 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Sampling with Quasicrystals
Jul 21, 2009
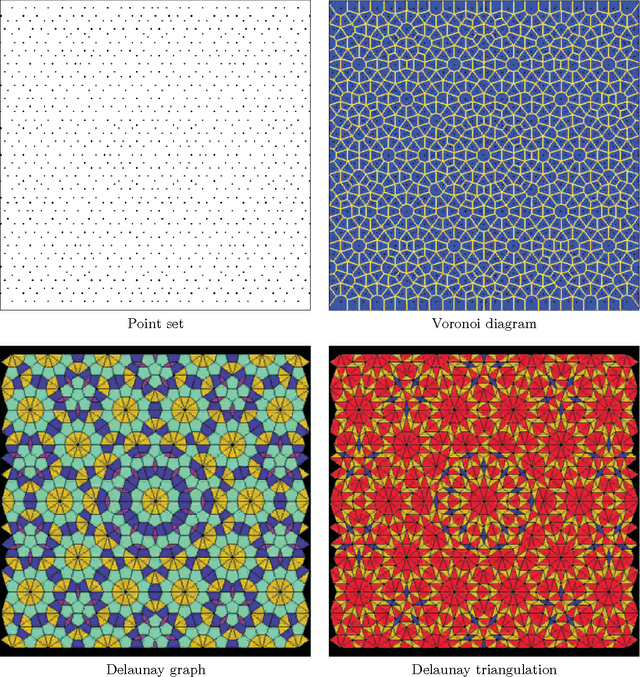
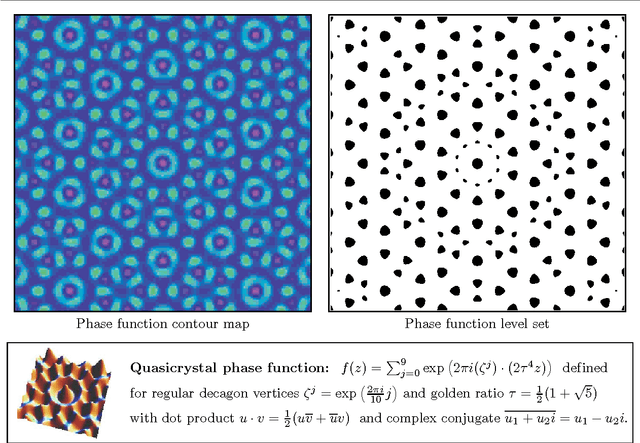
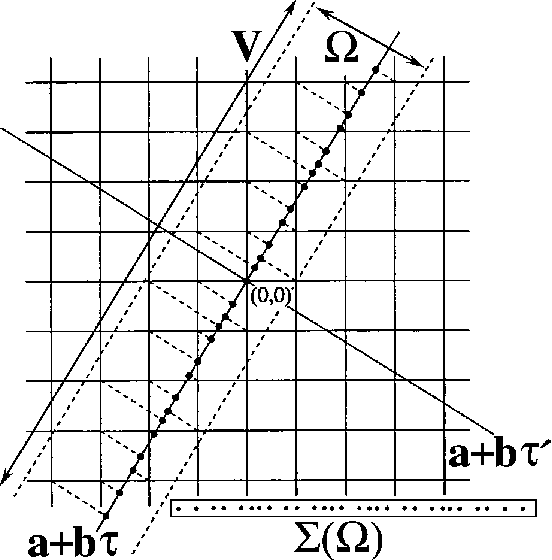

We investigate the use of quasicrystals in image sampling. Quasicrystals produce space-filling, non-periodic point sets that are uniformly discrete and relatively dense, thereby ensuring the sample sites are evenly spread out throughout the sampled image. Their self-similar structure can be attractive for creating sampling patterns endowed with a decorative symmetry. We present a brief general overview of the algebraic theory of cut-and-project quasicrystals based on the geometry of the golden ratio. To assess the practical utility of quasicrystal sampling, we evaluate the visual effects of a variety of non-adaptive image sampling strategies on photorealistic image reconstruction and non-photorealistic image rendering used in multiresolution image representations. For computer visualization of point sets used in image sampling, we introduce a mosaic rendering technique.
