 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Poisoned classifiers are not only backdoored, they are fundamentally broken
Oct 18, 2020
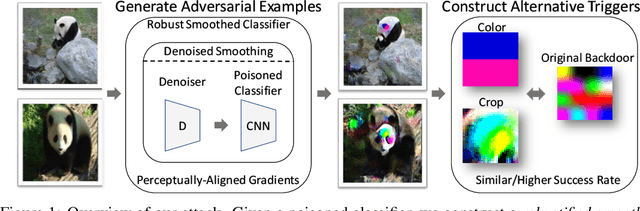
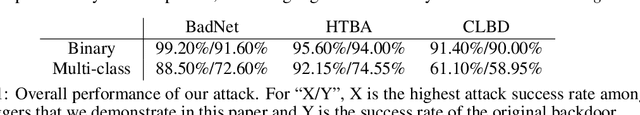
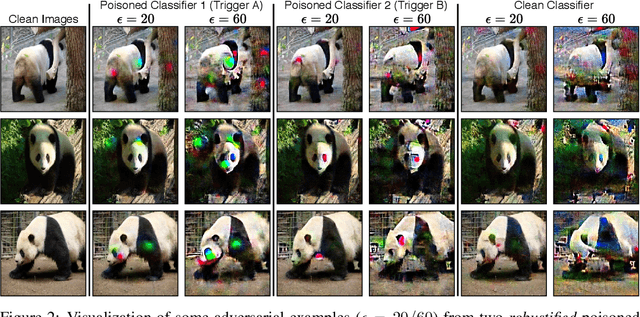

Under a commonly-studied "backdoor" poisoning attack against classification models, an attacker adds a small "trigger" to a subset of the training data, such that the presence of this trigger at test time causes the classifier to always predict some target class. It is often implicitly assumed that the poisoned classifier is vulnerable exclusively to the adversary who possesses the trigger. In this paper, we show empirically that this view of backdoored classifiers is fundamentally incorrect. We demonstrate that anyone with access to the classifier, even without access to any original training data or trigger, can construct several alternative triggers that are as effective or more so at eliciting the target class at test time. We construct these alternative triggers by first generating adversarial examples for a smoothed version of the classifier, created with a recent process called Denoised Smoothing, and then extracting colors or cropped portions of adversarial images. We demonstrate the effectiveness of our attack through extensive experiments on ImageNet and TrojAI datasets, including a user study which demonstrates that our method allows users to easily determine the existence of such backdoors in existing poisoned classifiers. Furthermore, we demonstrate that our alternative triggers can in fact look entirely different from the original trigger, highlighting that the backdoor actually learned by the classifier differs substantially from the trigger image itself. Thus, we argue that there is no such thing as a "secret" backdoor in poisoned classifiers: poisoning a classifier invites attacks not just by the party that possesses the trigger, but from anyone with access to the classifier. Code is available at https://github.com/locuslab/breaking-poisoned-classifier.
Fashion Landmark Detection and Category Classification for Robotics
Mar 26, 2020

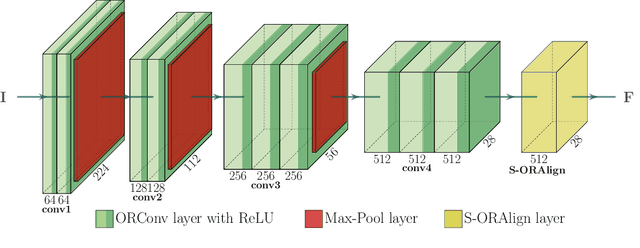
Research on automated, image based identification of clothing categories and fashion landmarks has recently gained significant interest due to its potential impact on areas such as robotic clothing manipulation, automated clothes sorting and recycling, and online shopping. Several public and annotated fashion datasets have been created to facilitate research advances in this direction. In this work, we make the first step towards leveraging the data and techniques developed for fashion image analysis in vision-based robotic clothing manipulation tasks. We focus on techniques that can generalize from large-scale fashion datasets to less structured, small datasets collected in a robotic lab. Specifically, we propose training data augmentation methods such as elastic warping, and model adjustments such as rotation invariant convolutions to make the model generalize better. Our experiments demonstrate that our approach outperforms stateof-the art models with respect to clothing category classification and fashion landmark detection when tested on previously unseen datasets. Furthermore, we present experimental results on a new dataset composed of images where a robot holds different garments, collected in our lab.
