 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Learning on Graphs: Deep Insights and New Direction
Jun 17, 2020
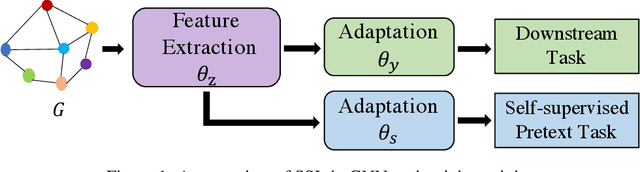

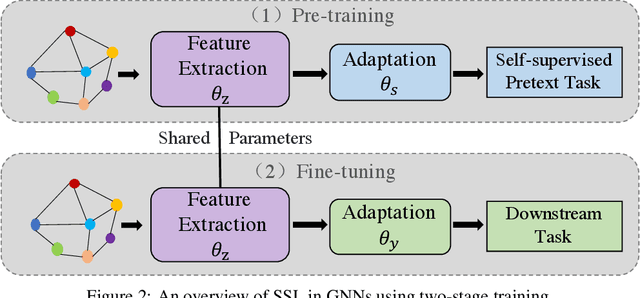
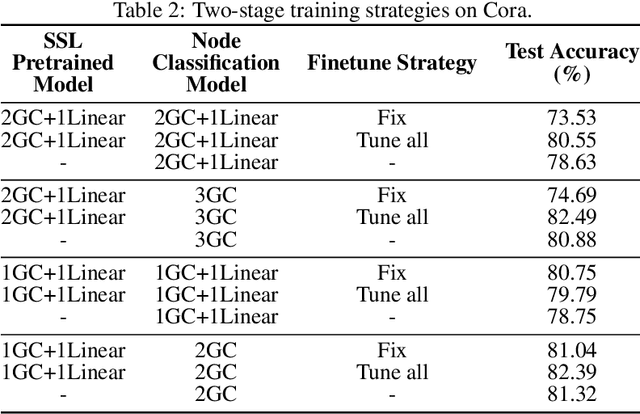
The success of deep learning notoriously requires larger amounts of costly annotated data. This has led to the development of self-supervised learning (SSL) that aims to alleviate this limitation by creating domain specific pretext tasks on unlabeled data. Simultaneously, there are increasing interests in generalizing deep learning to the graph domain in the form of graph neural networks (GNNs). GNNs can naturally utilize unlabeled nodes through the simple neighborhood aggregation that is unable to thoroughly make use of unlabeled nodes. Thus, we seek to harness SSL for GNNs to fully exploit the unlabeled data. Different from data instances in the image and text domains, nodes in graphs present unique structure information and they are inherently linked indicating not independent and identically distributed (or i.i.d.). Such complexity is a double-edged sword for SSL on graphs. On the one hand, it determines that it is challenging to adopt solutions from the image and text domains to graphs and dedicated efforts are desired. On the other hand, it provides rich information that enables us to build SSL from a variety of perspectives. Thus, in this paper, we first deepen our understandings on when, why, and which strategies of SSL work with GNNs by empirically studying numerous basic SSL pretext tasks on graphs. Inspired by deep insights from the empirical studies, we propose a new direction SelfTask to build advanced pretext tasks that are able to achieve state-of-the-art performance on various real-world datasets. The specific experimental settings to reproduce our results can be found in \url{https://github.com/ChandlerBang/SelfTask-GNN}.
