 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLEAR: Covariant LEAst-square Re-fitting with applications to image restoration
Sep 14, 2016
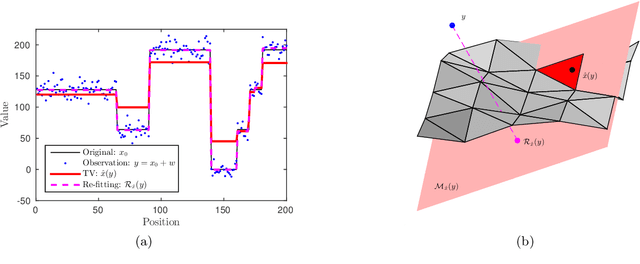
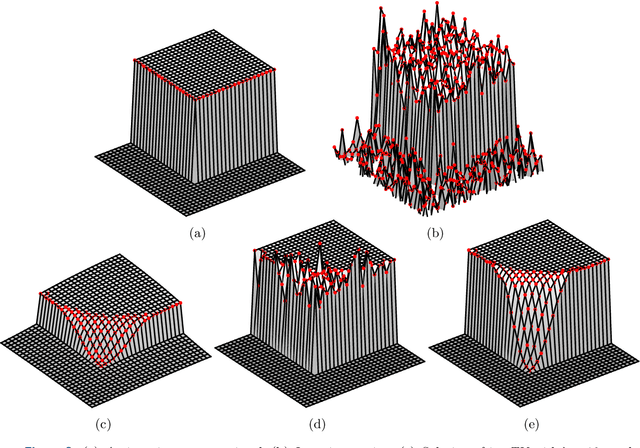


In this paper, we propose a new framework to remove parts of the systematic errors affecting popular restoration algorithms, with a special focus for image processing tasks. Generalizing ideas that emerged for $\ell_1$ regularization, we develop an approach re-fitting the results of standard methods towards the input data. Total variation regularizations and non-local means are special cases of interest. We identify important covariant information that should be preserved by the re-fitting method, and emphasize the importance of preserving the Jacobian (w.r.t. the observed signal) of the original estimator. Then, we provide an approach that has a "twicing" flavor and allows re-fitting the restored signal by adding back a local affine transformation of the residual term. We illustrate the benefits of our method on numerical simulations for image restoration tasks.
Fast Modeling and Understanding Fluid Dynamics Systems with Encoder-Decoder Networks
Jun 09, 2020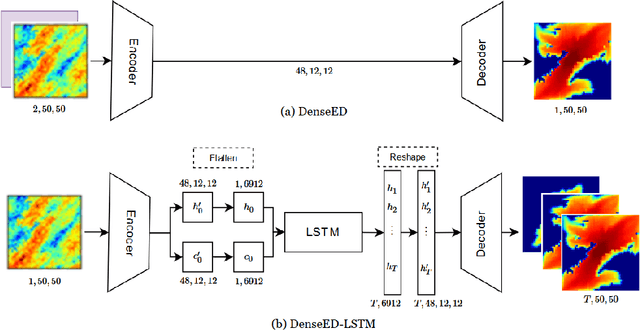
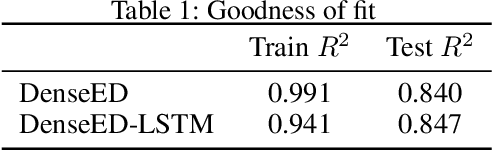


Is a deep learning model capable of understanding systems governed by certain first principle laws by only observing the system's output? Can deep learning learn the underlying physics and honor the physics when making predictions? The answers are both positive. In an effort to simulate two-dimensional subsurface fluid dynamics in porous media, we found that an accurate deep-learning-based proxy model can be taught efficiently by a computationally expensive finite-volume-based simulator. We pose the problem as an image-to-image regression, running the simulator with different input parameters to furnish a synthetic training dataset upon which we fit the deep learning models. Since the data is spatiotemporal, we compare the performance of two alternative treatments of time; a convolutional LSTM versus an autoencoder network that treats time as a direct input. Adversarial methods are adopted to address the sharp spatial gradient in the fluid dynamic problems. Compared to traditional simulation, the proposed deep learning approach enables much faster forward computation, which allows us to explore more scenarios with a much larger parameter space given the same time. It is shown that the improved forward computation efficiency is particularly valuable in solving inversion problems, where the physics model has unknown parameters to be determined by history matching. By computing the pixel-level attention of the trained model, we quantify the sensitivity of the deep learning model to key physical parameters and hence demonstrate that the inversion problems can be solved with great acceleration. We assess the efficacy of the machine learning surrogate in terms of its training speed and accuracy. The network can be trained within minutes using limited training data and achieve accuracy that scales desirably with the amount of training data supplied.
