 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Image Deblurring by Spectral Properties of Convolution Operators
Apr 22, 2014




In this paper, we study the problem of recovering a sharp version of a given blurry image when the blur kernel is unknown. Previous methods often introduce an image-independent regularizer (such as Gaussian or sparse priors) on the desired blur kernel. We shall show that the blurry image itself encodes rich information about the blur kernel. Such information can be found through analyzing and comparing how the spectrum of an image as a convolution operator changes before and after blurring. Our analysis leads to an effective convex regularizer on the blur kernel which depends only on the given blurry image. We show that the minimizer of this regularizer guarantees to give good approximation to the blur kernel if the original image is sharp enough. By combining this powerful regularizer with conventional image deblurring techniques, we show how we could significantly improve the deblurring results through simulations and experiments on real images. In addition, our analysis and experiments help explaining a widely accepted doctrine; that is, the edges are good features for deblurring.
Automated Identification of Thoracic Pathology from Chest Radiographs with Enhanced Training Pipeline
Jun 11, 2020Chest x-rays are the most common radiology studies for diagnosing lung and heart disease. Hence, a system for automated pre-reporting of pathologic findings on chest x-rays would greatly enhance radiologists' productivity. To this end, we investigate a deep-learning framework with novel training schemes for classification of different thoracic pathology labels from chest x-rays. We use the currently largest publicly available annotated dataset ChestX-ray14 of 112,120 chest radiographs of 30,805 patients. Each image was annotated with either a 'NoFinding' class, or one or more of 14 thoracic pathology labels. Subjects can have multiple pathologies, resulting in a multi-class, multi-label problem. We encoded labels as binary vectors using k-hot encoding. We study the ResNet34 architecture, pre-trained on ImageNet, where two key modifications were incorporated into the training framework: (1) Stochastic gradient descent with momentum and with restarts using cosine annealing, (2) Variable image sizes for fine-tuning to prevent overfitting. Additionally, we use a heuristic algorithm to select a good learning rate. Learning with restarts was used to avoid local minima. Area Under receiver operating characteristics Curve (AUC) was used to quantitatively evaluate diagnostic quality. Our results are comparable to, or outperform the best results of current state-of-the-art methods with AUCs as follows: Atelectasis:0.81, Cardiomegaly:0.91, Consolidation:0.81, Edema:0.92, Effusion:0.89, Emphysema: 0.92, Fibrosis:0.81, Hernia:0.84, Infiltration:0.73, Mass:0.85, Nodule:0.76, Pleural Thickening:0.81, Pneumonia:0.77, Pneumothorax:0.89 and NoFinding:0.79. Our results suggest that, in addition to using sophisticated network architectures, a good learning rate, scheduler and a robust optimizer can boost performance.
* 6 pages, 1 figure, 2 tables
Motion Capture from Internet Videos
Aug 18, 2020
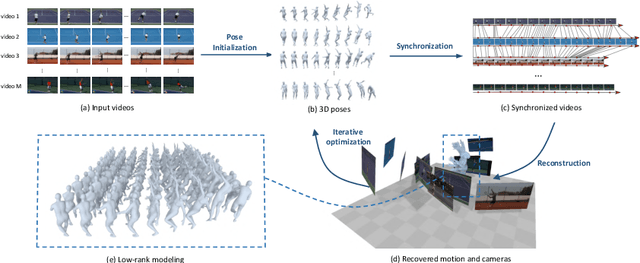

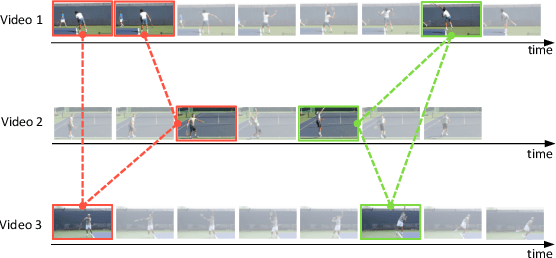
Recent advances in image-based human pose estimation make it possible to capture 3D human motion from a single RGB video. However, the inherent depth ambiguity and self-occlusion in a single view prohibit the recovery of as high-quality motion as multi-view reconstruction. While multi-view videos are not common, the videos of a celebrity performing a specific action are usually abundant on the Internet. Even if these videos were recorded at different time instances, they would encode the same motion characteristics of the person. Therefore, we propose to capture human motion by jointly analyzing these Internet videos instead of using single videos separately. However, this new task poses many new challenges that cannot be addressed by existing methods, as the videos are unsynchronized, the camera viewpoints are unknown, the background scenes are different, and the human motions are not exactly the same among videos. To address these challenges, we propose a novel optimization-based framework and experimentally demonstrate its ability to recover much more precise and detailed motion from multiple videos, compared against monocular motion capture methods.
