 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Diverse Latent Representations for Improving the Resilience to Adversarial Attacks
Jun 26, 2020
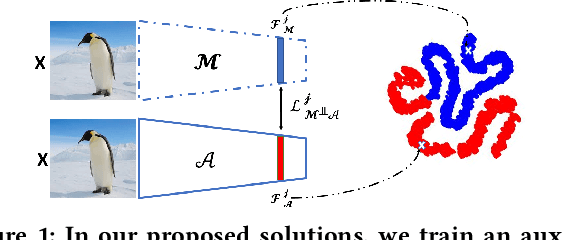
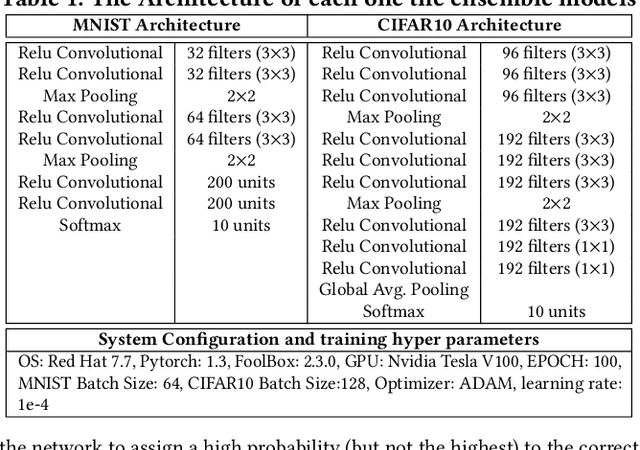
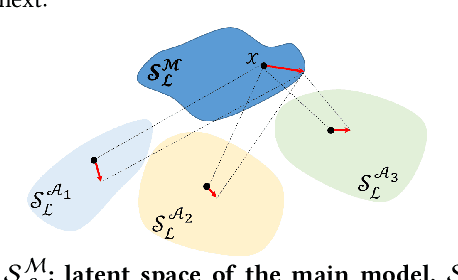
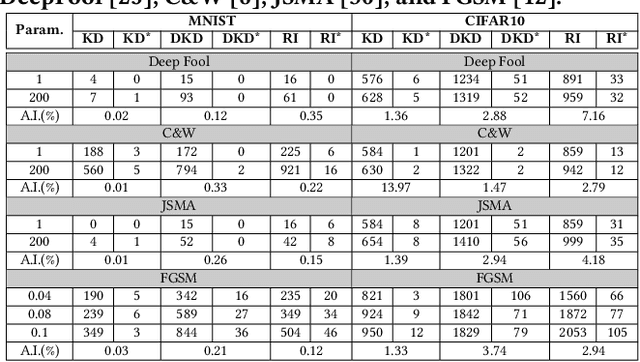
This paper proposes an ensemble learning model that is resistant to adversarial learning attacks. To build resilience, we proposed a training process where each member learns a radically different latent space. Member models are added one at a time to the ensemble. Each model is trained on data set to improve accuracy, while the loss function is regulated by a reverse knowledge distillation, forcing the new member to learn new features and map to a latent space safely distanced from those of existing members. We have evaluated the reliability and performance of the proposed solution on image classification tasks using CIFAR10 and MNIST datasets and show improved performance compared to the state of the art defense methods
Learning to Detect Important People in Unlabelled Images for Semi-supervised Important People Detection
Apr 16, 2020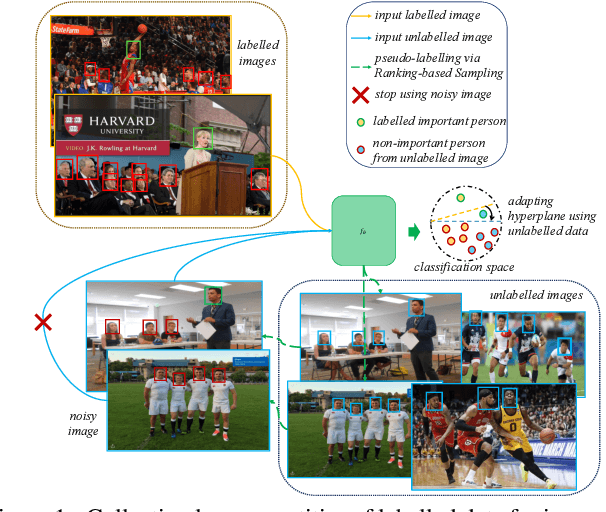
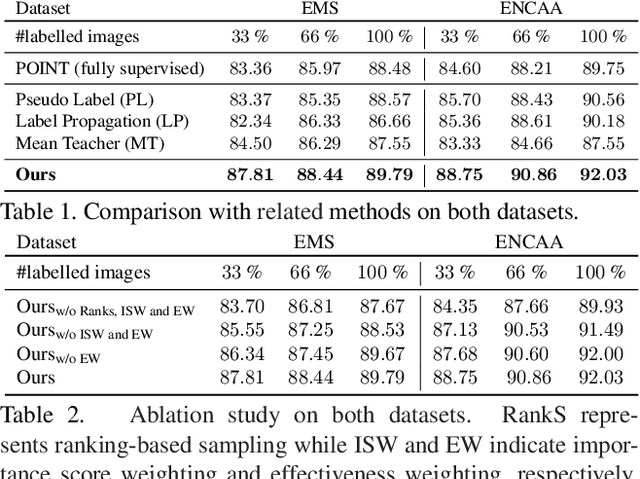
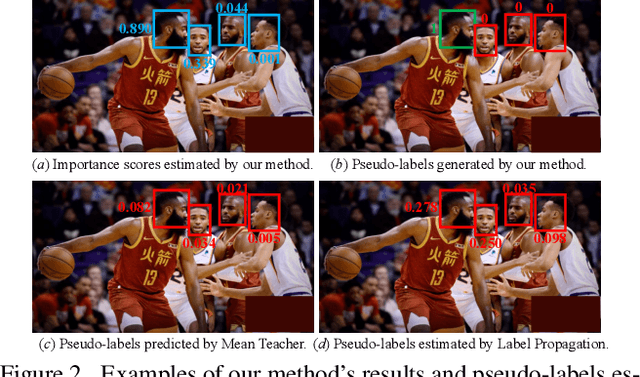
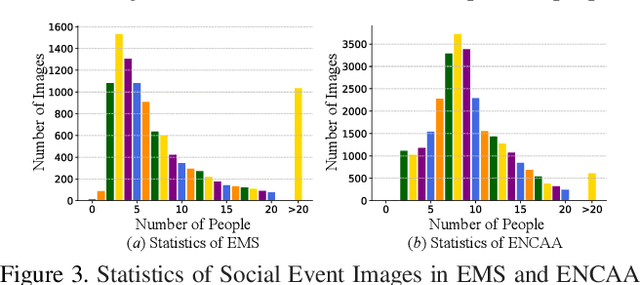
Important people detection is to automatically detect the individuals who play the most important roles in a social event image, which requires the designed model to understand a high-level pattern. However, existing methods rely heavily on supervised learning using large quantities of annotated image samples, which are more costly to collect for important people detection than for individual entity recognition (eg, object recognition). To overcome this problem, we propose learning important people detection on partially annotated images. Our approach iteratively learns to assign pseudo-labels to individuals in un-annotated images and learns to update the important people detection model based on data with both labels and pseudo-labels. To alleviate the pseudo-labelling imbalance problem, we introduce a ranking strategy for pseudo-label estimation, and also introduce two weighting strategies: one for weighting the confidence that individuals are important people to strengthen the learning on important people and the other for neglecting noisy unlabelled images (ie, images without any important people). We have collected two large-scale datasets for evaluation. The extensive experimental results clearly confirm the efficacy of our method attained by leveraging unlabelled images for improving the performance of important people detection.
