 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Aug 11, 2020
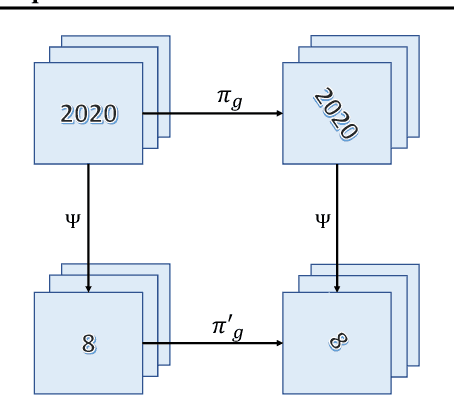
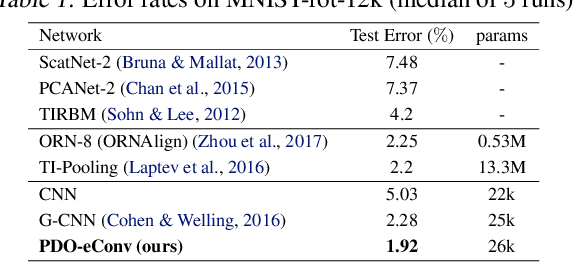

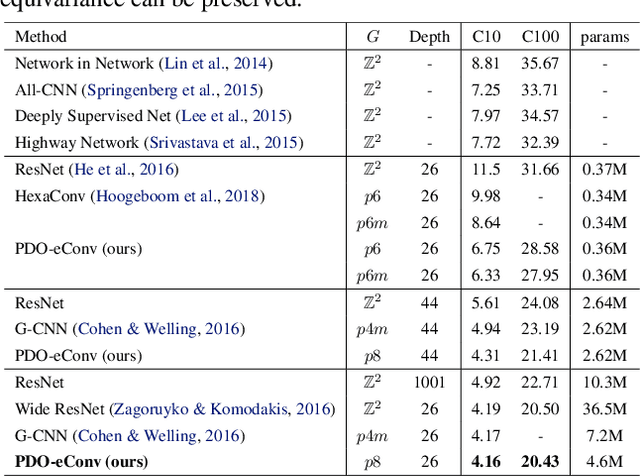
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.
Implanting Synthetic Lesions for Improving Liver Lesion Segmentation in CT Exams
Aug 11, 2020
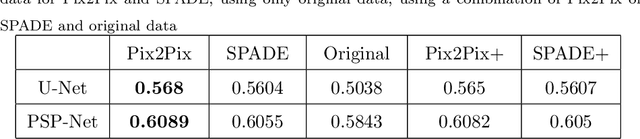
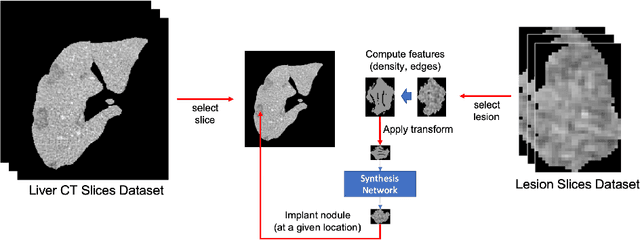
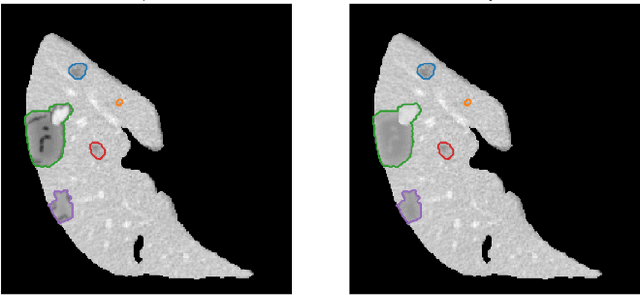
The success of supervised lesion segmentation algorithms using Computed Tomography (CT) exams depends significantly on the quantity and variability of samples available for training. While annotating such data constitutes a challenge itself, the variability of lesions in the dataset also depends on the prevalence of different types of lesions. This phenomenon adds an inherent bias to lesion segmentation algorithms that can be diminished, among different possibilities, using aggressive data augmentation methods. In this paper, we present a method for implanting realistic lesions in CT slices to provide a rich and controllable set of training samples and ultimately improving semantic segmentation network performances for delineating lesions in CT exams. Our results show that implanting synthetic lesions not only improves (up to around 12\%) the segmentation performance considering different architectures but also that this improvement is consistent among different image synthesis networks. We conclude that increasing the variability of lesions synthetically in terms of size, density, shape, and position seems to improve the performance of segmentation models for liver lesion segmentation in CT slices.
