 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Relational Regularized Autoencoders with Spherical Sliced Fused Gromov Wasserstein
Oct 05, 2020
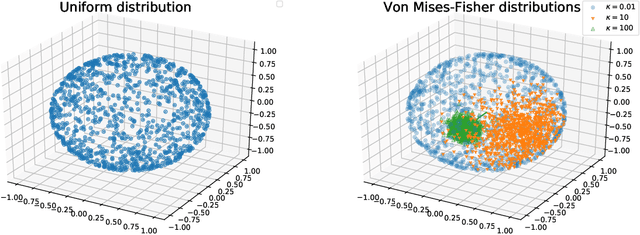
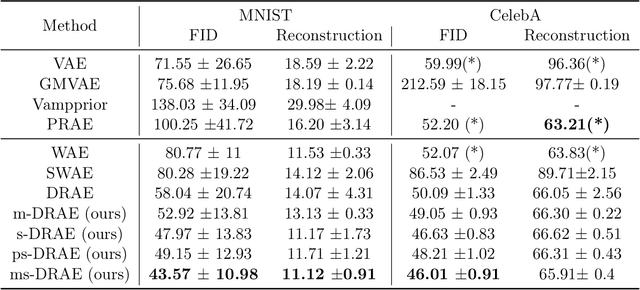
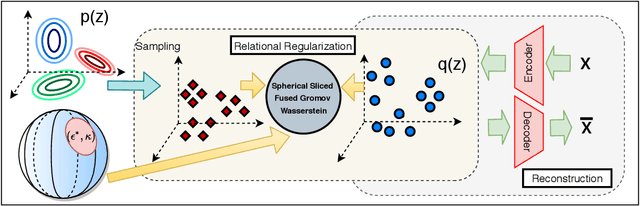
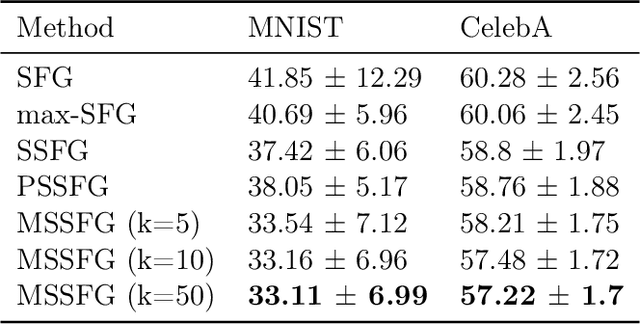
Relational regularized autoencoder (RAE) is a framework to learn the distribution of data by minimizing a reconstruction loss together with a relational regularization on the latent space. A recent attempt to reduce the inner discrepancy between the prior and aggregated posterior distributions is to incorporate sliced fused Gromov-Wasserstein (SFG) between these distributions. That approach has a weakness since it treats every slicing direction similarly, meanwhile several directions are not useful for the discriminative task. To improve the discrepancy and consequently the relational regularization, we propose a new relational discrepancy, named spherical sliced fused Gromov Wasserstein (SSFG), that can find an important area of projections characterized by a von Mises-Fisher distribution. Then, we introduce two variants of SSFG to improve its performance. The first variant, named mixture spherical sliced fused Gromov Wasserstein (MSSFG), replaces the vMF distribution by a mixture of von Mises-Fisher distributions to capture multiple important areas of directions that are far from each other. The second variant, named power spherical sliced fused Gromov Wasserstein (PSSFG), replaces the vMF distribution by a power spherical distribution to improve the sampling time in high dimension settings. We then apply the new discrepancies to the RAE framework to achieve its new variants. Finally, we conduct extensive experiments to show that the new proposed autoencoders have favorable performance in learning latent manifold structure, image generation, and reconstruction.
