 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DCT-SNN: Using DCT to Distribute Spatial Information over Time for Learning Low-Latency Spiking Neural Networks
Oct 05, 2020
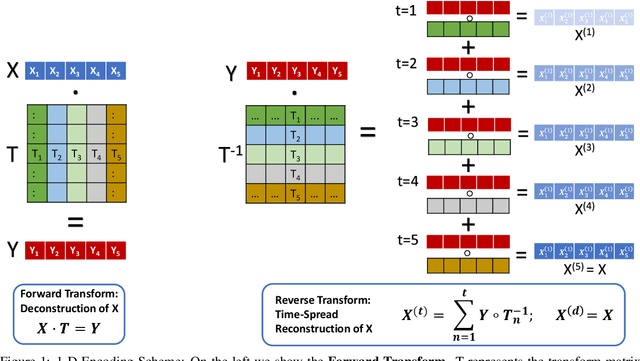
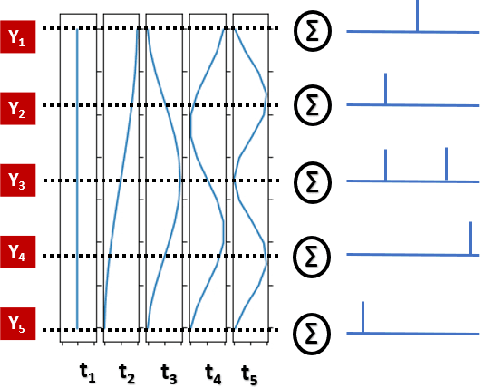
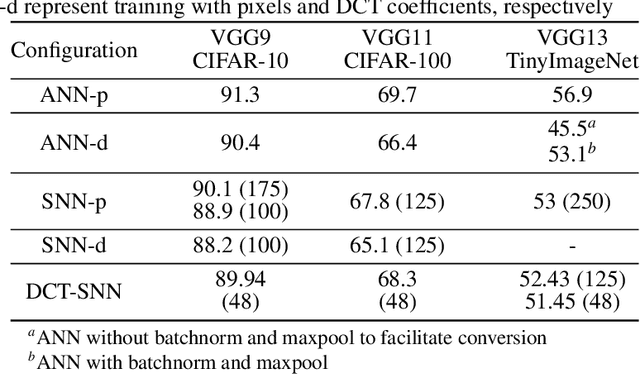

Spiking Neural Networks (SNNs) offer a promising alternative to traditional deep learning frameworks, since they provide higher computational efficiency due to event-driven information processing. SNNs distribute the analog values of pixel intensities into binary spikes over time. However, the most widely used input coding schemes, such as Poisson based rate-coding, do not leverage the additional temporal learning capability of SNNs effectively. Moreover, these SNNs suffer from high inference latency which is a major bottleneck to their deployment. To overcome this, we propose a scalable time-based encoding scheme that utilizes the Discrete Cosine Transform (DCT) to reduce the number of timesteps required for inference. DCT decomposes an image into a weighted sum of sinusoidal basis images. At each time step, the Hadamard product of the DCT coefficients and a single frequency base, taken in order, is given to an accumulator that generates spikes upon crossing a threshold. We use the proposed scheme to learn DCT-SNN, a low-latency deep SNN with leaky-integrate-and-fire neurons, trained using surrogate gradient descent based backpropagation. We achieve top-1 accuracy of 89.94%, 68.3% and 52.43% on CIFAR-10, CIFAR-100 and TinyImageNet, respectively using VGG architectures. Notably, DCT-SNN performs inference with 2-14X reduced latency compared to other state-of-the-art SNNs, while achieving comparable accuracy to their standard deep learning counterparts. The dimension of the transform allows us to control the number of timesteps required for inference. Additionally, we can trade-off accuracy with latency in a principled manner by dropping the highest frequency components during inference.