LRCN-RetailNet: A recurrent neural network architecture for accurate people counting
May 12, 2020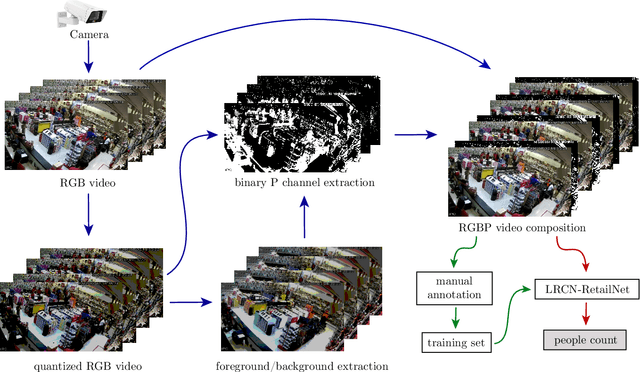
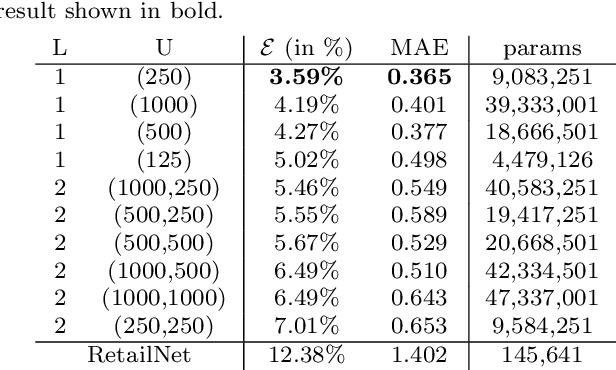
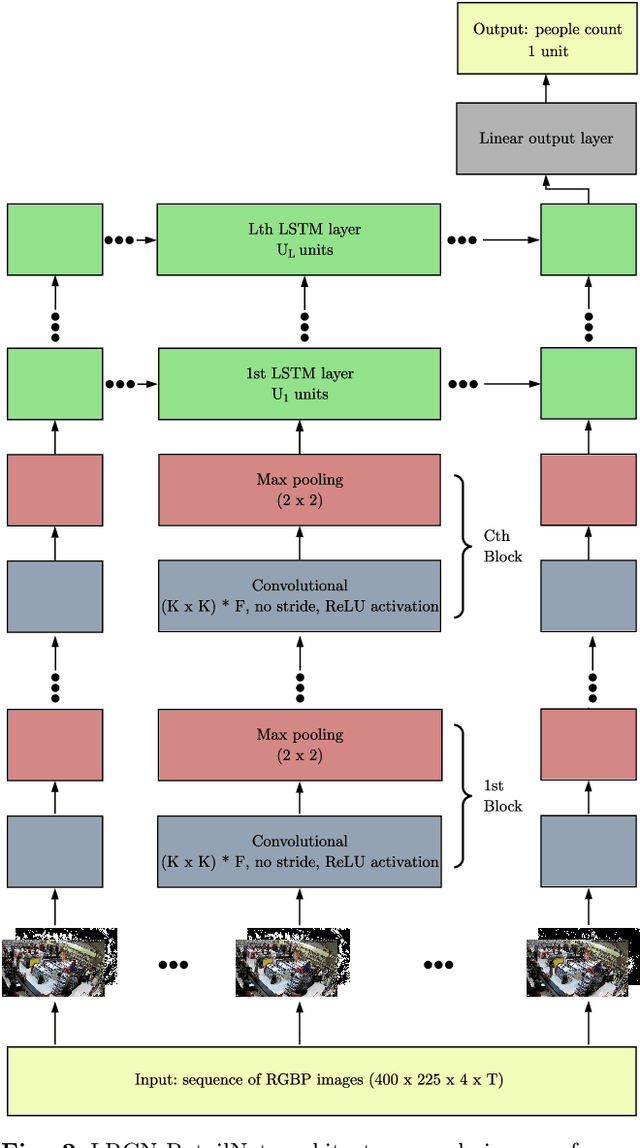
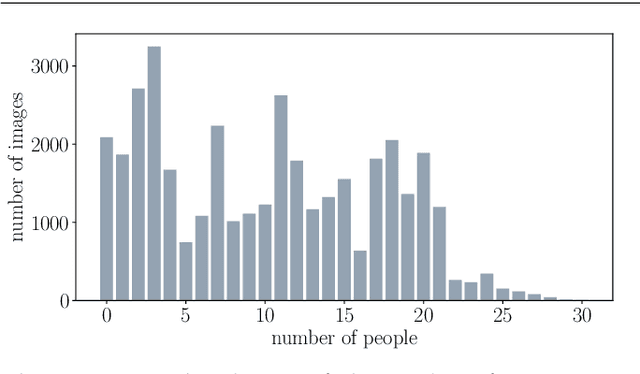
Measuring and analyzing the flow of customers in retail stores is essential for a retailer to better comprehend customers' behavior and support decision-making. Nevertheless, not much attention has been given to the development of novel technologies for automatic people counting. We introduce LRCN-RetailNet: a recurrent neural network architecture capable of learning a non-linear regression model and accurately predicting the people count from videos captured by low-cost surveillance cameras. The input video format follows the recently proposed RGBP image format, which is comprised of color and people (foreground) information. Our architecture is capable of considering two relevant aspects: spatial features extracted through convolutional layers from the RGBP images; and the temporal coherence of the problem, which is exploited by recurrent layers. We show that, through a supervised learning approach, the trained models are capable of predicting the people count with high accuracy. Additionally, we present and demonstrate that a straightforward modification of the methodology is effective to exclude salespeople from the people count. Comprehensive experiments were conducted to validate, evaluate and compare the proposed architecture. Results corroborated that LRCN-RetailNet remarkably outperforms both the previous RetailNet architecture, which was limited to evaluating a single image per iteration; and a state-of-the-art neural network for object detection. Finally, computational performance experiments confirmed that the entire methodology is effective to estimate people count in real-time.
