 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Unlabeled Faces for Novel Attribute Discovery
Dec 06, 2019
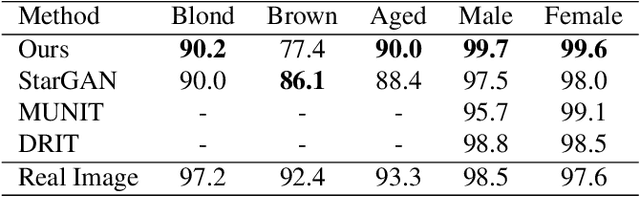

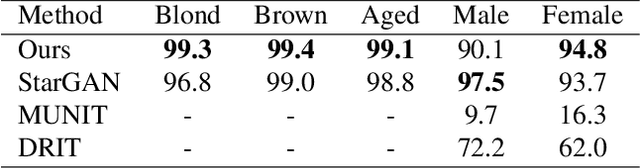

Despite remarkable success in unpaired image-to-image translation, existing systems still require a large amount of labeled images. This is a bottleneck for their real-world applications; in practice, a model trained on labeled CelebA dataset does not work well for test images from a different distribution -- greatly limiting their application to unlabeled images of a much larger quantity. In this paper, we attempt to alleviate this necessity for labeled data in the facial image translation domain. We aim to explore the degree to which you can discover novel attributes from unlabeled faces and perform high-quality translation. To this end, we use prior knowledge about the visual world as guidance to discover novel attributes and transfer them via a novel normalization method. Experiments show that our method trained on unlabeled data produces high-quality translations, preserves identity, and be perceptually realistic as good as, or better than, state-of-the-art methods trained on labeled data.
Sequential image processing methods for improving semantic video segmentation algorithms
Oct 29, 2019
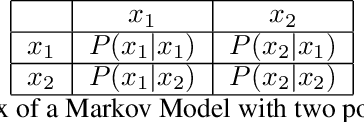

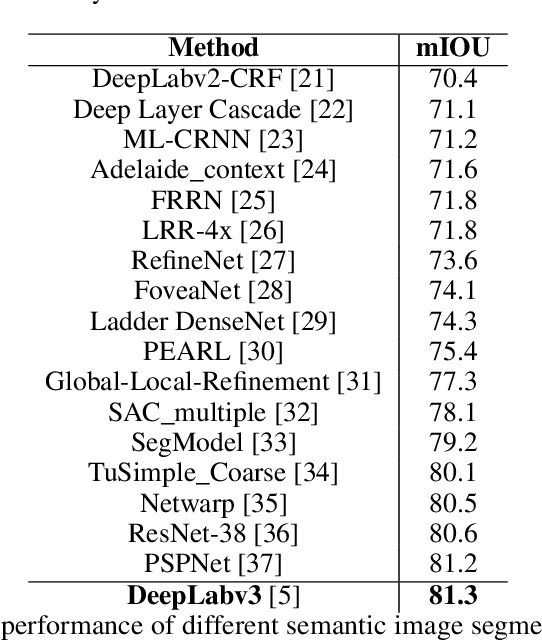
Recently, semantic video segmentation gained high attention especially for supporting autonomous driving systems. Deep learning methods made it possible to implement real time segmentation and object identification algorithms on videos. However, most of the available approaches process each video frame independently disregarding their sequential relation in time. Therefore their results suddenly miss some of the object segments in some of the frames even if they were detected properly in the earlier frames. Herein we propose two sequential probabilistic video frame analysis approaches to improve the segmentation performance of the existing algorithms. Our experiments show that using the information of the past frames we increase the performance and consistency of the state of the art algorithms.
How should a fixed budget of dwell time be spent in scanning electron microscopy to optimize image quality?
