 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking the Route Towards Weakly Supervised Object Localization
Feb 26, 2020
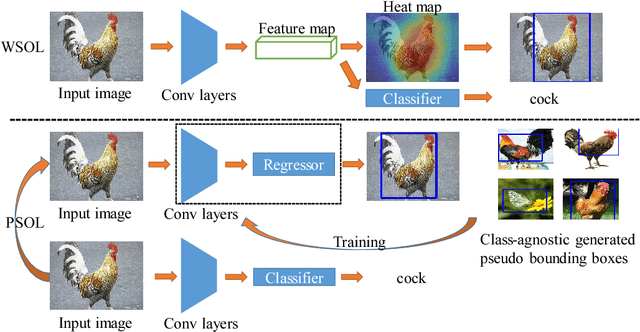
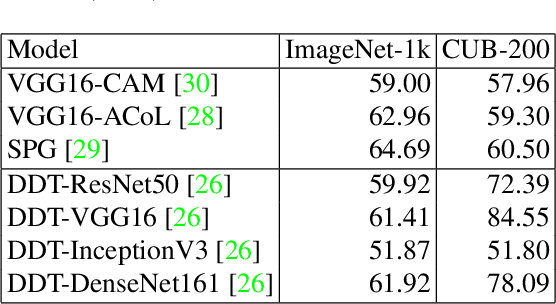
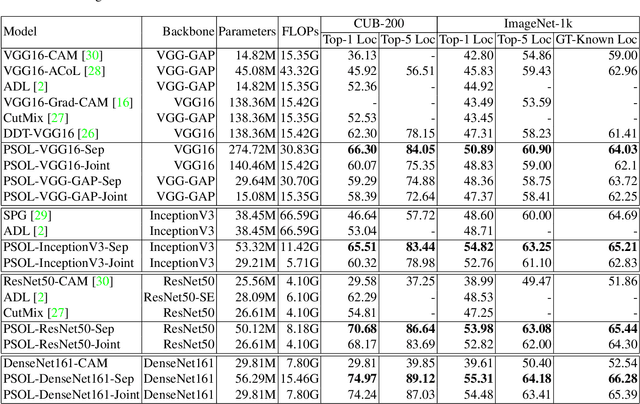
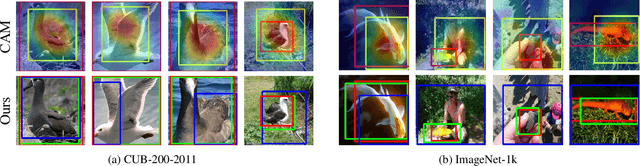
Weakly supervised object localization (WSOL) aims to localize objects with only image-level labels. Previous methods often try to utilize feature maps and classification weights to localize objects using image level annotations indirectly. In this paper, we demonstrate that weakly supervised object localization should be divided into two parts: class-agnostic object localization and object classification. For class-agnostic object localization, we should use class-agnostic methods to generate noisy pseudo annotations and then perform bounding box regression on them without class labels. We propose the pseudo supervised object localization (PSOL) method as a new way to solve WSOL. Our PSOL models have good transferability across different datasets without fine-tuning. With generated pseudo bounding boxes, we achieve 58.00% localization accuracy on ImageNet and 74.74% localization accuracy on CUB-200, which have a large edge over previous models.
