 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Schizophrenia-mimicking layers outperform conventional neural network layers
Sep 23, 2020

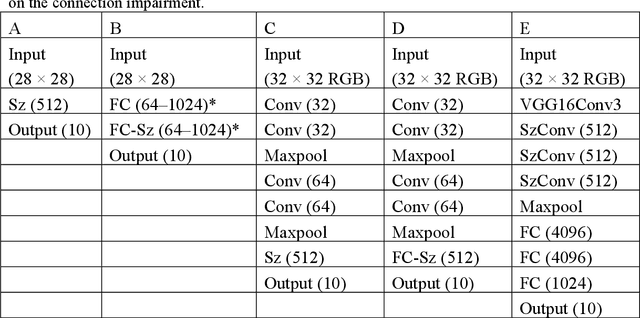
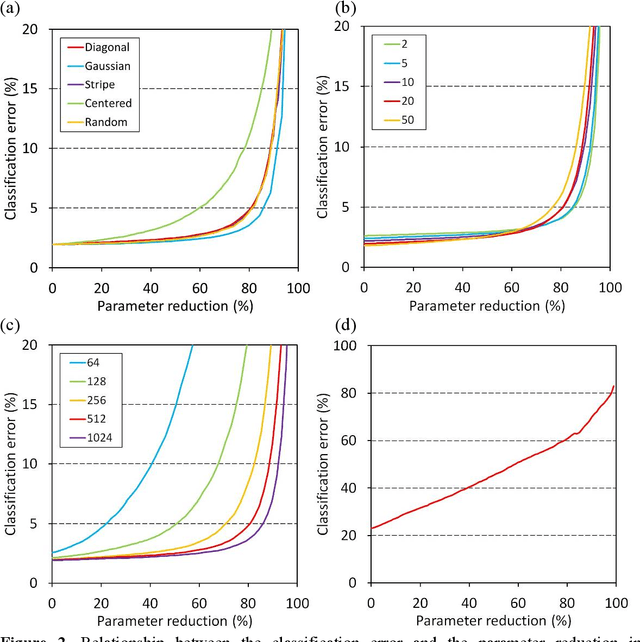
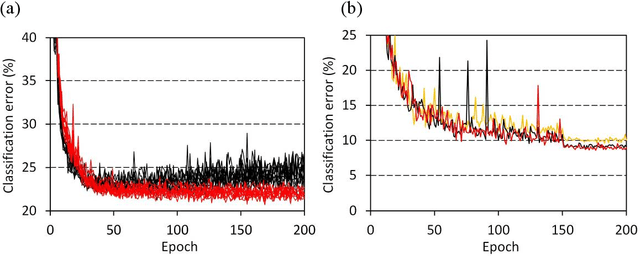
We have reported nanometer-scale three-dimensional studies of brain networks of schizophrenia cases and found that their neurites are thin and tortuous compared to healthy controls. This suggests that connections between distal neurons are impaired in microcircuits of the schizophrenia cases. In this study, we applied this biological findings to designing schizophrenia-mimicking artificial neural network to simulate the connection impairment in the disorder. Neural networks having the schizophrenia connection layer in place of fully connected layer were subjected to image classification tasks using MNIST and CIFAR-10 datasets. The obtained results revealed that the schizophrenia connection layer is tolerant to overfitting and outperforms fully connected layer. Schizophrenia-mimicking convolution layer was also tested with the VGG configuration, showing that 60% of kernel weights of the last convolution layer can be eliminated while keeping competitive performance. Schizophrenia-mimicking layers can be used instead of fully-connected or convolution layers without any change in the network configuration and training procedures, hence the outperformance of the schizophrenia-mimicking layer is easily incorporated in neural networks. The results of this study indicate that the connection impairment in schizophrenia is not a burden to the brain, but has some functional roles to attain a better brain performance. We suggest that the seemingly neuropathological alterations observed in schizophrenia have been rationally implemented in our brain during the process of biological evolution.
