 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Vertex Cut based Framework for Load Balancing and Parallelism Optimization in Multi-core Systems
Oct 09, 2020


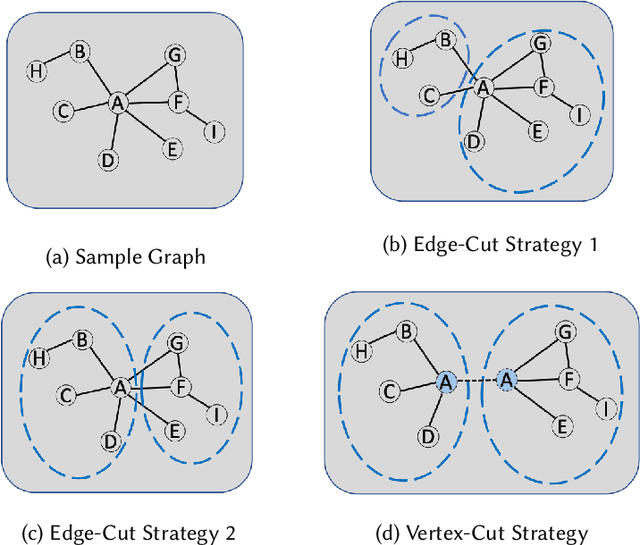
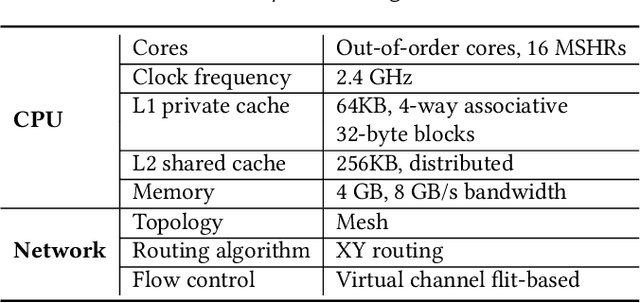
High-level applications, such as machine learning, are evolving from simple models based on multilayer perceptrons for simple image recognition to much deeper and more complex neural networks for self-driving vehicle control systems.The rapid increase in the consumption of memory and computational resources by these models demands the use of multi-core parallel systems to scale the execution of the complex emerging applications that depend on them. However, parallel programs running on high-performance computers often suffer from data communication bottlenecks, limited memory bandwidth, and synchronization overhead due to irregular critical sections. In this paper, we propose a framework to reduce the data communication and improve the scalability and performance of these applications in multi-core systems. We design a vertex cut framework for partitioning LLVM IR graphs into clusters while taking into consideration the data communication and workload balance among clusters. First, we construct LLVM graphs by compiling high-level programs into LLVM IR, instrumenting code to obtain the execution order of basic blocks and the execution time for each memory operation, and analyze data dependencies in dynamic LLVM traces. Next, we formulate the problem as Weight Balanced $p$-way Vertex Cut, and propose a generic and flexible framework, wherein four different greedy algorithms are proposed for solving this problem. Lastly, we propose a memory-centric run-time mapping of the linear time complexity to map clusters generated from the vertex cut algorithms onto a multi-core platform. We conclude that our best algorithm, WB-Libra, provides performance improvements of 1.56x and 1.86x over existing state-of-the-art approaches for 8 and 1024 clusters running on a multi-core platform, respectively.
