 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Skepxels: Spatio-temporal Image Representation of Human Skeleton Joints for Action Recognition
Aug 03, 2018
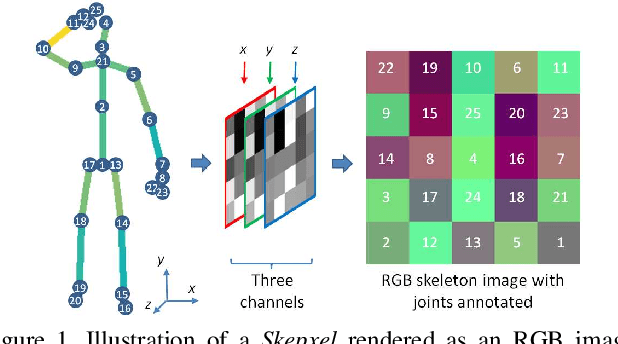
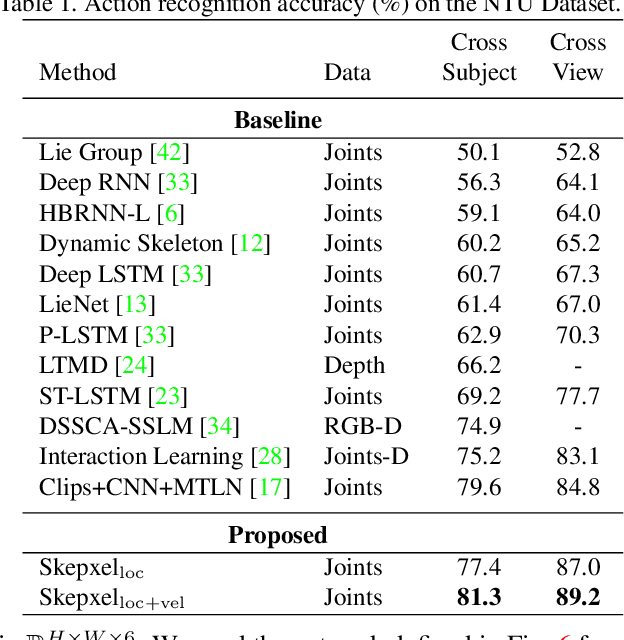

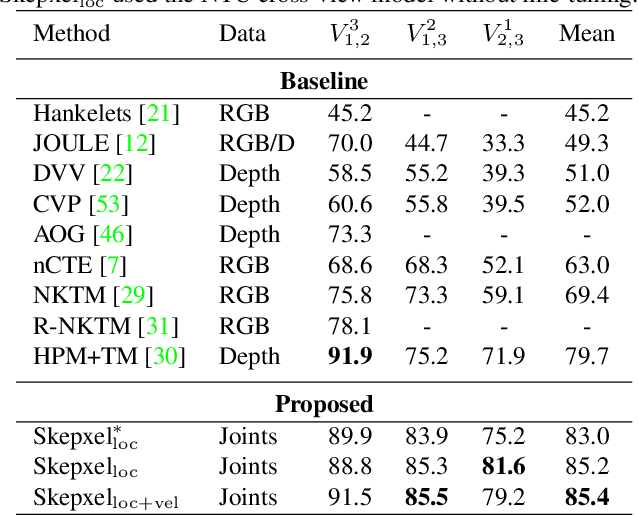
Human skeleton joints are popular for action analysis since they can be easily extracted from videos to discard background noises. However, current skeleton representations do not fully benefit from machine learning with CNNs. We propose "Skepxels" a spatio-temporal representation for skeleton sequences to fully exploit the "local" correlations between joints using the 2D convolution kernels of CNN. We transform skeleton videos into images of flexible dimensions using Skepxels and develop a CNN-based framework for effective human action recognition using the resulting images. Skepxels encode rich spatio-temporal information about the skeleton joints in the frames by maximizing a unique distance metric, defined collaboratively over the distinct joint arrangements used in the skeletal image. Moreover, they are flexible in encoding compound semantic notions such as location and speed of the joints. The proposed action recognition exploits the representation in a hierarchical manner by first capturing the micro-temporal relations between the skeleton joints with the Skepxels and then exploiting their macro-temporal relations by computing the Fourier Temporal Pyramids over the CNN features of the skeletal images. We extend the Inception-ResNet CNN architecture with the proposed method and improve the state-of-the-art accuracy by 4.4% on the large scale NTU human activity dataset. On the medium-sized N-UCLA and UTH-MHAD datasets, our method outperforms the existing results by 5.7% and 9.3% respectively.
