 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Peeking into occluded joints: A novel framework for crowd pose estimation
Mar 23, 2020

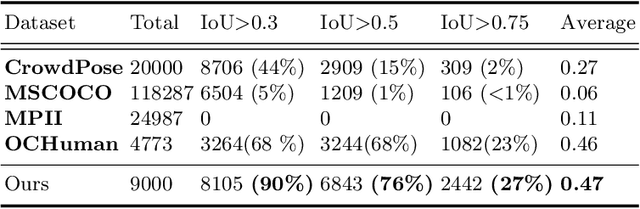
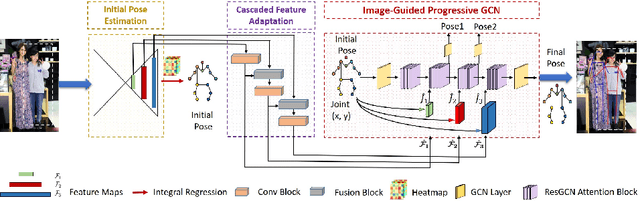

Although occlusion widely exists in nature and remains a fundamental challenge for pose estimation, existing heatmap-based approaches suffer serious degradation on occlusions. Their intrinsic problem is that they directly localize the joints based on visual information; however, the invisible joints are lack of that. In contrast to localization, our framework estimates the invisible joints from an inference perspective by proposing an Image-Guided Progressive GCN module which provides a comprehensive understanding of both image context and pose structure. Moreover, existing benchmarks contain limited occlusions for evaluation. Therefore, we thoroughly pursue this problem and propose a novel OPEC-Net framework together with a new Occluded Pose (OCPose) dataset with 9k annotated images. Extensive quantitative and qualitative evaluations on benchmarks demonstrate that OPEC-Net achieves significant improvements over recent leading works. Notably, our OCPose is the most complex occlusion dataset with respect to average IoU between adjacent instances. Source code and OCPose will be publicly available.
Learning Object-specific Distance from a Monocular Image
Sep 09, 2019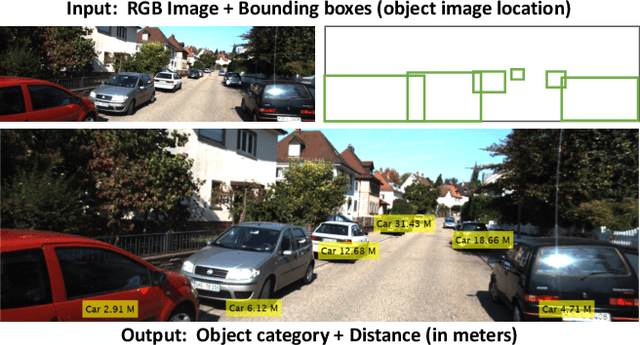
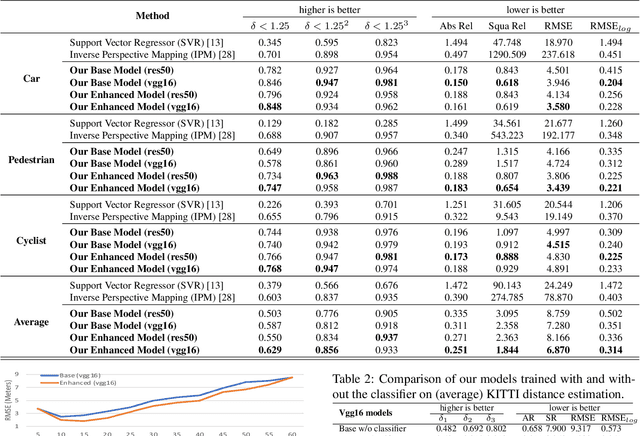
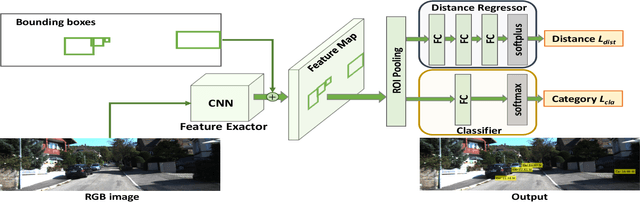
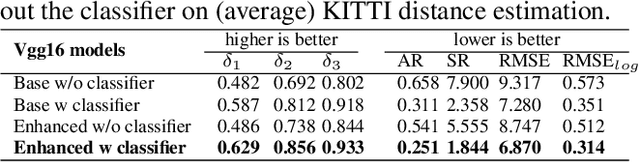
Environment perception, including object detection and distance estimation, is one of the most crucial tasks for autonomous driving. Many attentions have been paid on the object detection task, but distance estimation only arouse few interests in the computer vision community. Observing that the traditional inverse perspective mapping algorithm performs poorly for objects far away from the camera or on the curved road, in this paper, we address the challenging distance estimation problem by developing the first end-to-end learning-based model to directly predict distances for given objects in the images. Besides the introduction of a learning-based base model, we further design an enhanced model with a keypoint regressor, where a projection loss is defined to enforce a better distance estimation, especially for objects close to the camera. To facilitate the research on this task, we construct the extented KITTI and nuScenes (mini) object detection datasets with a distance for each object. Our experiments demonstrate that our proposed methods outperform alternative approaches (e.g., the traditional IPM, SVR) on object-specific distance estimation, particularly for the challenging cases that objects are on a curved road. Moreover, the performance margin implies the effectiveness of our enhanced method.