Jan 12, 2018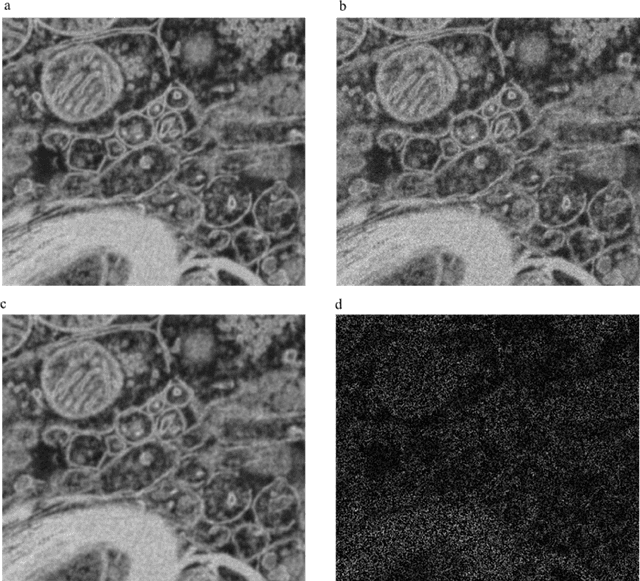
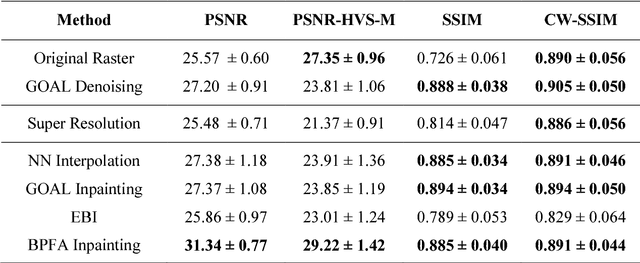

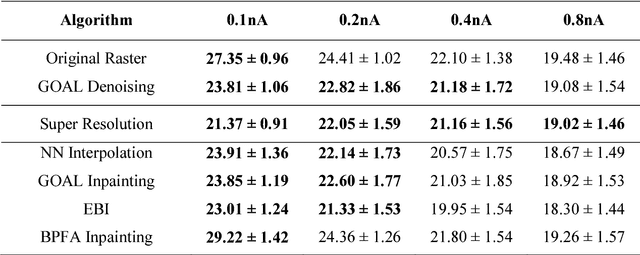
In scanning electron microscopy, the achievable image quality is often limited by a maximum feasible acquisition time per dataset. Particularly with regard to three-dimensional or large field-of-view imaging, a compromise must be found between a high amount of shot noise, which leads to a low signal-to-noise ratio, and excessive acquisition times. Assuming a fixed acquisition time per frame, we compared three different strategies for algorithm-assisted image acquisition in scanning electron microscopy. We evaluated (1) raster scanning with a reduced dwell time per pixel followed by a state-of-the-art Denoising algorithm, (2) raster scanning with a decreased resolution in conjunction with a state-of-the-art Super Resolution algorithm, and (3) a sparse scanning approach where a fixed percentage of pixels is visited by the beam in combination with state-of-the-art inpainting algorithms. Additionally, we considered increased beam currents for each of the strategies. The experiments showed that sparse scanning using an appropriate reconstruction technique was superior to the other strategies.
Adaptive Regularization of Some Inverse Problems in Image Analysis
May 09, 2017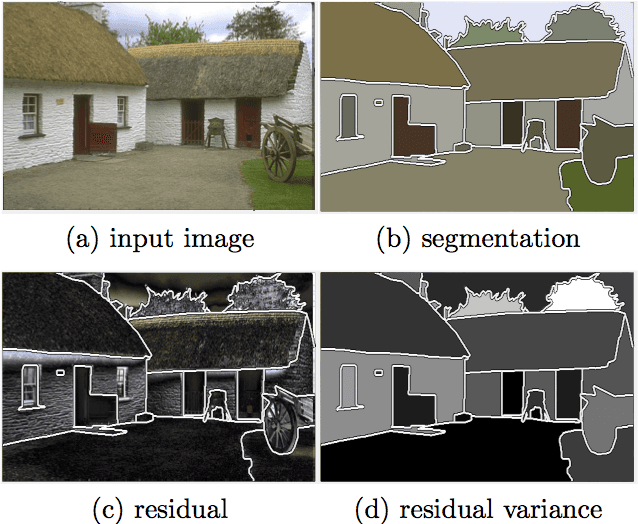
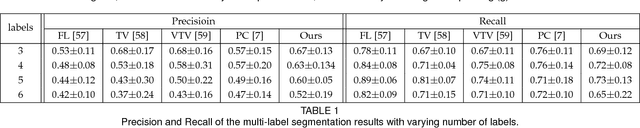
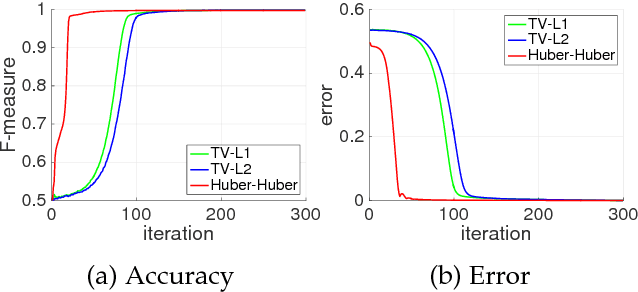
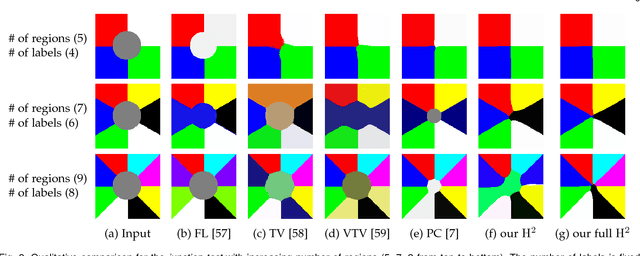
We present an adaptive regularization scheme for optimizing composite energy functionals arising in image analysis problems. The scheme automatically trades off data fidelity and regularization depending on the current data fit during the iterative optimization, so that regularization is strongest initially, and wanes as data fidelity improves, with the weight of the regularizer being minimized at convergence. We also introduce the use of a Huber loss function in both data fidelity and