 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Information-Bottleneck Approach to Salient Region Discovery
Jul 22, 2019
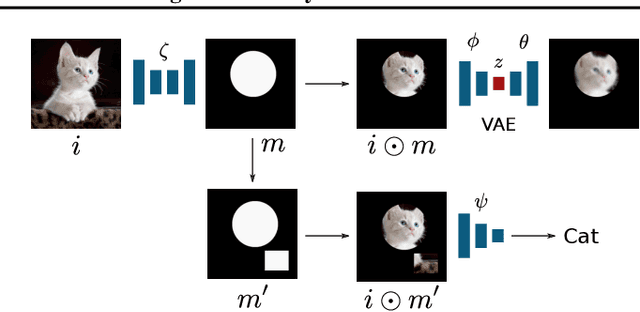



We propose a new method for learning image attention masks in a semi-supervised setting based on the Information Bottleneck principle. Provided with a set of labeled images, the mask generation model is minimizing mutual information between the input and the masked image while maximizing the mutual information between the same masked image and the image label. In contrast with other approaches, our attention model produces a Boolean rather than a continuous mask, entirely concealing the information in masked-out pixels. Using a set of synthetic datasets based on MNIST and CIFAR10 and the SVHN datasets, we demonstrate that our method can successfully attend to features known to define the image class.
Multi-Stream Networks and Ground-Truth Generation for Crowd Counting
Mar 11, 2020
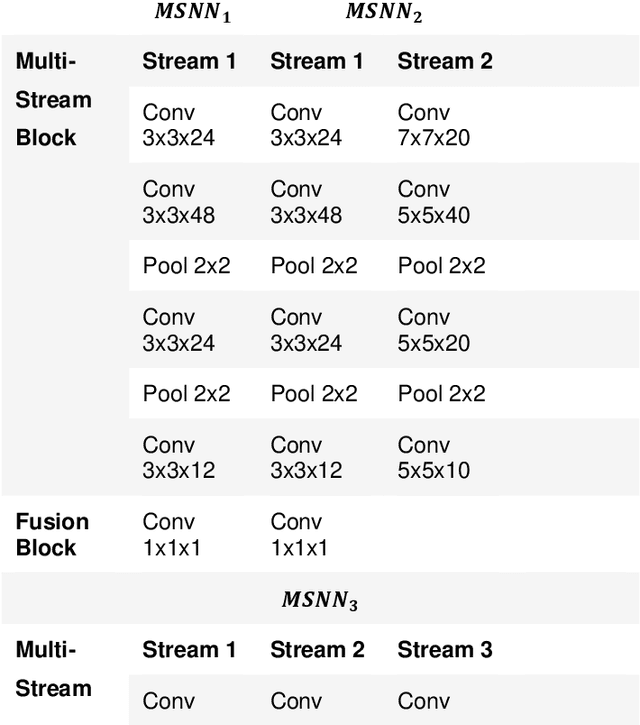
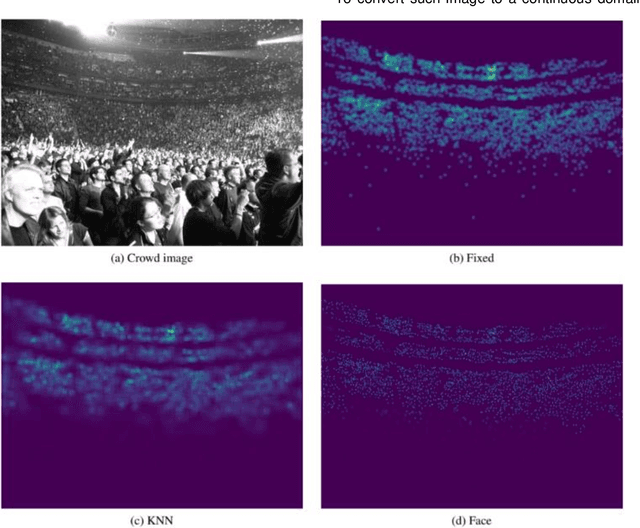
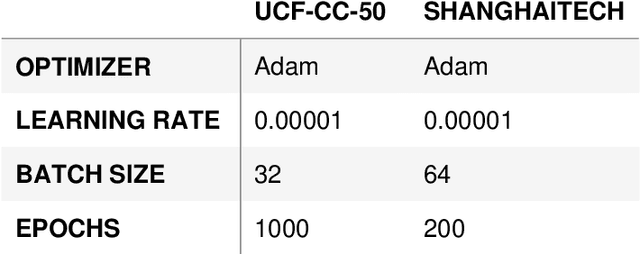
Crowd scene analysis has received a lot of attention recently due to the wide variety of applications, for instance, forensic science, urban planning, surveillance and security. In this context, a challenging task is known as crowd counting, whose main purpose is to estimate the number of people present in a single image. A Multi-Stream Convolutional Neural Network is developed and evaluated in this work, which receives an image as input and produces a density map that represents the spatial distribution of people in an end-to-end fashion. In order to address complex crowd counting issues, such as extremely unconstrained scale and perspective changes, the network architecture utilizes receptive fields with different size filters for each stream. In addition, we investigate the influence of the two most common fashions on the generation of ground truths and propose a hybrid method based on tiny face detection and scale interpolation. Experiments conducted on two challenging datasets, UCF-CC-50 and ShanghaiTech, demonstrate that using our ground truth generation methods achieves superior results.