Comparison of scanned administrative document images
Jan 29, 2020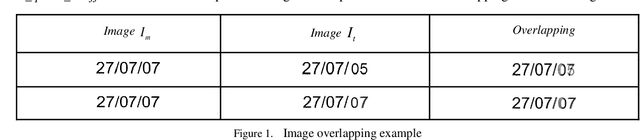
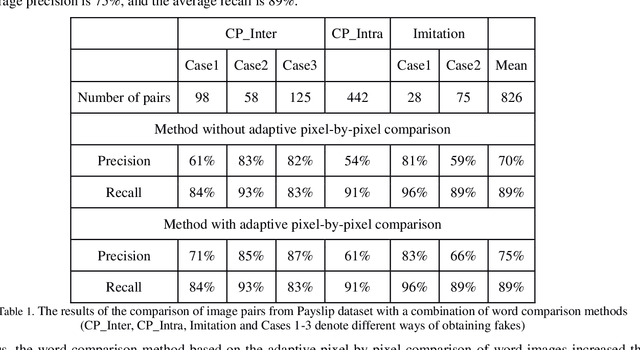
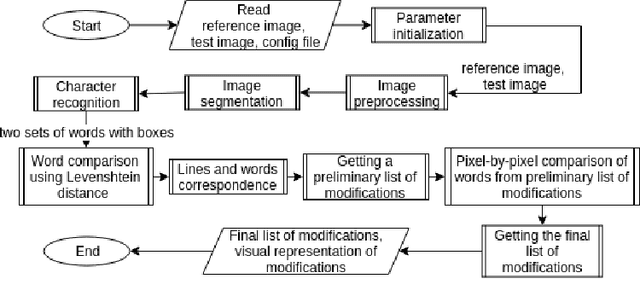
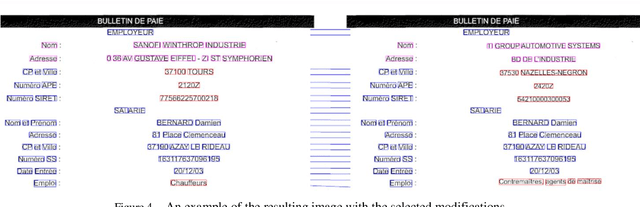
In this work the methods of comparison of digitized copies of administrative documents were considered. This problem arises, for example, when comparing two copies of documents signed by two parties in order to find possible modifications made by one party, in the banking sector at the conclusion of contracts in paper form. The proposed method of document image comparison is based on a combination of several ways of image comparison of words that are descriptors of text feature points. Testing was conducted on public Payslip Dataset (French). The results showed the high quality and the reliability of finding differences in two images that are versions of the same document.
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 05, 2020
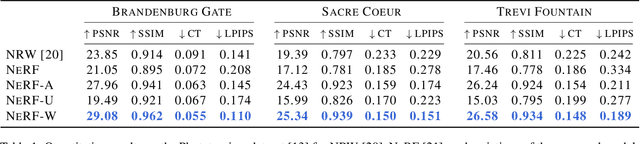

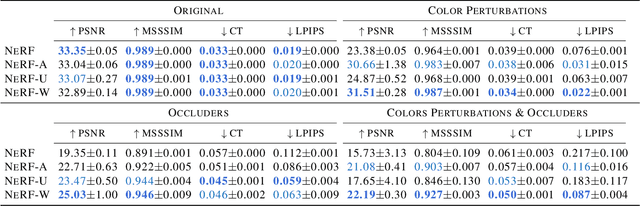
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.
