 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Simulation of Brain Resection for Cavity Segmentation Using Self-Supervised and Semi-Supervised Learning
Jun 28, 2020
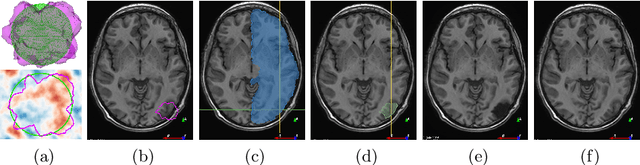
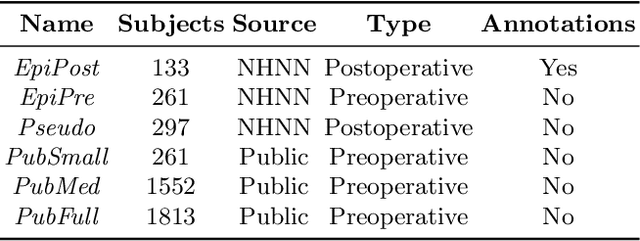
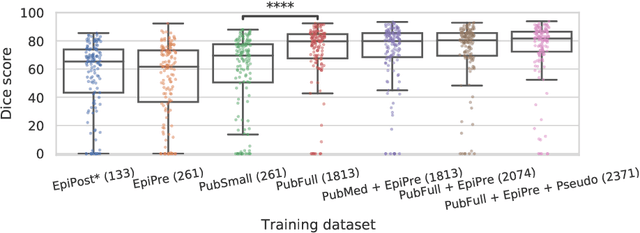
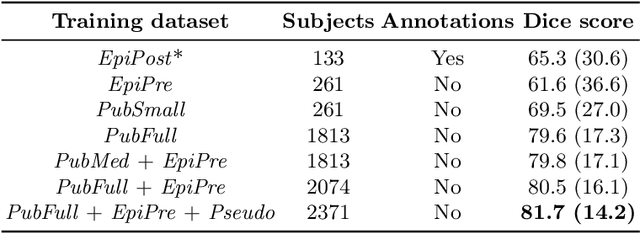
Resective surgery may be curative for drug-resistant focal epilepsy, but only 40% to 70% of patients achieve seizure freedom after surgery. Retrospective quantitative analysis could elucidate patterns in resected structures and patient outcomes to improve resective surgery. However, the resection cavity must first be segmented on the postoperative MR image. Convolutional neural networks (CNNs) are the state-of-the-art image segmentation technique, but require large amounts of annotated data for training. Annotation of medical images is a time-consuming process requiring highly-trained raters, and often suffering from high inter-rater variability. Self-supervised learning can be used to generate training instances from unlabeled data. We developed an algorithm to simulate resections on preoperative MR images. We curated a new dataset, EPISURG, comprising 431 postoperative and 269 preoperative MR images from 431 patients who underwent resective surgery. In addition to EPISURG, we used three public datasets comprising 1813 preoperative MR images for training. We trained a 3D CNN on artificially resected images created on the fly during training, using images from 1) EPISURG, 2) public datasets and 3) both. To evaluate trained models, we calculate Dice score (DSC) between model segmentations and 200 manual annotations performed by three human raters. The model trained on data with manual annotations obtained a median (interquartile range) DSC of 65.3 (30.6). The DSC of our best-performing model, trained with no manual annotations, is 81.7 (14.2). For comparison, inter-rater agreement between human annotators was 84.0 (9.9). We demonstrate a training method for CNNs using simulated resection cavities that can accurately segment real resection cavities, without manual annotations.
