 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
STaDA: Style Transfer as Data Augmentation
Sep 03, 2019

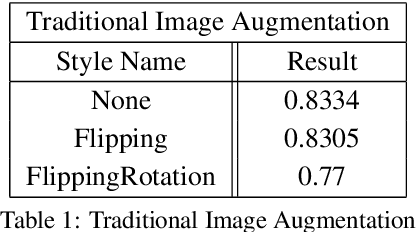

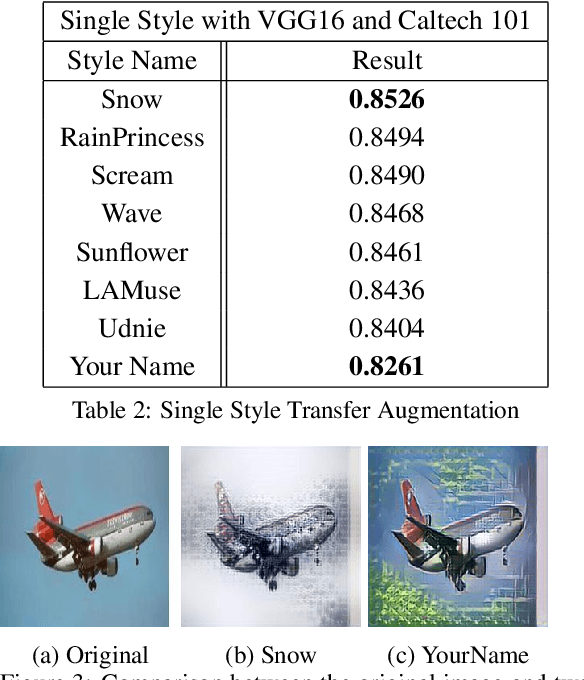
The success of training deep Convolutional Neural Networks (CNNs) heavily depends on a significant amount of labelled data. Recent research has found that neural style transfer algorithms can apply the artistic style of one image to another image without changing the latter's high-level semantic content, which makes it feasible to employ neural style transfer as a data augmentation method to add more variation to the training dataset. The contribution of this paper is a thorough evaluation of the effectiveness of the neural style transfer as a data augmentation method for image classification tasks. We explore the state-of-the-art neural style transfer algorithms and apply them as a data augmentation method on Caltech 101 and Caltech 256 dataset, where we found around 2% improvement from 83% to 85% of the image classification accuracy with VGG16, compared with traditional data augmentation strategies. We also combine this new method with conventional data augmentation approaches to further improve the performance of image classification. This work shows the potential of neural style transfer in computer vision field, such as helping us to reduce the difficulty of collecting sufficient labelled data and improve the performance of generic image-based deep learning algorithms.