Image segmentation based on the hybrid total variation model and the K-means clustering strategy
May 30, 2016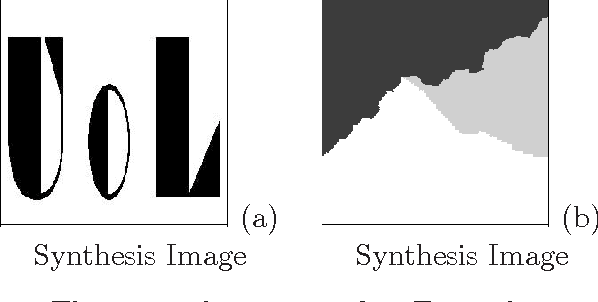
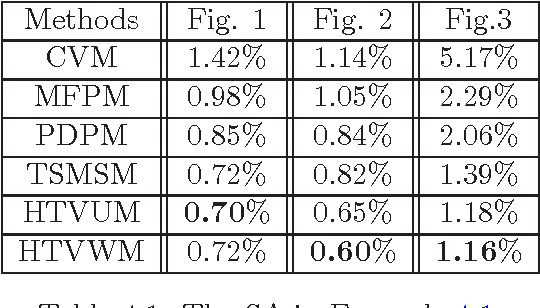
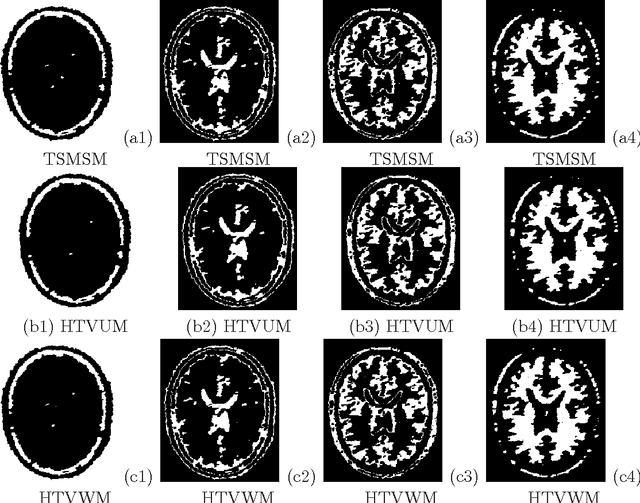

The performance of image segmentation highly relies on the original inputting image. When the image is contaminated by some noises or blurs, we can not obtain the efficient segmentation result by using direct segmentation methods. In order to efficiently segment the contaminated image, this paper proposes a two step method based on the hybrid total variation model with a box constraint and the K-means clustering method. In the first step, the hybrid model is based on the weighted convex combination between the total variation functional and the high-order total variation as the regularization term to obtain the original clustering data. In order to deal with non-smooth regularization term, we solve this model by employing the alternating split Bregman method. Then, in the second step, the segmentation can be obtained by thresholding this clustering data into different phases, where the thresholds can be given by using the K-means clustering method. Numerical comparisons show that our proposed model can provide more efficient segmentation results dealing with the noise image and blurring image.
Bayesian Image Quality Transfer with CNNs: Exploring Uncertainty in dMRI Super-Resolution
May 30, 2017
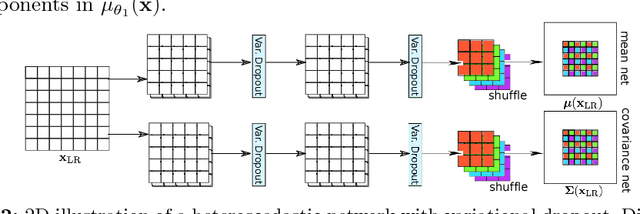
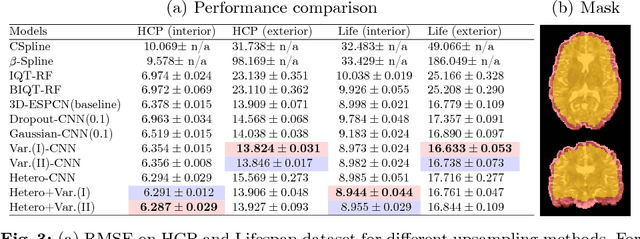
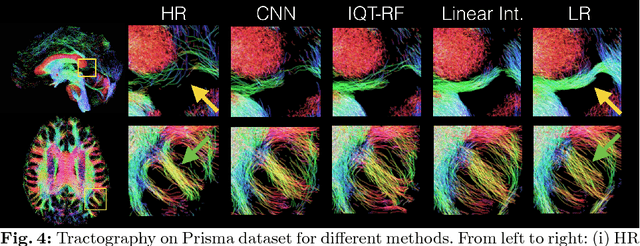
In this work, we investigate the value of uncertainty modeling in 3D super-resolution with convolutional neural networks (CNNs). Deep learning has shown success in a plethora of medical image transformation problems, such as super-resolution (SR) and image synthesis. However, the highly ill-posed nature of such problems results in inevitable ambiguity in the learning of networks. We propose to account for intrinsic uncertainty through a per-patch heteroscedastic noise model and for parameter uncertainty through approximate Bayesian inference in the form of variational dropout. We show that the combined benefits of both lead to the state-of-the-art performance SR of diffusion MR brain images in terms of errors compared to ground truth. We further show that the reduced error scores produce tangible benefits in downstream tractography. In addition, the probabilistic nature of the methods naturally confers a mechanism to quantify uncertainty over the super-resolved output. We demonstrate through experiments on both healthy and pathological brains the potential utility of such an uncertainty measure in the risk assessment of the super-resolved images for subsequent clinical use.