* For a full resolution version of this paper, along with supplementary materials, please visit at http://www.Eyemaginary.com/Portfolio/Publications.html
Unsupervised Shape and Pose Disentanglement for 3D Meshes
Jul 22, 2020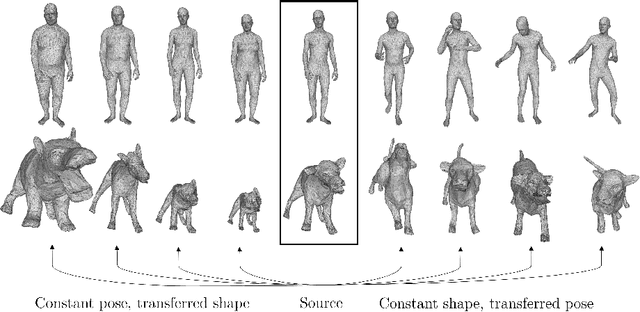
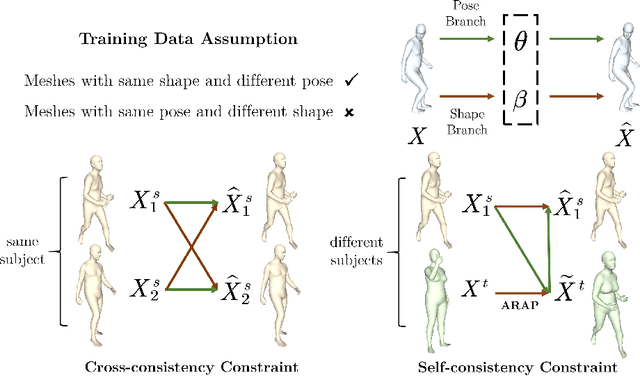
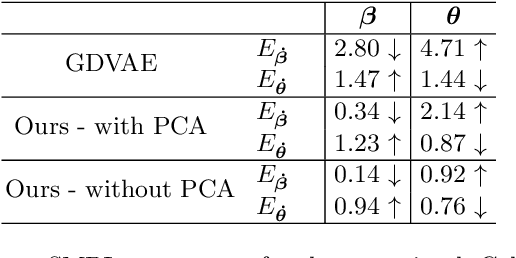
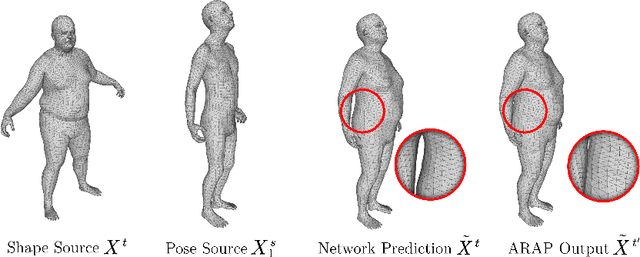
Parametric models of humans, faces, hands and animals have been widely used for a range of tasks such as image-based reconstruction, shape correspondence estimation, and animation. Their key strength is the ability to factor surface variations into shape and pose dependent components. Learning such models requires lots of expert knowledge and hand-defined object-specific constraints, making the learning approach unscalable to novel objects. In this paper, we present a simple yet effective approach to learn disentangled shape and pose representations in an unsupervised setting. We use a combination of self-consistency and cross-consistency constraints to learn pose and shape space from registered meshes. We additionally incorporate as-rigid-as-possible deformation(ARAP) into the training loop to avoid degenerate solutions. We demonstrate the usefulness of learned representations through a number of tasks including pose transfer and shape retrieval. The experiments on datasets of 3D humans, faces, hands and animals demonstrate the generality of our approach. Code is made available at https://virtualhumans.mpi-inf.mpg.de/unsup_shape_pose/.