DeVLBert: Learning Deconfounded Visio-Linguistic Representations
Aug 16, 2020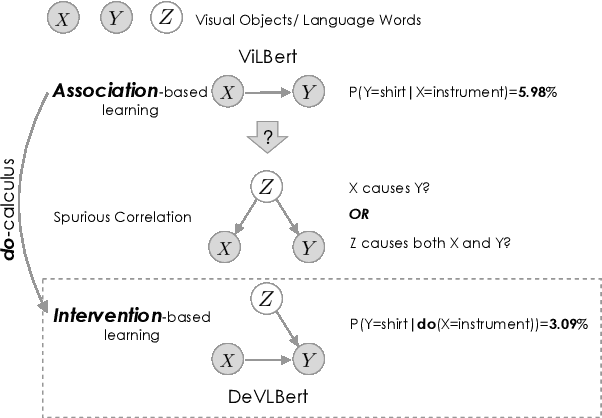
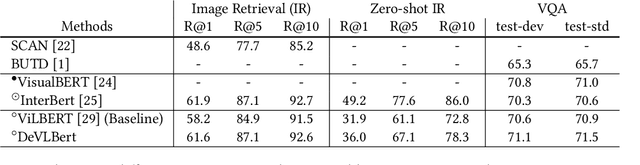
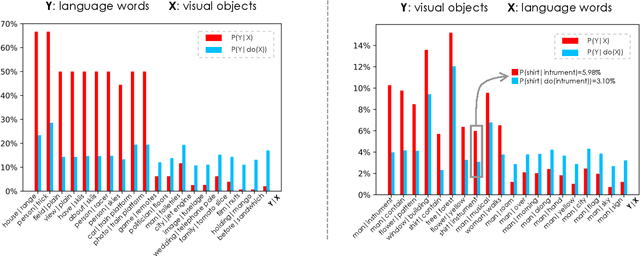
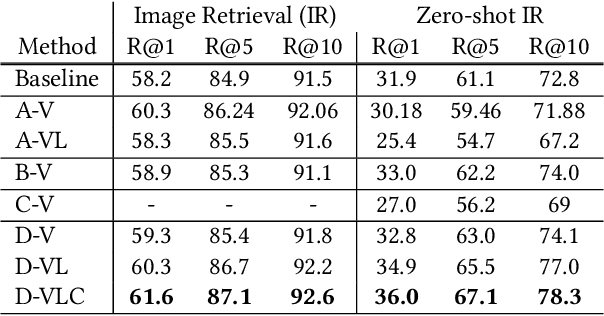
In this paper, we propose to investigate the problem of out-of-domain visio-linguistic pretraining, where the pretraining data distribution differs from that of downstream data on which the pretrained model will be fine-tuned. Existing methods for this problem are purely likelihood-based, leading to the spurious correlations and hurt the generalization ability when transferred to out-of-domain downstream tasks. By spurious correlation, we mean that the conditional probability of one token (object or word) given another one can be high (due to the dataset biases) without robust (causal) relationships between them. To mitigate such dataset biases, we propose a Deconfounded Visio-Linguistic Bert framework, abbreviated as DeVLBert, to perform intervention-based learning. We borrow the idea of the backdoor adjustment from the research field of causality and propose several neural-network based architectures for Bert-style out-of-domain pretraining. The quantitative results on three downstream tasks, Image Retrieval (IR), Zero-shot IR, and Visual Question Answering, show the effectiveness of DeVLBert by boosting generalization ability.