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
Mar 31, 2020
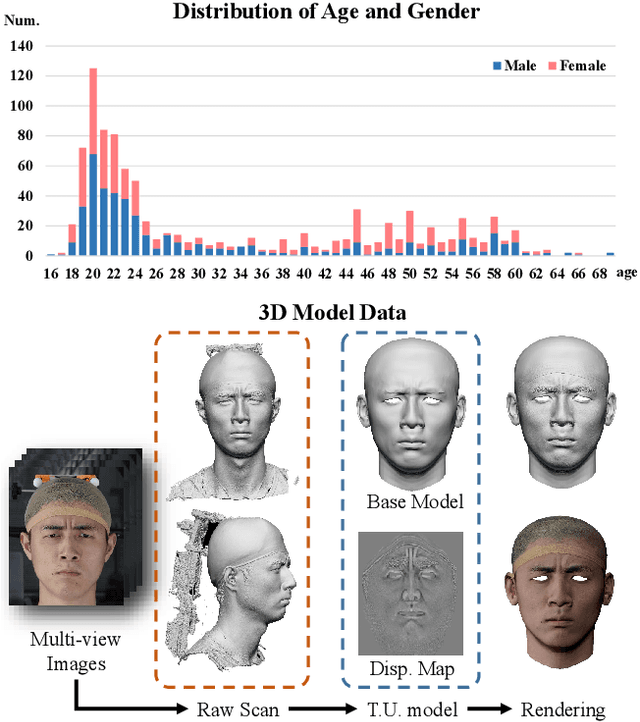
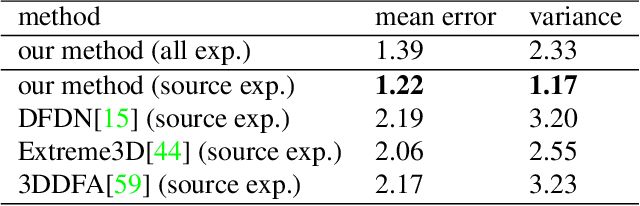
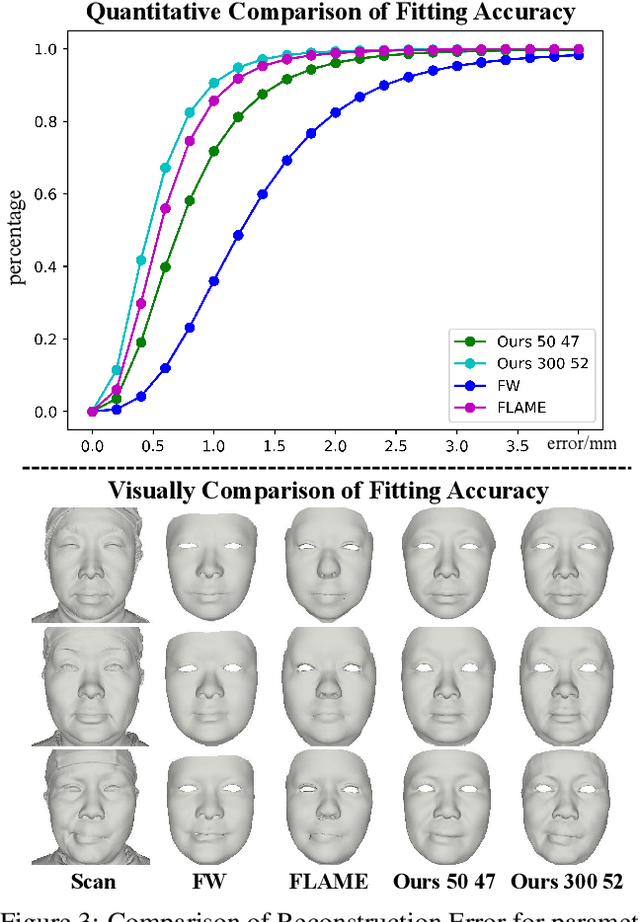
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and propose a novel algorithm that is able to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. The unprecedented dataset and code will be released to public for research purpose.
