 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Mesh Data Augmentation via Chebyshev Polynomial of Spectral filtering
Oct 06, 2020
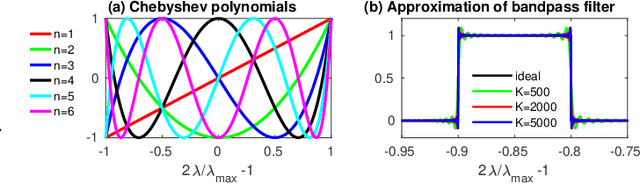
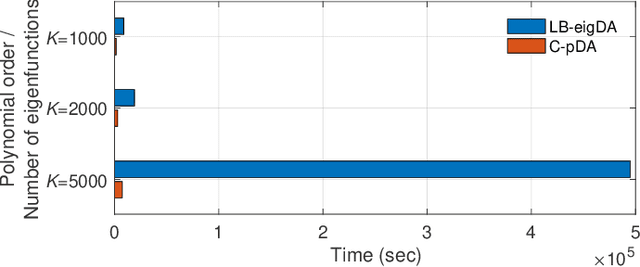
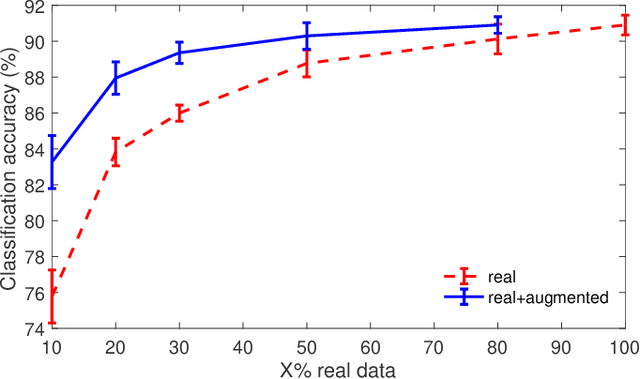
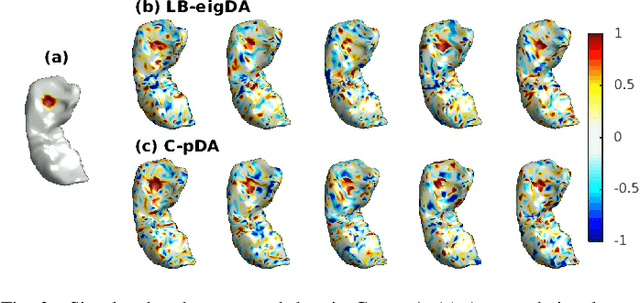
Deep neural networks have recently been recognized as one of the powerful learning techniques in computer vision and medical image analysis. Trained deep neural networks need to be generalizable to new data that was not seen before. In practice, there is often insufficient training data available and augmentation is used to expand the dataset. Even though graph convolutional neural network (graph-CNN) has been widely used in deep learning, there is a lack of augmentation methods to generate data on graphs or surfaces. This study proposes two unbiased augmentation methods, Laplace-Beltrami eigenfunction Data Augmentation (LB-eigDA) and Chebyshev polynomial Data Augmentation (C-pDA), to generate new data on surfaces, whose mean is the same as that of real data. LB-eigDA augments data via the resampling of the LB coefficients. In parallel with LB-eigDA, we introduce a fast augmentation approach, C-pDA, that employs a polynomial approximation of LB spectral filters on surfaces. We design LB spectral bandpass filters by Chebyshev polynomial approximation and resample signals filtered via these filters to generate new data on surfaces. We first validate LB-eigDA and C-pDA via simulated data and demonstrate their use for improving classification accuracy. We then employ the brain images of Alzheimer's Disease Neuroimaging Initiative (ADNI) and extract cortical thickness that is represented on the cortical surface to illustrate the use of the two augmentation methods. We demonstrate that augmented cortical thickness has a similar pattern to real data. Second, we show that C-pDA is much faster than LB-eigDA. Last, we show that C-pDA can improve the AD classification accuracy of graph-CNN.