Decision Support System for Detection and Classification of Skin Cancer using CNN
Dec 09, 2019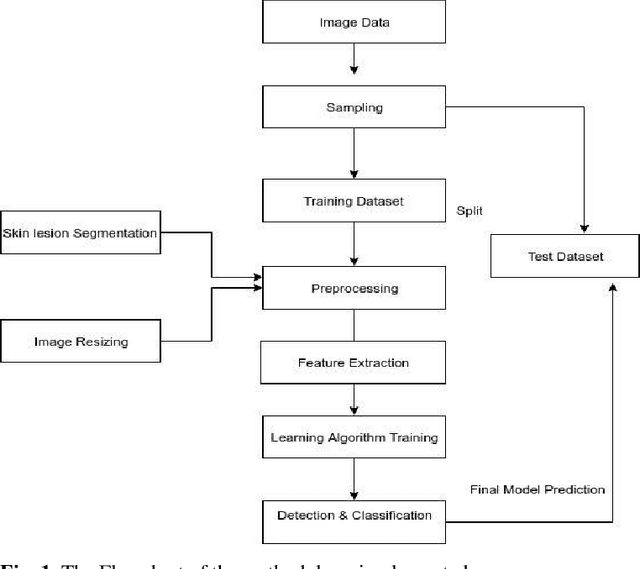
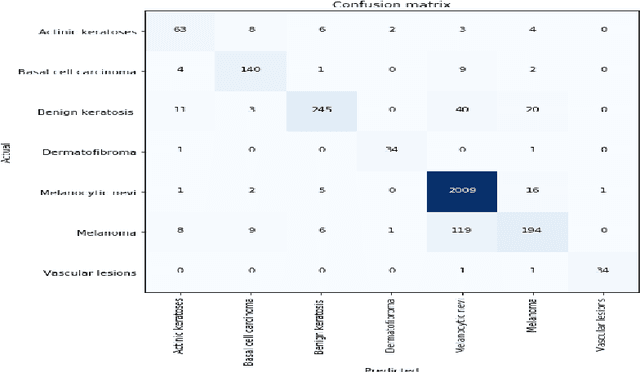
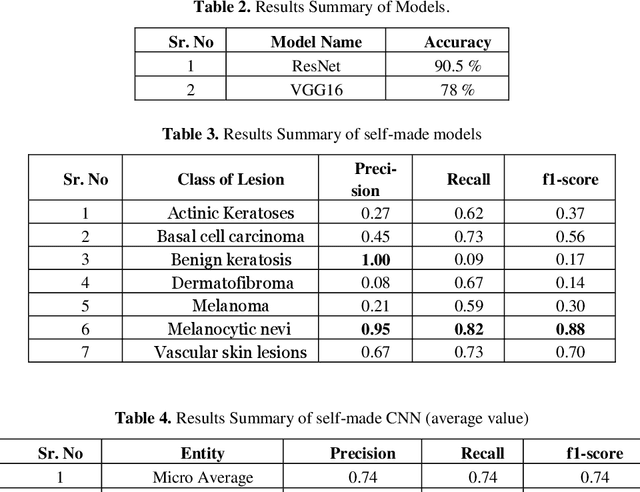
Skin Cancer is one of the most deathful of all the cancers. It is bound to spread to different parts of the body on the off chance that it is not analyzed and treated at the beginning time. It is mostly because of the abnormal growth of skin cells, often develops when the body is exposed to sunlight. The Detection Furthermore, the characterization of skin malignant growth in the beginning time is a costly and challenging procedure. It is classified where it develops and its cell type. High Precision and recall are required for the classification of lesions. The paper aims to use MNIST HAM-10000 dataset containing dermoscopy images. The objective is to propose a system that detects skin cancer and classifies it in different classes by using the Convolution Neural Network. The diagnosing methodology uses Image processing and deep learning model. The dermoscopy image of skin cancer taken, undergone various techniques to remove the noise and picture resolution. The image count is also increased by using various image augmentation techniques. In the end, the Transfer Learning method is used to increase the classification accuracy of the images further. Our CNN model gave a weighted average Precision of 0.88, a weighted Recall average of 0.74, and a weighted f1-score of 0.77. The transfer learning approach applied using ResNet model yielded an accuracy of 90.51%