A Fast HOG Descriptor Using Lookup Table and Integral Image
Mar 18, 2017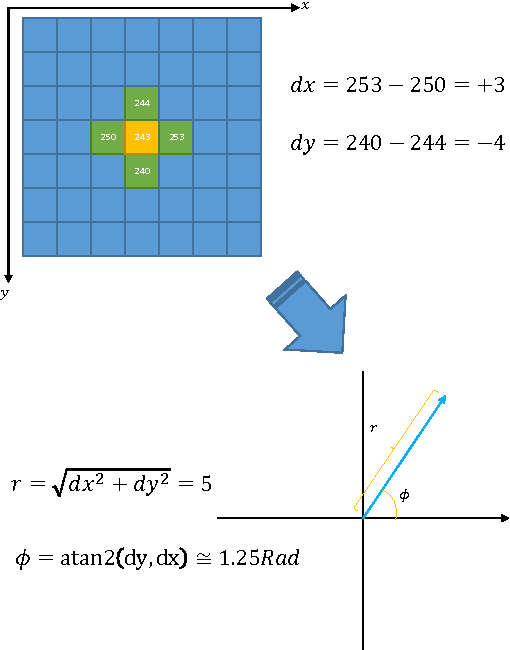
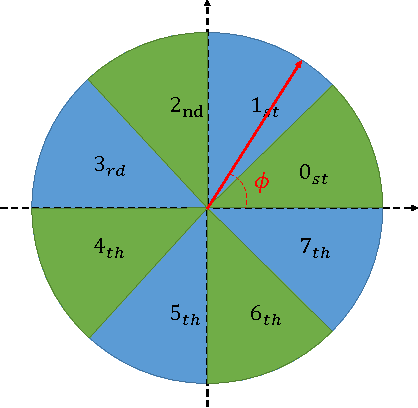
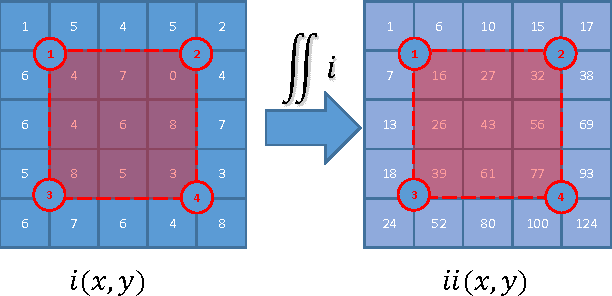
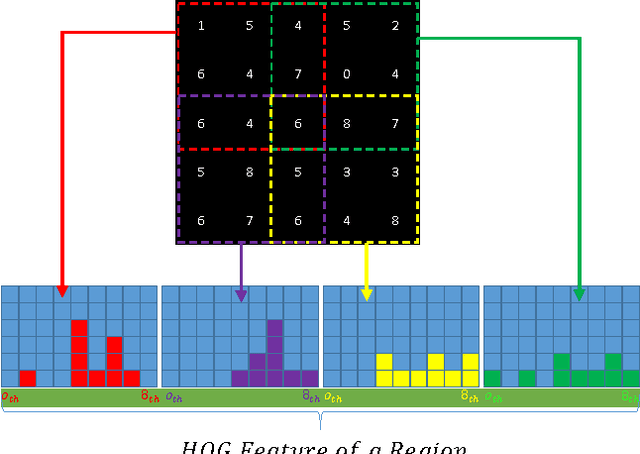
The histogram of oriented gradients (HOG) is a widely used feature descriptor in computer vision for the purpose of object detection. In the paper, a modified HOG descriptor is described, it uses a lookup table and the method of integral image to speed up the detection performance by a factor of 5~10. By exploiting the special hardware features of a given platform(e.g. a digital signal processor), further improvement can be made to the HOG descriptor in order to have real-time object detection and tracking.
