 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly Supervised Fine Tuning Approach for Brain Tumor Segmentation Problem
Nov 06, 2019
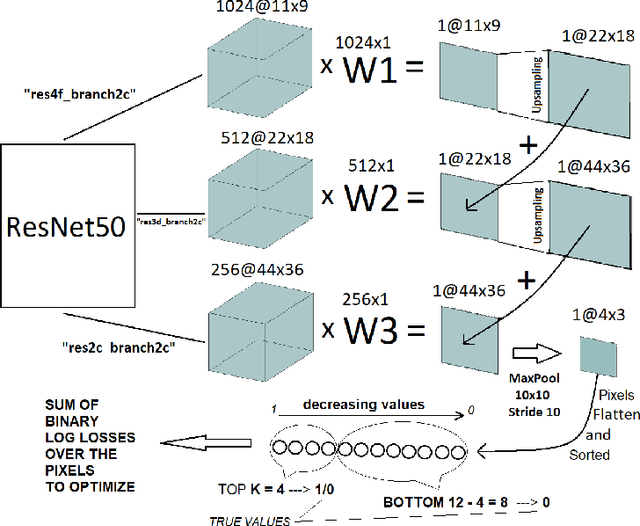
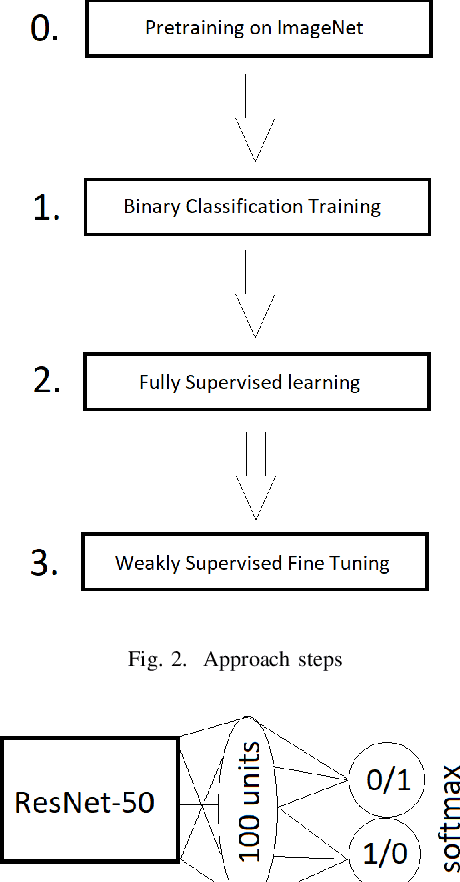
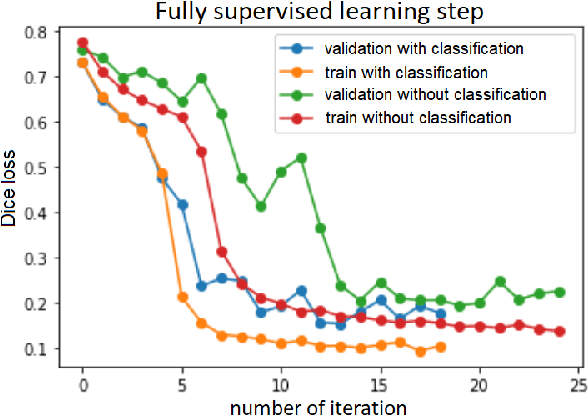
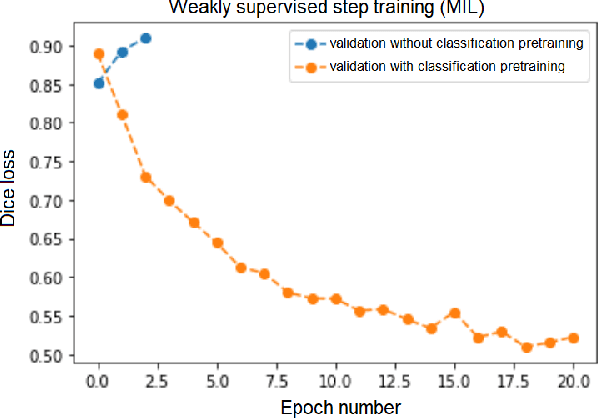
Segmentation of tumors in brain MRI images is a challenging task, where most recent methods demand large volumes of data with pixel-level annotations, which are generally costly to obtain. In contrast, image-level annotations, where only the presence of lesion is marked, are generally cheap, generated in far larger volumes compared to pixel-level labels, and contain less labeling noise. In the context of brain tumor segmentation, both pixel-level and image-level annotations are commonly available; thus, a natural question arises whether a segmentation procedure could take advantage of both. In the present work we: 1) propose a learning-based framework that allows simultaneous usage of both pixel- and image-level annotations in MRI images to learn a segmentation model for brain tumor; 2) study the influence of comparative amounts of pixel- and image-level annotations on the quality of brain tumor segmentation; 3) compare our approach to the traditional fully-supervised approach and show that the performance of our method in terms of segmentation quality may be competitive.
