 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation
Dec 13, 2019
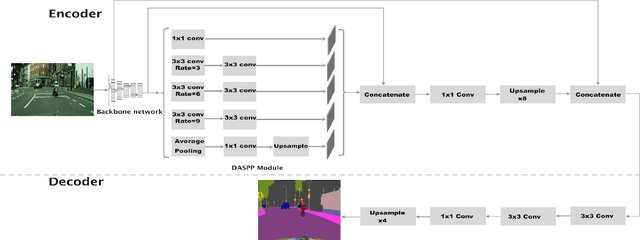



Semantic image segmentation plays a pivotal role in many vision applications including autonomous driving and medical image analysis. Most of the former approaches move towards enhancing the performance in terms of accuracy with a little awareness of computational efficiency. In this paper, we introduce LiteSeg, a lightweight architecture for semantic image segmentation. In this work, we explore a new deeper version of Atrous Spatial Pyramid Pooling module (ASPP) and apply short and long residual connections, and depthwise separable convolution, resulting in a faster and efficient model. LiteSeg architecture is introduced and tested with multiple backbone networks as Darknet19, MobileNet, and ShuffleNet to provide multiple trade-offs between accuracy and computational cost. The proposed model LiteSeg, with MobileNetV2 as a backbone network, achieves an accuracy of 67.81% mean intersection over union at 161 frames per second with $640 \times 360$ resolution on the Cityscapes dataset.
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 05, 2020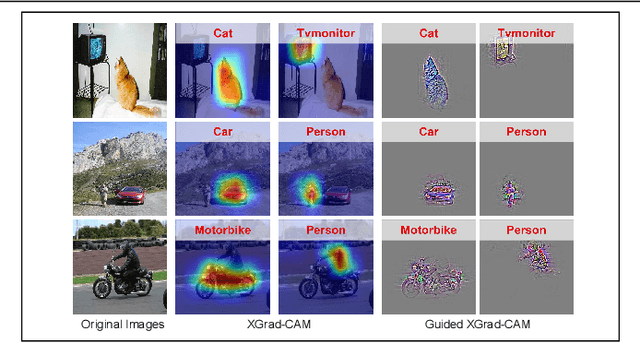
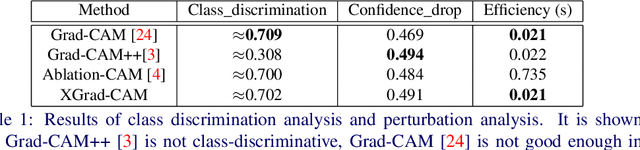
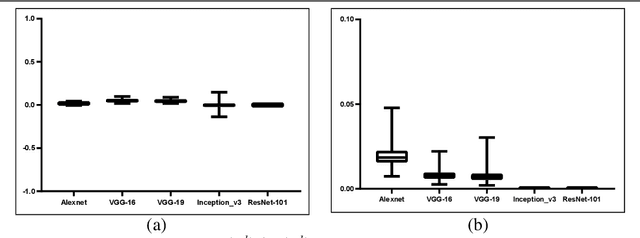
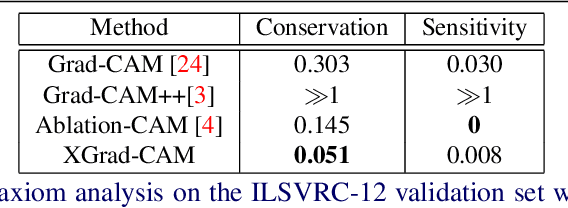
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.
Camera-Based Adaptive Trajectory Guidance via Neural Networks
Jan 09, 2020

In this paper, we introduce a novel method to capture visual trajectories for navigating an indoor robot in dynamic settings using streaming image data. First, an image processing pipeline is proposed to accurately segment trajectories from noisy backgrounds. Next, the captured trajectories are used to design, train, and compare two neural network architectures for predicting acceleration and steering commands for a line following robot over a continuous space in real time. Lastly, experimental results demonstrate the performance of the neural networks versus human teleoperation of the robot and the viability of the system in environments with occlusions and/or low-light conditions.