Explainable Deep CNNs for MRI-Based Diagnosis of Alzheimer's Disease
Apr 25, 2020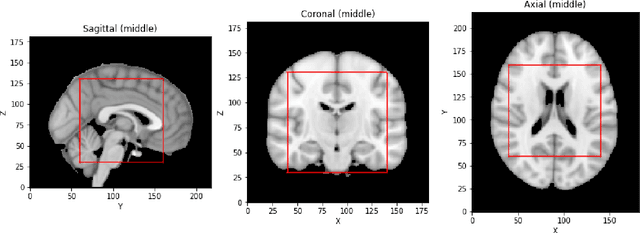
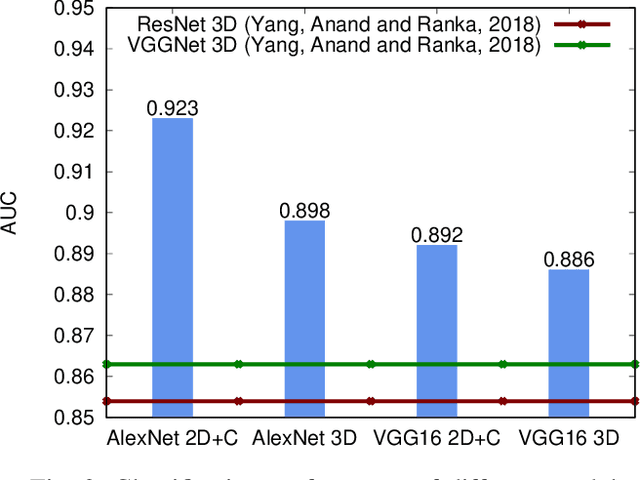
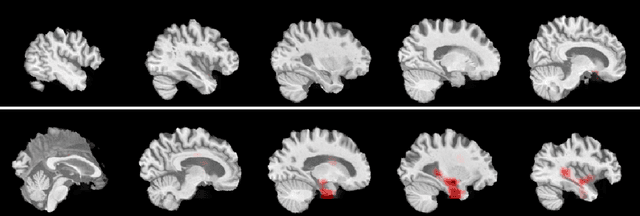
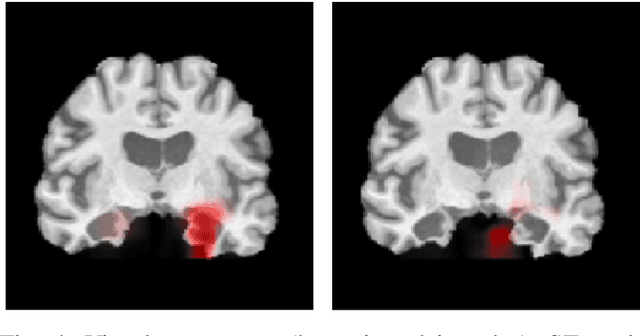
Deep Convolutional Neural Networks (CNNs) are becoming prominent models for semi-automated diagnosis of Alzheimer's Disease (AD) using brain Magnetic Resonance Imaging (MRI). Although being highly accurate, deep CNN models lack transparency and interpretability, precluding adequate clinical reasoning and not complying with most current regulatory demands. One popular choice for explaining deep image models is occluding regions of the image to isolate their influence on the prediction. However, existing methods for occluding patches of brain scans generate images outside the distribution to which the model was trained for, thus leading to unreliable explanations. In this paper, we propose an alternative explanation method that is specifically designed for the brain scan task. Our method, which we refer to as Swap Test, produces heatmaps that depict the areas of the brain that are most indicative of AD, providing interpretability for the model's decisions in a format understandable to clinicians. Experimental results using an axiomatic evaluation show that the proposed method is more suitable for explaining the diagnosis of AD using MRI while the opposite trend was observed when using a typical occlusion test. Therefore, we believe our method may address the inherent black-box nature of deep neural networks that are capable of diagnosing AD.
