 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Restoration: A General Wavelet Frame Based Model and Its Asymptotic Analysis
Feb 17, 2016

Image restoration is one of the most important areas in imaging science. Mathematical tools have been widely used in image restoration, where wavelet frame based approach is one of the successful examples. In this paper, we introduce a generic wavelet frame based image restoration model, called the "general model", which includes most of the existing wavelet frame based models as special cases. Moreover, the general model also includes examples that are new to the literature. Motivated by our earlier studies [1-3], We provide an asymptotic analysis of the general model as image resolution goes to infinity, which establishes a connection between the general model in discrete setting and a new variatonal model in continuum setting. The variational model also includes some of the existing variational models as special cases, such as the total generalized variational model proposed by [4]. In the end, we introduce an algorithm solving the general model and present one numerical simulation as an example.
Learning to adapt class-specific features across domains for semantic segmentation
Jan 22, 2020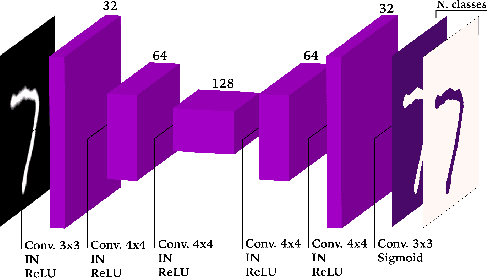


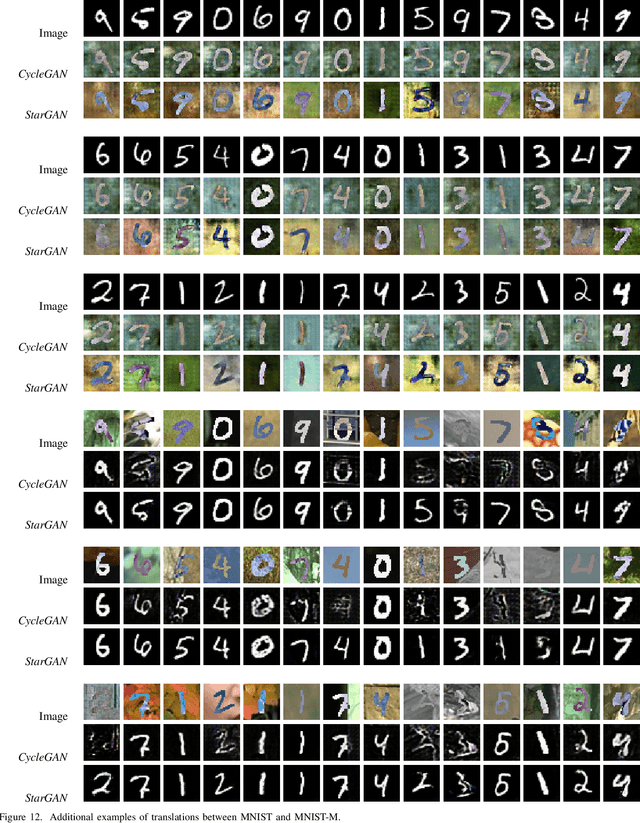
Recent advances in unsupervised domain adaptation have shown the effectiveness of adversarial training to adapt features across domains, endowing neural networks with the capability of being tested on a target domain without requiring any training annotations in this domain. The great majority of existing domain adaptation models rely on image translation networks, which often contain a huge amount of domain-specific parameters. Additionally, the feature adaptation step often happens globally, at a coarse level, hindering its applicability to tasks such as semantic segmentation, where details are of crucial importance to provide sharp results. In this thesis, we present a novel architecture, which learns to adapt features across domains by taking into account per class information. To that aim, we design a conditional pixel-wise discriminator network, whose output is conditioned on the segmentation masks. Moreover, following recent advances in image translation, we adopt the recently introduced StarGAN architecture as image translation backbone, since it is able to perform translations across multiple domains by means of a single generator network. Preliminary results on a segmentation task designed to assess the effectiveness of the proposed approach highlight the potential of the model, improving upon strong baselines and alternative designs.