Coupling Explicit and Implicit Surface Representations for Generative 3D Modeling
Jul 20, 2020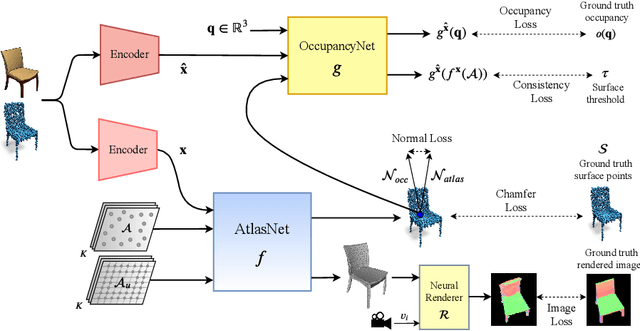
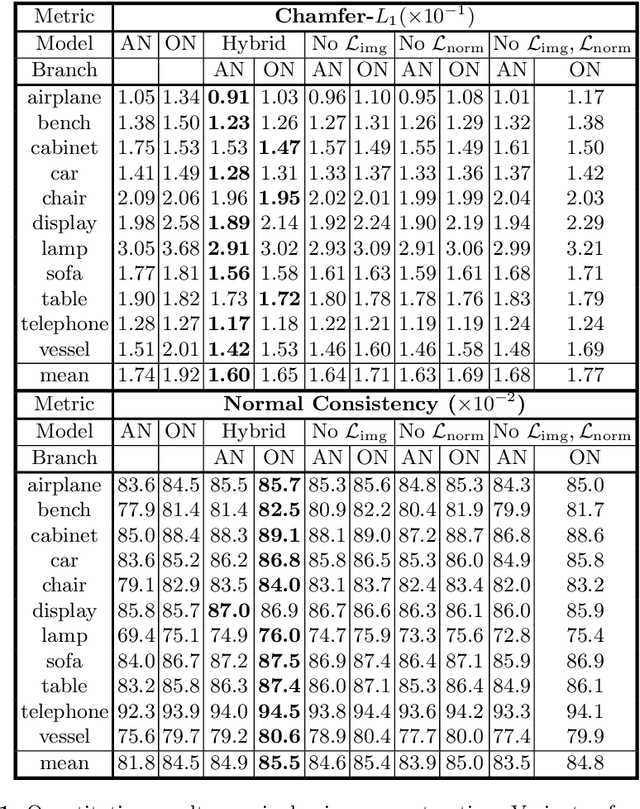
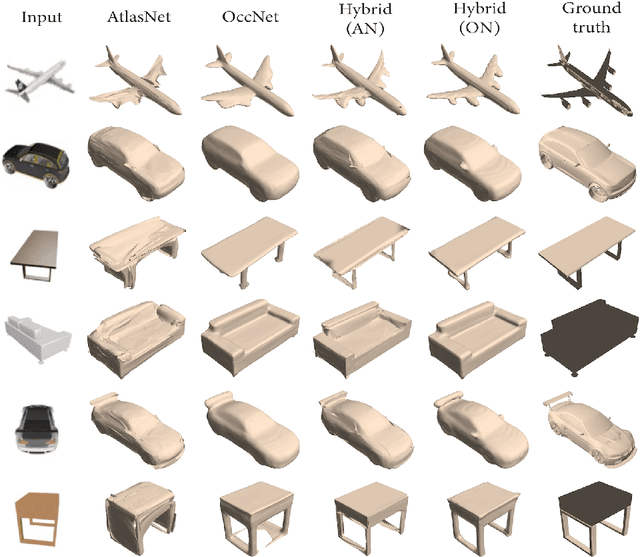
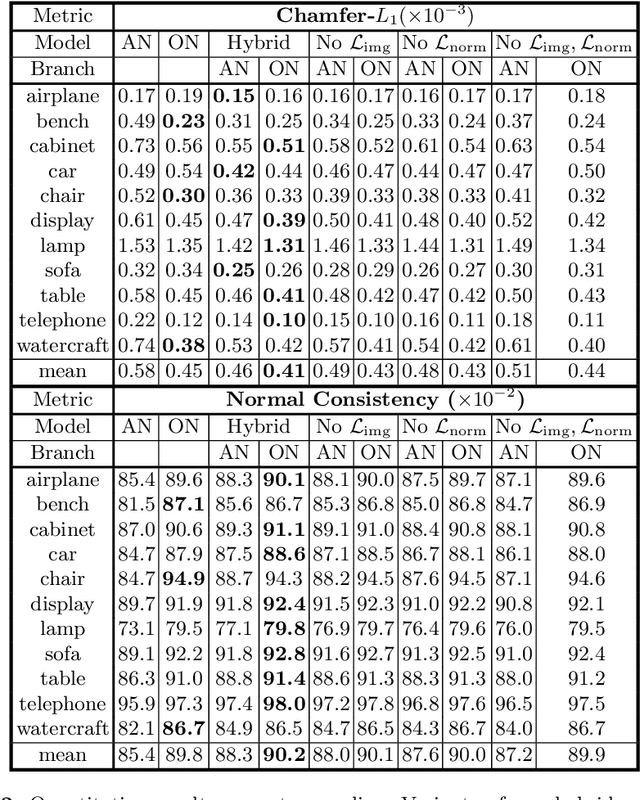
We propose a novel neural architecture for representing 3D surfaces, which harnesses two complementary shape representations: (i) an explicit representation via an atlas, i.e., embeddings of 2D domains into 3D; (ii) an implicit-function representation, i.e., a scalar function over the 3D volume, with its levels denoting surfaces. We make these two representations synergistic by introducing novel consistency losses that ensure that the surface created from the atlas aligns with the level-set of the implicit function. Our hybrid architecture outputs results which are superior to the output of the two equivalent single-representation networks, yielding smoother explicit surfaces with more accurate normals, and a more accurate implicit occupancy function. Additionally, our surface reconstruction step can directly leverage the explicit atlas-based representation. This process is computationally efficient, and can be directly used by differentiable rasterizers, enabling training our hybrid representation with image-based losses.