GPU-Accelerated Mobile Multi-view Style Transfer
Mar 02, 2020
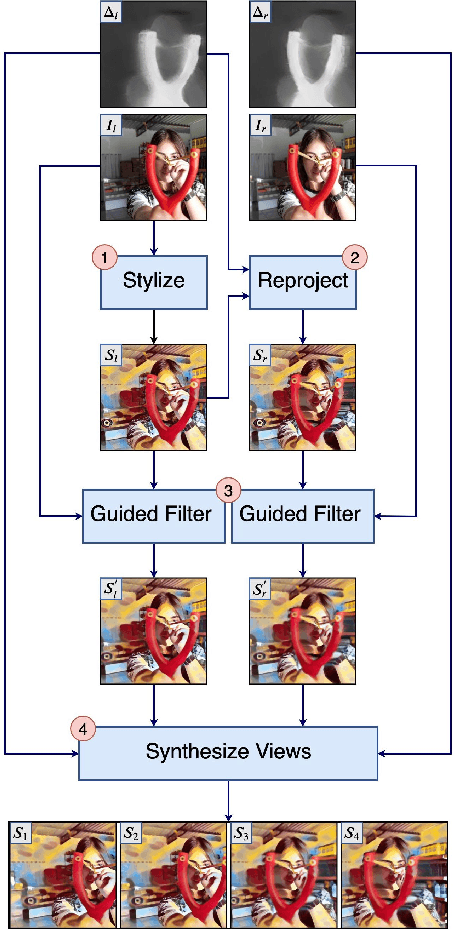
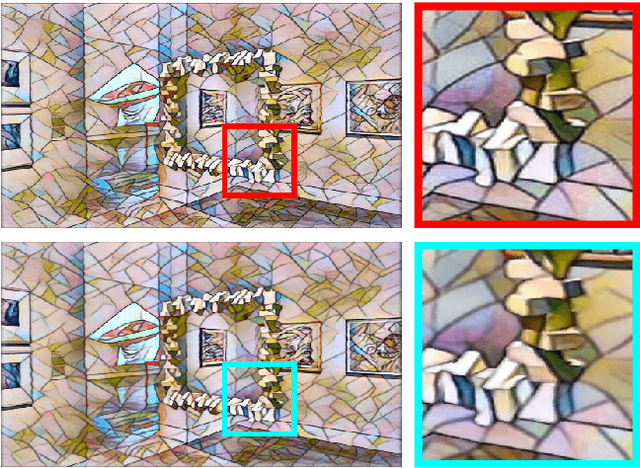

An estimated 60% of smartphones sold in 2018 were equipped with multiple rear cameras, enabling a wide variety of 3D-enabled applications such as 3D Photos. The success of 3D Photo platforms (Facebook 3D Photo, Holopix, etc) depend on a steady influx of user generated content. These platforms must provide simple image manipulation tools to facilitate content creation, akin to traditional photo platforms. Artistic neural style transfer, propelled by recent advancements in GPU technology, is one such tool for enhancing traditional photos. However, naively extrapolating single-view neural style transfer to the multi-view scenario produces visually inconsistent results and is prohibitively slow on mobile devices. We present a GPU-accelerated multi-view style transfer pipeline which enforces style consistency between views with on-demand performance on mobile platforms. Our pipeline is modular and creates high quality depth and parallax effects from a stereoscopic image pair.
Introducing Geometry in Active Learning for Image Segmentation
Aug 20, 2015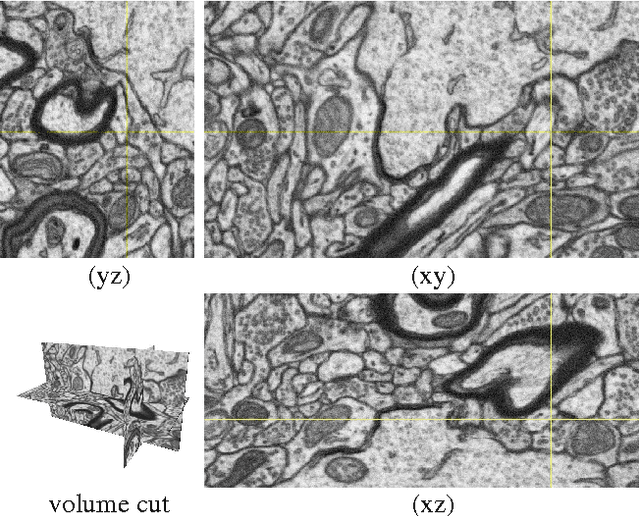
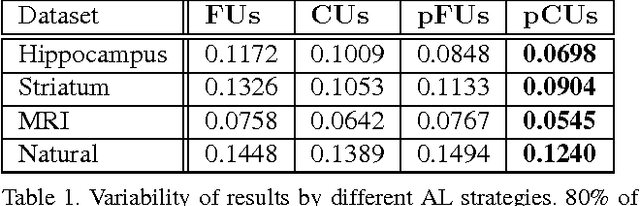
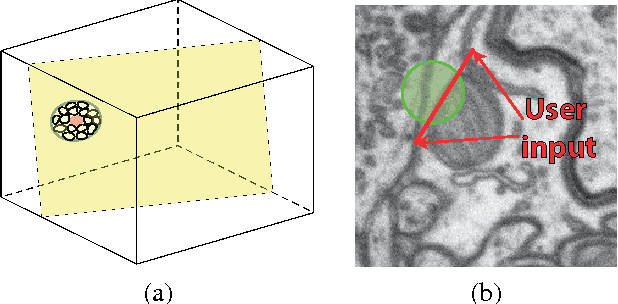
We propose an Active Learning approach to training a segmentation classifier that exploits geometric priors to streamline the annotation process in 3D image volumes. To this end, we use these priors not only to select voxels most in need of annotation but to guarantee that they lie on 2D planar patch, which makes it much easier to annotate than if they were randomly distributed in the volume. A simplified version of this approach is effective in natural 2D images. We evaluated our approach on Electron Microscopy and Magnetic Resonance image volumes, as well as on natural images. Comparing our approach against several accepted baselines demonstrates a marked performance increase.
