 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TENet: Triple Excitation Network for Video Salient Object Detection
Aug 30, 2020
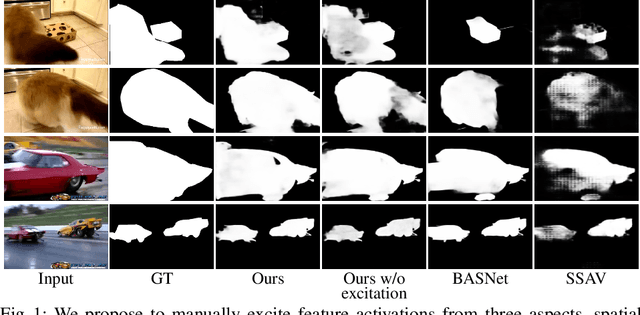
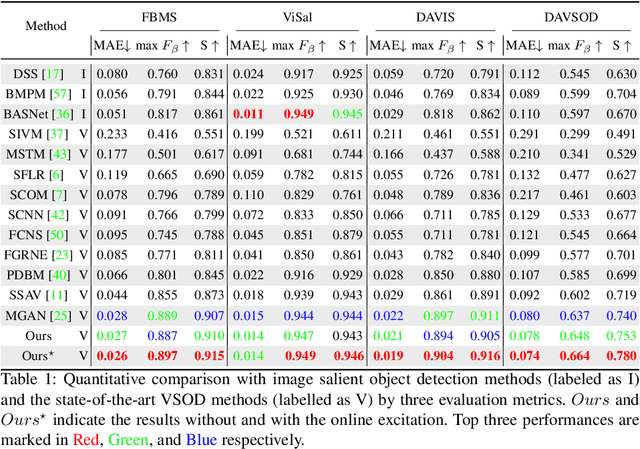
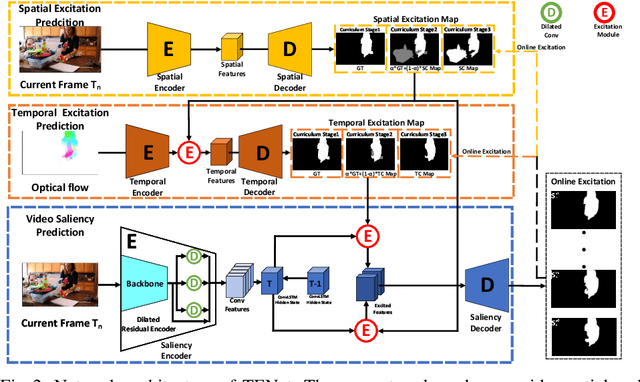
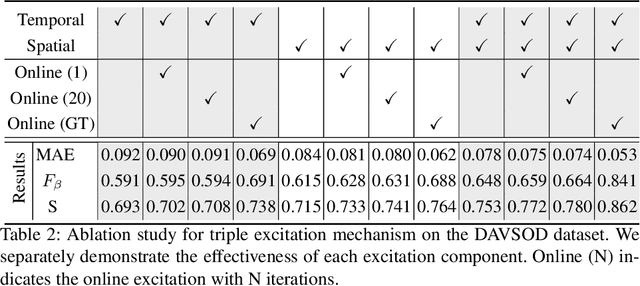
In this paper, we propose a simple yet effective approach, named Triple Excitation Network, to reinforce the training of video salient object detection (VSOD) from three aspects, spatial, temporal, and online excitations. These excitation mechanisms are designed following the spirit of curriculum learning and aim to reduce learning ambiguities at the beginning of training by selectively exciting feature activations using ground truth. Then we gradually reduce the weight of ground truth excitations by a curriculum rate and replace it by a curriculum complementary map for better and faster convergence. In particular, the spatial excitation strengthens feature activations for clear object boundaries, while the temporal excitation imposes motions to emphasize spatio-temporal salient regions. Spatial and temporal excitations can combat the saliency shifting problem and conflict between spatial and temporal features of VSOD. Furthermore, our semi-curriculum learning design enables the first online refinement strategy for VSOD, which allows exciting and boosting saliency responses during testing without re-training. The proposed triple excitations can easily plug in different VSOD methods. Extensive experiments show the effectiveness of all three excitation methods and the proposed method outperforms state-of-the-art image and video salient object detection methods.