A Hybrid Differential Evolution Approach to Designing Deep Convolutional Neural Networks for Image Classification
Aug 22, 2018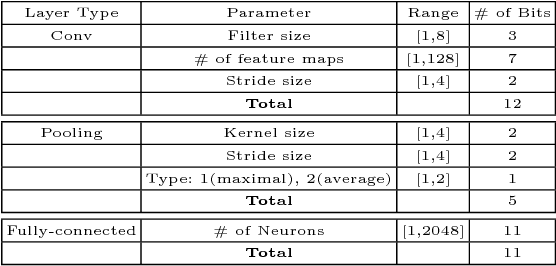
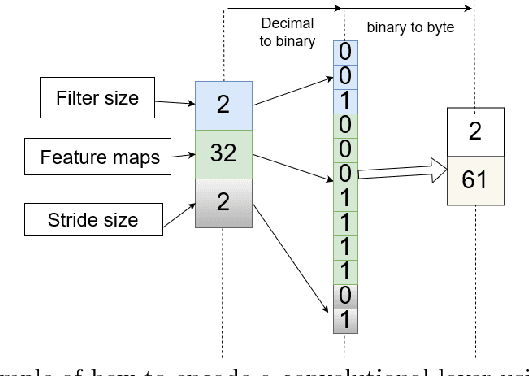
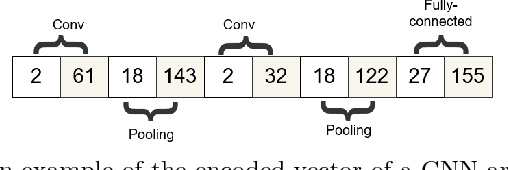
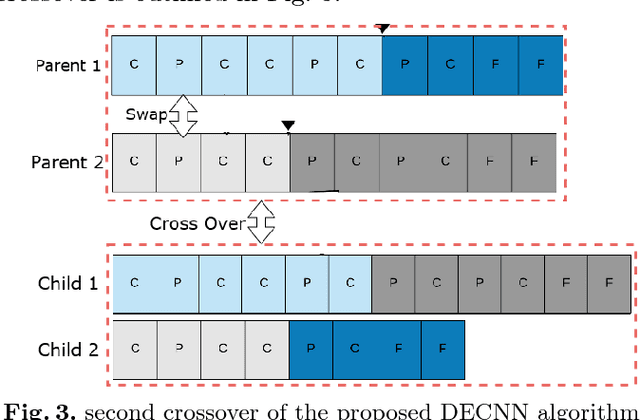
Convolutional Neural Networks (CNNs) have demonstrated their superiority in image classification, and evolutionary computation (EC) methods have recently been surging to automatically design the architectures of CNNs to save the tedious work of manually designing CNNs. In this paper, a new hybrid differential evolution (DE) algorithm with a newly added crossover operator is proposed to evolve the architectures of CNNs of any lengths, which is named DECNN. There are three new ideas in the proposed DECNN method. Firstly, an existing effective encoding scheme is refined to cater for variable-length CNN architectures; Secondly, the new mutation and crossover operators are developed for variable-length DE to optimise the hyperparameters of CNNs; Finally, the new second crossover is introduced to evolve the depth of the CNN architectures. The proposed algorithm is tested on six widely-used benchmark datasets and the results are compared to 12 state-of-the-art methods, which shows the proposed method is vigorously competitive to the state-of-the-art algorithms. Furthermore, the proposed method is also compared with a method using particle swarm optimisation with a similar encoding strategy named IPPSO, and the proposed DECNN outperforms IPPSO in terms of the accuracy.
