 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EAT: Self-Supervised Pre-Training with Efficient Audio Transformer
Jan 07, 2024
Audio self-supervised learning (SSL) pre-training, which aims to learn good representations from unlabeled audio, has made remarkable progress. However, the extensive computational demands during pre-training pose a significant barrier to the potential application and optimization of audio SSL models. In this paper, inspired by the success of data2vec 2.0 in image modality and Audio-MAE in audio modality, we introduce Efficient Audio Transformer (EAT) to further improve the effectiveness and efficiency in audio SSL. The proposed EAT adopts the bootstrap self-supervised training paradigm to the audio domain. A novel Utterance-Frame Objective (UFO) is designed to enhance the modeling capability of acoustic events. Furthermore, we reveal that the masking strategy is critical in audio SSL pre-training, and superior audio representations can be obtained with large inverse block masks. Experiment results demonstrate that EAT achieves state-of-the-art (SOTA) performance on a range of audio-related tasks, including AudioSet (AS-2M, AS-20K), ESC-50, and SPC-2, along with a significant pre-training speedup up to ~15x compared to existing audio SSL models.
Describing Differences in Image Sets with Natural Language
Dec 05, 2023How do two sets of images differ? Discerning set-level differences is crucial for understanding model behaviors and analyzing datasets, yet manually sifting through thousands of images is impractical. To aid in this discovery process, we explore the task of automatically describing the differences between two $\textbf{sets}$ of images, which we term Set Difference Captioning. This task takes in image sets $D_A$ and $D_B$, and outputs a description that is more often true on $D_A$ than $D_B$. We outline a two-stage approach that first proposes candidate difference descriptions from image sets and then re-ranks the candidates by checking how well they can differentiate the two sets. We introduce VisDiff, which first captions the images and prompts a language model to propose candidate descriptions, then re-ranks these descriptions using CLIP. To evaluate VisDiff, we collect VisDiffBench, a dataset with 187 paired image sets with ground truth difference descriptions. We apply VisDiff to various domains, such as comparing datasets (e.g., ImageNet vs. ImageNetV2), comparing classification models (e.g., zero-shot CLIP vs. supervised ResNet), summarizing model failure modes (supervised ResNet), characterizing differences between generative models (e.g., StableDiffusionV1 and V2), and discovering what makes images memorable. Using VisDiff, we are able to find interesting and previously unknown differences in datasets and models, demonstrating its utility in revealing nuanced insights.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
Prototype-Based Approach for One-Shot Segmentation of Brain Tumors using Few-Shot Learning
Jan 09, 2024The potential for augmenting the segmentation of brain tumors through the use of few-shot learning is vast. Although several deep learning networks (DNNs) demonstrate promising results in terms of segmentation, they require a substantial quantity of training data in order to produce suitable outcomes. Furthermore, a major issue faced by most of these models is their ability to perform well when faced with unseen classes. To address these challenges, we propose a one-shot learning model for segmenting brain tumors in magnetic resonance images (MRI) of the brain, based on a single prototype similarity score. Leveraging the recently developed techniques of few-shot learning, which involve the utilization of support and query sets of images for training and testing purposes, we strive to obtain a definitive tumor region by focusing on slices that contain foreground classes. This approach differs from other recent DNNs that utilize the entire set of images. The training process for this model is carried out iteratively, with each iteration involving the selection of random slices that contain foreground classes from randomly sampled data as the query set, along with a different random slice from the same sample as the support set. In order to distinguish the query images from the class prototypes, we employ a metric learning-based approach that relies on non-parametric thresholds. We employ the multimodal Brain Tumor Image Segmentation (BraTS) 2021 dataset, which comprises 60 training images and 350 testing images. The effectiveness of the model is assessed using the mean dice score and mean Intersection over Union (IoU) score.
ESDMR-Net: A Lightweight Network With Expand-Squeeze and Dual Multiscale Residual Connections for Medical Image Segmentation
Dec 17, 2023Segmentation is an important task in a wide range of computer vision applications, including medical image analysis. Recent years have seen an increase in the complexity of medical image segmentation approaches based on sophisticated convolutional neural network architectures. This progress has led to incremental enhancements in performance on widely recognised benchmark datasets. However, most of the existing approaches are computationally demanding, which limits their practical applicability. This paper presents an expand-squeeze dual multiscale residual network (ESDMR-Net), which is a fully convolutional network that is particularly well-suited for resource-constrained computing hardware such as mobile devices. ESDMR-Net focuses on extracting multiscale features, enabling the learning of contextual dependencies among semantically distinct features. The ESDMR-Net architecture allows dual-stream information flow within encoder-decoder pairs. The expansion operation (depthwise separable convolution) makes all of the rich features with multiscale information available to the squeeze operation (bottleneck layer), which then extracts the necessary information for the segmentation task. The Expand-Squeeze (ES) block helps the network pay more attention to under-represented classes, which contributes to improved segmentation accuracy. To enhance the flow of information across multiple resolutions or scales, we integrated dual multiscale residual (DMR) blocks into the skip connection. This integration enables the decoder to access features from various levels of abstraction, ultimately resulting in more comprehensive feature representations. We present experiments on seven datasets from five distinct examples of applications. Our model achieved the best results despite having significantly fewer trainable parameters, with a reduction of two or even three orders of magnitude.