From Inference to Generation: End-to-end Fully Self-supervised Generation of Human Face from Speech
Apr 13, 2020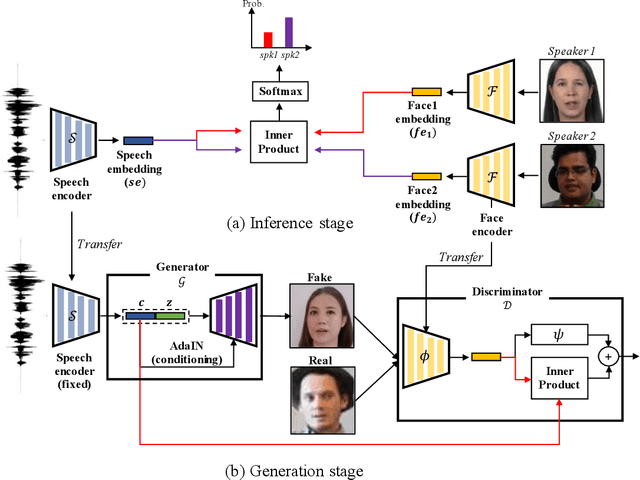
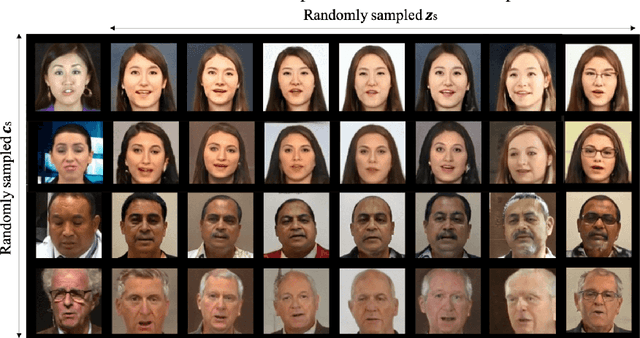

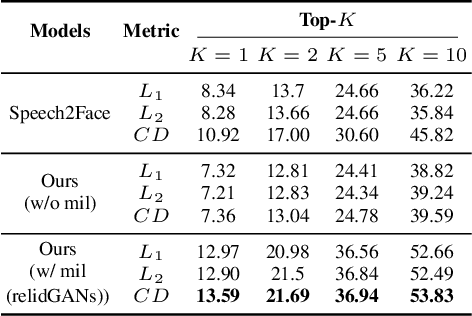
This work seeks the possibility of generating the human face from voice solely based on the audio-visual data without any human-labeled annotations. To this end, we propose a multi-modal learning framework that links the inference stage and generation stage. First, the inference networks are trained to match the speaker identity between the two different modalities. Then the trained inference networks cooperate with the generation network by giving conditional information about the voice. The proposed method exploits the recent development of GANs techniques and generates the human face directly from the speech waveform making our system fully end-to-end. We analyze the extent to which the network can naturally disentangle two latent factors that contribute to the generation of a face image - one that comes directly from a speech signal and the other that is not related to it - and explore whether the network can learn to generate natural human face image distribution by modeling these factors. Experimental results show that the proposed network can not only match the relationship between the human face and speech, but can also generate