Enhanced Quadratic Video Interpolation
Sep 10, 2020
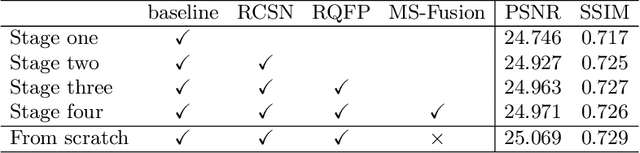
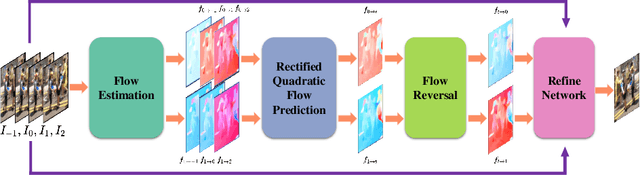
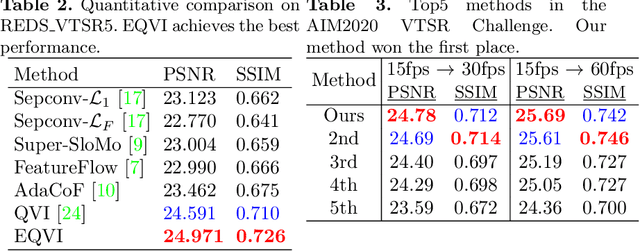
With the prosperity of digital video industry, video frame interpolation has arisen continuous attention in computer vision community and become a new upsurge in industry. Many learning-based methods have been proposed and achieved progressive results. Among them, a recent algorithm named quadratic video interpolation (QVI) achieves appealing performance. It exploits higher-order motion information (e.g. acceleration) and successfully models the estimation of interpolated flow. However, its produced intermediate frames still contain some unsatisfactory ghosting, artifacts and inaccurate motion, especially when large and complex motion occurs. In this work, we further improve the performance of QVI from three facets and propose an enhanced quadratic video interpolation (EQVI) model. In particular, we adopt a rectified quadratic flow prediction (RQFP) formulation with least squares method to estimate the motion more accurately. Complementary with image pixel-level blending, we introduce a residual contextual synthesis network (RCSN) to employ contextual information in high-dimensional feature space, which could help the model handle more complicated scenes and motion patterns. Moreover, to further boost the performance, we devise a novel multi-scale fusion network (MS-Fusion) which can be regarded as a learnable augmentation process. The proposed EQVI model won the first place in the AIM2020 Video Temporal Super-Resolution Challenge.