A Robust Attentional Framework for License Plate Recognition in the Wild
Jun 06, 2020

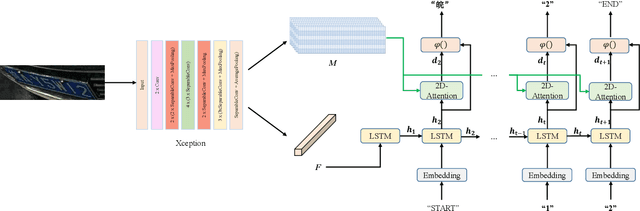
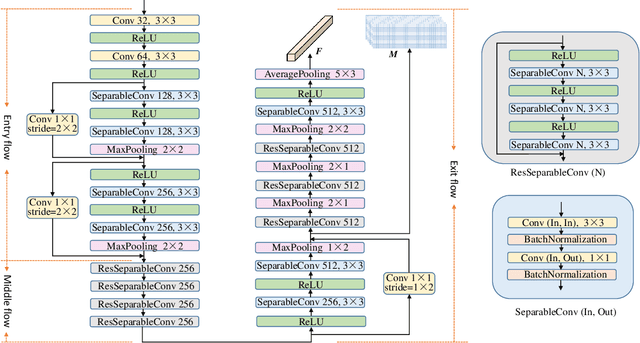
Recognizing car license plates in natural scene images is an important yet still challenging task in realistic applications. Many existing approaches perform well for license plates collected under constrained conditions, eg, shooting in frontal and horizontal view-angles and under good lighting conditions. However, their performance drops significantly in an unconstrained environment that features rotation, distortion, occlusion, blurring, shading or extreme dark or bright conditions. In this work, we propose a robust framework for license plate recognition in the wild. It is composed of a tailored CycleGAN model for license plate image generation and an elaborate designed image-to-sequence network for plate recognition. On one hand, the CycleGAN based plate generation engine alleviates the exhausting human annotation work. Massive amount of training data can be obtained with a more balanced character distribution and various shooting conditions, which helps to boost the recognition accuracy to a large extent. On the other hand, the 2D attentional based license plate recognizer with an Xception-based CNN encoder is capable of recognizing license plates with different patterns under various scenarios accurately and robustly. Without using any heuristics rule or post-processing, our method achieves the state-of-the-art performance on four public datasets, which demonstrates the generality and robustness of our framework. Moreover, we released a new license plate dataset, named "CLPD", with 1200 images from all 31 provinces in mainland China. The dataset can be available from: https://github.com/wangpengnorman/CLPD_dataset.
A non-discriminatory approach to ethical deep learning
Aug 04, 2020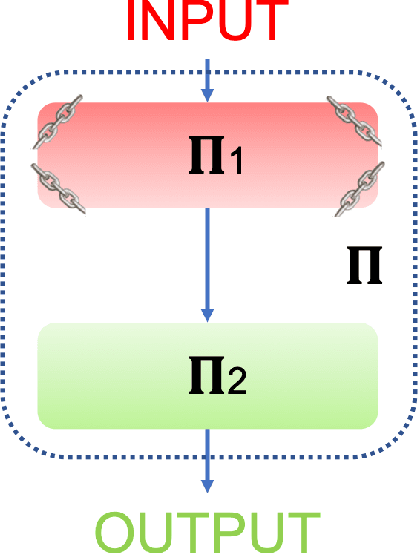
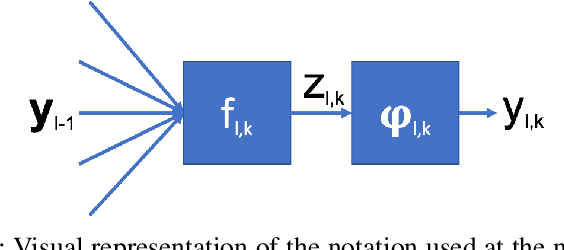
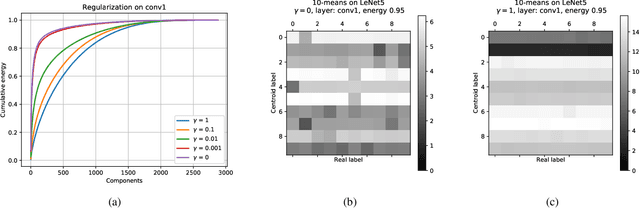
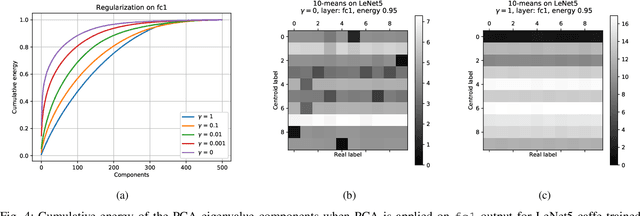
Artificial neural networks perform state-of-the-art in an ever-growing number of tasks, nowadays they are used to solve an incredibly large variety of tasks. However, typical training strategies do not take into account lawful, ethical and discriminatory potential issues the trained ANN models could incur in. In this work we propose NDR, a non-discriminatory regularization strategy to prevent the ANN model to solve the target task using some discriminatory features like, for example, the ethnicity in an image classification task for human faces. In particular, a part of the ANN model is trained to hide the discriminatory information such that the rest of the network focuses in learning the given learning task. Our experiments show that NDR can be exploited to achieve non-discriminatory models with both minimal computational overhead and performance loss.