Pose-Aware Instance Segmentation Framework from Cone Beam CT Images for Tooth Segmentation
Feb 06, 2020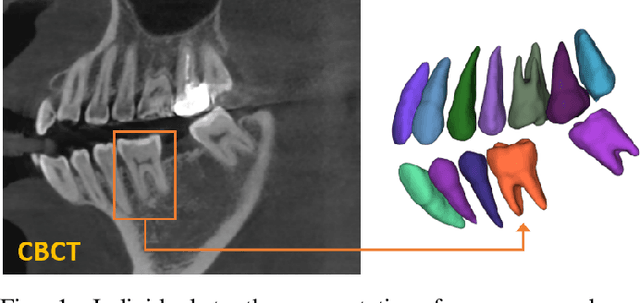
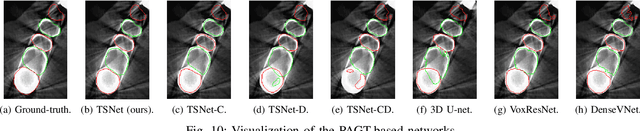

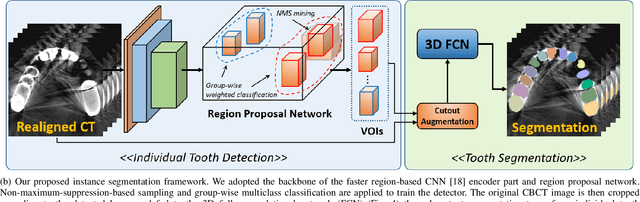
Individual tooth segmentation from cone beam computed tomography (CBCT) images is an essential prerequisite for an anatomical understanding of orthodontic structures in several applications, such as tooth reformation planning and implant guide simulations. However, the presence of severe metal artifacts in CBCT images hinders the accurate segmentation of each individual tooth. In this study, we propose a neural network for pixel-wise labeling to exploit an instance segmentation framework that is robust to metal artifacts. Our method comprises of three steps: 1) image cropping and realignment by pose regressions, 2) metal-robust individual tooth detection, and 3) segmentation. We first extract the alignment information of the patient by pose regression neural networks to attain a volume-of-interest (VOI) region and realign the input image, which reduces the inter-overlapping area between tooth bounding boxes. Then, individual tooth regions are localized within a VOI realigned image using a convolutional detector. We improved the accuracy of the detector by employing non-maximum suppression and multiclass classification metrics in the region proposal network. Finally, we apply a convolutional neural network (CNN) to perform individual tooth segmentation by converting the pixel-wise labeling task to a distance regression task. Metal-intensive image augmentation is also employed for a robust segmentation of metal artifacts. The result shows that our proposed method outperforms other state-of-the-art methods, especially for teeth with metal artifacts. The primary significance of the proposed method is two-fold: 1) an introduction of pose-aware VOI realignment followed by a robust tooth detection and 2) a metal-robust CNN framework for accurate tooth segmentation.
Image Fusion and Re-Modified SPIHT for Fused Image
Feb 29, 2012This paper presents the Discrete Wavelet based fusion techniques for combining perceptually important image features. SPIHT (Set Partitioning in Hierarchical Trees) algorithm is an efficient method for lossy and lossless coding of fused image. This paper presents some modifications on the SPIHT algorithm. It is based on the idea of insignificant correlation of wavelet coefficient among the medium and high frequency sub bands. In RE-MSPIHT algorithm, wavelet coefficients are scaled prior to SPIHT coding based on the sub band importance, with the goal of minimizing the MSE.