Multi-Sensor Data Fusion for Cloud Removal in Global and All-Season Sentinel-2 Imagery
Sep 16, 2020
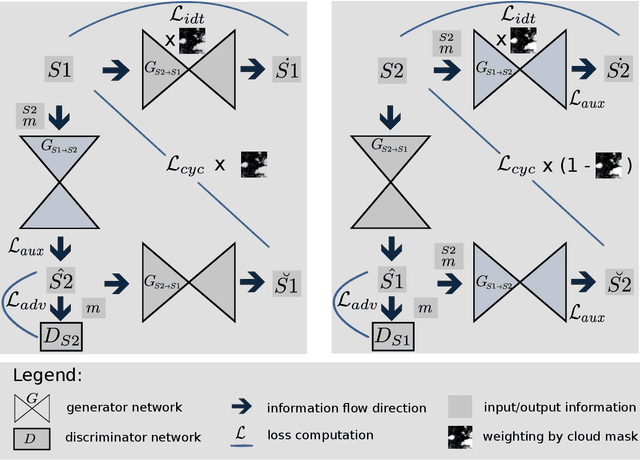
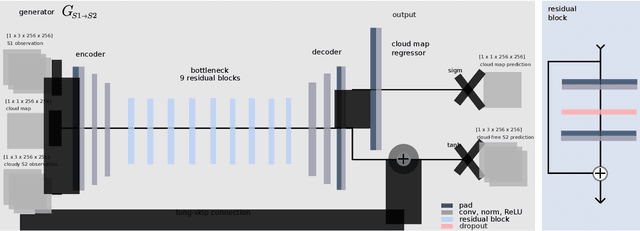

This work has been accepted by IEEE TGRS for publication. The majority of optical observations acquired via spaceborne earth imagery are affected by clouds. While there is numerous prior work on reconstructing cloud-covered information, previous studies are oftentimes confined to narrowly-defined regions of interest, raising the question of whether an approach can generalize to a diverse set of observations acquired at variable cloud coverage or in different regions and seasons. We target the challenge of generalization by curating a large novel data set for training new cloud removal approaches and evaluate on two recently proposed performance metrics of image quality and diversity. Our data set is the first publically available to contain a global sample of co-registered radar and optical observations, cloudy as well as cloud-free. Based on the observation that cloud coverage varies widely between clear skies and absolute coverage, we propose a novel model that can deal with either extremes and evaluate its performance on our proposed data set. Finally, we demonstrate the superiority of training models on real over synthetic data, underlining the need for a carefully curated data set of real observations. To facilitate future research, our data set is made available online
Fast Soft Color Segmentation