Multiple Abnormality Detection for Automatic Medical Image Diagnosis Using Bifurcated Convolutional Neural Network
Oct 15, 2018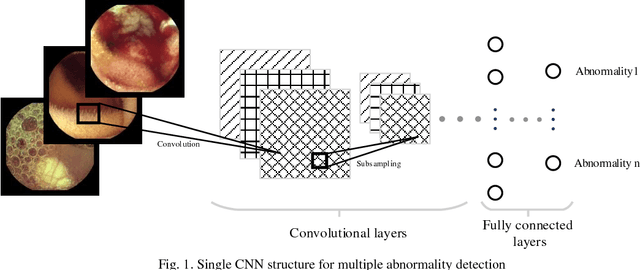
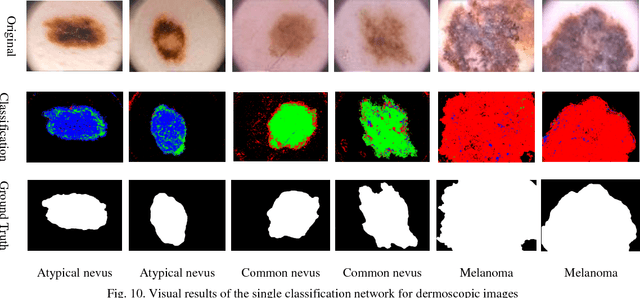
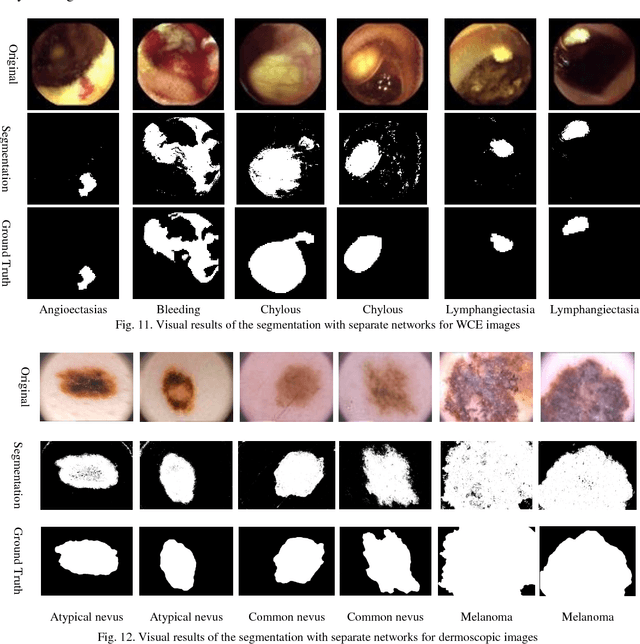
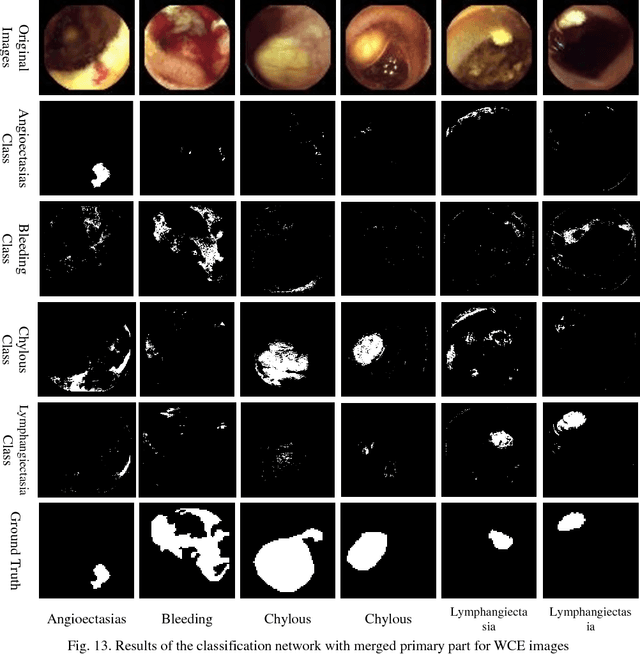
Automating classification and segmentation process of abnormal regions in different body organs has a crucial role in most of medical imaging applications such as funduscopy, endoscopy, and dermoscopy. Detecting multiple abnormalities in each type of images is necessary for better and more accurate diagnosis procedure and medical decisions. In recent years portable medical imaging devices such as capsule endoscopy and digital dermatoscope have been introduced and made the diagnosis procedure easier and more efficient. However, these portable devices have constrained power resources and limited computational capability. To address this problem, we propose a bifurcated structure for convolutional neural networks performing both classification and segmentation of multiple abnormalities simultaneously. The proposed network is first trained by each abnormality separately. Then the network is trained using all abnormalities. In order to reduce the computational complexity, the network is redesigned to share some features which are common among all abnormalities. Later, these shared features are used in different settings (directions) to segment and classify the abnormal region of the