Sparse Representation-based Image Quality Assessment
Jun 12, 2013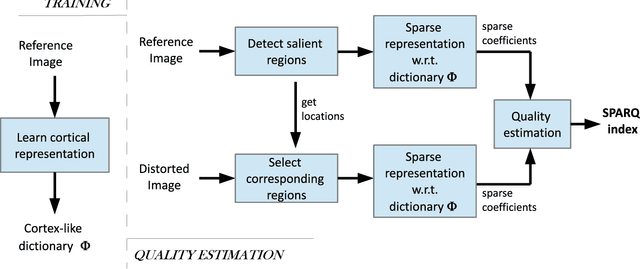

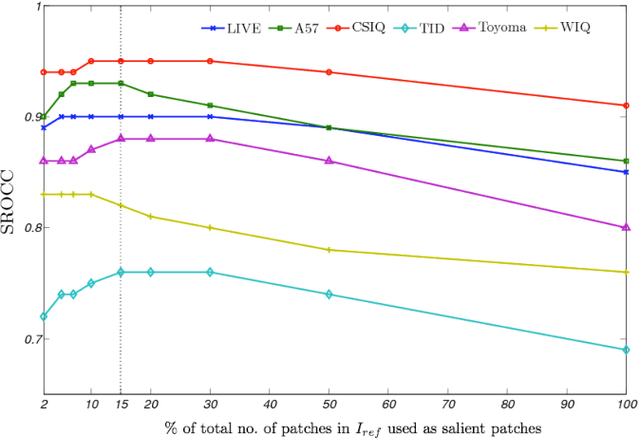
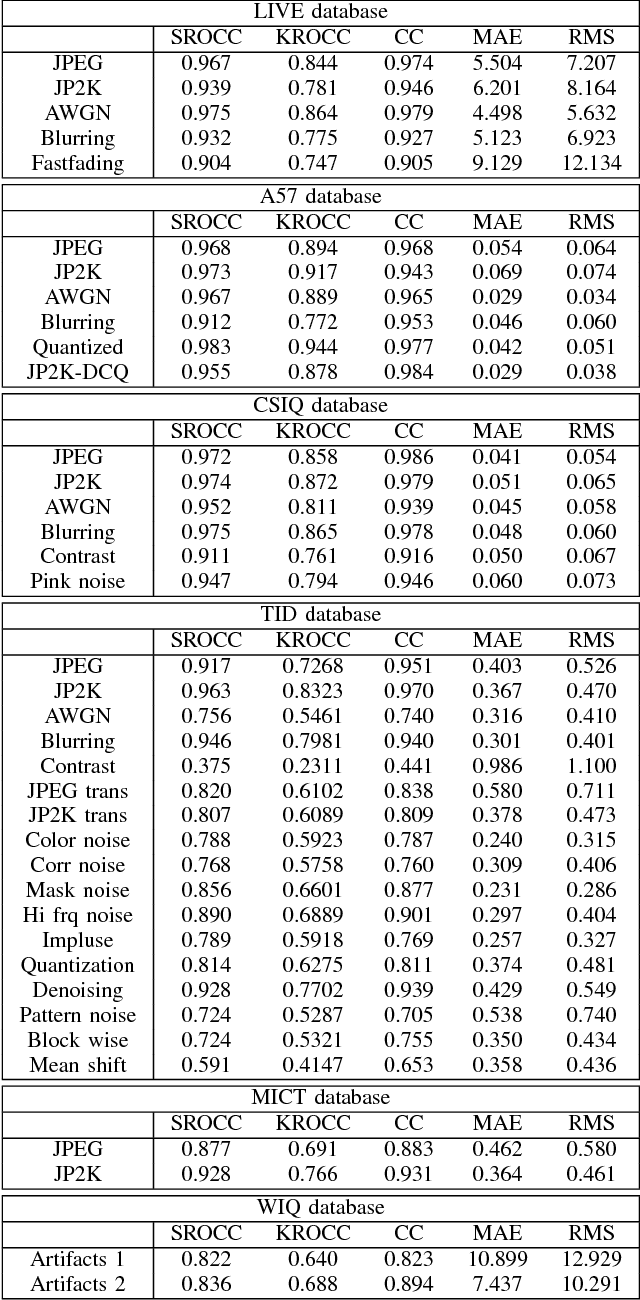
A successful approach to image quality assessment involves comparing the structural information between a distorted and its reference image. However, extracting structural information that is perceptually important to our visual system is a challenging task. This paper addresses this issue by employing a sparse representation-based approach and proposes a new metric called the \emph{sparse representation-based quality} (SPARQ) \emph{index}. The proposed method learns the inherent structures of the reference image as a set of basis vectors, such that any structure in the image can be represented by a linear combination of only a few of those basis vectors. This sparse strategy is employed because it is known to generate basis vectors that are qualitatively similar to the receptive field of the simple cells present in the mammalian primary visual cortex. The visual quality of the distorted image is estimated by comparing the structures of the reference and the distorted images in terms of the learnt basis vectors resembling cortical cells. Our approach is evaluated on six publicly available subject-rated image quality assessment datasets. The proposed SPARQ index consistently exhibits high correlation with the subjective ratings on all datasets and performs better or at par with the state-of-the-art.
Generic Semi-Supervised Adversarial Subject Translation for Sensor-Based Human Activity Recognition
Nov 11, 2020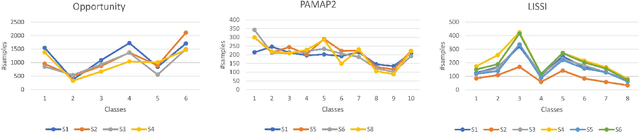