Conjugate-gradient-based Adam for stochastic optimization and its application to deep learning
Mar 03, 2020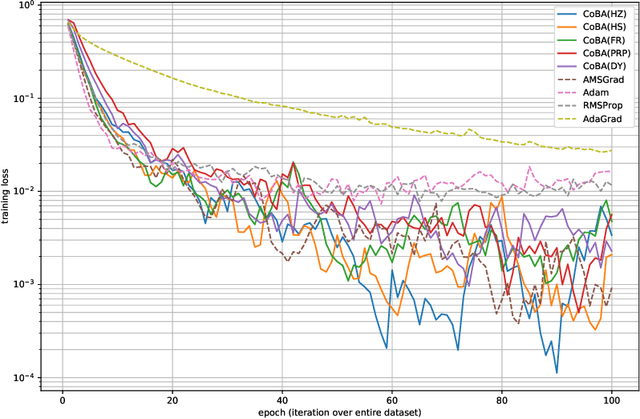
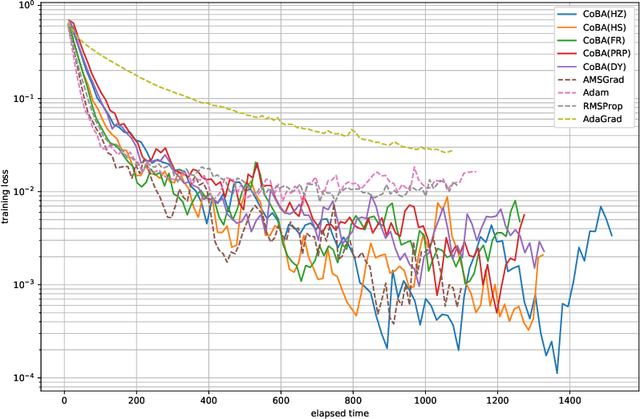
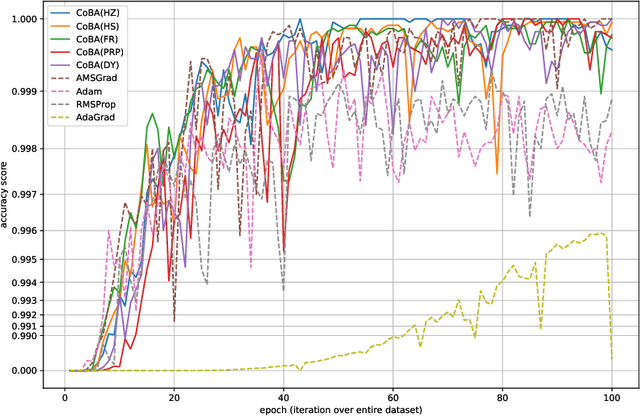
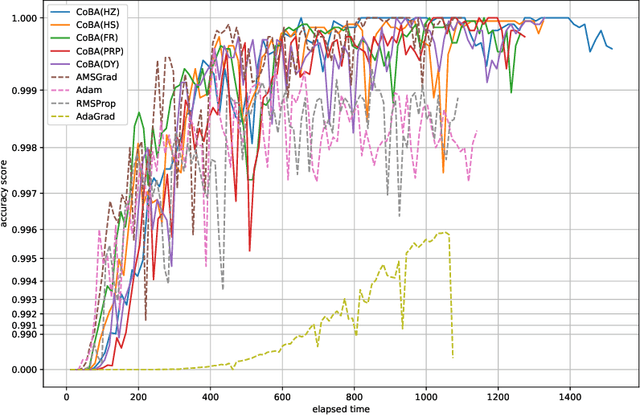
This paper proposes a conjugate-gradient-based Adam algorithm blending Adam with nonlinear conjugate gradient methods and shows its convergence analysis. Numerical experiments on text classification and image classification show that the proposed algorithm can train deep neural network models in fewer epochs than the existing adaptive stochastic optimization algorithms can.
Establishing an Evaluation Metric to Quantify Climate Change Image Realism
Oct 22, 2019

With success on controlled tasks, generative models are being increasingly applied to humanitarian applications [1,2]. In this paper, we focus on the evaluation of a conditional generative model that illustrates the consequences of climate change-induced flooding to encourage public interest and awareness on the issue. Because metrics for comparing the realism of different modes in a conditional generative model do not exist, we propose several automated and human-based methods for evaluation. To do this, we adapt several existing metrics, and assess the automated metrics against gold standard human evaluation. We find that using Fr\'echet Inception Distance (FID) with embeddings from an intermediary Inception-V3 layer that precedes the auxiliary classifier produces results most correlated with human realism. While insufficient alone to establish a human-correlated automatic evaluation metric, we believe this work begins to bridge the gap between human and automated generative evaluation procedures.
