 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated Identification of Thoracic Pathology from Chest Radiographs with Enhanced Training Pipeline
Jun 11, 2020
Chest x-rays are the most common radiology studies for diagnosing lung and heart disease. Hence, a system for automated pre-reporting of pathologic findings on chest x-rays would greatly enhance radiologists' productivity. To this end, we investigate a deep-learning framework with novel training schemes for classification of different thoracic pathology labels from chest x-rays. We use the currently largest publicly available annotated dataset ChestX-ray14 of 112,120 chest radiographs of 30,805 patients. Each image was annotated with either a 'NoFinding' class, or one or more of 14 thoracic pathology labels. Subjects can have multiple pathologies, resulting in a multi-class, multi-label problem. We encoded labels as binary vectors using k-hot encoding. We study the ResNet34 architecture, pre-trained on ImageNet, where two key modifications were incorporated into the training framework: (1) Stochastic gradient descent with momentum and with restarts using cosine annealing, (2) Variable image sizes for fine-tuning to prevent overfitting. Additionally, we use a heuristic algorithm to select a good learning rate. Learning with restarts was used to avoid local minima. Area Under receiver operating characteristics Curve (AUC) was used to quantitatively evaluate diagnostic quality. Our results are comparable to, or outperform the best results of current state-of-the-art methods with AUCs as follows: Atelectasis:0.81, Cardiomegaly:0.91, Consolidation:0.81, Edema:0.92, Effusion:0.89, Emphysema: 0.92, Fibrosis:0.81, Hernia:0.84, Infiltration:0.73, Mass:0.85, Nodule:0.76, Pleural Thickening:0.81, Pneumonia:0.77, Pneumothorax:0.89 and NoFinding:0.79. Our results suggest that, in addition to using sophisticated network architectures, a good learning rate, scheduler and a robust optimizer can boost performance.
* 6 pages, 1 figure, 2 tables