Unsupervised Learning of Lagrangian Dynamics from Images for Prediction and Control
Jul 03, 2020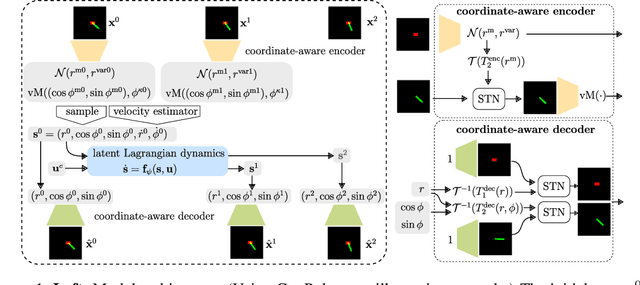
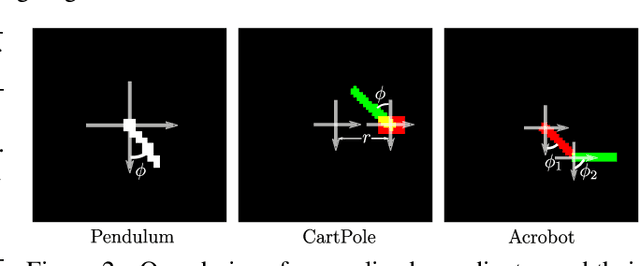
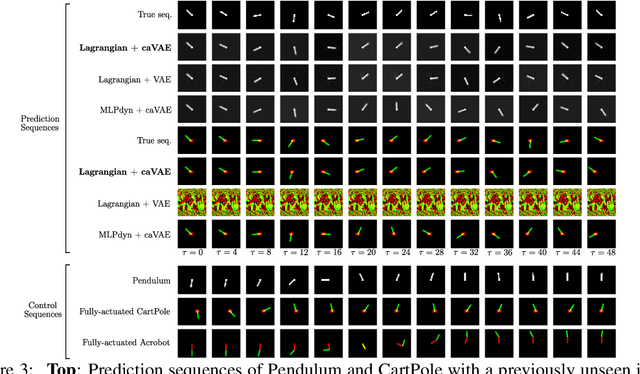
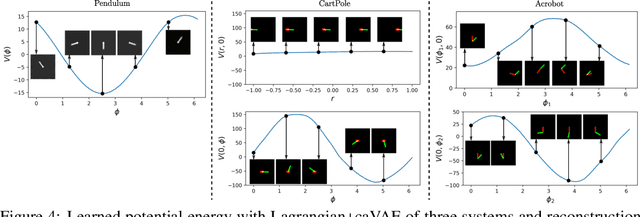
Recent approaches for modelling dynamics of physical systems with neural networks enforce Lagrangian or Hamiltonian structure to improve prediction and generalization. However, these approaches fail to handle the case when coordinates are embedded in high-dimensional data such as images. We introduce a new unsupervised neural network model that learns Lagrangian dynamics from images, with interpretability that benefits prediction and control. The model infers Lagrangian dynamics on generalized coordinates that are simultaneously learned with a coordinate-aware variational autoencoder (VAE). The VAE is designed to account for the geometry of physical systems composed of multiple rigid bodies in the plane. By inferring interpretable Lagrangian dynamics, the model learns physical system properties, such as kinetic and potential energy, which enables long-term prediction of dynamics in the image space and synthesis of energy-based controllers.