Gesture Recognition for Initiating Human-to-Robot Handovers
Jul 20, 2020
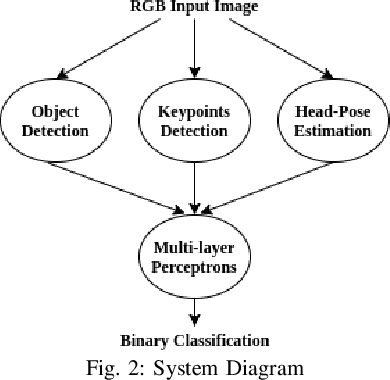
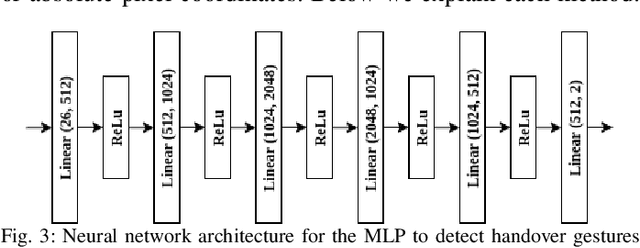

Human-to-Robot handovers are useful for many Human-Robot Interaction scenarios. It is important to recognize when a human intends to initiate handovers, so that the robot does not try to take objects from humans when a handover is not intended. We pose the handover gesture recognition as a binary classification problem in a single RGB image. Three separate neural network modules for detecting the object, human body key points and head orientation, are implemented to extract relevant features from the RGB images, and then the feature vectors are passed into a deep neural net to perform binary classification. Our results show that the handover gestures are correctly identified with an accuracy of over 90%. The abstraction of the features makes our approach modular and generalizable to different objects and human body types.
Sparse Image Representation with Epitomes
Oct 13, 2011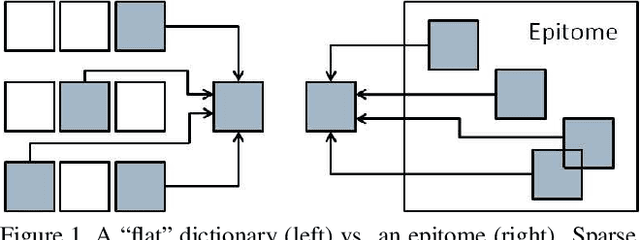
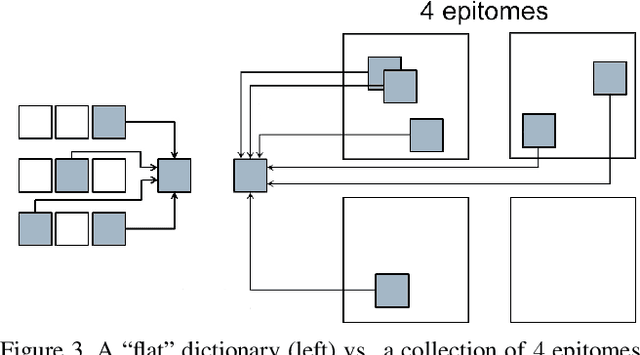
Sparse coding, which is the decomposition of a vector using only a few basis elements, is widely used in machine learning and image processing. The basis set, also called dictionary, is learned to adapt to specific data. This approach has proven to be very effective in many image processing tasks. Traditionally, the dictionary is an unstructured "flat" set of atoms. In this paper, we study structured dictionaries which are obtained from an epitome, or a set of epitomes. The epitome is itself a small image, and the atoms are all the patches of a chosen size inside this image. This considerably reduces the number of parameters to learn and provides sparse image decompositions with shiftinvariance properties. We propose a new formulation and an algorithm for learning the structured dictionaries associated with epitomes, and illustrate their use in image denoising tasks.