RNN Fisher Vectors for Action Recognition and Image Annotation
Dec 12, 2015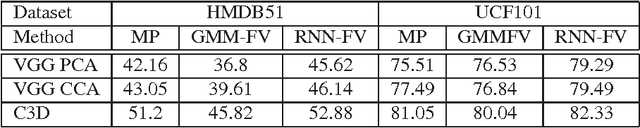
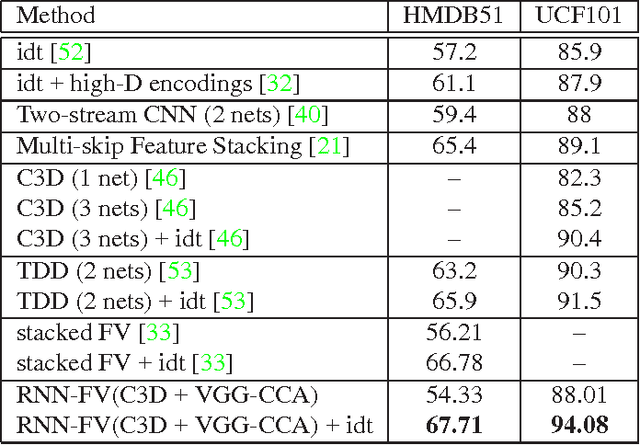
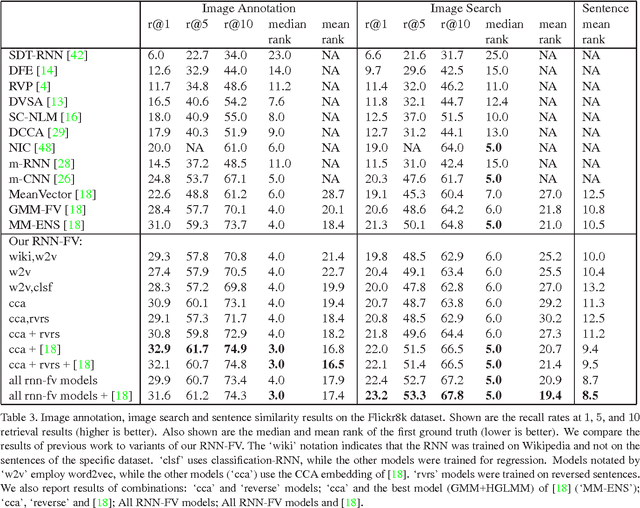
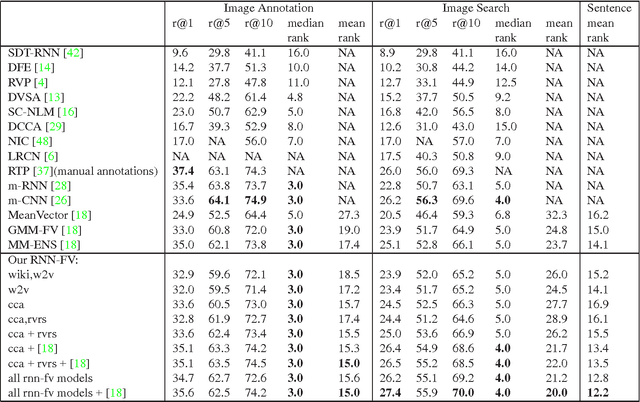
Recurrent Neural Networks (RNNs) have had considerable success in classifying and predicting sequences. We demonstrate that RNNs can be effectively used in order to encode sequences and provide effective representations. The methodology we use is based on Fisher Vectors, where the RNNs are the generative probabilistic models and the partial derivatives are computed using backpropagation. State of the art results are obtained in two central but distant tasks, which both rely on sequences: video action recognition and image annotation. We also show a surprising transfer learning result from the task of image annotation to the task of video action recognition.
Coarse-to-Fine Pseudo-Labeling Guided Meta-Learning for Inexactly-Supervised Few-Shot Classification
Jul 11, 2020
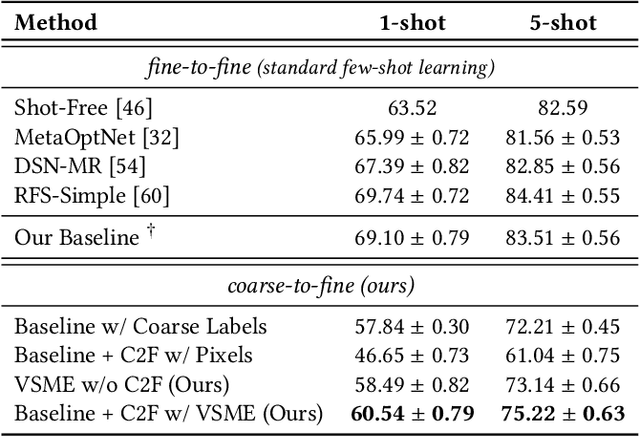
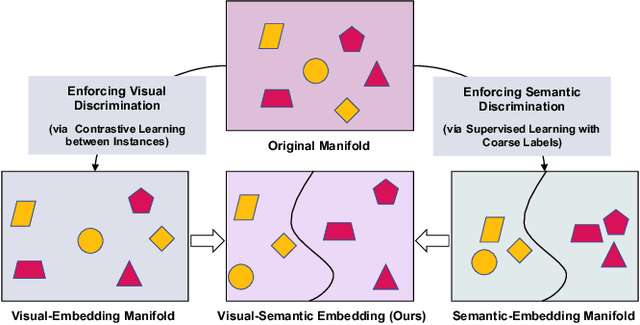
Meta-learning has recently emerged as a promising technique to address the challenge of few-shot learning. However, most existing meta-learning algorithms require fine-grained supervision, thereby involving prohibitive annotation cost. In this paper, we present a new problem named inexactly-supervised meta-learning to alleviate such limitation, focusing on tackling few-shot classification tasks with only coarse-grained supervision. Accordingly, we propose a Coarse-to-Fine (C2F) pseudo-labeling process to construct pseudo-tasks from coarsely-labeled data by grouping each coarse-class into pseudo-fine-classes via similarity matching. Moreover, we develop a Bi-level Discriminative Embedding (BDE) to obtain a good image similarity measure in both visual and semantic aspects with inexact supervision. Experiments across representative benchmarks indicate that our approach shows profound advantages over baseline models.