Multi-channel Deep 3D Face Recognition
Sep 30, 2020
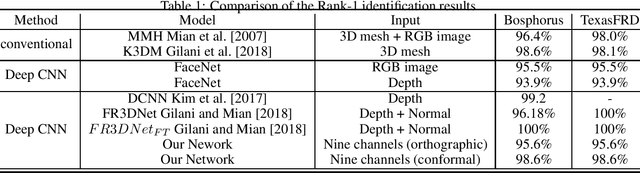
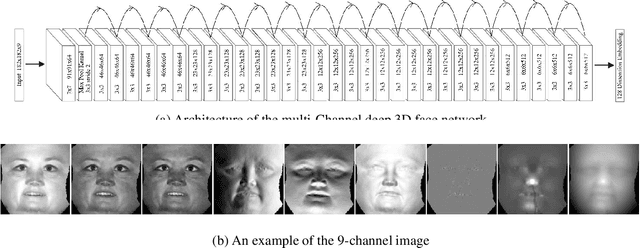
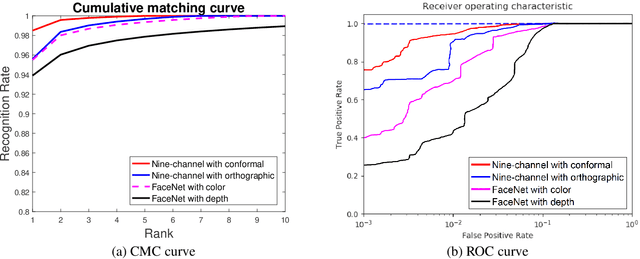
Face recognition has been of great importance in many applications as a biometric for its throughput, convenience, and non-invasiveness. Recent advancements in deep Convolutional Neural Network (CNN) architectures have boosted significantly the performance of face recognition based on two-dimensional (2D) facial texture images and outperformed the previous state of the art using conventional methods. However, the accuracy of 2D face recognition is still challenged by the change of pose, illumination, make-up, and expression. On the other hand, the geometric information contained in three-dimensional (3D) face data has the potential to overcome the fundamental limitations of 2D face data. We propose a multi-Channel deep 3D face network for face recognition based on 3D face data. We compute the geometric information of a 3D face based on its piecewise-linear triangular mesh structure and then conformally flatten geometric information along with the color from 3D to 2D plane to leverage the state-of-the-art deep CNN architectures. We modify the input layer of the network to take images with nine channels instead of three only such that more geometric information can be explicitly fed to it. We pre-train the network using images from the VGG-Face \cite{Parkhi2015} and then fine-tune it with the generated multi-channel face images. The face recognition accuracy of the multi-Channel deep 3D face network has achieved 98.6. The experimental results also clearly show that the network performs much better when a 9-channel image is flattened to plane based on the conformal map compared with the orthographic projection.
Associations among Image Assessments as Cost Functions in Linear Decomposition: MSE, SSIM, and Correlation Coefficient
Aug 04, 2017The traditional methods of image assessment, such as mean squared error (MSE), signal-to-noise ratio (SNR), and Peak signal-to-noise ratio (PSNR), are all based on the absolute error of images. Pearson's inner-product correlation coefficient (PCC) is also usually used to measure the similarity between images. Structural similarity (SSIM) index is another important measurement which has been shown to be more effective in the human vision system (HVS). Although there are many essential differences among these image assessments, some important associations among them as cost functions in linear decomposition are discussed in this paper. Firstly, the selected bases from a basis set for a target vector are the same in the linear decomposition schemes with different cost functions MSE, SSIM, and PCC. Moreover, for a target vector, the ratio of the corresponding affine parameters in the MSE-based linear decomposition scheme and the SSIM-based scheme is a constant, which is just the value of PCC between the target vector and its estimated vector.
Efficient Deep Representation Learning by Adaptive Latent Space Sampling
Apr 12, 2020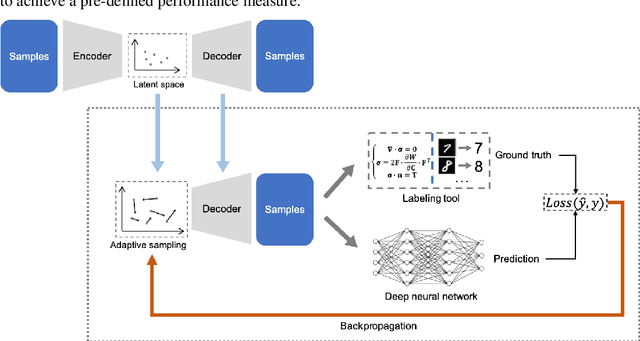

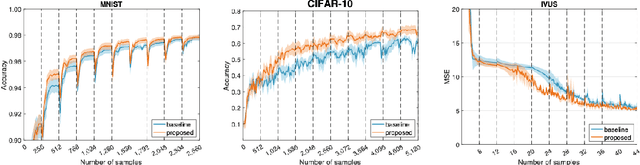
Supervised deep learning requires a large amount of training samples with annotations (e.g. label class for classification task, pixel- or voxel-wised label map for segmentation tasks), which are expensive and time-consuming to obtain. During the training of a deep neural network, the annotated samples are fed into the network in a mini-batch way, where they are often regarded of equal importance. However, some of the samples may become less informative during training, as the magnitude of the gradient start to vanish for these samples. In the meantime, other samples of higher utility or hardness may be more demanded for the training process to proceed and require more exploitation. To address the challenges of expensive annotations and loss of sample informativeness, here we propose a novel training framework which adaptively selects informative samples that are fed to the training process. The adaptive selection or sampling is performed based on a hardness-aware strategy in the latent space constructed by a generative model. To evaluate the proposed training framework, we perform experiments on three different datasets, including MNIST and CIFAR-10 for image classification task and a medical image dataset IVUS for biophysical simulation task. On all three datasets, the proposed framework outperforms a random sampling method, which demonstrates the effectiveness of proposed framework.