Self-Supervised GAN Compression
Jul 12, 2020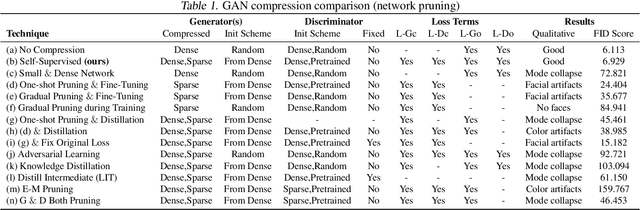

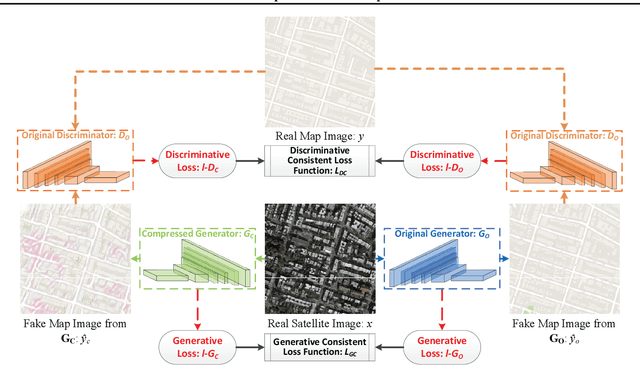
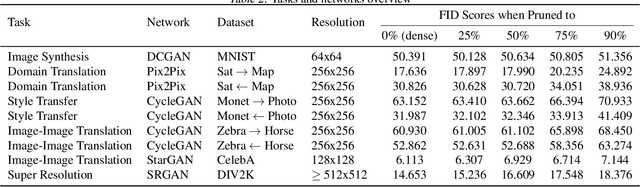
Deep learning's success has led to larger and larger models to handle more and more complex tasks; trained models can contain millions of parameters. These large models are compute- and memory-intensive, which makes it a challenge to deploy them with minimized latency, throughput, and storage requirements. Some model compression methods have been successfully applied to image classification and detection or language models, but there has been very little work compressing generative adversarial networks (GANs) performing complex tasks. In this paper, we show that a standard model compression technique, weight pruning, cannot be applied to GANs using existing methods. We then develop a self-supervised compression technique which uses the trained discriminator to supervise the training of a compressed generator. We show that this framework has a compelling performance to high degrees of sparsity, can be easily applied to new tasks and models, and enables meaningful comparisons between different pruning granularities.
SeCo: Exploring Sequence Supervision for Unsupervised Representation Learning
Aug 03, 2020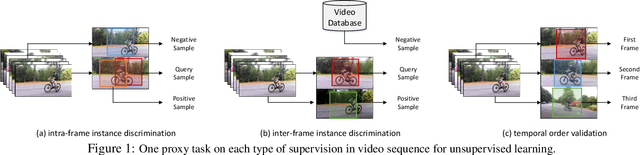
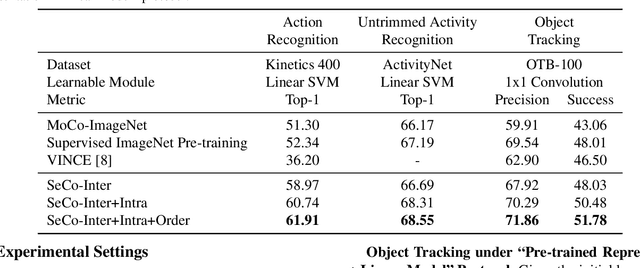
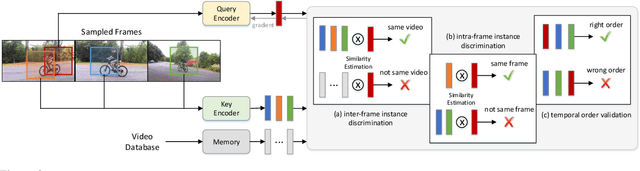
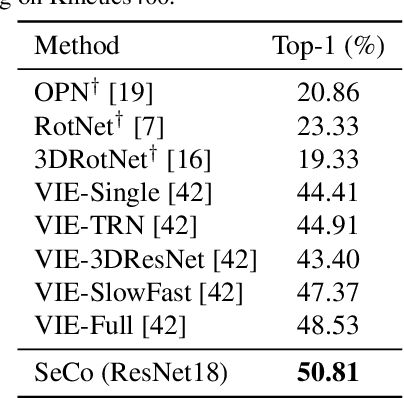
A steady momentum of innovations and breakthroughs has convincingly pushed the limits of unsupervised image representation learning. Compared to static 2D images, video has one more dimension (time). The inherent supervision existing in such sequential structure offers a fertile ground for building unsupervised learning models. In this paper, we compose a trilogy of exploring the basic and generic supervision in the sequence from spatial, spatiotemporal and sequential perspectives. We materialize the supervisory signals through determining whether a pair of samples is from one frame or from one video, and whether a triplet of samples is in the correct temporal order. We uniquely regard the signals as the foundation in contrastive learning and derive a particular form named Sequence Contrastive Learning (SeCo). SeCo shows superior results under the linear protocol on action recognition (Kinetics), untrimmed activity recognition (ActivityNet) and object tracking (OTB-100). More remarkably, SeCo demonstrates considerable improvements over recent unsupervised pre-training techniques, and leads the accuracy by 2.96% and 6.47% against fully-supervised ImageNet pre-training in action recognition task on UCF101 and HMDB51, respectively.