Bootstrapping Disjoint Datasets for Multilingual Multimodal Representation Learning
Nov 09, 2019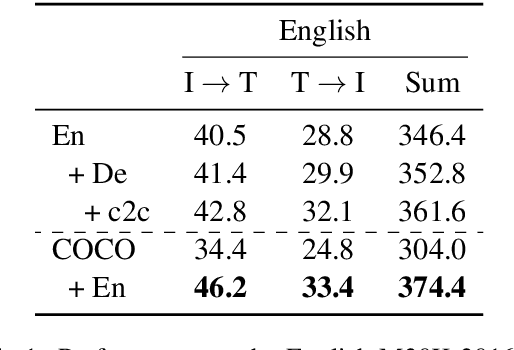

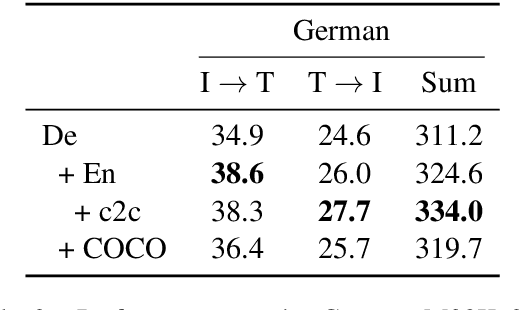

Recent work has highlighted the advantage of jointly learning grounded sentence representations from multiple languages. However, the data used in these studies has been limited to an aligned scenario: the same images annotated with sentences in multiple languages. We focus on the more realistic disjoint scenario in which there is no overlap between the images in multilingual image--caption datasets. We confirm that training with aligned data results in better grounded sentence representations than training with disjoint data, as measured by image--sentence retrieval performance. In order to close this gap in performance, we propose a pseudopairing method to generate synthetically aligned English--German--image triplets from the disjoint sets. The method works by first training a model on the disjoint data, and then creating new triples across datasets using sentence similarity under the learned model. Experiments show that pseudopairs improve image--sentence retrieval performance compared to disjoint training, despite requiring no external data or models. However, we do find that using an external machine translation model to generate the synthetic data sets results in better performance.
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Aug 19, 2020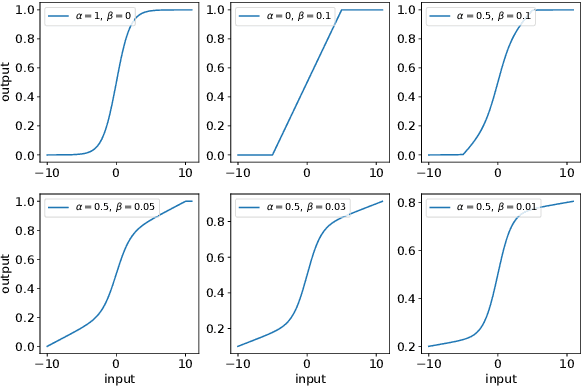
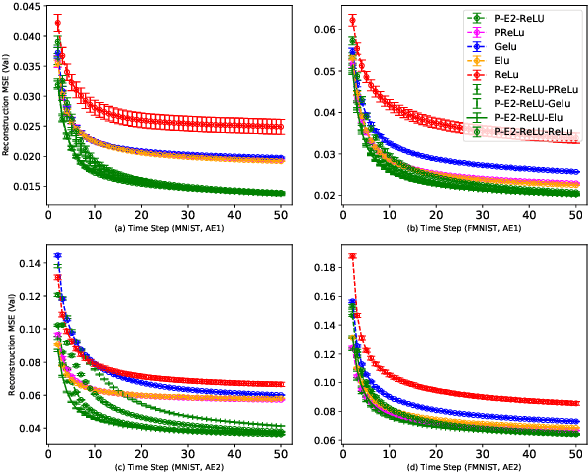
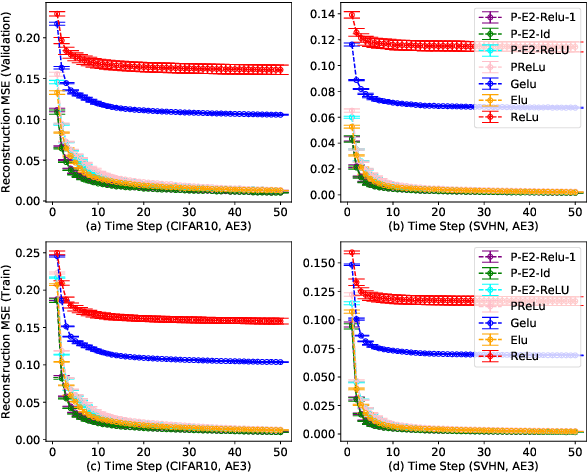
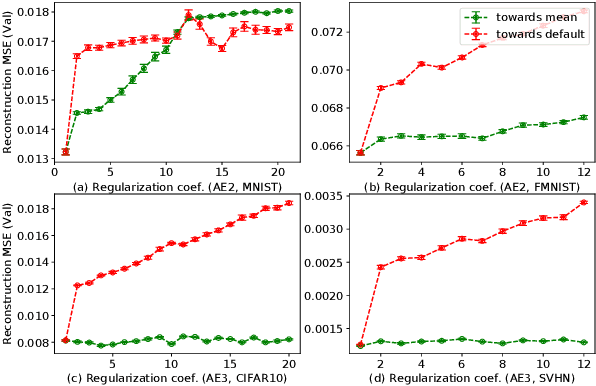
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. In this study, three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions.