Coarse to fine non-rigid registration: a chain of scale-specific neural networks for multimodal image alignment with application to remote sensing
Feb 27, 2018

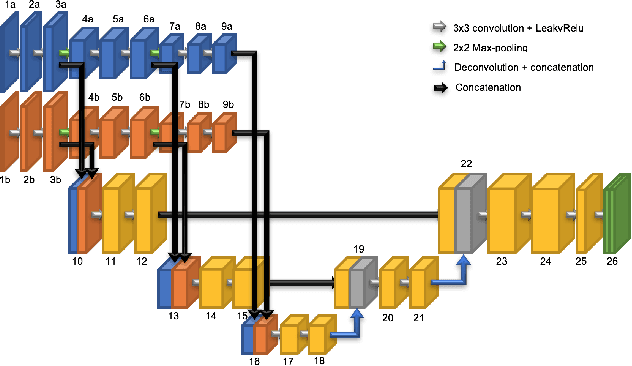
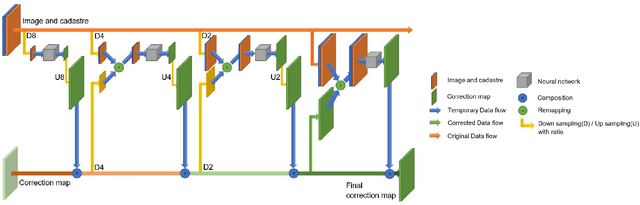
We tackle here the problem of multimodal image non-rigid registration, which is of prime importance in remote sensing and medical imaging. The difficulties encountered by classical registration approaches include feature design and slow optimization by gradient descent. By analyzing these methods, we note the significance of the notion of scale. We design easy-to-train, fully-convolutional neural networks able to learn scale-specific features. Once chained appropriately, they perform global registration in linear time, getting rid of gradient descent schemes by predicting directly the deformation.We show their performance in terms of quality and speed through various tasks of remote sensing multimodal image alignment. In particular, we are able to register correctly cadastral maps of buildings as well as road polylines onto RGB images, and outperform current keypoint matching methods.
Effective Image Retrieval via Multilinear Multi-index Fusion
Sep 27, 2017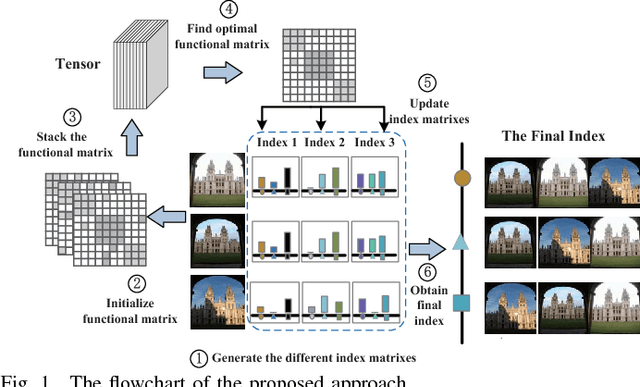
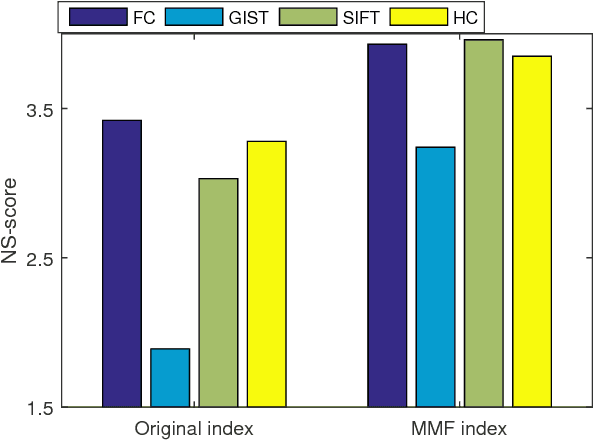
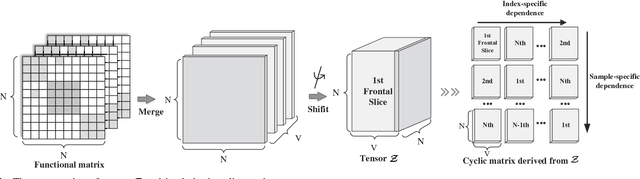
Multi-index fusion has demonstrated impressive performances in retrieval task by integrating different visual representations in a unified framework. However, previous works mainly consider propagating similarities via neighbor structure, ignoring the high order information among different visual representations. In this paper, we propose a new multi-index fusion scheme for image retrieval. By formulating this procedure as a multilinear based optimization problem, the complementary information hidden in different indexes can be explored more thoroughly. Specially, we first build our multiple indexes from various visual representations. Then a so-called index-specific functional matrix, which aims to