Camera-Based Adaptive Trajectory Guidance via Neural Networks
Jan 09, 2020

In this paper, we introduce a novel method to capture visual trajectories for navigating an indoor robot in dynamic settings using streaming image data. First, an image processing pipeline is proposed to accurately segment trajectories from noisy backgrounds. Next, the captured trajectories are used to design, train, and compare two neural network architectures for predicting acceleration and steering commands for a line following robot over a continuous space in real time. Lastly, experimental results demonstrate the performance of the neural networks versus human teleoperation of the robot and the viability of the system in environments with occlusions and/or low-light conditions.
Flood severity mapping from Volunteered Geographic Information by interpreting water level from images containing people: a case study of Hurricane Harvey
Jun 21, 2020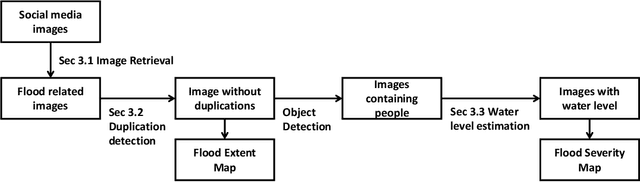

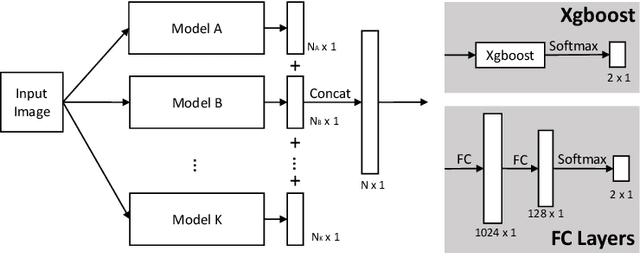
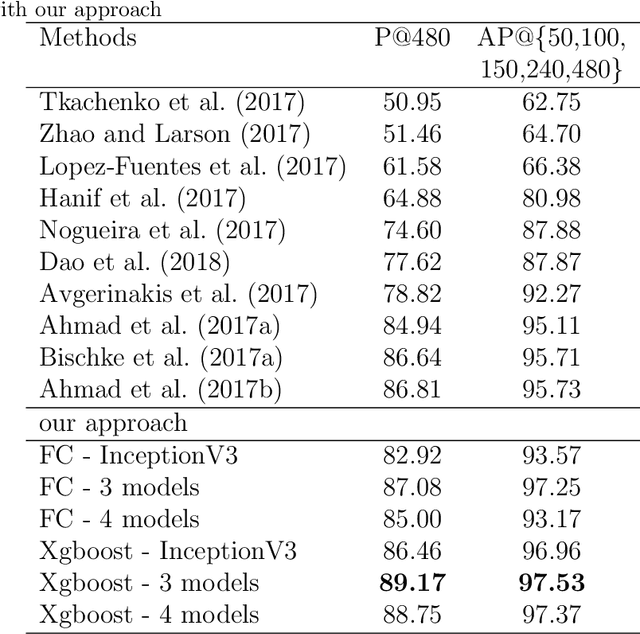
With increasing urbanization, in recent years there has been a growing interest and need in monitoring and analyzing urban flood events. Social media, as a new data source, can provide real-time information for flood monitoring. The social media posts with locations are often referred to as Volunteered Geographic Information (VGI), which can reveal the spatial pattern of such events. Since more images are shared on social media than ever before, recent research focused on the extraction of flood-related posts by analyzing images in addition to texts. Apart from merely classifying posts as flood relevant or not, more detailed information, e.g. the flood severity, can also be extracted based on image interpretation. However, it has been less tackled and has not yet been applied for flood severity mapping. In this paper, we propose a novel three-step pipeline method to extract and map flood severity information. First, flood relevant images are retrieved with the help of pre-trained convolutional neural networks as feature extractors. Second, the images containing people are further classified into four severity levels by observing the relationship between body parts and their partial inundation, i.e. images are classified according to the water level with respect to different body parts, namely ankle, knee, hip, and chest. Lastly, locations of the Tweets are used for generating a map of estimated flood extent and severity. This pipeline was applied to an image dataset collected during Hurricane Harvey in 2017, as a proof of concept. The results show that VGI can be used as a supplement to remote sensing observations for flood extent mapping and is beneficial, especially for urban areas, where the infrastructure is often occluding water. Based on the extracted water level information, an integrated overview of flood severity can be provided for the early stages of emergency response.
LiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation
Dec 13, 2019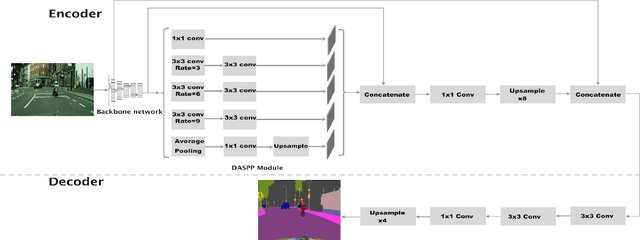



Semantic image segmentation plays a pivotal role in many vision applications including autonomous driving and medical image analysis. Most of the former approaches move towards enhancing the performance in terms of accuracy with a little awareness of computational efficiency. In this paper, we introduce LiteSeg, a lightweight architecture for semantic image segmentation. In this work, we explore a new deeper version of Atrous Spatial Pyramid Pooling module (ASPP) and apply short and long residual connections, and depthwise separable convolution, resulting in a faster and efficient model. LiteSeg architecture is introduced and tested with multiple backbone networks as Darknet19, MobileNet, and ShuffleNet to provide multiple trade-offs between accuracy and computational cost. The proposed model LiteSeg, with MobileNetV2 as a backbone network, achieves an accuracy of 67.81% mean intersection over union at 161 frames per second with $640 \times 360$ resolution on the Cityscapes dataset.
Automatic elimination of the pectoral muscle in mammograms based on anatomical features
Aug 17, 2020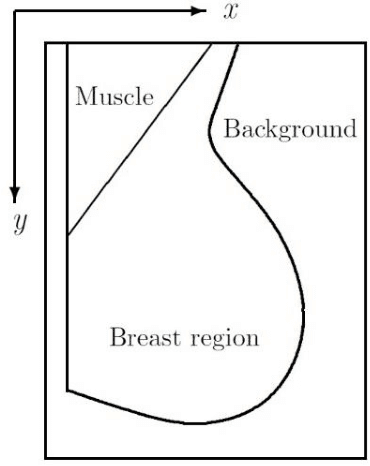
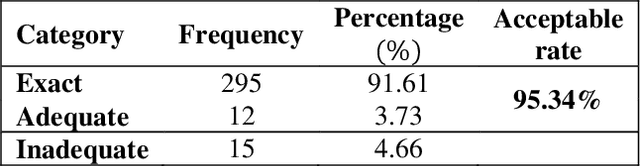
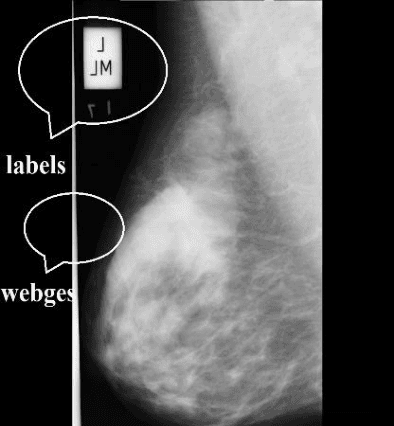
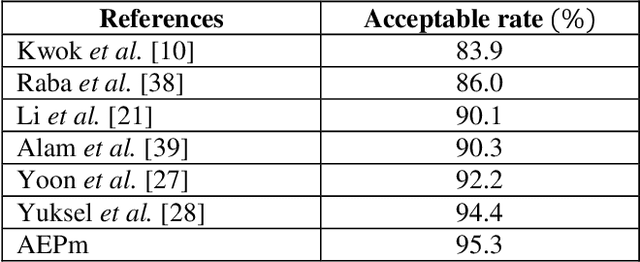
Digital mammogram inspection is the most popular technique for early detection of abnormalities in human breast tissue. When mammograms are analyzed through a computational method, the presence of the pectoral muscle might affect the results of breast lesions detection. This problem is particularly evident in the mediolateral oblique view (MLO), where pectoral muscle occupies a large part of the mammography. Therefore, identifying and eliminating the pectoral muscle are essential steps for improving the automatic discrimination of breast tissue. In this paper, we propose an approach based on anatomical features to tackle this problem. Our method consists of two steps: (1) a process to remove the noisy elements such as labels, markers, scratches and wedges, and (2) application of an intensity transformation based on the Beta distribution. The novel methodology is tested with 322 digital mammograms from the Mammographic Image Analysis Society (mini-MIAS) database and with a set of 84 mammograms for which the area normalized error was previously calculated. The results show a very good performance of the method.