The problems with using STNs to align CNN feature maps
Jan 14, 2020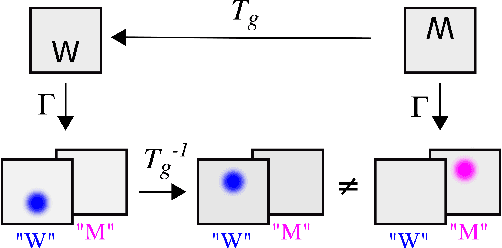



Spatial transformer networks (STNs) were designed to enable CNNs to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image and its original. We present a theoretical argument for this and investigate the practical implications, showing that this inability is coupled with decreased classification accuracy. We advocate taking advantage of more complex features in deeper layers by instead sharing parameters between the classification and the localisation network.
End-to-end 3D shape inverse rendering of different classes of objects from a single input image
Nov 11, 2017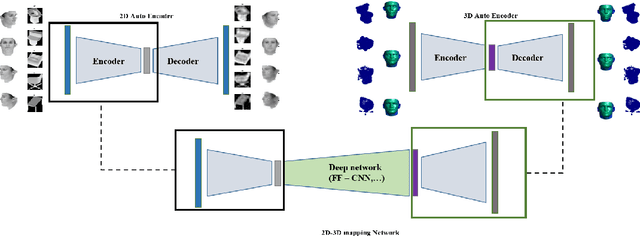
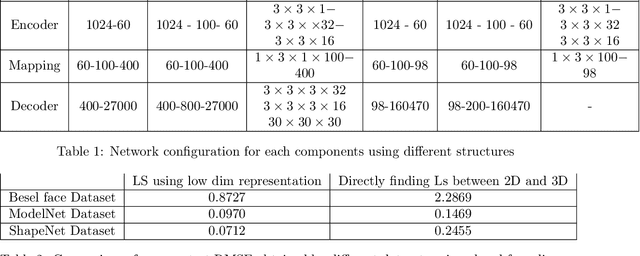
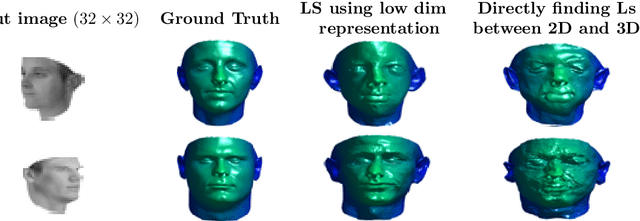

In this paper a semi-supervised deep framework is proposed for the problem of 3D shape inverse rendering from a single 2D input image. The main structure of proposed framework consists of unsupervised pre-trained components which significantly reduce the need to labeled data for training the whole framework. using labeled data has the advantage of achieving to accurate results without the need to predefined assumptions about image formation process. Three main components are used in the proposed network: an encoder which maps 2D input image to a representation space, a 3D decoder which decodes a representation to a 3D structure and a mapping component in order to map 2D to 3D representation. The only part that needs label for training is the mapping part with not too many parameters. The other components in the network can be pre-trained unsupervised using only 2D images or 3D data in each case. The way of reconstructing 3D shapes in the decoder component, inspired by the model based methods for 3D reconstruction, maps a low dimensional representation to 3D shape space with the advantage of extracting the basis vectors of shape space from training data itself and is not restricted to a small set of examples as used in predefined models. Therefore, the proposed framework deals directly with coordinate values of the point cloud representation which leads to achieve dense 3D shapes in the output. The experimental results on several benchmark datasets of objects and human faces and comparing with recent similar methods shows the power of proposed network in recovering more details from single 2D images.
