 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Frame-To-Frame Consistent Semantic Segmentation
Aug 20, 2020
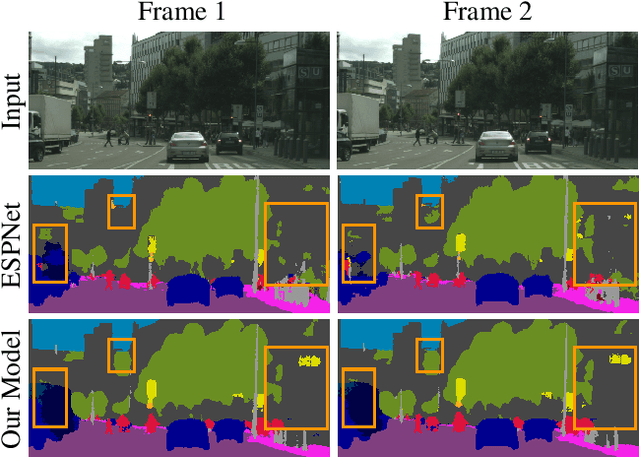
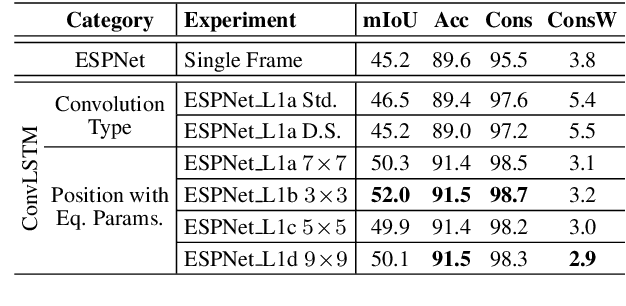
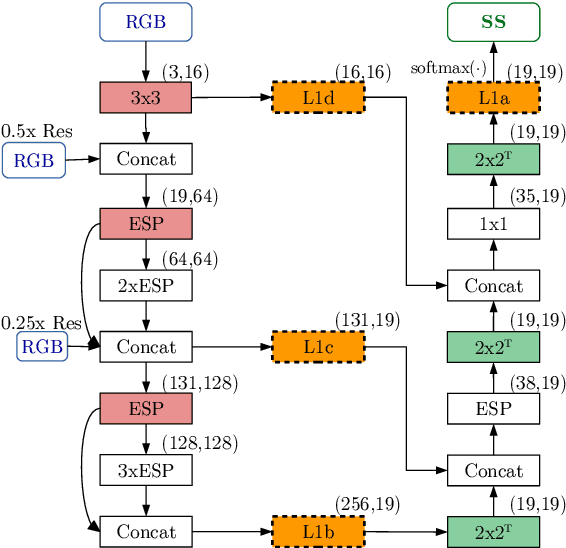
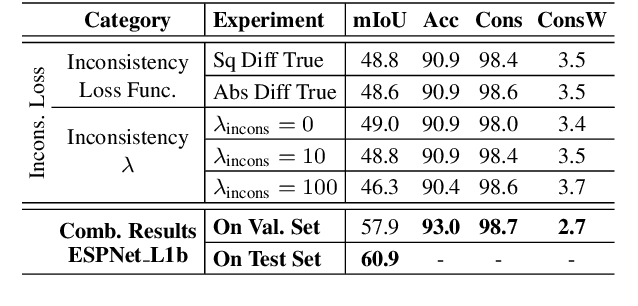
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
Vision-based Manipulation of Deformable and Rigid Objects Using Subspace Projections of 2D Contours
Jun 16, 2020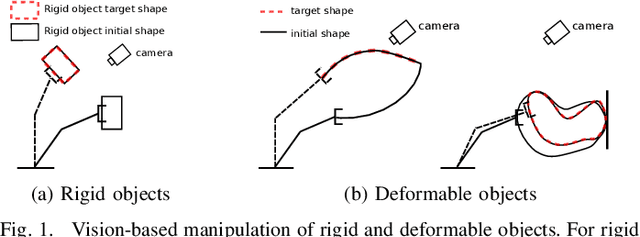
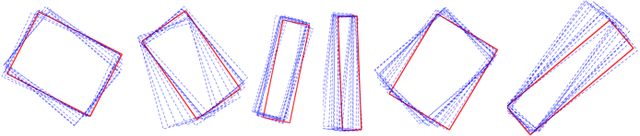
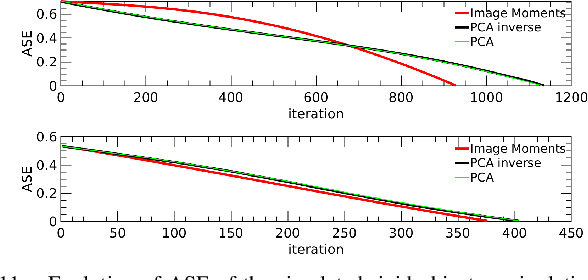
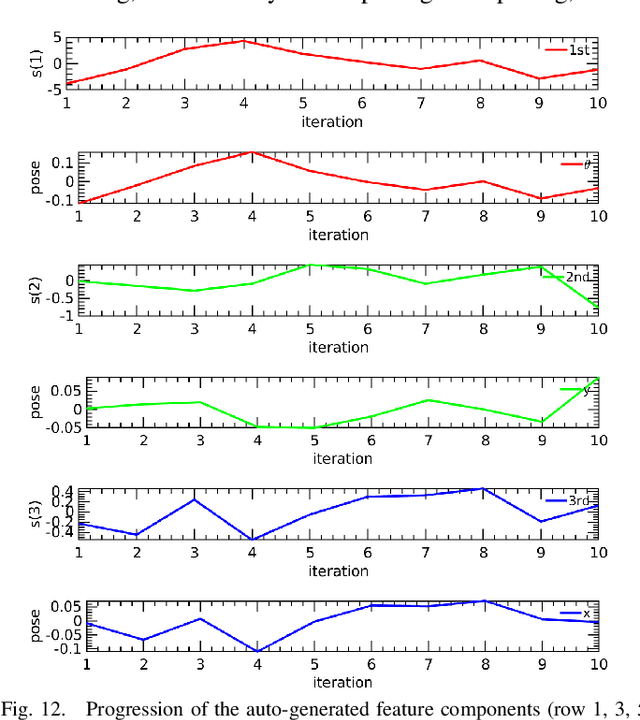
This paper proposes a unified vision-based manipulation framework using image contours of deformable/rigid objects. Instead of using human-defined cues, the robot automatically learns the features from processed vision data. Our method simultaneously generates---from the same data---both, visual features and the interaction matrix that relates them to the robot control inputs. Extraction of the feature vector and control commands is done online and