Sketch-to-Art: Synthesizing Stylized Art Images From Sketches
Feb 26, 2020



We propose a new approach for synthesizing fully detailed art-stylized images from sketches. Given a sketch, with no semantic tagging, and a reference image of a specific style, the model can synthesize meaningful details with colors and textures. The model consists of three modules designed explicitly for better artistic style capturing and generation. Based on a GAN framework, a dual-masked mechanism is introduced to enforce the content constraints (from the sketch), and a feature-map transformation technique is developed to strengthen the style consistency (to the reference image). Finally, an inverse procedure of instance-normalization is proposed to disentangle the style and content information, therefore yields better synthesis performance. Experiments demonstrate a significant qualitative and quantitative boost over baselines based on previous state-of-the-art techniques, adopted for the proposed process.
Conditional Sampling With Monotone GANs
Jun 11, 2020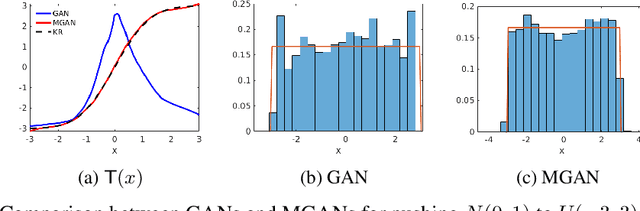
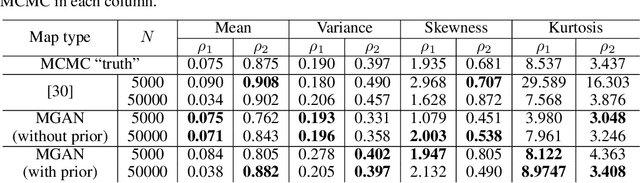
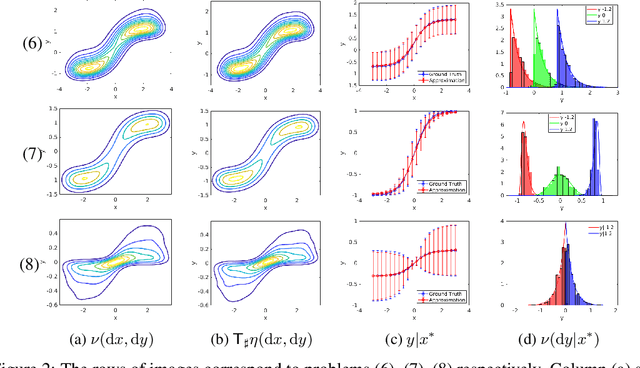
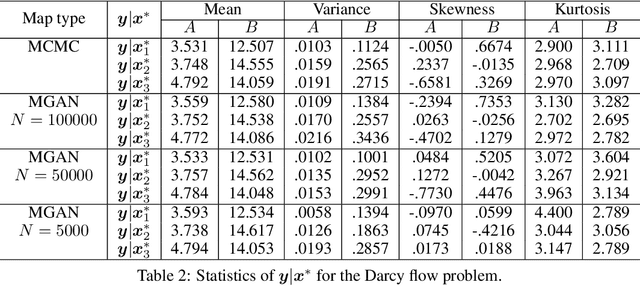
We present a new approach for sampling conditional measures that enables uncertainty quantification in supervised learning tasks. We construct a mapping that transforms a reference measure to the probability measure of the output conditioned on new inputs. The mapping is trained via a modification of generative adversarial networks (GANs), called monotone GANs, that imposes monotonicity constraints and a block triangular structure. We present theoretical results, in an idealized setting, that support our proposed method as well as numerical experiments demonstrating the ability of our method to sample the correct conditional measures in applications ranging from inverse problems to image in-painting.