* Computer Vision and Pattern Recognition, Colorado Springs : United States (2011)
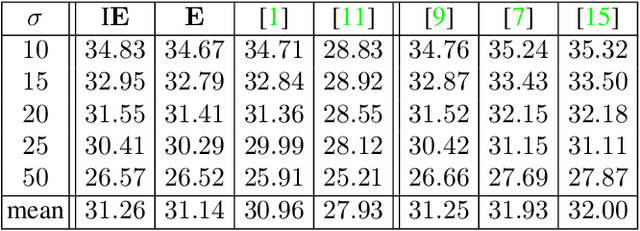
Total Deep Variation for Linear Inverse Problems
Feb 17, 2020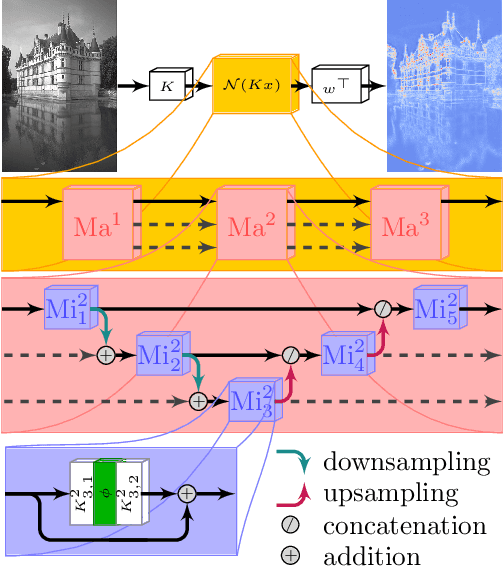
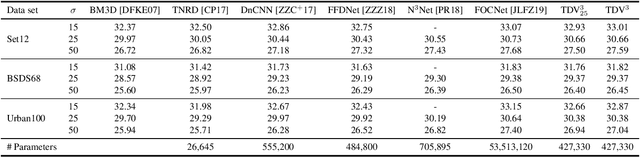
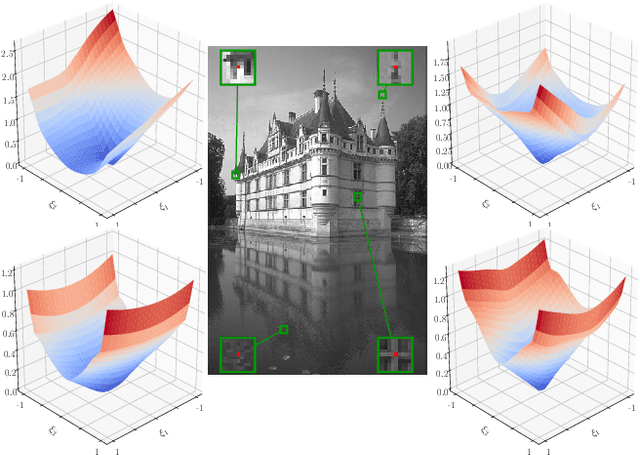
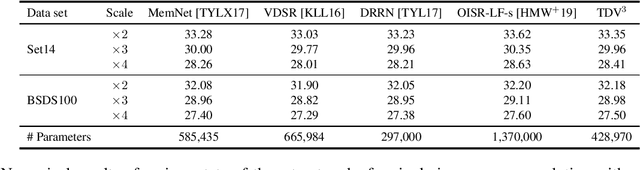
Diverse inverse problems in imaging can be cast as variational problems composed of a task-specific data fidelity term and a regularization term. In this paper, we propose a novel learnable general-purpose regularizer exploiting recent architectural design patterns from deep learning. We cast the learning problem as a discrete sampled optimal control problem, for which we derive the adjoint state equations and an optimality condition. By exploiting the variational structure of our approach, we perform a sensitivity analysis with respect to the learned parameters obtained from different training datasets. Moreover, we carry out a nonlinear eigenfunction analysis, which reveals interesting properties of the learned regularizer. We show state-of-the-art performance for classical image restoration and medical image reconstruction problems.