Tangent Images for Mitigating Spherical Distortion
Dec 19, 2019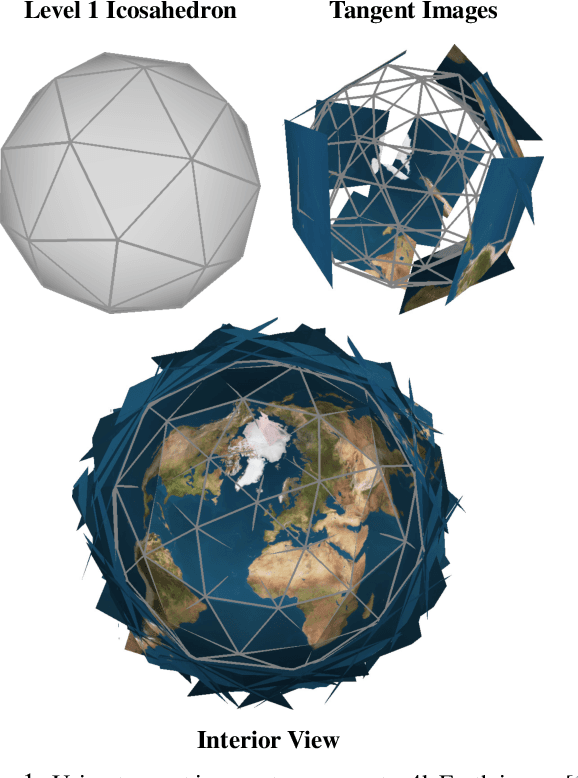
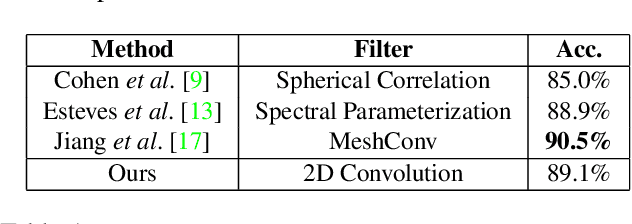

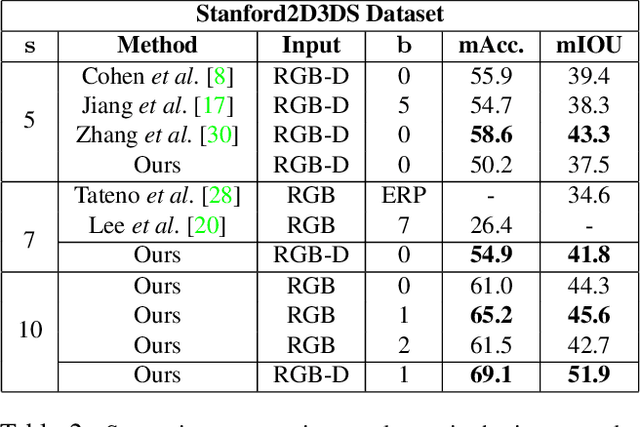
In this work, we propose "tangent images," a spherical image representation that facilitates transferable and scalable $360^\circ$ computer vision. Inspired by techniques in cartography and computer graphics, we render a spherical image to a set of distortion-mitigated, locally-planar image grids tangent to a subdivided icosahedron. By varying the resolution of these grids independently of the subdivision level, we can effectively represent high resolution spherical images while still benefiting from the low-distortion icosahedral spherical approximation. We show that training standard convolutional neural networks on tangent images compares favorably to the many specialized spherical convolutional kernels that have been developed, while also allowing us to scale training to significantly higher spherical resolutions. Furthermore, because we do not require specialized kernels, we show that we can transfer networks trained on perspective images to spherical data without fine-tuning and with limited performance drop-off. Finally, we demonstrate that tangent images can be used to improve the quality of sparse feature detection on spherical images, illustrating its usefulness for traditional computer vision tasks like structure-from-motion and SLAM.