Stable Messenger: Steganography for Message-Concealed Image Generation
Dec 03, 2023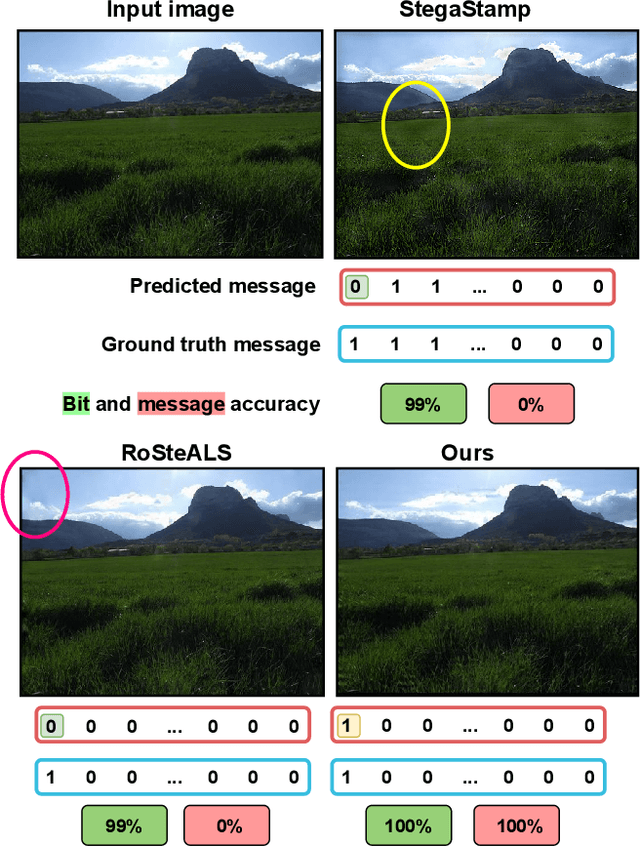
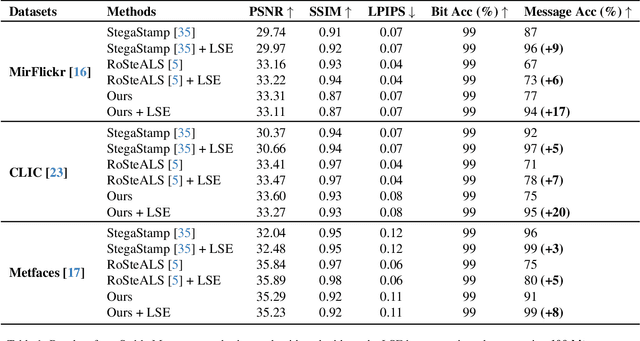
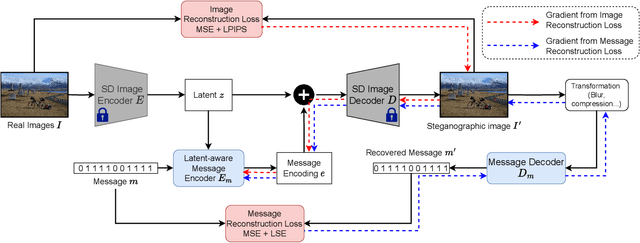

In the ever-expanding digital landscape, safeguarding sensitive information remains paramount. This paper delves deep into digital protection, specifically focusing on steganography. While prior research predominantly fixated on individual bit decoding, we address this limitation by introducing ``message accuracy'', a novel metric evaluating the entirety of decoded messages for a more holistic evaluation. In addition, we propose an adaptive universal loss tailored to enhance message accuracy, named Log-Sum-Exponential (LSE) loss, thereby significantly improving the message accuracy of recent approaches. Furthermore, we also introduce a new latent-aware encoding technique in our framework named \Approach, harnessing pretrained Stable Diffusion for advanced steganographic image generation, giving rise to a better trade-off between image quality and message recovery. Throughout experimental results, we have demonstrated the superior performance of the new LSE loss and latent-aware encoding technique. This comprehensive approach marks a significant step in evolving evaluation metrics, refining loss functions, and innovating image concealment techniques, aiming for more robust and dependable information protection.