Strengths and Weaknesses of Deep Learning Models for Face Recognition Against Image Degradations
Oct 04, 2017
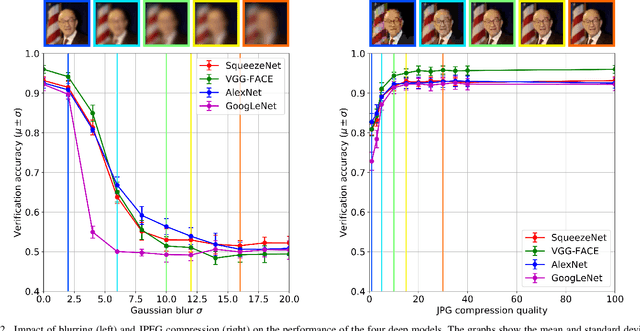
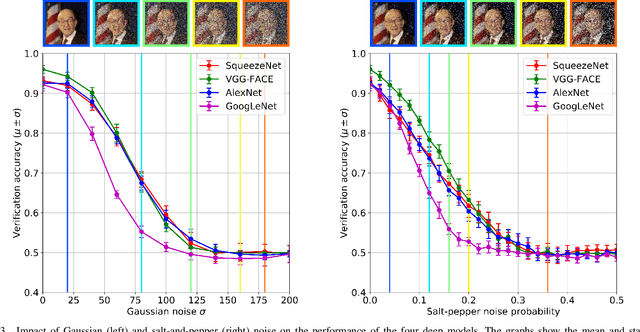
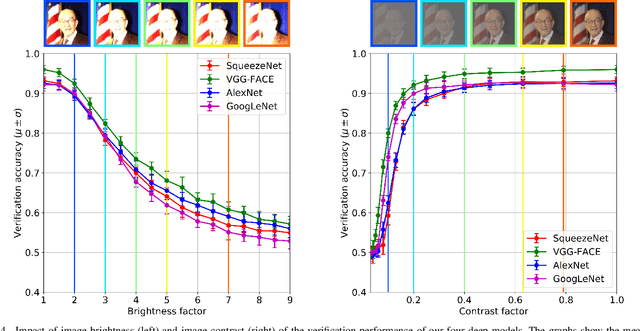
Deep convolutional neural networks (CNNs) based approaches are the state-of-the-art in various computer vision tasks, including face recognition. Considerable research effort is currently being directed towards further improving deep CNNs by focusing on more powerful model architectures and better learning techniques. However, studies systematically exploring the strengths and weaknesses of existing deep models for face recognition are still relatively scarce in the literature. In this paper, we try to fill this gap and study the effects of different covariates on the verification performance of four recent deep CNN models using the Labeled Faces in the Wild (LFW) dataset. Specifically, we investigate the influence of covariates related to: image quality -- blur, JPEG compression, occlusion, noise, image brightness, contrast, missing pixels; and model characteristics -- CNN architecture, color information, descriptor computation; and analyze their impact on the face verification performance of AlexNet, VGG-Face, GoogLeNet, and SqueezeNet. Based on comprehensive and rigorous experimentation, we identify the strengths and weaknesses of the deep learning models, and present key areas for potential future research. Our results indicate that high levels of noise, blur, missing pixels, and brightness have a detrimental effect on the verification performance of all models, whereas the impact of contrast changes and compression artifacts is limited. It has been found that the descriptor computation strategy and color information does not have a significant influence on performance.
