 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Ground Truth Explainability on Tabular Data
Jul 20, 2020
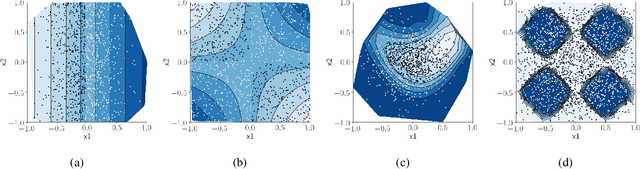
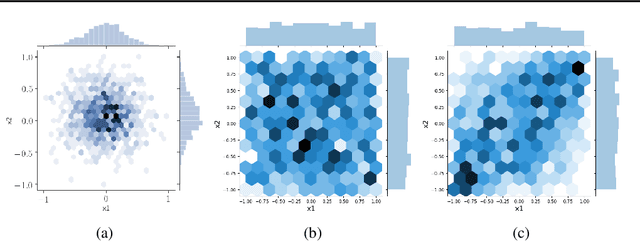
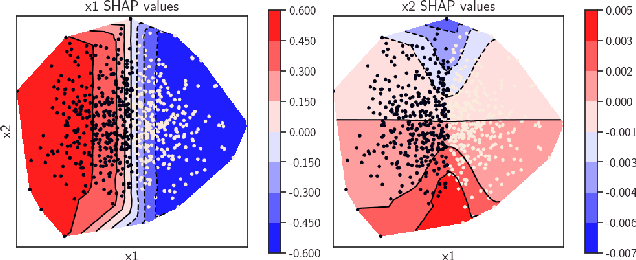
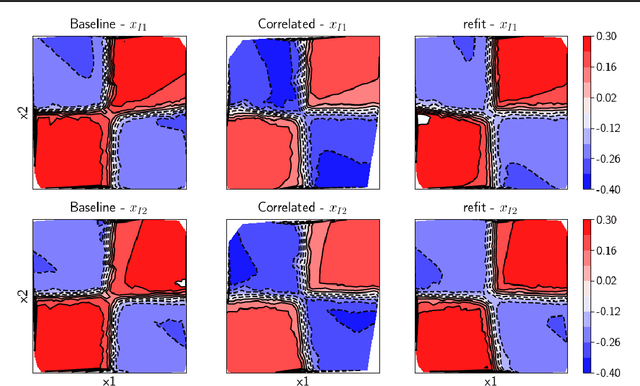
In data science, there is a long history of using synthetic data for method development, feature selection and feature engineering. Our current interest in synthetic data comes from recent work in explainability. Today's datasets are typically larger and more complex - requiring less interpretable models. In the setting of \textit{post hoc} explainability, there is no ground truth for explanations. Inspired by recent work in explaining image classifiers that does provide ground truth, we propose a similar solution for tabular data. Using copulas, a concise specification of the desired statistical properties of a dataset, users can build intuition around explainability using controlled data sets and experimentation. The current capabilities are demonstrated on three use cases: one dimensional logistic regression, impact of correlation from informative features, impact of correlation from redundant variables.
