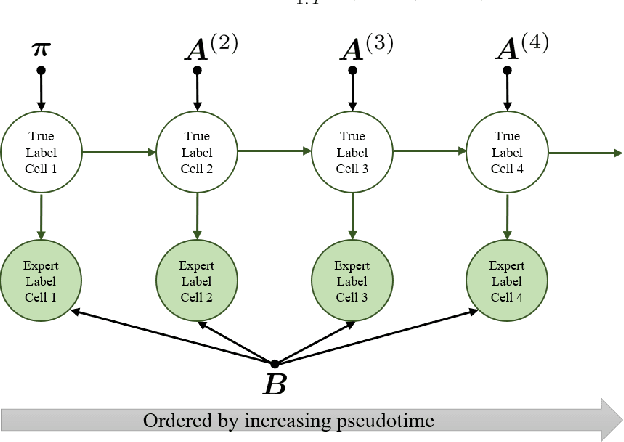
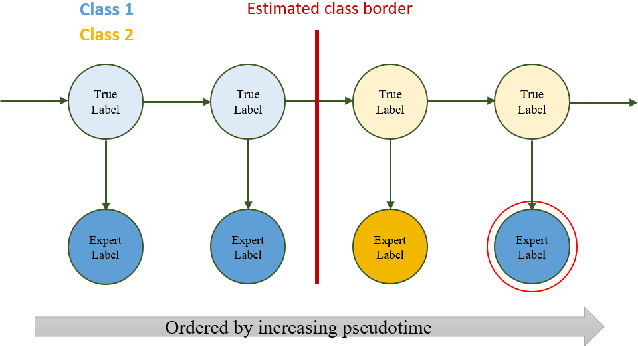
Diagnosing diseases such as leukemia or anemia requires reliable counts of blood cells. Hematologists usually label and count microscopy images of blood cells manually. In many cases, however, cells in different maturity states are difficult to distinguish, and in combination with image noise and subjectivity, humans are prone to make labeling mistakes. This results in labels that are often not reproducible, which can directly affect the diagnoses. We introduce TIMELY, a probabilistic model that combines pseudotime inference methods with inhomogeneous hidden Markov trees, which addresses this challenge of label inconsistency. We show first on simulation data that TIMELY is able to identify and correct wrong labels with higher precision and recall than baseline methods for labeling correction. We then apply our method to two real-world datasets of blood cell data and show that TIMELY successfully finds inconsistent labels, thereby improving the quality of human-generated labels.
Mirrored Autoencoders with Simplex Interpolation for Unsupervised Anomaly Detection
Mar 24, 2020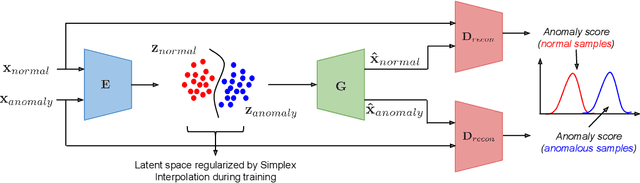
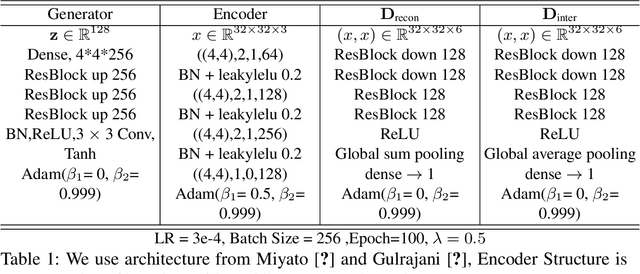
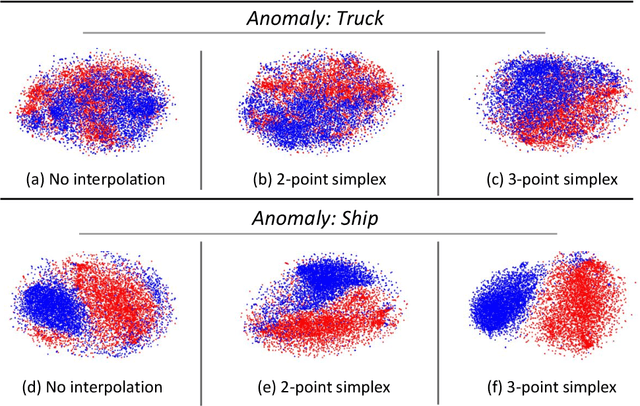
Use of deep generative models for unsupervised anomaly detection has shown great promise partially owing to their ability to learn proper representations of complex input data distributions. Current methods, however, lack a strong latent representation of the data, thereby resulting in sub-optimal unsupervised anomaly detection results. In this work, we propose a novel representation learning technique using deep autoencoders to tackle the problem of unsupervised anomaly detection. Our approach replaces the $L_{p}$ reconstruction loss in the autoencoder optimization objective with a novel adversarial loss to enforce semantic-level reconstruction. In addition, we propose a novel simplex interpolation loss to improve the structure of the latent space representation in the autoencoder. Our technique improves the state-of-the-art unsupervised anomaly detection performance by a large margin on several image datasets including MNIST, fashion MNIST, CIFAR and Coil-100 as well as on several non-image datasets including KDD99, Arrhythmia and Thyroid. For example, On the CIFAR-10 dataset, using a standard leave-one-out evaluation protocol, our method achieves a substantial performance gain of 0.23 AUC points compared to the state-of-the-art.