Adversarial Semantic Data Augmentation for Human Pose Estimation
Aug 03, 2020
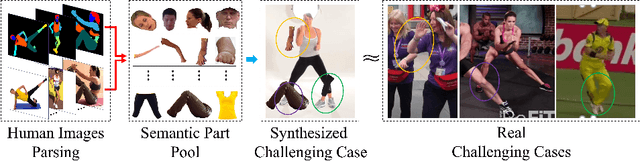
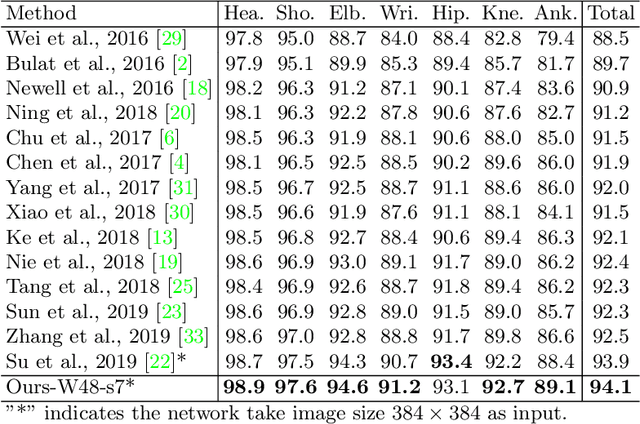
Human pose estimation is the task of localizing body keypoints from still images. The state-of-the-art methods suffer from insufficient examples of challenging cases such as symmetric appearance, heavy occlusion and nearby person. To enlarge the amounts of challenging cases, previous methods augmented images by cropping and pasting image patches with weak semantics, which leads to unrealistic appearance and limited diversity. We instead propose Semantic Data Augmentation (SDA), a method that augments images by pasting segmented body parts with various semantic granularity. Furthermore, we propose Adversarial Semantic Data Augmentation (ASDA), which exploits a generative network to dynamiclly predict tailored pasting configuration. Given off-the-shelf pose estimation network as discriminator, the generator seeks the most confusing transformation to increase the loss of the discriminator while the discriminator takes the generated sample as input and learns from it. The whole pipeline is optimized in an adversarial manner. State-of-the-art results are achieved on challenging benchmarks.
Understanding 3D CNN Behavior for Alzheimer's Disease Diagnosis from Brain PET Scan
Dec 10, 2019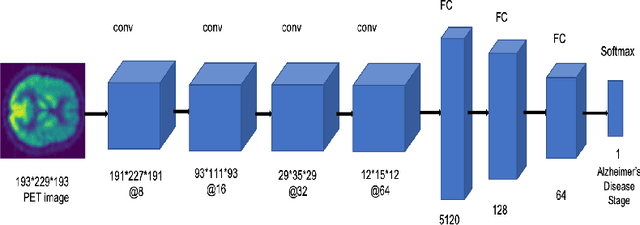

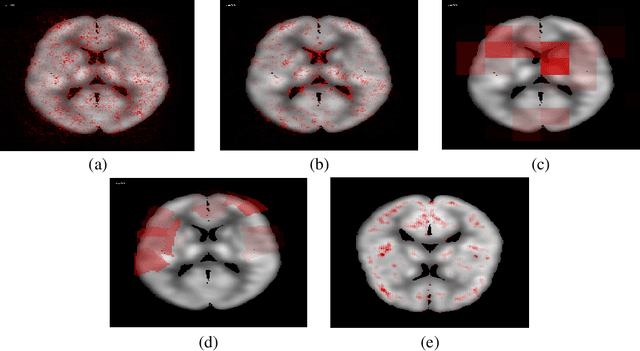
In recent days, Convolutional Neural Networks (CNN) have demonstrated impressive performance in medical image analysis. However, there is a lack of clear understanding of why and how the Convolutional Neural Network performs so well for image analysis task. How CNN analyzes an image and discriminates among samples of different classes are usually considered as non-transparent. As a result, it becomes difficult to apply CNN based approaches in clinical procedures and automated disease diagnosis systems. In this paper, we consider this issue and work on visualizing and understanding the decision of Convolutional Neural Network for Alzheimer's Disease (AD) Diagnosis. We develop a 3D deep convolutional neural network for AD diagnosis using brain PET scans and propose using five visualizations techniques - Sensitivity Analysis (Backpropagation), Guided Backpropagation, Occlusion, Brain Area Occlusion, and Layer-wise Relevance Propagation (LRP) to understand the decision of the CNN by highlighting the relevant areas in the PET data.