Transfer learning extensions for the probabilistic classification vector machine
Jul 11, 2020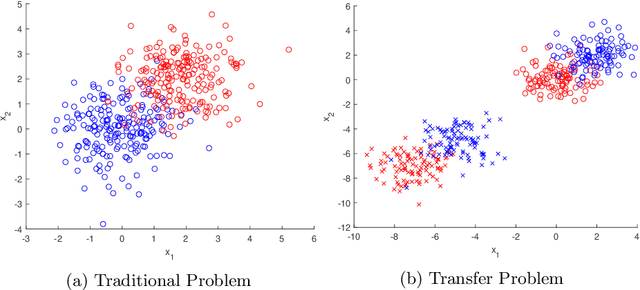
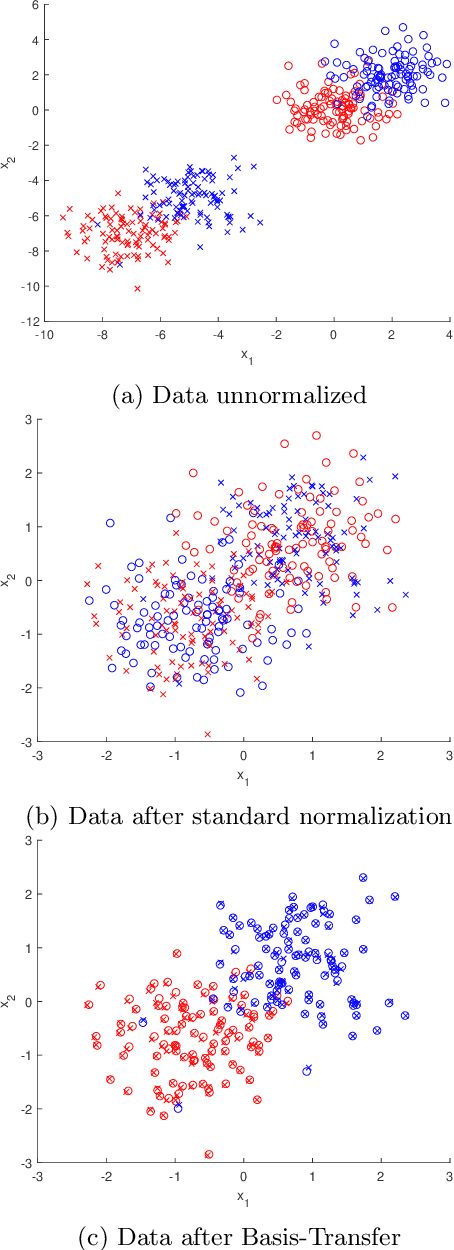
Transfer learning is focused on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these fields, the learning scenarios are naturally changing but often remain related to each other motivating the reuse of existing supervised models. Current transfer learning models are neither sparse nor interpretable. Sparsity is very desirable if the methods have to be used in technically limited environments and interpretability is getting more critical due to privacy regulations. In this work, we propose two transfer learning extensions integrated into the sparse and interpretable probabilistic classification vector machine. They are compared to standard benchmarks in the field and show their relevance either by sparsity or performance improvements.
* arXiv admin note: text overlap with arXiv:1907.01343
Unsupervised Person Re-identification via Softened Similarity Learning
Apr 07, 2020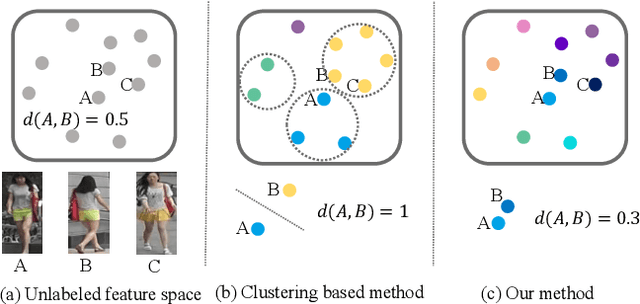
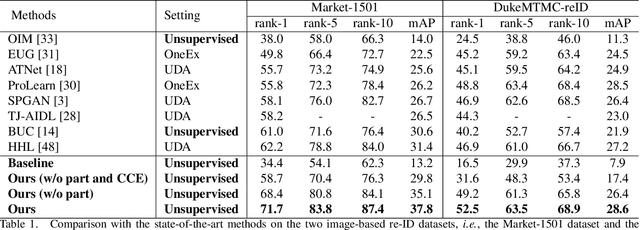
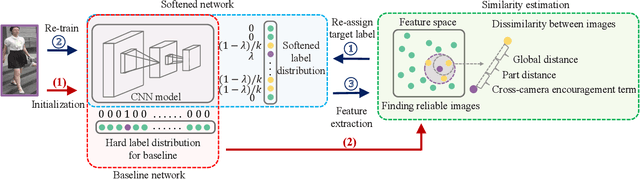
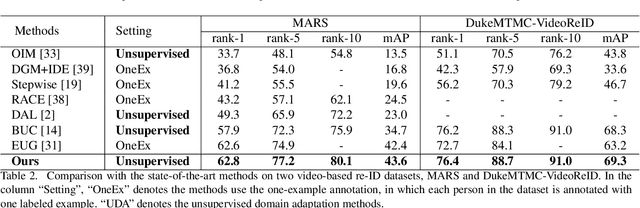
Person re-identification (re-ID) is an important topic in computer vision. This paper studies the unsupervised setting of re-ID, which does not require any labeled information and thus is freely deployed to new scenarios. There are very few studies under this setting, and one of the best approach till now used iterative clustering and classification, so that unlabeled images are clustered into pseudo classes for a classifier to get trained, and the updated features are used for clustering and so on. This approach suffers two problems, namely, the difficulty of determining the number of clusters, and the hard quantization loss in clustering. In this paper, we follow the iterative training mechanism but discard clustering, since it incurs loss from hard quantization, yet its only