Learning stochastic object models from medical imaging measurements using Progressively-Growing AmbientGANs
May 29, 2020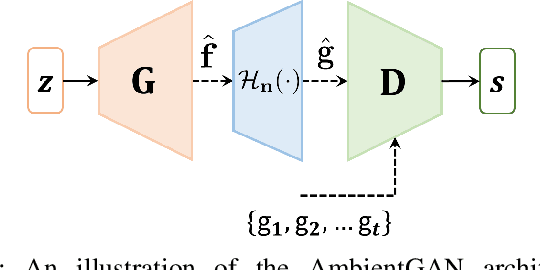
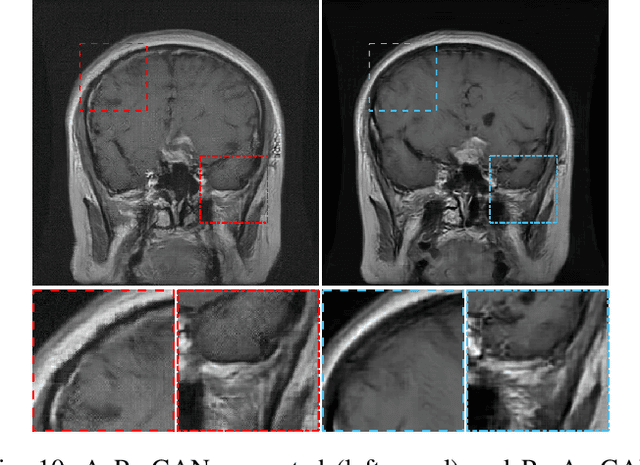
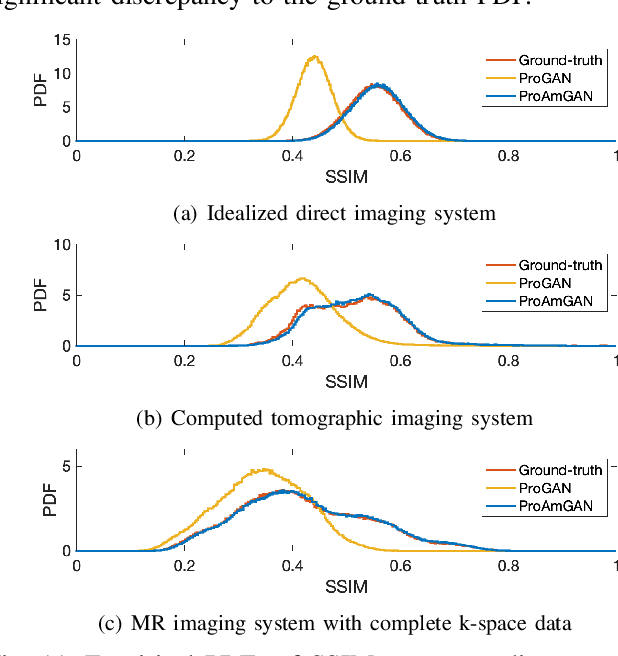
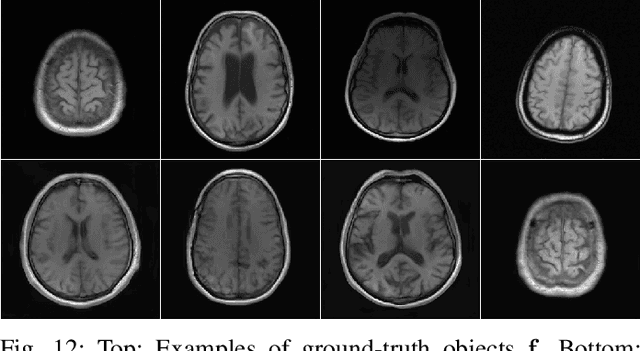
It has been advocated that medical imaging systems and reconstruction algorithms should be assessed and optimized by use of objective measures of image quality that quantify the performance of an observer at specific diagnostic tasks. One important source of variability that can significantly limit observer performance is variation in the objects to-be-imaged. This source of variability can be described by stochastic object models (SOMs). A SOM is a generative model that can be employed to establish an ensemble of to-be-imaged objects with prescribed statistical properties. In order to accurately model variations in anatomical structures and object textures, it is desirable to establish SOMs from experimental imaging measurements acquired by use of a well-characterized imaging system. Deep generative neural networks, such as generative adversarial networks (GANs) hold great potential for this task. However, conventional GANs are typically trained by use of reconstructed images that are influenced by the effects of measurement noise and the reconstruction process. To circumvent this, an AmbientGAN has been proposed that augments a GAN with a measurement operator. However, the original AmbientGAN could not immediately benefit from modern training procedures, such as progressive growing, which limited its ability to be applied to realistically sized medical image data. To circumvent this, in this work, a new Progressive Growing AmbientGAN (ProAmGAN) strategy is developed for establishing SOMs from medical imaging measurements. Stylized numerical studies corresponding to common medical imaging modalities are conducted to demonstrate and validate the proposed method for establishing SOMs.