Code-Bridged Classifier (CBC): A Low or Negative Overhead Defense for Making a CNN Classifier Robust Against Adversarial Attacks
Jan 16, 2020
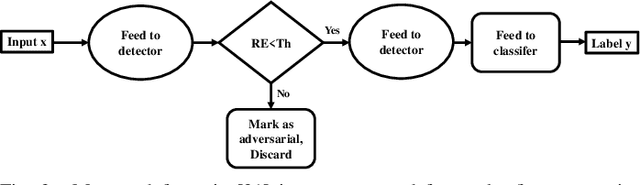
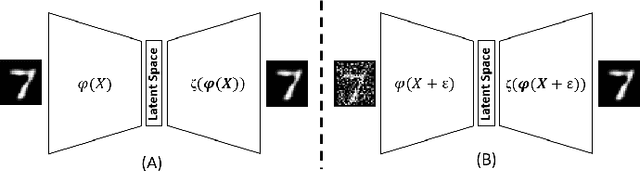
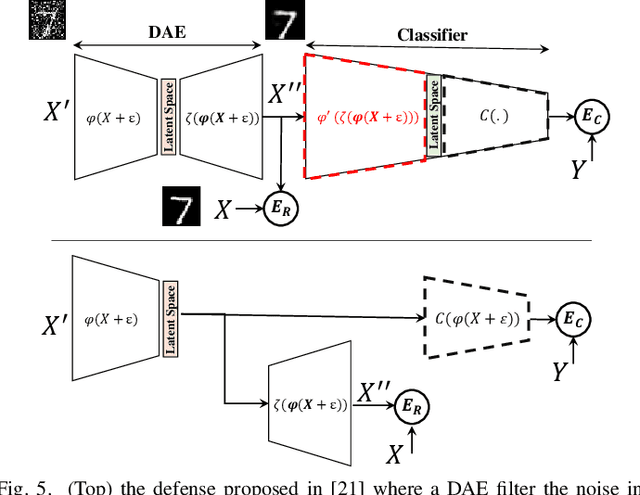
In this paper, we propose Code-Bridged Classifier (CBC), a framework for making a Convolutional Neural Network (CNNs) robust against adversarial attacks without increasing or even by decreasing the overall models' computational complexity. More specifically, we propose a stacked encoder-convolutional model, in which the input image is first encoded by the encoder module of a denoising auto-encoder, and then the resulting latent representation (without being decoded) is fed to a reduced complexity CNN for image classification. We illustrate that this network not only is more robust to adversarial examples but also has a significantly lower computational complexity when compared to the prior art defenses.