Learning Connectivity of Neural Networks from a Topological Perspective
Aug 19, 2020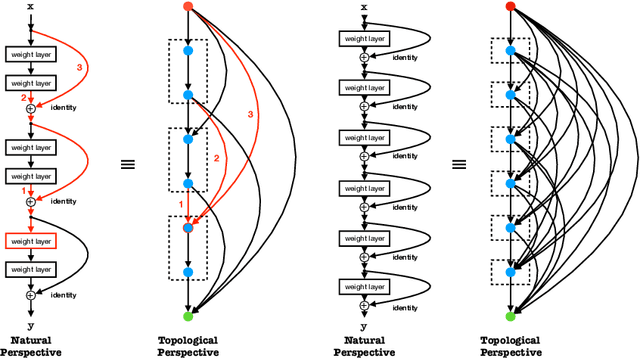
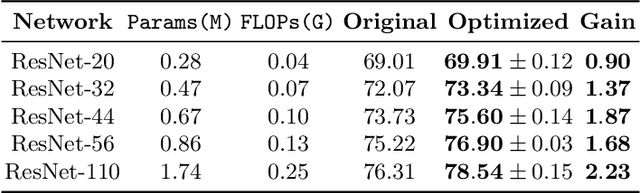
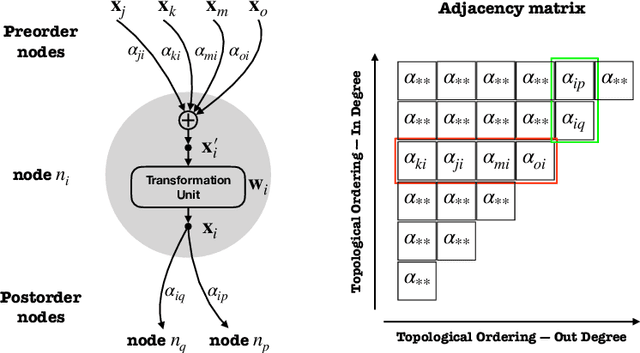
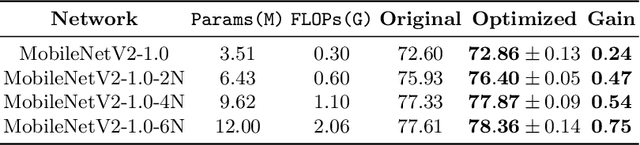
Seeking effective neural networks is a critical and practical field in deep learning. Besides designing the depth, type of convolution, normalization, and nonlinearities, the topological connectivity of neural networks is also important. Previous principles of rule-based modular design simplify the difficulty of building an effective architecture, but constrain the possible topologies in limited spaces. In this paper, we attempt to optimize the connectivity in neural networks. We propose a topological perspective to represent a network into a complete graph for analysis, where nodes carry out aggregation and transformation of features, and edges determine the flow of information. By assigning learnable parameters to the edges which reflect the magnitude of connections, the learning process can be performed in a differentiable manner. We further attach auxiliary sparsity constraint to the distribution of connectedness, which promotes the learned topology focus on critical connections. This learning process is compatible with existing networks and owns adaptability to larger search spaces and different tasks. Quantitative results of experiments reflect the learned connectivity is superior to traditional rule-based ones, such as random, residual, and complete. In addition, it obtains significant improvements in image classification and object detection without introducing excessive computation burden.