propagate similarities, is introduced for updating the original index. The functional matrices are then optimized in a unified tensor space to achieve a refinement, such that the relevant images can be pushed more closer. The optimization problem can be efficiently solved by the augmented Lagrangian method with theoretical convergence guarantee. Unlike the traditional multi-index fusion scheme, our approach embeds the multi-index subspace structure into the new indexes with sparse constraint, thus it has little additional memory consumption in online query stage. Experimental evaluation on three benchmark datasets reveals that the proposed approach achieves the state-of-the-art performance, i.e., N-score 3.94 on UKBench, mAP 94.1\% on Holiday and 62.39\% on Market-1501.
Quantum-soft QUBO Suppression for Accurate Object Detection
Jul 28, 2020
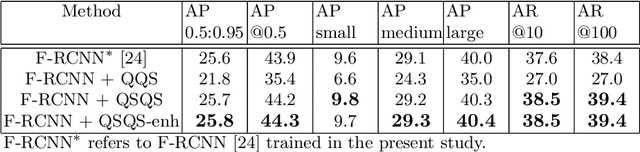
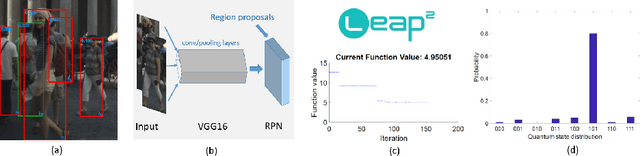
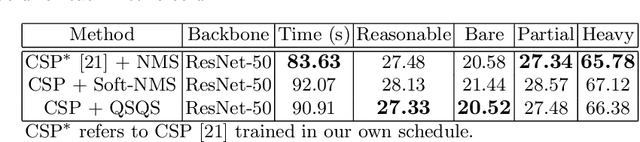
Non-maximum suppression (NMS) has been adopted by default for removing redundant object detections for decades. It eliminates false positives by only keeping the image M with highest detection score and images whose overlap ratio with M is less than a predefined threshold. However, this greedy algorithm may not work well for object detection under occlusion scenario where true positives with lower detection scores are possibly suppressed. In this paper, we first map the task of removing redundant detections into Quadratic Unconstrained Binary Optimization (QUBO) framework that consists of detection score from each bounding box and overlap ratio between pair of bounding boxes. Next, we solve the QUBO problem using the proposed Quantum-soft QUBO Suppression (QSQS) algorithm for fast and accurate detection by exploiting quantum computing advantages. Experiments indicate that QSQS improves mean average precision from 74.20% to 75.11% for PASCAL VOC 2007. It consistently outperforms NMS and soft-NMS for Reasonable subset of benchmark pedestrian detection CityPersons.