regularization terms, and present an efficient convex optimization algorithm based on the alternating direction method of multipliers (ADMM) using the equivalent relation between the Huber function and the proximal operator of the one-norm. We illustrate and validate our adaptive Huber-Huber model on synthetic and real images in segmentation, motion estimation, and denoising problems.
Fuzzy-Based Dialectical Non-Supervised Image Classification and Clustering
Dec 03, 2017
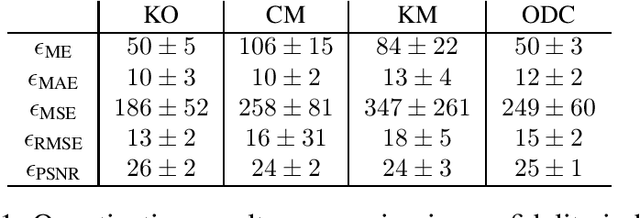
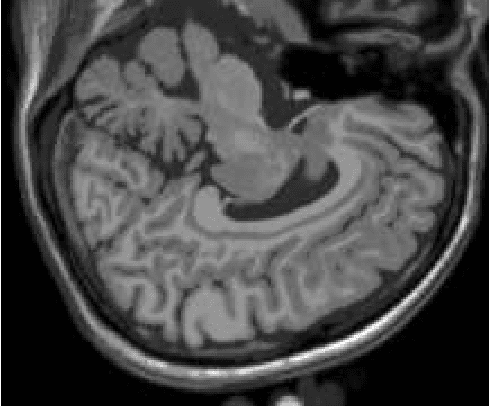
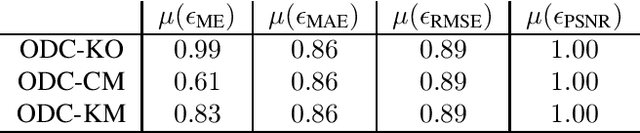
The materialist dialectical method is a philosophical investigative method to analyze aspects of reality. These aspects are viewed as complex processes composed by basic units named poles, which interact with each other. Dialectics has experienced considerable progress in the 19th century, with Hegel's dialectics and, in the 20th century, with the works of Marx, Engels, and Gramsci, in Philosophy and Economics. The movement of poles through their contradictions is viewed as a dynamic process with intertwined phases of evolution and revolutionary crisis. In order to build a computational process based on dialectics, the interaction between poles can be modeled using fuzzy membership functions. Based on this assumption, we introduce the Objective Dialectical Classifier (ODC), a non-supervised map for classification based on materialist dialectics and designed as an extension of fuzzy c-means classifier. As a case study, we used ODC to classify 181 magnetic resonance synthetic multispectral images composed by proton density, $T_1$- and $T_2$-weighted synthetic brain images. Comparing ODC to k-means, fuzzy c-means, and Kohonen's self-organized maps, concerning with image fidelity indexes as estimatives of quantization distortion, we proved that ODC can reach almost the same quantization performance as optimal non-supervised classifiers like Kohonen's self-organized maps.
