 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 13, 2020

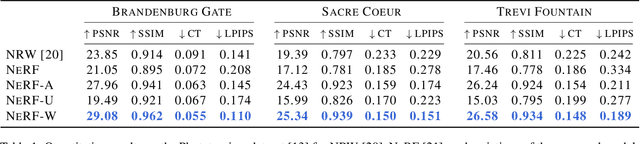

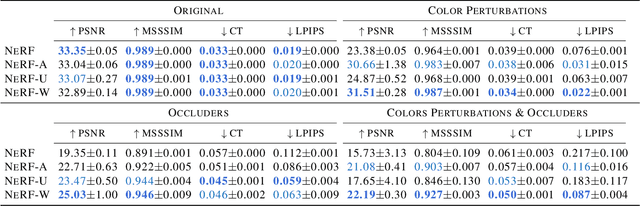
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.
GeoGraph: Learning graph-based multi-view object detection with geometric cues end-to-end
Mar 24, 2020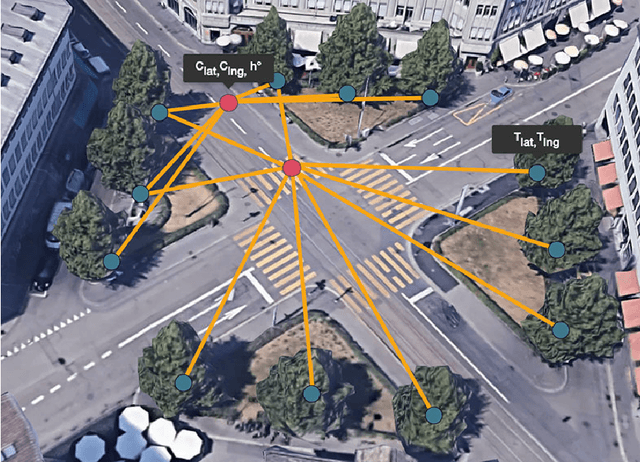
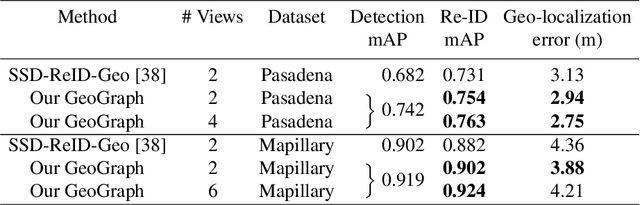
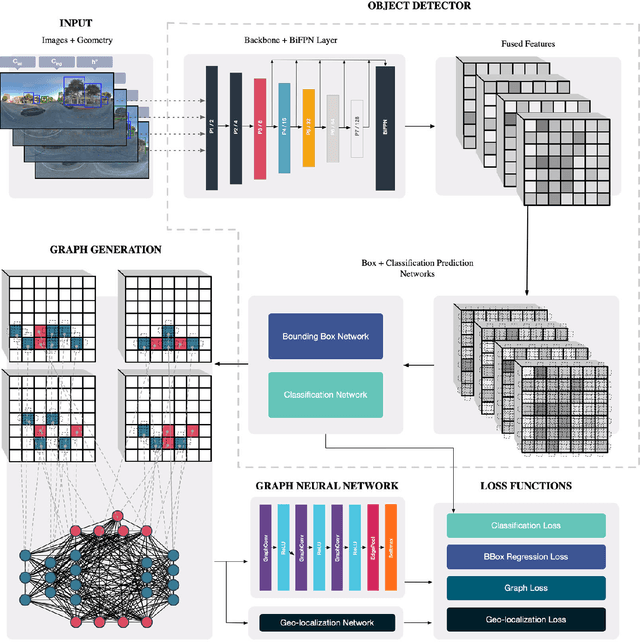
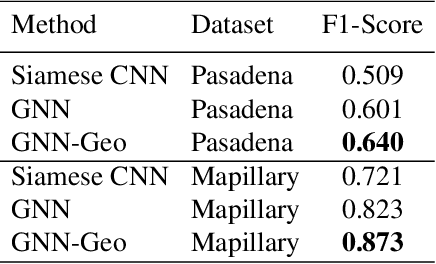
In this paper we propose an end-to-end learnable approach that detects static urban objects from multiple views, re-identifies instances, and finally assigns a geographic position per object. Our method relies on a Graph Neural Network (GNN) to, detect all objects and output their geographic positions given images and approximate camera poses as input. Our GNN simultaneously models relative pose and image evidence, and is further able to deal with an arbitrary number of input views. Our method is robust to occlusion, with similar appearance of neighboring objects, and severe changes in viewpoints by jointly reasoning about visual image appearance and relative pose. Experimental evaluation on two challenging, large-scale datasets and comparison with state-of-the-art methods show significant and systematic improvements both in accuracy and efficiency, with 2-6% gain in detection and re-ID average precision as well as 8x reduction of training time.