DeepC-MVS: Deep Confidence Prediction for Multi-View Stereo Reconstruction
Dec 01, 2019
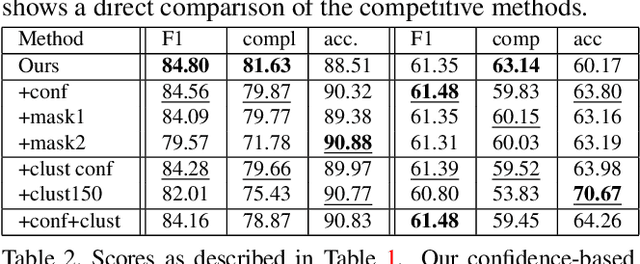
Deep Neural Networks (DNNs) have the potential to improve the quality of image-based 3D reconstructions. A challenge which still remains is to utilize the potential of DNNs to improve 3D reconstructions from high-resolution image datasets as available by the ETH3D benchmark. In this paper, we propose a way to employ DNNs in the image domain to gain a significant quality improvement of geometric image based 3D reconstruction. This is achieved by utilizing confidence prediction networks which have been adapted to the Multi-View Stereo (MVS) case and are trained on automatically generated ground truth established by geometric error propagation. In addition to a semi-dense real-world ground truth dataset for training the DNN, we present a synthetic dataset to enlarge the training dataset. We demonstrate the utility of the confidence predictions for two essential steps within a 3D reconstruction pipeline: Firstly, to be used for outlier clustering and filtering and secondly to be used within a depth refinement step. The presented 3D reconstruction pipeline DeepC-MVS makes use of deep learning for an essential part in MVS from high-resolution images and the experimental evaluation on popular benchmarks demonstrates the achieved state-of-the-art quality in 3D reconstruction.
Lightweight Photometric Stereo for Facial Details Recovery
Mar 27, 2020

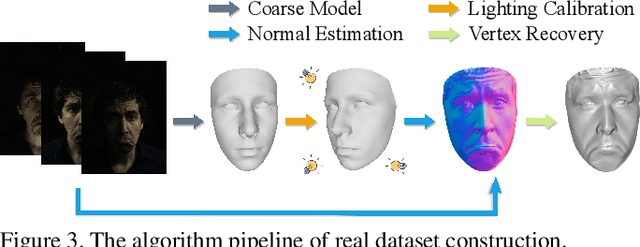
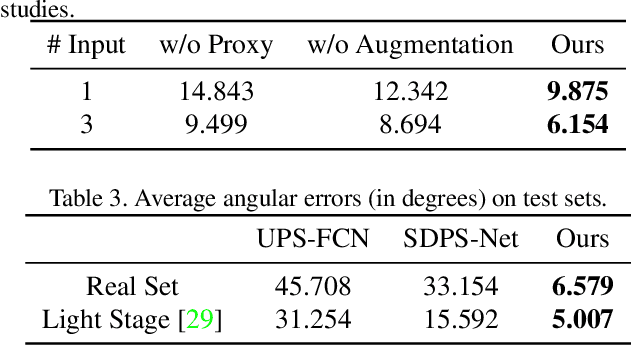
Recently, 3D face reconstruction from a single image has achieved great success with the help of deep learning and shape prior knowledge, but they often fail to produce accurate geometry details. On the other hand, photometric stereo methods can recover reliable geometry details, but require dense inputs and need to solve a complex optimization problem. In this paper, we present a lightweight strategy that only requires sparse inputs or even a single image to recover high-fidelity face shapes with images captured under near-field lights. To this end, we construct a dataset containing 84 different subjects with 29 expressions under 3 different lights. Data augmentation is applied to enrich the data in terms of diversity in identity, lighting, expression, etc. With this constructed dataset, we propose a novel neural network specially designed for photometric stereo based 3D face reconstruction. Extensive experiments and comparisons demonstrate that our method can generate high-quality reconstruction results with one to three facial images captured under near-field lights. Our full framework is available at https://github.com/Juyong/FacePSNet.