Apr 17, 2020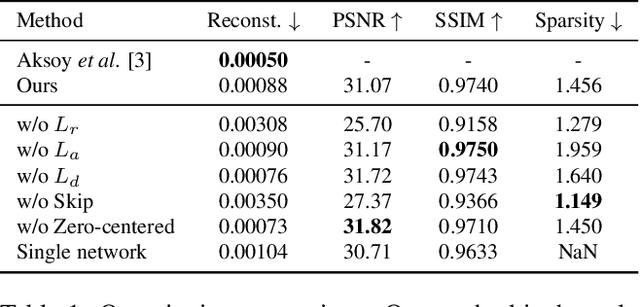


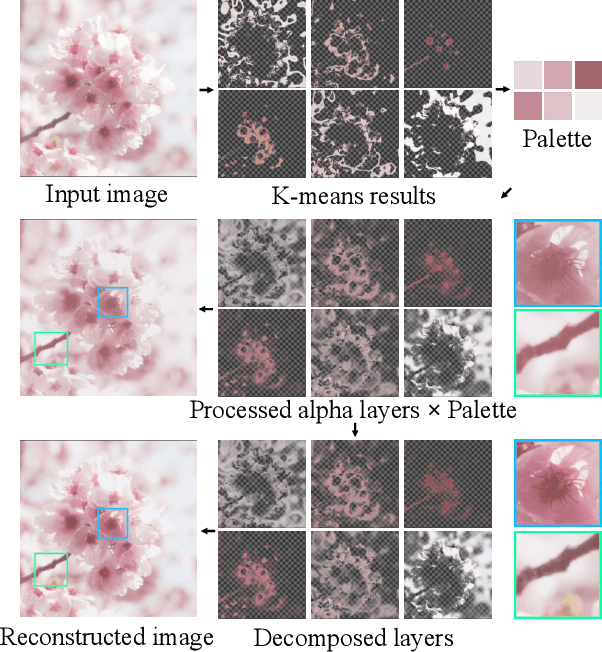
We address the problem of soft color segmentation, defined as decomposing a given image into several RGBA layers, each containing only homogeneous color regions. The resulting layers from decomposition pave the way for applications that benefit from layer-based editing, such as recoloring and compositing of images and videos. The current state-of-the-art approach for this problem is hindered by slow processing time due to its iterative nature, and consequently does not scale to certain real-world scenarios. To address this issue, we propose a neural network based method for this task that decomposes a given image into multiple layers in a single forward pass. Furthermore, our method separately decomposes the color layers and the alpha channel layers. By leveraging a novel training objective, our method achieves proper assignment of colors amongst layers. As a consequence, our method achieve promising quality without existing issue of inference speed for iterative approaches. Our thorough experimental analysis shows that our method produces qualitative and quantitative results comparable to previous methods while achieving a 300,000x speed improvement. Finally, we utilize our proposed method on several applications, and demonstrate its speed advantage, especially in video editing.
Cross-modal Center Loss
Aug 08, 2020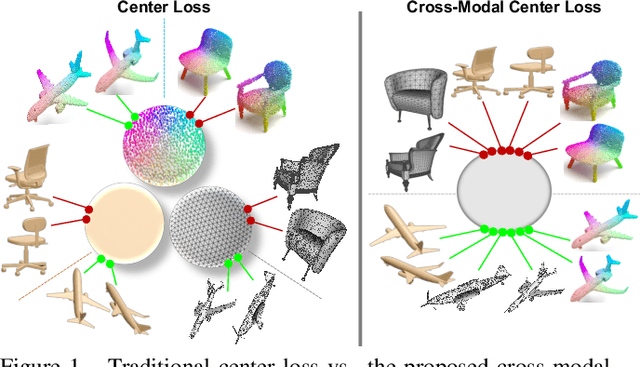
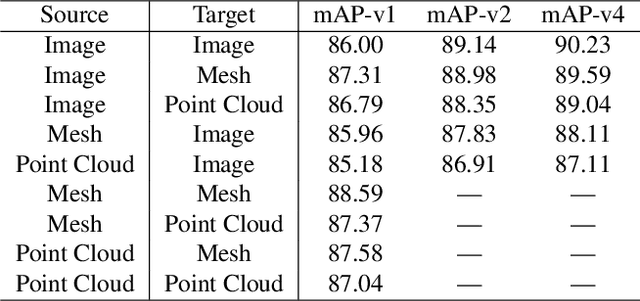
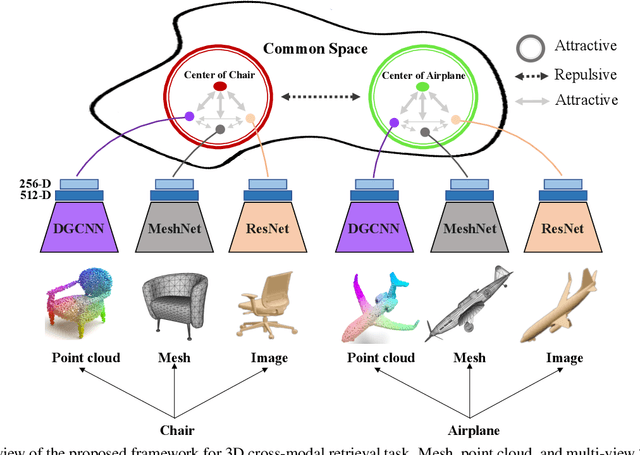