An ensemble learning method for scene classification based on Hidden Markov Model image representation
Oct 05, 2016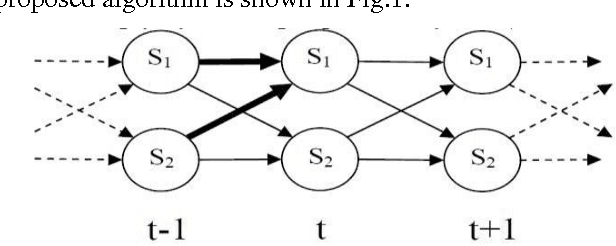
Low level images representation in feature space performs poorly for classification with high accuracy since this level of representation is not able to project images into the discriminative feature space. In this work, we propose an efficient image representation model for classification. First we apply Hidden Markov Model (HMM) on ordered grids represented by different type of image descriptors in order to include causality of local properties existing in image for feature extraction and then we train up a separate classifier for each of these features sets. Finally we ensemble these classifiers efficiently in a way that they can cancel out each other errors for obtaining higher accuracy. This method is evaluated on 15 natural scene dataset. Experimental results show the superiority of the proposed method in comparison to some current existing methods
Scilab and SIP for Image Processing
Mar 18, 2012
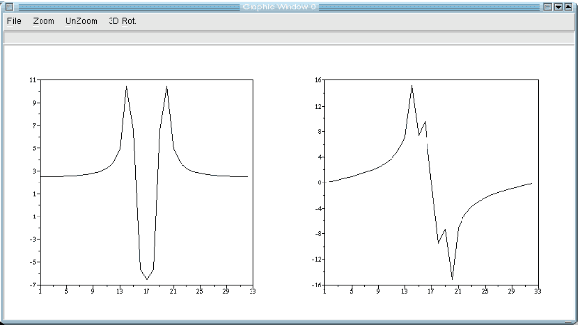
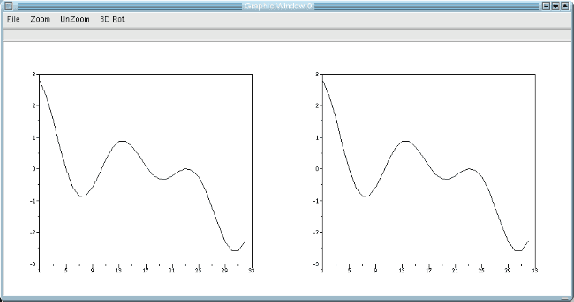

This paper is an overview of Image Processing and Analysis using Scilab, a free prototyping environment for numerical calculations similar to Matlab. We demonstrate the capabilities of SIP -- the Scilab Image Processing Toolbox -- which extends Scilab with many functions to read and write images in over 100 major file formats, including PNG, JPEG, BMP, and TIFF. It also provides routines for image filtering, edge detection, blurring, segmentation, shape analysis, and image recognition. Basic directions to install Scilab and SIP are given, and also a mini-tutorial on Scilab. Three practical examples of image analysis are presented, in increasing degrees of complexity, showing how advanced image analysis techniques seems uncomplicated in this environment.
Classification of Diabetic Retinopathy Using Unlabeled Data and Knowledge Distillation
Sep 01, 2020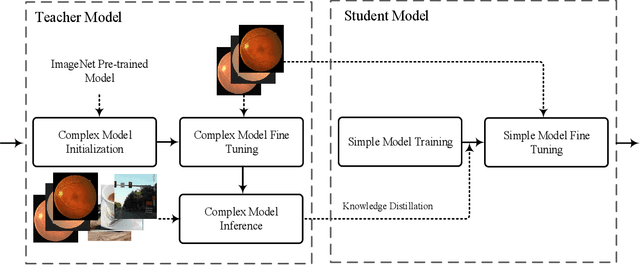
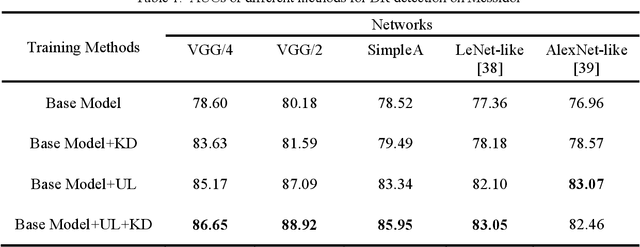
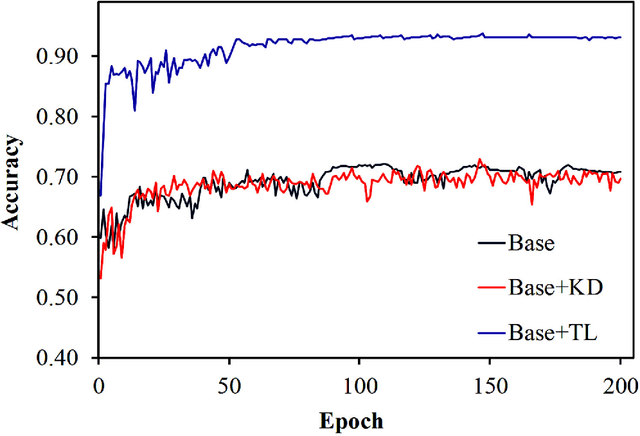
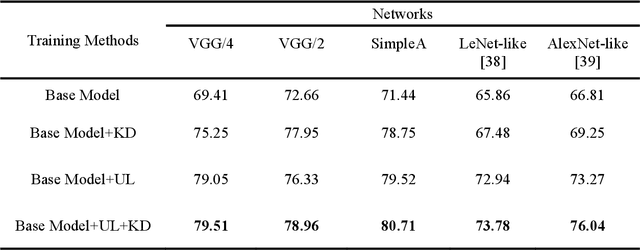
Knowledge distillation allows transferring knowledge from a pre-trained model to another. However, it suffers from limitations, and constraints related to the two models need to be architecturally similar. Knowledge distillation addresses some of the shortcomings associated with transfer learning by generalizing a complex model to a lighter model. However, some parts of the knowledge may not be distilled by knowledge distillation sufficiently. In this paper, a novel knowledge distillation approach using transfer learning is proposed. The proposed method transfers the entire knowledge of a model to a new smaller one. To accomplish this, unlabeled data are used in an unsupervised manner to transfer the maximum amount of knowledge to the new slimmer model. The proposed method can be beneficial in medical image analysis, where labeled data are typically scarce. The proposed approach is evaluated in the context of classification of images for diagnosing Diabetic Retinopathy on two publicly available datasets, including Messidor and EyePACS. Simulation results demonstrate that the approach is effective in transferring knowledge from a complex model to a lighter one. Furthermore, experimental results illustrate that the performance of different small models is improved significantly using unlabeled data and knowledge distillation.