the high-quality human face sample conditioned on its speech. Finally, the correlation between the generated face and the corresponding speech is quantitatively measured to analyze the relationship between the two modalities.
Deep Reinforcement Learning and its Neuroscientific Implications
Jul 07, 2020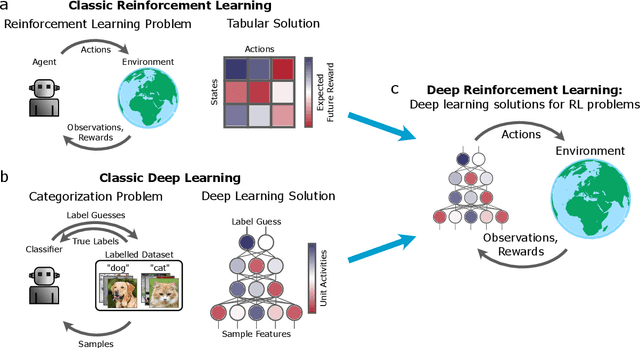
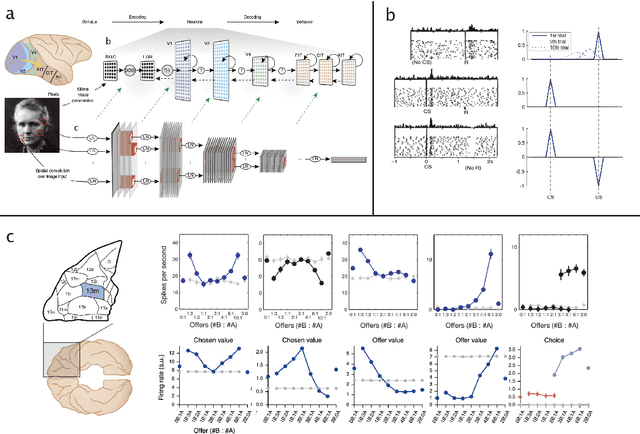
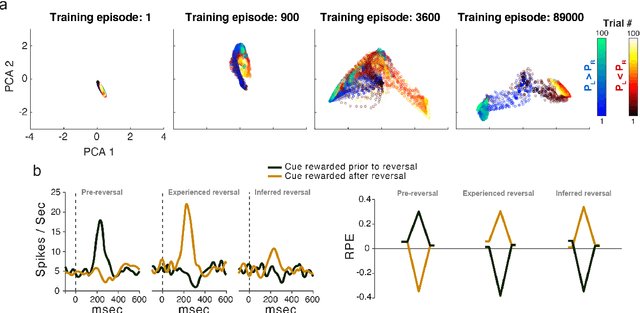
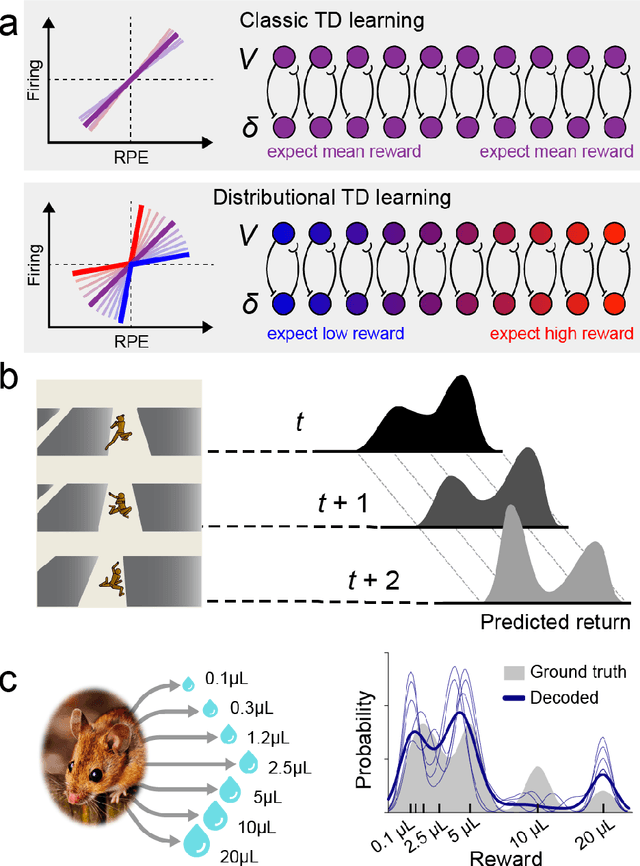
The emergence of powerful artificial intelligence is defining new research directions in neuroscience. To date, this research has focused largely on deep neural networks trained using supervised learning, in tasks such as image classification. However, there is another area of recent AI work which has so far received less attention from neuroscientists, but which may have profound neuroscientific implications: deep reinforcement learning. Deep RL offers a comprehensive framework for studying the interplay among learning, representation and decision-making, offering to the brain sciences a new set of research tools and a wide range of novel hypotheses. In the present review, we provide a high-level introduction to deep RL, discuss some of its initial applications to neuroscience, and survey its wider implications for research on brain and behavior, concluding with a list of opportunities for next-stage research.