Noise Reduction to Compute Tissue Mineral Density and Trabecular Bone Volume Fraction from Low Resolution QCT
Nov 04, 2020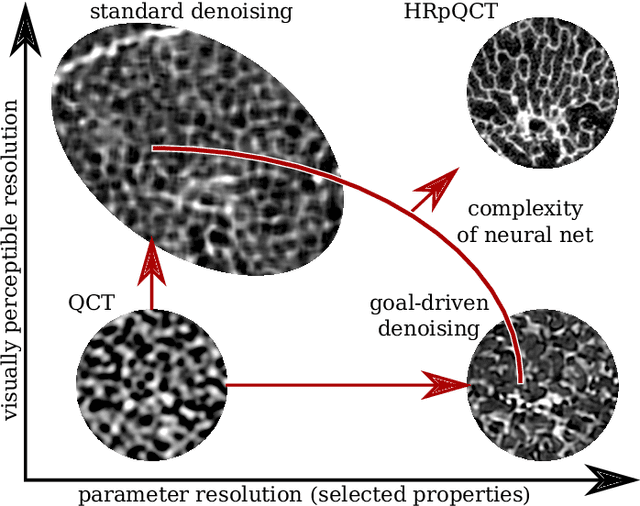
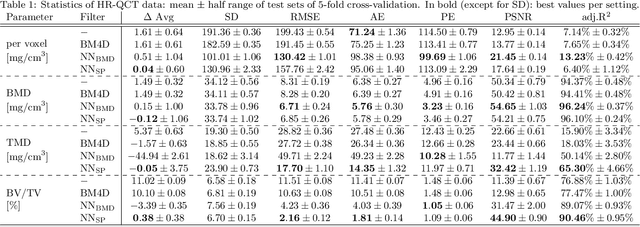
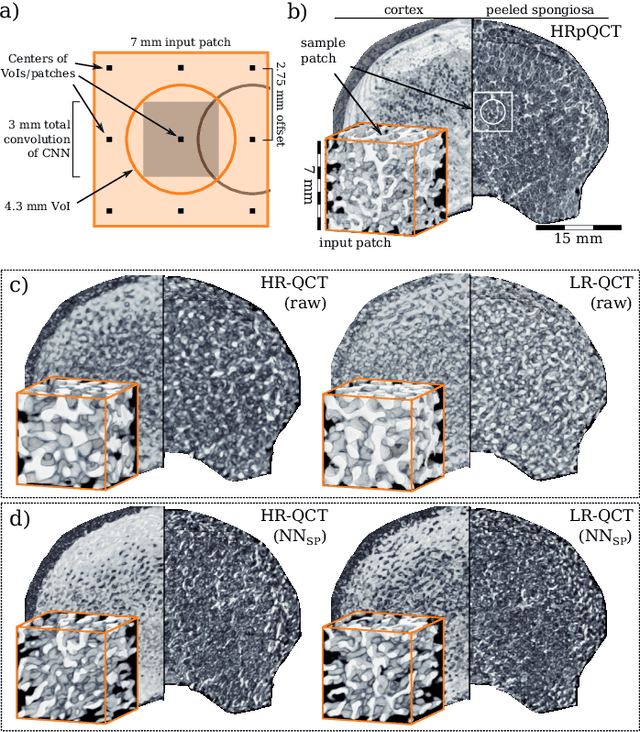
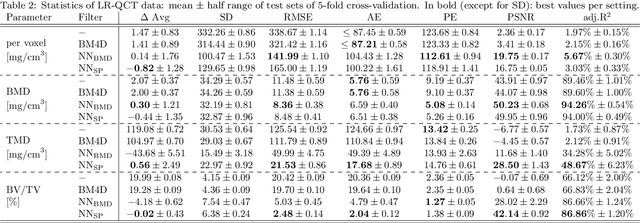
We propose a 3D neural network with specific loss functions for quantitative computed tomography (QCT) noise reduction to compute micro-structural parameters such as tissue mineral density (TMD) and bone volume ratio (BV/TV) with significantly higher accuracy than using no or standard noise reduction filters. The vertebra-phantom study contained high resolution peripheral and clinical CT scans with simulated in vivo CT noise and nine repetitions of three different tube currents (100, 250 and 360 mAs). Five-fold cross validation was performed on 20466 purely spongy pairs of noisy and ground-truth patches. Comparison of training and test errors revealed high robustness against over-fitting. While not showing effects for the assessment of BMD and voxel-wise densities, the filter improved thoroughly the computation of TMD and BV/TV with respect to the unfiltered data. Root-mean-square and accuracy errors of low resolution TMD and BV/TV decreased to less than 17% of the initial values. Furthermore filtered low resolution scans revealed still more TMD- and BV/TV-relevant information than high resolution CT scans, either unfiltered or filtered with two state-of-the-art standard denoising methods. The proposed architecture is threshold and rotational invariant, applicable on a wide range of image resolutions at once, and likely serves for an accurate computation of further micro-structural parameters. Furthermore, it is less prone for over-fitting than neural networks that compute structural parameters directly. In conclusion, the method is potentially important for the diagnosis of osteoporosis and other bone diseases since it allows to assess relevant 3D micro-structural information from standard low exposure CT protocols such as 100 mAs and 120 kVp.
Image Fusion and Re-Modified SPIHT for Fused Image
Feb 29, 2012This paper presents the Discrete Wavelet based fusion techniques for combining perceptually important image features. SPIHT (Set Partitioning in Hierarchical Trees) algorithm is an efficient method for lossy and lossless coding of fused image. This paper presents some modifications on the SPIHT algorithm. It is based on the idea of insignificant correlation of wavelet coefficient among the medium and high frequency sub bands. In RE-MSPIHT algorithm, wavelet coefficients are scaled prior to SPIHT coding based on the sub band importance, with the goal of minimizing the MSE.