Flood severity mapping from Volunteered Geographic Information by interpreting water level from images containing people: a case study of Hurricane Harvey
Jun 21, 2020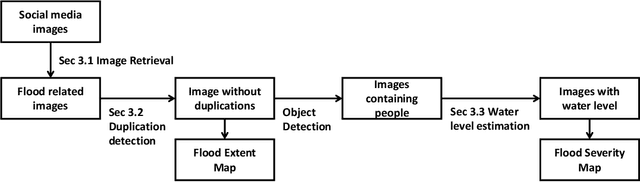

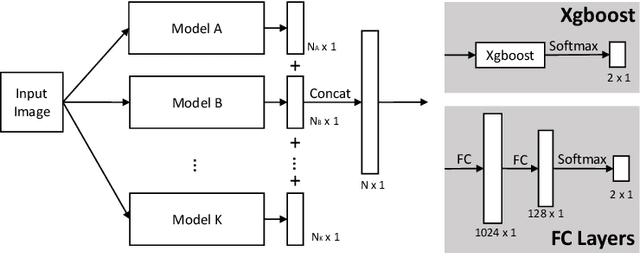
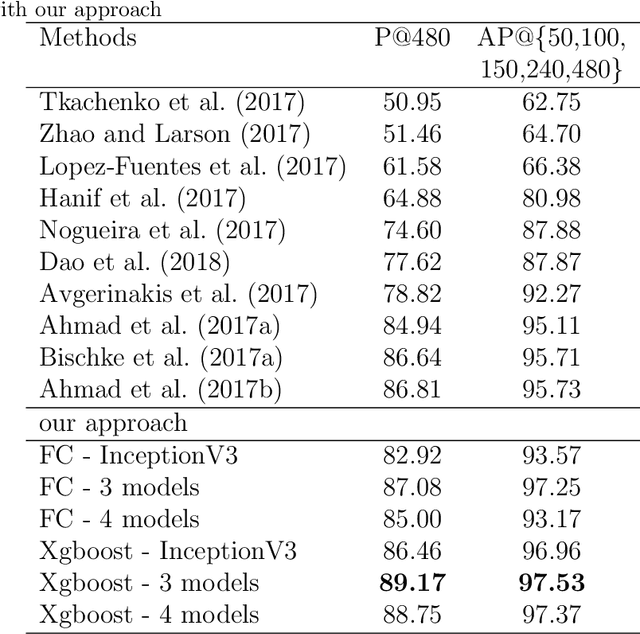
With increasing urbanization, in recent years there has been a growing interest and need in monitoring and analyzing urban flood events. Social media, as a new data source, can provide real-time information for flood monitoring. The social media posts with locations are often referred to as Volunteered Geographic Information (VGI), which can reveal the spatial pattern of such events. Since more images are shared on social media than ever before, recent research focused on the extraction of flood-related posts by analyzing images in addition to texts. Apart from merely classifying posts as flood relevant or not, more detailed information, e.g. the flood severity, can also be extracted based on image interpretation. However, it has been less tackled and has not yet been applied for flood severity mapping. In this paper, we propose a novel three-step pipeline method to extract and map flood severity information. First, flood relevant images are retrieved with the help of pre-trained convolutional neural networks as feature extractors. Second, the images containing people are further classified into four severity levels by observing the relationship between body parts and their partial inundation, i.e. images are classified according to the water level with respect to different body parts, namely ankle, knee, hip, and chest. Lastly, locations of the Tweets are used for generating a map of estimated flood extent and severity. This pipeline was applied to an image dataset collected during Hurricane Harvey in 2017, as a proof of concept. The results show that VGI can be used as a supplement to remote sensing observations for flood extent mapping and is beneficial, especially for urban areas, where the infrastructure is often occluding water. Based on the extracted water level information, an integrated overview of flood severity can be provided for the early stages of emergency response.