Perceiving Humans: from Monocular 3D Localization to Social Distancing
Sep 01, 2020
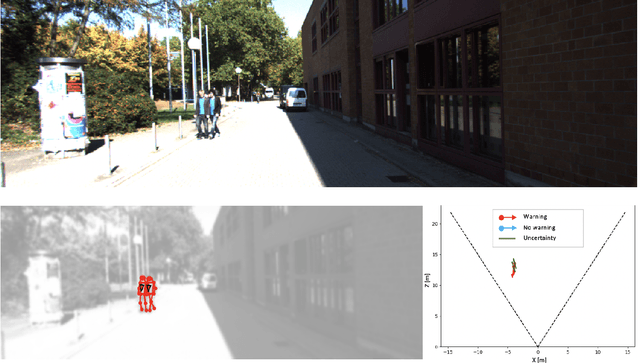
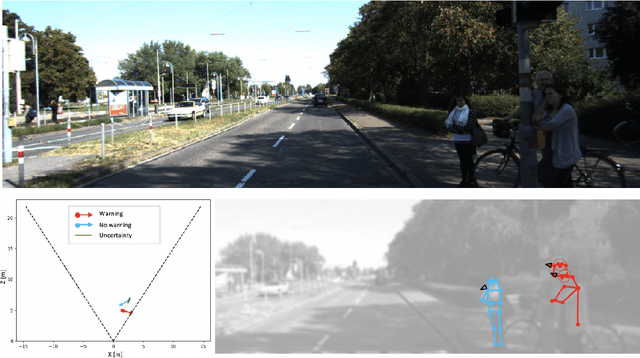
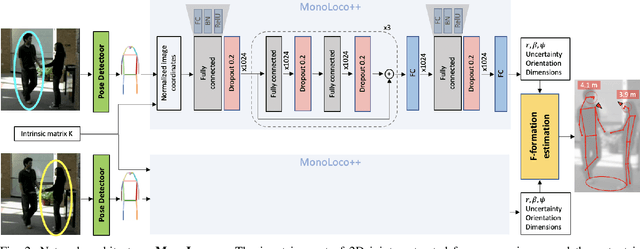
Perceiving humans in the context of Intelligent Transportation Systems (ITS) often relies on multiple cameras or expensive LiDAR sensors. In this work, we present a new cost-effective vision-based method that perceives humans' locations in 3D and their body orientation from a single image. We address the challenges related to the ill-posed monocular 3D tasks by proposing a deep learning method that predicts confidence intervals in contrast to point estimates. Our neural network architecture estimates humans 3D body locations and their orientation with a measure of uncertainty. Our vision-based system (i) is privacy-safe, (ii) works with any fixed or moving cameras, and (iii) does not rely on ground plane estimation. We demonstrate the performance of our method with respect to three applications: locating humans in 3D, detecting social interactions, and verifying the compliance of recent safety measures due to the COVID-19 outbreak. Indeed, we show that we can rethink the concept of "social distancing" as a form of social interaction in contrast to a simple location-based rule. We publicly share the source code towards an open science mission.