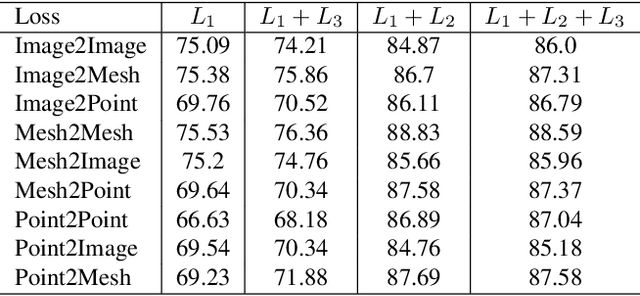
Cross-modal retrieval aims to learn discriminative and modal-invariant features for data from different modalities. Unlike the existing methods which usually learn from the features extracted by offline networks, in this paper, we propose an approach to jointly train the components of cross-modal retrieval framework with metadata, and enable the network to find optimal features. The proposed end-to-end framework is updated with three loss functions: 1) a novel cross-modal center loss to eliminate cross-modal discrepancy, 2) cross-entropy loss to maximize inter-class variations, and 3) mean-square-error loss to reduce modality variations. In particular, our proposed cross-modal center loss minimizes the distances of features from objects belonging to the same class across all modalities. Extensive experiments have been conducted on the retrieval tasks across multi-modalities, including 2D image, 3D point cloud, and mesh data. The proposed framework significantly outperforms the state-of-the-art methods on the ModelNet40 dataset.
RNN Fisher Vectors for Action Recognition and Image Annotation
Dec 12, 2015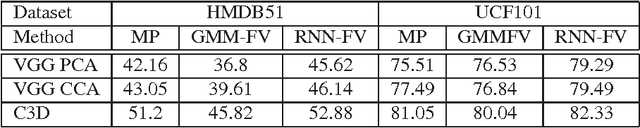
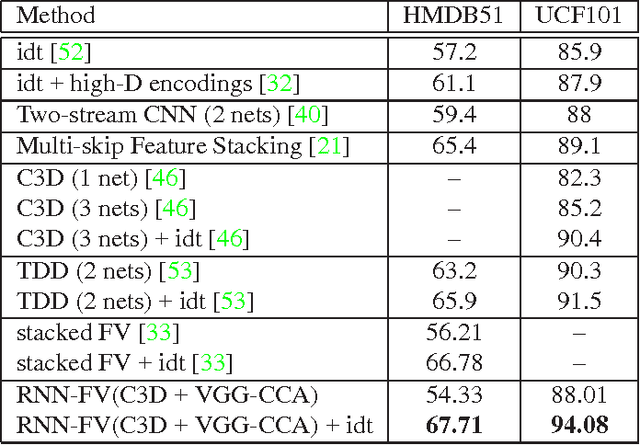
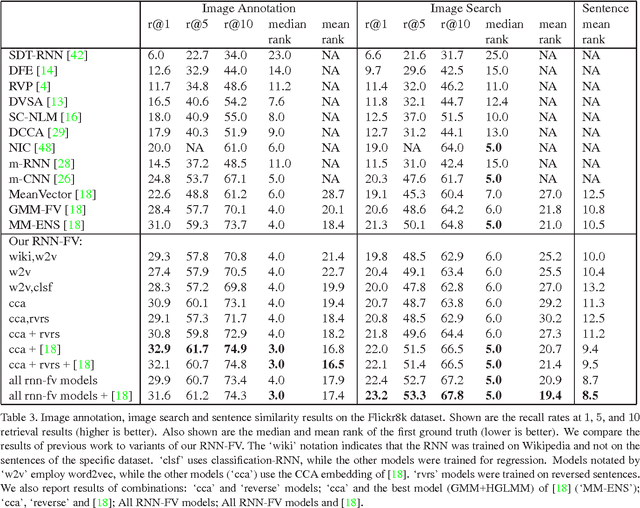
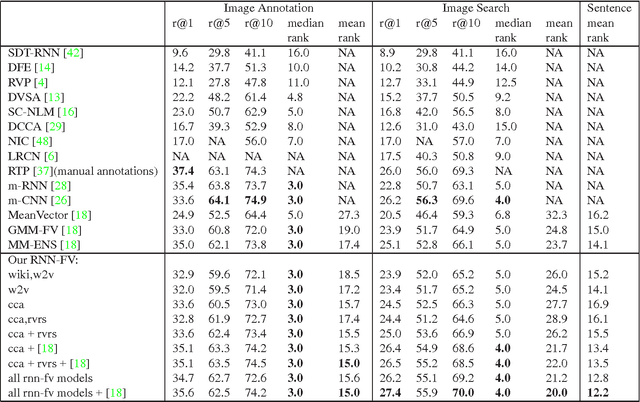