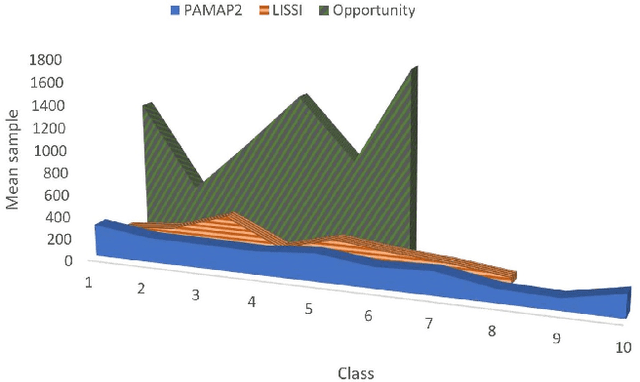
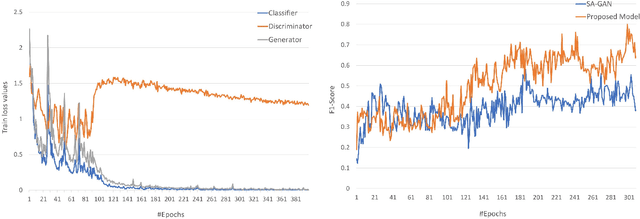
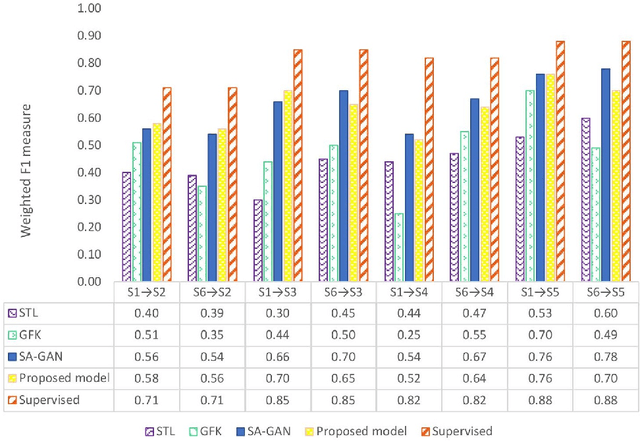
The performance of Human Activity Recognition (HAR) models, particularly deep neural networks, is highly contingent upon the availability of the massive amount of annotated training data which should be sufficiently labeled. Though, data acquisition and manual annotation in the HAR domain are prohibitively expensive due to skilled human resource requirements in both steps. Hence, domain adaptation techniques have been proposed to adapt the knowledge from the existing source of data. More recently, adversarial transfer learning methods have shown very promising results in image classification, yet limited for sensor-based HAR problems, which are still prone to the unfavorable effects of the imbalanced distribution of samples. This paper presents a novel generic and robust approach for semi-supervised domain adaptation in HAR, which capitalizes on the advantages of the adversarial framework to tackle the shortcomings, by leveraging knowledge from annotated samples exclusively from the source subject and unlabeled ones of the target subject. Extensive subject translation experiments are conducted on three large, middle, and small-size datasets with different levels of imbalance to assess the robustness and effectiveness of the proposed model to the scale as well as imbalance in the data. The results demonstrate the effectiveness of our proposed algorithms over state-of-the-art methods, which led in up to 13%, 4%, and 13% improvement of our high-level activities recognition metrics for Opportunity, LISSI, and