Mining self-similarity: Label super-resolution with epitomic representations
Apr 24, 2020
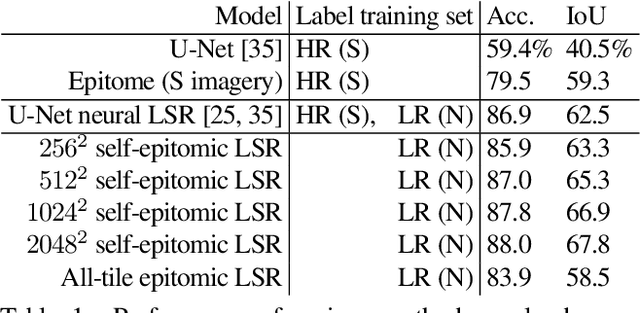

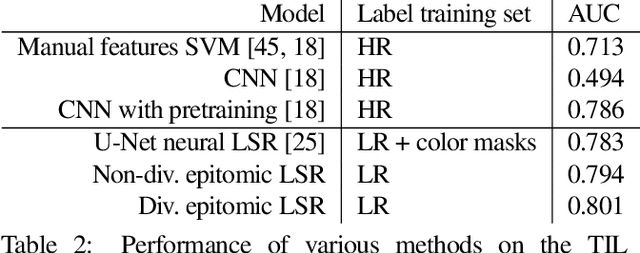
We show that simple patch-based models, such as epitomes, can have superior performance to the current state of the art in semantic segmentation and label super-resolution, which uses deep convolutional neural networks. We derive a new training algorithm for epitomes which allows, for the first time, learning from very large data sets and derive a label super-resolution algorithm as a statistical inference algorithm over epitomic representations. We illustrate our methods on land cover mapping and medical image analysis tasks.
Including Images into Message Veracity Assessment in Social Media
Jul 20, 2020
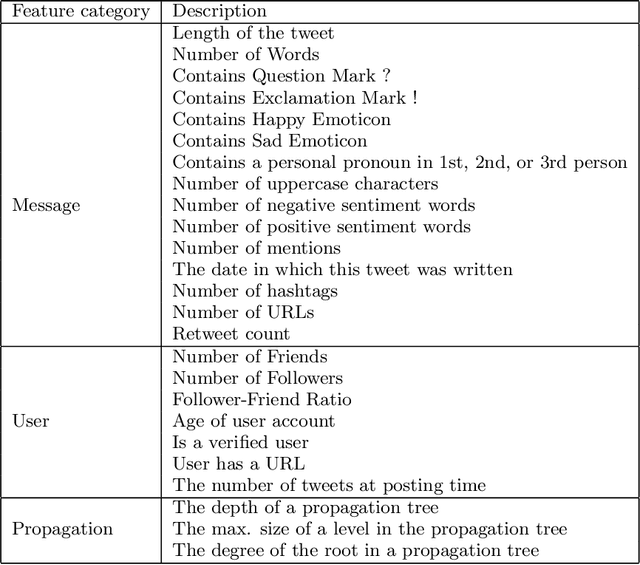
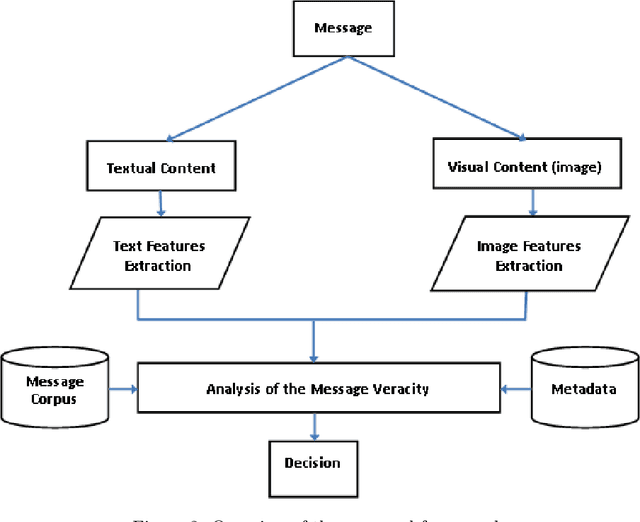

The extensive use of social media in the diffusion of information has also laid a fertile ground for the spread of rumors, which could significantly affect the credibility of social media. An ever-increasing number of users post news including, in addition to text, multimedia data such as images and videos. Yet, such multimedia content is easily editable due to the broad availability of simple and effective image and video processing tools. The problem of assessing the veracity of social network posts has attracted a lot of attention from researchers in recent years. However, almost all previous works have focused on analyzing textual contents to determine veracity, while visual contents, and more particularly images, remains ignored or little exploited in the literature. In this position paper, we propose a framework that explores two novel ways to assess the veracity of messages published on social networks by analyzing the credibility of both their textual and visual contents.