Recurrent Neural Networks (RNNs) have had considerable success in classifying and predicting sequences. We demonstrate that RNNs can be effectively used in order to encode sequences and provide effective representations. The methodology we use is based on Fisher Vectors, where the RNNs are the generative probabilistic models and the partial derivatives are computed using backpropagation. State of the art results are obtained in two central but distant tasks, which both rely on sequences: video action recognition and image annotation. We also show a surprising transfer learning result from the task of image annotation to the task of video action recognition.
Meta-Learning for Variational Inference
Jul 06, 2020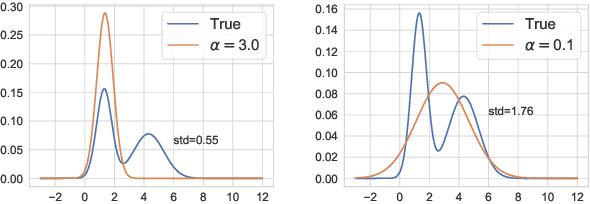
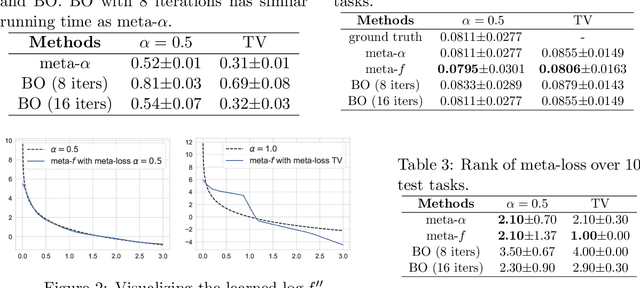
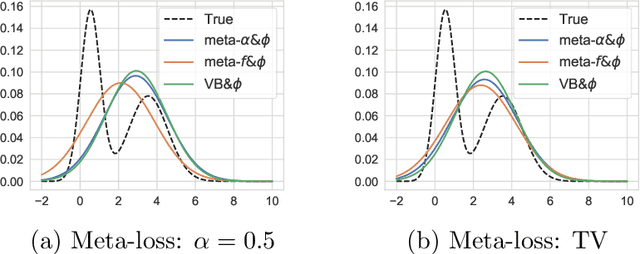
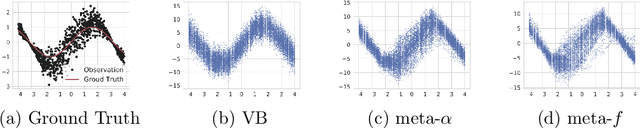
Variational inference (VI) plays an essential role in approximate Bayesian inference due to its computational efficiency and broad applicability. Crucial to the performance of VI is the selection of the associated divergence measure, as VI approximates the intractable distribution by minimizing this divergence. In this paper we propose a meta-learning algorithm to learn the divergence metric suited for the task of interest, automating the design of VI methods. In addition, we learn the initialization of the variational parameters without additional cost when our method is deployed in the few-shot learning scenarios. We demonstrate our approach outperforms standard VI on Gaussian mixture distribution approximation, Bayesian neural network regression, image generation with variational autoencoders and recommender systems with a partial variational autoencoder.