Lightweight Photometric Stereo for Facial Details Recovery
Mar 27, 2020

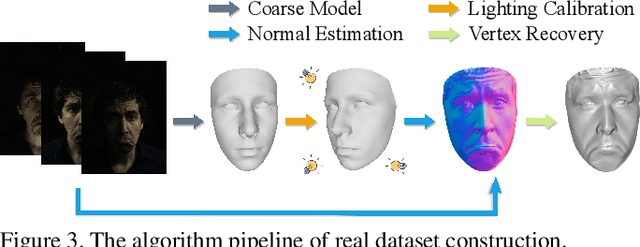
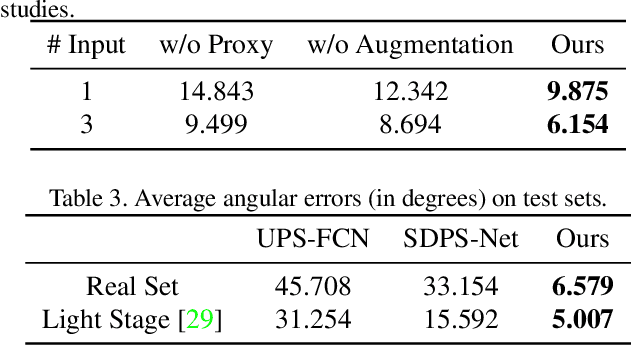
Recently, 3D face reconstruction from a single image has achieved great success with the help of deep learning and shape prior knowledge, but they often fail to produce accurate geometry details. On the other hand, photometric stereo methods can recover reliable geometry details, but require dense inputs and need to solve a complex optimization problem. In this paper, we present a lightweight strategy that only requires sparse inputs or even a single image to recover high-fidelity face shapes with images captured under near-field lights. To this end, we construct a dataset containing 84 different subjects with 29 expressions under 3 different lights. Data augmentation is applied to enrich the data in terms of diversity in identity, lighting, expression, etc. With this constructed dataset, we propose a novel neural network specially designed for photometric stereo based 3D face reconstruction. Extensive experiments and comparisons demonstrate that our method can generate high-quality reconstruction results with one to three facial images captured under near-field lights. Our full framework is available at https://github.com/Juyong/FacePSNet.
Adversarial Semantic Data Augmentation for Human Pose Estimation
Aug 03, 2020
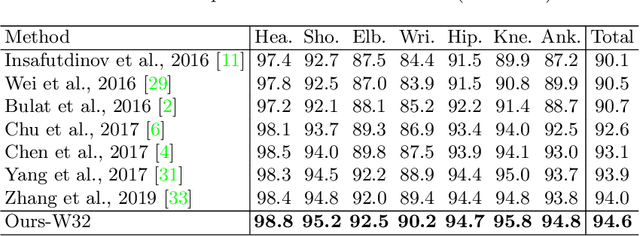
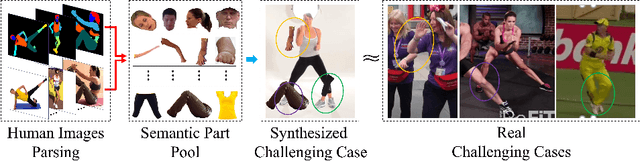
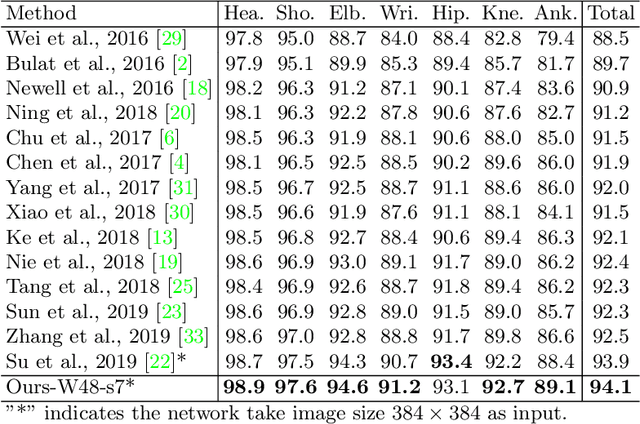
Human pose estimation is the task of localizing body keypoints from still images. The state-of-the-art methods suffer from insufficient examples of challenging cases such as symmetric appearance, heavy occlusion and nearby person. To enlarge the amounts of challenging cases, previous