Attention Correctness in Neural Image Captioning
Nov 23, 2016
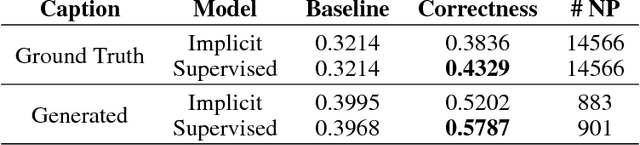
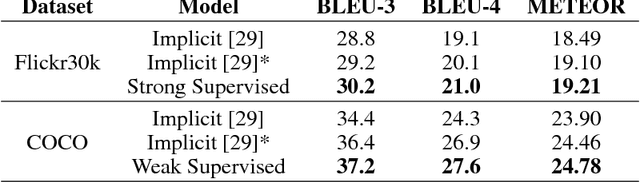

Attention mechanisms have recently been introduced in deep learning for various tasks in natural language processing and computer vision. But despite their popularity, the "correctness" of the implicitly-learned attention maps has only been assessed qualitatively by visualization of several examples. In this paper we focus on evaluating and improving the correctness of attention in neural image captioning models. Specifically, we propose a quantitative evaluation metric for the consistency between the generated attention maps and human annotations, using recently released datasets with alignment between regions in images and entities in captions. We then propose novel models with different levels of explicit supervision for learning attention maps during training. The supervision can be strong when alignment between regions and caption entities are available, or weak when only object segments and categories are provided. We show on the popular Flickr30k and COCO datasets that introducing supervision of attention maps during training solidly improves both attention correctness and caption quality, showing the promise of making machine perception more human-like.
Music SketchNet: Controllable Music Generation via Factorized Representations of Pitch and Rhythm
Aug 04, 2020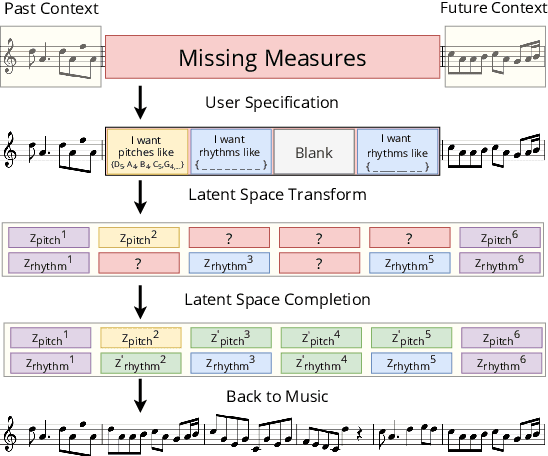
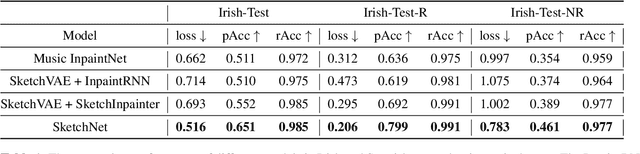
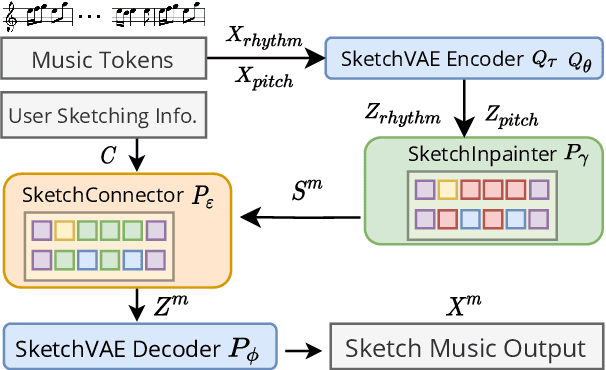
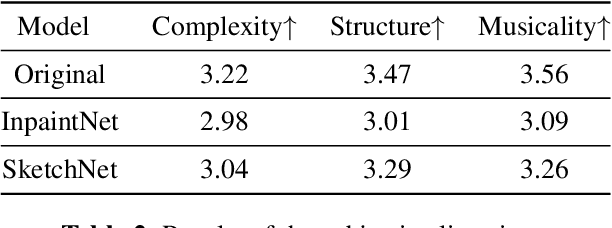
Drawing an analogy with automatic image completion systems, we propose Music SketchNet, a neural network framework that allows users to specify partial musical ideas guiding automatic music generation. We focus on generating the missing measures in incomplete monophonic musical pieces, conditioned on surrounding context, and optionally guided by user-specified pitch and rhythm snippets. First, we introduce SketchVAE, a novel variational autoencoder that explicitly factorizes rhythm and pitch contour to form the basis of our proposed model. Then we introduce two discriminative architectures, SketchInpainter and SketchConnector, that in conjunction perform the guided music completion, filling in representations for the missing measures conditioned on surrounding context and user-specified snippets. We evaluate SketchNet on a standard dataset of Irish folk music and compare with models from recent works. When used for music completion, our approach outperforms the state-of-the-art both in terms of objective metrics and subjective listening tests. Finally, we demonstrate that our model can successfully incorporate user-specified snippets during the generation process.