A combined Approach Based on Fuzzy Classification and Contextual Region Growing to Image Segmentation
Aug 08, 2016
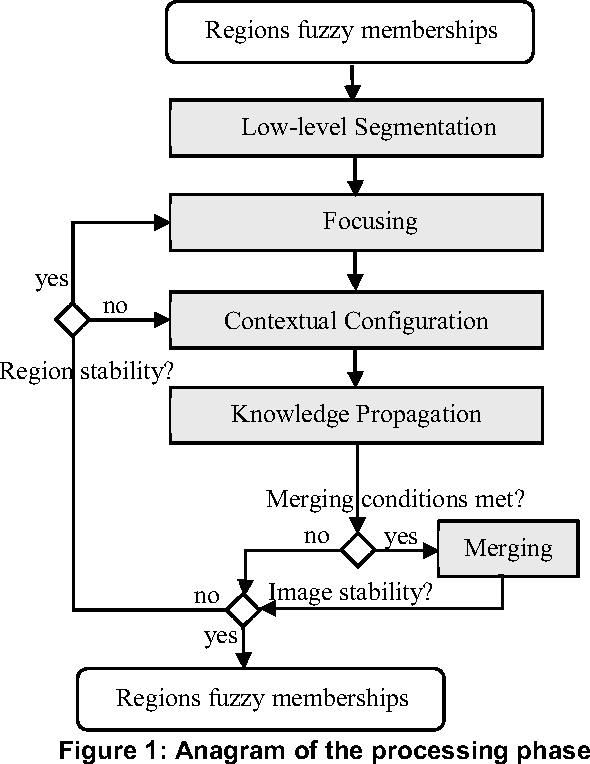
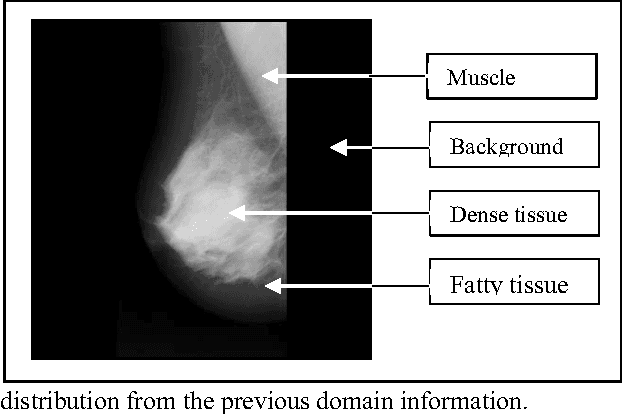
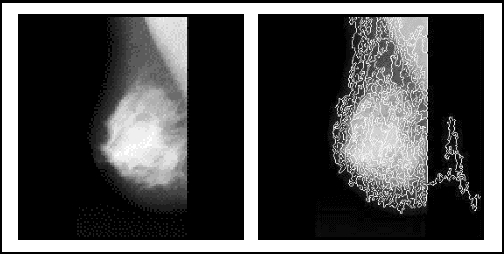
We present in this paper an image segmentation approach that combines a fuzzy semantic region classification and a context based region-growing. Input image is first over-segmented. Then, prior domain knowledge is used to perform a fuzzy classification of these regions to provide a fuzzy semantic labeling. This allows the proposed approach to operate at high level instead of using low-level features and consequently to remedy to the problem of the semantic gap. Each over-segmented region is represented by a vector giving its corresponding membership degrees to the different thematic labels and the whole image is therefore represented by a Regions Partition Matrix. The segmentation is achieved on this matrix instead of the image pixels through two main phases: focusing and propagation. The focusing aims at selecting seeds regions from which information propagation will be performed. Thepropagation phase allows to spread toward others regions and using fuzzy contextual information the needed knowledge ensuring the semantic segmentation. An application of the proposed approach on mammograms shows promising results
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Nov 16, 2017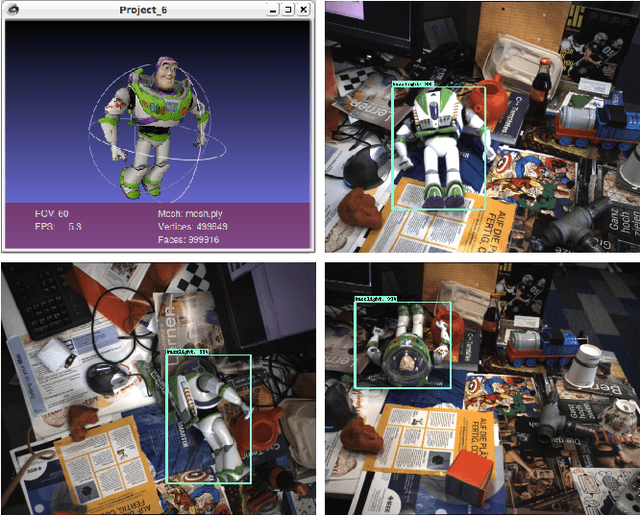
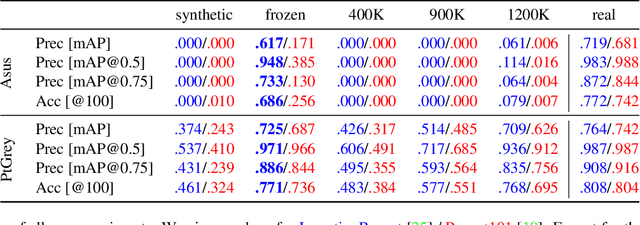
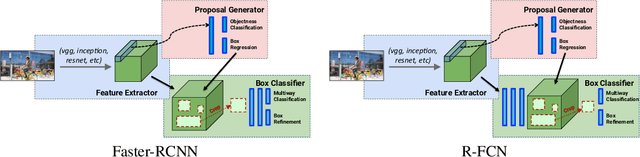
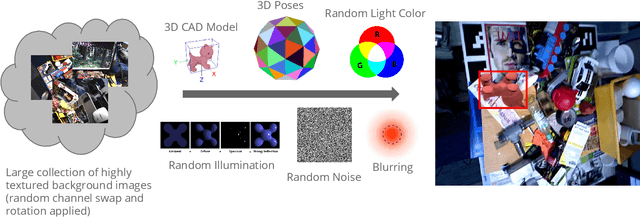