* 16 pages
PointIso: Point Cloud Based Deep Learning Model for Detecting Arbitrary-Precision Peptide Features in LC-MS Map through Attention Based Segmentation
Sep 15, 2020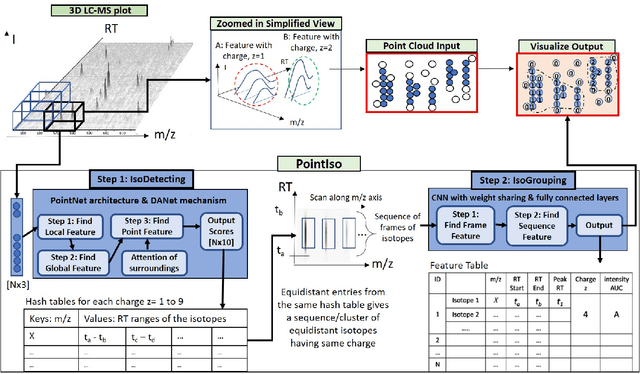

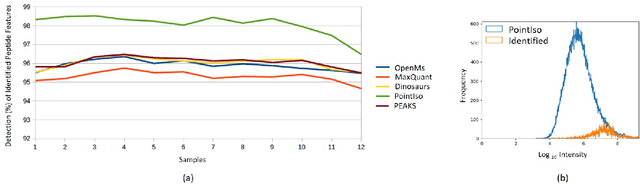

A promising technique of discovering disease biomarkers is to measure the relative protein abundance in multiple biofluid samples through liquid chromatography with tandem mass spectrometry (LC-MS/MS) based quantitative proteomics. The key step involves peptide feature detection in LC-MS map, along with its charge and intensity. Existing heuristic algorithms suffer from inaccurate parameters since different settings of the parameters result in significantly different outcomes. Therefore, we propose PointIso, to serve the necessity of an automated system for peptide feature detection that is able to find out the proper parameters itself, and is easily adaptable to different types of datasets. It consists of an attention based scanning step for segmenting the multi-isotopic pattern of peptide features along with charge and a sequence classification step for grouping those isotopes into potential peptide features. PointIso is the first point cloud based, arbitrary-precision deep learning network to address the problem and achieves 98% detection of high quality MS/MS identifications in a benchmark dataset, which is higher than several other widely used algorithms. Besides contributing to the proteomics study, we believe our novel segmentation technique should serve the general image processing domain as well.
3D_DEN: Open-ended 3D Object Recognition using Dynamically Expandable Networks
Sep 15, 2020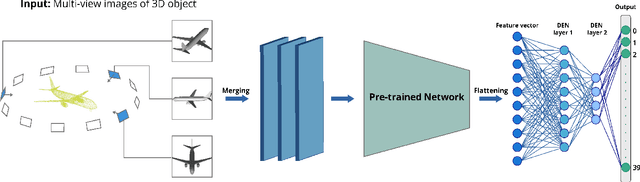
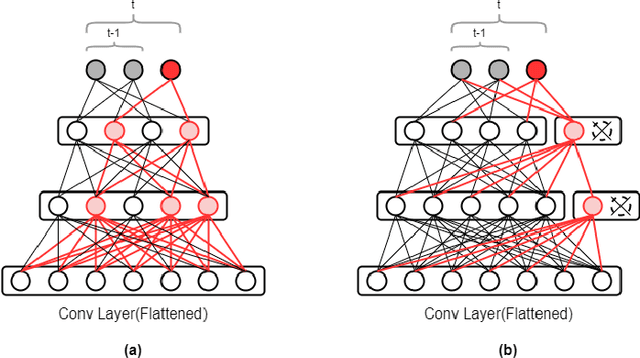
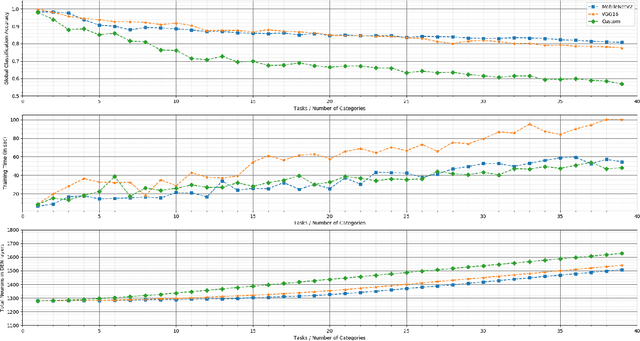
Service robots, in general, have to work independently and adapt to the dynamic changes in the environment. One important aspect in such scenarios is to continually learn to recognize new objects when they become available. This combines two main research problems namely continual learning and 3D object recognition. Most of the existing research approaches include the use of deep Convolutional Neural Networks (CNNs) focusing on image datasets. A modified approach might be needed for continually learning 3D objects. A major concern in using CNNs is the problem of catastrophic forgetting when a model tries to learn new data. In spite of various recent proposed solutions to mitigate this problem, there still exist a few side-effects (such as time/computational complexity) of such solutions. We propose a model capable of learning 3D objects in an open-ended fashion by employing deep transfer learning-based approach combined with dynamically expandable layers, which also makes sure that these side-effects are minimized to a great extent. We show that this model sets a new state-of-the-art standard not only with regards to accuracy but also for computational complexity.