adaptively, with little data for initialization. The method allows the robot to manipulate an object without knowing whether it is rigid or deformable. To validate our approach, we conduct numerical simulations and experiments with both deformable and rigid objects.
LRCN-RetailNet: A recurrent neural network architecture for accurate people counting
May 12, 2020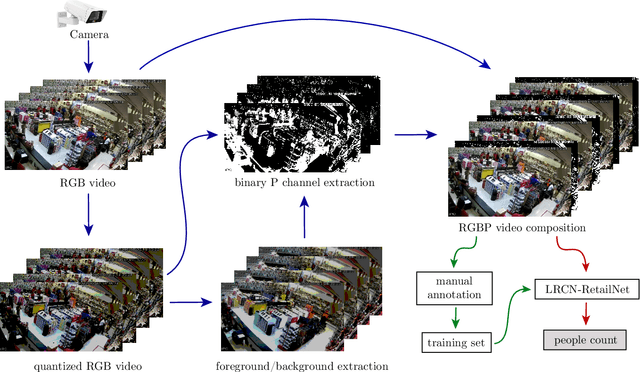
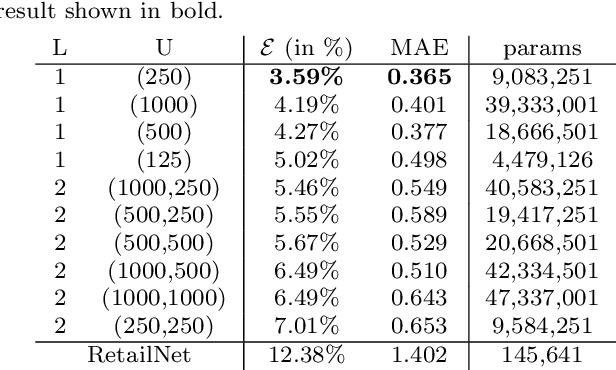
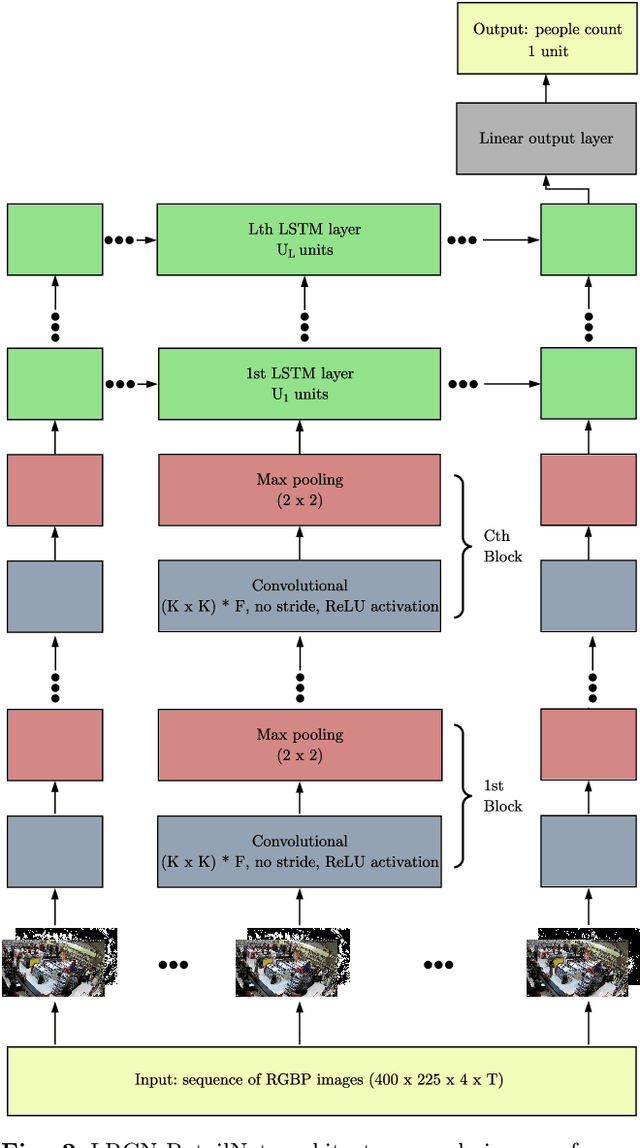
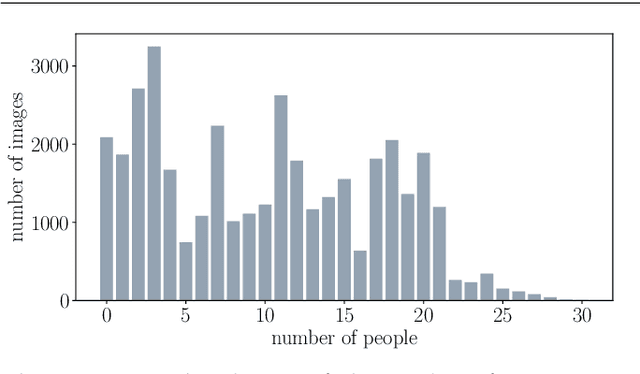
Measuring and analyzing the flow of customers in retail stores is essential for a retailer to better comprehend customers' behavior and support decision-making. Nevertheless, not much attention has been given to the development of novel technologies for automatic people counting. We introduce LRCN-RetailNet: a recurrent neural network architecture capable of learning a non-linear regression model and accurately predicting the people count from videos captured by low-cost surveillance cameras. The input video format follows the recently proposed RGBP image format, which is comprised of color and people (foreground) information. Our architecture is capable of considering two relevant aspects: spatial features extracted through convolutional layers from the RGBP images; and the temporal coherence of the problem, which is exploited by recurrent layers. We show that, through a supervised learning approach, the trained models are capable of predicting the people count with high accuracy. Additionally, we present and demonstrate that a straightforward modification of the methodology is effective to exclude salespeople from the people count. Comprehensive experiments were conducted to validate, evaluate and compare the proposed architecture. Results corroborated that LRCN-RetailNet remarkably outperforms both the previous RetailNet architecture, which was limited to evaluating a single image per iteration; and a state-of-the-art neural network for object detection. Finally, computational performance experiments confirmed that the entire methodology is effective to estimate people count in real-time.