Land Cover Semantic Segmentation Using ResUNet
Oct 13, 2020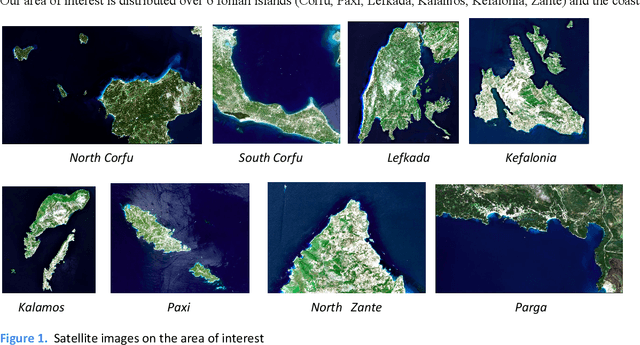
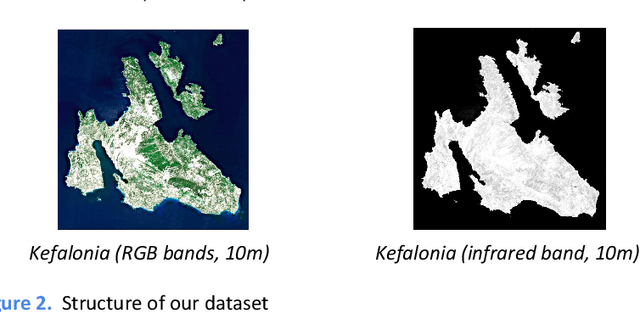

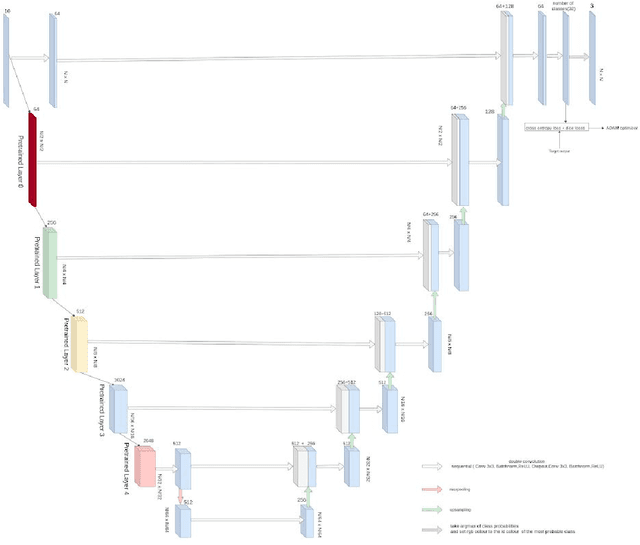
In this paper we present our work on developing an automated system for land cover classification. This system takes a multiband satellite image of an area as input and outputs the land cover map of the area at the same resolution as the input. For this purpose convolutional machine learning models were trained in the task of predicting the land cover semantic segmentation of satellite images. This is a case of supervised learning. The land cover label data were taken from the CORINE Land Cover inventory and the satellite images were taken from the Copernicus hub. As for the model, U-Net architecture variations were applied. Our area of interest are the Ionian islands (Greece). We created a dataset from scratch covering this particular area. In addition, transfer learning from the BigEarthNet dataset [1] was performed. In [1] simple classification of satellite images into the classes of CLC is performed but not segmentation as we do. However, their models have been trained into a dataset much bigger than ours, so we applied transfer learning using their pretrained models as the first part of out network, utilizing the ability these networks have developed to extract useful features from the satellite images (we transferred a pretrained ResNet50 into a U-Res-Net). Apart from transfer learning other techniques were applied in order to overcome the limitations set by the small size of our area of interest. We used data augmentation (cutting images into overlapping patches, applying random transformations such as rotations and flips) and cross validation. The results are tested on the 3 CLC class hierarchy levels and a comparative study is made on the results of different approaches.