Data-driven Meta-set Based Fine-Grained Visual Classification
Aug 06, 2020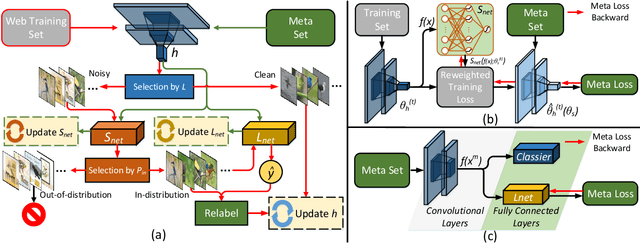
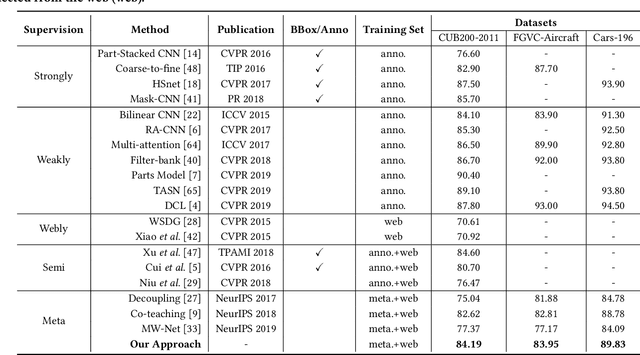
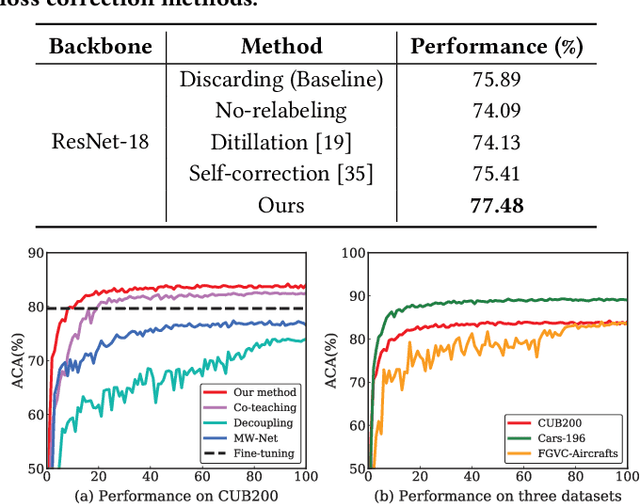
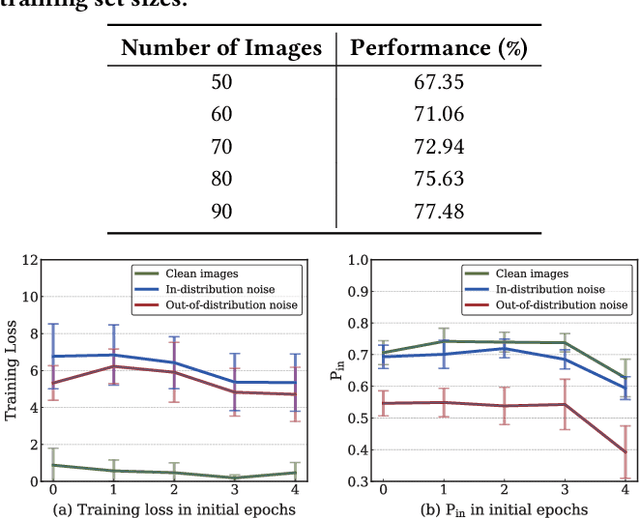
Constructing fine-grained image datasets typically requires domain-specific expert knowledge, which is not always available for crowd-sourcing platform annotators. Accordingly, learning directly from web images becomes an alternative method for fine-grained visual recognition. However, label noise in the web training set can severely degrade the model performance. To this end, we propose a data-driven meta-set based approach to deal with noisy web images for fine-grained recognition. Specifically, guided by a small amount of clean meta-set, we train a selection net in a meta-learning manner to distinguish in- and out-of-distribution noisy images. To further boost the robustness of model, we also learn a labeling net to correct the labels of in-distribution noisy data. In this way, our proposed method can alleviate the harmful effects caused by out-of-distribution noise and properly exploit the in-distribution noisy samples for training. Extensive experiments on three commonly used fine-grained datasets demonstrate that our approach is much superior to state-of-the-art noise-robust methods.
