 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Benchmarking Image Sensors Under Adverse Weather Conditions for Autonomous Driving
Dec 06, 2019

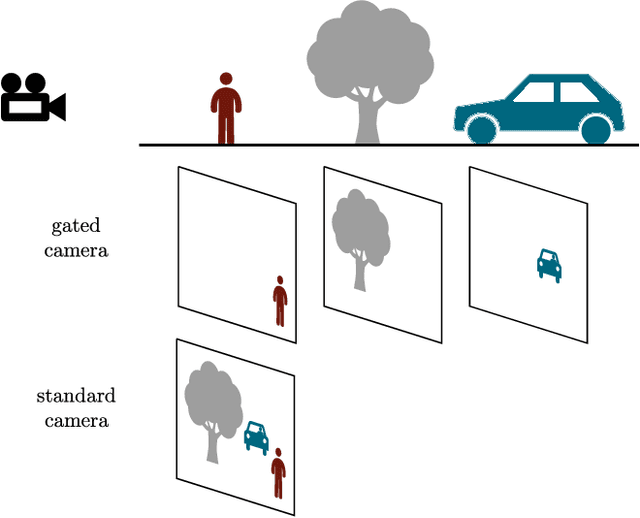

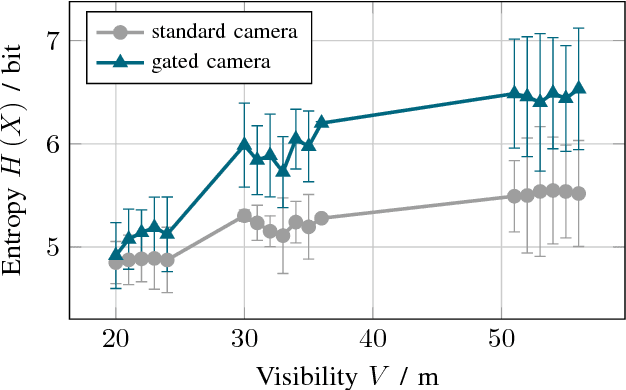
Adverse weather conditions are very challenging for autonomous driving because most of the state-of-the-art sensors stop working reliably under these conditions. In order to develop robust sensors and algorithms, tests with current sensors in defined weather conditions are crucial for determining the impact of bad weather for each sensor. This work describes a testing and evaluation methodology that helps to benchmark novel sensor technologies and compare them to state-of-the-art sensors. As an example, gated imaging is compared to standard imaging under foggy conditions. It is shown that gated imaging outperforms state-of-the-art standard passive imaging due to time-synchronized active illumination.
A Framework based on Deep Neural Networks to Extract Anatomy of Mosquitoes from Images
Jul 29, 2020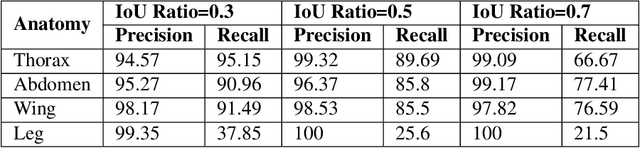
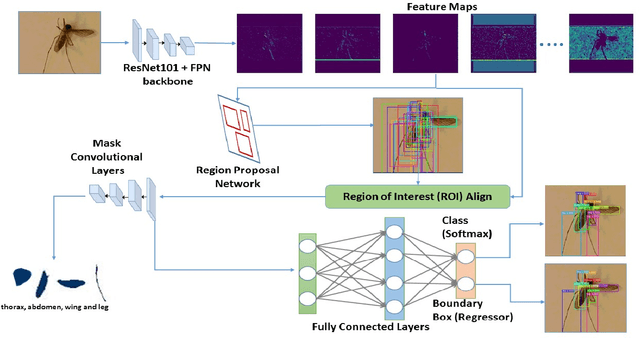
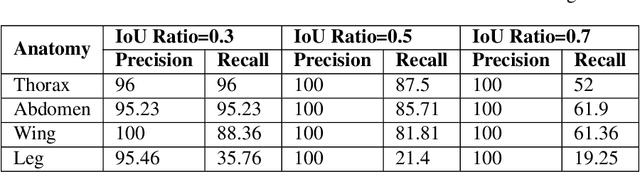

We design a framework based on Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect and separately extract anatomical components of mosquitoes - thorax, wings, abdomen and legs from images. Our training dataset consisted of 1500 smartphone images of nine mosquito species trapped in Florida. In the proposed technique, the first step is to detect anatomical components within a mosquito image. Then, we localize and classify the extracted anatomical components, while simultaneously adding a branch in the neural network architecture to segment pixels containing only the anatomical components. Evaluation results are favorable. To evaluate generality, we test our architecture trained only with mosquito images on bumblebee images. We again reveal favorable results, particularly in extracting wings. Our techniques in this paper have practical applications in public health, taxonomy and citizen-science efforts.