* 16 pages
Path Planning using Neural A* Search
Sep 16, 2020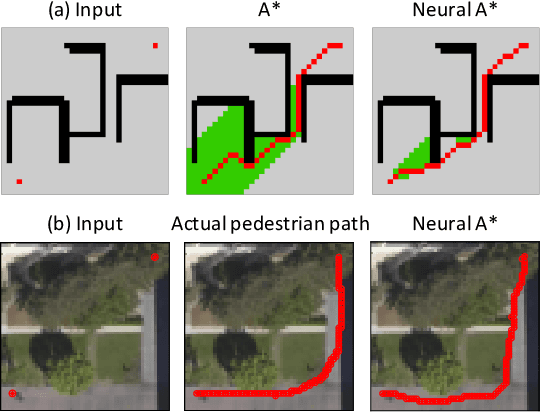
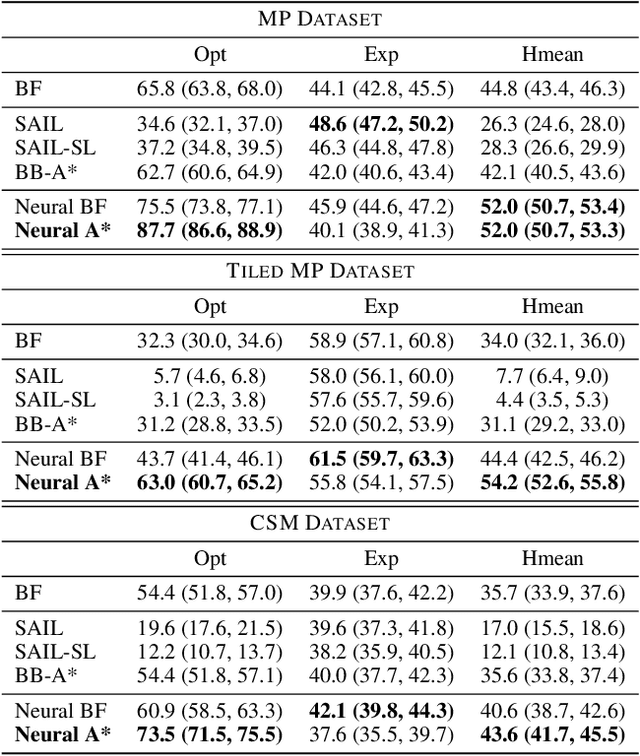


We present Neural A*, a novel data-driven search algorithm for path planning problems. Although data-driven planning has received much attention in recent years, little work has focused on how search-based methods can learn from demonstrations to plan better. In this work, we reformulate a canonical A* search algorithm to be differentiable and couple it with a convolutional encoder to form an end-to-end trainable neural network planner. Neural A* solves a path planning problem by (1) encoding a visual representation of the problem to estimate a movement cost map and (2) performing the A* search on the cost map to output a solution path. By minimizing the difference between the search results and ground-truth paths in demonstrations, the encoder learns to capture a variety of visual planning cues in input images, such as shapes of dead-end obstacles, bypasses, and shortcuts, which makes estimated cost maps informative. Our extensive experiments confirmed that Neural A* (a) outperformed state-of-the-art data-driven planners in terms of the search optimality and efficiency trade-off and (b) predicted realistic pedestrian paths by directly performing a search on raw image inputs.
Synthetic Training for Monocular Human Mesh Recovery
Oct 27, 2020
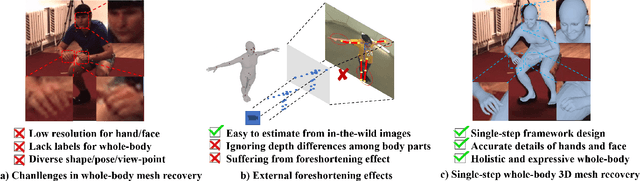
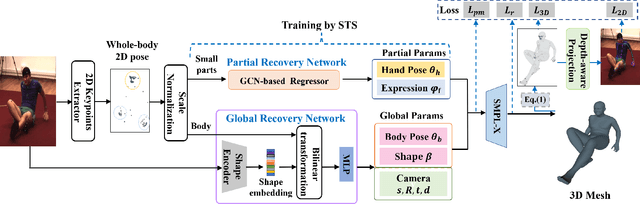
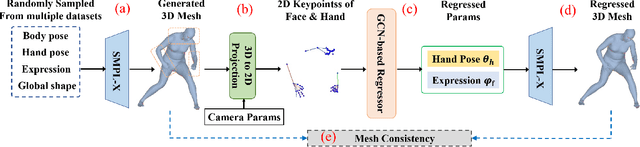
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.