image. Finally, results of the classification and segmentation directions are fused to obtain the classified segmentation map. Proposed framework is simulated using four frequent gastrointestinal abnormalities as well as three dermoscopic lesions and for evaluation of the proposed framework the results are compared with the corresponding ground truth map. Properties of the bifurcated network like low complexity and resource sharing make it suitable to be implemented as a part of portable medical imaging devices.
Deep Sub-Ensembles for Fast Uncertainty Estimation in Image Classification
Nov 29, 2019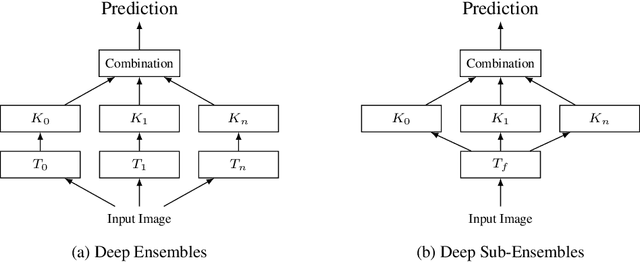
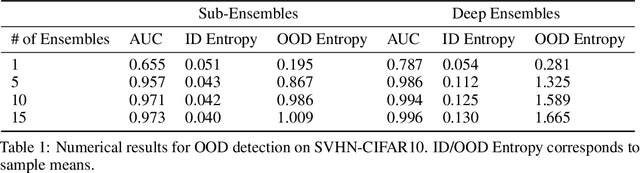
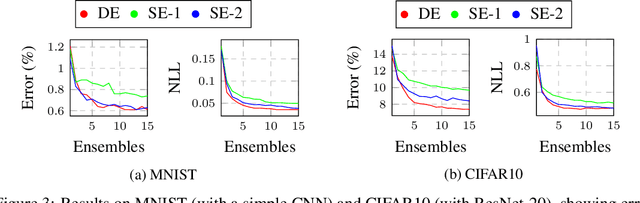
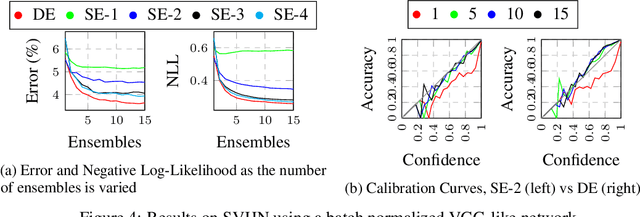
Fast estimates of model uncertainty are required for many robust robotics applications. Deep Ensembles provides state of the art uncertainty without requiring Bayesian methods, but still it is computationally expensive. In this paper we propose deep sub-ensembles, an approximation to deep ensembles where the core idea is to ensemble only the layers close to the output, and not the whole model. With ResNet-20 on the CIFAR10 dataset, we obtain 1.5-2.5 speedup over a Deep Ensemble, with a small increase in error and NLL, and similarly up to 5-15 speedup with a VGG-like network on the SVHN dataset. Our results show that this idea enables a trade-off between error and uncertainty quality versus computational performance.