One Weight Bitwidth to Rule Them All
Aug 28, 2020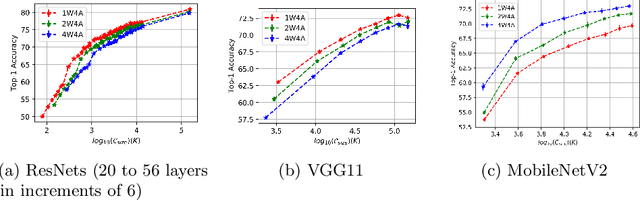

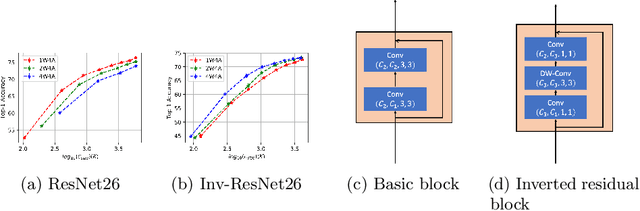
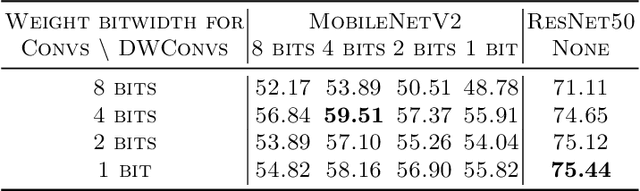
Weight quantization for deep ConvNets has shown promising results for applications such as image classification and semantic segmentation and is especially important for applications where memory storage is limited. However, when aiming for quantization without accuracy degradation, different tasks may end up with different bitwidths. This creates complexity for software and hardware support and the complexity accumulates when one considers mixed-precision quantization, in which case each layer's weights use a different bitwidth. Our key insight is that optimizing for the least bitwidth subject to no accuracy degradation is not necessarily an optimal strategy. This is because one cannot decide optimality between two bitwidths if one has a smaller model size while the other has better accuracy. In this work, we take the first step to understand if some weight bitwidth is better than others by aligning all to the same model size using a width-multiplier. Under this setting, somewhat surprisingly, we show that using a single bitwidth for the whole network can achieve better accuracy compared to mixed-precision quantization targeting zero accuracy degradation when both have the same model size. In particular, our results suggest that when the number of channels becomes a target hyperparameter, a single weight bitwidth throughout the network shows superior results for model compression.