Controllable Face Aging
Dec 20, 2019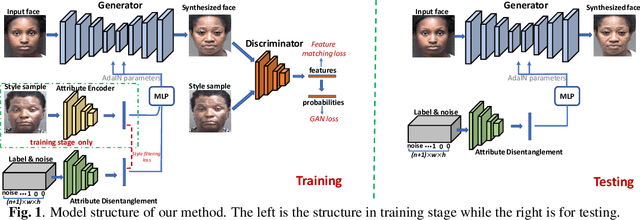
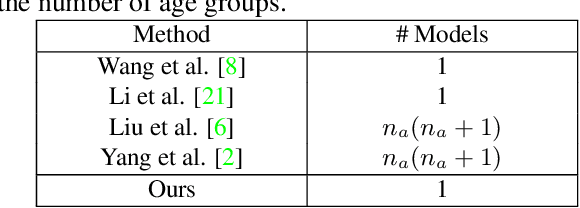
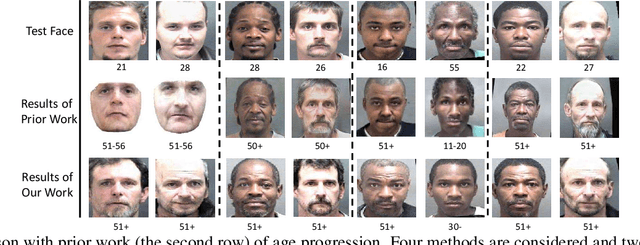
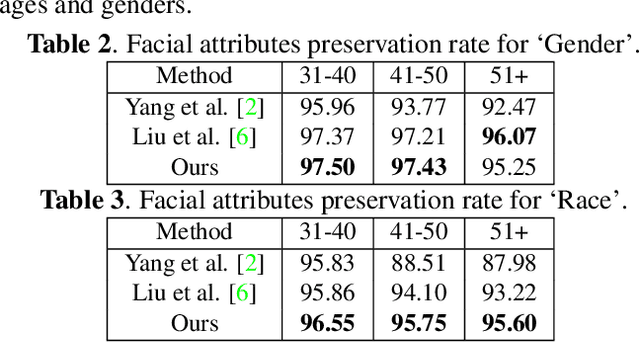
Motivated by the following two observations: 1) people are aging differently under different conditions for changeable facial attributes, e.g., skin color may become darker when working outside, and 2) it needs to keep some unchanged facial attributes during the aging process, e.g., race and gender, we propose a controllable face aging method via attribute disentanglement generative adversarial network. To offer fine control over the synthesized face images, first, an individual embedding of the face is directly learned from an image that contains the desired facial attribute. Second, since the image may contain other unwanted attributes, an attribute disentanglement network is used to separate the individual embedding and learn the common embedding that contains information about the face attribute (e.g., race). With the common embedding, we can manipulate the generated face image with the desired attribute in an explicit manner. Experimental results on two common benchmarks demonstrate that our proposed generator achieves comparable performance on the aging effect with state-of-the-art baselines while gaining more flexibility for attribute control. Code is available at supplementary material.
A Benchmark for Studying Diabetic Retinopathy: Segmentation, Grading, and Transferability
Aug 30, 2020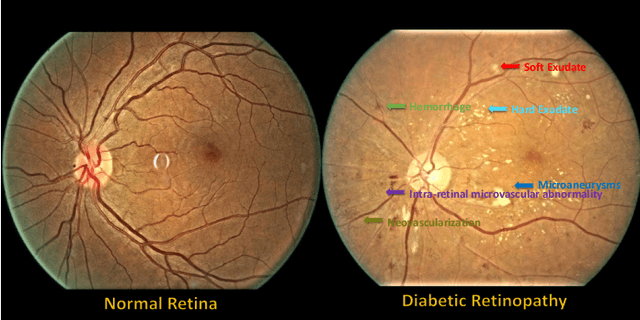
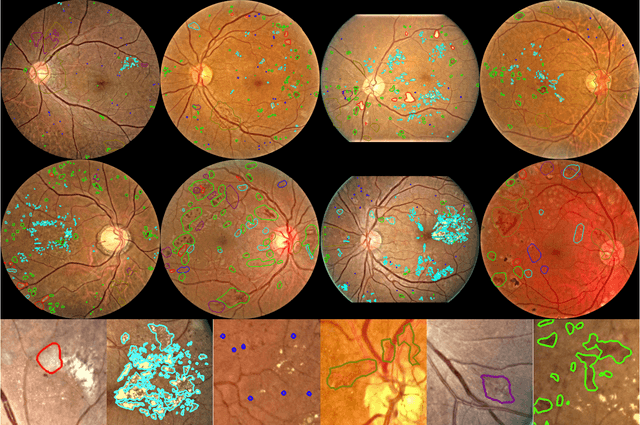
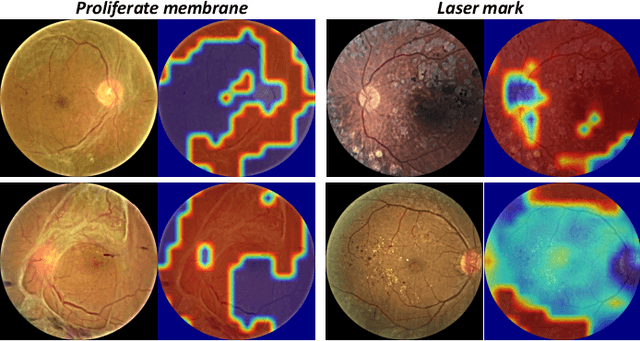