Egocentric Basketball Motion Planning from a Single First-Person Image
Mar 04, 2018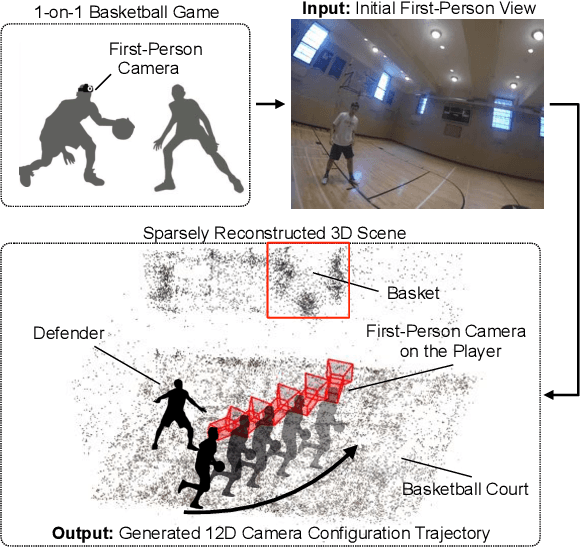
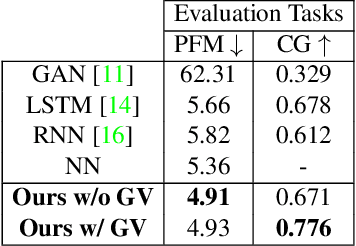
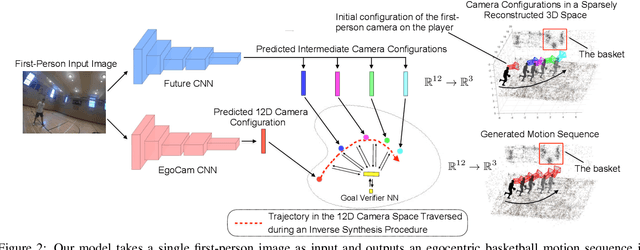
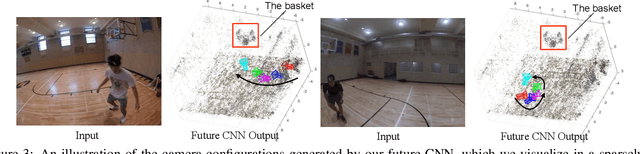
We present a model that uses a single first-person image to generate an egocentric basketball motion sequence in the form of a 12D camera configuration trajectory, which encodes a player's 3D location and 3D head orientation throughout the sequence. To do this, we first introduce a future convolutional neural network (CNN) that predicts an initial sequence of 12D camera configurations, aiming to capture how real players move during a one-on-one basketball game. We also introduce a goal verifier network, which is trained to verify that a given camera configuration is consistent with the final goals of real one-on-one basketball players. Next, we propose an inverse synthesis procedure to synthesize a refined sequence of 12D camera configurations that (1) sufficiently matches the initial configurations predicted by the future CNN, while (2) maximizing the output of the goal verifier network. Finally, by following the trajectory resulting from the refined camera configuration sequence, we obtain the complete 12D motion sequence. Our model generates realistic basketball motion sequences that capture the goals of real players, outperforming standard deep learning approaches such as recurrent neural networks (RNNs), long short-term memory networks (LSTMs), and generative adversarial networks (GANs).