Fast Automatic Visibility Optimization for Thermal Synthetic Aperture Visualization
May 08, 2020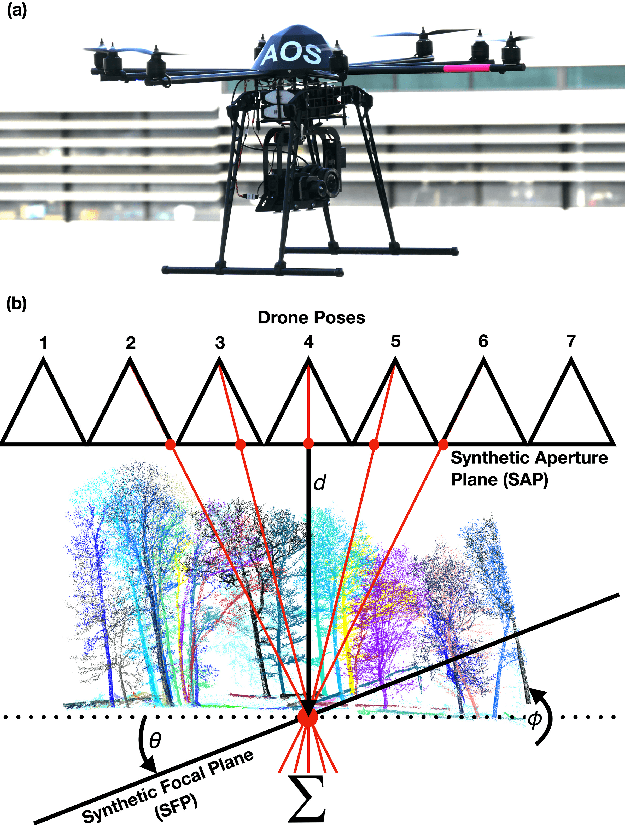

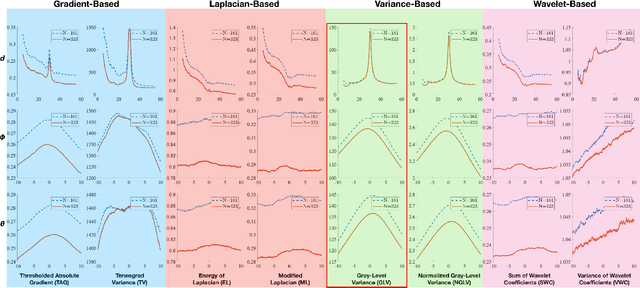
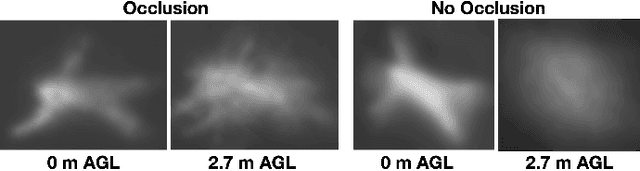
In this article, we describe and validate the first fully automatic parameter optimization for thermal synthetic aperture visualization. It replaces previous manual exploration of the parameter space, which is time consuming and error prone. We prove that the visibility of targets in thermal integral images is proportional to the variance of the targets' image. Since this is invariant to occlusion it represents a suitable objective function for optimization. Our findings have the potential to enable fully autonomous search and recuse operations with camera drones.
ROAM: Random Layer Mixup for Semi-Supervised Learning in Medical Imaging
Mar 20, 2020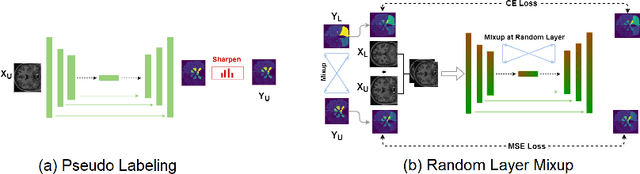
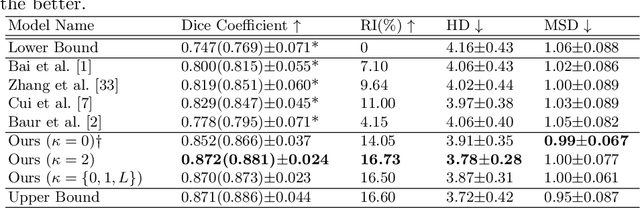

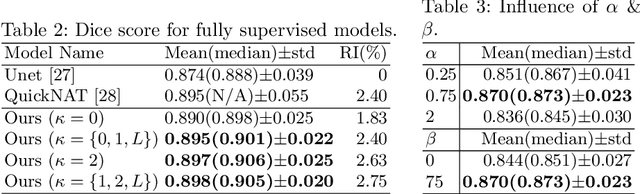
Medical image segmentation is one of the major challenges addressed by machine learning methods. Yet, deep learning methods profoundly depend on a huge amount of annotated data which is time-consuming and costly. Though semi-supervised learning methods approach this problem by leveraging an abundant amount of unlabeled data along with a small amount of labeled data in the training process. Recently, MixUp regularizer [32] has been successfully introduced to semi-supervised learning methods showing superior performance [3]. MixUp augments the model with new data points through linear interpolation of the data at the input space. In this paper, we argue that this option is limited, instead, we propose ROAM, a random layer mixup, which encourages the network to be less confident for interpolated data points at randomly selected space. Hence, avoids over-fitting and enhances the generalization ability. We validate our method on publicly available datasets on whole-brain image segmentation (MALC) achieving state-of-the-art results in fully supervised (89.8%) and semi-supervised (87.2%) settings with relative improvement up to 2.75% and 16.73%, respectively.