ArchNet: Data Hiding Model in Distributed Machine Learning System
Apr 23, 2020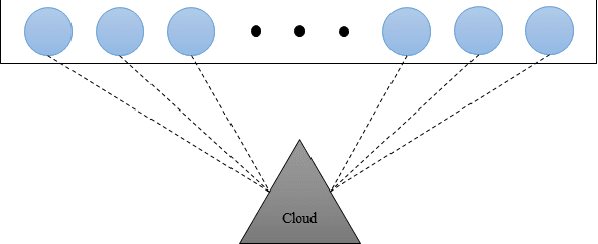
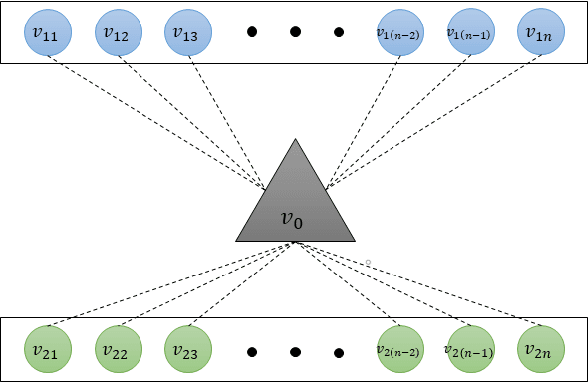
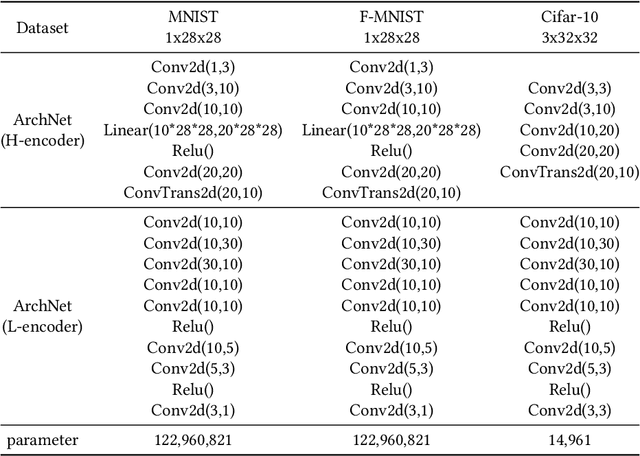
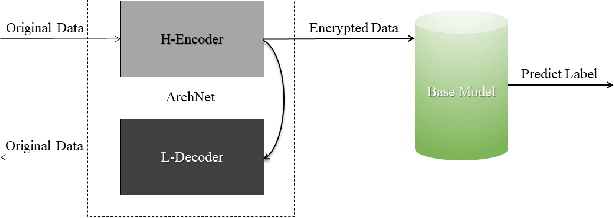
Cloud computing services has become the de facto standard technique for training neural network. However, the computing resources of the cloud servers are limited by hardware and the fixed algorithms of service provider. We observe that this problem can be addressed by a distributed machine learning system, which can utilize the idle devices on the Internet. We further demonstrate that such system can improve the computing flexibility by providing diverse algorithm. For the purpose of the data encryption in the distributed system, we propose Tripartite Asymmetric Encryption theorem and give a mathematical proof. Based on the theorem, we design a universal image encryption model ArchNet. The model has been implemented on MNIST, Fashion-MNIST and Cifar-10 datasets. We use different base models on the encrypted datasets and contrast the results with RC4 algorithm and Difference Privacy policy. The accuracies on the datasets encrypted by ArchNet are 97.26\%, 84.15\% and 79.80\%, and they are 97.31\%, 82.31\% and 80.22\% on the original datasets. Our evaluations show that ArchNet significantly outperforms RC4 on 3 classic image classification datasets at the recognition accuracy and our encrypted dataset sometimes outperforms than the original dataset and the difference privacy policy.
Decomposition of Longitudinal Deformations via Beltrami Descriptors
Aug 06, 2020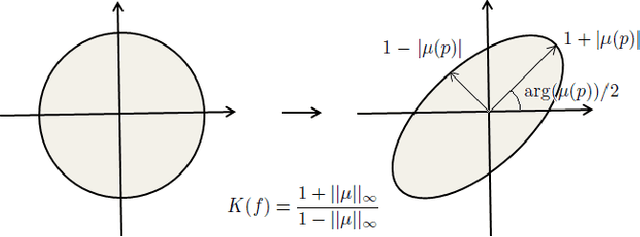


We present a mathematical model to decompose a longitudinal deformation into normal and abnormal components. The goal is to detect and extract subtle quivers from periodic motions in a video sequence. It has important applications in medical image analysis. To achieve this goal, we consider a representation of the longitudinal deformation, called the Beltrami descriptor, based on quasiconformal theories. The Beltrami descriptor is a complex-valued matrix. Each longitudinal deformation is associated to a Beltrami descriptor and vice versa. To decompose the longitudinal deformation, we propose to carry out the low rank and sparse decomposition of the Beltrami descriptor. The low rank component corresponds to the periodic motions, whereas the sparse part corresponds to the abnormal motions of a longitudinal deformation. Experiments have been carried out on both synthetic and real video sequences. Results demonstrate the efficacy of our proposed model to decompose a longitudinal deformation into regular and irregular components.