product, image-level similarity, can be easily replaced by pairwise computation and a softened classification task. With these improvements, our approach becomes more elegant and is more robust to hyper-parameter changes. Experiments on two image-based and video-based datasets demonstrate state-of-the-art performance under the unsupervised re-ID setting.
Encoding Power Traces as Images for Efficient Side-Channel Analysis
May 18, 2020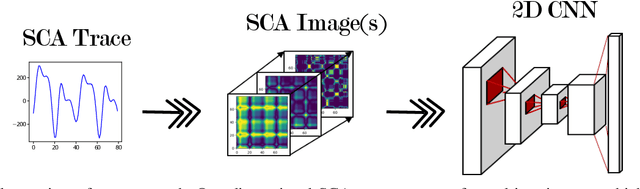
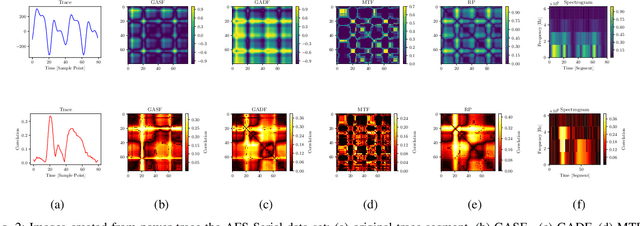
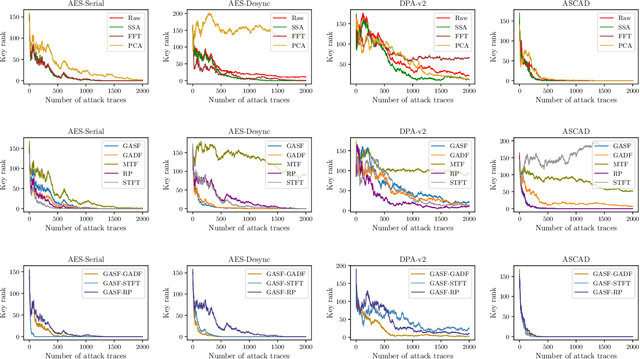
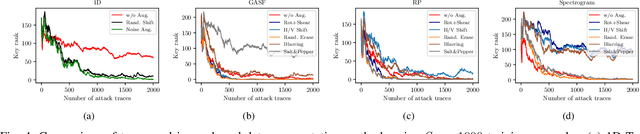
Side-Channel Attacks (SCAs) are a powerful method to attack implementations of cryptographic algorithms. State-of-the-art techniques such as template attacks and stochastic models usually require a lot of manual preprocessing and feature extraction by the attacker. Deep Learning (DL) methods have been introduced to simplify SCAs and simultaneously lowering the amount of required side-channel traces for a successful attack. However, the general success of DL is largely driven by their capability to classify images, a field in which they easily outperform humans. In this paper, we present a novel technique to interpret 1D traces as 2D images. We show and compare several techniques to transform power traces into images, and apply these on different implementations of the Advanced Encryption Standard (AES). By allowing the neural network to interpret the trace as an image, we are able to significantly reduce the number of required attack traces for a correct key guess.We also demonstrate that the attack efficiency can be improved by using multiple 2D images in the depth channel as an input. Furthermore, by applying image-based data augmentation, we show how the number of profiling traces is reduced by a factor of 50 while simultaneously enhancing the attack performance. This is a crucial improvement, as the amount of traces that can be recorded by an attacker is often very limited in real-life applications.