Rethinking the Route Towards Weakly Supervised Object Localization
Feb 26, 2020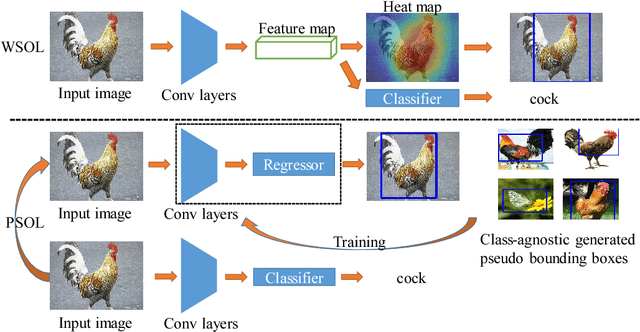
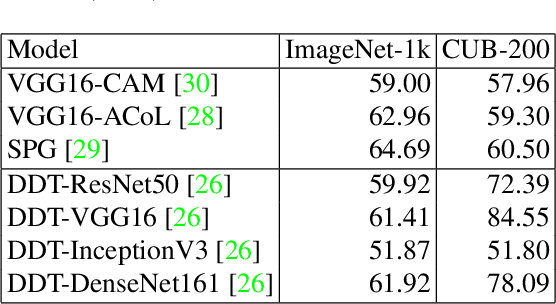
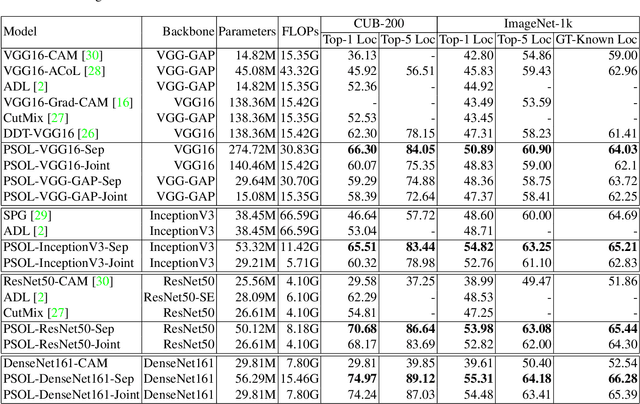
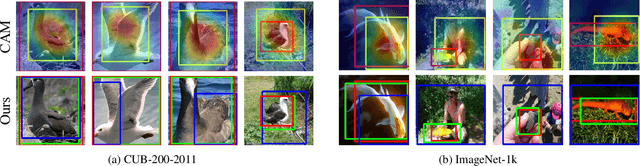
Weakly supervised object localization (WSOL) aims to localize objects with only image-level labels. Previous methods often try to utilize feature maps and classification weights to localize objects using image level annotations indirectly. In this paper, we demonstrate that weakly supervised object localization should be divided into two parts: class-agnostic object localization and object classification. For class-agnostic object localization, we should use class-agnostic methods to generate noisy pseudo annotations and then perform bounding box regression on them without class labels. We propose the pseudo supervised object localization (PSOL) method as a new way to solve WSOL. Our PSOL models have good transferability across different datasets without fine-tuning. With generated pseudo bounding boxes, we achieve 58.00% localization accuracy on ImageNet and 74.74% localization accuracy on CUB-200, which have a large edge over previous models.