Full-Body Awareness from Partial Observations
Aug 13, 2020
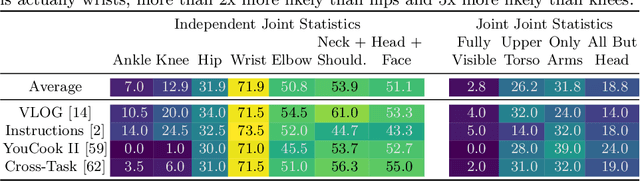
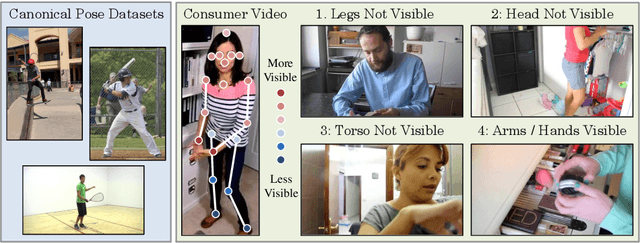
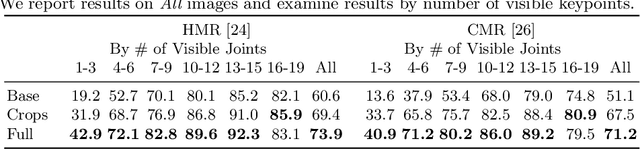
There has been great progress in human 3D mesh recovery and great interest in learning about the world from consumer video data. Unfortunately current methods for 3D human mesh recovery work rather poorly on consumer video data, since on the Internet, unusual camera viewpoints and aggressive truncations are the norm rather than a rarity. We study this problem and make a number of contributions to address it: (i) we propose a simple but highly effective self-training framework that adapts human 3D mesh recovery systems to consumer videos and demonstrate its application to two recent systems; (ii) we introduce evaluation protocols and keypoint annotations for 13K frames across four consumer video datasets for studying this task, including evaluations on out-of-image keypoints; and (iii) we show that our method substantially improves PCK and human-subject judgments compared to baselines, both on test videos from the dataset it was trained on, as well as on three other datasets without further adaptation. Project website: https://crockwell.github.io/partial_humans
Discovering beautiful attributes for aesthetic image analysis
Dec 16, 2014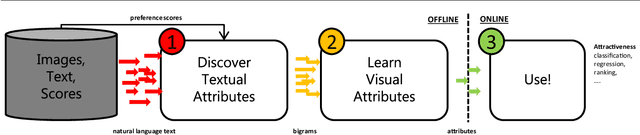
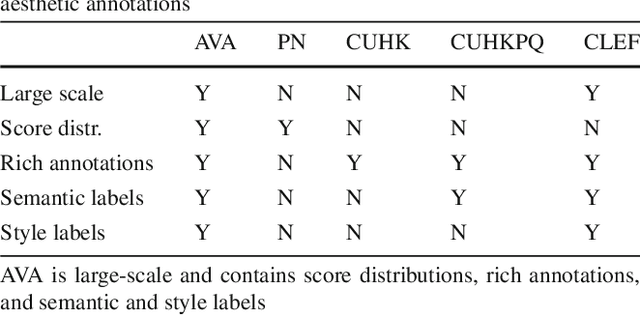

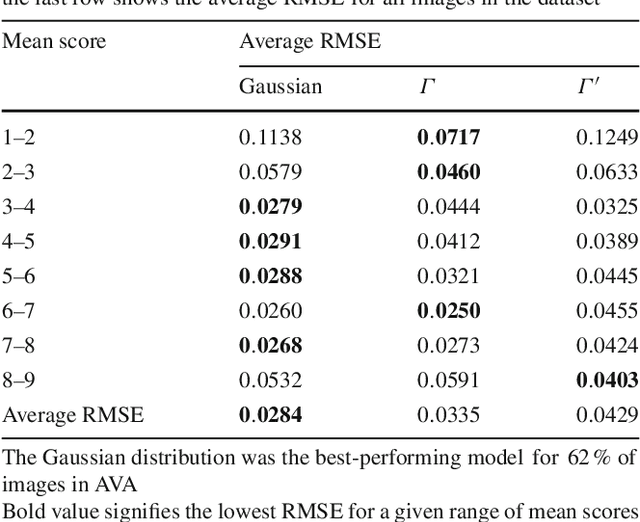
Aesthetic image analysis is the study and assessment of the aesthetic properties of images. Current computational approaches to aesthetic image analysis either provide accurate or interpretable results. To obtain both accuracy and interpretability by humans, we advocate the use of learned and nameable visual attributes as mid-level features. For this purpose, we propose to