 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Assisting Scene Graph Generation with Self-Supervision
Aug 08, 2020


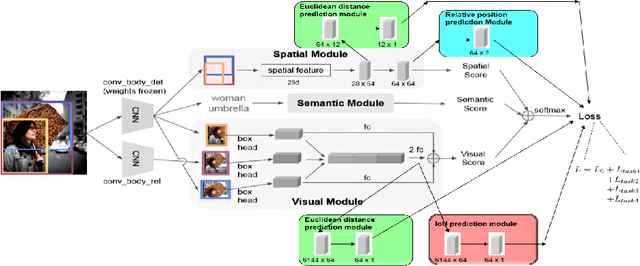

Research in scene graph generation has quickly gained traction in the past few years because of its potential to help in downstream tasks like visual question answering, image captioning, etc. Many interesting approaches have been proposed to tackle this problem. Most of these works have a pre-trained object detection model as a preliminary feature extractor. Therefore, getting object bounding box proposals from the object detection model is relatively cheaper. We take advantage of this ready availability of bounding box annotations produced by the pre-trained detector. We propose a set of three novel yet simple self-supervision tasks and train them as auxiliary multi-tasks to the main model. While comparing, we train the base-model from scratch with these self-supervision tasks, we achieve state-of-the-art results in all the metrics and recall settings. We also resolve some of the confusion between two types of relationships: geometric and possessive, by training the model with the proposed self-supervision losses. We use the benchmark dataset, Visual Genome to conduct our experiments and show our results.
Optimizing Codes for Source Separation in Color Image Demosaicing and Compressive Video Recovery
Jul 11, 2017


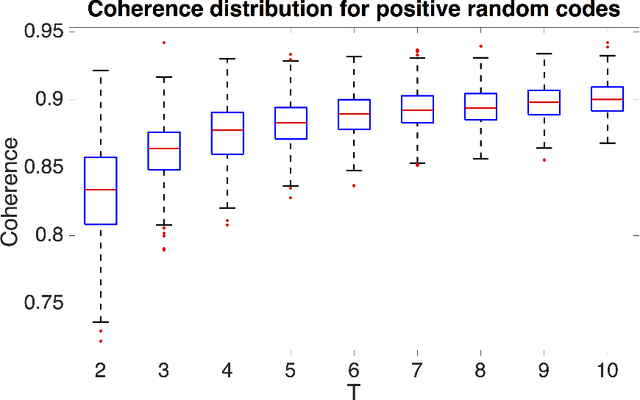
There exist several applications in image processing (eg: video compressed sensing [Hitomi, Y. et al, "Video from a single coded exposure photograph using a learned overcomplete dictionary"] and color image demosaicing [Moghadam, A. A. et al, "Compressive Framework for Demosaicing of Natural Images"]) which require separation of constituent images given measurements in the form of a coded superposition of those images. Physically practical code patterns in these applications are non-negative, systematically structured, and do not always obey the nice incoherence properties of other patterns such as Gaussian codes, which can adversely affect reconstruction performance. The contribution of this paper is to design code patterns for video compressed sensing and demosaicing by minimizing the mutual coherence of the matrix $\boldsymbol{\Phi \Psi}$ where $\boldsymbol{\Phi}$ represents the sensing matrix created from the code, and $\boldsymbol{\Psi}$ is the signal representation matrix. Our main contribution is that we explicitly take into account the special structure of those code patterns as required by these applications: (1)~non-negativity, (2)~block-diagonal nature, and (3)~circular shifting. In particular, the last property enables for accurate and seamless patch-wise reconstruction for some important compressed sensing architectures.