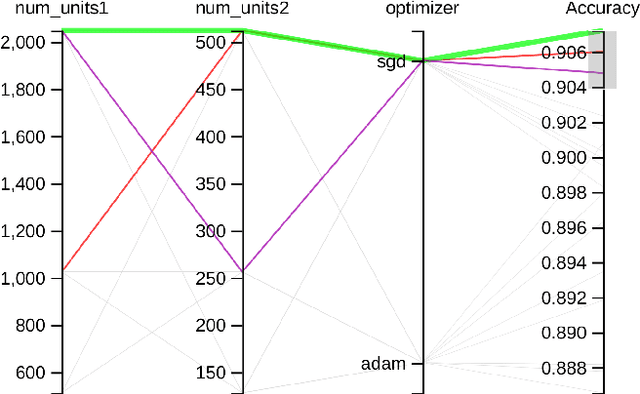
Interactive Visual Study of Multiple Attributes Learning Model of X-Ray Scattering Images
Sep 03, 2020

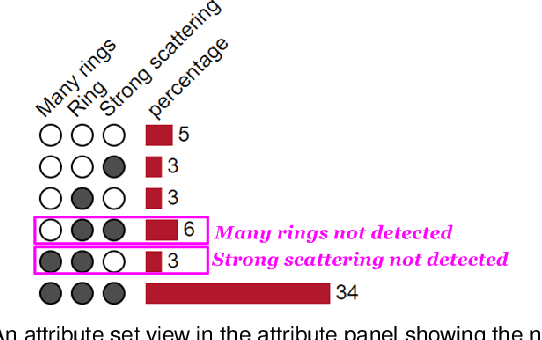

Existing interactive visualization tools for deep learning are mostly applied to the training, debugging, and refinement of neural network models working on natural images. However, visual analytics tools are lacking for the specific application of x-ray image classification with multiple structural attributes. In this paper, we present an interactive system for domain scientists to visually study the multiple attributes learning models applied to x-ray scattering images. It allows domain scientists to interactively explore this important type of scientific images in embedded spaces that are defined on the model prediction output, the actual labels, and the discovered feature space of neural networks. Users are allowed to flexibly select instance images, their clusters, and compare them regarding the specified visual representation of attributes. The exploration is guided by the manifestation of model performance related to mutual relationships among attributes, which often affect the learning accuracy and effectiveness. The system thus supports domain scientists to improve the training dataset and model, find questionable attributes labels, and identify outlier images or spurious data clusters. Case studies and scientists feedback demonstrate its functionalities and usefulness.
* IEEE SciVis Conference 2020
AMRNet: Chips Augmentation in Areial Images Object Detection
Sep 15, 2020
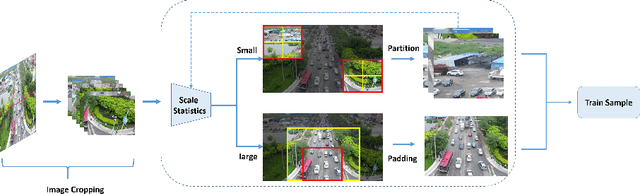
Detecting object in aerial image is challenging task due to 1) objects are often small and dense relative to images. 2) object scale varies in a large range. 3) object number in different classes is imbalanced. Current solutions almost adopt cropping method: splitting high resolution images into serials subregions (chips) and detecting on them. However, few works notice that some problems including scale variation, object sparsity exist when directly train network with chips. In this work, Three augmentation methods are introduced. Specifically, we propose a scale adaptive module compatable with all existing cropping method. It dynamically adjust cropping size to balance cover proportion between objects and chips, which narrows object scale variation in training and improves performance without bells and whistels; In addtion, we introduce mosaic effective sloving object sparity and background similarity problems in areial dataset; To balance catgory, we present mask resampling in chips providing higher quality training sample; Our model achieves state-of-the-art perfomance on two popular aerial images datasets of VisDrone and UAVDT. Remarkably, All methods can independent apply to detectiors increasing performance steady without the sacrifice of inference efficiency.