discover and learn the visual appearance of attributes automatically, using a recently introduced database, called AVA, which contains more than 250,000 images together with their aesthetic scores and textual comments given by photography enthusiasts. We provide a detailed analysis of these annotations as well as the context in which they were given. We then describe how these three key components of AVA - images, scores, and comments - can be effectively leveraged to learn visual attributes. Lastly, we show that these learned attributes can be successfully used in three applications: aesthetic quality prediction, image tagging and retrieval.
PolyLaneNet: Lane Estimation via Deep Polynomial Regression
Apr 23, 2020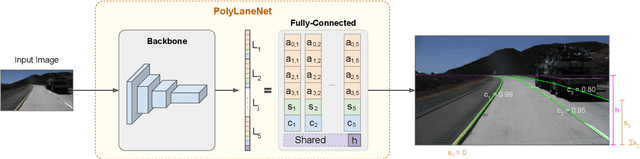


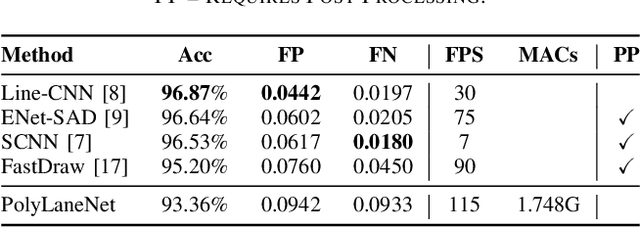
One of the main factors that contributed to the large advances in autonomous driving is the advent of deep learning. For safer self-driving vehicles, one of the problems that has yet to be solved completely is lane detection. Since methods for this task have to work in real time (+30 FPS), they not only have to be effective (i.e., have high accuracy) but they also have to be efficient (i.e., fast). In this work, we present a novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression. The proposed method is shown to be competitive with existing state-of-the-art methods in the TuSimple dataset, while maintaining its efficiency (115 FPS). Additionally, extensive qualitative results on two additional public datasets are presented, alongside with limitations in the evaluation metrics used by recent works for lane detection. Finally, we provide source code and trained models that allow others to replicate all the results shown in this paper, which is surprisingly rare in state-of-the-art lane detection methods.