Training Object Detectors from Few Weakly-Labeled and Many Unlabeled Images
Dec 01, 2019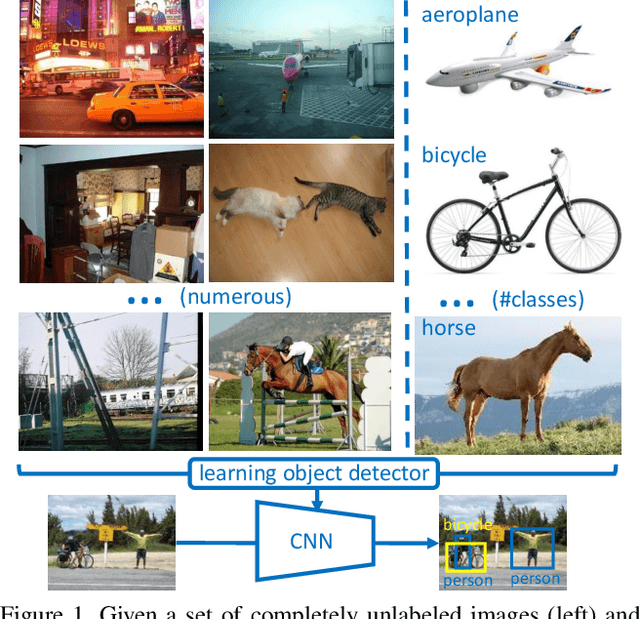


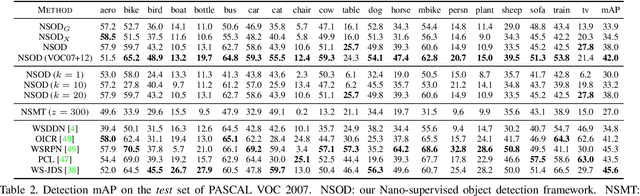
Weakly-supervised object detection attempts to limit the amount of supervision by dispensing the need for bounding boxes, but still assumes image-level labels on the entire training set are available. In this work, we study the problem of training an object detector from one or few clean images with image-level labels and a larger set of completely unlabeled images. This is an extreme case of semi-supervised learning where the labeled data are not enough to bootstrap the learning of a classifier or detector. Our solution is to use a standard weakly-supervised pipeline to train a student model from image-level pseudo-labels generated on the unlabeled set by a teacher model, bootstrapped by region-level similarities to clean labeled images. By using the recent pipeline of PCL and more unlabeled images, we achieve performance competitive or superior to many state of the art weakly-supervised detection solutions.
Joint Optimization of Sampling Patterns and Deep Priors for Improved Parallel MRI