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling. Using synthetic images is therefore very attractive to train object detectors, as the labeling comes for free, and several approaches have been proposed to combine synthetic and real images for training. In this paper, we show that a simple trick is sufficient to train very effectively modern object detectors with synthetic images only: We freeze the layers responsible for feature extraction to generic layers pre-trained on real images, and train only the remaining layers with plain OpenGL rendering. Our experiments with very recent deep architectures for object recognition (Faster-RCNN, R-FCN, Mask-RCNN) and image feature extractors (InceptionResnet and Resnet) show this simple approach performs surprisingly well.
Human eye inspired log-polar pre-processing for neural networks
Nov 04, 2019
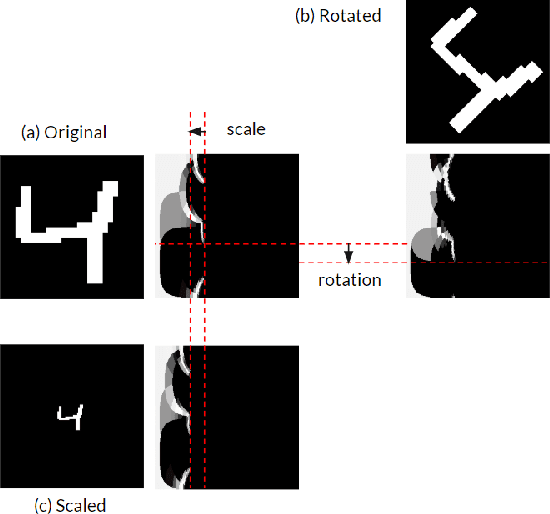

In this paper we draw inspiration from the human visual system, and present a bio-inspired pre-processing stage for neural networks. We implement this by applying a log-polar transformation as a pre-processing step, and to demonstrate, we have used a naive convolutional neural network (CNN). We demonstrate that a bio-inspired pre-processing stage can achieve rotation and scale robustness in CNNs. A key point in this paper is that the CNN does not need to be trained to identify rotation or scaling permutations; rather it is the log-polar pre-processing step that converts the image into a format that allows the CNN to handle rotation and scaling permutations. In addition we demonstrate how adding a log-polar transformation as a pre-processing step can reduce the image size to ~20\% of the Euclidean image size, without significantly compromising classification accuracy of the CNN. The pre-processing stage presented in this paper is modelled after the retina and therefore is only tested against an image dataset. Note: This paper has been submitted for SAUPEC/RobMech/PRASA 2020.