Deep Hashing with Hash-Consistent Large Margin Proxy Embeddings
Jul 27, 2020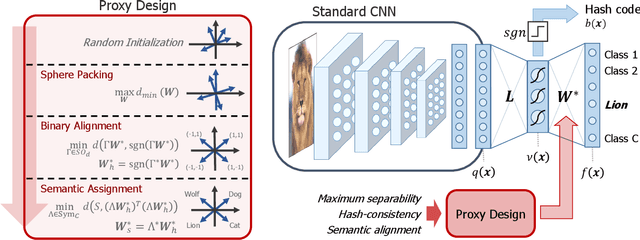
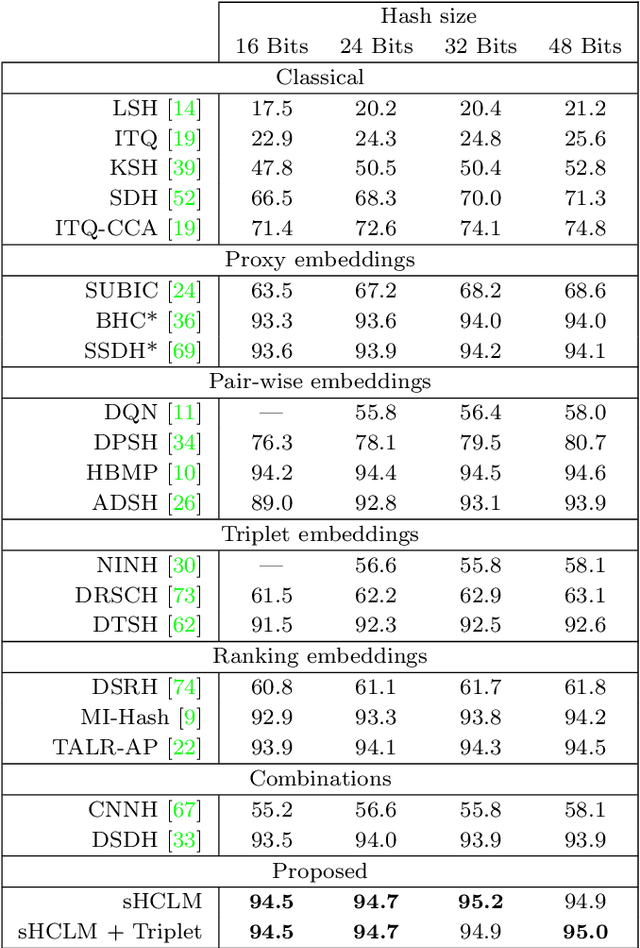
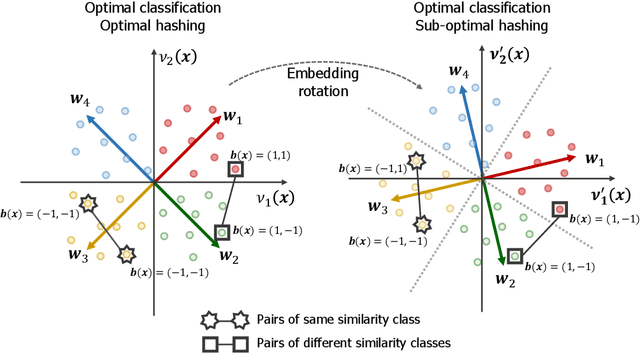
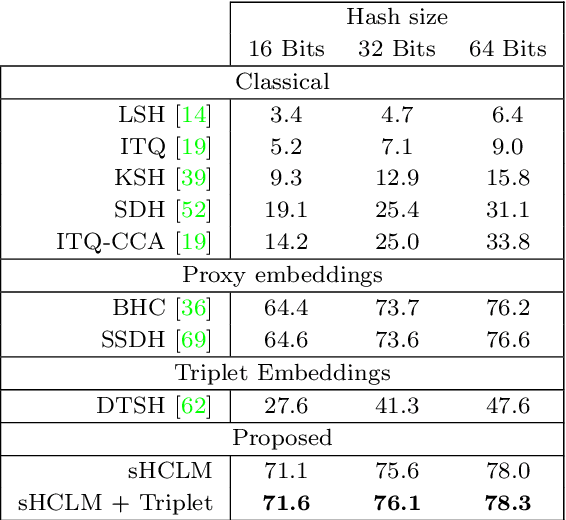
Image hash codes are produced by binarizing the embeddings of convolutional neural networks (CNN) trained for either classification or retrieval. While proxy embeddings achieve good performance on both tasks, they are non-trivial to binarize, due to a rotational ambiguity that encourages non-binary embeddings. The use of a fixed set of proxies (weights of the CNN classification layer) is proposed to eliminate this ambiguity, and a procedure to design proxy sets that are nearly optimal for both classification and hashing is introduced. The resulting hash-consistent large margin (HCLM) proxies are shown to encourage saturation of hashing units, thus guaranteeing a small binarization error, while producing highly discriminative hash-codes. A semantic extension (sHCLM), aimed to improve hashing performance in a transfer scenario, is also proposed. Extensive experiments show that sHCLM embeddings achieve significant improvements over state-of-the-art hashing procedures on several small and large datasets, both within and beyond the set of training classes.