Quantum-soft QUBO Suppression for Accurate Object Detection
Jul 28, 2020
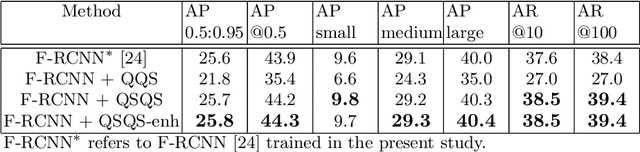
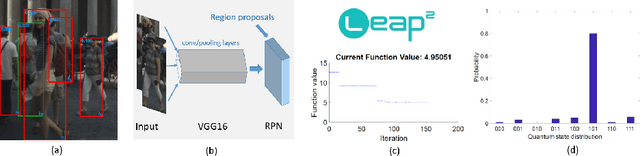
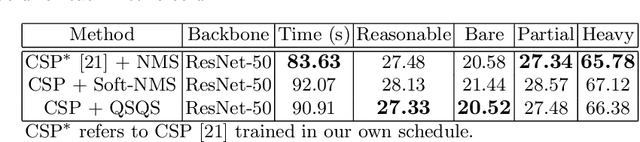
Non-maximum suppression (NMS) has been adopted by default for removing redundant object detections for decades. It eliminates false positives by only keeping the image M with highest detection score and images whose overlap ratio with M is less than a predefined threshold. However, this greedy algorithm may not work well for object detection under occlusion scenario where true positives with lower detection scores are possibly suppressed. In this paper, we first map the task of removing redundant detections into Quadratic Unconstrained Binary Optimization (QUBO) framework that consists of detection score from each bounding box and overlap ratio between pair of bounding boxes. Next, we solve the QUBO problem using the proposed Quantum-soft QUBO Suppression (QSQS) algorithm for fast and accurate detection by exploiting quantum computing advantages. Experiments indicate that QSQS improves mean average precision from 74.20% to 75.11% for PASCAL VOC 2007. It consistently outperforms NMS and soft-NMS for Reasonable subset of benchmark pedestrian detection CityPersons.
Approximate Manifold Defense Against Multiple Adversarial Perturbations
Apr 05, 2020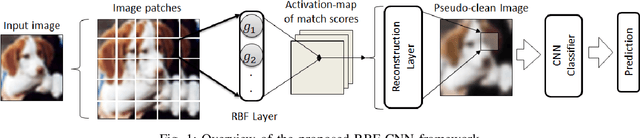



Existing defenses against adversarial attacks are typically tailored to a specific perturbation type. Using adversarial training to defend against multiple types of perturbation requires expensive adversarial examples from different perturbation types at each training step. In contrast, manifold-based defense incorporates a generative network to project an input sample onto the clean data manifold. This approach eliminates the need to generate expensive adversarial examples while achieving robustness against multiple perturbation types. However, the success of this approach relies on whether the generative network can capture the complete clean data manifold, which remains an open problem for complex input domain. In this work, we devise an approximate manifold defense mechanism, called RBF-CNN, for image classification. Instead of capturing the complete data manifold, we use an RBF layer to learn the density of small image patches. RBF-CNN also utilizes a reconstruction layer that mitigates any minor adversarial perturbations. Further, incorporating our proposed reconstruction process for training improves the adversarial robustness of our RBF-CNN models. Experiment results on MNIST and CIFAR-10 datasets indicate that RBF-CNN offers robustness for multiple perturbations without the need for expensive adversarial training.
Lifespan Age Transformation Synthesis
Mar 21, 2020

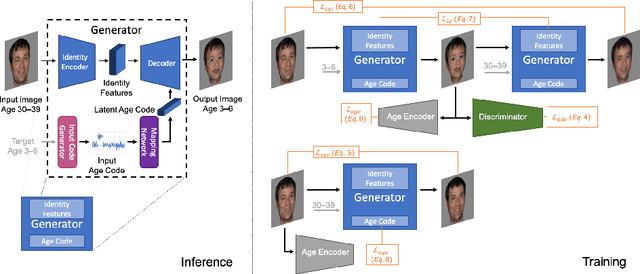
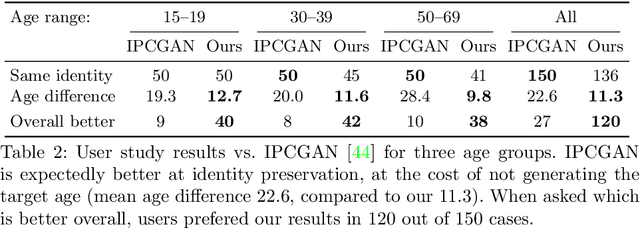
We address the problem of single photo age progression and regression-the prediction of how a person might look in the future, or how they looked in the past. Most existing aging methods are limited to changing the texture, overlooking transformations in head shape that occur during the human aging and growth process. This limits the applicability of previous methods to aging of adults to slightly older adults, and application of those methods to photos of children does not produce quality results. We propose a novel multi-domain image-to-image generative adversarial network architecture, whose learned latent space models a continuous bi-directional aging process. The network is trained on the FFHQ dataset, which we labeled for ages, gender, and semantic segmentation. Fixed age classes are used as anchors to approximate continuous age transformation. Our framework can predict a full head portrait for ages 0-70 from a single photo, modifying both texture and shape of the head. We demonstrate results on a wide variety of photos and datasets, and show significant improvement over the state of the art.