Attention to Scale: Scale-aware Semantic Image Segmentation
Jun 02, 2016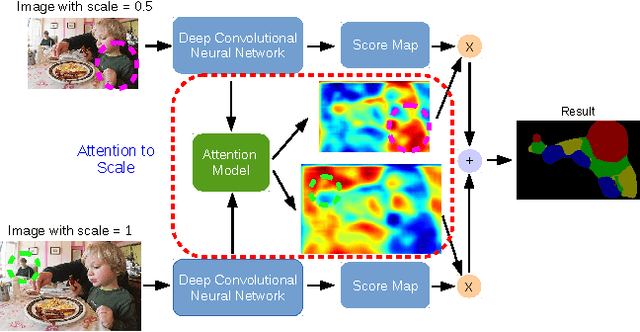
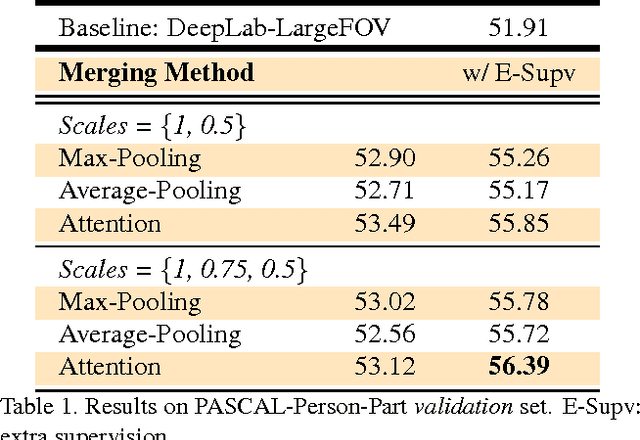
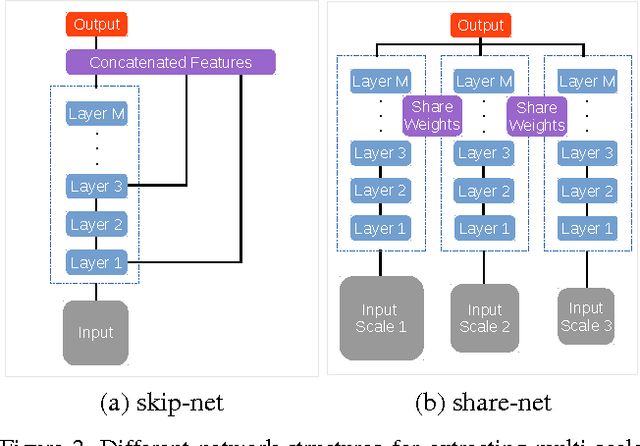

Incorporating multi-scale features in fully convolutional neural networks (FCNs) has been a key element to achieving state-of-the-art performance on semantic image segmentation. One common way to extract multi-scale features is to feed multiple resized input images to a shared deep network and then merge the resulting features for pixelwise classification. In this work, we propose an attention mechanism that learns to softly weight the multi-scale features at each pixel location. We adapt a state-of-the-art semantic image segmentation model, which we jointly train with multi-scale input images and the attention model. The proposed attention model not only outperforms average- and max-pooling, but allows us to diagnostically visualize the importance of features at different positions and scales. Moreover, we show that adding extra supervision to the output at each scale is essential to achieving excellent performance when merging multi-scale features. We demonstrate the effectiveness of our model with extensive experiments on three challenging datasets, including PASCAL-Person-Part, PASCAL VOC 2012 and a subset of MS-COCO 2014.
Learning Stereo from Single Images
Aug 20, 2020
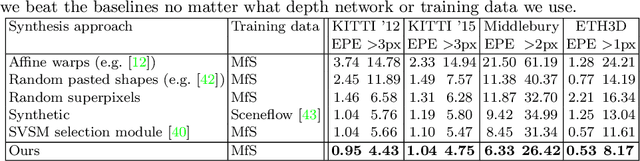
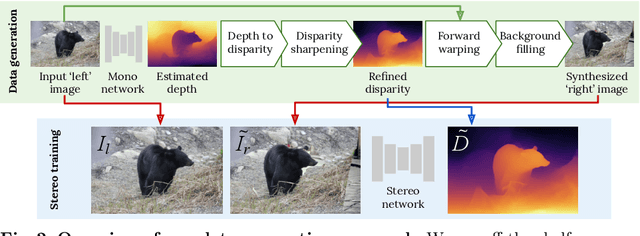

Supervised deep networks are among the best methods for finding correspondences in stereo image pairs. Like all supervised approaches, these networks require ground truth data during training. However, collecting large quantities of accurate dense correspondence data is very challenging. We propose that it is unnecessary to have such a high reliance on ground truth depths or even corresponding stereo pairs. Inspired by recent progress in monocular depth estimation, we generate plausible disparity maps from single images. In turn, we use those flawed disparity maps in a carefully designed pipeline to generate stereo training pairs. Training in this manner makes it possible to convert any collection of single RGB images into stereo training data. This results in a significant reduction in human effort, with no need to collect real depths or to hand-design synthetic data. We can consequently train a stereo matching network from scratch on datasets like COCO, which were previously hard to exploit for stereo. Through extensive experiments we show that our approach outperforms stereo networks trained with standard synthetic datasets, when evaluated on KITTI, ETH3D, and Middlebury.