Including Images into Message Veracity Assessment in Social Media
Jul 20, 2020
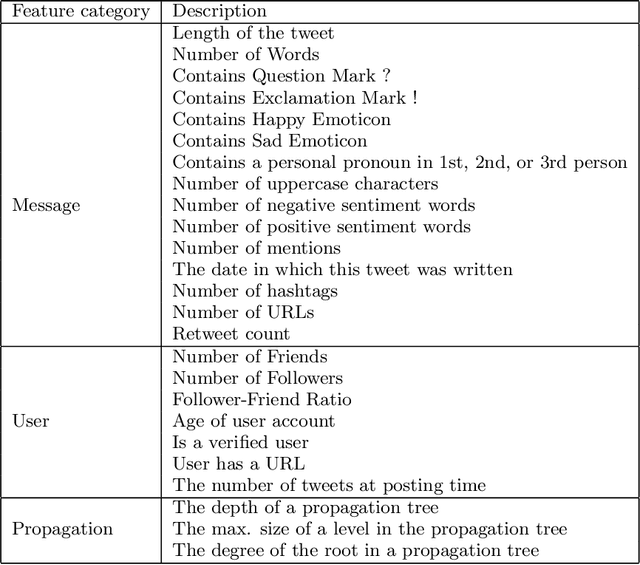
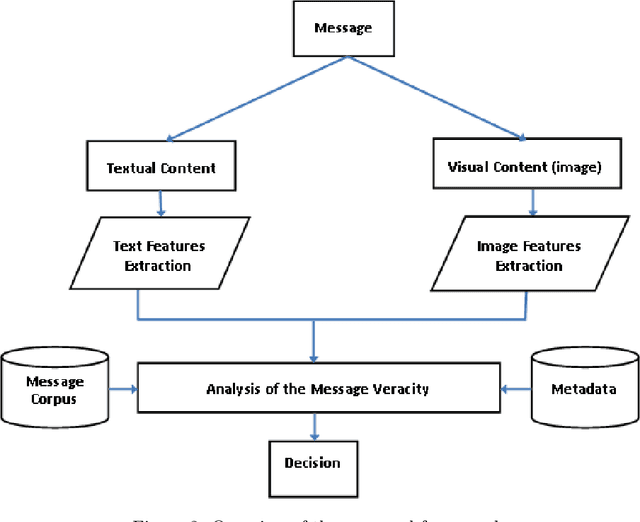

The extensive use of social media in the diffusion of information has also laid a fertile ground for the spread of rumors, which could significantly affect the credibility of social media. An ever-increasing number of users post news including, in addition to text, multimedia data such as images and videos. Yet, such multimedia content is easily editable due to the broad availability of simple and effective image and video processing tools. The problem of assessing the veracity of social network posts has attracted a lot of attention from researchers in recent years. However, almost all previous works have focused on analyzing textual contents to determine veracity, while visual contents, and more particularly images, remains ignored or little exploited in the literature. In this position paper, we propose a framework that explores two novel ways to assess the veracity of messages published on social networks by analyzing the credibility of both their textual and visual contents.