A Novel Feature Descriptor for Image Retrieval by Combining Modified Color Histogram and Diagonally Symmetric Co-occurrence Texture Pattern
Jan 03, 2018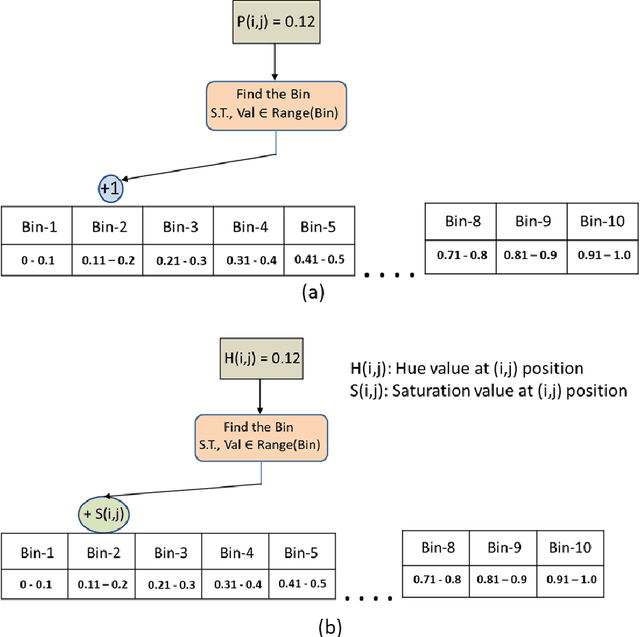

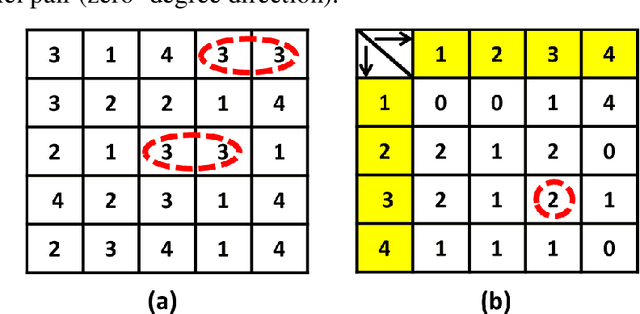
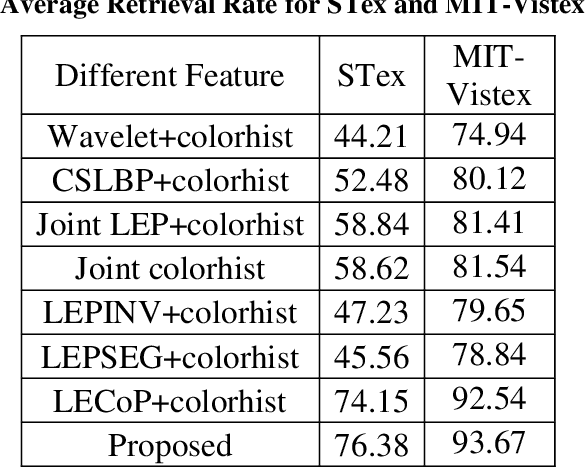
In this paper, we have proposed a novel feature descriptors combining color and texture information collectively. In our proposed color descriptor component, the inter-channel relationship between Hue (H) and Saturation (S) channels in the HSV color space has been explored which was not done earlier. We have quantized the H channel into a number of bins and performed the voting with saturation values and vice versa by following a principle similar to that of the HOG descriptor, where orientation of the gradient is quantized into a certain number of bins and voting is done with gradient magnitude. This helps us to study the nature of variation of saturation with variation in Hue and nature of variation of Hue with the variation in saturation. The texture component of our descriptor considers the co-occurrence relationship between the pixels symmetric about both the diagonals of a 3x3 window. Our work is inspired from the work done by Dubey et al.[1]. These two components, viz. color and texture information individually perform better than existing texture and color descriptors. Moreover, when concatenated the proposed descriptors provide significant improvement over existing descriptors for content base color image retrieval. The proposed descriptor has been tested for image retrieval on five databases, including texture image databases - MIT VisTex database and Salzburg texture database and natural scene databases Corel 1K, Corel 5K and Corel 10K. The precision and recall values experimented on these databases are compared with some state-of-art local patterns. The proposed method provided satisfactory results from the experiments.