Learning to Detect Important People in Unlabelled Images for Semi-supervised Important People Detection
Apr 16, 2020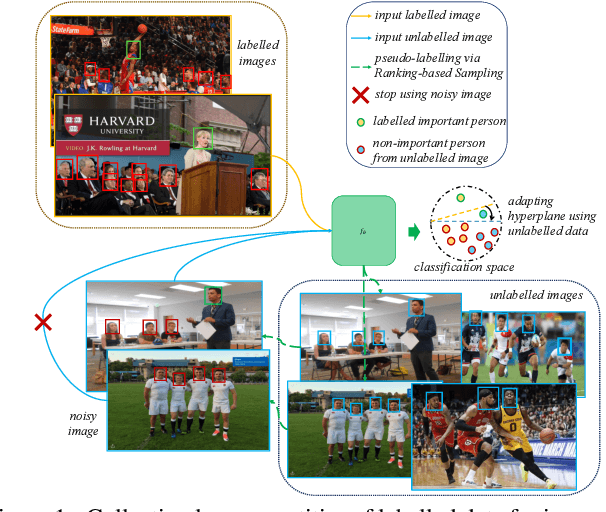
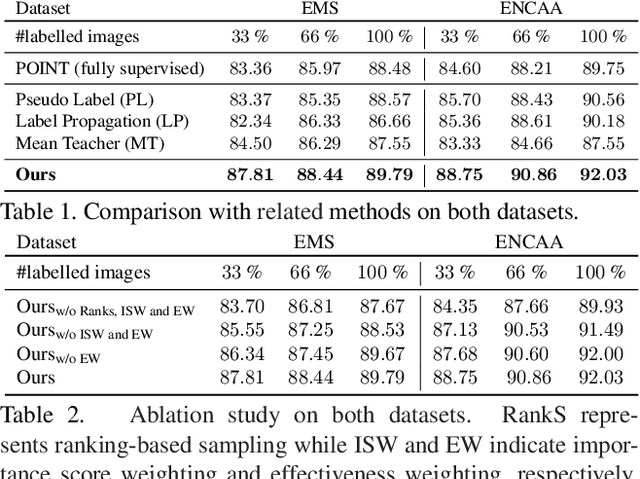
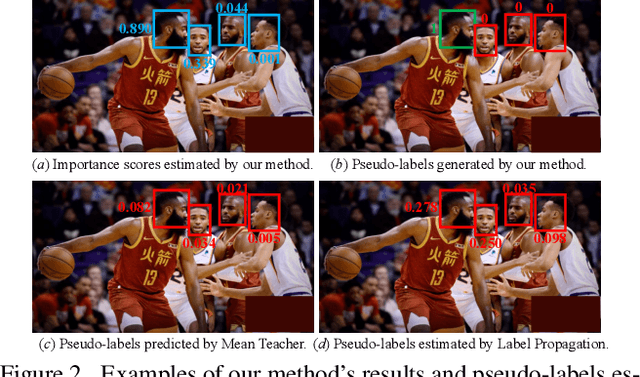
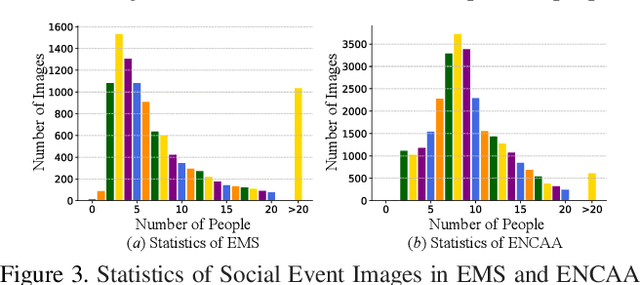
Important people detection is to automatically detect the individuals who play the most important roles in a social event image, which requires the designed model to understand a high-level pattern. However, existing methods rely heavily on supervised learning using large quantities of annotated image samples, which are more costly to collect for important people detection than for individual entity recognition (eg, object recognition). To overcome this problem, we propose learning important people detection on partially annotated images. Our approach iteratively learns to assign pseudo-labels to individuals in un-annotated images and learns to update the important people detection model based on data with both labels and pseudo-labels. To alleviate the pseudo-labelling imbalance problem, we introduce a ranking strategy for pseudo-label estimation, and also introduce two weighting strategies: one for weighting the confidence that individuals are important people to strengthen the learning on important people and the other for neglecting noisy unlabelled images (ie, images without any important people). We have collected two large-scale datasets for evaluation. The extensive experimental results clearly confirm the efficacy of our method attained by leveraging unlabelled images for improving the performance of important people detection.