methods augmented images by cropping and pasting image patches with weak semantics, which leads to unrealistic appearance and limited diversity. We instead propose Semantic Data Augmentation (SDA), a method that augments images by pasting segmented body parts with various semantic granularity. Furthermore, we propose Adversarial Semantic Data Augmentation (ASDA), which exploits a generative network to dynamiclly predict tailored pasting configuration. Given off-the-shelf pose estimation network as discriminator, the generator seeks the most confusing transformation to increase the loss of the discriminator while the discriminator takes the generated sample as input and learns from it. The whole pipeline is optimized in an adversarial manner. State-of-the-art results are achieved on challenging benchmarks.
Custom Extended Sobel Filters
Sep 30, 2019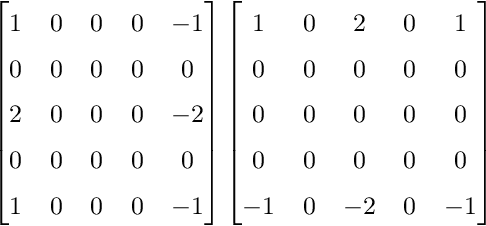
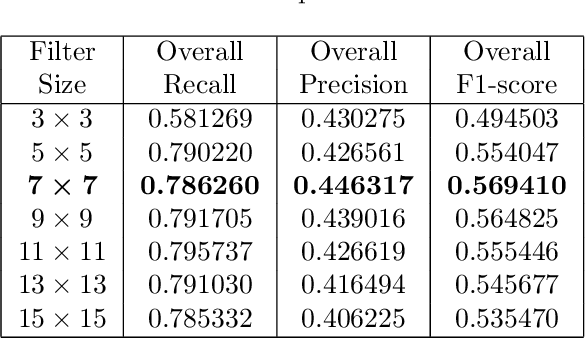

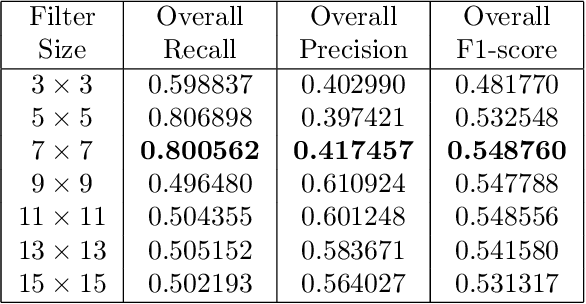
Edge detection is widely and fundamental feature used in various algorithms in computer vision to determine the edges in an image. The edge detection algorithm is used to determine the edges in an image which are further used by various algorithms from line detection to machine learning that can determine objects based on their contour. Inspired by new convolution techniques in machine learning we discuss here the idea of extending the standard Sobel kernels, which are used to compute the gradient of an image in order to find its edges. We compare the result of our custom extended filters with the results of the standard Sobel filter and other edge detection filters using different image sets and algorithms. We present statistical results regarding the custom extended Sobel filters improvements.