SPN-CNN: Boosting Sensor-Based Source Camera Attribution With Deep Learning
Feb 07, 2020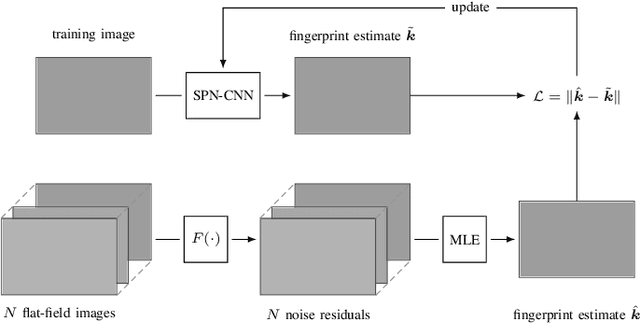

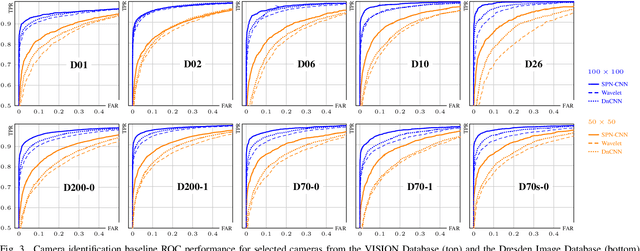
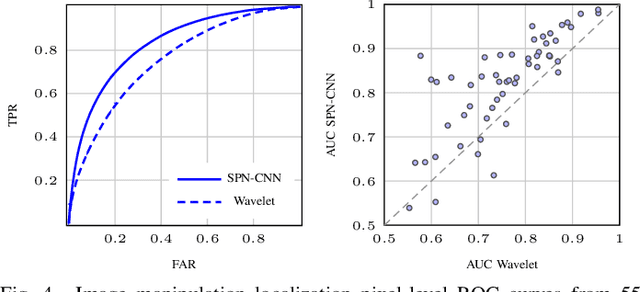
We explore means to advance source camera identification based on sensor noise in a data-driven framework. Our focus is on improving the sensor pattern noise (SPN) extraction from a single image at test time. Where existing works suppress nuisance content with denoising filters that are largely agnostic to the specific SPN signal of interest, we demonstrate that a~deep learning approach can yield a more suitable extractor that leads to improved source attribution. A series of extensive experiments on various public datasets confirms the feasibility of our approach and its applicability to image manipulation localization and video source attribution. A critical discussion of potential pitfalls completes the text.
Feature Binding with Category-Dependant MixUp for Semantic Segmentation and Adversarial Robustness
Aug 13, 2020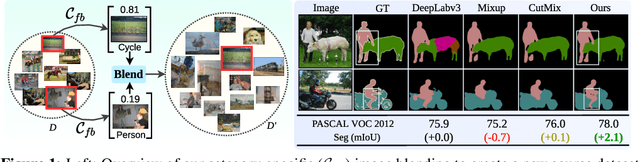

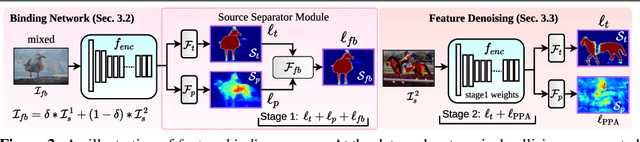
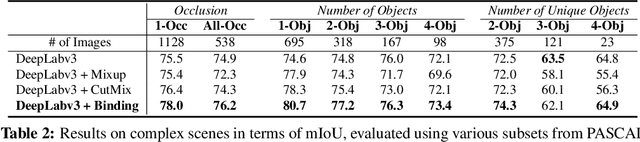
In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activation's spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on their class labels, and then training a feature binding network, which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation network while simultaneously increasing robustness to adversarial attacks.