Graudally Applying Weakly Supervised and Active Learning for Mass Detection in Breast Ultrasound Images
Aug 19, 2020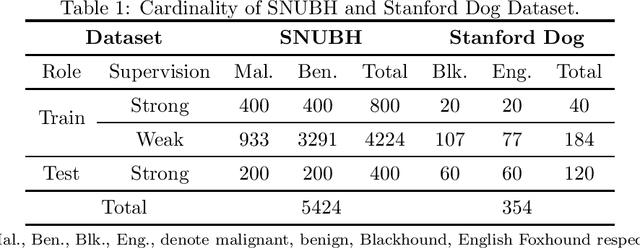
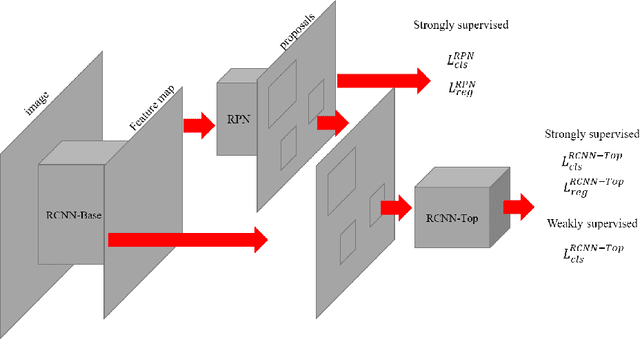
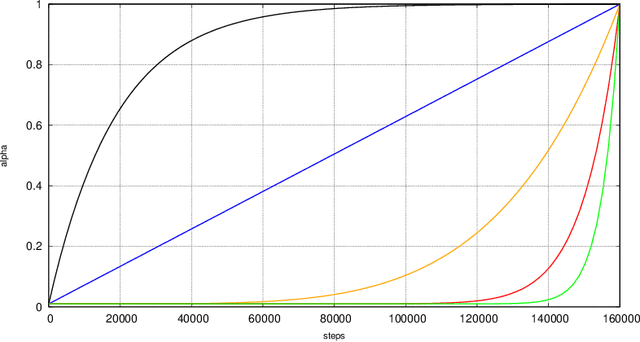
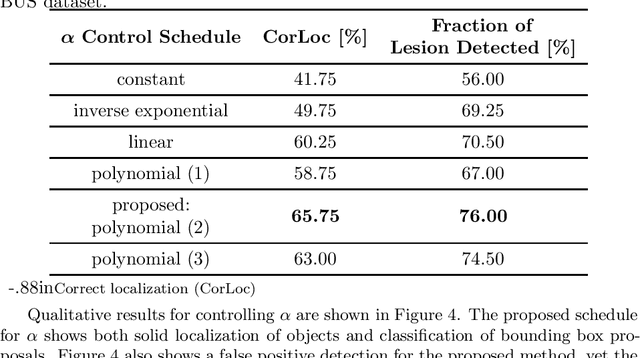
We propose a method for effectively utilizing weakly annotated image data in an object detection tasks of breast ultrasound images. Given the problem setting where a small, strongly annotated dataset and a large, weakly annotated dataset with no bounding box information are available, training an object detection model becomes a non-trivial problem. We suggest a controlled weight for handling the effect of weakly annotated images in a two stage object detection model. We~also present a subsequent active learning scheme for safely assigning weakly annotated images a strong annotation using the trained model. Experimental results showed a 24\% point increase in correct localization (CorLoc) measure, which is the ratio of correctly localized and classified images, by assigning the properly controlled weight. Performing active learning after a model is trained showed an additional increase in CorLoc. We tested the proposed method on the Stanford Dog datasets to assure that it can be applied to general cases, where strong annotations are insufficient to obtain resembling results. The presented method showed that higher performance is achievable with lesser annotation effort.
Improving Blind Spot Denoising for Microscopy