Unsupervised Learning for Real-World Super-Resolution
Sep 20, 2019
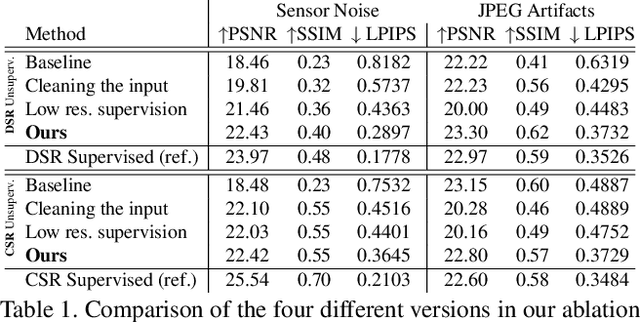

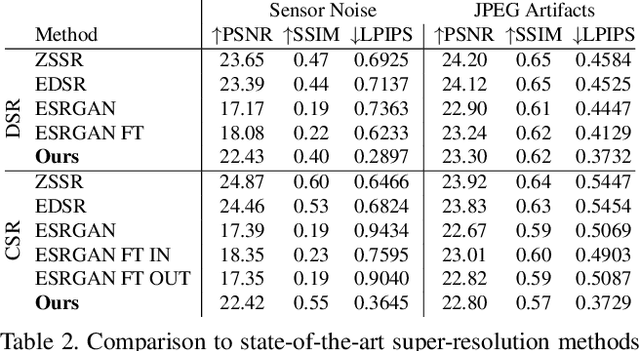
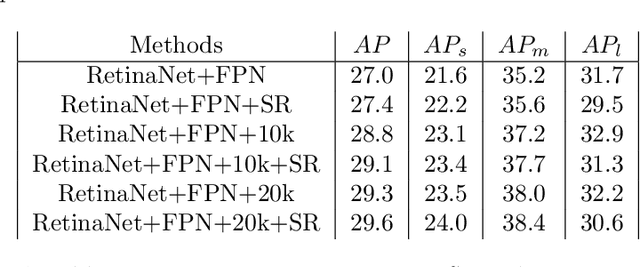
Most current super-resolution methods rely on low and high resolution image pairs to train a network in a fully supervised manner. However, such image pairs are not available in real-world applications. Instead of directly addressing this problem, most works employ the popular bicubic downsampling strategy to artificially generate a corresponding low resolution image. Unfortunately, this strategy introduces significant artifacts, removing natural sensor noise and other real-world characteristics. Super-resolution networks trained on such bicubic images therefore struggle to generalize to natural images. In this work, we propose an unsupervised approach for image super-resolution. Given only unpaired data, we learn to invert the effects of bicubic downsampling in order to restore the natural image characteristics present in the data. This allows us to generate realistic image pairs, faithfully reflecting the distribution of real-world images. Our super-resolution network can therefore be trained with direct pixel-wise supervision in the high resolution domain, while robustly generalizing to real input. We demonstrate the effectiveness of our approach in quantitative and qualitative experiments.