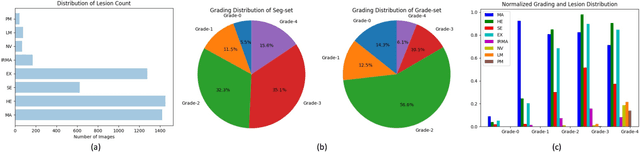
People with diabetes are at risk of developing an eye disease called diabetic retinopathy (DR). This disease occurs when high blood glucose levels cause damage to blood vessels in the retina. Computer-aided DR diagnosis is a promising tool for early detection of DR and severity grading, due to the great success of deep learning. However, most current DR diagnosis systems do not achieve satisfactory performance or interpretability for ophthalmologists, due to the lack of training data with consistent and fine-grained annotations. To address this problem, we construct a large fine-grained annotated DR dataset containing 2,842 images (FGADR). This dataset has 1,842 images with pixel-level DR-related lesion annotations, and 1,000 images with image-level labels graded by six board-certified ophthalmologists with intra-rater consistency. The proposed dataset will enable extensive studies on DR diagnosis. We set up three benchmark tasks for evaluation: 1. DR lesion segmentation; 2. DR grading by joint classification and segmentation; 3. Transfer learning for ocular multi-disease identification. Moreover, a novel inductive transfer learning method is introduced for the third task. Extensive experiments using different state-of-the-art methods are conducted on our FGADR dataset, which can serve as baselines for future research.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Jan 20, 2020
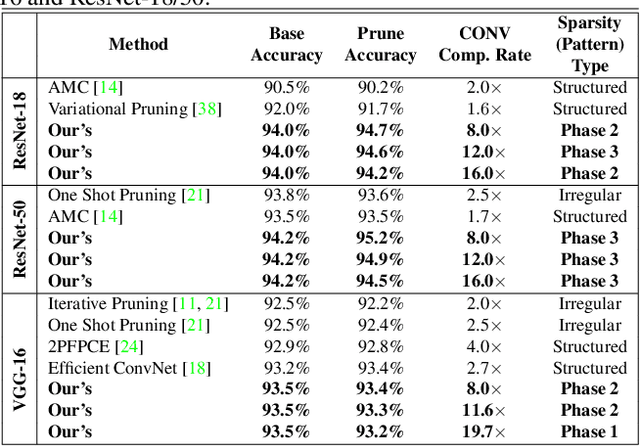
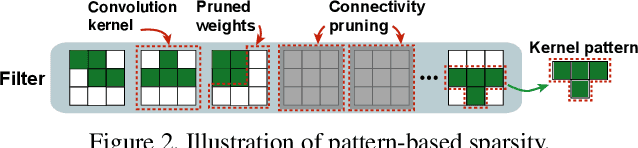
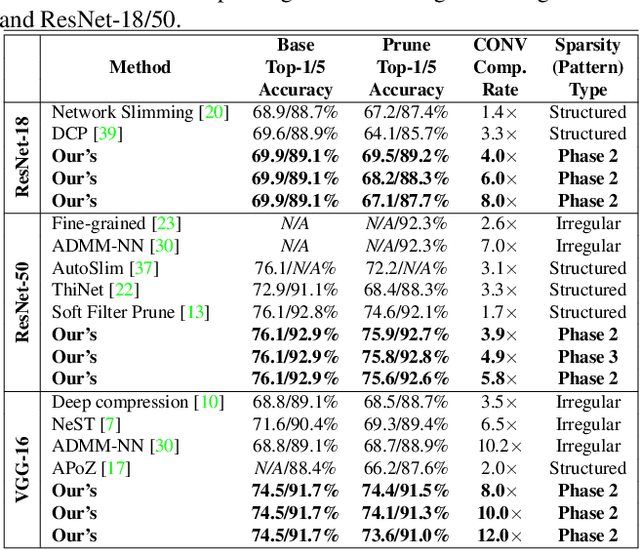
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.