Multi-View Matching Network for 6D Pose Estimation
Nov 27, 2019
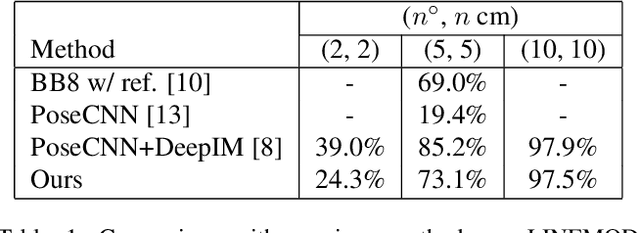
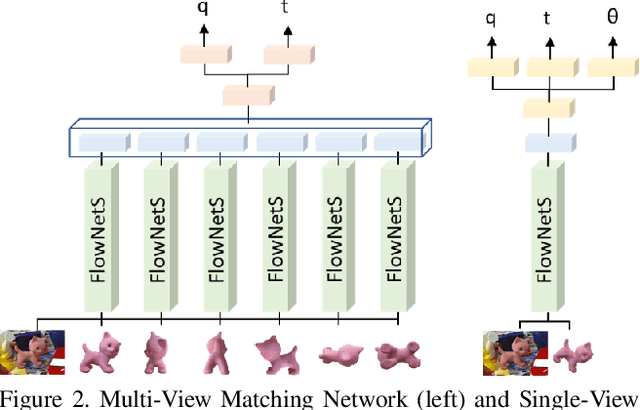

Applications that interact with the real world such as augmented reality or robot manipulation require a good understanding of the location and pose of the surrounding objects. In this paper, we present a new approach to estimate the 6 Degree of Freedom (DoF) or 6D pose of objects from a single RGB image. Our approach can be paired with an object detection and segmentation method to estimate, refine and track the pose of the objects by matching the input image with rendered images.
SPEED: Secure, PrivatE, and Efficient Deep learning
Jun 16, 2020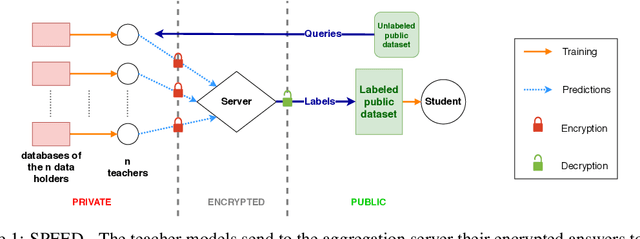
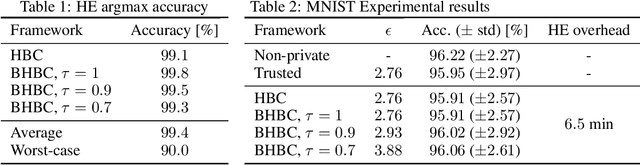
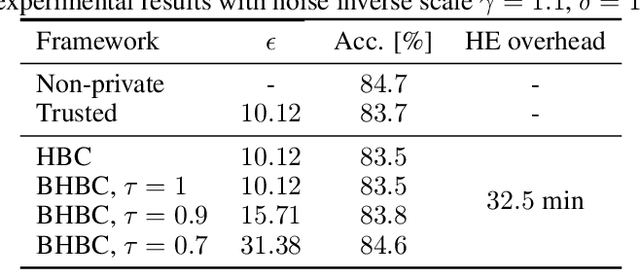
This paper addresses the issue of collaborative deep learning with privacy constraints. Building upon differentially private decentralized semi-supervised learning, we introduce homomorphically encrypted operations to extend the set of threats considered so far. While previous methods relied on the existence of an hypothetical 'trusted' third party, we designed specific aggregation operations in the encrypted domain that allow us to circumvent this assumption. This makes our method practical to real-life scenario where data holders do not trust any third party to process their datasets. Crucially the computational burden of the approach is maintained reasonable, making it suitable to deep learning applications. In order to illustrate the performances of our method, we carried out numerical experiments using image datasets in a classification context.