Learning to adapt class-specific features across domains for semantic segmentation
Jan 22, 2020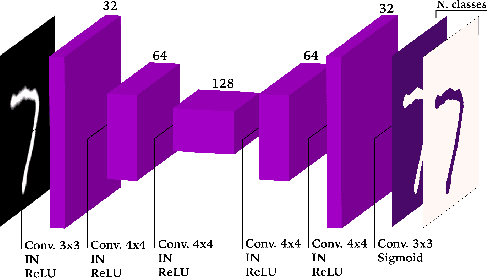


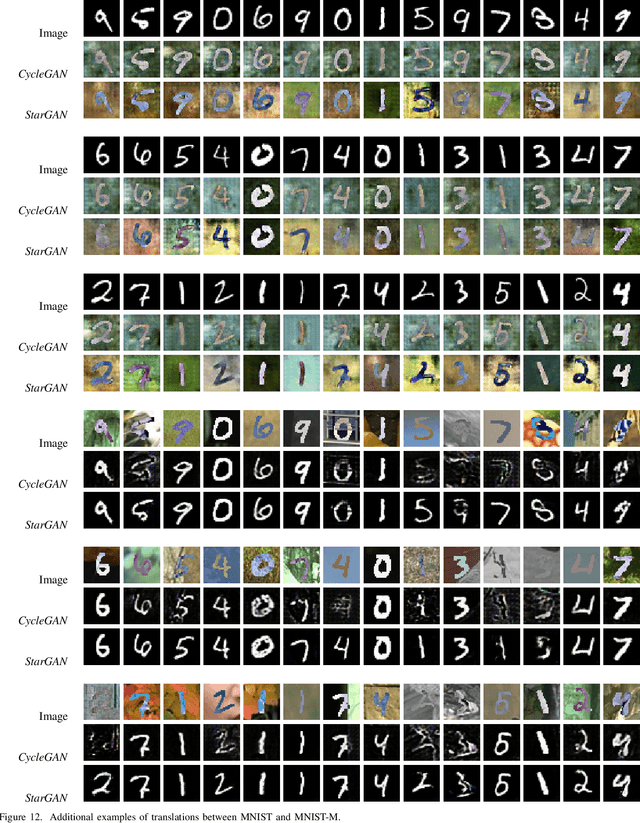
Recent advances in unsupervised domain adaptation have shown the effectiveness of adversarial training to adapt features across domains, endowing neural networks with the capability of being tested on a target domain without requiring any training annotations in this domain. The great majority of existing domain adaptation models rely on image translation networks, which often contain a huge amount of domain-specific parameters. Additionally, the feature adaptation step often happens globally, at a coarse level, hindering its applicability to tasks such as semantic segmentation, where details are of crucial importance to provide sharp results. In this thesis, we present a novel architecture, which learns to adapt features across domains by taking into account per class information. To that aim, we design a conditional pixel-wise discriminator network, whose output is conditioned on the segmentation masks. Moreover, following recent advances in image translation, we adopt the recently introduced StarGAN architecture as image translation backbone, since it is able to perform translations across multiple domains by means of a single generator network. Preliminary results on a segmentation task designed to assess the effectiveness of the proposed approach highlight the potential of the model, improving upon strong baselines and alternative designs.
An Improvement for Capsule Networks using Depthwise Separable Convolution
Jul 30, 2020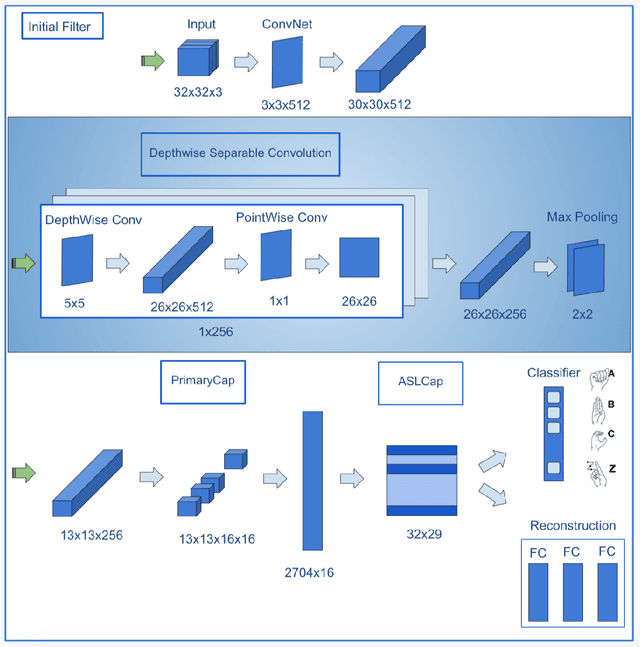
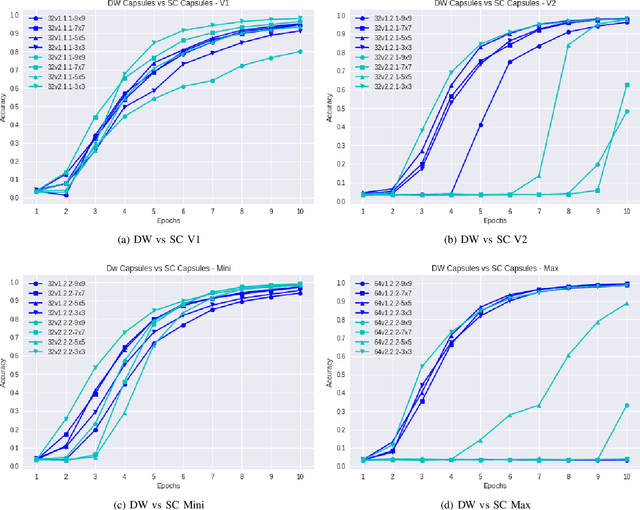
Capsule Networks face a critical problem in computer vision in the sense that the image background can challenge its performance, although they learn very well on training data. In this work, we propose to improve Capsule Networks' architecture by replacing the Standard Convolution with a Depthwise Separable Convolution. This new design significantly reduces the