Assisting Scene Graph Generation with Self-Supervision
Aug 08, 2020

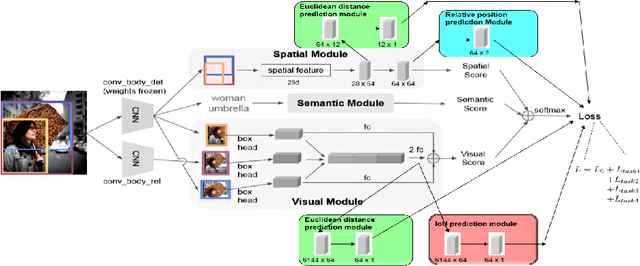

Research in scene graph generation has quickly gained traction in the past few years because of its potential to help in downstream tasks like visual question answering, image captioning, etc. Many interesting approaches have been proposed to tackle this problem. Most of these works have a pre-trained object detection model as a preliminary feature extractor. Therefore, getting object bounding box proposals from the object detection model is relatively cheaper. We take advantage of this ready availability of bounding box annotations produced by the pre-trained detector. We propose a set of three novel yet simple self-supervision tasks and train them as auxiliary multi-tasks to the main model. While comparing, we train the base-model from scratch with these self-supervision tasks, we achieve state-of-the-art results in all the metrics and recall settings. We also resolve some of the confusion between two types of relationships: geometric and possessive, by training the model with the proposed self-supervision losses. We use the benchmark dataset, Visual Genome to conduct our experiments and show our results.
Learning to Teach with Deep Interactions
Jul 09, 2020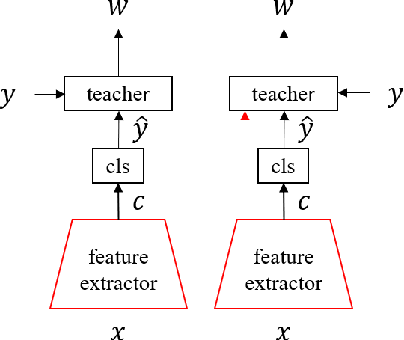
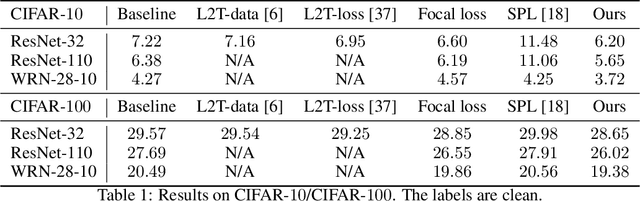

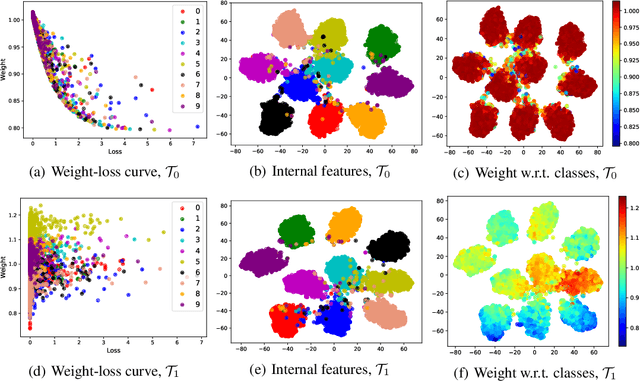
Machine teaching uses a meta/teacher model to guide the training of a student model (which will be used in real tasks) through training data selection, loss function design, etc. Previously, the teacher model only takes shallow/surface information as inputs (e.g., training iteration number, loss and accuracy from training/validation sets) while ignoring the internal states of the student model, which limits the potential of learning to teach. In this work, we propose an improved data teaching algorithm, where the teacher model deeply interacts with the student model by accessing its internal states. The teacher model is jointly trained with the student model using meta gradients propagated from a validation set. We conduct experiments on image classification with clean/noisy labels and empirically demonstrate that our algorithm makes significant improvement over previous data teaching methods.