Learned Fine-Tuner for Incongruous Few-Shot Learning
Sep 29, 2020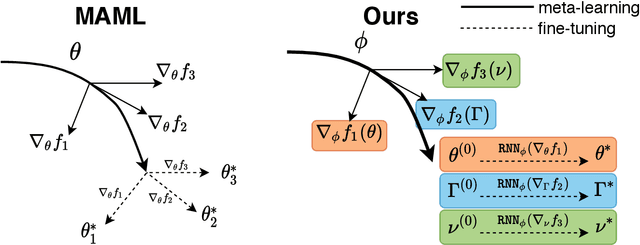
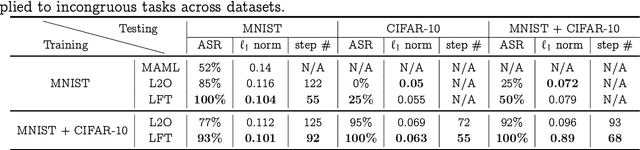
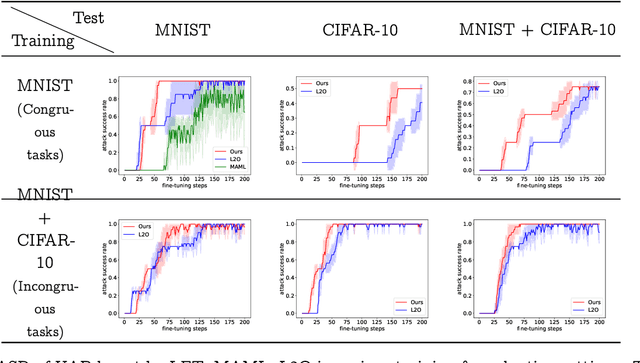
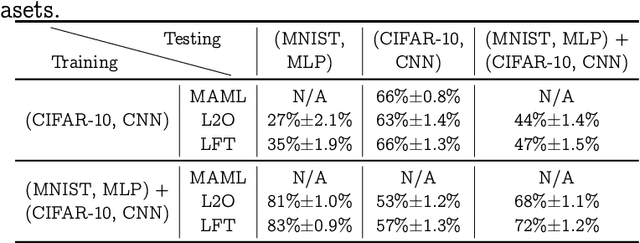
Model-agnostic meta-learning (MAML) effectively meta-learns an initialization of model parameters for few-shot learning where all learning problems share the same format of model parameters -- congruous meta-learning. We extend MAML to incongruous meta-learning where different yet related few-shot learning problems may not share any model parameters. In this setup, we propose the use of a Learned Fine Tuner (LFT) to replace hand-designed optimizers (such as SGD) for the task-specific fine-tuning. The meta-learned initialization in MAML is replaced by learned optimizers based on the learning-to-optimize (L2O) framework to meta-learn across incongruous tasks such that models fine-tuned with LFT (even from random initializations) adapt quickly to new tasks. The introduction of LFT within MAML (i) offers the capability to tackle few-shot learning tasks by meta-learning across incongruous yet related problems (e.g., classification over images of different sizes and model architectures), and (ii) can {efficiently} work with first-order and derivative-free few-shot learning problems. Theoretically, we quantify the difference between LFT (for MAML) and L2O. Empirically, we demonstrate the effectiveness of LFT through both synthetic and real problems and a novel application of generating universal adversarial attacks across different image sources in the few-shot learning regime.
Table Structure Recognition using Top-Down and Bottom-Up Cues
Oct 09, 2020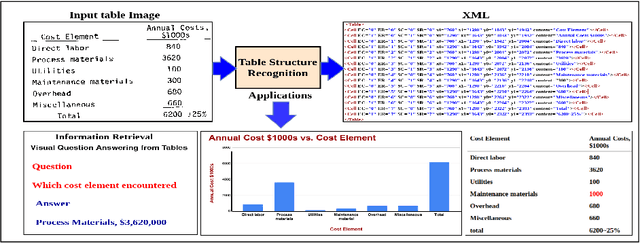

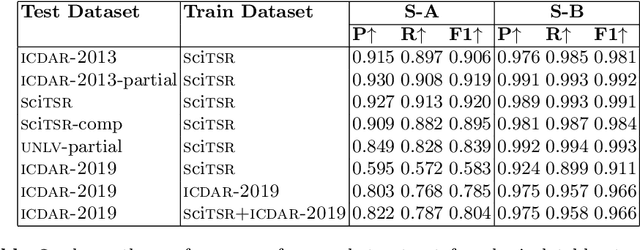
Tables are information-rich structured objects in document images. While significant work has been done in localizing tables as graphic objects in document images, only limited attempts exist on table structure recognition. Most existing literature on structure recognition depends on extraction of meta-features from the PDF document or on the optical character recognition (OCR) models to extract low-level layout features from the image. However, these methods fail to generalize well because of the absence of meta-features or errors made by the OCR when there is a significant variance in table layouts and text organization. In our work, we focus on tables that have complex structures, dense content, and varying layouts with no dependency on meta-features and/or OCR. We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells. We incorporate structural constraints as additional differential components to the loss function for cell detection. We empirically validate our method on the publicly available real-world datasets - ICDAR-2013, ICDAR-2019 (cTDaR) archival, UNLV, SciTSR, SciTSR-COMP, TableBank, and PubTabNet. Our attempt opens up a new direction for table structure recognition by combining top-down (table cells detection) and bottom-up (structure recognition) cues in visually understanding the tables.