NASirt: AutoML based learning with instance-level complexity information
Aug 26, 2020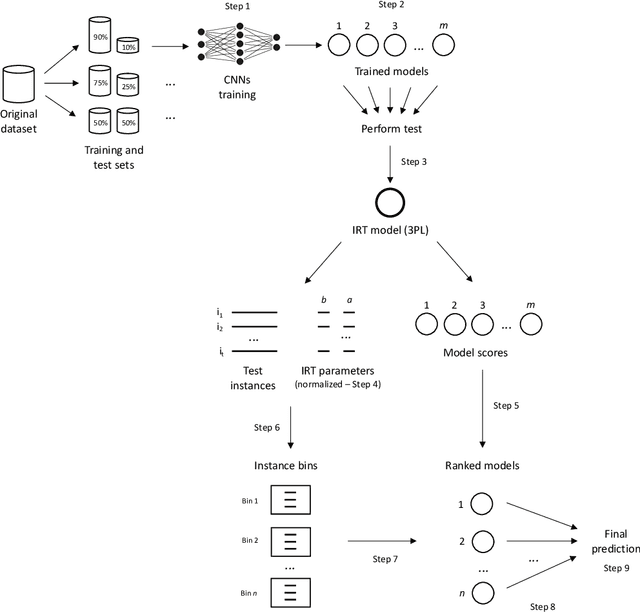
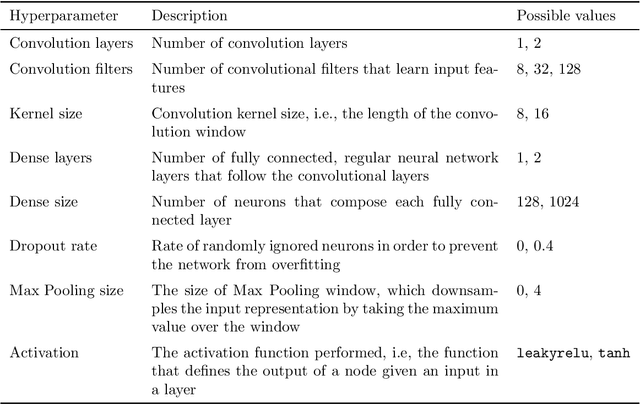

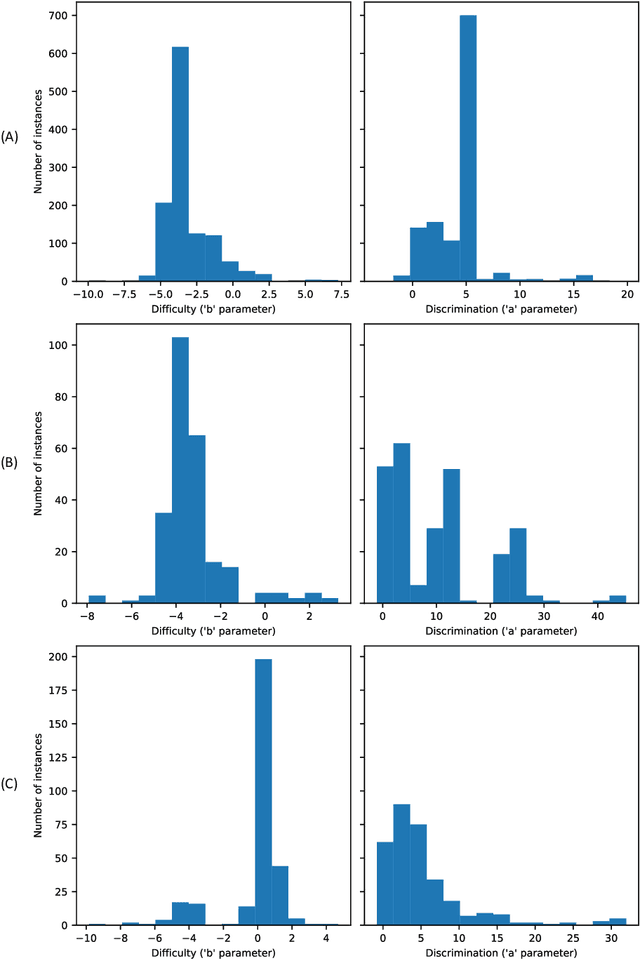
Designing adequate and precise neural architectures is a challenging task, often done by highly specialized personnel. AutoML is a machine learning field that aims to generate good performing models in an automated way. Spectral data such as those obtained from biological analysis have generally a lot of important information, and these data are specifically well suited to Convolutional Neural Networks (CNN) due to their image-like shape. In this work we present NASirt, an AutoML methodology based on Neural Architecture Search (NAS) that finds high accuracy CNN architectures for spectral datasets. The proposed methodology relies on the Item Response Theory (IRT) for obtaining characteristics from an instance level, such as discrimination and difficulty, and it is able to define a rank of top performing submodels. Several experiments are performed in order to demonstrate the methodology's performance with different spectral datasets. Accuracy results are compared to other benchmarks methods, such as a high performing, manually crafted CNN and the Auto-Keras AutoML tool. The results show that our method performs, in most cases, better than the benchmarks, achieving average accuracy as high as 96.96%.