Weed Density and Distribution Estimation for Precision Agriculture using Semi-Supervised Learning
Nov 04, 2020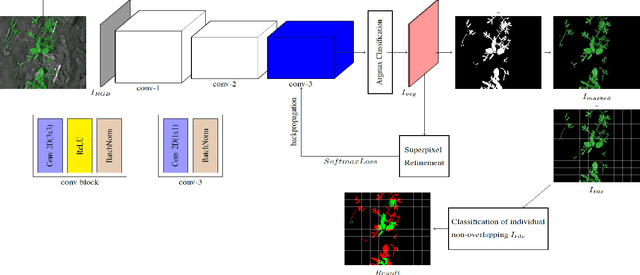
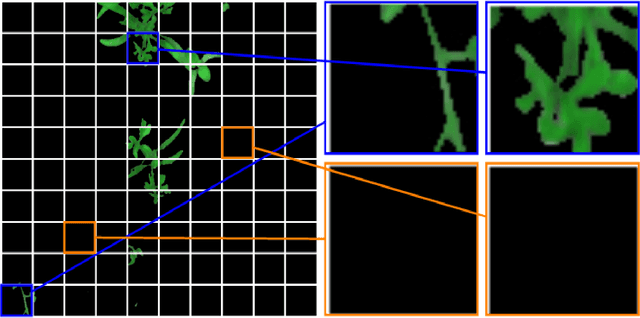
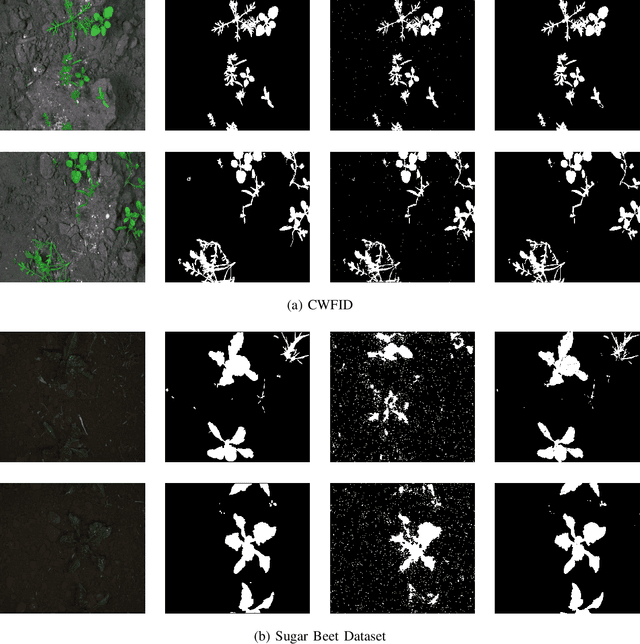
Uncontrolled growth of weeds can severely affect the crop yield and quality. Unrestricted use of herbicide for weed removal alters biodiversity and cause environmental pollution. Instead, identifying weed-infested regions can aid selective chemical treatment of these regions. Advances in analyzing farm images have resulted in solutions to identify weed plants. However, a majority of these approaches are based on supervised learning methods which requires huge amount of manually annotated images. As a result, these supervised approaches are economically infeasible for the individual farmer because of the wide variety of plant species being cultivated. In this paper, we propose a deep learning-based semi-supervised approach for robust estimation of weed density and distribution across farmlands using only limited color images acquired from autonomous robots. This weed density and distribution can be useful in a site-specific weed management system for selective treatment of infected areas using autonomous robots. In this work, the foreground vegetation pixels containing crops and weeds are first identified using a Convolutional Neural Network (CNN) based unsupervised segmentation. Subsequently, the weed infected regions are identified using a fine-tuned CNN, eliminating the need for designing hand-crafted features. The approach is validated on two datasets of different crop/weed species (1) Crop Weed Field Image Dataset (CWFID), which consists of carrot plant images and the (2) Sugar Beets dataset. The proposed method is able to localize weed-infested regions a maximum recall of 0.99 and estimate weed density with a maximum accuracy of 82.13%. Hence, the proposed approach is shown to generalize to different plant species without the need for extensive labeled data.