Fully Embedding Fast Convolutional Networks on Pixel Processor Arrays
Apr 27, 2020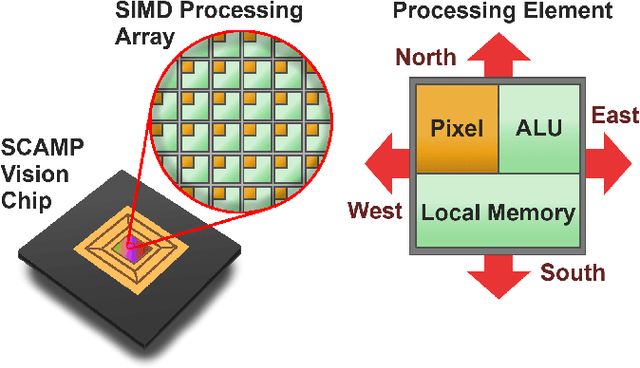
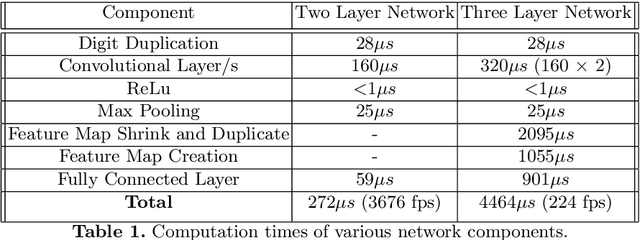
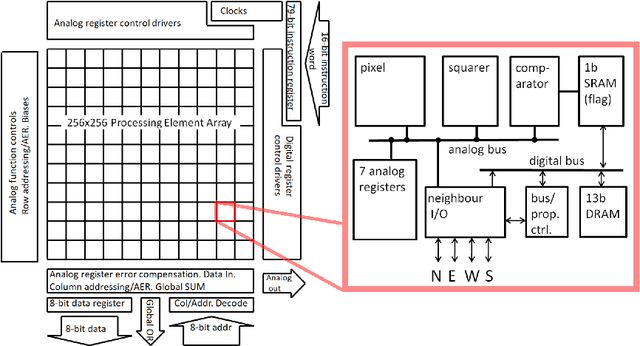
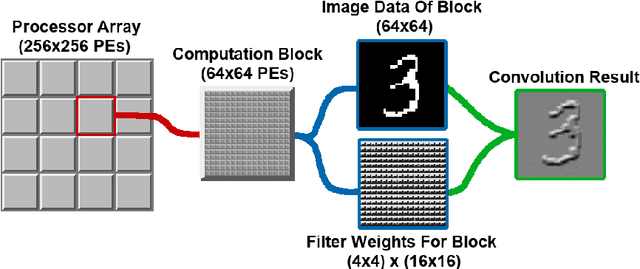
We present a novel method of CNN inference for pixel processor array (PPA) vision sensors, designed to take advantage of their massive parallelism and analog compute capabilities. PPA sensors consist of an array of processing elements (PEs), with each PE capable of light capture, data storage and computation, allowing various computer vision processing to be executed directly upon the sensor device. The key idea behind our approach is storing network weights "in-pixel" within the PEs of the PPA sensor itself to allow various computations, such as multiple different image convolutions, to be carried out in parallel. Our approach can perform convolutional layers, max pooling, ReLu, and a final fully connected layer entirely upon the PPA sensor, while leaving no untapped computational resources. This is in contrast to previous works that only use a sensor-level processing to sequentially compute image convolutions, and must transfer data to an external digital processor to complete the computation. We demonstrate our approach on the SCAMP-5 vision system, performing inference of a MNIST digit classification network at over 3000 frames per second and over 93% classification accuracy. This is the first work demonstrating CNN inference conducted entirely upon the processor array of a PPA vision sensor device, requiring no external processing.