S$^{2}$OMGAN: Shortcut from Remote Sensing Images to Online Maps
Jan 21, 2020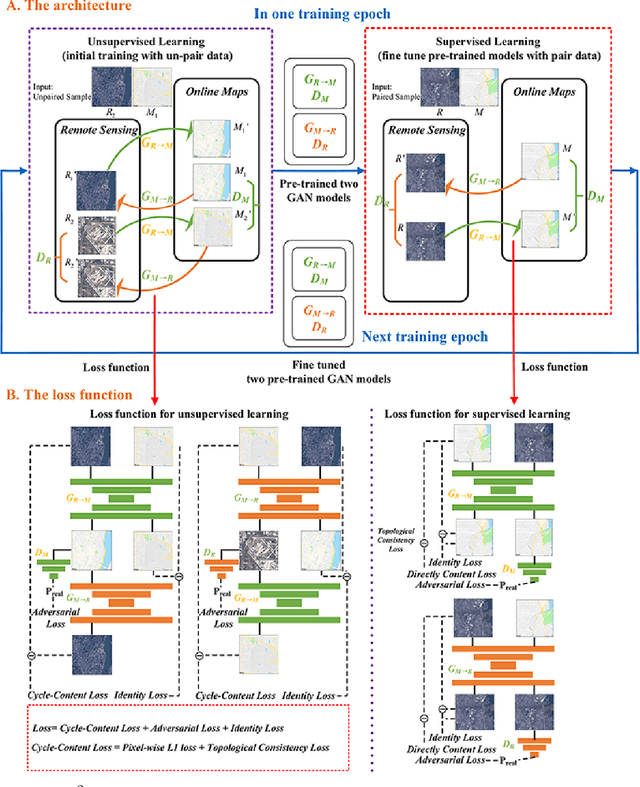
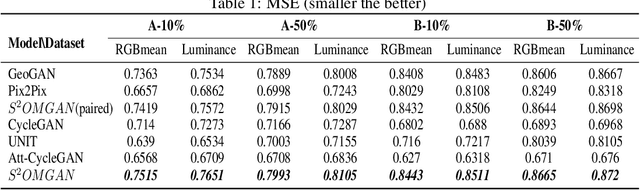
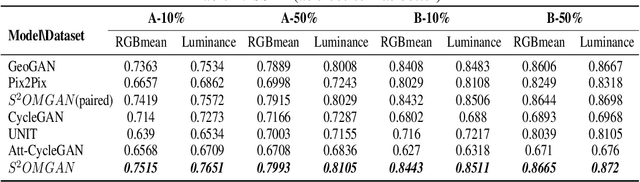
Traditional online maps, widely used on Internet such as Google map and Baidu map, are rendered from vector data. Timely updating online maps from vector data, of which the generating is time-consuming, is a difficult mission. It is a shortcut to generate online maps in time from remote sensing images, which can be acquired timely without vector data. However, this mission used to be challenging or even impossible. Inspired by image-to-image translation (img2img) techniques based on generative adversarial network (GAN), we propose a semi-supervised structure-augmented online map GAN (S$^{2}$OMGAN) model to generate online maps directly from remote sensing images. In this model, we designed a semi-supervised learning strategy to pre-train S$^{2}$OMGAN on rich unpaired samples and finetune it on limited paired samples in reality. We also designed image gradient L1 loss and image gradient structure loss to generate an online map with global topological relationship and detailed edge curves of objects, which are important in cartography. Moreover, we propose edge structural similarity index (ESSI) as a metric to evaluate the quality of topological consistency between generated online maps and ground truths. Experimental results present that S$^{2}$OMGAN outperforms state-of-the-art (SOTA) works according to mean squared error, structural similarity index and ESSI. Also, S$^{2}$OMGAN wins more approval than SOTA in the human perceptual test on visual realism of cartography. Our work shows that S$^{2}$OMGAN is potentially a new paradigm to produce online maps. Our implementation of the S$^{2}$OMGAN is available at \url{https://github.com/imcsq/S2OMGAN}.