Can Learned Frame-Prediction Compete with Block-Motion Compensation for Video Coding?
Jul 17, 2020
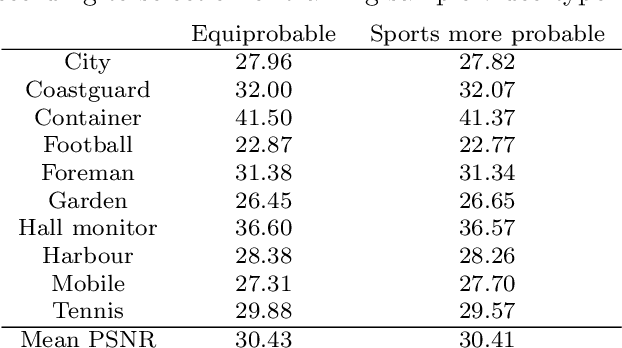
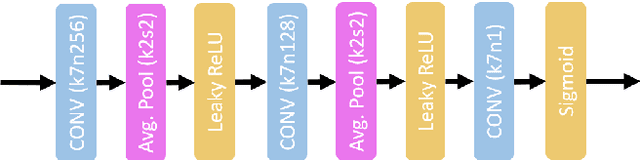
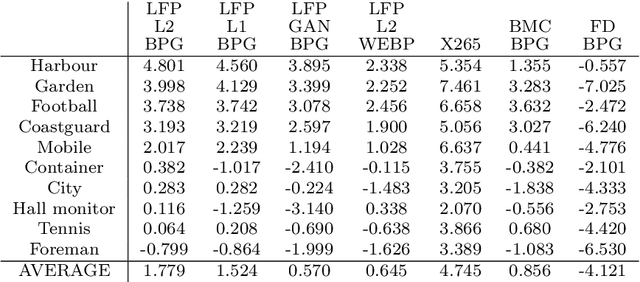
Given recent advances in learned video prediction, we investigate whether a simple video codec using a pre-trained deep model for next frame prediction based on previously encoded/decoded frames without sending any motion side information can compete with standard video codecs based on block-motion compensation. Frame differences given learned frame predictions are encoded by a standard still-image (intra) codec. Experimental results show that the rate-distortion performance of the simple codec with symmetric complexity is on average better than that of x264 codec on 10 MPEG test videos, but does not yet reach the level of x265 codec. This result demonstrates the power of learned frame prediction (LFP), since unlike motion compensation, LFP does not use information from the current picture. The implications of training with L1, L2, or combined L2 and adversarial loss on prediction performance and compression efficiency are analyzed.
Dominant Sets for "Constrained" Image Segmentation
Jul 15, 2017
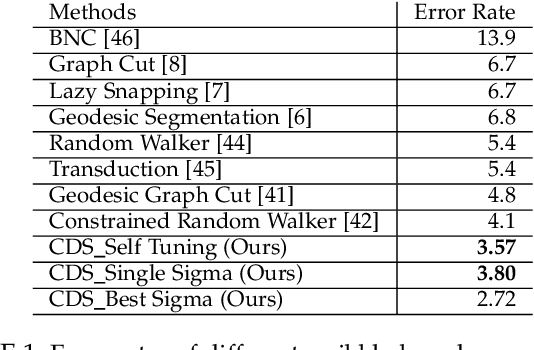

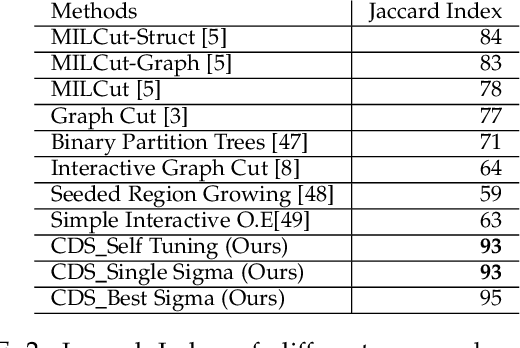
Image segmentation has come a long way since the early days of computer vision, and still remains a challenging task. Modern variations of the classical (purely bottom-up) approach, involve, e.g., some form of user assistance (interactive segmentation) or ask for the simultaneous segmentation of two or more images (co-segmentation). At an abstract level, all these variants can be thought of as "constrained" versions of the original formulation, whereby the segmentation process is guided by some external source of information. In this paper, we propose a new approach to tackle this kind of problems in a unified way. Our work is based on some properties of a family of quadratic optimization problems related to dominant sets, a well-known graph-theoretic notion of a cluster which generalizes the concept of a maximal clique to edge-weighted graphs. In particular, we show that by properly controlling a regularization parameter which determines the structure and the scale of the underlying problem, we are in a position to extract groups of dominant-set clusters that are constrained to contain predefined elements. In particular, we shall focus on interactive segmentation and co-segmentation (in both the unsupervised and the interactive versions). The proposed algorithm can deal naturally with several type of constraints and input modality, including scribbles, sloppy contours, and bounding boxes, and is able to robustly handle noisy annotations on the part of the user. Experiments on standard benchmark datasets show the effectiveness of our approach as compared to state-of-the-art algorithms on a variety of natural images under several input conditions and constraints.