PAMAP2 datasets, respectively. The LISSI dataset is the most challenging one owing to its less populated and imbalanced distribution. Compared to the SA-GAN adversarial domain adaptation method, the proposed approach enhances the final classification performance with an average of 7.5% for the three datasets, which emphasizes the effectiveness of micro-mini-batch training.
Peeking into occluded joints: A novel framework for crowd pose estimation
Mar 31, 2020
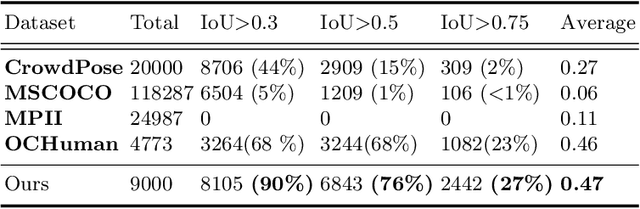
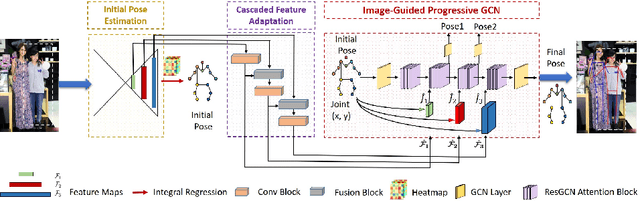

Although occlusion widely exists in nature and remains a fundamental challenge for pose estimation, existing heatmap-based approaches suffer serious degradation on occlusions. Their intrinsic problem is that they directly localize the joints based on visual information; however, the invisible joints are lack of that. In contrast to localization, our framework estimates the invisible joints from an inference perspective by proposing an Image-Guided Progressive GCN module which provides a comprehensive understanding of both image context and pose structure. Moreover, existing benchmarks contain limited occlusions for evaluation. Therefore, we thoroughly pursue this problem and propose a novel OPEC-Net framework together with a new Occluded Pose (OCPose) dataset with 9k annotated images. Extensive quantitative and qualitative evaluations on benchmarks demonstrate that OPEC-Net achieves significant improvements over recent leading works. Notably, our OCPose is the most complex occlusion dataset with respect to average IoU between adjacent instances. Source code and OCPose will be publicly available.