Adaptive Visual Tracking for Robotic Systems Without Image-Space Velocity Measurement
Apr 27, 2015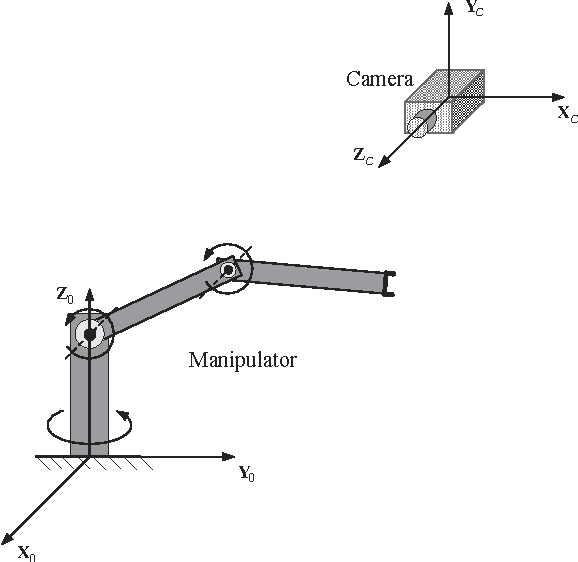
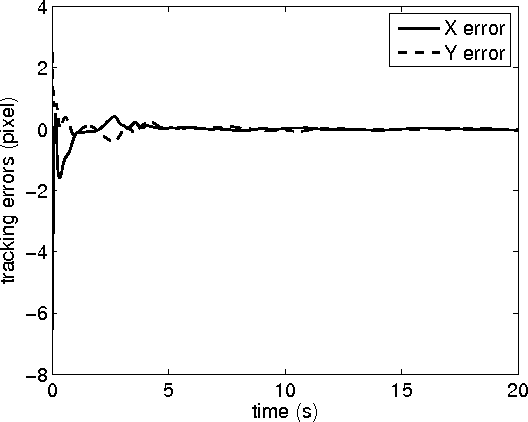
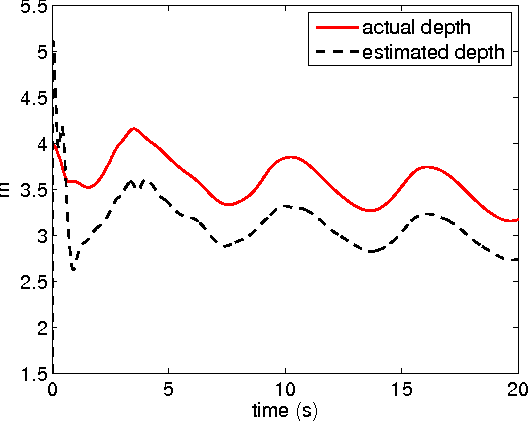
In this paper, we investigate the visual tracking problem for robotic systems without image-space velocity measurement, simultaneously taking into account the uncertainties of the camera model and the manipulator kinematics and dynamics. We propose a new image-space observer that exploits the image-space velocity information contained in the unknown kinematics, upon which, we design an adaptive controller without using the image-space velocity signal where the adaptations of the depth-rate-independent kinematic parameter and depth parameter are driven by both the image-space tracking errors and observation errors. The major superiority of the proposed observer-based adaptive controller lies in its simplicity and the separation of the handling of multiple uncertainties in visually servoed robotic systems, thus avoiding the overparametrization problem of the existing work. Using Lyapunov analysis, we demonstrate that the image-space tracking errors converge to zero asymptotically. The performance of the proposed adaptive control scheme is illustrated by a numerical simulation.