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
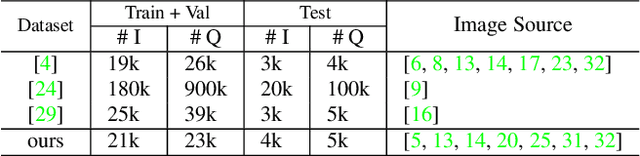

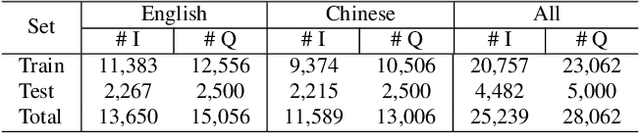
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
Multi-modal Datasets for Super-resolution
Apr 13, 2020
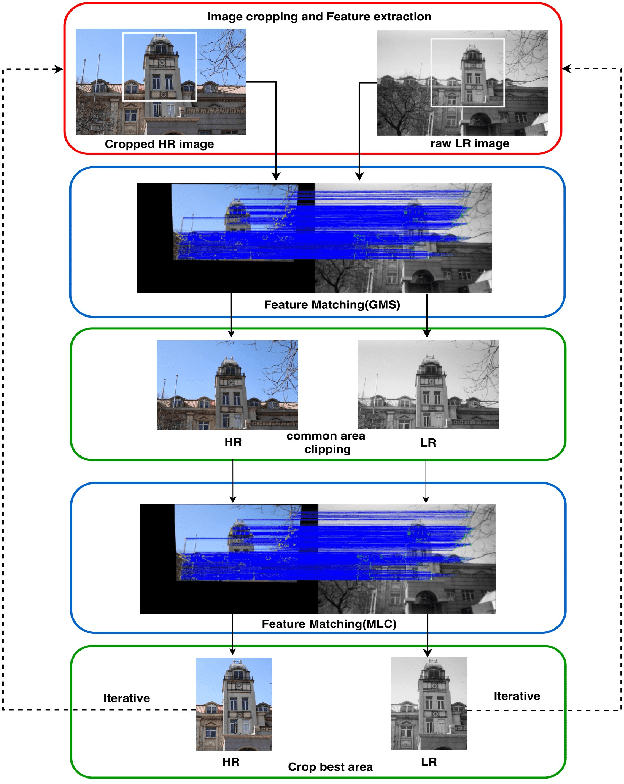
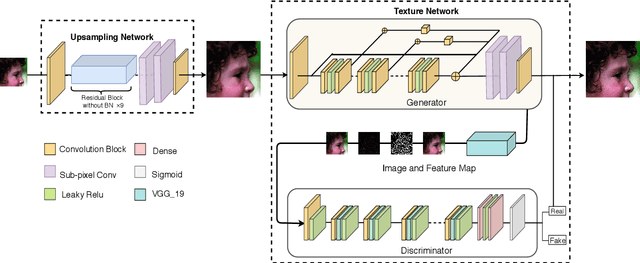

Nowdays, most datasets used to train and evaluate super-resolution models are single-modal simulation datasets. However, due to the variety of image degradation types in the real world, models trained on single-modal simulation datasets do not always have good robustness and generalization ability in different degradation scenarios. Previous work tended to focus only on true-color images. In contrast, we first proposed real-world black-and-white old photo datasets for super-resolution (OID-RW), which is constructed using two methods of manually filling pixels and shooting with different cameras. The dataset contains 82 groups of images, including 22 groups of character type and 60 groups of landscape and architecture. At the same time, we also propose a multi-modal degradation dataset (MDD400) to solve the super-resolution reconstruction in real-life image degradation scenarios. We managed to simulate the process of generating degraded images by the following four methods: interpolation algorithm, CNN network, GAN network and capturing videos with different bit rates. Our experiments demonstrate that not only the models trained on our dataset have better generalization capability and robustness, but also the trained images can maintain better edge contours and texture features.