Half-CNN: A General Framework for Whole-Image Regression
Dec 22, 2014
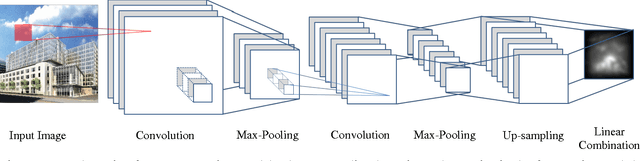


The Convolutional Neural Network (CNN) has achieved great success in image classification. The classification model can also be utilized at image or patch level for many other applications, such as object detection and segmentation. In this paper, we propose a whole-image CNN regression model, by removing the full connection layer and training the network with continuous feature maps. This is a generic regression framework that fits many applications. We demonstrate this method through two tasks: simultaneous face detection & segmentation, and scene saliency prediction. The result is comparable with other models in the respective fields, using only a small scale network. Since the regression model is trained on corresponding image / feature map pairs, there are no requirements on uniform input size as opposed to the classification model. Our framework avoids classifier design, a process that may introduce too much manual intervention in model development. Yet, it is highly correlated to the classification network and offers some in-deep review of CNN structures.
PoshakNet: Framework for matching dresses from real-life photos using GAN and Siamese Network
Nov 11, 2019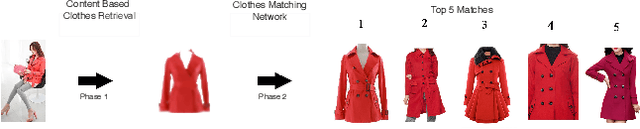
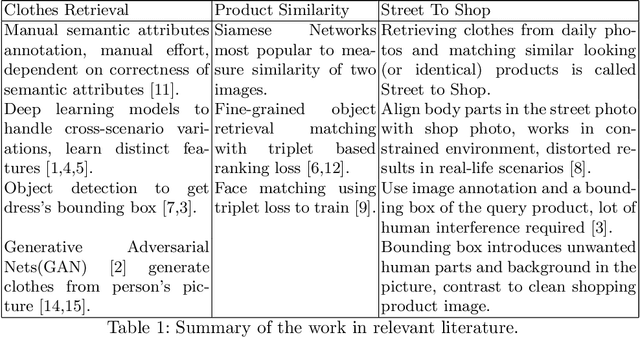

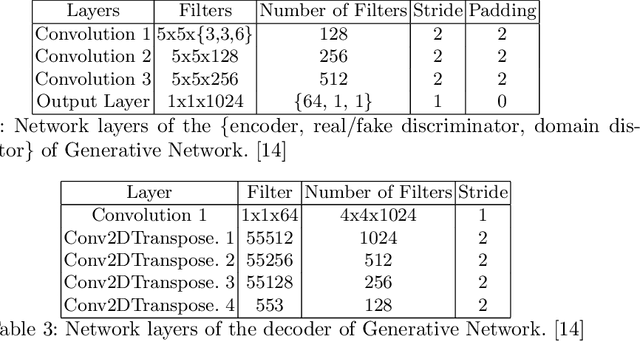
Online garment shopping has gained many customers in recent years. Describing a dress using keywords does not always yield the proper results, which in turn leads to dissatisfaction of customers. A visual search based system will be enormously beneficent to the industry. Hence, we propose a framework that can retrieve similar clothes that can be found in an image. The first task is to extract the garment from the input image (street photo). There are various challenges for that, including pose, illumination, and background clutter. We use a Generative Adversarial Network for the task of retrieving the garment that the person in the image was wearing. It has been shown that GAN can retrieve the garment very efficiently despite the challenges of street photos. Finally, a siamese based matching system takes the retrieved cloth image and matches it with the clothes in the dataset, giving us the top k matches. We take a pre-trained inception-ResNet v1 module as a siamese network (trained using triplet loss for face detection) and fine-tune it on the shopping dataset using center loss. The dataset has been collected inhouse. For training the GAN, we use the LookBook dataset, which is publically available.