Robust Multi-Image HDR Reconstruction for the Modulo Camera
Jul 05, 2017
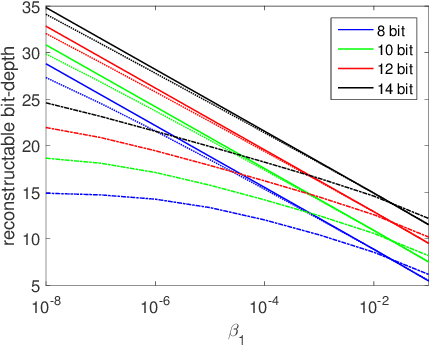
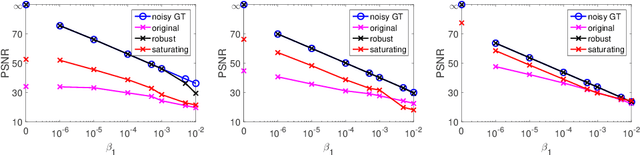

Photographing scenes with high dynamic range (HDR) poses great challenges to consumer cameras with their limited sensor bit depth. To address this, Zhao et al. recently proposed a novel sensor concept - the modulo camera - which captures the least significant bits of the recorded scene instead of going into saturation. Similar to conventional pipelines, HDR images can be reconstructed from multiple exposures, but significantly fewer images are needed than with a typical saturating sensor. While the concept is appealing, we show that the original reconstruction approach assumes noise-free measurements and quickly breaks down otherwise. To address this, we propose a novel reconstruction algorithm that is robust to image noise and produces significantly fewer artifacts. We theoretically analyze correctness as well as limitations, and show that our approach significantly outperforms the baseline on real data.
Learning a Recurrent Visual Representation for Image Caption Generation
Nov 20, 2014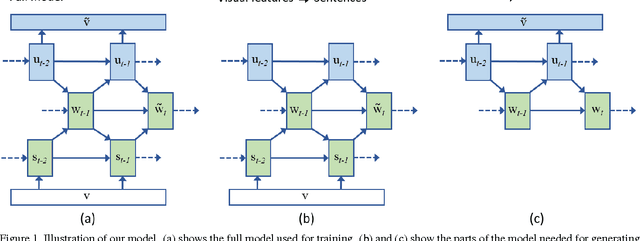
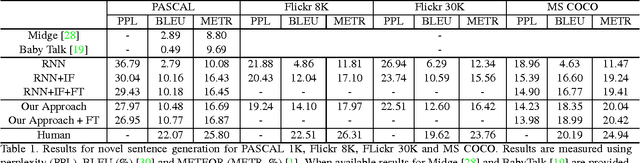

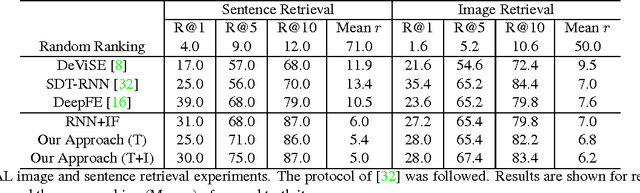
In this paper we explore the bi-directional mapping between images and their sentence-based descriptions. We propose learning this mapping using a recurrent neural network. Unlike previous approaches that map both sentences and images to a common embedding, we enable the generation of novel sentences given an image. Using the same model, we can also reconstruct the visual features associated with an image given its visual description. We use a novel recurrent visual memory that automatically learns to remember long-term visual concepts to aid in both sentence generation and visual feature reconstruction. We evaluate our approach on several tasks. These include sentence generation, sentence retrieval and image retrieval. State-of-the-art results are shown for the task of generating novel image descriptions. When compared to human generated captions, our automatically generated captions are preferred by humans over $19.8\%$ of the time. Results are better than or comparable to state-of-the-art results on the image and sentence retrieval tasks for methods using similar visual features.