Hidden Footprints: Learning Contextual Walkability from 3D Human Trails
Aug 19, 2020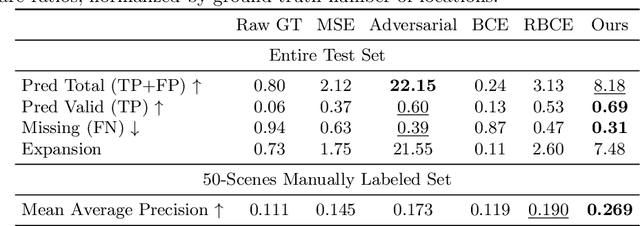
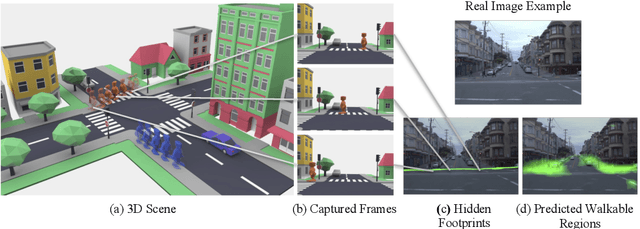
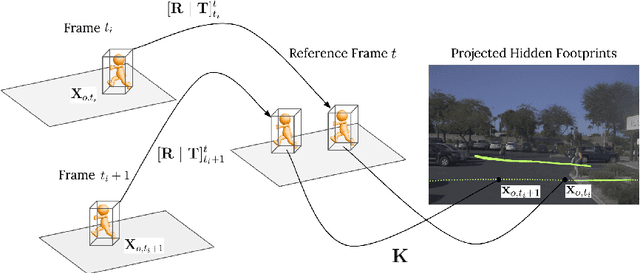

Predicting where people can walk in a scene is important for many tasks, including autonomous driving systems and human behavior analysis. Yet learning a computational model for this purpose is challenging due to semantic ambiguity and a lack of labeled data: current datasets only tell you where people are, not where they could be. We tackle this problem by leveraging information from existing datasets, without additional labeling. We first augment the set of valid, labeled walkable regions by propagating person observations between images, utilizing 3D information to create what we call hidden footprints. However, this augmented data is still sparse. We devise a training strategy designed for such sparse labels, combining a class-balanced classification loss with a contextual adversarial loss. Using this strategy, we demonstrate a model that learns to predict a walkability map from a single image. We evaluate our model on the Waymo and Cityscapes datasets, demonstrating superior performance compared to baselines and state-of-the-art models.
Null-sampling for Interpretable and Fair Representations
Aug 12, 2020

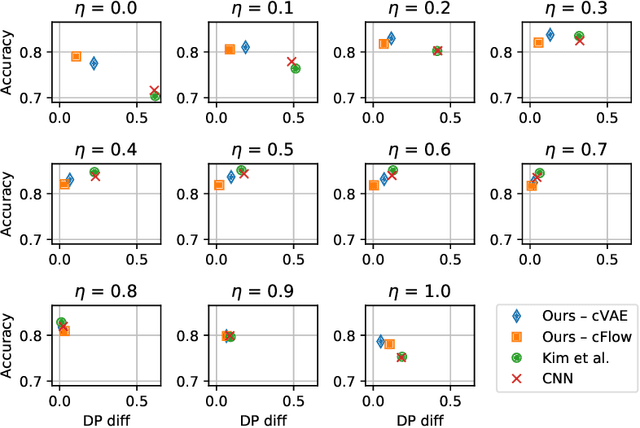

We propose to learn invariant representations, in the data domain, to achieve interpretability in algorithmic fairness. Invariance implies a selectivity for high level, relevant correlations w.r.t. class label annotations, and a robustness to irrelevant correlations with protected characteristics such as race or gender. We introduce a non-trivial setup in which the training set exhibits a strong bias such that class label annotations are irrelevant and spurious correlations cannot be distinguished. To address this problem, we introduce an adversarially trained model with a null-sampling procedure to produce invariant representations in the data domain. To enable disentanglement, a partially-labelled representative set is used. By placing the representations into the data domain, the changes made by the model are easily examinable by human auditors. We show the effectiveness of our method on both image and tabular datasets: Coloured MNIST, the CelebA and the Adult dataset.