* 21 pages, 3 figures, revised for making improvements based on the reviewers' and AE's comments from Automatica and for adding the journal reference
CNN-generated images are surprisingly easy to spot... for now
Dec 23, 2019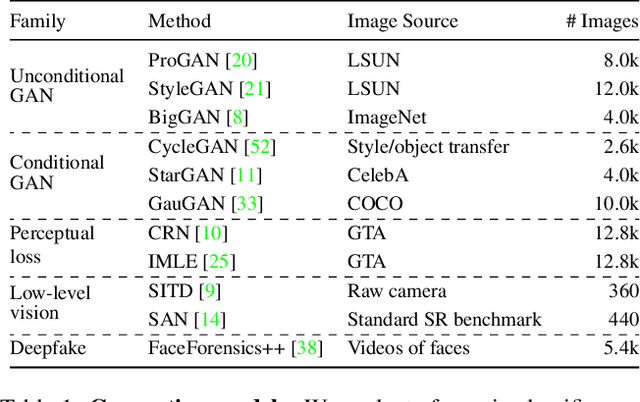
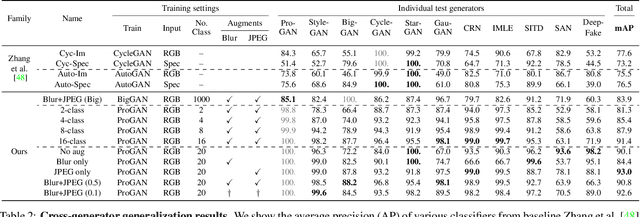
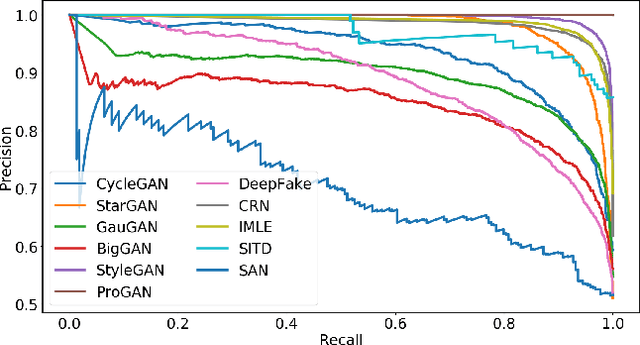

In this work we ask whether it is possible to create a "universal" detector for telling apart real images from these generated by a CNN, regardless of architecture or dataset used. To test this, we collect a dataset consisting of fake images generated by 11 different CNN-based image generator models, chosen to span the space of commonly used architectures today (ProGAN, StyleGAN, BigGAN, CycleGAN, StarGAN, GauGAN, DeepFakes, cascaded refinement networks, implicit maximum likelihood estimation, second-order attention super-resolution, seeing-in-the-dark). We demonstrate that, with careful pre- and post-processing and data augmentation, a standard image classifier trained on only one specific CNN generator (ProGAN) is able to generalize surprisingly well to unseen architectures, datasets, and training methods (including the just released StyleGAN2). Our findings suggest the intriguing possibility that today's CNN-generated images share some common systematic flaws, preventing them from achieving realistic image synthesis.
Relatable Clothing: Detecting Visual Relationships between People and Clothing
Jul 20, 2020
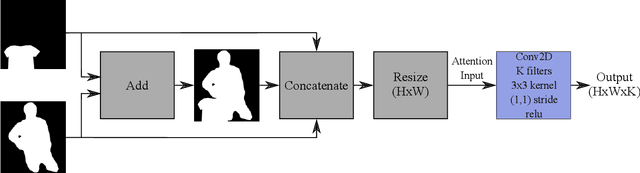
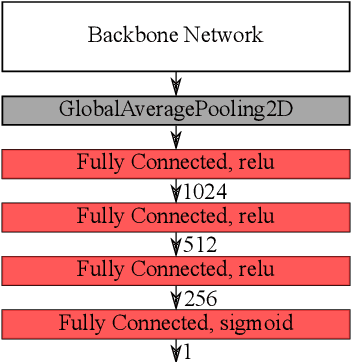
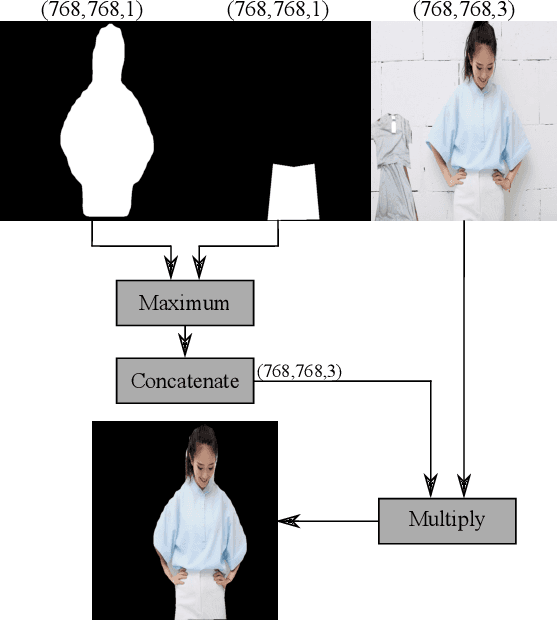
Detecting visual relationships between people and clothing in an image has been a relatively unexplored problem in the field of computer vision and biometrics. The lack readily available public dataset for ``worn'' and ``unworn'' classification has slowed the development of solutions for this problem. We present the release of the Relatable Clothing Dataset which contains 35287 person-clothing pairs and segmentation masks for the development of ``worn'' and ``unworn'' classification models. Additionally, we propose a novel soft attention unit for performing ``worn'' and ``unworn'' classification using deep neural networks. The proposed soft attention models have an accuracy of upward $98.55\% \pm 0.35\%$ on the Relatable Clothing Dataset and demonstrate high generalizable, allowing us to classify unseen articles of clothing such as high visibility vests as ``worn'' or ``unworn''.