Nov 06, 2019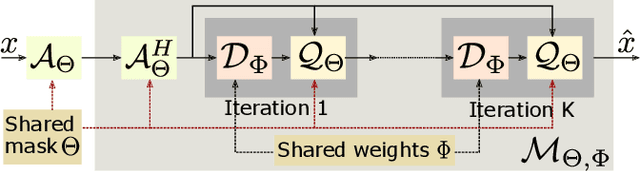
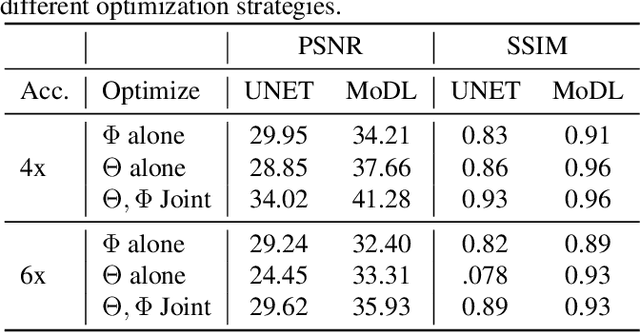
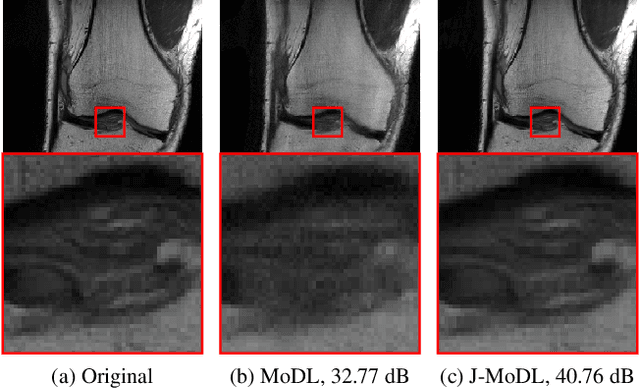
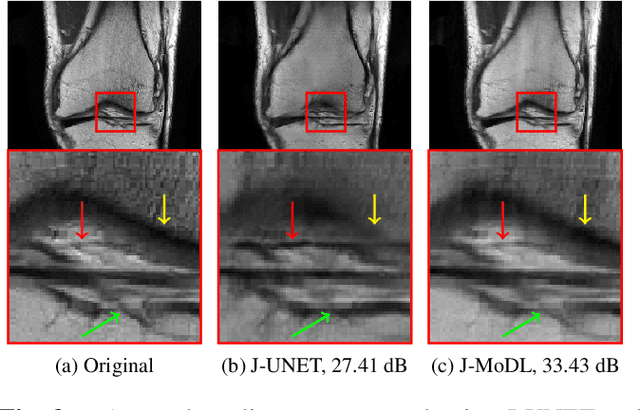
Multichannel imaging techniques are widely used in MRI to reduce the scan time. These schemes typically perform undersampled acquisition and utilize compressed-sensing based regularized reconstruction algorithms. Model-based deep learning (MoDL) frameworks are now emerging as powerful alternatives to compressed sensing, with significantly improved image quality. In this work, we investigate the impact of sampling patterns on the quality of the image recovered using the MoDL algorithm. We introduce a scheme to jointly optimize the sampling pattern and the reconstruction network parameters in MoDL for parallel MRI. The improved decoupling of the network parameters from the sampling patterns offered by the MoDL scheme translates to improved optimization and thus improved performance. Preliminary experimental results demonstrate that the proposed joint optimization framework significantly improves the image quality.
Dissimilarity Mixture Autoencoder for Deep Clustering