SeCo: Exploring Sequence Supervision for Unsupervised Representation Learning
Aug 03, 2020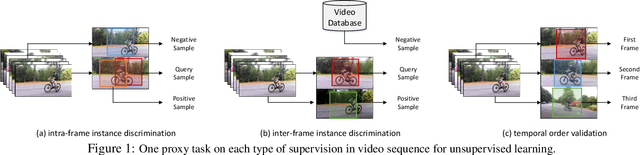
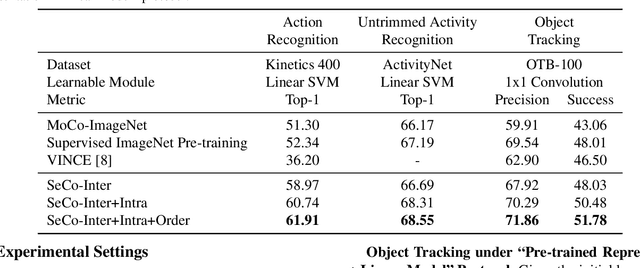
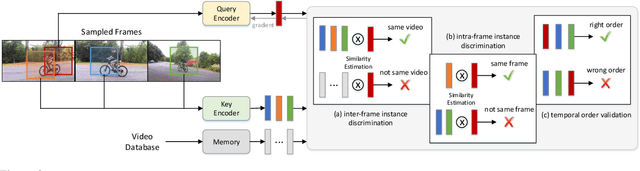
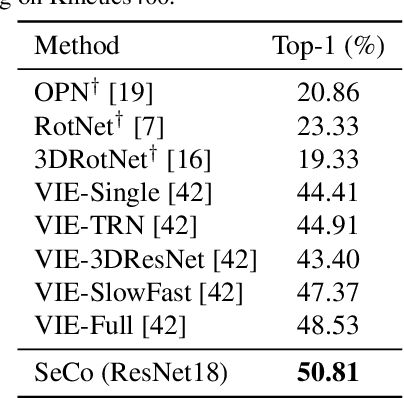
A steady momentum of innovations and breakthroughs has convincingly pushed the limits of unsupervised image representation learning. Compared to static 2D images, video has one more dimension (time). The inherent supervision existing in such sequential structure offers a fertile ground for building unsupervised learning models. In this paper, we compose a trilogy of exploring the basic and generic supervision in the sequence from spatial, spatiotemporal and sequential perspectives. We materialize the supervisory signals through determining whether a pair of samples is from one frame or from one video, and whether a triplet of samples is in the correct temporal order. We uniquely regard the signals as the foundation in contrastive learning and derive a particular form named Sequence Contrastive Learning (SeCo). SeCo shows superior results under the linear protocol on action recognition (Kinetics), untrimmed activity recognition (ActivityNet) and object tracking (OTB-100). More remarkably, SeCo demonstrates considerable improvements over recent unsupervised pre-training techniques, and leads the accuracy by 2.96% and 6.47% against fully-supervised ImageNet pre-training in action recognition task on UCF101 and HMDB51, respectively.
Quantitative Analysis of Automatic Image Cropping Algorithms: A Dataset and Comparative Study
Jan 05, 2017
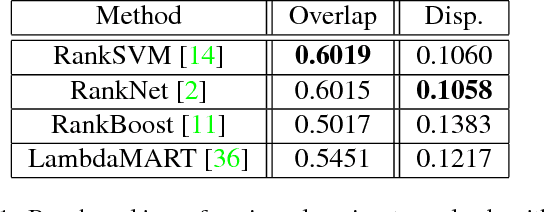

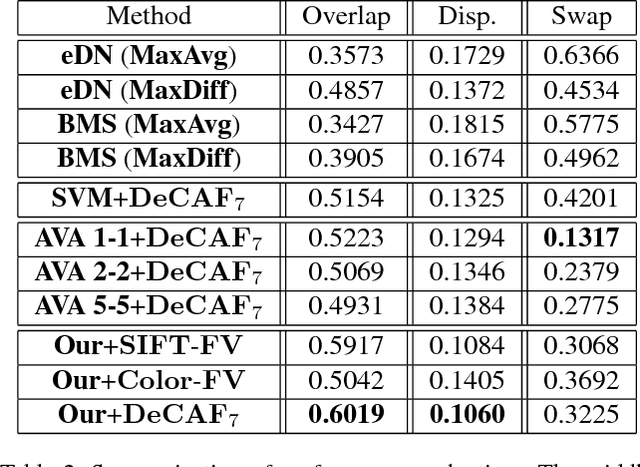
Automatic photo cropping is an important tool for improving visual quality of digital photos without resorting to tedious manual selection. Traditionally, photo cropping is accomplished by determining the best proposal window through visual quality assessment or saliency detection. In essence, the performance of an image cropper highly depends on the ability to correctly rank a number of visually similar proposal windows. Despite the ranking nature of automatic photo cropping, little attention has been paid to learning-to-rank algorithms in tackling such a problem. In this work, we conduct an extensive study on traditional approaches as well as ranking-based croppers trained on various image features. In addition, a new dataset consisting of high quality cropping and pairwise ranking annotations is presented to evaluate the performance of various baselines. The experimental results on the new dataset provide useful insights into the design of better photo cropping algorithms.