Unsupervised Learning of Lagrangian Dynamics from Images for Prediction and Control
Jul 03, 2020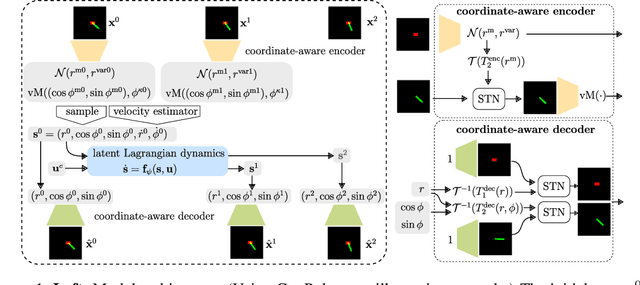
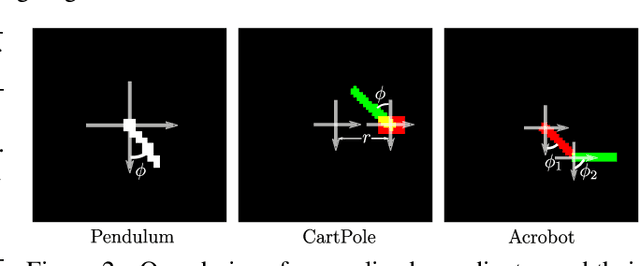
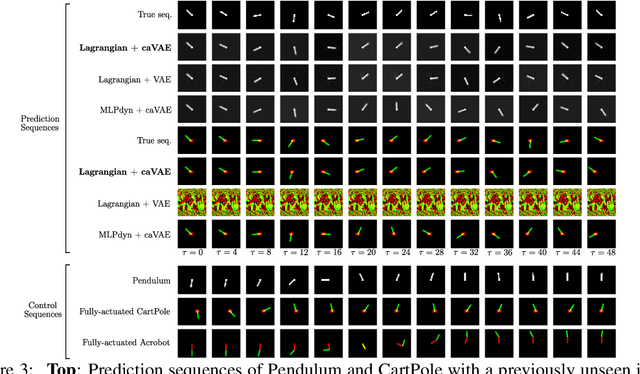
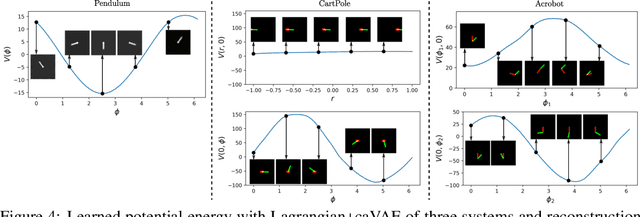
Recent approaches for modelling dynamics of physical systems with neural networks enforce Lagrangian or Hamiltonian structure to improve prediction and generalization. However, these approaches fail to handle the case when coordinates are embedded in high-dimensional data such as images. We introduce a new unsupervised neural network model that learns Lagrangian dynamics from images, with interpretability that benefits prediction and control. The model infers Lagrangian dynamics on generalized coordinates that are simultaneously learned with a coordinate-aware variational autoencoder (VAE). The VAE is designed to account for the geometry of physical systems composed of multiple rigid bodies in the plane. By inferring interpretable Lagrangian dynamics, the model learns physical system properties, such as kinetic and potential energy, which enables long-term prediction of dynamics in the image space and synthesis of energy-based controllers.
On the Comparison of Classic and Deep Keypoint Detector and Descriptor Methods
Jul 20, 2020
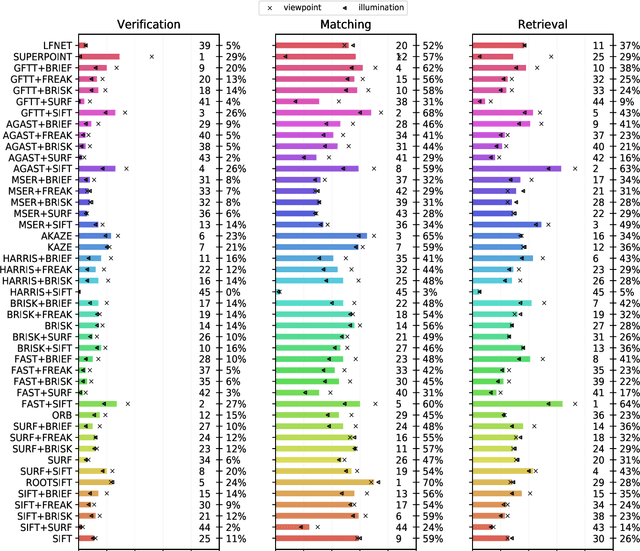
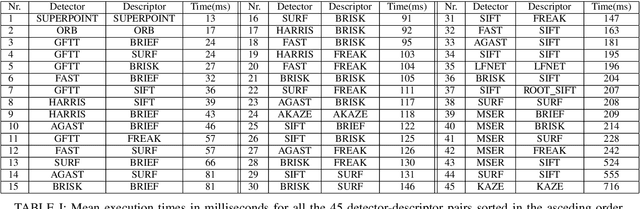
The purpose of this study is to give a performance comparison between several classic hand-crafted and deep key-point detector and descriptor methods. In particular, we consider the following classical algorithms: SIFT, SURF, ORB, FAST, BRISK, MSER, HARRIS, KAZE, AKAZE, AGAST, GFTT, FREAK, BRIEF and RootSIFT, where a subset of all combinations is paired into detector-descriptor pipelines. Additionally, we analyze the performance of two recent and perspective deep detector-descriptor models, LF-Net and SuperPoint. Our benchmark relies on the HPSequences dataset that provides real and diverse images under various geometric and illumination changes. We analyze the performance on three evaluation tasks: keypoint verification, image matching and keypoint retrieval. The results show that certain classic and deep approaches are still comparable, with some classic detector-descriptor combinations overperforming pretrained deep models. In terms of the execution times of tested implementations, SuperPoint model is the fastest, followed by ORB.