End-to-end 3D shape inverse rendering of different classes of objects from a single input image
Nov 11, 2017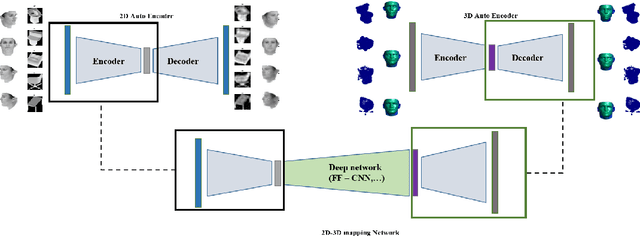
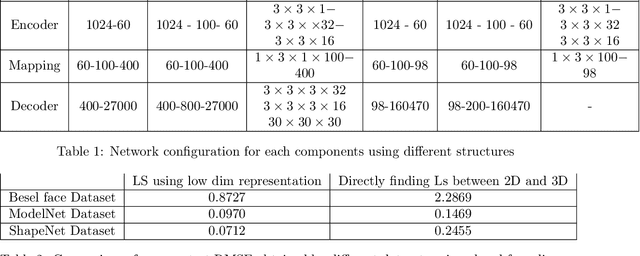

In this paper a semi-supervised deep framework is proposed for the problem of 3D shape inverse rendering from a single 2D input image. The main structure of proposed framework consists of unsupervised pre-trained components which significantly reduce the need to labeled data for training the whole framework. using labeled data has the advantage of achieving to accurate results without the need to predefined assumptions about image formation process. Three main components are used in the proposed network: an encoder which maps 2D input image to a representation space, a 3D decoder which decodes a representation to a 3D structure and a mapping component in order to map 2D to 3D representation. The only part that needs label for training is the mapping part with not too many parameters. The other components in the network can be pre-trained unsupervised using only 2D images or 3D data in each case. The way of reconstructing 3D shapes in the decoder component, inspired by the model based methods for 3D reconstruction, maps a low dimensional representation to 3D shape space with the advantage of extracting the basis vectors of shape space from training data itself and is not restricted to a small set of examples as used in predefined models. Therefore, the proposed framework deals directly with coordinate values of the point cloud representation which leads to achieve dense 3D shapes in the output. The experimental results on several benchmark datasets of objects and human faces and comparing with recent similar methods shows the power of proposed network in recovering more details from single 2D images.
Privacy-preserving Artificial Intelligence Techniques in Biomedicine
Jul 22, 2020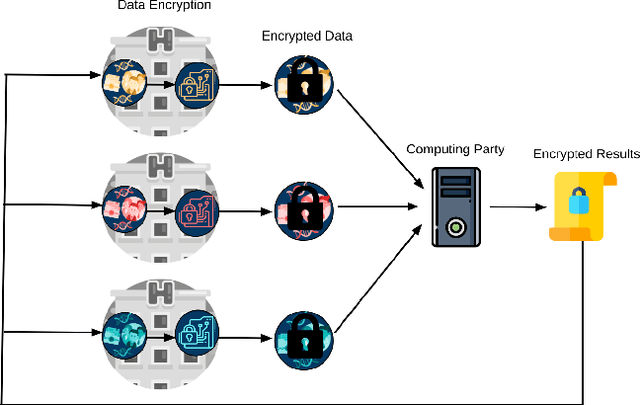
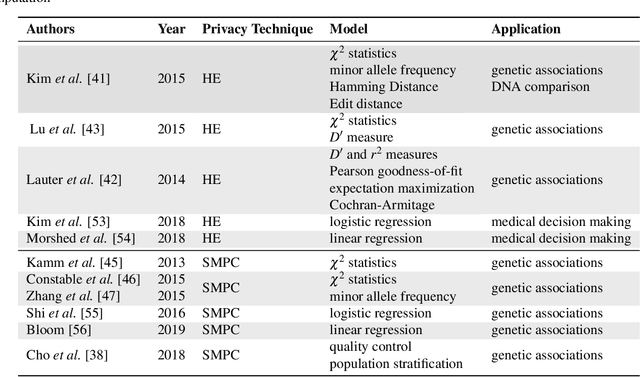