Confidence-guided Lesion Mask-based Simultaneous Synthesis of Anatomic and Molecular MR Images in Patients with Post-treatment Malignant Gliomas
Aug 06, 2020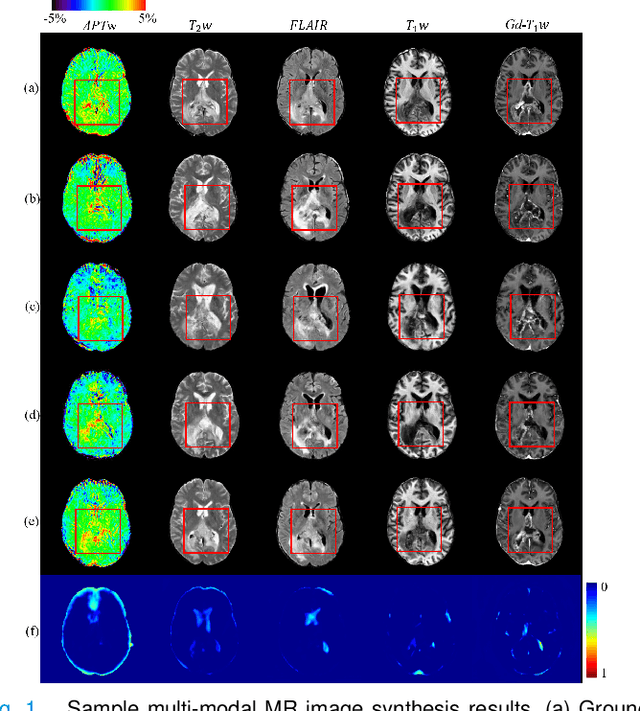
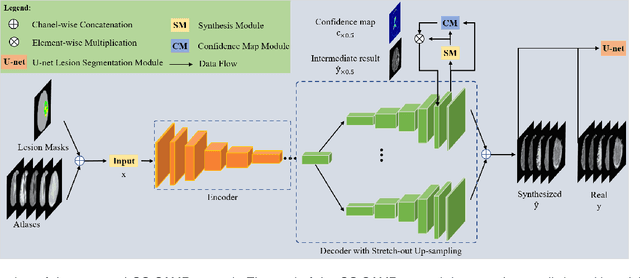
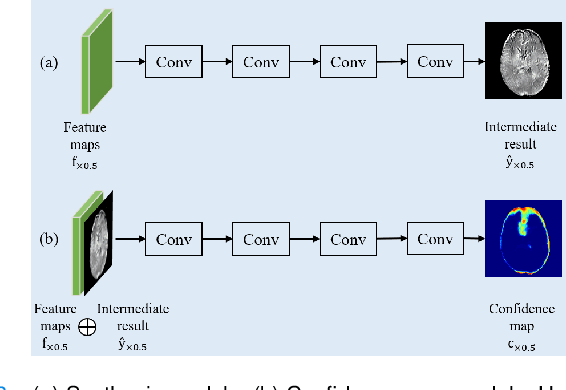
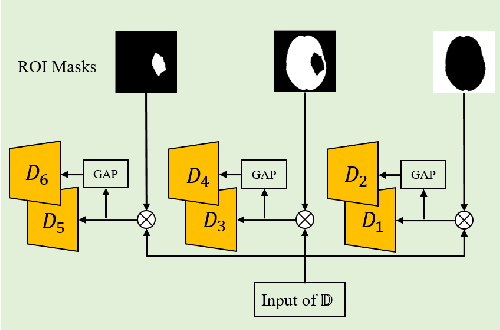
Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas in neuro-oncology, especially with the help of standard anatomic and advanced molecular MR images. However, data quantity and quality remain a key determinant of, and a significant limit on, the potential of such applications. In our previous work, we explored synthesis of anatomic and molecular MR image network (SAMR) in patients with post-treatment malignant glioms. Now, we extend it and propose Confidence Guided SAMR (CG-SAMR) that synthesizes data from lesion information to multi-modal anatomic sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), and fluid-attenuated inversion recovery (FLAIR), and the molecular amide proton transfer-weighted (APTw) sequence. We introduce a module which guides the synthesis based on confidence measure about the intermediate results. Furthermore, we extend the proposed architecture for unsupervised synthesis so that unpaired data can be used for training the network. Extensive experiments on real clinical data demonstrate that the proposed model can perform better than the state-of-theart synthesis methods.
Synthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild
Sep 21, 2020
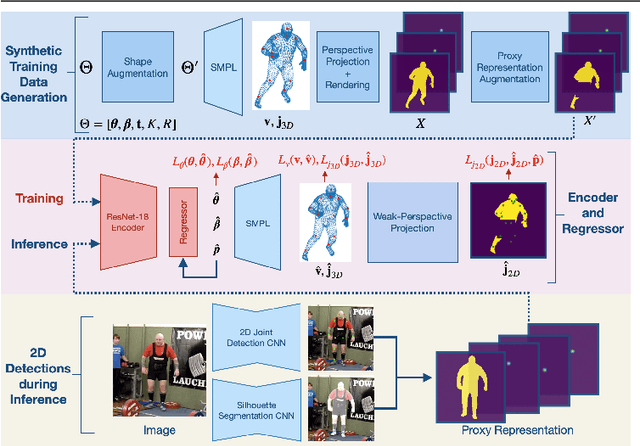
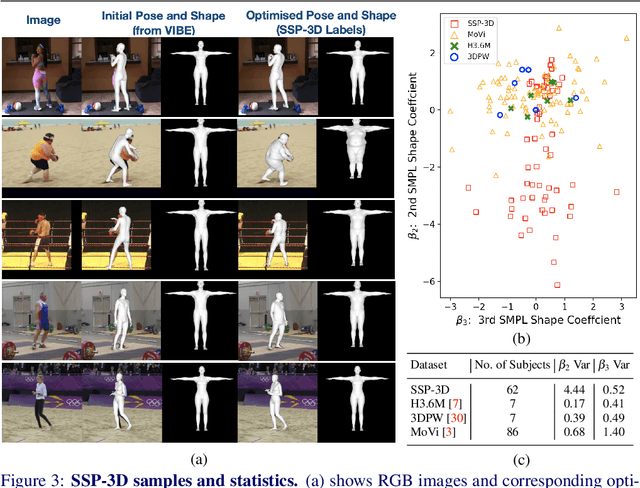