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 24, 2020
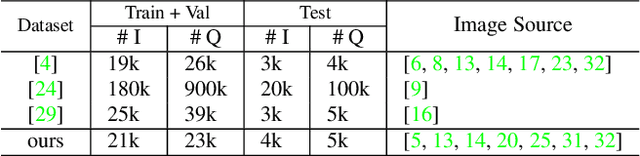

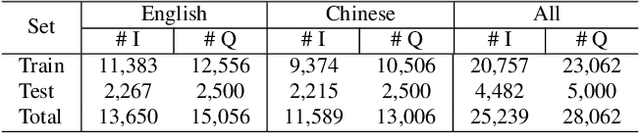
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
Hierarchical Deep Convolutional Neural Networks for Multi-category Diagnosis of Gastrointestinal Disorders on Histopathological Images
May 08, 2020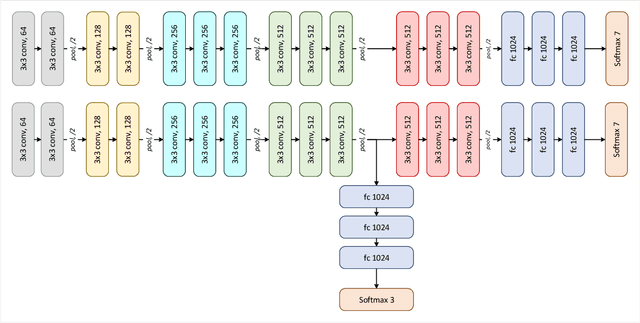
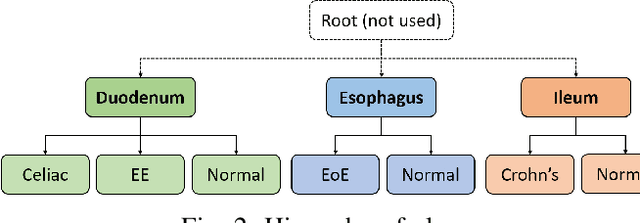
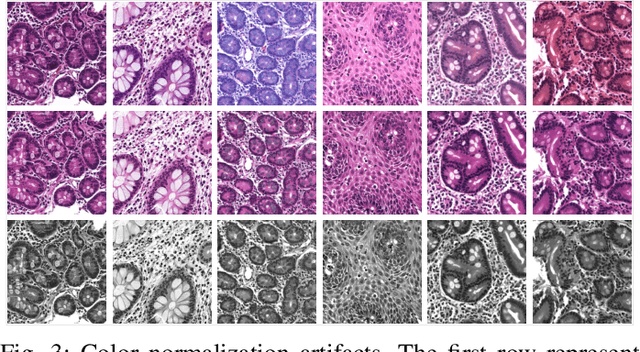
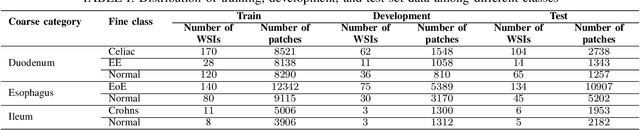
Deep convolutional neural networks (CNNs) have been successful for a wide range of computer vision tasks including image classification. A specific area of application lies in digital pathology for pattern recognition in tissue-based diagnosis of gastrointestinal (GI) diseases. This domain can utilize CNNs to translate histopathological images into precise diagnostics. This is challenging since these complex biopsies are heterogeneous and require multiple levels of assessment. This is mainly due to structural similarities in different parts of the GI tract and shared features among different gut diseases. Addressing this problem with a flat model which assumes all classes (parts of the gut and their diseases) are equally difficult to distinguish leads to an inadequate assessment of each class. Since hierarchical model restricts classification error to each sub-class, it leads to a more informative model compared to a flat model. In this paper we propose to apply hierarchical classification of biopsy images from different parts of the GI tract and the receptive diseases within each. We embedded a class hierarchy into the plain VGGNet to take advantage of the hierarchical structure of its layers. The proposed model was evaluated using an independent set of image patches from 373 whole slide images. The results indicate that hierarchical model can achieve better results compared to the flat model for multi-category diagnosis of GI disorders using histopathological images.