Project to Adapt: Domain Adaptation for Depth Completion from Noisy and Sparse Sensor Data
Aug 05, 2020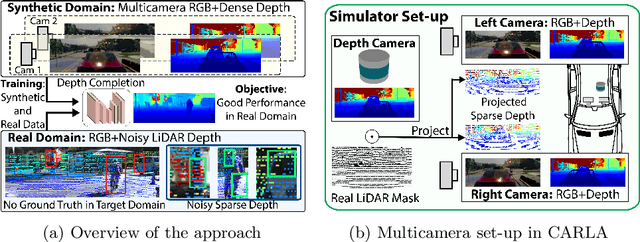
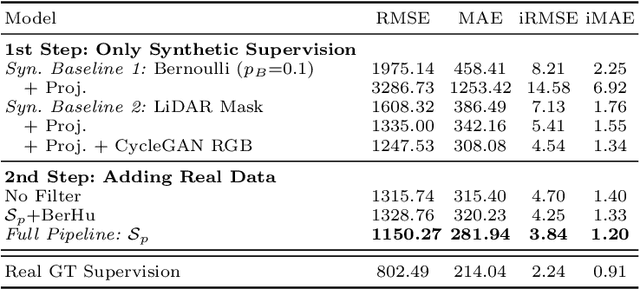
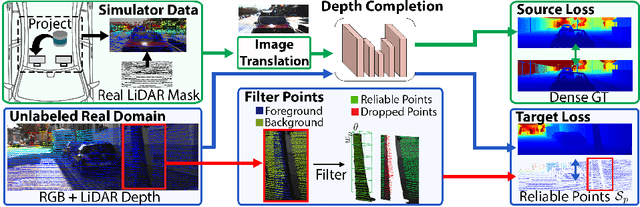
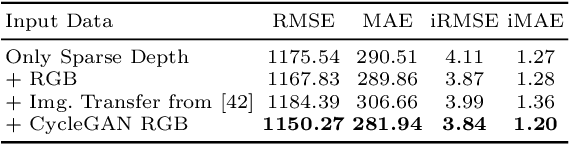
Depth completion aims to predict a dense depth map from a sparse depth input. The acquisition of dense ground truth annotations for depth completion settings can be difficult and, at the same time, a significant domain gap between real LiDAR measurements and synthetic data has prevented from successful training of models in virtual settings. We propose a domain adaptation approach for sparse-to-dense depth completion that is trained from synthetic data, without annotations in the real domain or additional sensors. Our approach simulates the real sensor noise in an RGB+LiDAR set-up, and consists of three modules: simulating the real LiDAR input in the synthetic domain via projections, filtering the real noisy LiDAR for supervision and adapting the synthetic RGB image using a CycleGAN approach. We extensively evaluate these modules against the state-of-the-art in the KITTI depth completion benchmark, showing significant improvements.
Controlling generative models with continuous factors of variations
Jan 28, 2020

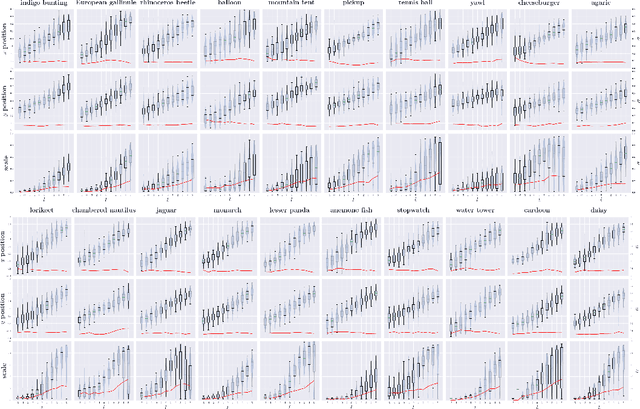
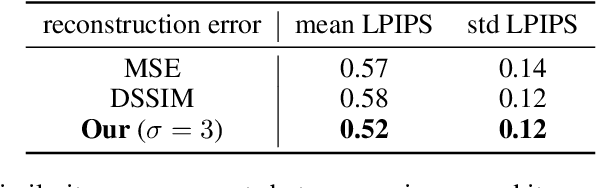
Recent deep generative models are able to provide photo-realistic images as well as visual or textual content embeddings useful to address various tasks of computer vision and natural language processing. Their usefulness is nevertheless often limited by the lack of control over the generative process or the poor understanding of the learned representation. To overcome these major issues, very recent work has shown the interest of studying the semantics of the latent space of generative models. In this paper, we propose to advance on the interpretability of the latent space of generative models by introducing a new method to find meaningful directions in the latent space of any generative model along which we can move to control precisely specific properties of the generated image like the position or scale of the object in the image. Our method does not require human annotations and is particularly well suited for the search of directions encoding simple transformations of the generated image, such as translation, zoom or color variations. We demonstrate the effectiveness of our method qualitatively and quantitatively, both for GANs and variational auto-encoders.