Jun 22, 2020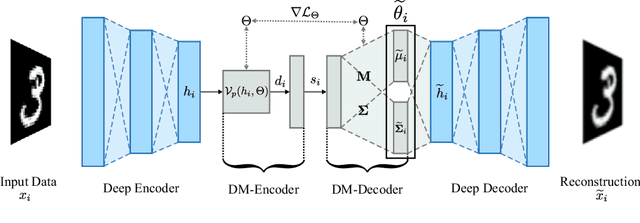
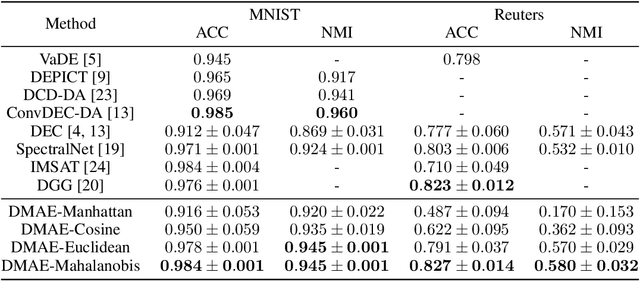
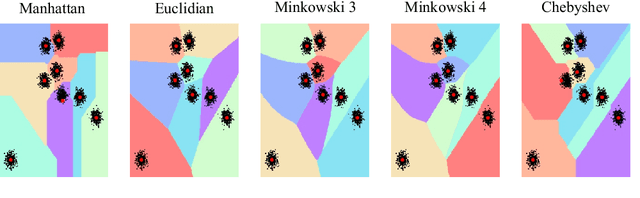
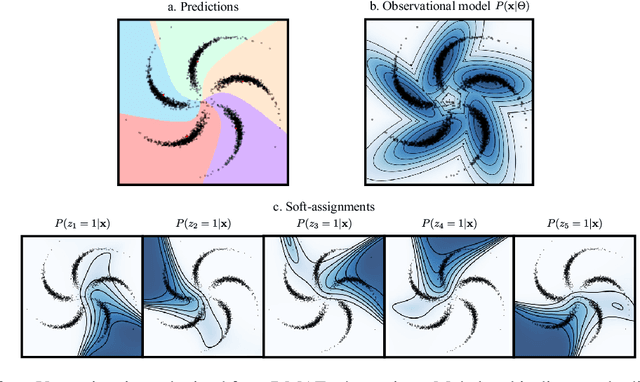
In this paper, we introduce the Dissimilarity Mixture Autoencoder (DMAE), a novel neural network model that uses a dissimilarity function to generalize a family of density estimation and clustering methods. It is formulated in such a way that it internally estimates the parameters of a probability distribution through gradient-based optimization. Also, the proposed model can leverage from deep representation learning due to its straightforward incorporation into deep learning architectures, because, it consists of an encoder-decoder network that computes a probabilistic representation. Experimental evaluation was performed on image and text clustering benchmark datasets showing that the method is competitive in terms of unsupervised classification accuracy and normalized mutual information. The source code to replicate the experiments is publicly available at https://github.com/larajuse/DMAE
Image Retrieval And Classification Using Local Feature Vectors
Sep 02, 2014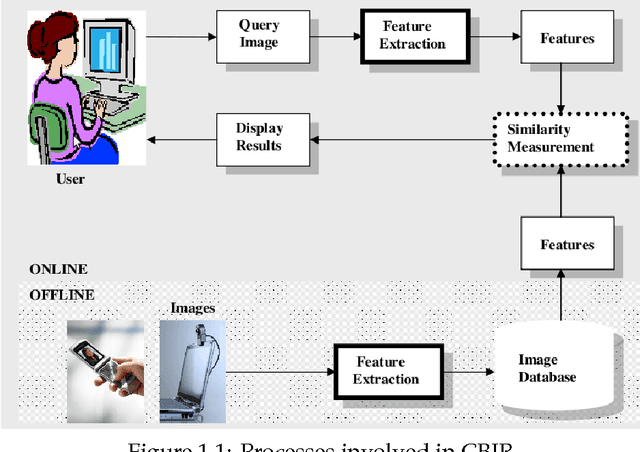