Medical Deep Learning -- A systematic Meta-Review
Oct 28, 2020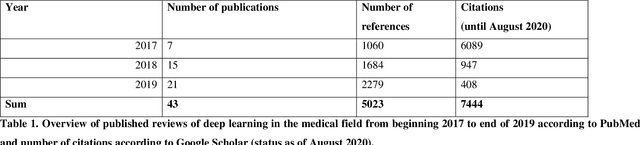
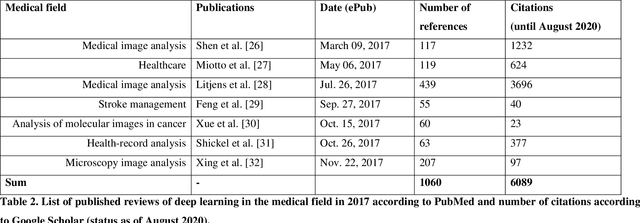
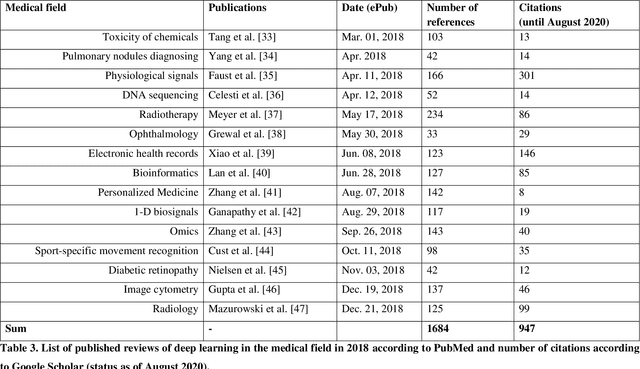

Deep learning had a remarkable impact in different scientific disciplines during the last years. This was demonstrated in numerous tasks, where deep learning algorithms were able to outperform the state-of-art methods, also in image processing and analysis. Moreover, deep learning delivers good results in tasks like autonomous driving, which could not have been performed automatically before. There are even applications where deep learning outperformed humans, like object recognition or games. Another field in which this development is showing a huge potential is the medical domain. With the collection of large quantities of patient records and data, and a trend towards personalized treatments, there is a great need for an automatic and reliable processing and analysis of this information. Patient data is not only collected in clinical centres, like hospitals, but it relates also to data coming from general practitioners, healthcare smartphone apps or online websites, just to name a few. This trend resulted in new, massive research efforts during the last years. In Q2/2020, the search engine PubMed returns already over 11.000 results for the search term $'$deep learning$'$, and around 90% of these publications are from the last three years. Hence, a complete overview of the field of $'$medical deep learning$'$ is almost impossible to obtain and getting a full overview of medical sub-fields gets increasingly more difficult. Nevertheless, several review and survey articles about medical deep learning have been presented within the last years. They focused, in general, on specific medical scenarios, like the analysis of medical images containing specific pathologies. With these surveys as foundation, the aim of this contribution is to provide a very first high-level, systematic meta-review of medical deep learning surveys.