Development of a Machine-Learning System to Classify Lung CT Scan Images into Normal/COVID-19 Class
Apr 24, 2020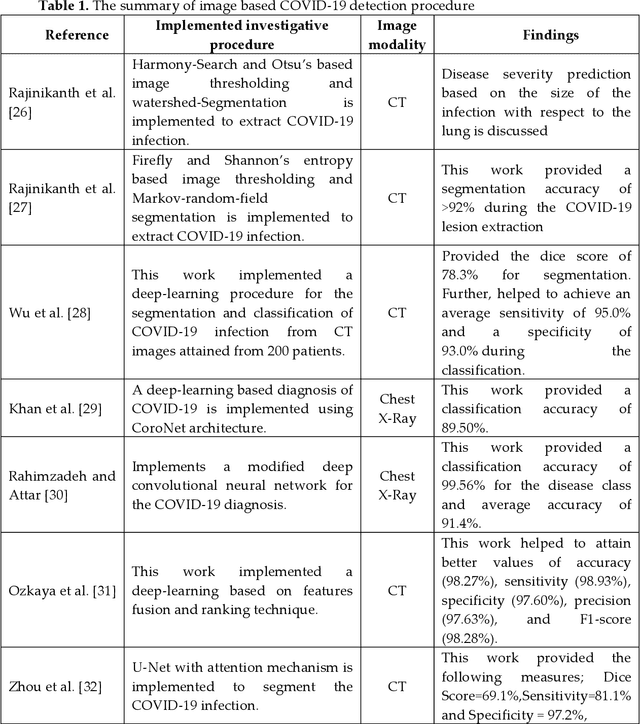
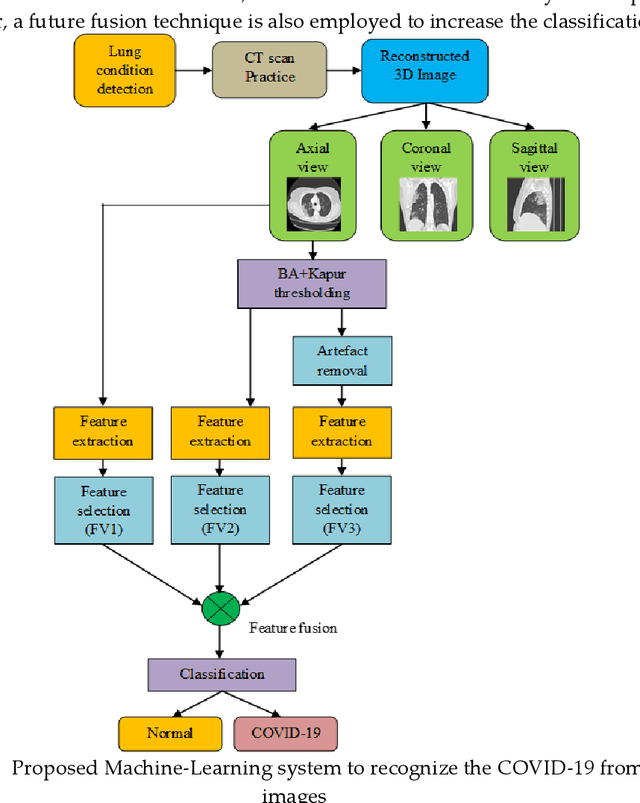
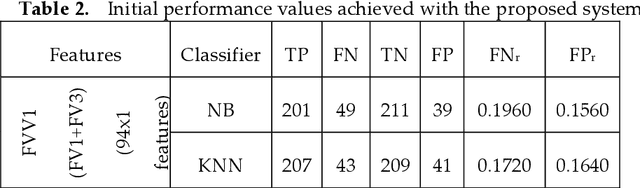
Recently, the lung infection due to Coronavirus Disease (COVID-19) affected a large human group worldwide and the assessment of the infection rate in the lung is essential for treatment planning. This research aims to propose a Machine-Learning-System (MLS) to detect the COVID-19 infection using the CT scan Slices (CTS). This MLS implements a sequence of methods, such as multi-thresholding, image separation using threshold filter, feature-extraction, feature-selection, feature-fusion and classification. The initial part implements the Chaotic-Bat-Algorithm and Kapur's Entropy (CBA+KE) thresholding to enhance the CTS. The threshold filter separates the image into two segments based on a chosen threshold 'Th'. The texture features of these images are extracted, refined and selected using the chosen procedures. Finally, a two-class classifier system is implemented to categorize the chosen CTS (n=500 with a pixel dimension of 512x512x1) into normal/COVID-19 group. In this work, the classifiers, such as Naive Bayes (NB), k-Nearest Neighbors (KNN), Decision Tree (DT), Random Forest (RF) and Support Vector Machine with linear kernel (SVM) are implemented and the classification task is performed using various feature vectors. The experimental outcome of the SVM with Fused-Feature-Vector (FFV) helped to attain a detection accuracy of 89.80%.