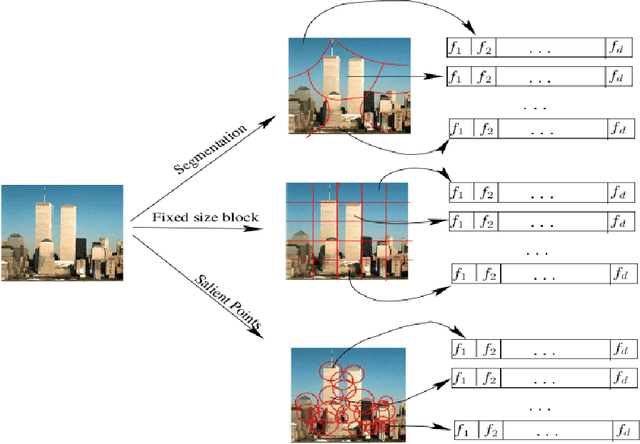
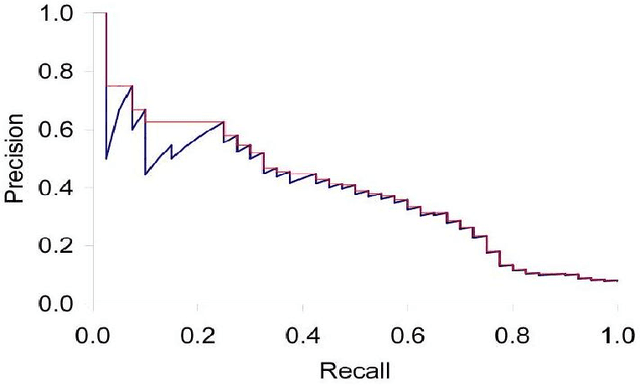
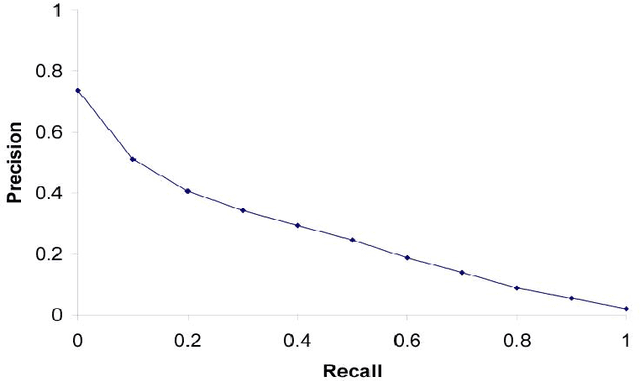
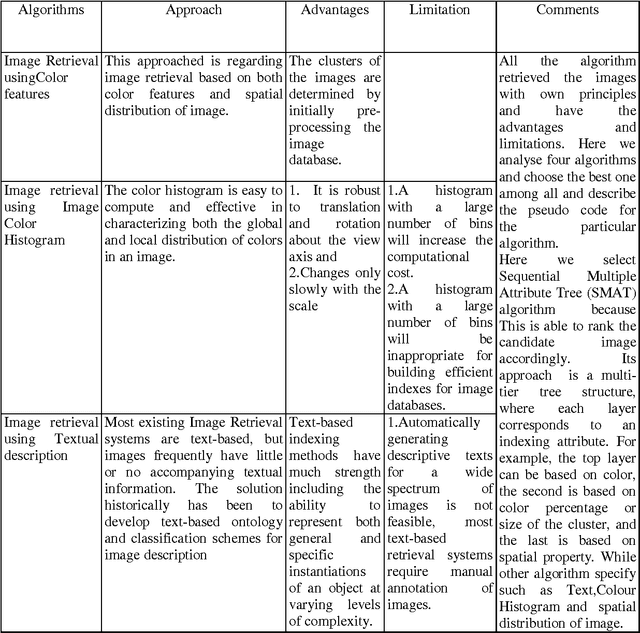
Content Based Image Retrieval(CBIR) is one of the important subfield in the field of Information Retrieval. The goal of a CBIR algorithm is to retrieve semantically similar images in response to a query image submitted by the end user. CBIR is a hard problem because of the phenomenon known as $\textit {semantic gap}$. In this thesis, we aim at analyzing the performance of a CBIR system build using local feature vectors and Intermediate Matching Kernel. We also propose a Two-Step Matching process for reducing the response time of the CBIR systems. Further, we develop a Meta-Learning framework for improving the retrieval performance of these systems. Our results show that the Two-Step Matching process significantly reduces response time and the Meta-Learning Framework improves the retrieval performance by more than two fold. We also analyze the performance of various image classification systems that use different image representations constructed from the local feature vectors.