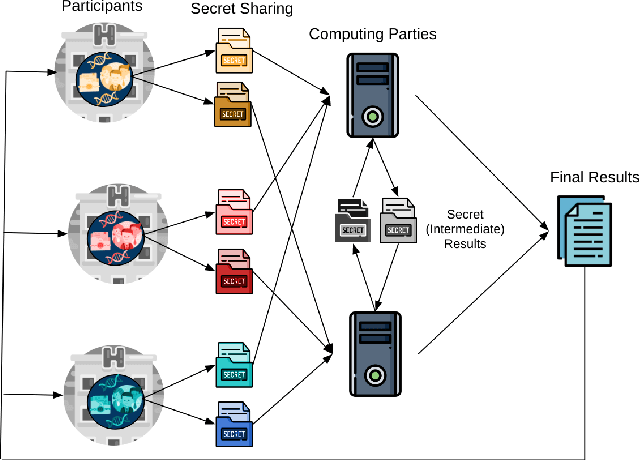
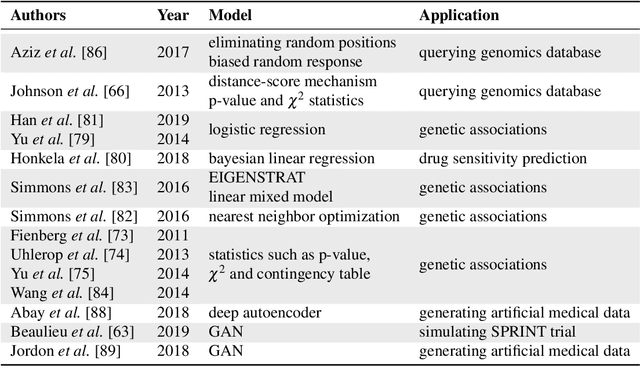
Artificial intelligence (AI) has been successfully applied in numerous scientific domains including biomedicine and healthcare. Here, it has led to several breakthroughs ranging from clinical decision support systems, image analysis to whole genome sequencing. However, training an AI model on sensitive data raises also concerns about the privacy of individual participants. Adversary AIs, for example, can abuse even summary statistics of a study to determine the presence or absence of an individual in a given dataset. This has resulted in increasing restrictions to access biomedical data, which in turn is detrimental for collaborative research and impedes scientific progress. Hence there has been an explosive growth in efforts to harness the power of AI for learning from sensitive data while protecting patients' privacy. This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy, and discusses their strengths, limitations, and open problems.
Benchmarking Differentially Private Residual Networks for Medical Imagery
Jun 28, 2020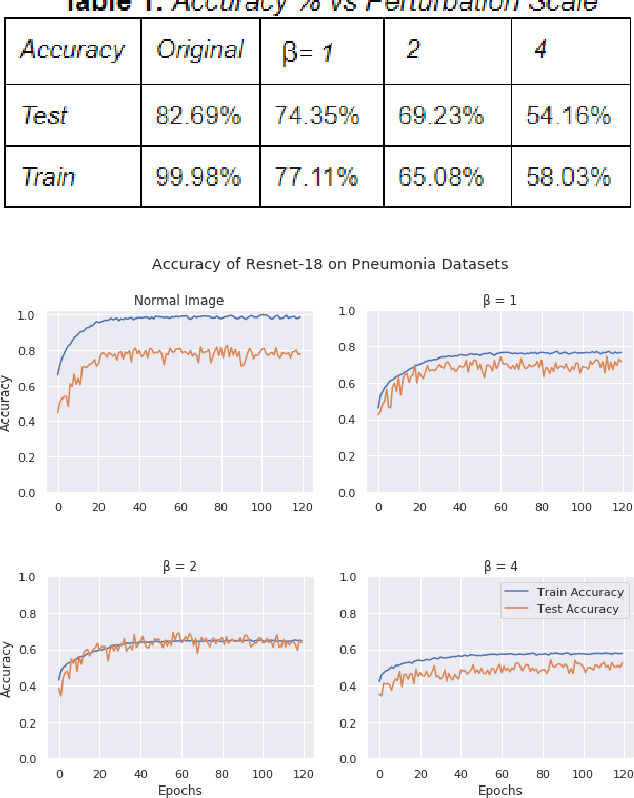
Hospitals and other medical institutions often have vast amounts of medical data which can provide significant value when utilized to advance research. However, this data is often sensitive in nature and as such is not readily available for use in a research setting, often due to privacy concerns. In this paper, we measure the performance of a deep neural network on differentially private image datasets pertaining to Pneumonia. We analyze the trade-off between the model's accuracy and the scale of perturbation among the images. Knowing how the model's accuracy varies among different perturbation levels in differentially private medical images can be quite a useful measure for hospitals to know. Furthermore, we also seek to measure the usefulness of local differential privacy for such medical imagery tasks and see if there's room for improvement.