Improving the Speed and Quality of GAN by Adversarial Training
Aug 07, 2020
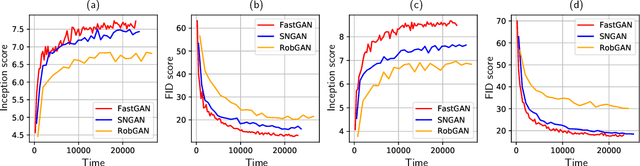
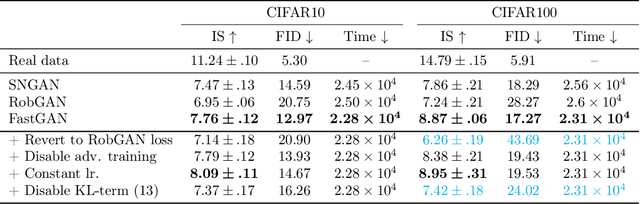

Generative adversarial networks (GAN) have shown remarkable results in image generation tasks. High fidelity class-conditional GAN methods often rely on stabilization techniques by constraining the global Lipschitz continuity. Such regularization leads to less expressive models and slower convergence speed; other techniques, such as the large batch training, require unconventional computing power and are not widely accessible. In this paper, we develop an efficient algorithm, namely FastGAN (Free AdverSarial Training), to improve the speed and quality of GAN training based on the adversarial training technique. We benchmark our method on CIFAR10, a subset of ImageNet, and the full ImageNet datasets. We choose strong baselines such as SNGAN and SAGAN; the results demonstrate that our training algorithm can achieve better generation quality (in terms of the Inception score and Frechet Inception distance) with less overall training time. Most notably, our training algorithm brings ImageNet training to the broader public by requiring 2-4 GPUs.
Robust Template Matching via Hierarchical Convolutional Features from a Shape Biased CNN
Jul 31, 2020

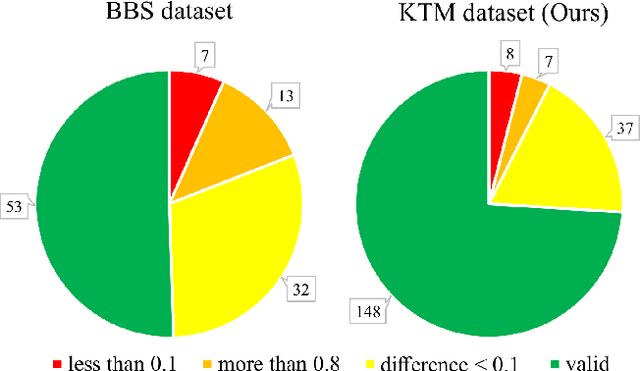
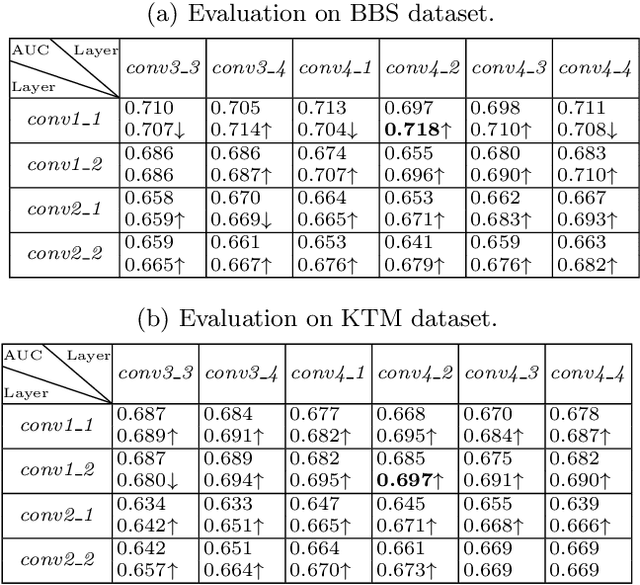
Finding a template in a search image is an important task underlying many computer vision applications. Recent approaches perform template matching in a feature-space, such as that produced by a convolutional neural network (CNN), that provides more tolerance to changes in appearance. In this article we investigate combining features from different layers of a CNN in order to obtain a feature-space that allows both precise and tolerant template matching. Furthermore we investigate if enhancing the encoding of shape information by the CNN can improve the performance of template matching. These investigations result in a new template matching method that produces state-of-the-art results on a standard benchmark. To confirm these results we also create a new benchmark and show that the proposed method also outperforms existing techniques on this new dataset. We further applied the proposed method to tracking and achieved more robust results.