Aug 19, 2020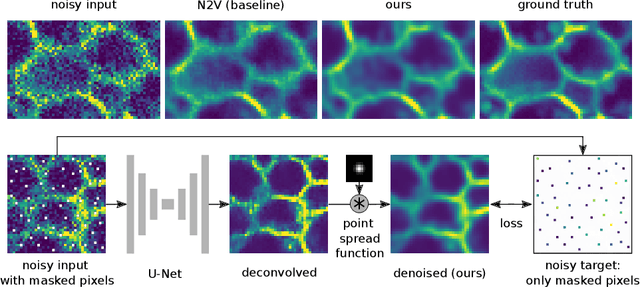
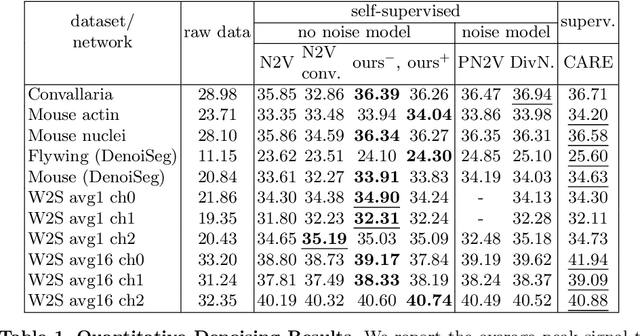
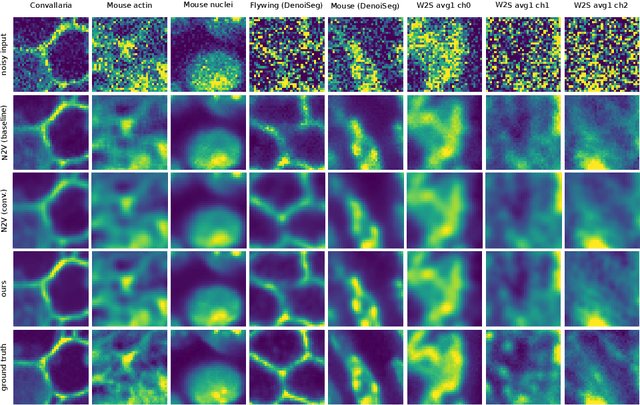
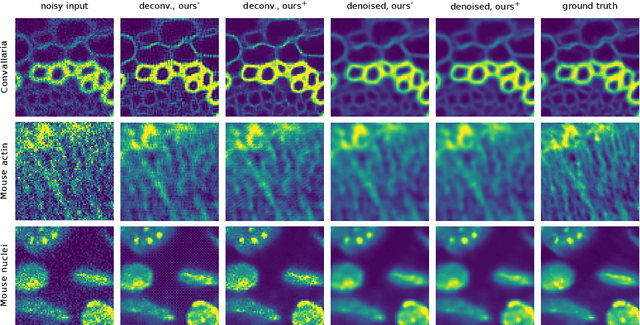
Many microscopy applications are limited by the total amount of usable light and are consequently challenged by the resulting levels of noise in the acquired images. This problem is often addressed via (supervised) deep learning based denoising. Recently, by making assumptions about the noise statistics, self-supervised methods have emerged. Such methods are trained directly on the images that are to be denoised and do not require additional paired training data. While achieving remarkable results, self-supervised methods can produce high-frequency artifacts and achieve inferior results compared to supervised approaches. Here we present a novel way to improve the quality of self-supervised denoising. Considering that light microscopy images are usually diffraction-limited, we propose to include this knowledge in the denoising process. We assume the clean image to be the result of a convolution with a point spread function (PSF) and explicitly include this operation at the end of our neural network. As a consequence, we are able to eliminate high-frequency artifacts and achieve self-supervised results that are very close to the ones achieved with traditional supervised methods.
Quantification of MagLIF morphology using the Mallat Scattering Transformation
Apr 13, 2020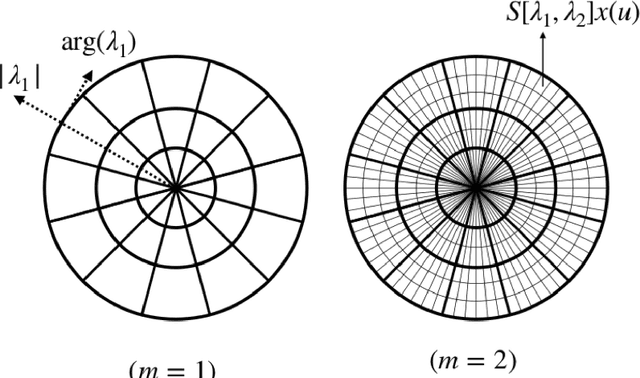