Sequential image processing methods for improving semantic video segmentation algorithms
Oct 29, 2019
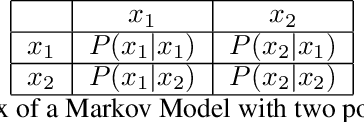

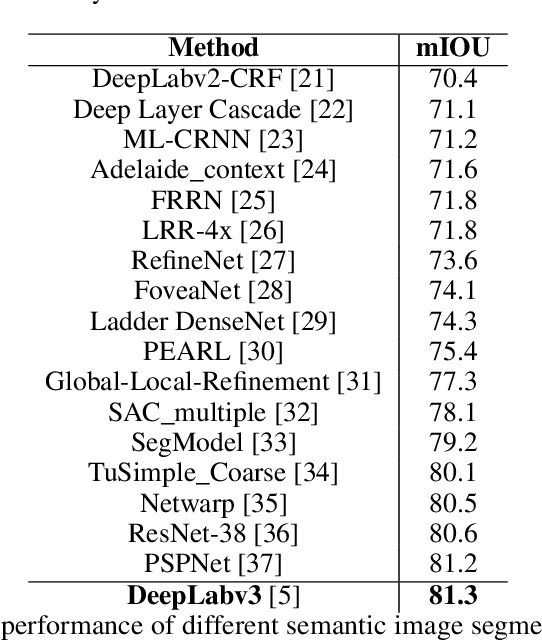
Recently, semantic video segmentation gained high attention especially for supporting autonomous driving systems. Deep learning methods made it possible to implement real time segmentation and object identification algorithms on videos. However, most of the available approaches process each video frame independently disregarding their sequential relation in time. Therefore their results suddenly miss some of the object segments in some of the frames even if they were detected properly in the earlier frames. Herein we propose two sequential probabilistic video frame analysis approaches to improve the segmentation performance of the existing algorithms. Our experiments show that using the information of the past frames we increase the performance and consistency of the state of the art algorithms.
Coarse to fine non-rigid registration: a chain of scale-specific neural networks for multimodal image alignment with application to remote sensing
Feb 27, 2018

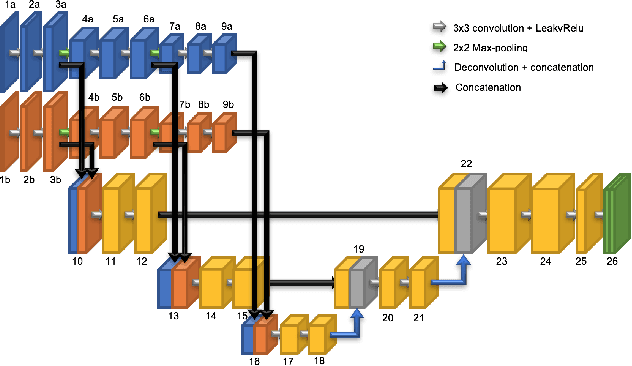
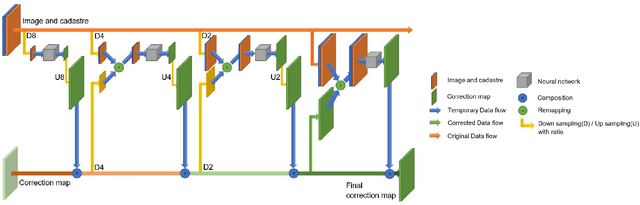
We tackle here the problem of multimodal image non-rigid registration, which is of prime importance in remote sensing and medical imaging. The difficulties encountered by classical registration approaches include feature design and slow optimization by gradient descent. By analyzing these methods, we note the significance of the notion of scale. We design easy-to-train, fully-convolutional neural networks able to learn scale-specific features. Once chained appropriately, they perform global registration in linear time, getting rid of gradient descent schemes by predicting directly the deformation.We show their performance in terms of quality and speed through various tasks of remote sensing multimodal image alignment. In particular, we are able to register correctly cadastral maps of buildings as well as road polylines onto RGB images, and outperform current keypoint matching methods.
Content Based Image Indexing and Retrieval
Jan 08, 2014
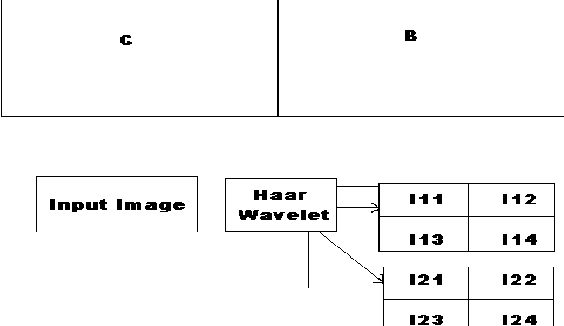

In this paper, we present the efficient content based image retrieval systems which employ the color, texture and shape information of images to facilitate the retrieval process. For efficient feature extraction, we extract the color, texture and shape feature of images automatically using edge detection which is widely used in signal processing and image compression. For facilitated the speedy retrieval we are implements the antipole-tree algorithm for indexing the images.