Fidelity-Naturalness Evaluation of Single Image Super Resolution
Nov 21, 2015
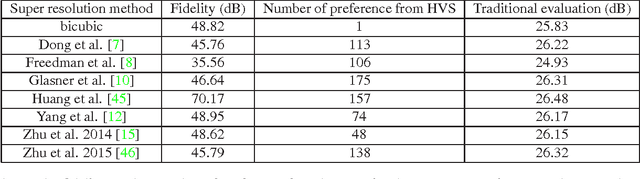


We study the problem of evaluating super resolution methods. Traditional evaluation methods usually judge the quality of super resolved images based on a single measure of their difference with the original high resolution images. In this paper, we proposed to use both fidelity (the difference with original images) and naturalness (human visual perception of super resolved images) for evaluation. For fidelity evaluation, a new metric is proposed to solve the bias problem of traditional evaluation. For naturalness evaluation, we let humans label preference of super resolution results using pair-wise comparison, and test the correlation between human labeling results and image quality assessment metrics' outputs. Experimental results show that our fidelity-naturalness method is better than the traditional evaluation method for super resolution methods, which could help future research on single-image super resolution.
DC-Al GAN: Pseudoprogression and True Tumor Progression of Glioblastoma multiform Image Classification Based On DCGAN and Alexnet
Feb 16, 2019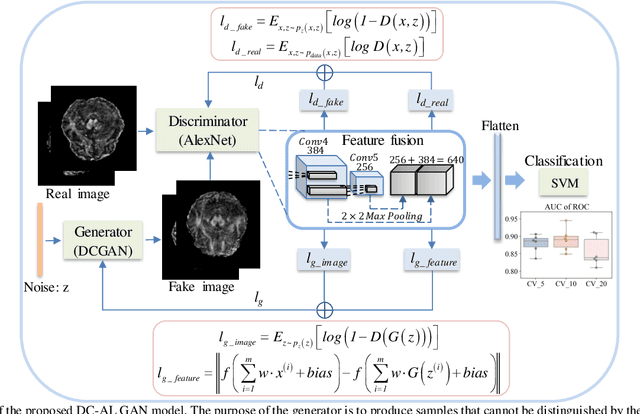
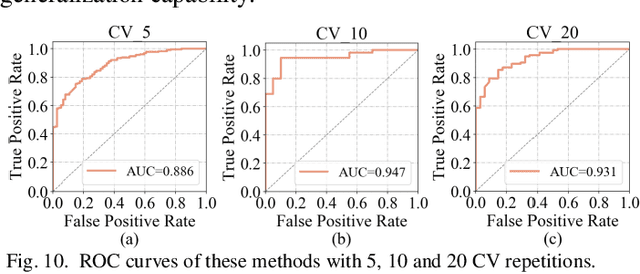
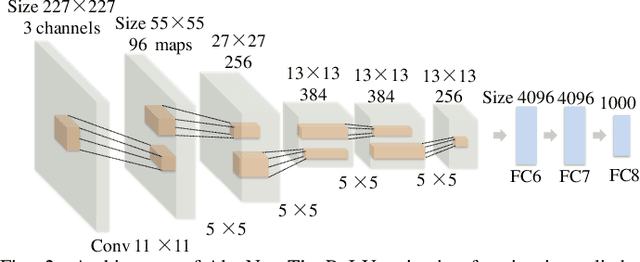
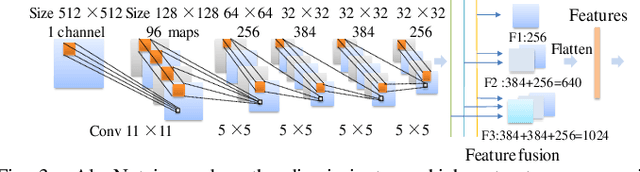
Glioblastoma multiform (GBM) is a kind of head tumor with an extraordinarily complex treatment process. The survival period is typically 14-16 months, and the 2 year survival rate is approximately 26%-33%. The clinical treatment strategies for the pseudoprogression (PsP) and true tumor progression (TTP) of GBM are different, so accurately distinguishing these two conditions is particularly significant.As PsP and TTP of GBM are similar in shape and other characteristics, it is hard to distinguish these two forms with precision. In order to differentiate them accurately, this paper introduces a feature learning method based on a generative adversarial network: DC-Al GAN. GAN consists of two architectures: generator and discriminator. Alexnet is used as the