This paper addresses the problem of monocular 3D human shape and pose estimation from an RGB image. Despite great progress in this field in terms of pose prediction accuracy, state-of-the-art methods often predict inaccurate body shapes. We suggest that this is primarily due to the scarcity of \textit{in-the-wild} training data with \textit{diverse and accurate} body shape labels. Thus, we propose STRAPS (Synthetic Training for Real Accurate Pose and Shape), a system that utilises proxy representations, such as silhouettes and 2D joints, as inputs to a shape and pose regression neural network, which is trained with synthetic training data (generated on-the-fly during training using the SMPL statistical body model) to overcome data scarcity. We bridge the gap between synthetic training inputs and noisy real inputs, which are predicted by keypoint detection and segmentation CNNs at test-time, by using data augmentation and corruption during training. In order to evaluate our approach, we curate and provide a challenging evaluation dataset for monocular human shape estimation, Sports Shape and Pose 3D (SSP-3D). It consists of RGB images of tightly-clothed sports-persons with a variety of body shapes and corresponding pseudo-ground-truth SMPL shape and pose parameters, obtained via multi-frame optimisation. We show that STRAPS outperforms other state-of-the-art methods on SSP-3D in terms of shape prediction accuracy, while remaining competitive with the state-of-the-art on pose-centric datasets and metrics.
Script Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Aug 07, 2018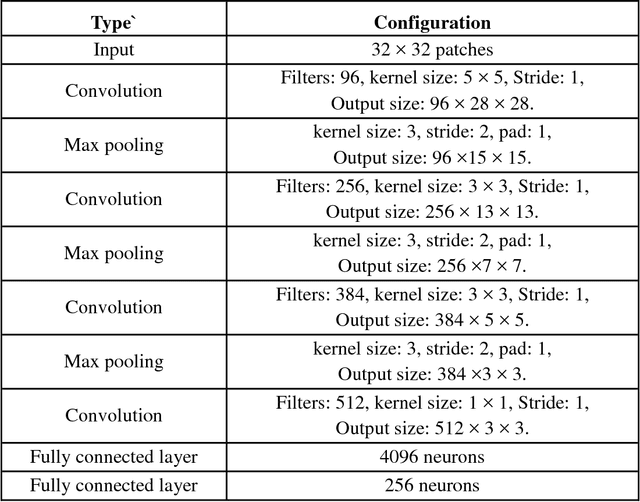
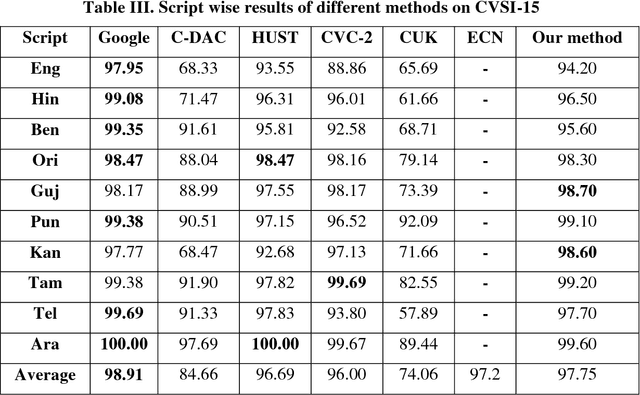
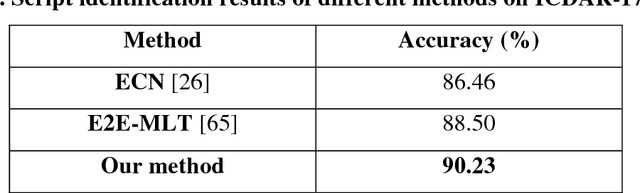
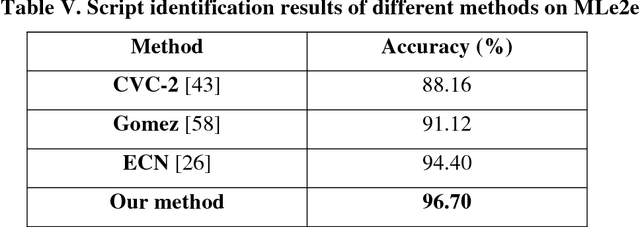
Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.