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
Oct 27, 2020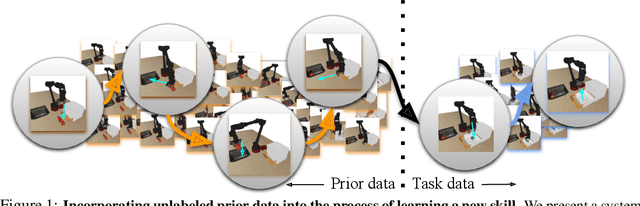
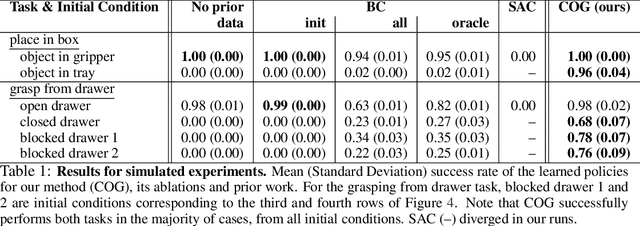
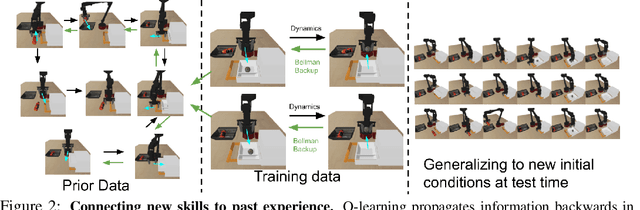

Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: https://sites.google.com/view/cog-rl
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Nov 16, 2017
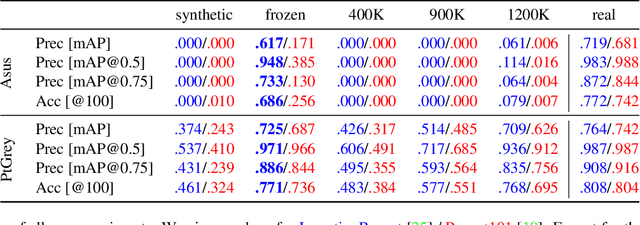
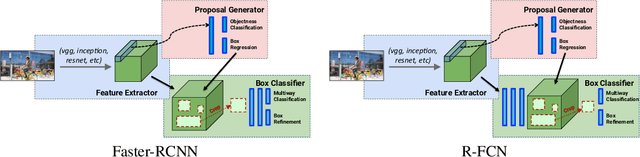
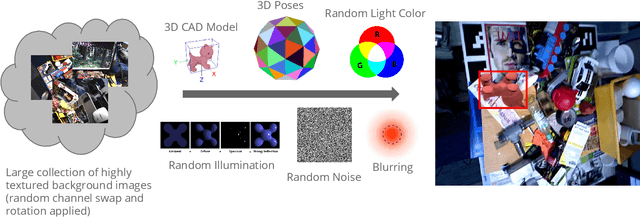
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.