Generalized Product Quantization Network for Semi-supervised Hashing
Feb 26, 2020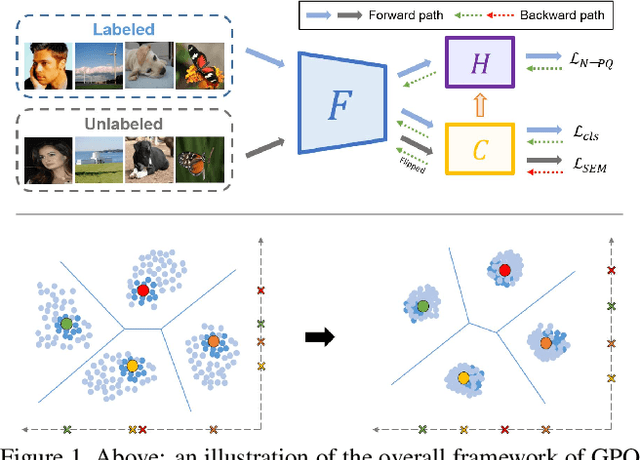
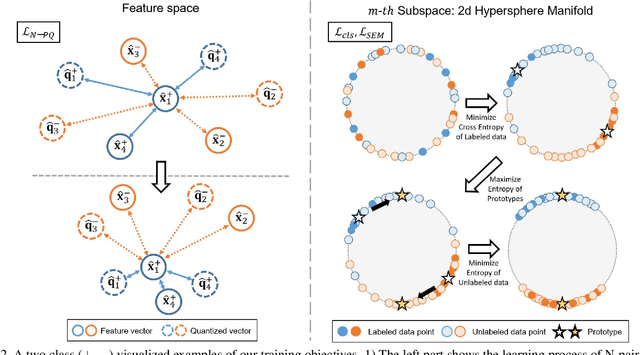
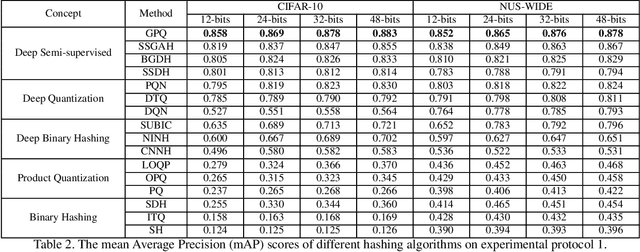
Learning to hash has achieved great success in image retrieval due to its low storage cost and fast search speed. In recent years, hashing methods that take advantage of deep learning have come into the spotlight with some positive outcomes. However, these approaches do not meet expectations unless expensive label information is sufficient. To resolve this issue, we propose the first quantization-based semi-supervised hashing scheme: Generalized Product Quantization (\textbf{GPQ}) network. We design a novel metric learning strategy that preserves semantic similarity between labeled data, and employ entropy regularization term to fully exploit inherent potentials of unlabeled data. Our solution increases the generalization capacity of the hash function, which allows overcoming previous limitations in the retrieval community. Extensive experimental results demonstrate that GPQ yields state-of-the-art performance on large-scale real image benchmark datasets.
Poisson Noise Reduction with Higher-order Natural Image Prior Model
Sep 19, 2016
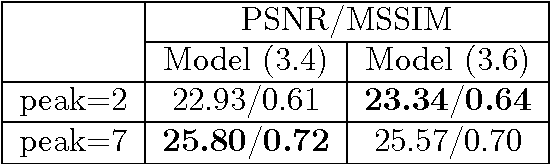

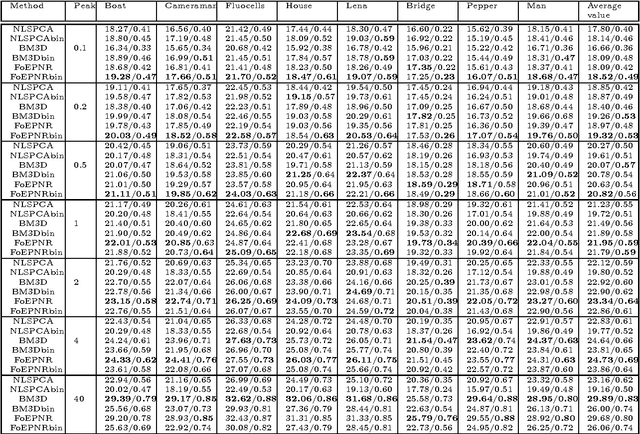
Poisson denoising is an essential issue for various imaging applications, such as night vision, medical imaging and microscopy. State-of-the-art approaches are clearly dominated by patch-based non-local methods in recent years. In this paper, we aim to propose a local Poisson denoising model with both structure simplicity and good performance. To this end, we consider a variational modeling to integrate the so-called Fields of Experts (FoE) image prior, that has proven an effective higher-order Markov Random Fields (MRF) model for many classic image restoration problems. We exploit several feasible variational variants for this task. We start with a direct modeling in the original image domain by taking into account the Poisson noise statistics, which performs generally well for the cases of high SNR. However, this strategy encounters problem in cases of low SNR. Then we turn to an alternative modeling strategy by using the Anscombe transform and Gaussian statistics derived data term. We retrain the FoE prior model directly in the transform domain. With the newly trained FoE model, we end up with a local variational model providing strongly competitive results against state-of-the-art non-local approaches, meanwhile bearing the property of simple structure. Furthermore, our proposed model comes along with an additional advantage, that the inference is very efficient as it is well-suited for parallel computation on GPUs. For images of size $512 \times 512$, our GPU implementation takes less than 1 second to produce state-of-the-art Poisson denoising performance.