MineNav: An Expandable Synthetic Dataset Based on Minecraft for Aircraft Visual Navigation
Aug 19, 2020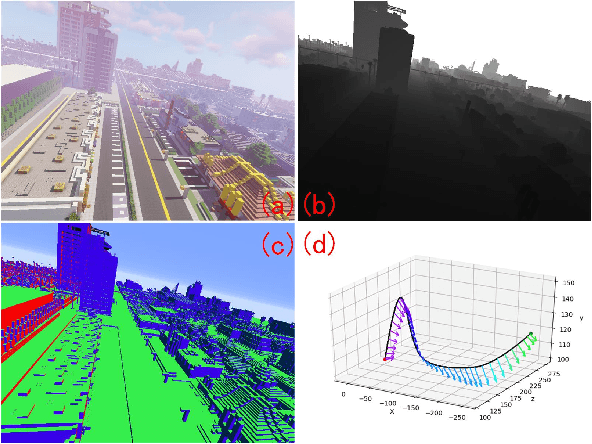
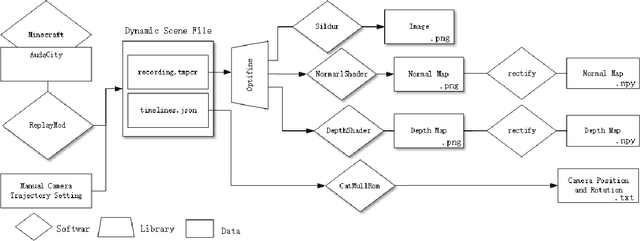

We propose a simply method to generate high quality synthetic dataset based on open-source game Minecraft includes rendered image, Depth map, surface normal map, and 6-dof camera trajectory. This dataset has a perfect ground-truth generated by plug-in program, and thanks for the large game's community, there is an extremely large number of 3D open-world environment, users can find suitable scenes for shooting and build data sets through it and they can also build scenes in-game. as such, We don't need to worry about manual over fitting caused by too small datasets. what's more, there is also a shader community which We can use to minimize data bias between rendered images and real-images as little as possible. Last but not least, we now provide three tools to generate the data for depth prediction ,surface normal prediction and visual odometry, user can also develop the plug-in module for other vision task like segmentation or optical flow prediction.
Targeted Attack for Deep Hashing based Retrieval
Apr 15, 2020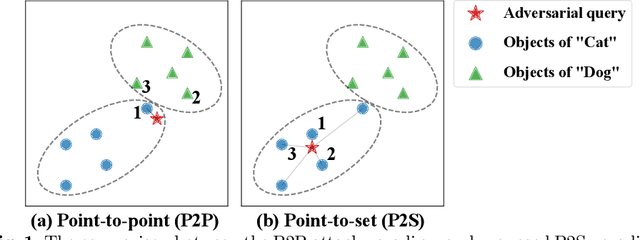
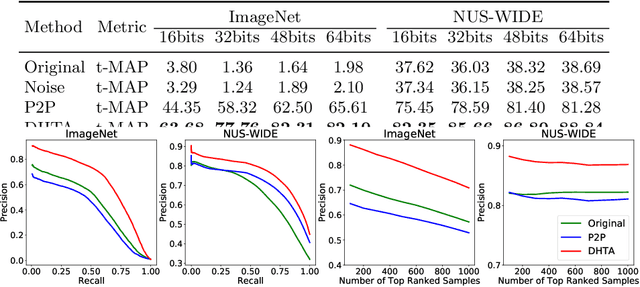
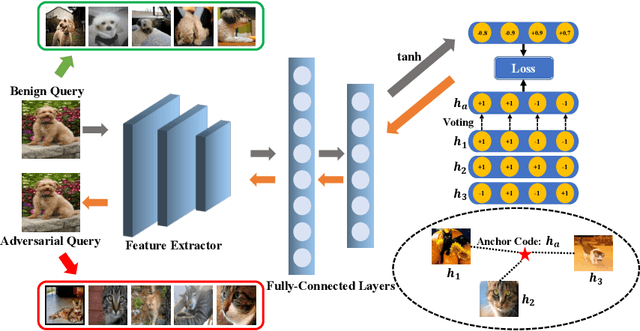
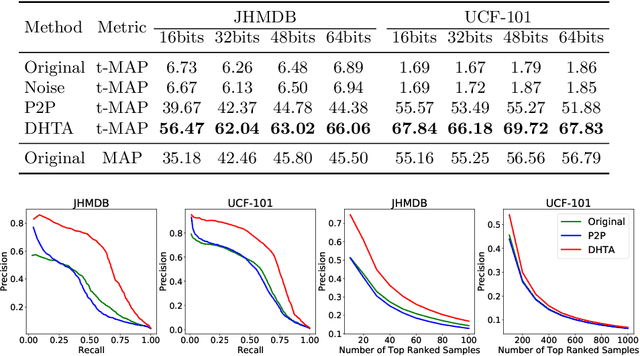
The deep hashing based retrieval method is widely adopted in large-scale image and video retrieval. However, there is little investigation on its security. In this paper, we propose a novel method, dubbed deep hashing targeted attack (DHTA), to study the targeted attack on such retrieval. Specifically, we first formulate the targeted attack as a point-to-set optimization, which minimizes the average distance between the hash code of an adversarial