Anisotropic 3D Multi-Stream CNN for Accurate Prostate Segmentation from Multi-Planar MRI
Sep 23, 2020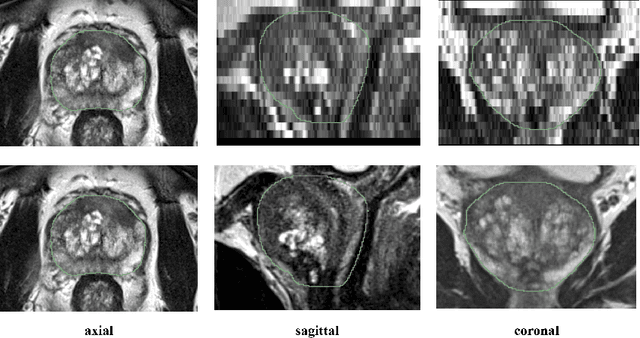

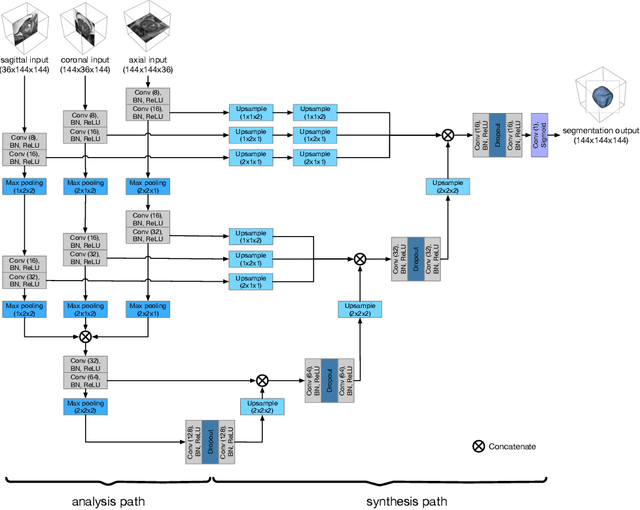

Background and Objective: Accurate and reliable segmentation of the prostate gland in MR images can support the clinical assessment of prostate cancer, as well as the planning and monitoring of focal and loco-regional therapeutic interventions. Despite the availability of multi-planar MR scans due to standardized protocols, the majority of segmentation approaches presented in the literature consider the axial scans only. Methods: We propose an anisotropic 3D multi-stream CNN architecture, which processes additional scan directions to produce a higher-resolution isotropic prostate segmentation. We investigate two variants of our architecture, which work on two (dual-plane) and three (triple-plane) image orientations, respectively. We compare them with the standard baseline (single-plane) used in literature, i.e., plain axial segmentation. To realize a fair comparison, we employ a hyperparameter optimization strategy to select optimal configurations for the individual approaches. Results: Training and evaluation on two datasets spanning multiple sites obtain statistical significant improvement over the plain axial segmentation ($p<0.05$ on the Dice similarity coefficient). The improvement can be observed especially at the base ($0.898$ single-plane vs. $0.906$ triple-plane) and apex ($0.888$ single-plane vs. $0.901$ dual-plane). Conclusion: This study indicates that models employing two or three scan directions are superior to plain axial segmentation. The knowledge of precise boundaries of the prostate is crucial for the conservation of risk structures. Thus, the proposed models have the potential to improve the outcome of prostate cancer diagnosis and therapies.