Visual Summarization of Lecture Video Segments for Enhanced Navigation
Jun 03, 2020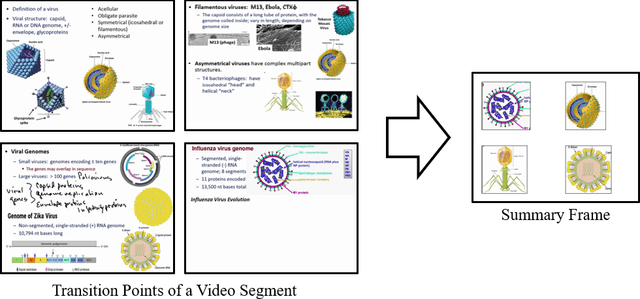
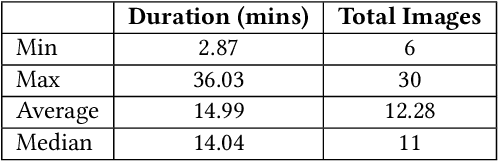
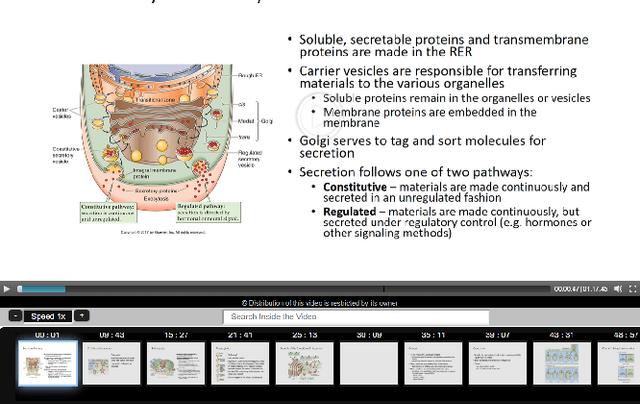
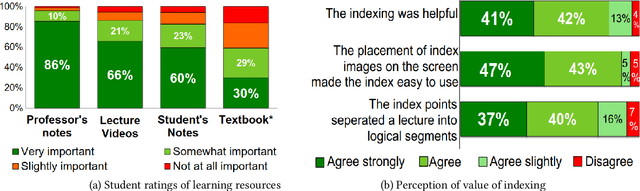
Lecture videos are an increasingly important learning resource for higher education. However, the challenge of quickly finding the content of interest in a lecture video is an important limitation of this format. This paper introduces visual summarization of lecture video segments to enhance navigation. A lecture video is divided into segments based on the frame-to-frame similarity of content. The user navigates the lecture video content by viewing a single frame visual and textual summary of each segment. The paper presents a novel methodology to generate the visual summary of a lecture video segment by computing similarities between images extracted from the segment and employing a graph-based algorithm to identify the subset of most representative images. The results from this research are integrated into a real-world lecture video management portal called Videopoints. To collect ground truth for evaluation, a survey was conducted where multiple users manually provided visual summaries for 40 lecture video segments. The users also stated whether any images were not selected for the summary because they were similar to other selected images. The graph based algorithm for identifying summary images achieves 78% precision and 72% F1-measure with frequently selected images as the ground truth, and 94% precision and 72% F1-measure with the union of all user selected images as the ground truth. For 98% of algorithm selected visual summary images, at least one user also selected that image for their summary or considered it similar to another image they selected. Over 65% of automatically generated summaries were rated as good or very good by the users on a 4-point scale from poor to very good. Overall, the results establish that the methodology introduced in this paper produces good quality visual summaries that are practically useful for lecture video navigation.