Evaluation of 3D CNN Semantic Mapping for Rover Navigation
Jun 17, 2020
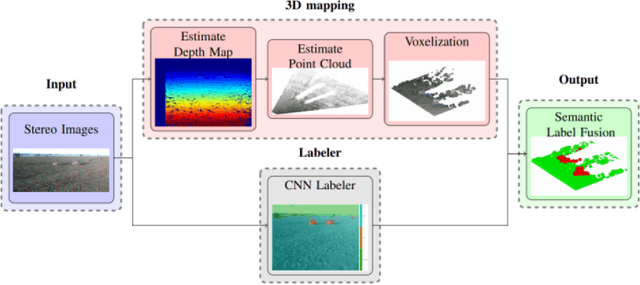
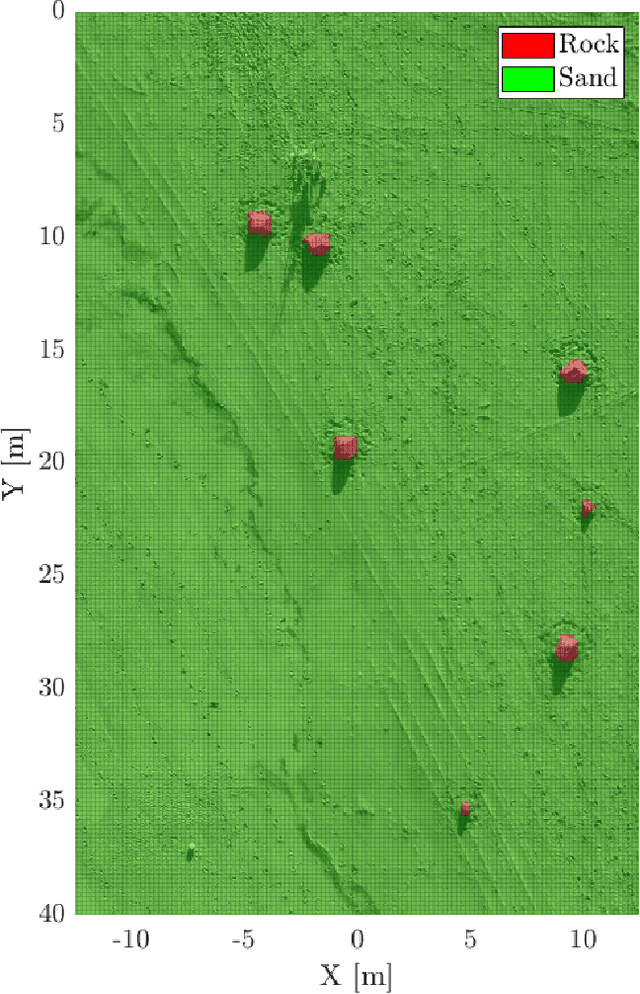

Terrain assessment is a key aspect for autonomous exploration rovers, surrounding environment recognition is required for multiple purposes, such as optimal trajectory planning and autonomous target identification. In this work we present a technique to generate accurate three-dimensional semantic maps for Martian environment. The algorithm uses as input a stereo image acquired by a camera mounted on a rover. Firstly, images are labeled with DeepLabv3+, which is an encoder-decoder Convolutional Neural Networl (CNN). Then, the labels obtained by the semantic segmentation are combined to stereo depth-maps in a Voxel representation. We evaluate our approach on the ESA Katwijk Beach Planetary Rover Dataset.