example and those of a set of objects with the target label. Then we design a novel component-voting scheme to obtain an anchor code as the representative of the set of hash codes of objects with the target label, whose optimality guarantee is also theoretically derived. To balance the performance and perceptibility, we propose to minimize the Hamming distance between the hash code of the adversarial example and the anchor code under the $\ell^\infty$ restriction on the perturbation. Extensive experiments verify that DHTA is effective in attacking both deep hashing based image retrieval and video retrieval.
Loss Max-Pooling for Semantic Image Segmentation
Apr 10, 2017
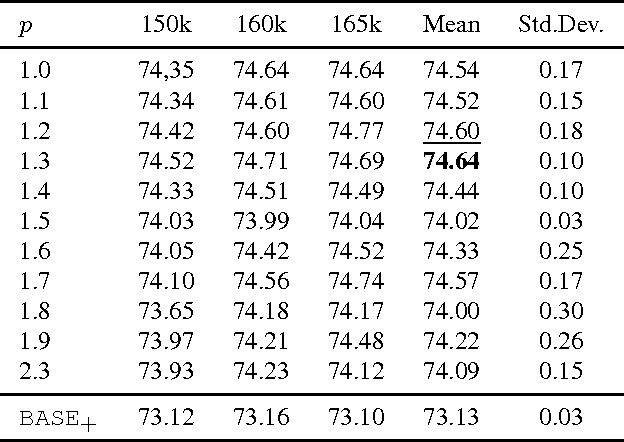
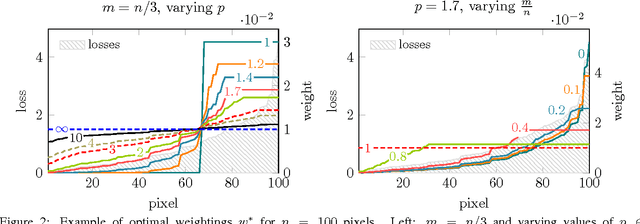

We introduce a novel loss max-pooling concept for handling imbalanced training data distributions, applicable as alternative loss layer in the context of deep neural networks for semantic image segmentation. Most real-world semantic segmentation datasets exhibit long tail distributions with few object categories comprising the majority of data and consequently biasing the classifiers towards them. Our method adaptively re-weights the contributions of each pixel based on their observed losses, targeting under-performing classification results as often encountered for under-represented object classes. Our approach goes beyond conventional cost-sensitive learning attempts through adaptive considerations that allow us to indirectly address both, inter- and intra-class imbalances. We provide a theoretical justification of our approach, complementary to experimental analyses on benchmark datasets. In our experiments on the Cityscapes and Pascal VOC 2012 segmentation datasets we find consistently improved results, demonstrating the efficacy of our approach.