Adaptive and Azimuth-Aware Fusion Network of Multimodal Local Features for 3D Object Detection
Oct 10, 2019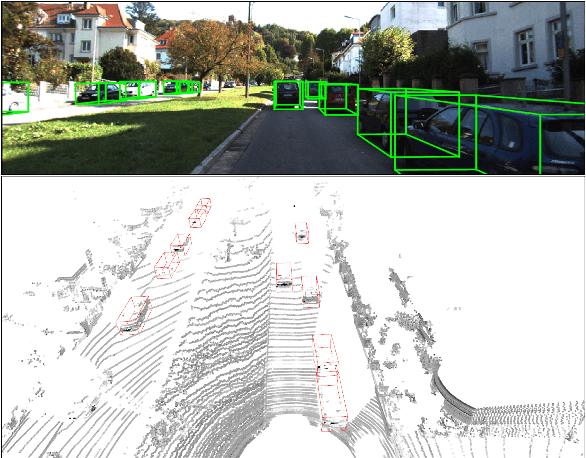
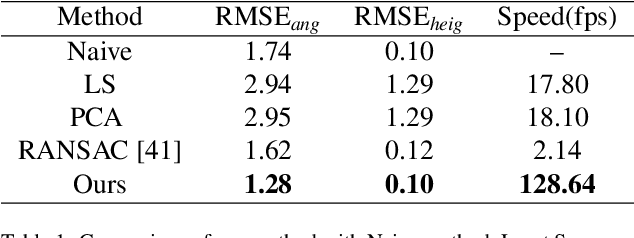
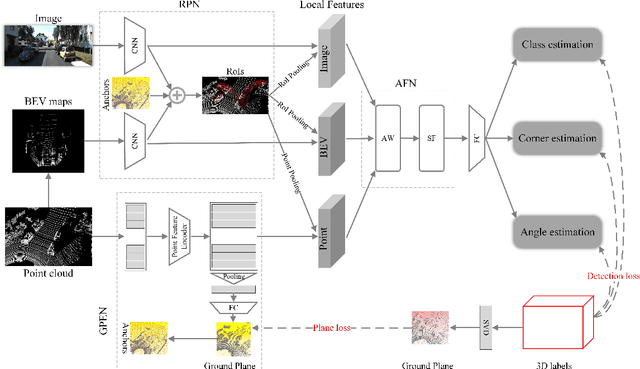
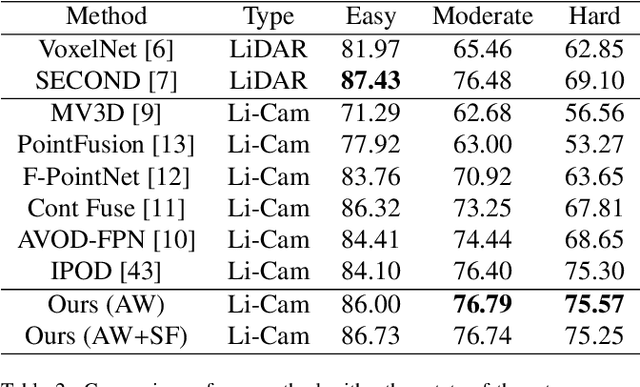
This paper focuses on the construction of stronger local features and the effective fusion of image and LiDAR data. We adopt different modalities of LiDAR data to generate richer features and present an adaptive and azimuth-aware network to aggregate local features from image, bird's eye view maps and point cloud. Our network mainly consists of three subnetworks: ground plane estimation network, region proposal network and adaptive fusion network. The ground plane estimation network extracts features of point cloud and predicts the parameters of a plane which are used for generating abundant 3D anchors. The region proposal network generates features of image and bird's eye view maps to output region proposals. To integrate heterogeneous image and point cloud features, the adaptive fusion network explicitly adjusts the intensity of multiple local features and achieves the orientation consistency between image and LiDAR data by introduce an azimuth-aware fusion module. Experiments are conducted on KITTI dataset and the results validate the advantages of our aggregation of multimodal local features and the adaptive fusion network.