The Rate-Distortion-Accuracy Tradeoff: JPEG Case Study
Aug 03, 2020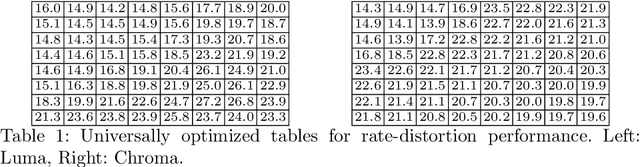
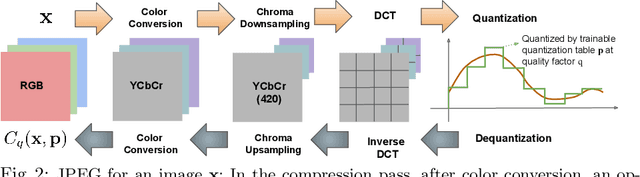
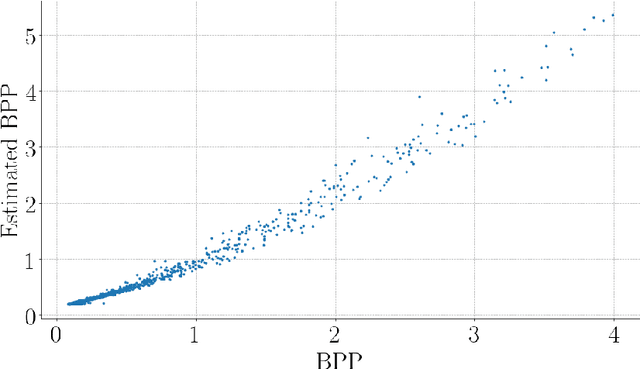
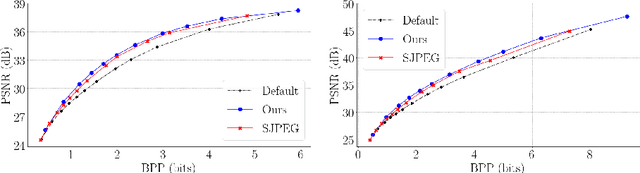
Handling digital images is almost always accompanied by a lossy compression in order to facilitate efficient transmission and storage. This introduces an unavoidable tension between the allocated bit-budget (rate) and the faithfulness of the resulting image to the original one (distortion). An additional complicating consideration is the effect of the compression on recognition performance by given classifiers (accuracy). This work aims to explore this rate-distortion-accuracy tradeoff. As a case study, we focus on the design of the quantization tables in the JPEG compression standard. We offer a novel optimal tuning of these tables via continuous optimization, leveraging a differential implementation of both the JPEG encoder-decoder and an entropy estimator. This enables us to offer a unified framework that considers the interplay between rate, distortion and classification accuracy. In all these fronts, we report a substantial boost in performance by a simple and easily implemented modification of these tables.
Development of a Machine-Learning System to Classify Lung CT Scan Images into Normal/COVID-19 Class
Apr 24, 2020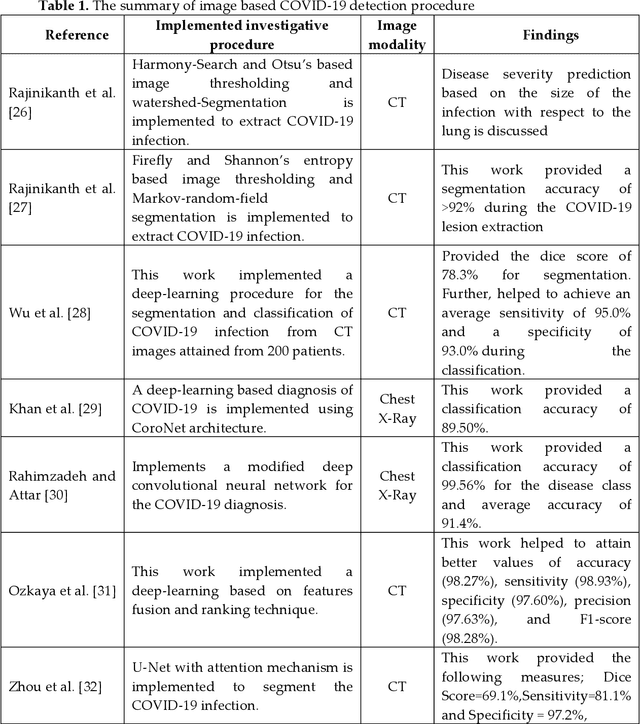