Deep Belief Networks for Image Denoising
Jan 02, 2014

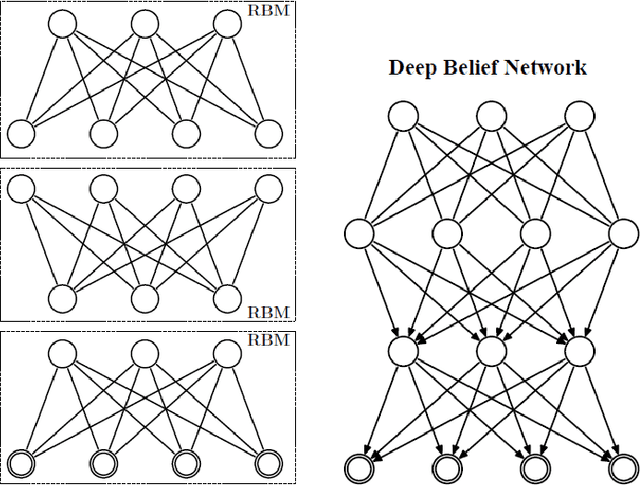
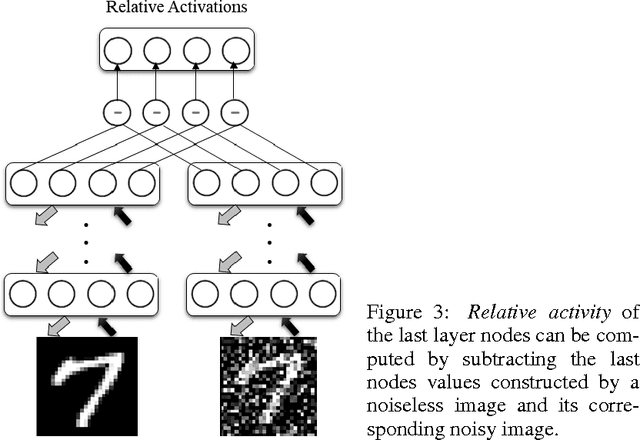
Deep Belief Networks which are hierarchical generative models are effective tools for feature representation and extraction. Furthermore, DBNs can be used in numerous aspects of Machine Learning such as image denoising. In this paper, we propose a novel method for image denoising which relies on the DBNs' ability in feature representation. This work is based upon learning of the noise behavior. Generally, features which are extracted using DBNs are presented as the values of the last layer nodes. We train a DBN a way that the network totally distinguishes between nodes presenting noise and nodes presenting image content in the last later of DBN, i.e. the nodes in the last layer of trained DBN are divided into two distinct groups of nodes. After detecting the nodes which are presenting the noise, we are able to make the noise nodes inactive and reconstruct a noiseless image. In section 4 we explore the results of applying this method on the MNIST dataset of handwritten digits which is corrupted with additive white Gaussian noise (AWGN). A reduction of 65.9% in average mean square error (MSE) was achieved when the proposed method was used for the reconstruction of the noisy images.
Schizophrenia-mimicking layers outperform conventional neural network layers
Sep 23, 2020
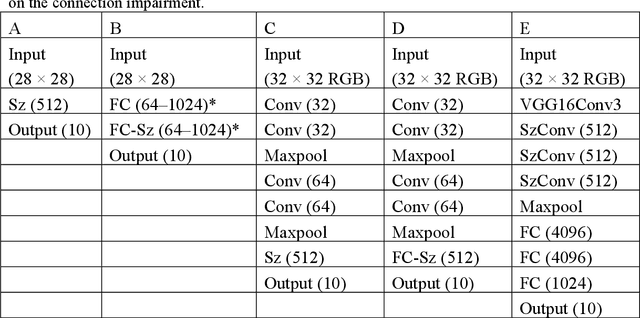
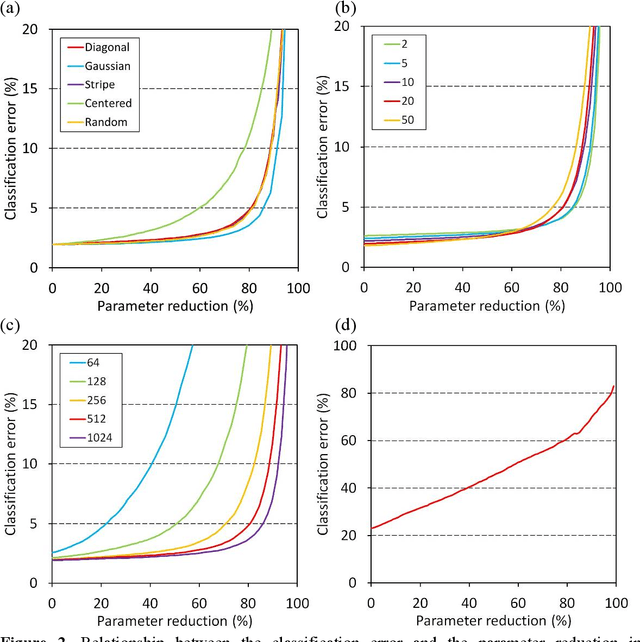
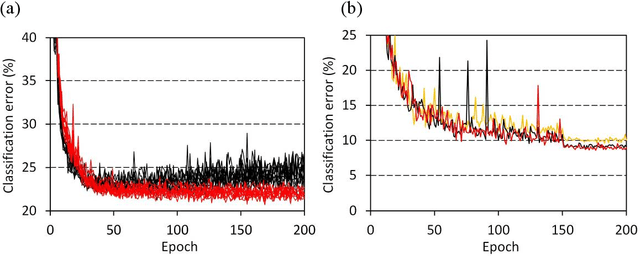
We have reported nanometer-scale three-dimensional studies of brain networks of schizophrenia cases and found that their neurites are thin and tortuous compared to healthy controls. This suggests that connections between distal neurons are impaired in microcircuits of the schizophrenia cases. In this study, we applied this biological findings to designing schizophrenia-mimicking artificial neural network to simulate the connection impairment in the disorder. Neural networks having the schizophrenia connection layer in place of fully connected layer were subjected to image classification tasks using MNIST