A Practical Solution for SAR Despeckling with Only Single Speckled Images
Dec 13, 2019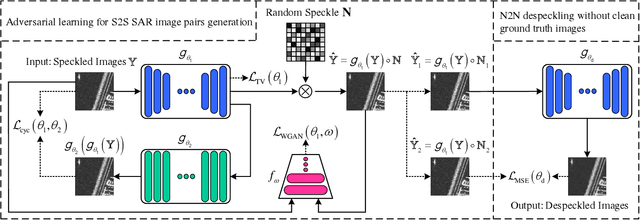
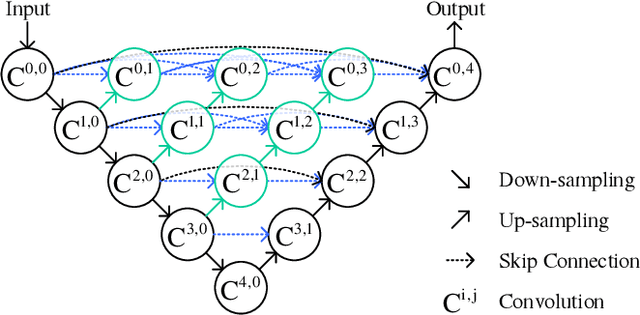

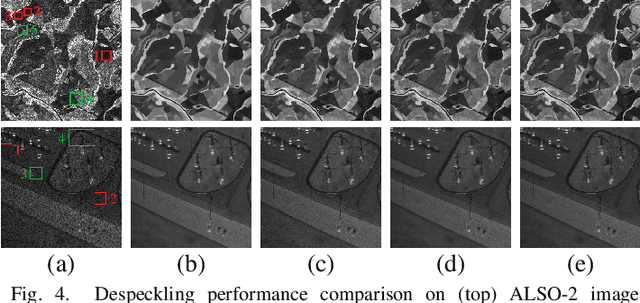
In this letter, we aim to address synthetic aperture radar (SAR) despeckling problem with the necessity of neither clean (speckle-free) SAR images nor independent speckled image pairs from the same scene, a practical solution for SAR despeckling (PSD) is proposed. Firstly, to generate speckled-to-speckled (S2S) image pairs from the same scene in the situation of only single speckled SAR images are available, an adversarial learning framework is designed. Then, the S2S SAR image pairs are employed to train a modified despeckling Nested-UNet model using the Noise2Noise (N2N) strategy. Moreover, an iterative version of the PSD method (PSDi) is also proposed. The performance of the proposed methods is demonstrated by both synthetic speckled and real SAR data. SAR block-matching 3-D algorithm (SAR-BM3D) and SAR dilated residual network (SAR-DRN) are used in the visual and quantitative comparison. Experimental results show that the proposed methods can reach a good tradeoff between speckle suppression and edge preservation.