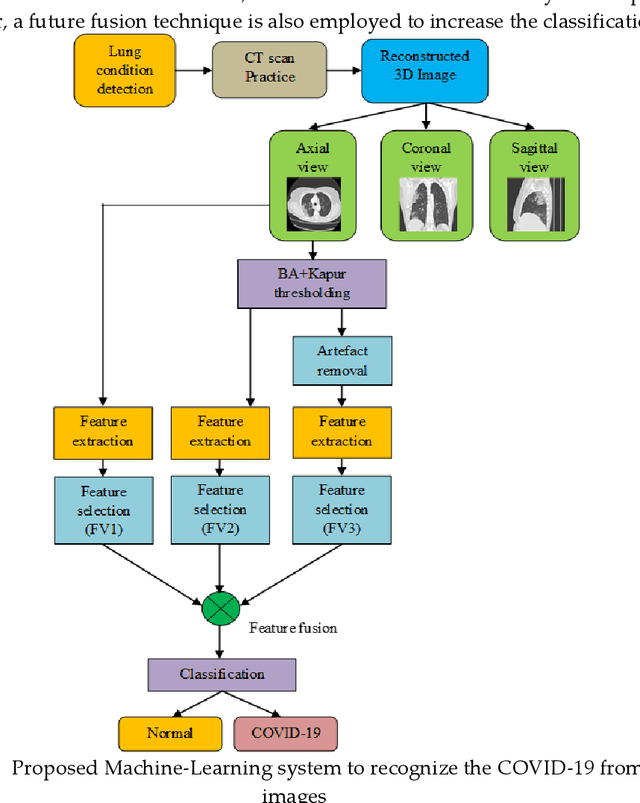
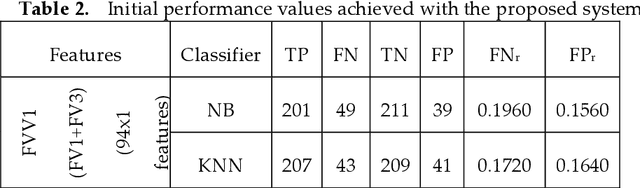
Recently, the lung infection due to Coronavirus Disease (COVID-19) affected a large human group worldwide and the assessment of the infection rate in the lung is essential for treatment planning. This research aims to propose a Machine-Learning-System (MLS) to detect the COVID-19 infection using the CT scan Slices (CTS). This MLS implements a sequence of methods, such as multi-thresholding, image separation using threshold filter, feature-extraction, feature-selection, feature-fusion and classification. The initial part implements the Chaotic-Bat-Algorithm and Kapur's Entropy (CBA+KE) thresholding to enhance the CTS. The threshold filter separates the image into two segments based on a chosen threshold 'Th'. The texture features of these images are extracted, refined and selected using the chosen procedures. Finally, a two-class classifier system is implemented to categorize the chosen CTS (n=500 with a pixel dimension of 512x512x1) into normal/COVID-19 group. In this work, the classifiers, such as Naive Bayes (NB), k-Nearest Neighbors (KNN), Decision Tree (DT), Random Forest (RF) and Support Vector Machine with linear kernel (SVM) are implemented and the classification task is performed using various feature vectors. The experimental outcome of the SVM with Fused-Feature-Vector (FFV) helped to attain a detection accuracy of 89.80%.