Domain Generalizer: A Few-shot Meta Learning Framework for Domain Generalization in Medical Imaging
Aug 18, 2020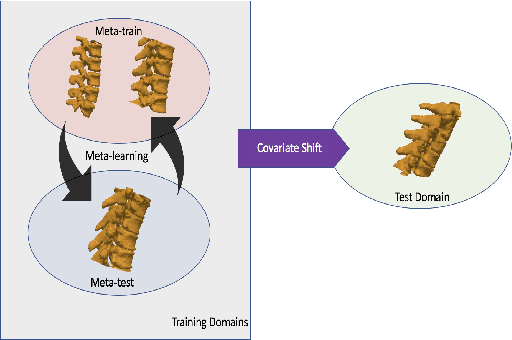


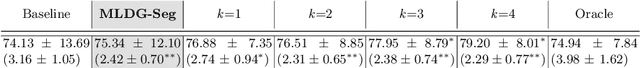
Deep learning models perform best when tested on target (test) data domains whose distribution is similar to the set of source (train) domains. However, model generalization can be hindered when there is significant difference in the underlying statistics between the target and source domains. In this work, we adapt a domain generalization method based on a model-agnostic meta-learning framework to biomedical imaging. The method learns a domain-agnostic feature representation to improve generalization of models to the unseen test distribution. The method can be used for any imaging task, as it does not depend on the underlying model architecture. We validate the approach through a computed tomography (CT) vertebrae segmentation task across healthy and pathological cases on three datasets. Next, we employ few-shot learning, i.e. training the generalized model using very few examples from the unseen domain, to quickly adapt the model to new unseen data distribution. Our results suggest that the method could help generalize models across different medical centers, image acquisition protocols, anatomies, different regions in a given scan, healthy and diseased populations across varied imaging modalities.
Deep Residual Mixture Models
Jun 22, 2020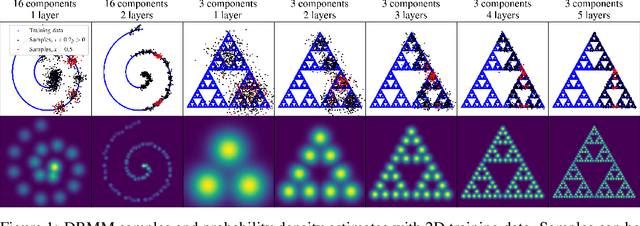
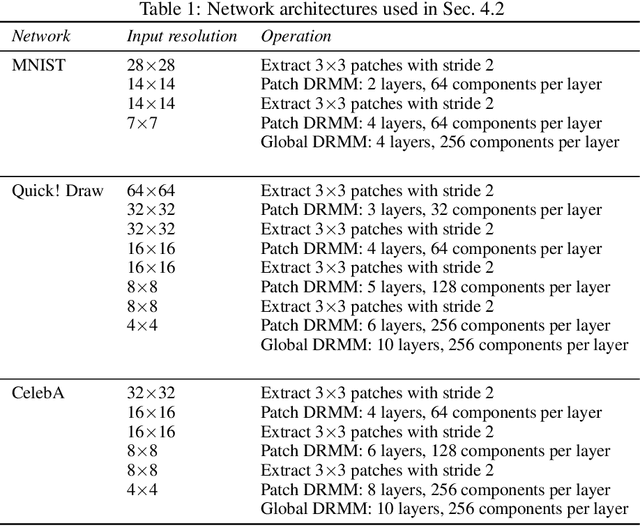
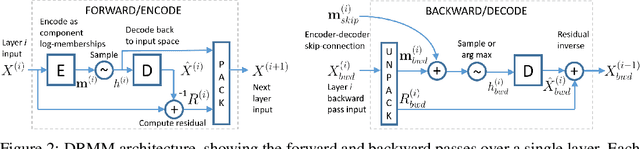

We propose Deep Residual Mixture Models (DRMMs) which share the many desirable properties of Gaussian Mixture Models (GMMs), but with a crucial benefit: The modeling capacity of a DRMM can grow exponentially with depth, while the number of model parameters only grows quadratically. DRMMs allow for extremely flexible conditional sampling, as the conditioning variables can be freely selected without re-training the model, and it is easy to combine the sampling with priors and (in)equality constraints. DRMMs should be applicable where GMMs are traditionally used, but as demonstrated in our experiments, DRMMs scale better to complex, high-dimensional data. We demonstrate the approach in constrained multi-limb inverse kinematics and image completion.