and CIFAR-10 datasets. The obtained results revealed that the schizophrenia connection layer is tolerant to overfitting and outperforms fully connected layer. Schizophrenia-mimicking convolution layer was also tested with the VGG configuration, showing that 60% of kernel weights of the last convolution layer can be eliminated while keeping competitive performance. Schizophrenia-mimicking layers can be used instead of fully-connected or convolution layers without any change in the network configuration and training procedures, hence the outperformance of the schizophrenia-mimicking layer is easily incorporated in neural networks. The results of this study indicate that the connection impairment in schizophrenia is not a burden to the brain, but has some functional roles to attain a better brain performance. We suggest that the seemingly neuropathological alterations observed in schizophrenia have been rationally implemented in our brain during the process of biological evolution.
Coarse-to-Fine Pseudo-Labeling Guided Meta-Learning for Inexactly-Supervised Few-Shot Classification
Jul 11, 2020
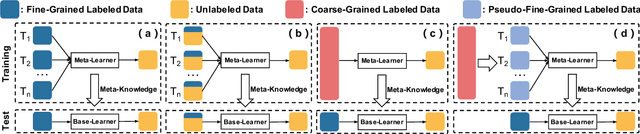
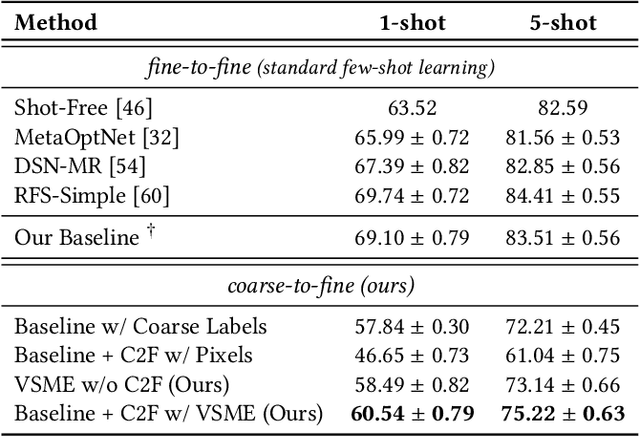
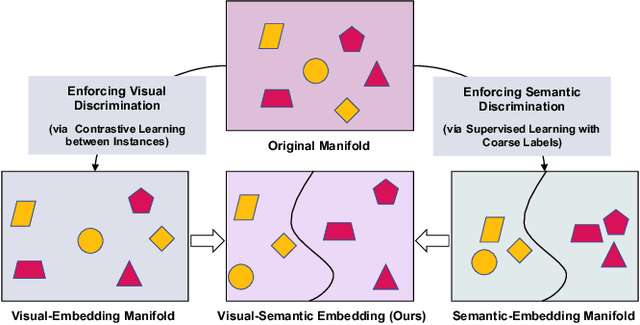
Meta-learning has recently emerged as a promising technique to address the challenge of few-shot learning. However, most existing meta-learning algorithms require fine-grained supervision, thereby involving prohibitive annotation cost. In this paper, we present a new problem named inexactly-supervised meta-learning to alleviate such limitation, focusing on tackling few-shot classification tasks with only coarse-grained supervision. Accordingly, we propose a Coarse-to-Fine (C2F) pseudo-labeling process to construct pseudo-tasks from coarsely-labeled data by grouping each coarse-class into pseudo-fine-classes via similarity matching. Moreover, we develop a Bi-level Discriminative Embedding (BDE) to obtain a good image similarity measure in both visual and semantic aspects with inexact supervision. Experiments across representative benchmarks indicate that our approach shows profound advantages over baseline models.