Discriminating image textures with the multiscale two-dimensional complexity-entropy causality plane
Sep 07, 2016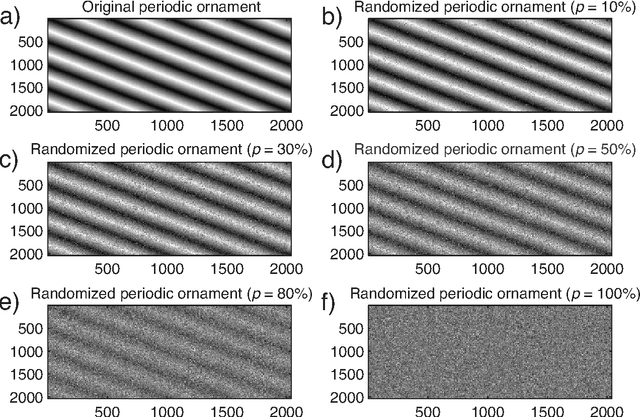
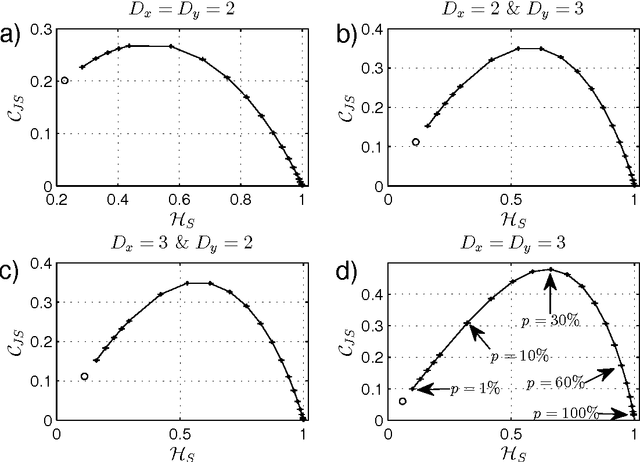
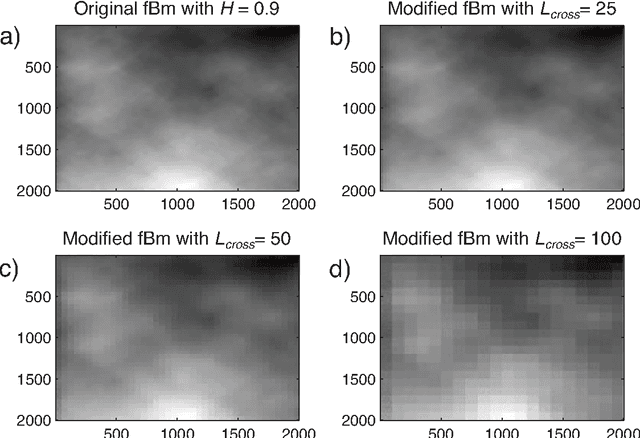
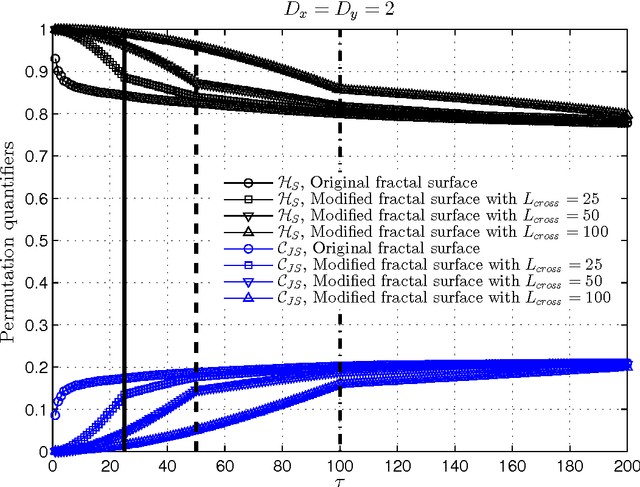
The aim of this paper is to further explore the usefulness of the two-dimensional complexity-entropy causality plane as a texture image descriptor. A multiscale generalization is introduced in order to distinguish between different roughness features of images at small and large spatial scales. Numerically generated two-dimensional structures are initially considered for illustrating basic concepts in a controlled framework. Then, more realistic situations are studied. Obtained results allow us to confirm that intrinsic spatial correlations of images are successfully unveiled by implementing this multiscale symbolic information-theory approach. Consequently, we conclude that the proposed representation space is a versatile and practical tool for identifying, characterizing and discriminating image textures.