A Multi-modal Machine Learning Approach and Toolkit to Automate Recognition of Early Stages of Dementia among British Sign Language Users
Oct 01, 2020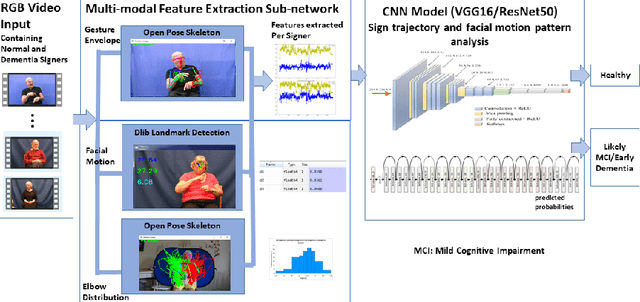
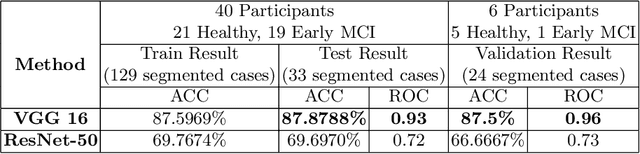
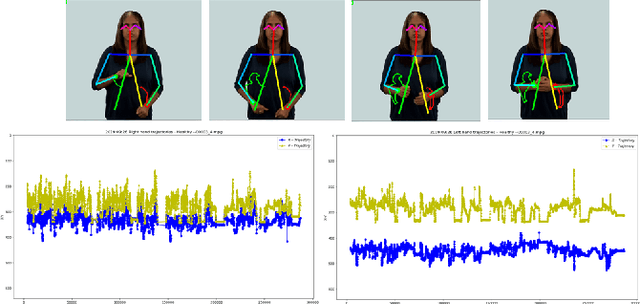
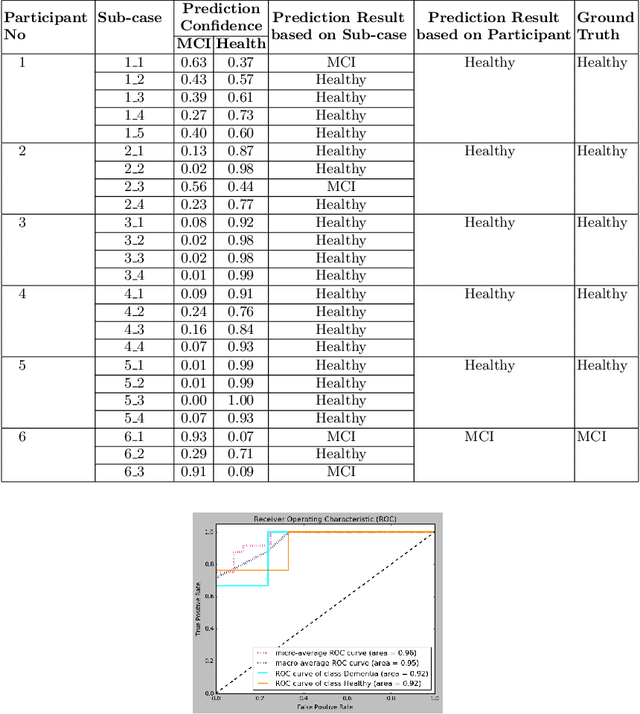
The ageing population trend is correlated with an increased prevalence of acquired cognitive impairments such as dementia. Although there is no cure for dementia, a timely diagnosis helps in obtaining necessary support and appropriate medication. Researchers are working urgently to develop effective technological tools that can help doctors undertake early identification of cognitive disorder. In particular, screening for dementia in ageing Deaf signers of British Sign Language (BSL) poses additional challenges as the diagnostic process is bound up with conditions such as quality and availability of interpreters, as well as appropriate questionnaires and cognitive tests. On the other hand, deep learning based approaches for image and video analysis and understanding are promising, particularly the adoption of Convolutional Neural Network (CNN), which require large amounts of training data. In this paper, however, we demonstrate novelty in the following way: a) a multi-modal machine learning based automatic recognition toolkit for early stages of dementia among BSL users in that features from several parts of the body contributing to the sign envelope, e.g., hand-arm movements and facial expressions, are combined, b) universality in that it is possible to apply our technique to users of any sign language, since it is language independent, c) given the trade-off between complexity and accuracy of machine learning (ML) prediction models as well as the limited amount of training and testing data being available, we show that our approach is not over-fitted and has the potential to scale up.