A Closed-Form Model for Image-Based Distant Lighting
May 14, 2017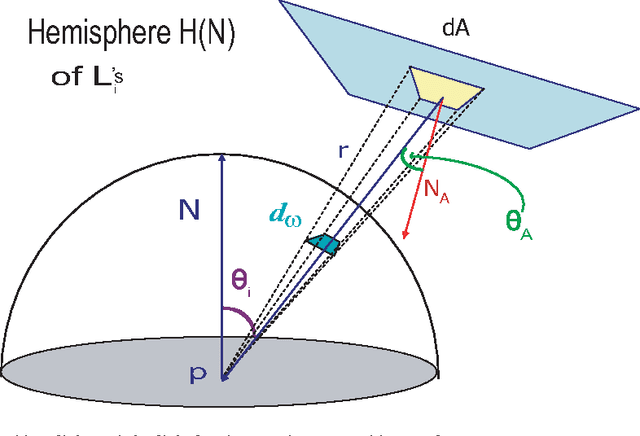
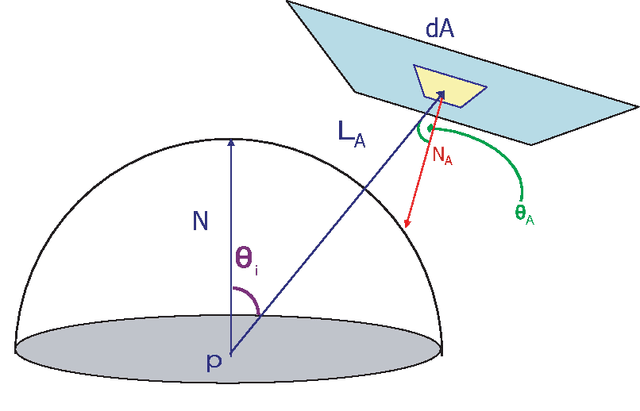
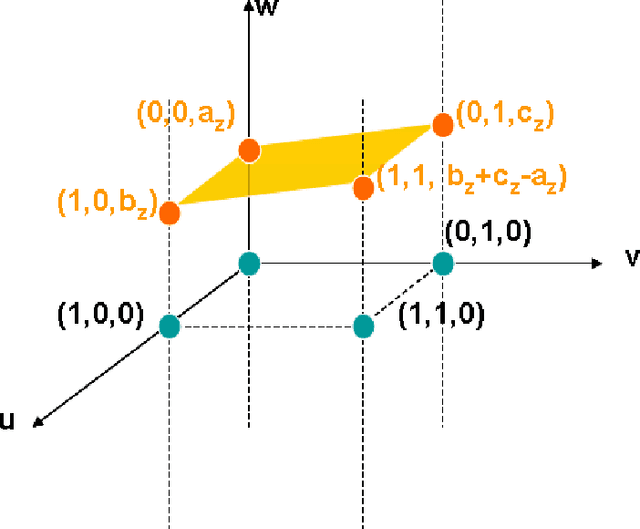
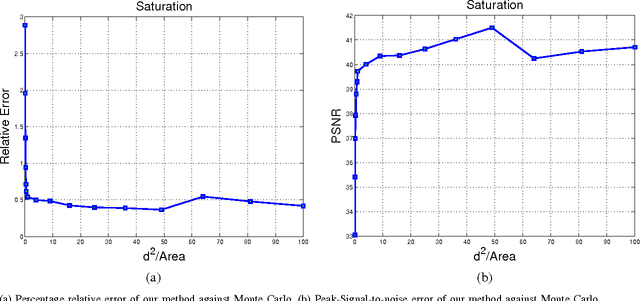
In this paper, we present a new mathematical foundation for image-based lighting. Using a simple manipulation of the local coordinate system, we derive a closed-form solution to the light integral equation under distant environment illumination. We derive our solution for different BRDF's such as lambertian and Phong-like. The method is free of noise, and provides the possibility of using the full spectrum of frequencies captured by images taken from the environment. This allows for the color of the rendered object to be toned according to the color of the light in the environment. Experimental results also show that one can gain an order of magnitude or higher in rendering time compared to Monte Carlo quadrature methods and spherical harmonics.