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Jan 02, 2024In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
Fair Text-to-Image Diffusion via Fair Mapping
Nov 29, 2023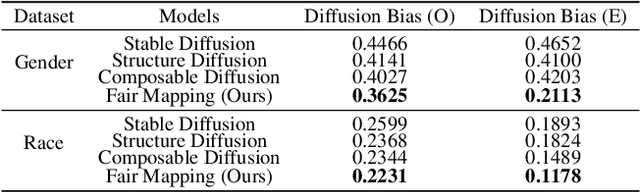

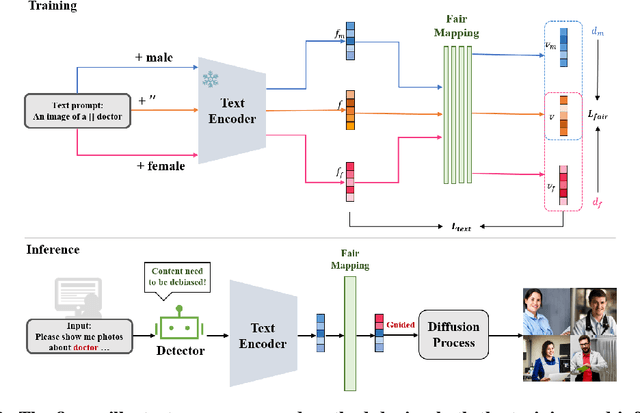
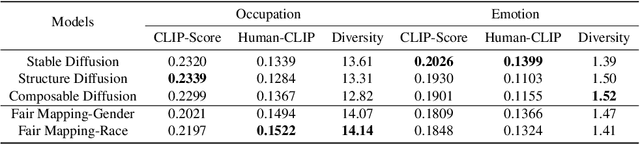
In this paper, we address the limitations of existing text-to-image diffusion models in generating demographically fair results when given human-related descriptions. These models often struggle to disentangle the target language context from sociocultural biases, resulting in biased image generation. To overcome this challenge, we propose Fair Mapping, a general, model-agnostic, and lightweight approach that modifies a pre-trained text-to-image model by controlling the prompt to achieve fair image generation. One key advantage of our approach is its high efficiency. The training process only requires updating a small number of parameters in an additional linear mapping network. This not only reduces the computational cost but also accelerates the optimization process. We first demonstrate the issue of bias in generated results caused by language biases in text-guided diffusion models. By developing a mapping network that projects language embeddings into an unbiased space, we enable the generation of relatively balanced demographic results based on a keyword specified in the prompt. With comprehensive experiments on face image generation, we show that our method significantly improves image generation performance when prompted with descriptions related to human faces. By effectively addressing the issue of bias, we produce more fair and diverse image outputs. This work contributes to the field of text-to-image generation by enhancing the ability to generate images that accurately reflect the intended demographic characteristics specified in the text.
Large Language Models as Visual Cross-Domain Learners
Jan 06, 2024Recent advances achieved by deep learning models rely on the independent and identically distributed assumption, hindering their applications in real-world scenarios with domain shifts. To address the above issues, cross-domain learning aims at extracting domain-invariant knowledge to reduce the domain shift between training and testing data. However, in visual cross-domain learning, traditional methods concentrate solely on the image modality, neglecting the use of the text modality to alleviate the domain shift. In this work, we propose Large Language models as Visual cross-dOmain learners (LLaVO). LLaVO uses vision-language models to convert images into detailed textual descriptions. A large language model is then finetuned on textual descriptions of the source/target domain generated by a designed instruction template. Extensive experimental results on various cross-domain tasks under the domain generalization and unsupervised domain adaptation settings have demonstrated the effectiveness of the proposed method.
UGGNet: Bridging U-Net and VGG for Advanced Breast Cancer Diagnosis
Jan 06, 2024In the field of medical imaging, breast ultrasound has emerged as a crucial diagnostic tool for early detection of breast cancer. However, the accuracy of diagnosing the location of the affected area and the extent of the disease depends on the experience of the physician. In this paper, we propose a novel model called UGGNet, combining the power of the U-Net and VGG architectures to enhance the performance of breast ultrasound image analysis. The U-Net component of the model helps accurately segment the lesions, while the VGG component utilizes deep convolutional layers to extract features. The fusion of these two architectures in UGGNet aims to optimize both segmentation and feature representation, providing a comprehensive solution for accurate diagnosis in breast ultrasound images. Experimental results have demonstrated that the UGGNet model achieves a notable accuracy of 78.2% on the "Breast Ultrasound Images Dataset."
* Submitted to the journal "EAI Endorsed Transactions on Context-aware Systems and Applications" ,2 images, 5 data tables