Deep-URL: A Model-Aware Approach To Blind Deconvolution Based On Deep Unfolded Richardson-Lucy Network
Feb 06, 2020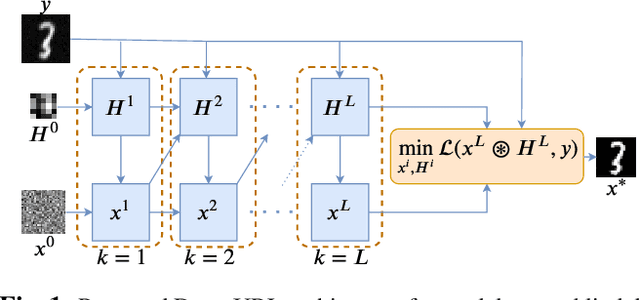
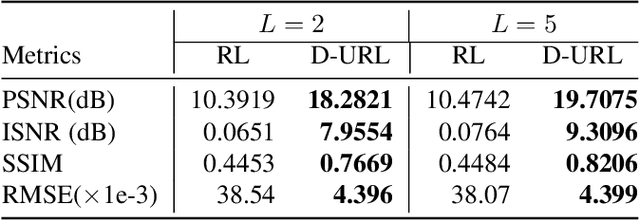
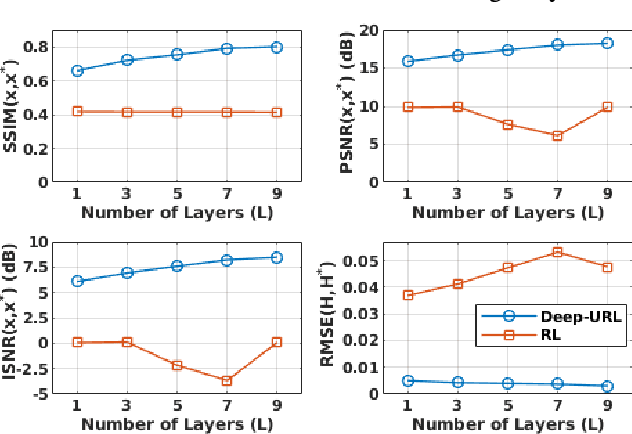
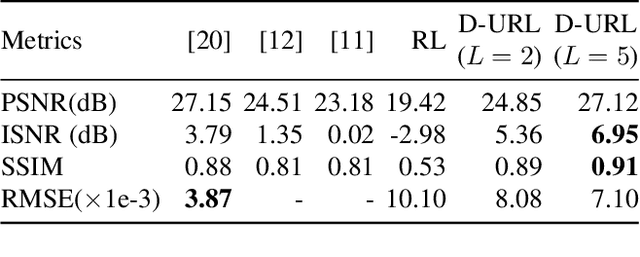
The lack of interpretability in current deep learning models causes serious concerns as they are extensively used for various life-critical applications. Hence, it is of paramount importance to develop interpretable deep learning models. In this paper, we consider the problem of blind deconvolution and propose a novel model-aware deep architecture that allows for the recovery of both the blur kernel and the sharp image from the blurred image. In particular, we propose the Deep Unfolded Richardson-Lucy (Deep-URL) framework -- an interpretable deep-learning architecture that can be seen as an amalgamation of classical estimation technique and deep neural network, and consequently leads to improved performance. Our numerical investigations demonstrate significant improvement compared to state-of-the-art algorithms.