System Design and Analysis for Energy-Efficient Passive UAV Radar Imaging System using Illuminators of Opportunity
Oct 01, 2020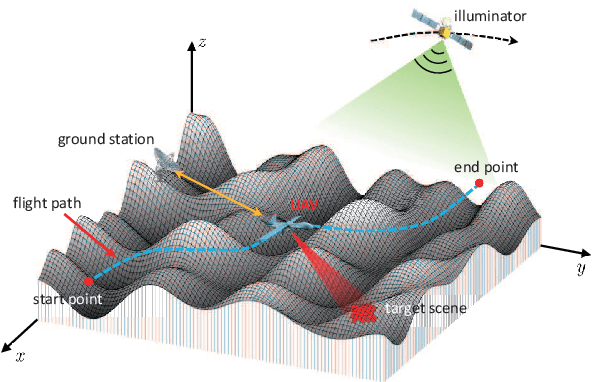
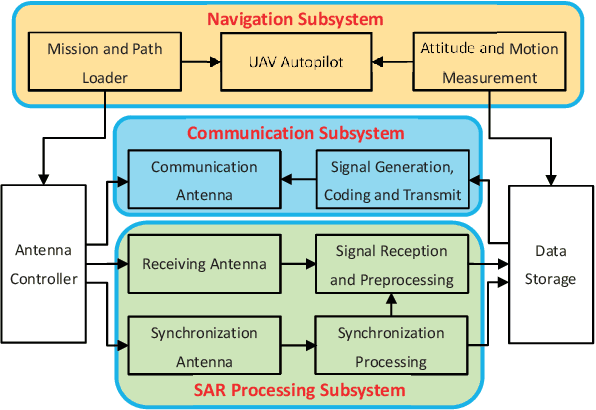
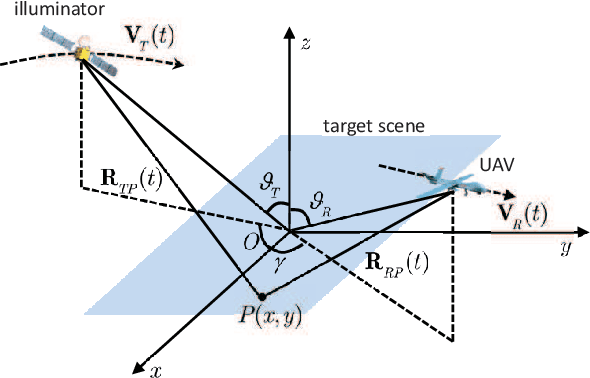
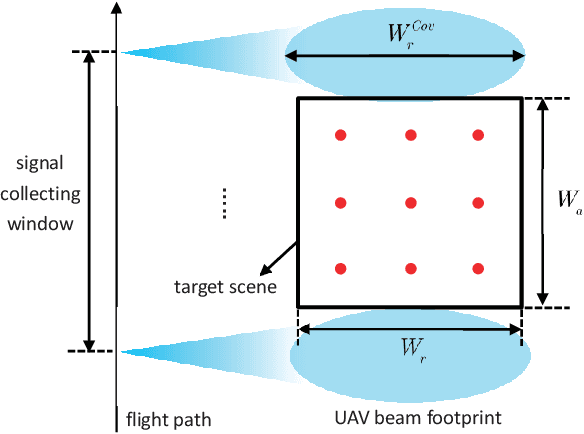
Unmanned ariel vehicle (UAV) can provide superior flexibility and cost-efficiency for modern radar imaging systems, which is an ideal platform for advanced remote sensing applications using synthetic aperture radar (SAR) technology. In this paper, an energy-efficient passive UAV radar imaging system using illuminators of opportunity is first proposed and investigated. Equipped with a SAR receiver, the UAV platform passively reuses the backscattered signal of the target scene from an external illuminator, such as SAR satellite, GNSS or ground-based stationary commercial illuminators, and achieves bi-static SAR imaging and data communication. The system can provide instant accessibility to the radar image of the interested targets with enhanced platform concealment, which is an essential tool for stealth observation and scene monitoring. The mission concept and system block diagram are first presented with justifications on the advantages of the system. Then, the prospective imaging performance and system feasibility are analyzed for the typical illuminators based on signal and spatial resolution model. With different illuminators, the proposed system can achieve distinct imaging performance, which offers more alternatives for various mission requirements. A set of mission performance evaluators is established to quantitatively assess the capability of the system in a comprehensive manner, including UAV navigation, passive SAR imaging and communication. Finally, the validity of the proposed performance evaluators are verified by numerical simulations.