On Disentangling Spoof Trace for Generic Face Anti-Spoofing
Jul 17, 2020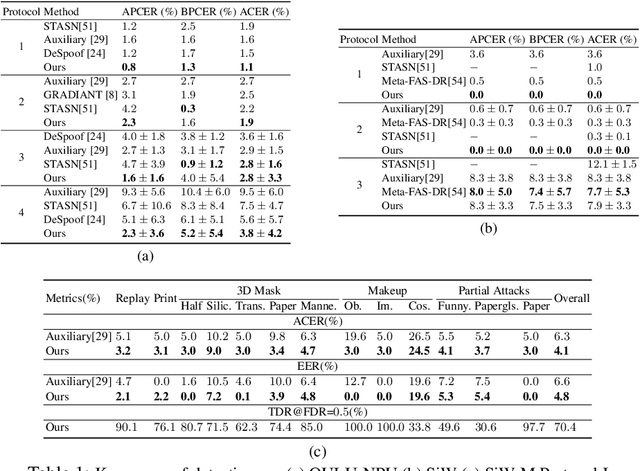
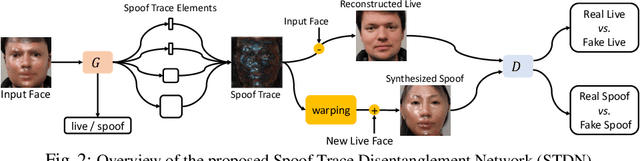
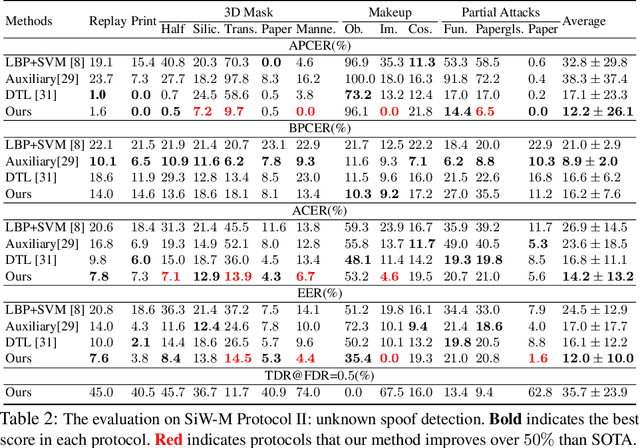
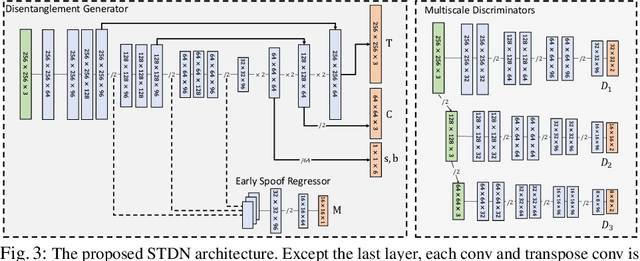
Prior studies show that the key to face anti-spoofing lies in the subtle image pattern, termed "spoof trace", e.g., color distortion, 3D mask edge, Moire pattern, and many others. Designing a generic anti-spoofing model to estimate those spoof traces can improve not only the generalization of the spoof detection, but also the interpretability of the model's decision. Yet, this is a challenging task due to the diversity of spoof types and the lack of ground truth in spoof traces. This work designs a novel adversarial learning framework to disentangle the spoof traces from input faces as a hierarchical combination of patterns at multiple scales. With the disentangled spoof traces, we unveil the live counterpart of the original spoof face, and further synthesize realistic new spoof faces after a proper geometric correction. Our method demonstrates superior spoof detection performance on both seen and unseen spoof scenarios while providing visually convincing estimation of spoof traces. Code is available at https://github.com/yaojieliu/ECCV20-STDN.