Automated Management of Pothole related Disasters Using Image Processing and Geotagging
Jan 08, 2016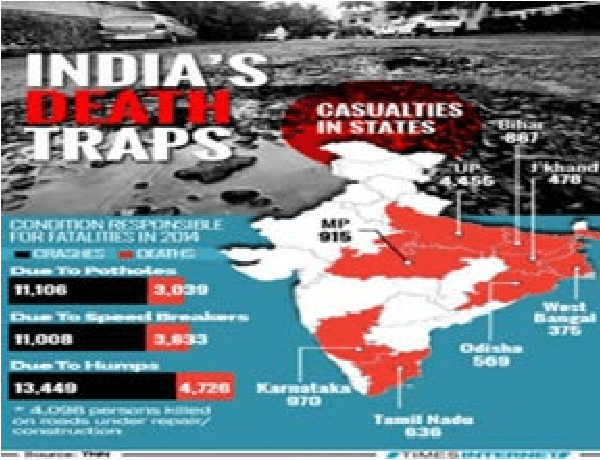
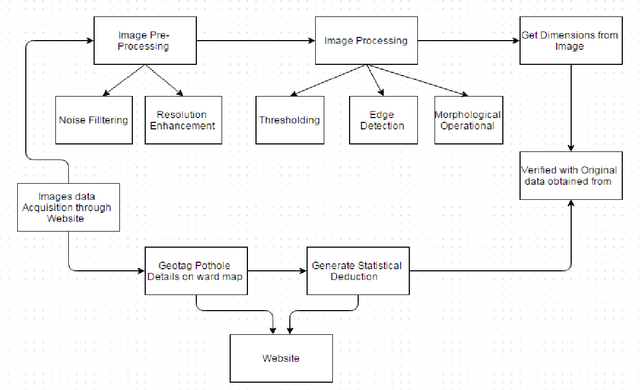
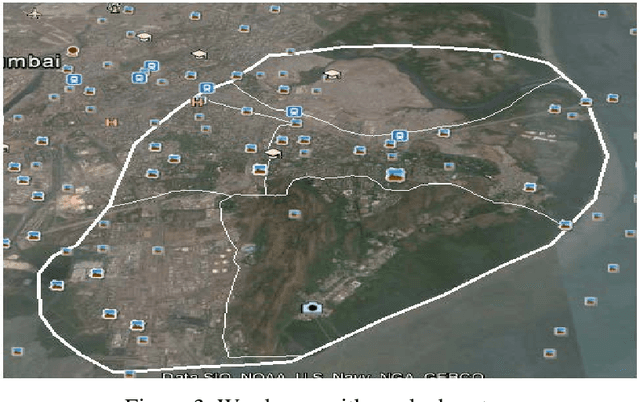
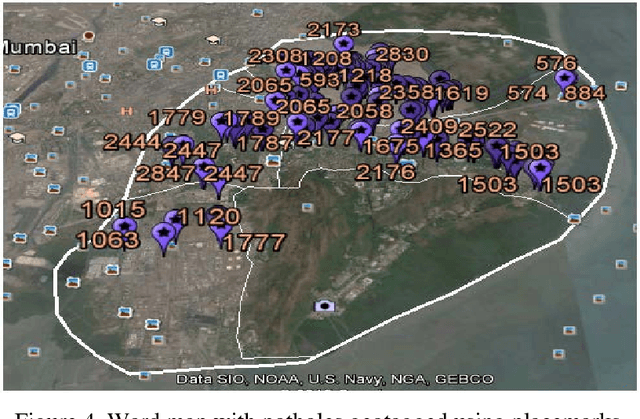
Potholes though seem inconsequential, may cause accidents resulting in loss of human life. In this paper, we present an automated system to efficiently manage the potholes in a ward by deploying geotagging and image processing techniques that overcomes the drawbacks associated with the existing survey-oriented systems. Image processing is used for identification of target pothole regions in the 2D images using edge detection and morphological image processing operations. A method is developed to accurately estimate the dimensions of the potholes from their images, analyze their area and depth, estimate the quantity of filling material required and therefore enabling pothole attendance on a priority basis. This will further enable the government official to have a fully automated system for effectively managing pothole related disasters.