Image Representation Learning Using Graph Regularized Auto-Encoders
Feb 19, 2014
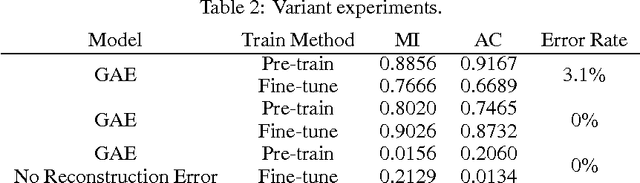
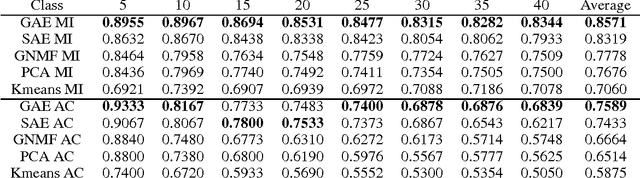
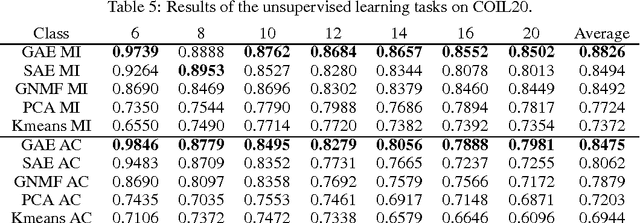
We consider the problem of image representation for the tasks of unsupervised learning and semi-supervised learning. In those learning tasks, the raw image vectors may not provide enough representation for their intrinsic structures due to their highly dense feature space. To overcome this problem, the raw image vectors should be mapped to a proper representation space which can capture the latent structure of the original data and represent the data explicitly for further learning tasks such as clustering. Inspired by the recent research works on deep neural network and representation learning, in this paper, we introduce the multiple-layer auto-encoder into image representation, we also apply the locally invariant ideal to our image representation with auto-encoders and propose a novel method, called Graph regularized Auto-Encoder (GAE). GAE can provide a compact representation which uncovers the hidden semantics and simultaneously respects the intrinsic geometric structure. Extensive experiments on image clustering show encouraging results of the proposed algorithm in comparison to the state-of-the-art algorithms on real-word cases.
Biased Mixtures Of Experts: Enabling Computer Vision Inference Under Data Transfer Limitations
Aug 21, 2020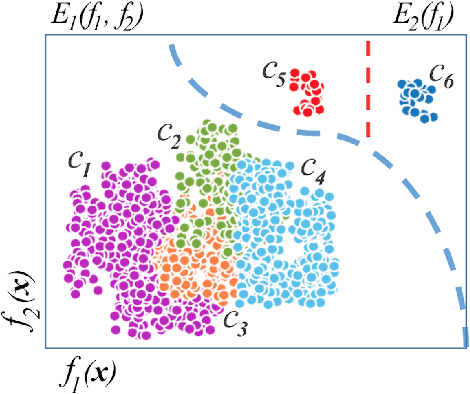
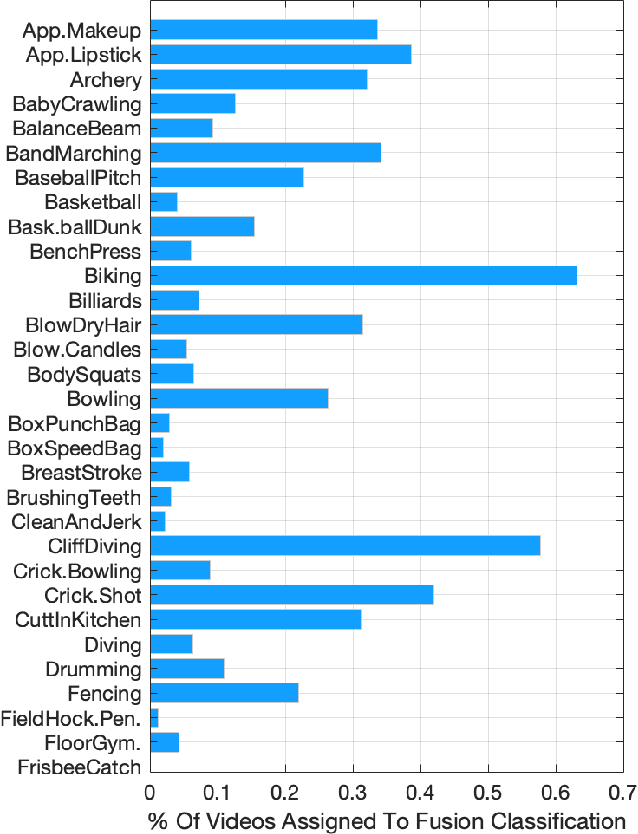
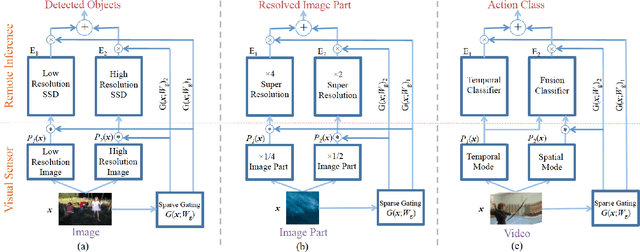
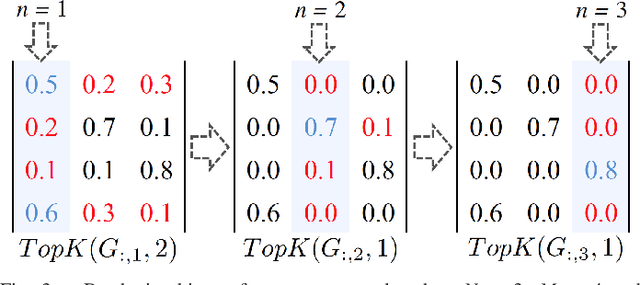