New Methods to Improve Large-Scale Microscopy Image Analysis with Prior Knowledge and Uncertainty
Aug 30, 2016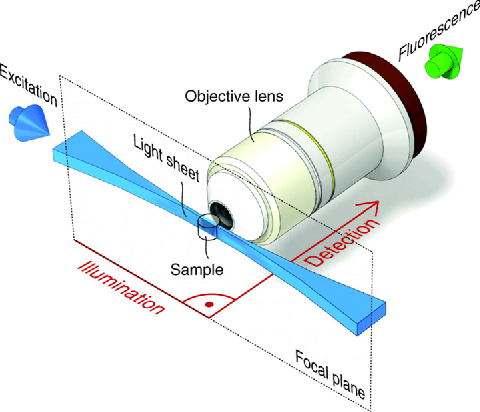
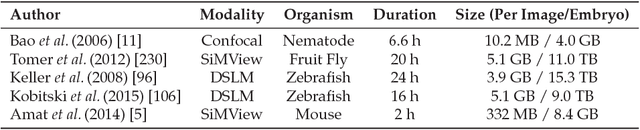


Multidimensional imaging techniques provide powerful ways to examine various kinds of scientific questions. The routinely produced datasets in the terabyte-range, however, can hardly be analyzed manually and require an extensive use of automated image analysis. The present thesis introduces a new concept for the estimation and propagation of uncertainty involved in image analysis operators and new segmentation algorithms that are suitable for terabyte-scale analyses of 3D+t microscopy images.
Frame-To-Frame Consistent Semantic Segmentation
Aug 03, 2020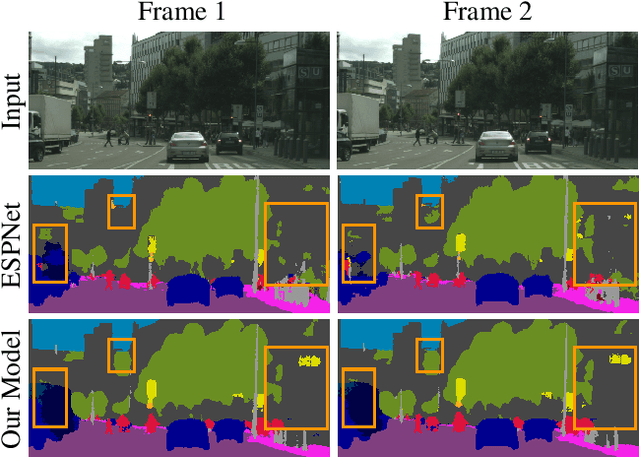
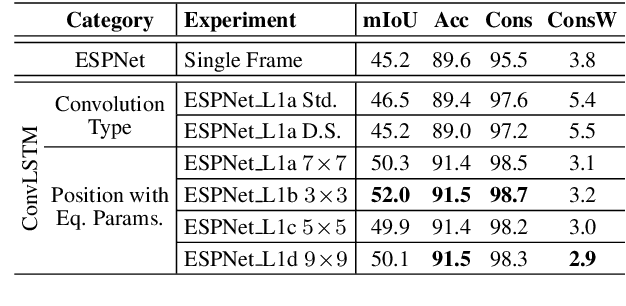
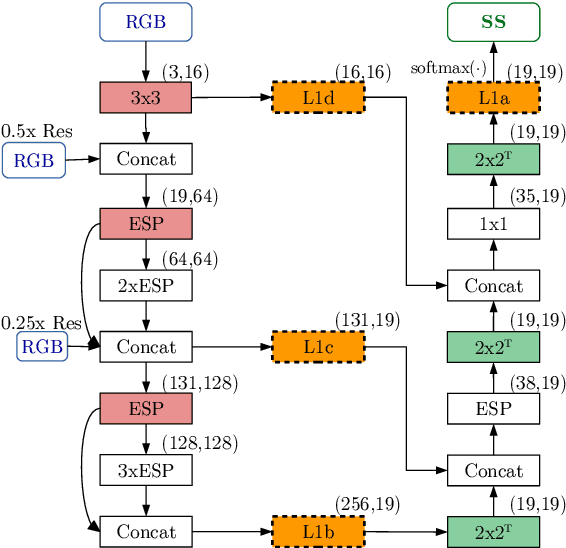
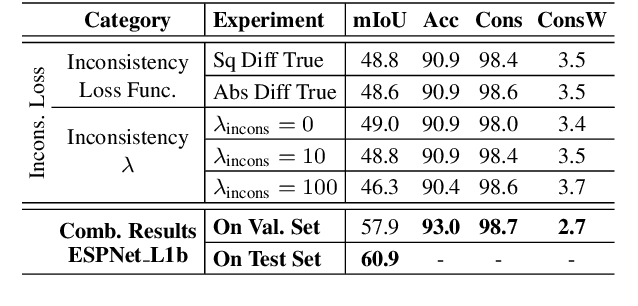
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020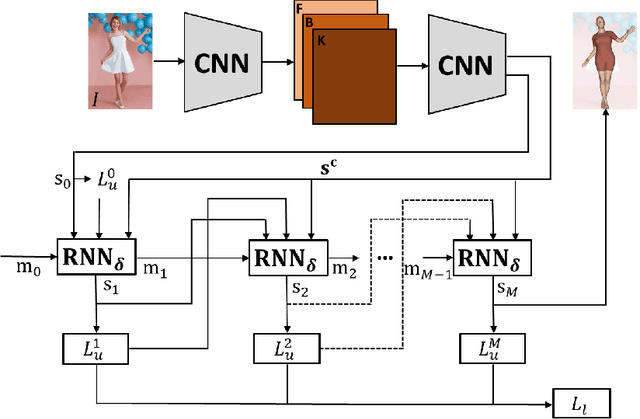