discriminator in this work. Owing to the adversarial and competitive relationship between generator and discriminator, the latter extracts highly concise features during training. In DC-Al GAN, features are extracted from Alexnet in the final classification phase, and the highly nature of them contributes positively to the classification accuracy.The generator in DC-Al GAN is modified by the deep convolutional generative adversarial network (DCGAN) by adding three convolutional layers. This effectively generates higher resolution sample images. Feature fusion is used to combine high layer features with low layer features, allowing for the creation and use of more precise features for classification. The experimental results confirm that DC-Al GAN achieves high accuracy on GBM datasets for PsP and TTP image classification, which is superior to other state-of-the-art methods.
Additive Tensor Decomposition Considering Structural Data Information
Jul 27, 2020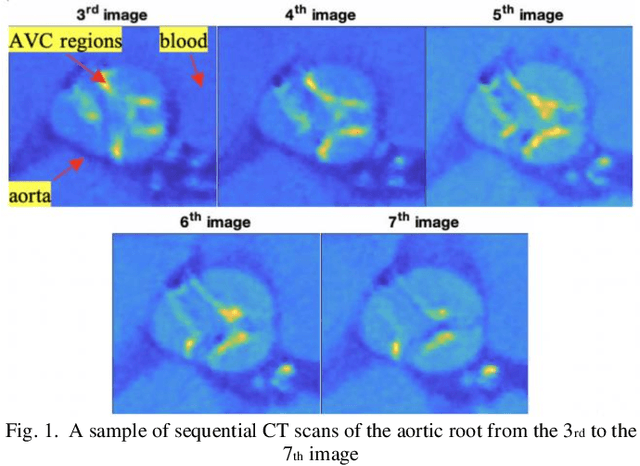
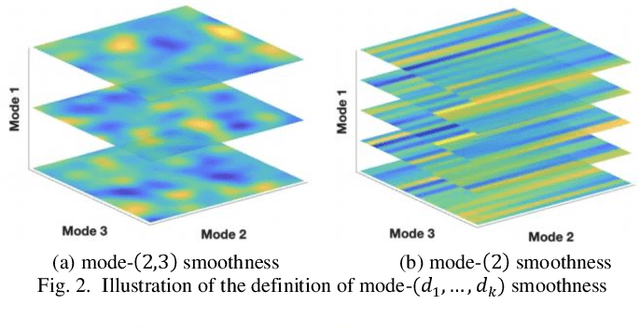

Tensor data with rich structural information becomes increasingly important in process modeling, monitoring, and diagnosis. Here structural information is referred to structural properties such as sparsity, smoothness, low-rank, and piecewise constancy. To reveal useful information from tensor data, we propose to decompose the tensor into the summation of multiple components based on different structural information of them. In this paper, we provide a new definition of structural information in tensor data. Based on it, we propose an additive tensor decomposition (ATD) framework to extract useful information from tensor data. This framework specifies a high dimensional optimization problem to obtain the components with distinct structural information. An alternating direction method of multipliers (ADMM) algorithm is proposed to solve it, which is highly parallelable and thus suitable for the proposed optimization problem. Two simulation examples and a real case study in medical image analysis illustrate the versatility and effectiveness of the ATD framework.