We propose a novel mixture-of-experts class to optimize computer vision models in accordance with data transfer limitations at test time. Our approach postulates that the minimum acceptable amount of data allowing for highly-accurate results can vary for different input space partitions. Therefore, we consider mixtures where experts require different amounts of data, and train a sparse gating function to divide the input space for each expert. By appropriate hyperparameter selection, our approach is able to bias mixtures of experts towards selecting specific experts over others. In this way, we show that the data transfer optimization between visual sensing and processing can be solved as a convex optimization problem.To demonstrate the relation between data availability and performance, we evaluate biased mixtures on a range of mainstream computer vision problems, namely: (i) single shot detection, (ii) image super resolution, and (iii) realtime video action classification. For all cases, and when experts constitute modified baselines to meet different limits on allowed data utility, biased mixtures significantly outperform previous work optimized to meet the same constraints on available data.
Domain Contrast for Domain Adaptive Object Detection
Jun 26, 2020
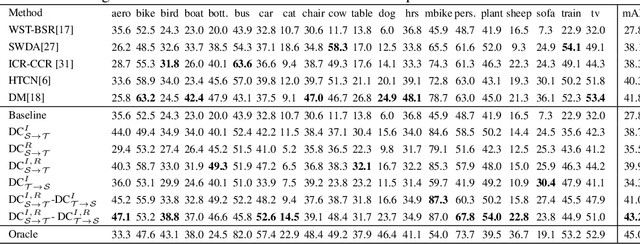
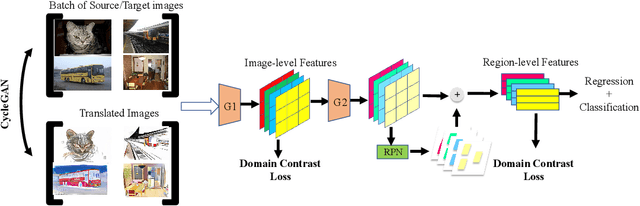
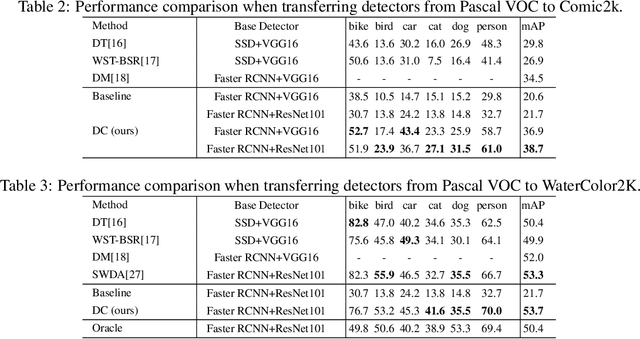
We present Domain Contrast (DC), a simple yet effective approach inspired by contrastive learning for training domain adaptive detectors. DC is deduced from the error bound minimization perspective of a transferred model, and is implemented with cross-domain contrast loss which is plug-and-play. By minimizing cross-domain contrast loss, DC guarantees the transferability of detectors while naturally alleviating the class imbalance issue in the target domain. DC can be applied at either image level or region level, consistently improving detectors' transferability and discriminability. Extensive experiments on commonly used benchmarks show that DC improves the baseline and state-of-the-art by significant margins, while demonstrating great potential for large domain divergence.