TENet: Triple Excitation Network for Video Salient Object Detection
Aug 30, 2020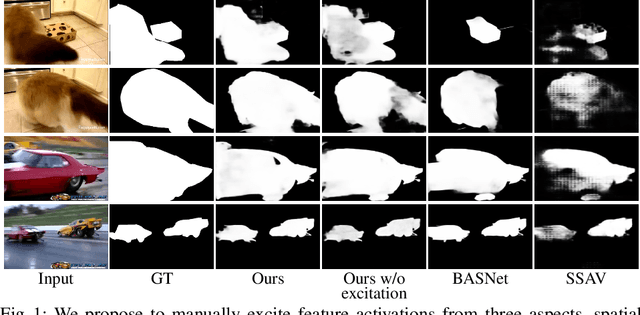
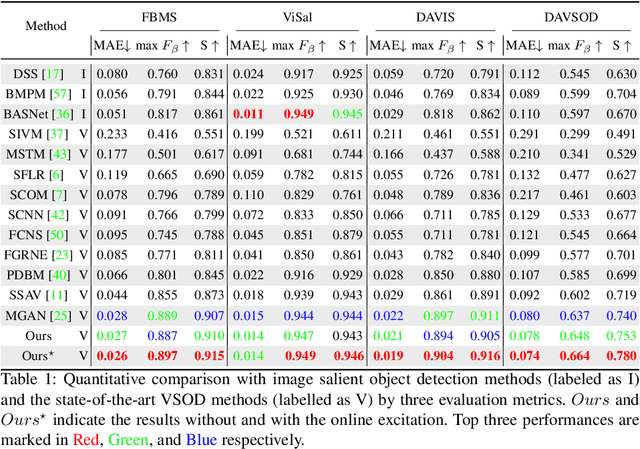
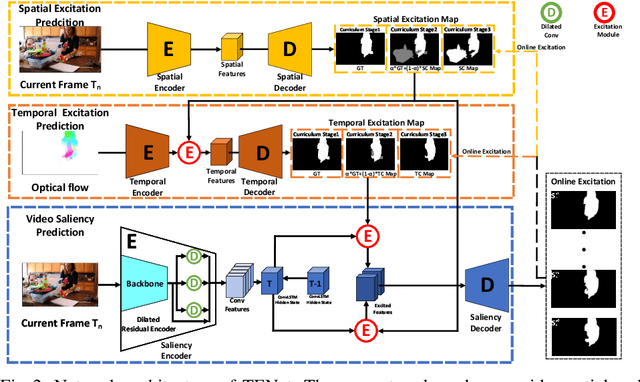
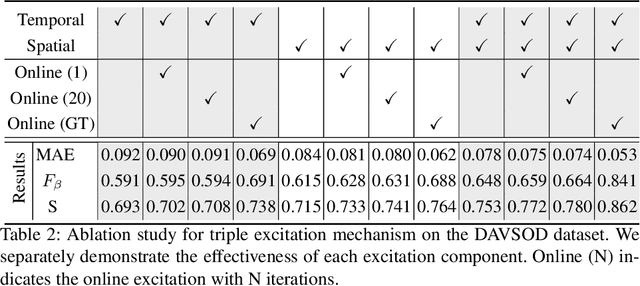
In this paper, we propose a simple yet effective approach, named Triple Excitation Network, to reinforce the training of video salient object detection (VSOD) from three aspects, spatial, temporal, and online excitations. These excitation mechanisms are designed following the spirit of curriculum learning and aim to reduce learning ambiguities at the beginning of training by selectively exciting feature activations using ground truth. Then we gradually reduce the weight of ground truth excitations by a curriculum rate and replace it by a curriculum complementary map for better and faster convergence. In particular, the spatial excitation strengthens feature activations for clear object boundaries, while the temporal excitation imposes motions to emphasize spatio-temporal salient regions. Spatial and temporal excitations can combat the saliency shifting problem and conflict between spatial and temporal features of VSOD. Furthermore, our semi-curriculum learning design enables the first online refinement strategy for VSOD, which allows exciting and boosting saliency responses during testing without re-training. The proposed triple excitations can easily plug in different VSOD methods. Extensive experiments show the effectiveness of all three excitation methods and the proposed method outperforms state-of-the-art image and video salient object detection methods.
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
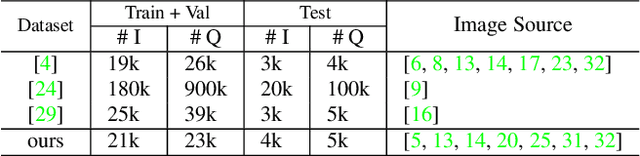

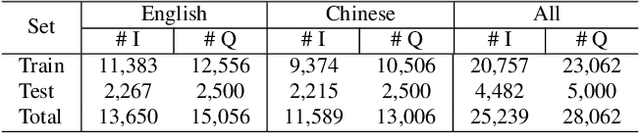
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.