Tabular Structure Detection from Document Images for Resource Constrained Devices Using A Row Based Similarity Measure
Aug 26, 2020
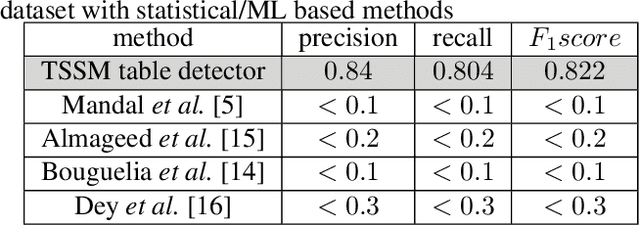

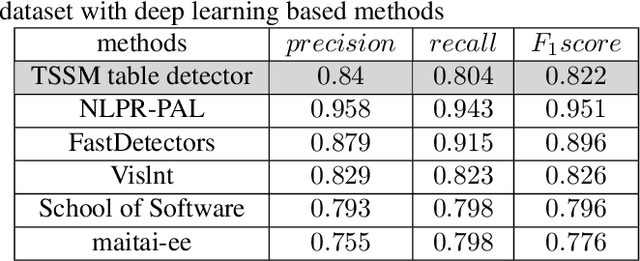
Tabular structures are used to present crucial information in a structured and crisp manner. Detection of such regions is of great importance for proper understanding of a document. Tabular structures can be of various layouts and types. Therefore, detection of these regions is a hard problem. Most of the existing techniques detect tables from a document image by using prior knowledge of the structures of the tables. However, these methods are not applicable for generalized tabular structures. In this work, we propose a similarity measure to find similarities between pairs of rows in a tabular structure. This similarity measure is utilized to identify a tabular region. Since the tabular regions are detected exploiting the similarities among all rows, the method is inherently independent of layouts of the tabular regions present in the training data. Moreover, the proposed similarity measure can be used to identify tabular regions without using large sets of parameters associated with recent deep learning based methods. Thus, the proposed method can easily be used with resource constrained devices such as mobile devices without much of an overhead.