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 21, 2020
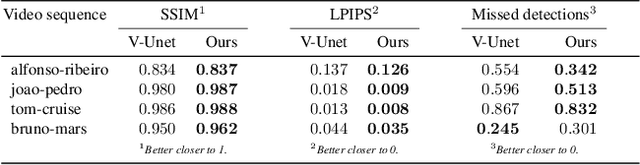

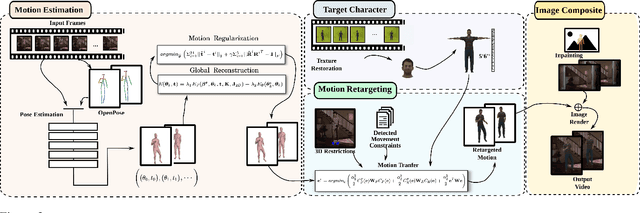
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance, and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).
Spectral-Spatial Classification of Hyperspectral Image Using Autoencoders
Nov 09, 2015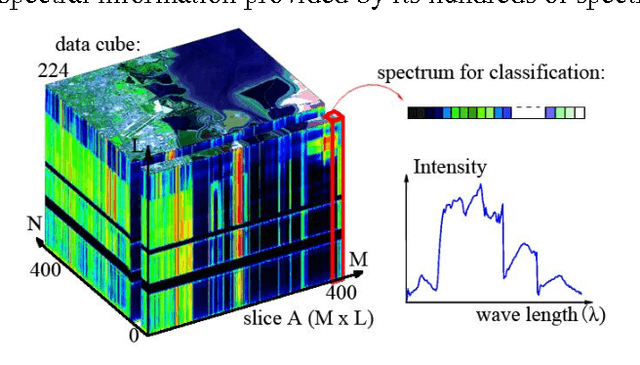
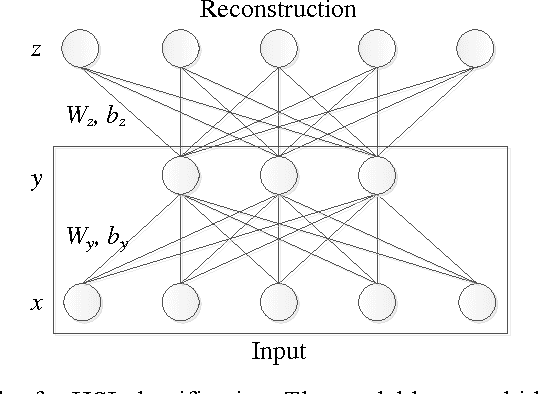
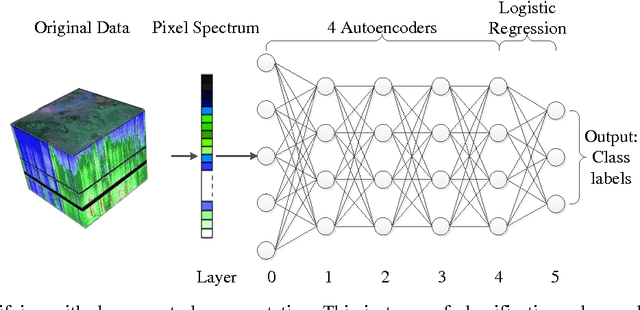
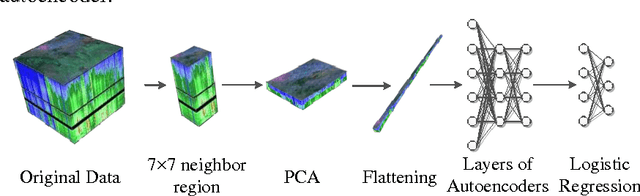
Hyperspectral image (HSI) classification is a hot topic in the remote sensing community. This paper proposes a new framework of spectral-spatial feature extraction for HSI classification, in which for the first time the concept of deep learning is introduced. Specifically, the model of autoencoder is exploited in our framework to extract various kinds of features. First we verify the eligibility of autoencoder by following classical spectral information based classification and use autoencoders with different depth to classify hyperspectral image. Further in the proposed framework, we combine PCA on spectral dimension and autoencoder on the other two spatial dimensions to extract spectral-spatial information for classification. The experimental results show that this framework achieves the highest classification accuracy among all methods, and outperforms classical classifiers such as SVM and PCA-based SVM.