* Accepted for publication in Chaos, Solitons & Fractals
SPICE: Semantic Propositional Image Caption Evaluation
Jul 29, 2016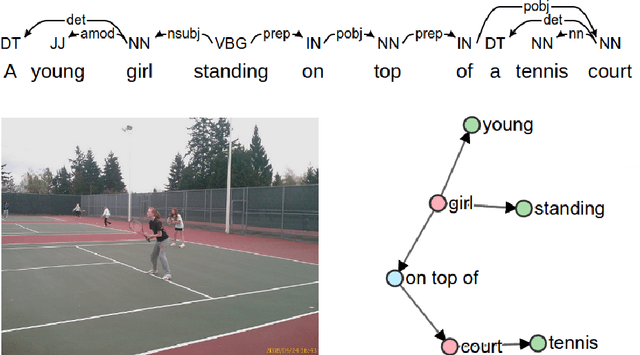
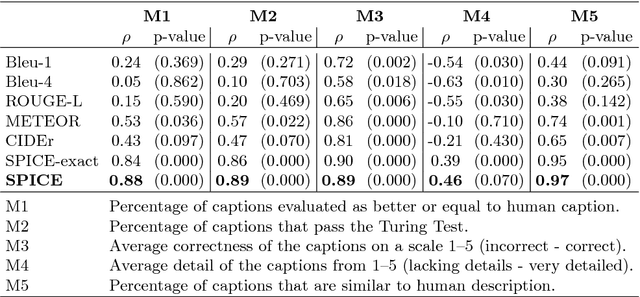
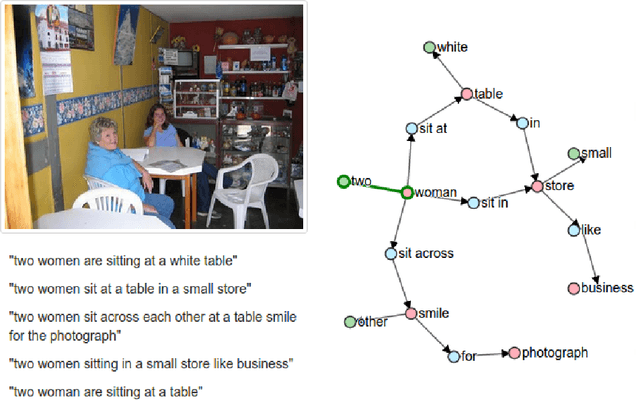
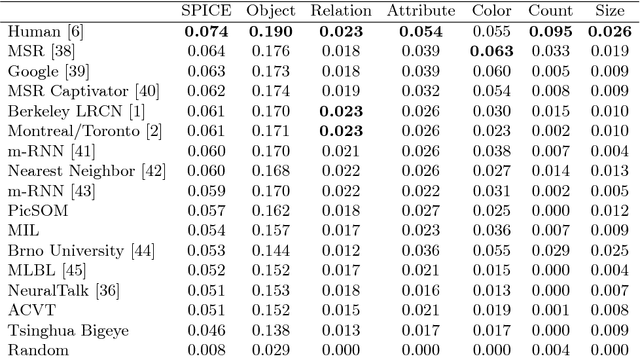
There is considerable interest in the task of automatically generating image captions. However, evaluation is challenging. Existing automatic evaluation metrics are primarily sensitive to n-gram overlap, which is neither necessary nor sufficient for the task of simulating human judgment. We hypothesize that semantic propositional content is an important component of human caption evaluation, and propose a new automated caption evaluation metric defined over scene graphs coined SPICE. Extensive evaluations across a range of models and datasets indicate that SPICE captures human judgments over model-generated captions better than other automatic metrics (e.g., system-level correlation of 0.88 with human judgments on the MS COCO dataset, versus 0.43 for CIDEr and 0.53 for METEOR). Furthermore, SPICE can answer questions such as `which caption-generator best understands colors?' and `can caption-generators count?'