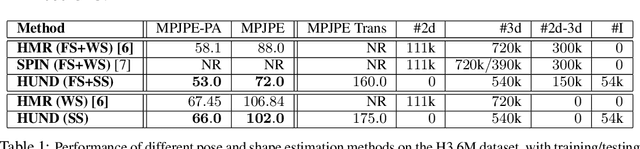

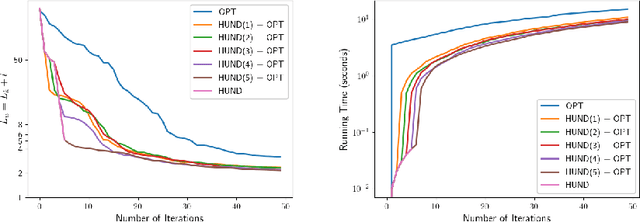
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
A Total Variation Denoising Method Based on Median Filter and Phase Consistency
Jan 01, 2020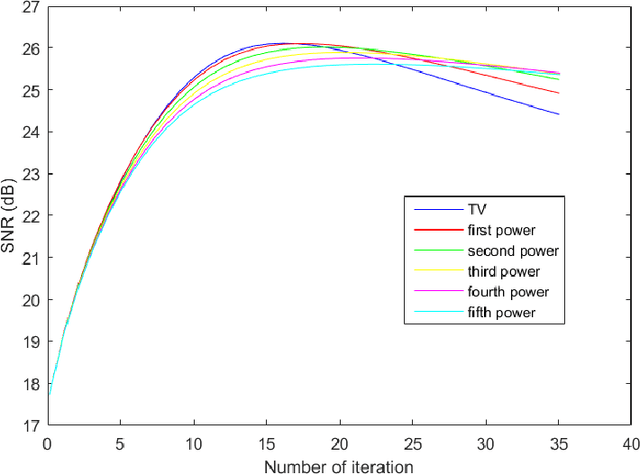

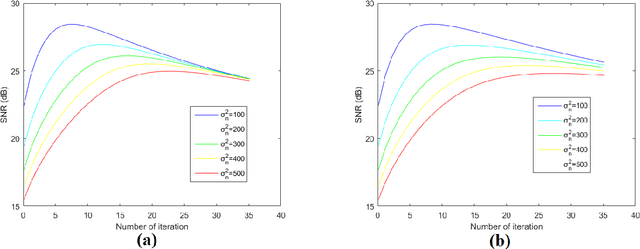

The total variation method is widely used in image noise suppression. However, this method is easy to cause the loss of image details, and it is also sensitive to parameters such as iteration time. In this work, the total variation method has been modified using a diffusion rate adjuster based on the phase congruency and a fusion filter of median filter and phase consistency boundary, which is called the MPC-TV method. Experimental results indicate that MPC-TV method is effective in noise suppression, especially for the removing of speckle noise, and it can also improve the robustness of iteration time of TV method on noise with different variance.