MulGAN: Facial Attribute Editing by Exemplar
Dec 28, 2019
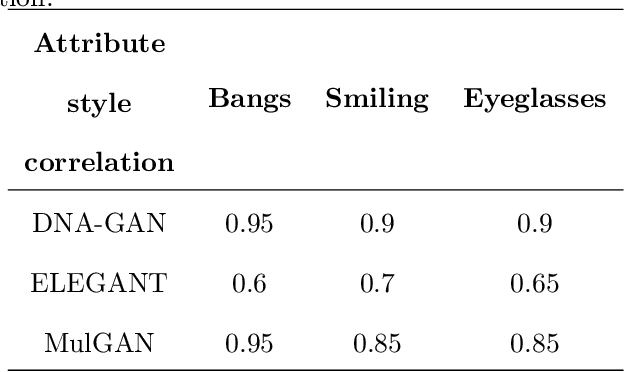
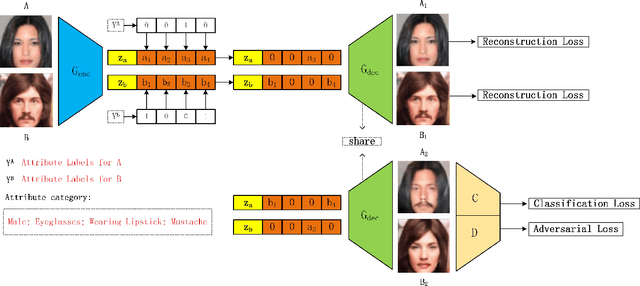
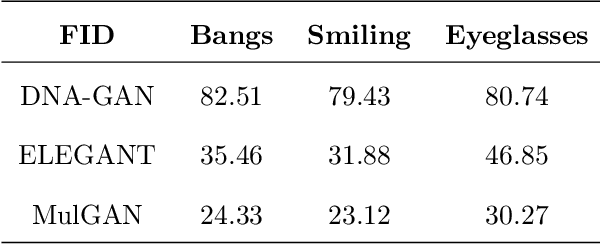
Recent studies on face attribute editing by exemplars have achieved promising results due to the increasing power of deep convolutional networks and generative adversarial networks. These methods encode attribute-related information in images into the predefined region of the latent feature space by employing a pair of images with opposite attributes as input to train model, the face attribute transfer between the input image and the exemplar can be achieved by exchanging their attribute-related latent feature region. However, they suffer from three limitations: (1) the model must be trained using a pair of images with opposite attributes as input; (2) weak capability of editing multiple attributes by exemplars; (3) poor quality of generating image. Instead of imposing opposite-attribute constraints on the input image in order to make the attribute information of images be encoded in the predefined region of the latent feature space, in this work we directly apply the attribute labels constraint to the predefined region of the latent feature space. Meanwhile, an attribute classification loss is employed to make the model learn to extract the attribute-related information of images into the predefined latent feature region of the corresponding attribute, which enables our method to transfer multiple attributes of the exemplar simultaneously. Besides, a novel model structure is designed to enhance attribute transfer capabilities by exemplars while improve the quality of the generated image. Experiments demonstrate the effectiveness of our model on overcoming the above three limitations by comparing with other methods on the CelebA dataset.