Deep Semantic Face Deblurring
Jan 19, 2020
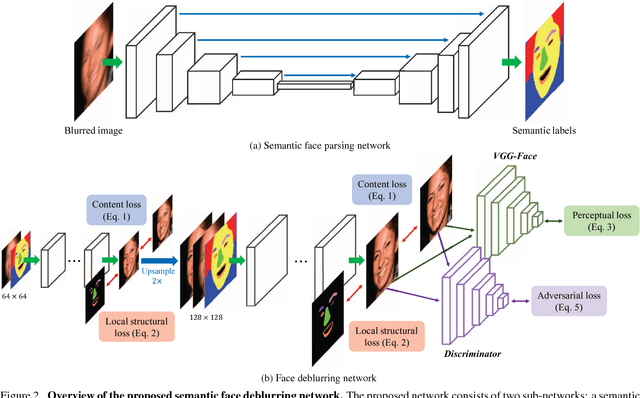
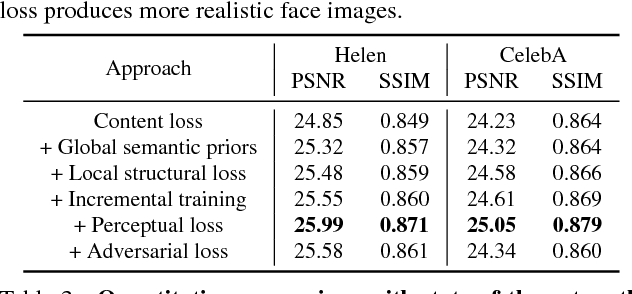

In this paper, we propose an effective and efficient face deblurring algorithm by exploiting semantic cues via deep convolutional neural networks. As the human faces are highly structured and share unified facial components (e.g., eyes and mouths), such semantic information provides a strong prior for restoration. We incorporate face semantic labels as input priors and propose an adaptive structural loss to regularize facial local structures within an end-to-end deep convolutional neural network. Specifically, we first use a coarse deblurring network to reduce the motion blur on the input face image. We then adopt a parsing network to extract the semantic features from the coarse deblurred image. Finally, the fine deblurring network utilizes the semantic information to restore a clear face image. We train the network with perceptual and adversarial losses to generate photo-realistic results. The proposed method restores sharp images with more accurate facial features and details. Quantitative and qualitative evaluations demonstrate that the proposed face deblurring algorithm performs favorably against the state-of-the-art methods in terms of restoration quality, face recognition and execution speed.
Progressively Guided Alternate Refinement Network for RGB-D Salient Object Detection
Aug 17, 2020
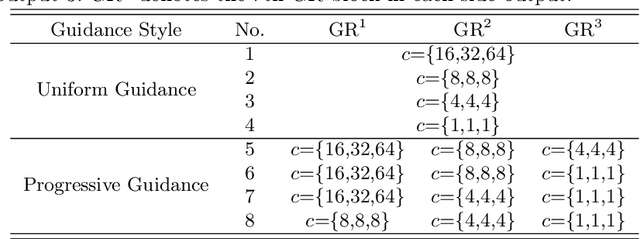
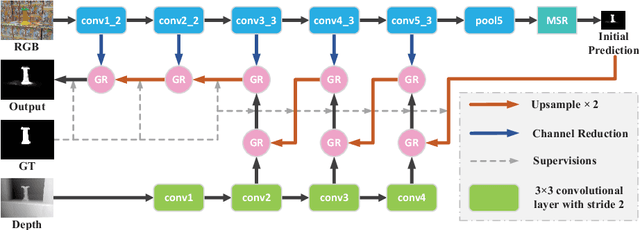
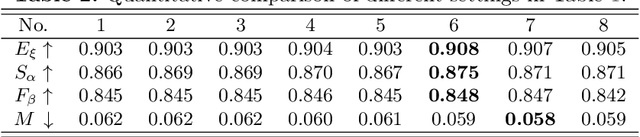
In this paper, we aim to develop an efficient and compact deep network for RGB-D salient object detection, where the depth image provides complementary information to boost performance in complex scenarios. Starting from a coarse initial prediction by a multi-scale residual block, we propose a progressively guided alternate refinement network to refine it. Instead of using ImageNet pre-trained backbone network, we first construct a lightweight depth stream by learning from scratch, which can extract complementary features more efficiently with less redundancy. Then, different from the existing fusion based methods, RGB and depth features are fed into proposed guided residual (GR) blocks alternately to reduce their mutual degradation. By assigning progressive guidance in the stacked GR blocks within each side-output, the false detection and missing parts can be well remedied. Extensive experiments on seven benchmark datasets demonstrate that our model outperforms existing state-of-the-art approaches by a large margin, and also shows superiority in efficiency (71 FPS) and model size (64.9 MB).