On The Usage Of Average Hausdorff Distance For Segmentation Performance Assessment: Hidden Bias When Used For Ranking
Sep 01, 2020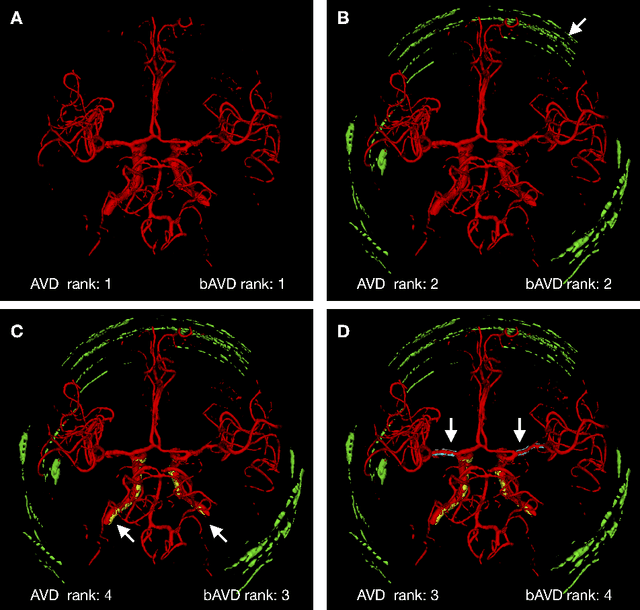
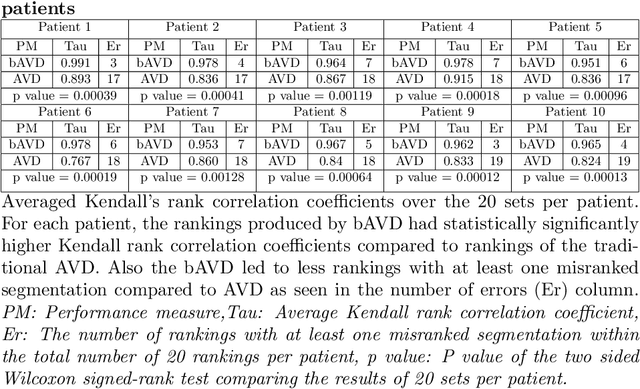
Average Hausdorff Distance (AVD) is a widely used performance measure to calculate the distance between two point sets. In medical image segmentation, AVD is used to compare ground truth images with segmentation results allowing their ranking. We identified, however, a ranking bias of AVD making it less suitable for segmentation ranking. To mitigate this bias, we present a modified calculation of AVD that we have coined balanced AVD (bAVD). To simulate segmentations for ranking, we manually created non-overlapping segmentation errors common in cerebral vessel segmentation as our use-case. Adding the created errors consecutively and randomly to the ground truth, we created sets of simulated segmentations with increasing number of errors. Each set of simulated segmentations was ranked using AVD and bAVD. We calculated the Kendall-rank-correlation-coefficient between the segmentation ranking and the number of errors in each simulated segmentation. The rankings produced by bAVD had a significantly higher average correlation (0.969) than those of AVD (0.847). In 200 total rankings, bAVD misranked 52 and AVD misranked 179 segmentations. Our proposed evaluation measure, bAVD, alleviates AVDs ranking bias making it more suitable for rankings and quality assessment of segmentations.