* 12 pages
Bidirectional Mapping Generative Adversarial Networks for Brain MR to PET Synthesis
Aug 08, 2020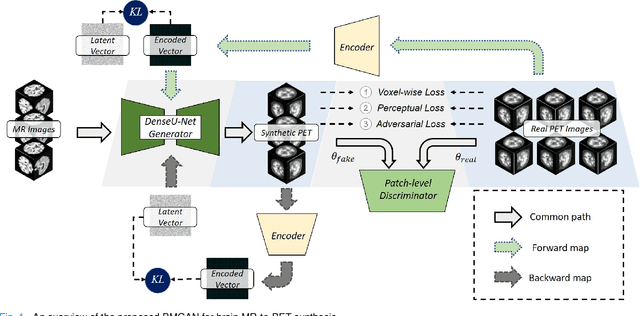
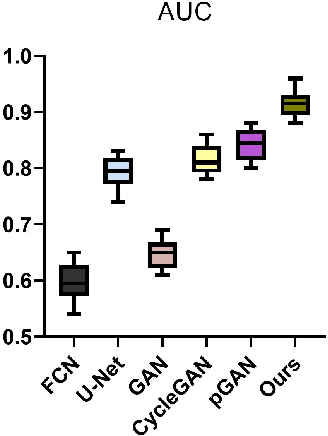
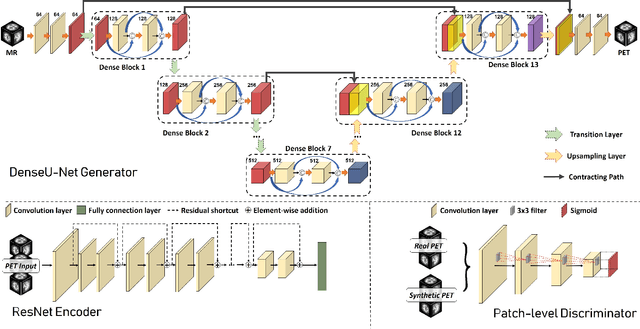
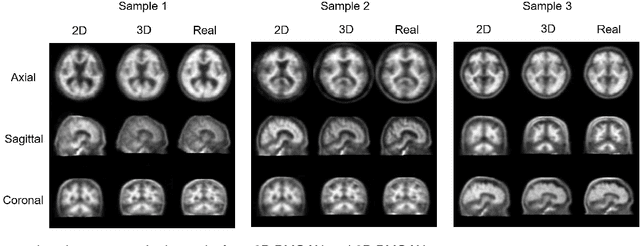
Fusing multi-modality medical images, such as MR and PET, can provide various anatomical or functional information about human body. But PET data is always unavailable due to different reasons such as cost, radiation, or other limitations. In this paper, we propose a 3D end-to-end synthesis network, called Bidirectional Mapping Generative Adversarial Networks (BMGAN), where image contexts and latent vector are effectively used and jointly optimized for brain MR-to-PET synthesis. Concretely, a bidirectional mapping mechanism is designed to embed the semantic information of PET images into the high dimensional latent space. And the 3D DenseU-Net generator architecture and the extensive objective functions are further utilized to improve the visual quality of synthetic results. The most appealing part is that the proposed method can synthesize the perceptually realistic PET images while preserving the diverse brain structures of different subjects. Experimental results demonstrate that the performance of the proposed method outperforms other competitive cross-modality synthesis methods in terms of quantitative measures, qualitative displays, and classification evaluation.