A Mobile Robot Hand-Arm Teleoperation System by Vision and IMU
Mar 11, 2020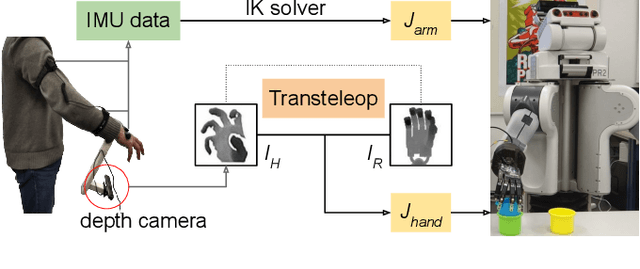
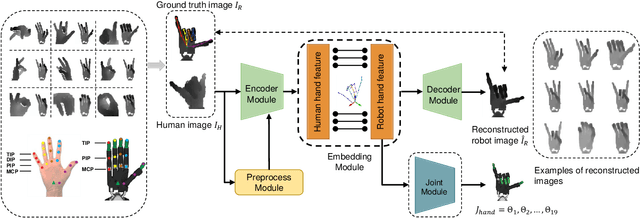


In this paper, we present a multimodal mobile teleoperation system that consists of a novel vision-based hand pose regression network (Transteleop) and an IMU-based arm tracking method. Transteleop observes the human hand through a low-cost depth camera and generates not only joint angles but also depth images of paired robot hand poses through an image-to-image translation process. A keypoint-based reconstruction loss explores the resemblance in appearance and anatomy between human and robotic hands and enriches the local features of reconstructed images. A wearable camera holder enables simultaneous hand-arm control and facilitates the mobility of the whole teleoperation system. Network evaluation results on a test dataset and a variety of complex manipulation tasks that go beyond simple pick-and-place operations show the efficiency and stability of our multimodal teleoperation system.
Web image annotation by diffusion maps manifold learning algorithm
Dec 08, 2014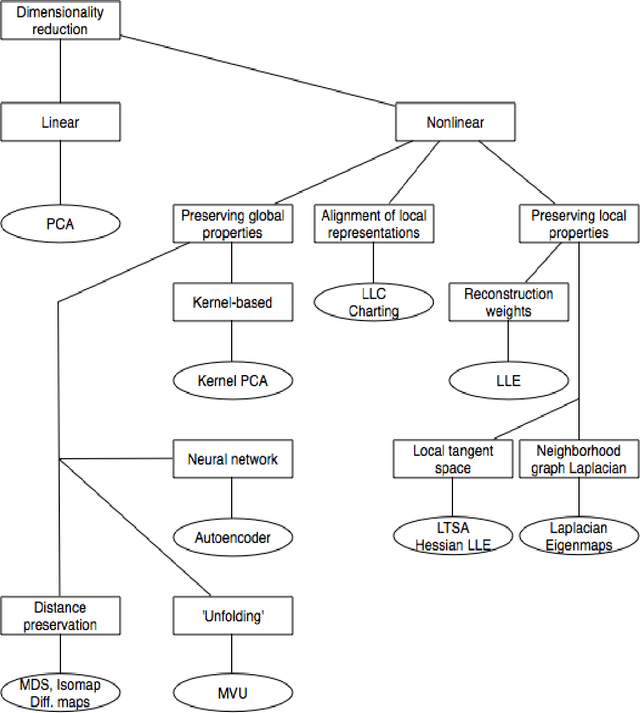

Automatic image annotation is one of the most challenging problems in machine vision areas. The goal of this task is to predict number of keywords automatically for images captured in real data. Many methods are based on visual features in order to calculate similarities between image samples. But the computation cost of these approaches is very high. These methods require many training samples to be stored in memory. To lessen this burden, a number of techniques have been developed to reduce the number of features in a dataset. Manifold learning is a popular approach to nonlinear dimensionality reduction. In this paper, we investigate Diffusion maps manifold learning method for web image auto-annotation task. Diffusion maps manifold learning method is used to reduce the dimension of some visual features. Extensive experiments and analysis on NUS-WIDE-LITE web image dataset with different visual features show how this manifold learning dimensionality reduction method can be applied effectively to image annotation.