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
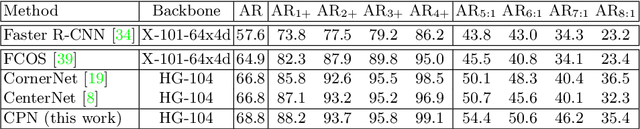

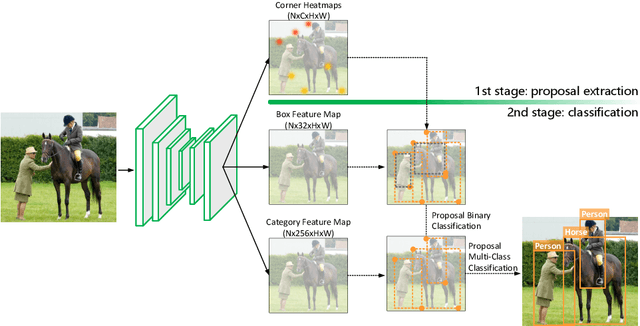
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
MaxDropout: Deep Neural Network Regularization Based on Maximum Output Values
Jul 27, 2020

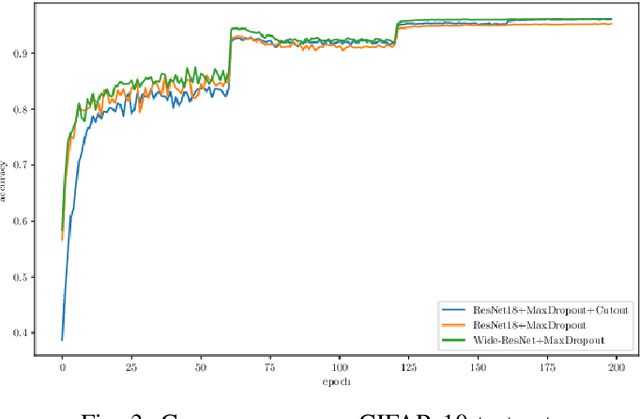
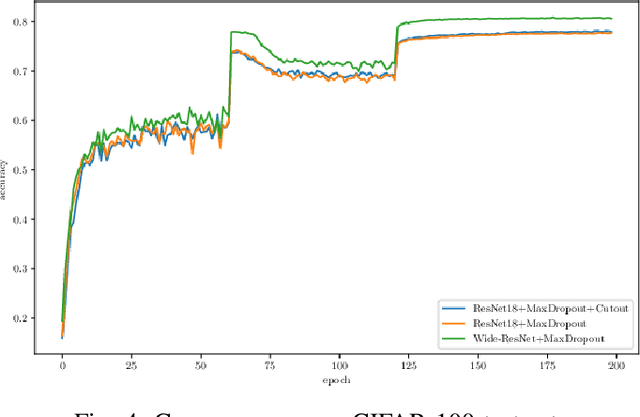
Different techniques have emerged in the deep learning scenario, such as Convolutional Neural Networks, Deep Belief Networks, and Long Short-Term Memory Networks, to cite a few. In lockstep, regularization methods, which aim to prevent overfitting by penalizing the weight connections, or turning off some units, have been widely studied either. In this paper, we present a novel approach called MaxDropout, a regularizer for deep neural network models that works in a supervised fashion by removing (shutting off) the prominent neurons (i.e., most active) in each hidden layer. The model forces fewer activated units to learn more representative information, thus providing sparsity. Regarding the experiments, we show that it is possible to improve existing neural networks and provide better results in neural networks when Dropout is replaced by MaxDropout. The proposed method was evaluated in image classification, achieving comparable results to existing regularizers, such as Cutout and RandomErasing, also improving the accuracy of neural networks that uses Dropout by replacing the existing layer by MaxDropout.