Deep Encoder-decoder Adversarial Reconstruction (DEAR) Network for 3D CT from Few-view Data
Nov 13, 2019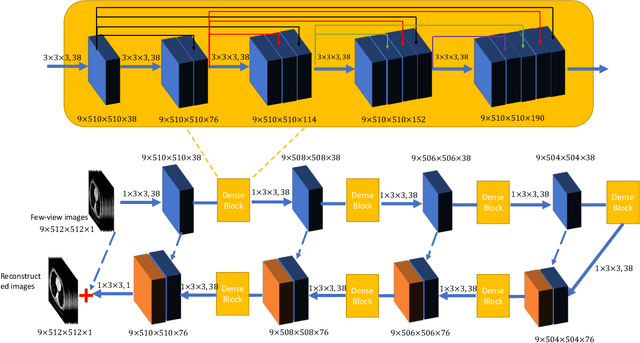

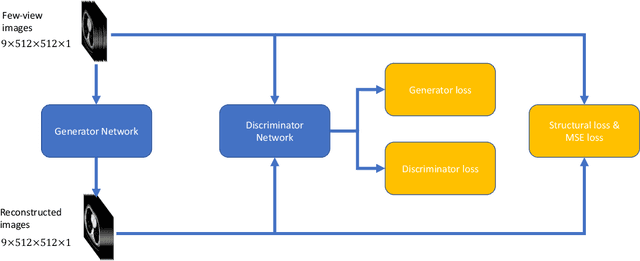
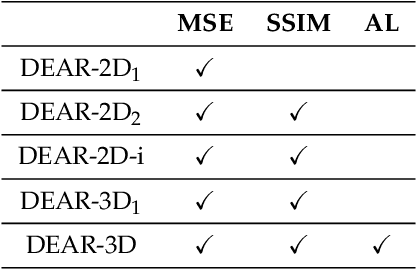
X-ray computed tomography (CT) is widely used in clinical practice. The involved ionizing X-ray radiation, however, could increase cancer risk. Hence, the reduction of the radiation dose has been an important topic in recent years. Few-view CT image reconstruction is one of the main ways to minimize radiation dose and potentially allow a stationary CT architecture. In this paper, we propose a deep encoder-decoder adversarial reconstruction (DEAR) network for 3D CT image reconstruction from few-view data. Since the artifacts caused by few-view reconstruction appear in 3D instead of 2D geometry, a 3D deep network has a great potential for improving the image quality in a data-driven fashion. More specifically, our proposed DEAR-3D network aims at reconstructing 3D volume directly from clinical 3D spiral cone-beam image data. DEAR is validated on a publicly available abdominal CT dataset prepared and authorized by Mayo Clinic. Compared with other 2D deep-learning methods, the proposed DEAR-3D network can utilize 3D information to produce promising reconstruction results.
Higher-order MRFs based image super resolution: why not MAP?
Oct 24, 2015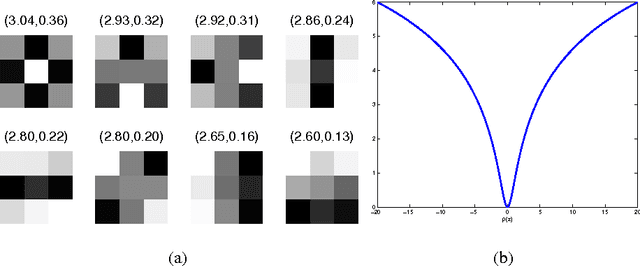



A trainable filter-based higher-order Markov Random Fields (MRFs) model - the so called Fields of Experts (FoE), has proved a highly effective image prior model for many classic image restoration problems. Generally, two options are available to incorporate the learned FoE prior in the inference procedure: (1) sampling-based minimum mean square error (MMSE) estimate, and (2) energy minimization-based maximum a posteriori (MAP) estimate. This letter is devoted to the FoE prior based single image super resolution (SR) problem, and we suggest to make use of the MAP estimate for inference based on two facts: (I) It is well-known that the MAP inference has a remarkable advantage of high computational efficiency, while the sampling-based MMSE estimate is very time consuming. (II) Practical SR experiment results demonstrate that the MAP estimate works equally well compared to the MMSE estimate with exactly the same FoE prior model. Moreover, it can lead to even further improvements by incorporating our discriminatively trained FoE prior model. In summary, we hold that for higher-order natural image prior based SR problem, it is better to employ the MAP estimate for inference.