Identifying and Tracking Solar Magnetic Flux Elements with Deep Learning
Aug 27, 2020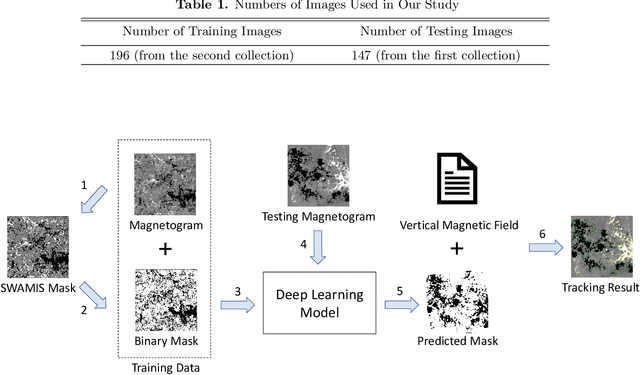
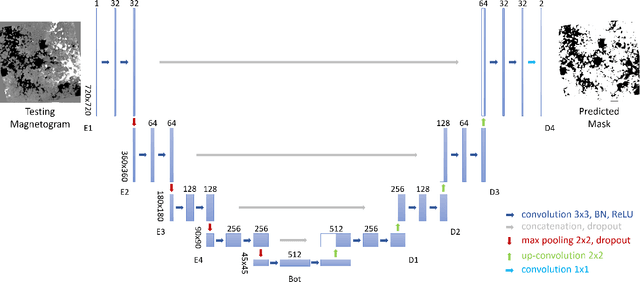

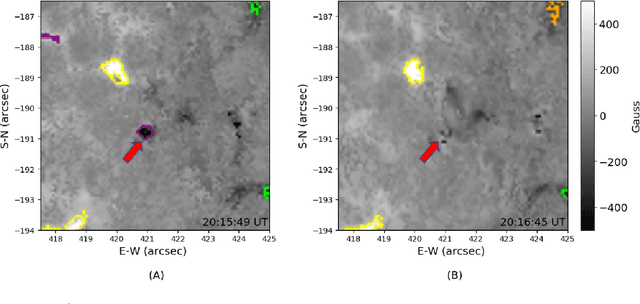
Deep learning has drawn a lot of interest in recent years due to its effectiveness in processing big and complex observational data gathered from diverse instruments. Here we propose a new deep learning method, called SolarUnet, to identify and track solar magnetic flux elements or features in observed vector magnetograms based on the Southwest Automatic Magnetic Identification Suite (SWAMIS). Our method consists of a data pre-processing component that prepares training data from the SWAMIS tool, a deep learning model implemented as a U-shaped convolutional neural network for fast and accurate image segmentation, and a post-processing component that prepares tracking results. SolarUnet is applied to data from the 1.6 meter Goode Solar Telescope at the Big Bear Solar Observatory. When compared to the widely used SWAMIS tool, SolarUnet is faster while agreeing mostly with SWAMIS on feature size and flux distributions, and complementing SWAMIS in tracking long-lifetime features. Thus, the proposed physics-guided deep learning-based tool can be considered as an alternative method for solar magnetic tracking.
* 17 pages, 12 figures