model's total parameters while increases stability and offers competitive accuracy. In addition, the proposed model on $64\times64$ pixel images outperforms standard models on $32\times32$ and $64\times64$ pixel images. Moreover, we empirically evaluate these models with Deep Learning architectures using state-of-the-art Transfer Learning networks such as Inception V3 and MobileNet V1. The results show that Capsule Networks perform equivalently against Deep Learning models. To the best of our knowledge, we believe that this is the first work on the integration of Depthwise Separable Convolution into Capsule Networks.
* 6 pages
Memory-Efficient Incremental Learning Through Feature Adaptation
Apr 01, 2020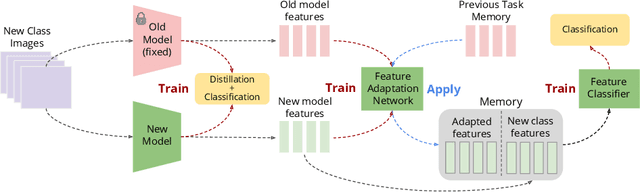
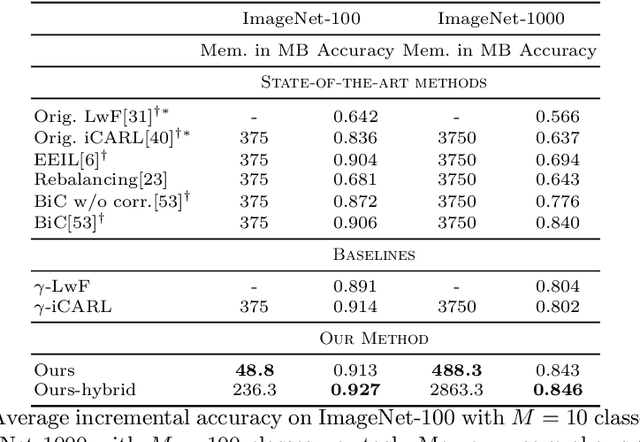
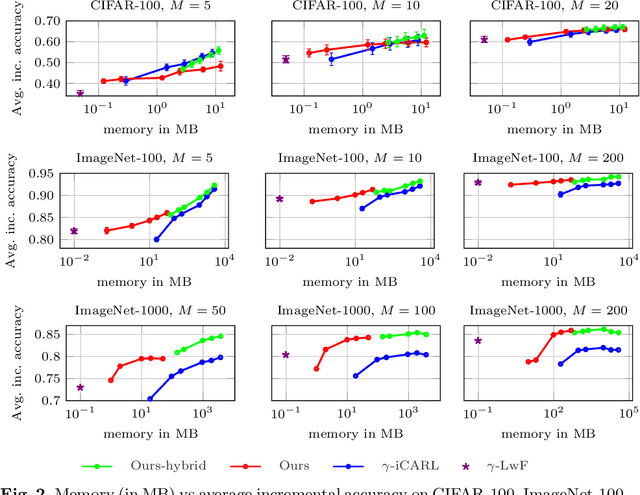
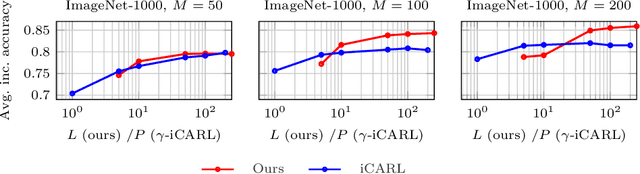
In this work we introduce an approach for incremental learning, which preserves feature descriptors instead of images unlike most existing work. Keeping such low-dimensional embeddings instead of images reduces the memory footprint significantly. We assume that the model is updated incrementally for new classes as new data becomes available sequentially. This requires adapting the previously stored feature vectors to the updated feature space without having access to the corresponding images. Feature adaptation is learned with a multi-layer perceptron, which is trained on feature pairs of an image corresponding to the outputs of the original and updated network. We validate experimentally that such a transformation generalizes well to the features of the previous set of classes, and maps features to a discriminative subspace in the feature space. As a result, the classifier is optimized jointly over new and old classes without requiring old class images. Experimental results show that our method achieves state-of-the-art classification accuracy in incremental learning benchmarks, while having at least an order of magnitude lower memory footprint compared to image preserving strategies.