Socializing the Semantic Gap: A Comparative Survey on Image Tag Assignment, Refinement and Retrieval
Mar 23, 2016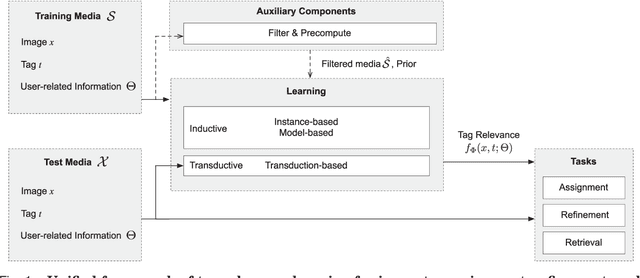
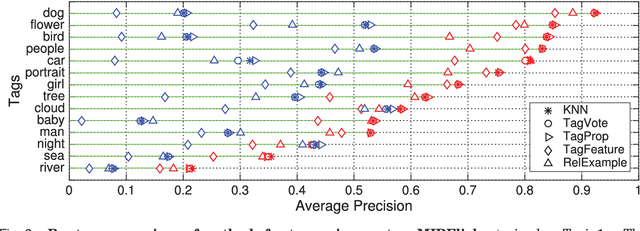
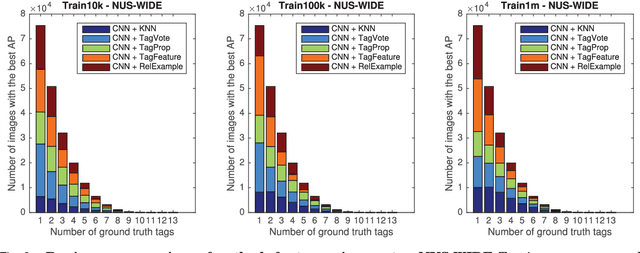
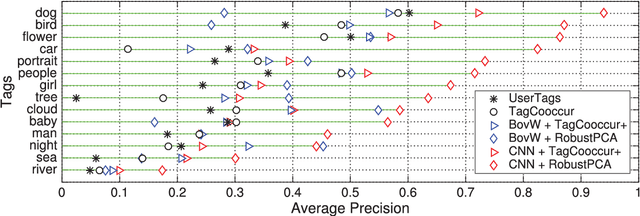
Where previous reviews on content-based image retrieval emphasize on what can be seen in an image to bridge the semantic gap, this survey considers what people tag about an image. A comprehensive treatise of three closely linked problems, i.e., image tag assignment, refinement, and tag-based image retrieval is presented. While existing works vary in terms of their targeted tasks and methodology, they rely on the key functionality of tag relevance, i.e. estimating the relevance of a specific tag with respect to the visual content of a given image and its social context. By analyzing what information a specific method exploits to construct its tag relevance function and how such information is exploited, this paper introduces a taxonomy to structure the growing literature, understand the ingredients of the main works, clarify their connections and difference, and recognize their merits and limitations. For a head-to-head comparison between the state-of-the-art, a new experimental protocol is presented, with training sets containing 10k, 100k and 1m images and an evaluation on three test sets, contributed by various research groups. Eleven representative works are implemented and evaluated. Putting all this together, the survey aims to provide an overview of the past and foster progress for the near future.
* to appear in ACM Computing Surveys
The Rate-Distortion-Accuracy Tradeoff: JPEG Case Study
Aug 03, 2020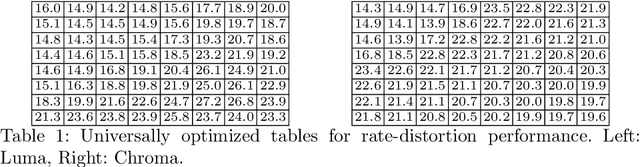
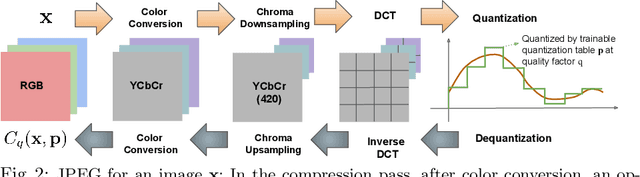
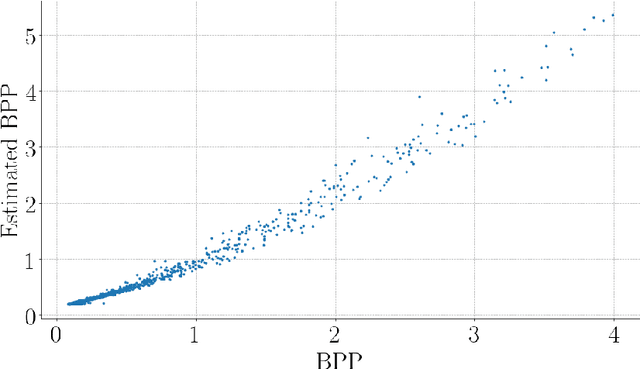
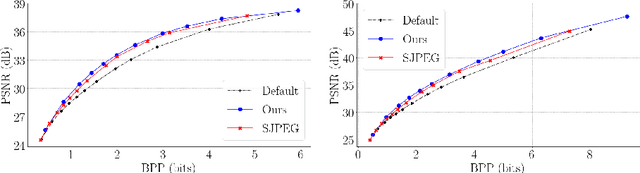