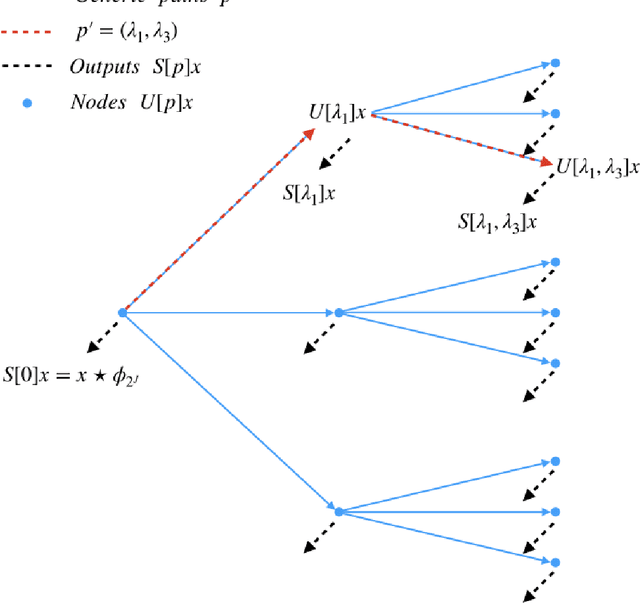
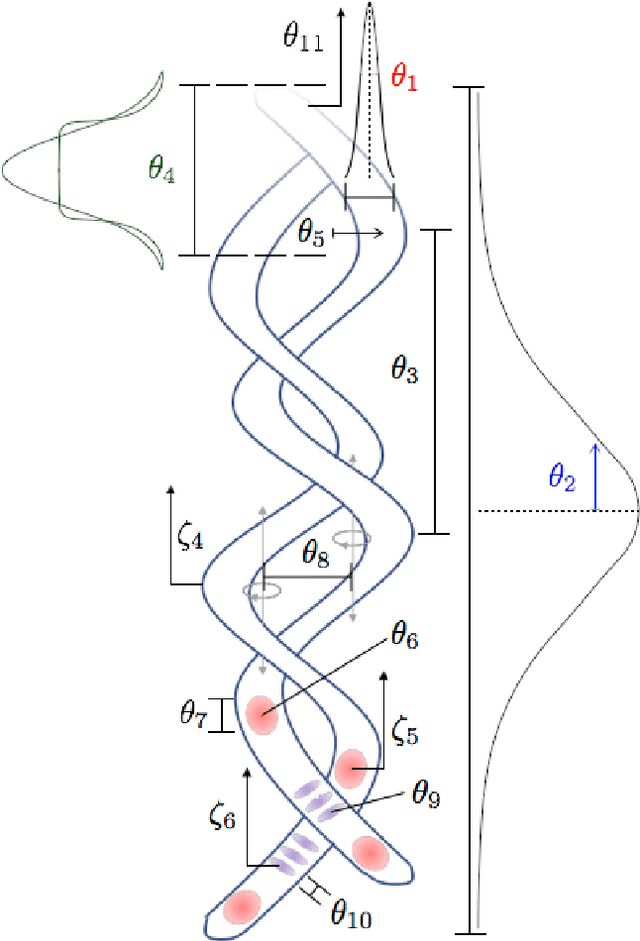
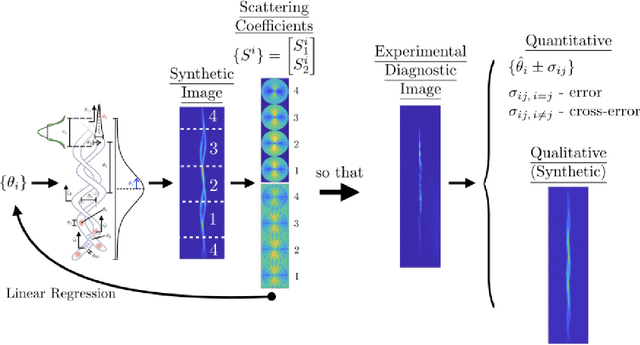
The morphology of the stagnated plasma resulting from Magnetized Liner Inertial Fusion (MagLIF) is measured by imaging the self-emission x-rays coming from the multi-keV plasma. Equivalent diagnostic response can be generated by integrated radiation-magnetohydrodynamic (rad-MHD) simulations from programs such as HYDRA and GORGON. There have been only limited quantitative ways to compare the image morphology, that is the texture, of simulations and experiments. We have developed a metric of image morphology based on the Mallat Scattering Transformation (MST), a transformation that has proved to be effective at distinguishing textures, sounds, and written characters. This metric is designed, demonstrated, and refined by classifying ensembles (i.e., classes) of synthetic stagnation images, and by regressing an ensemble of synthetic stagnation images to the morphology (i.e., model) parameters used to generate the synthetic images. We use this metric to quantitatively compare simulations to experimental images, experimental images to each other, and to estimate the morphological parameters of the experimental images with uncertainty. This coordinate space has proved very adept at doing a sophisticated relative background subtraction in the MST space. This was needed to compare the experimental self emission images to the rad-MHD simulation images.