Adversarial Perturbations Fool Deepfake Detectors
Mar 24, 2020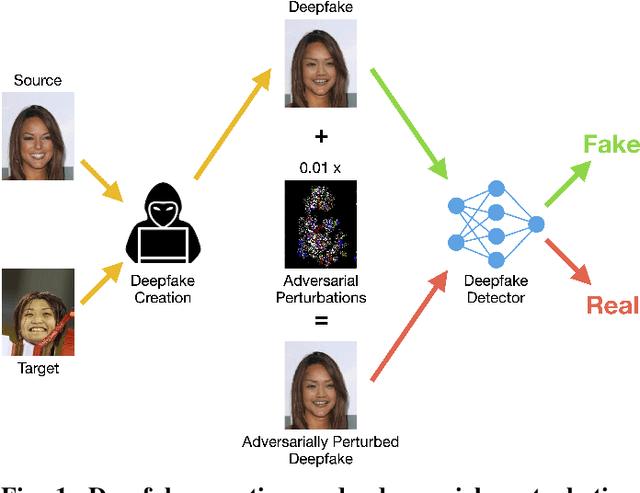

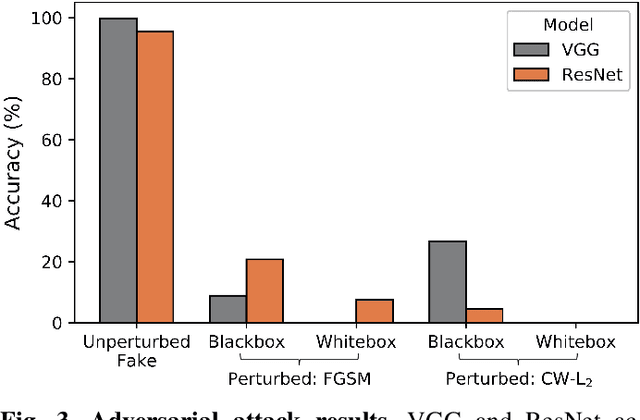
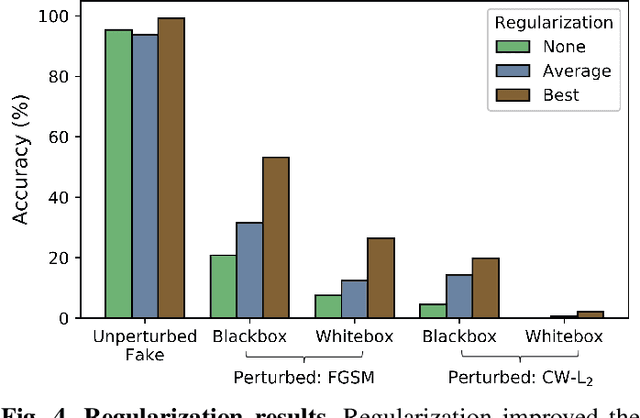
This work uses adversarial perturbations to enhance deepfake images and fool common deepfake detectors. We created adversarial perturbations using the Fast Gradient Sign Method and the Carlini and Wagner L2 norm attack in both blackbox and whitebox settings. Detectors achieved over 95% accuracy on unperturbed deepfakes, but less than 27% accuracy on perturbed deepfakes. We also explore two improvements to deepfake detectors: (i) Lipschitz regularization, and (ii) Deep Image Prior (DIP). Lipschitz regularization constrains the gradient of the detector with respect to the input in order to increase robustness to input perturbations. The DIP defense removes perturbations using generative convolutional neural networks in an unsupervised manner. Regularization improved the detection of perturbed deepfakes on average, including a 10% accuracy boost in the blackbox case. The DIP defense achieved 95% accuracy on perturbed deepfakes that fooled the original detector, while retaining 98% accuracy in other cases on a 100 image subsample.