ConvGRU in Fine-grained Pitching Action Recognition for Action Outcome Prediction
Aug 18, 2020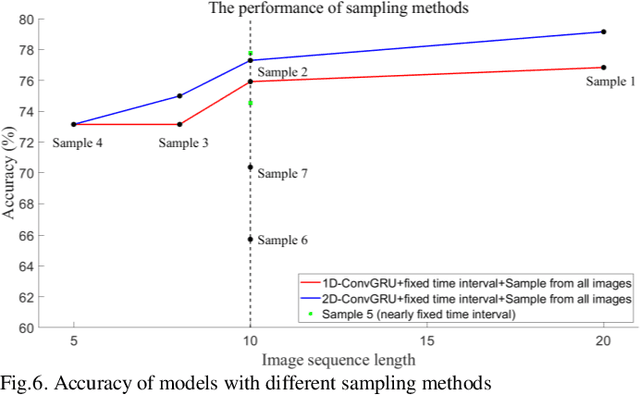


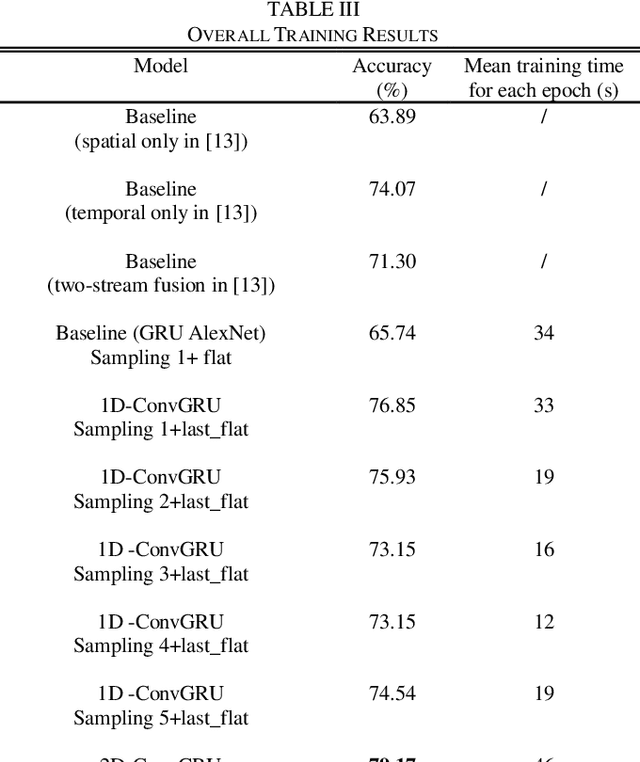
Prediction of the action outcome is a new challenge for a robot collaboratively working with humans. With the impressive progress in video action recognition in recent years, fine-grained action recognition from video data turns into a new concern. Fine-grained action recognition detects subtle differences of actions in more specific granularity and is significant in many fields such as human-robot interaction, intelligent traffic management, sports training, health caring. Considering that the different outcomes are closely connected to the subtle differences in actions, fine-grained action recognition is a practical method for action outcome prediction. In this paper, we explore the performance of convolutional gate recurrent unit (ConvGRU) method on a fine-grained action recognition tasks: predicting outcomes of ball-pitching. Based on sequences of RGB images of human actions, the proposed approach achieved the performance of 79.17% accuracy, which exceeds the current state-of-the-art result. We also compared different network implementations and showed the influence of different image sampling methods, different fusion methods and pre-training, etc. Finally, we discussed the advantages and limitations of ConvGRU in such action outcome prediction and fine-grained action recognition tasks.