Hierarchical Modeling of Multidimensional Data in Regularly Decomposed Spaces: Applications in Image Analysis
May 04, 2016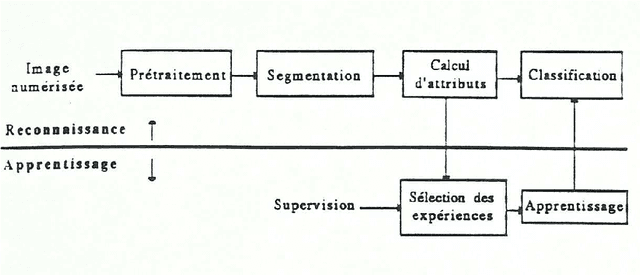
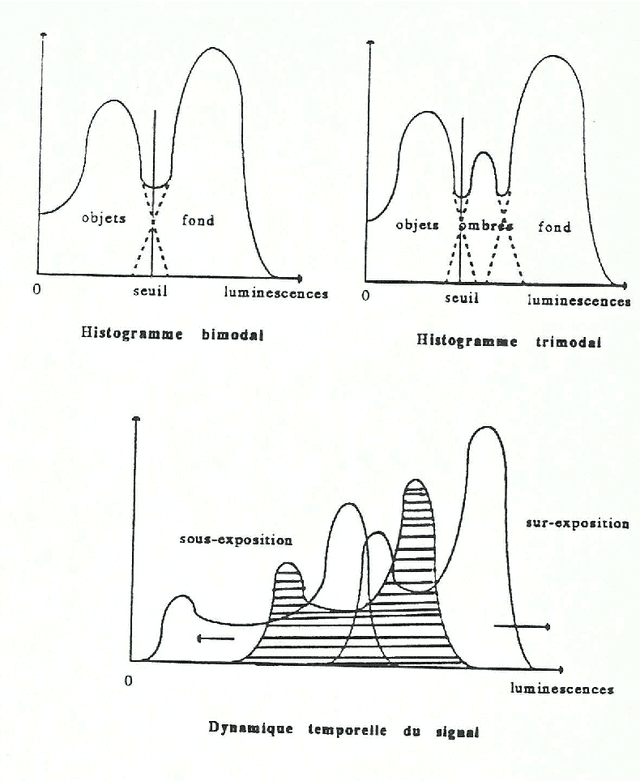
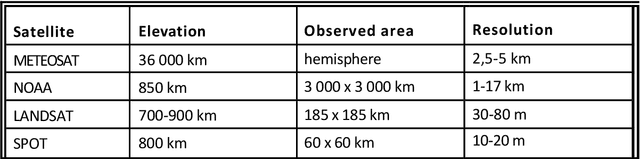
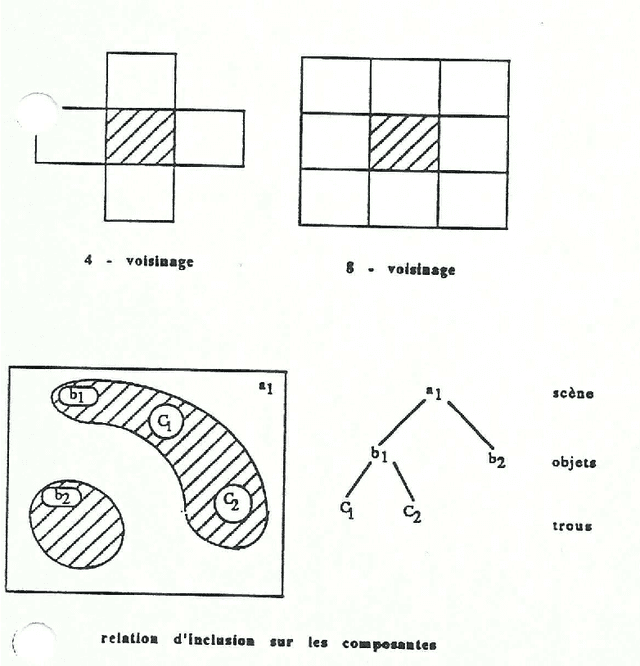
This last document is showing the gradual introduction of hierarchical modeling techniques in image analysis. The first chapter is dealing with the first works carried out in the field of industrial applications of pattern recognition. The second chapter is focusing on the usage of these techniques in satellite imagery and on the development of a satellite data archiving system in the aim of using it in digital geography. The third chapter is about face recognition based on planar image analysis and about the recognition of partially hidden patterns. The present publication is ending with the description of a future system of self-descriptive coding of still or moving pictures in relation with the current video coding standards. As in the previous documents, it will be found in annex algorithms targeted on image analysis according two complementary approaches: - boundary-based approach for the industrial applications of artificial vision; - region-based approach for satellite image analysis.