Image Retrieval Based on LBP Pyramidal Multiresolution using Reversible Watermarking
Sep 20, 2015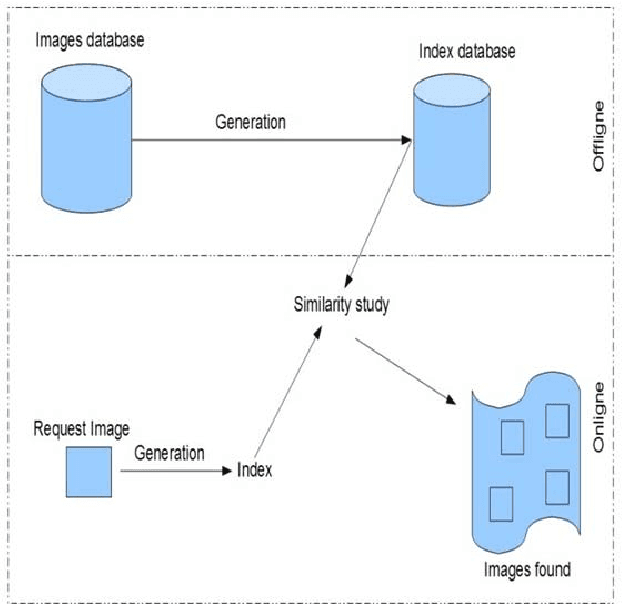
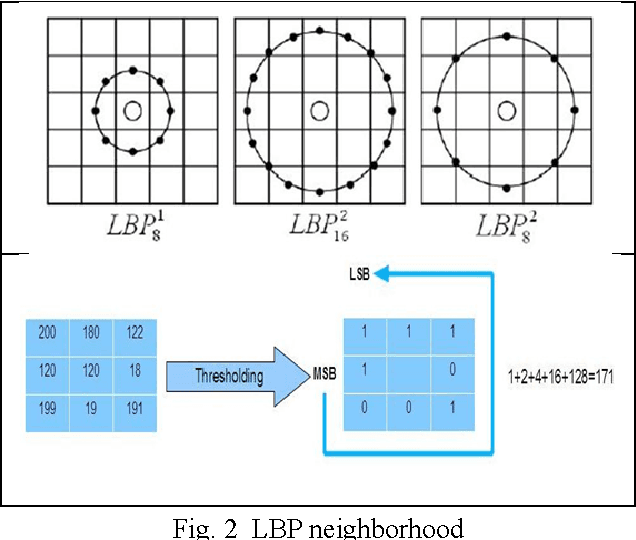
In the medical field, images are increasingly used to facilitate diagnosis of diseases. These images are stored in multimedia databases accompanied by doctor s prescriptions and other information related to patients.Search for medical images has become for clinical applications an essential tool to bring effective aid in diagnosis. Content Based Image Retrieval (CBIR) is one of the possible solutions to effectively manage these databases. Our contribution is to define a relevant descriptor to retrieve images based on multiresolution analysis of texture using Local Binary Pattern LBP. This descriptor once calculated and information s relating to the patient; will be placed in the image using the technique of reversible watermarking. Thereby, the image, descriptor of its contents, the BFILE locator and patientrelated information become a single entity, so even the administrator cannot have access to the patient private data.