Handling digital images is almost always accompanied by a lossy compression in order to facilitate efficient transmission and storage. This introduces an unavoidable tension between the allocated bit-budget (rate) and the faithfulness of the resulting image to the original one (distortion). An additional complicating consideration is the effect of the compression on recognition performance by given classifiers (accuracy). This work aims to explore this rate-distortion-accuracy tradeoff. As a case study, we focus on the design of the quantization tables in the JPEG compression standard. We offer a novel optimal tuning of these tables via continuous optimization, leveraging a differential implementation of both the JPEG encoder-decoder and an entropy estimator. This enables us to offer a unified framework that considers the interplay between rate, distortion and classification accuracy. In all these fronts, we report a substantial boost in performance by a simple and easily implemented modification of these tables.
HERS: Homomorphically Encrypted Representation Search
Mar 27, 2020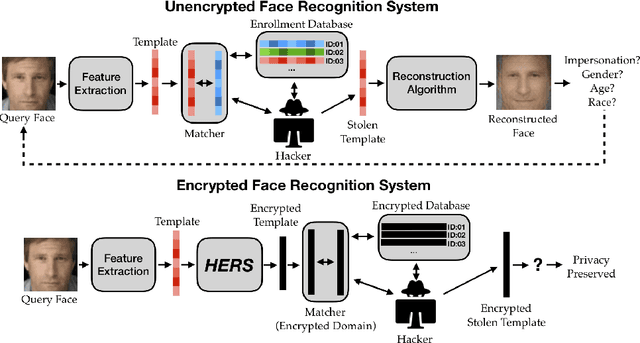
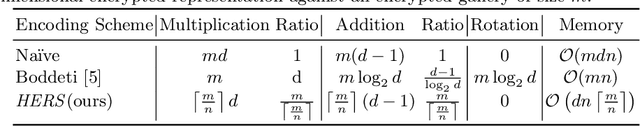
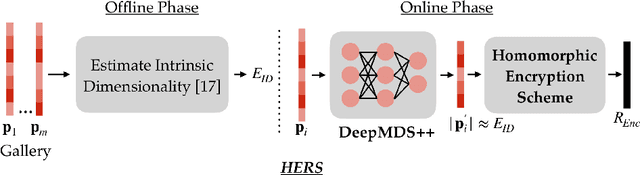

We present a method to search for a probe (or query) image representation against a large gallery in the encrypted domain. We require that the probe and gallery images be represented in terms of a fixed-length representation, which is typical for representations obtained from learned networks. Our encryption scheme is agnostic to how the fixed-length representation is obtained and can, therefore, be applied to any fixed-length representation in any application domain. Our method, dubbed HERS (Homomorphically Encrypted Representation Search), operates by (i) compressing the representation towards its estimated intrinsic dimensionality, (ii) encrypting the compressed representation using the proposed fully homomorphic encryption scheme, and (iii) searching against a gallery of encrypted representations directly in the encrypted domain, without decrypting them, and with minimal loss of accuracy. Numerical results on large galleries of face, fingerprint, and object datasets such as ImageNet show that, for the first time, accurate and fast image search within the encrypted domain is feasible at scale (296 seconds; 46x speedup over state-of-the-art for face search against a background of 1 million).