Pairwise-GAN: Pose-based View Synthesis through Pair-Wise Training
Sep 13, 2020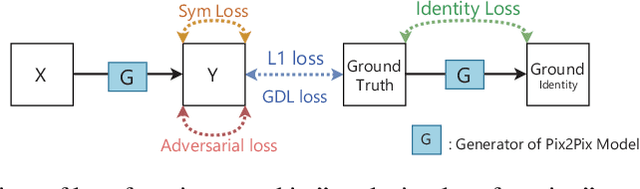
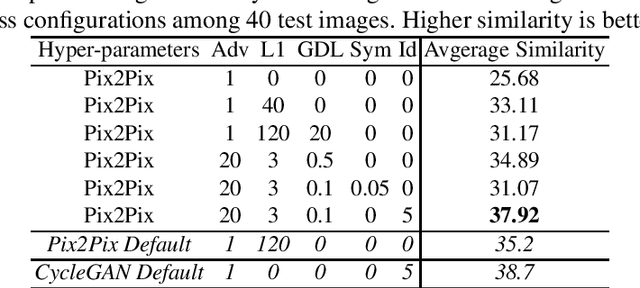
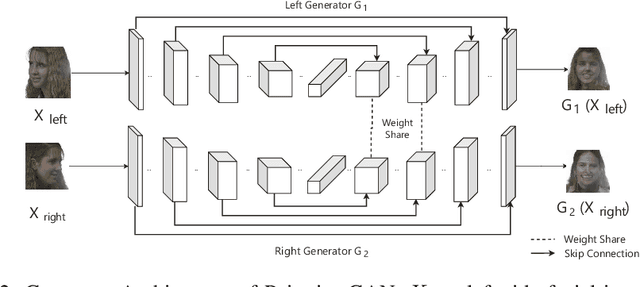
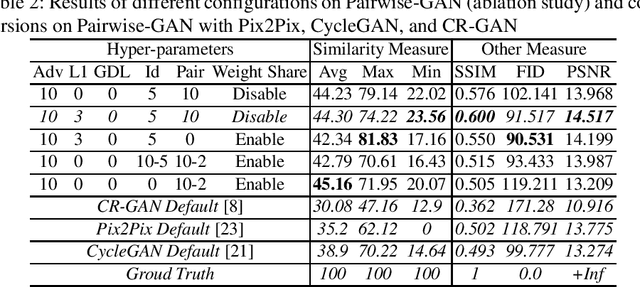
Three-dimensional face reconstruction is one of the popular applications in computer vision. However, even state-of-the-art models still require frontal face as inputs, which restricts its usage scenarios in the wild. A similar dilemma also happens in face recognition. New research designed to recover the frontal face from a single side-pose facial image has emerged. The state-of-the-art in this area is the Face-Transformation generative adversarial network, which is based on the CycleGAN. This inspired our research which explores the performance of two models from pixel transformation in frontal facial synthesis, Pix2Pix and CycleGAN. We conducted the experiments on five different loss functions on Pix2Pix to improve its performance, then followed by proposing a new network Pairwise-GAN in frontal facial synthesis. Pairwise-GAN uses two parallel U-Nets as the generator and PatchGAN as the discriminator. The detailed hyper-parameters are also discussed. Based on the quantitative measurement by face similarity comparison, our results showed that Pix2Pix with L1 loss, gradient difference loss, and identity loss results in 2.72% of improvement at average similarity compared to the default Pix2Pix model. Additionally, the performance of Pairwise-GAN is 5.4% better than the CycleGAN and 9.1% than the Pix2Pix at average similarity.