Explanation of Unintended Radiated Emission Classification via LIME
Sep 08, 2020
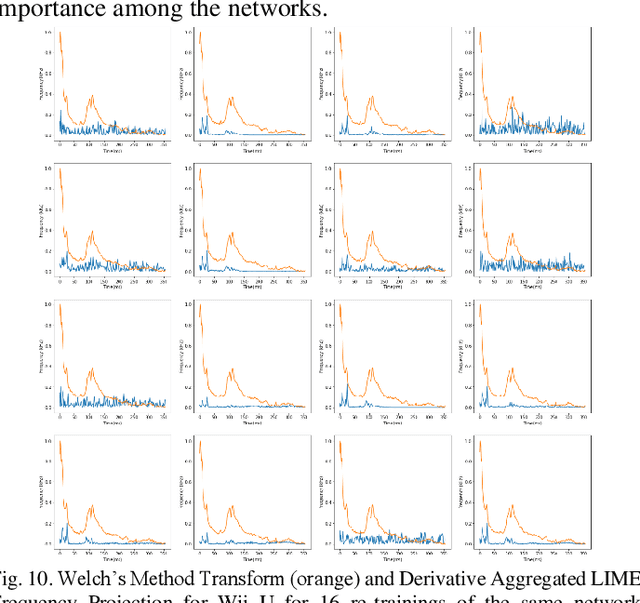
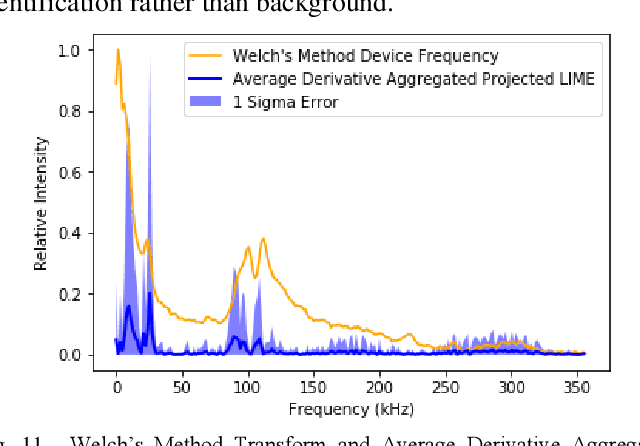
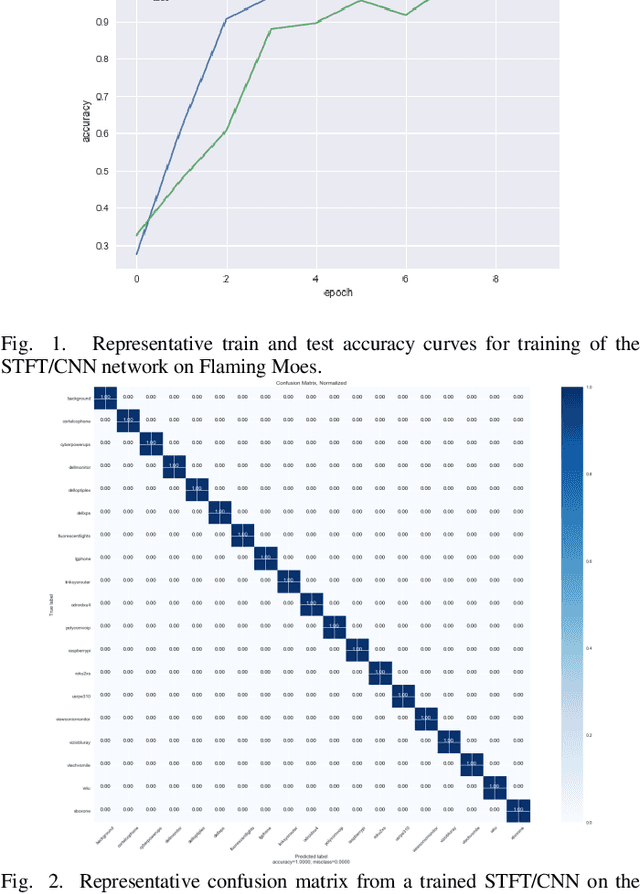
Unintended radiated emissions arise during the use of electronic devices. Identifying and mitigating the effects of these emissions is a key element of modern power engineering and associated control systems. Signal processing of the electrical system can identify the sources of these emissions. A dataset known as Flaming Moes includes captured unintended radiated emissions from consumer electronics. This dataset was analyzed to construct next-generation methods for device identification. To this end, a neural network based on applying the ResNet-18 image classification architecture to the short time Fourier transforms of short segments of voltage signatures was constructed. Using this classifier, the 18 device classes and background class were identified with close to 100 percent accuracy. By applying LIME to this classifier and aggregating the results over many classifications for the same device, it was possible to determine the frequency bands used by the classifier to make decisions. Using ensembles of classifiers trained on very similar datasets from the same parent data distribution, it was possible to recover robust sets of features of device output useful for identification. The additional understanding provided by the application of LIME enhances the trainability, trustability, and transferability of URE analysis networks.