Frame-To-Frame Consistent Semantic Segmentation
Aug 03, 2020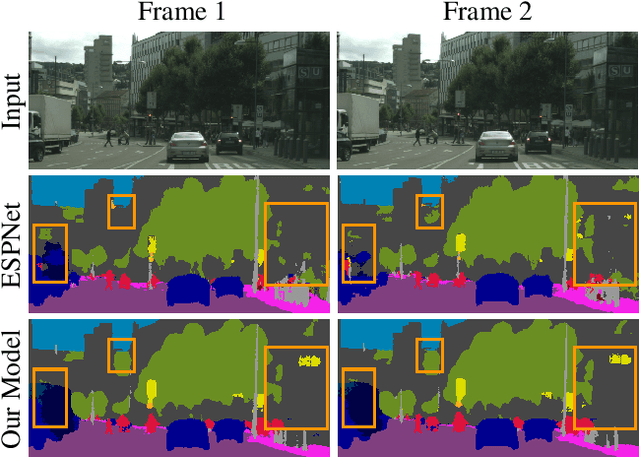
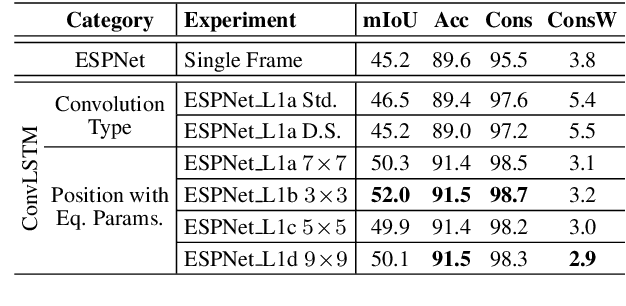
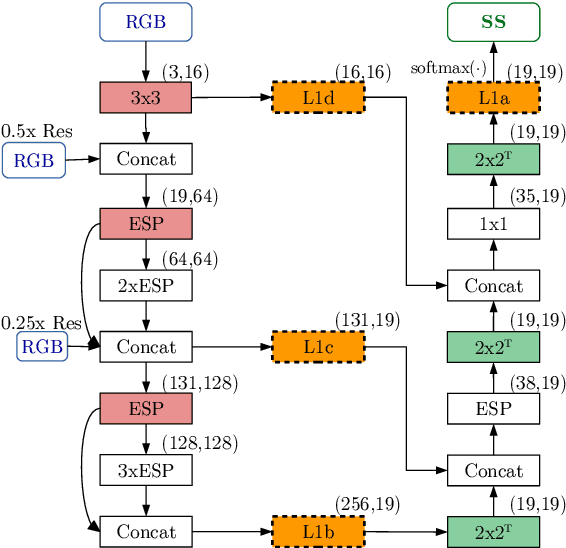
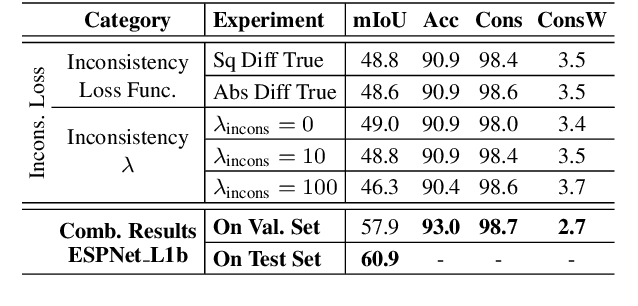
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.