On the Comparison of Classic and Deep Keypoint Detector and Descriptor Methods
Jul 20, 2020
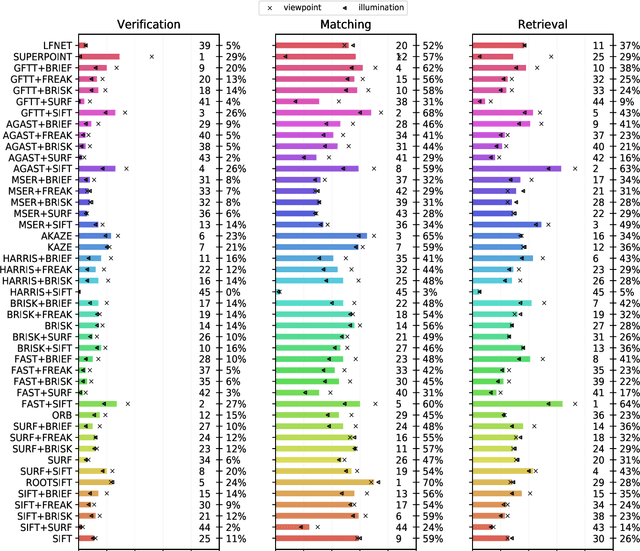
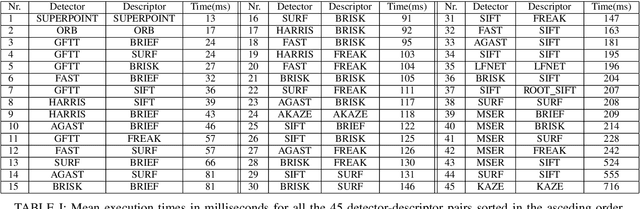
The purpose of this study is to give a performance comparison between several classic hand-crafted and deep key-point detector and descriptor methods. In particular, we consider the following classical algorithms: SIFT, SURF, ORB, FAST, BRISK, MSER, HARRIS, KAZE, AKAZE, AGAST, GFTT, FREAK, BRIEF and RootSIFT, where a subset of all combinations is paired into detector-descriptor pipelines. Additionally, we analyze the performance of two recent and perspective deep detector-descriptor models, LF-Net and SuperPoint. Our benchmark relies on the HPSequences dataset that provides real and diverse images under various geometric and illumination changes. We analyze the performance on three evaluation tasks: keypoint verification, image matching and keypoint retrieval. The results show that certain classic and deep approaches are still comparable, with some classic detector-descriptor combinations overperforming pretrained deep models. In terms of the execution times of tested implementations, SuperPoint model is the fastest, followed by ORB.
DeLTra: Deep Light Transport for Projector-Camera Systems
Mar 06, 2020
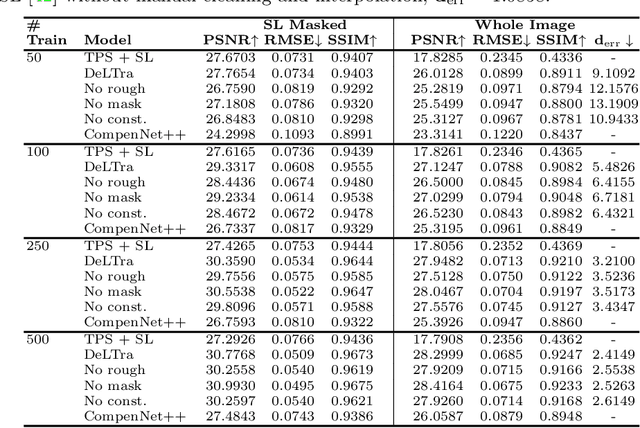
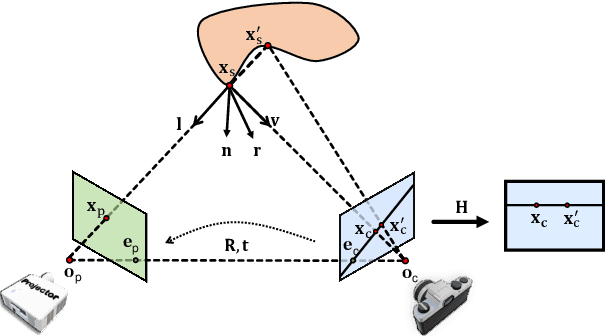

In projector-camera systems, light transport models the propagation from projector emitted radiance to camera-captured irradiance. In this paper, we propose the first end-to-end trainable solution named Deep Light Transport (DeLTra) that estimates radiometrically uncalibrated projector-camera light transport. DeLTra is designed to have two modules: DepthToAtrribute and ShadingNet. DepthToAtrribute explicitly learns rays, depth and normal, and then estimates rough Phong illuminations. Afterwards, the CNN-based ShadingNet renders photorealistic camera-captured image using estimated shading attributes and rough Phong illuminations. A particular challenge addressed by DeLTra is occlusion, for which we exploit epipolar constraint and propose a novel differentiable direct light mask. Thus, it can be learned end-to-end along with the other DeLTra modules. Once trained, DeLTra can be applied simultaneously to three projector-camera tasks: image-based relighting, projector compensation and depth/normal reconstruction. In our experiments, DeLTra shows clear advantages over previous arts with promising quality and meanwhile being practically convenient.