Detecting soccer balls with reduced neural networks: a comparison of multiple architectures under constrained hardware scenarios
Sep 28, 2020
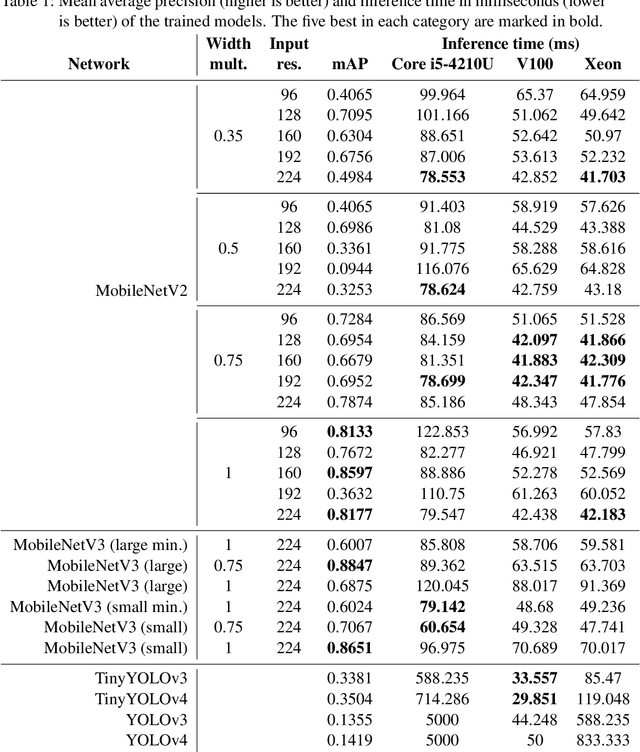
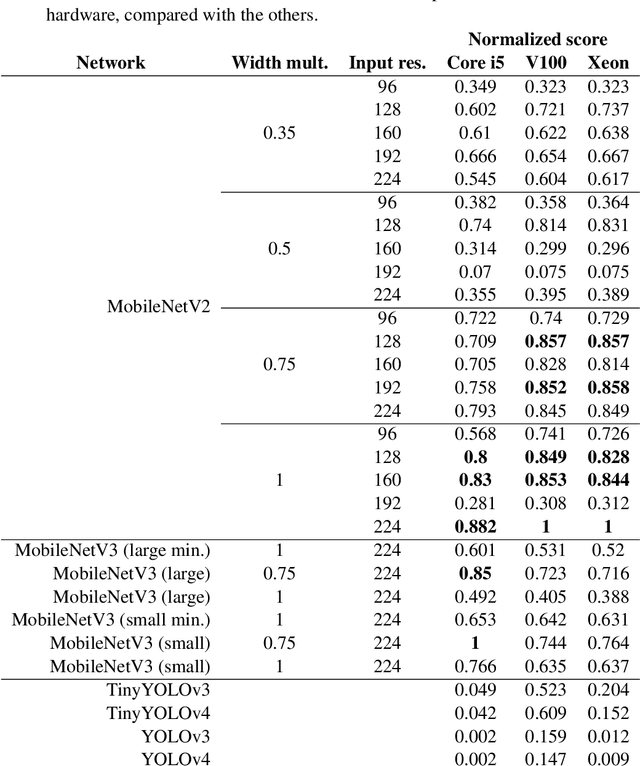
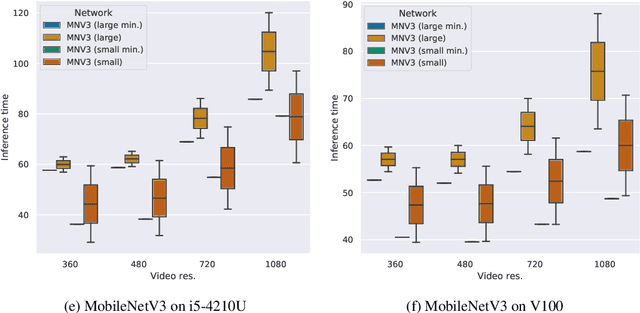
Object detection techniques that achieve state-of-the-art detection accuracy employ convolutional neural networks, implemented to have optimal performance in graphics processing units. Some hardware systems, such as mobile robots, operate under constrained hardware situations, but still benefit from object detection capabilities. Multiple network models have been proposed, achieving comparable accuracy with reduced architectures and leaner operations. Motivated by the need to create an object detection system for a soccer team of mobile robots, this work provides a comparative study of recent proposals of neural networks targeted towards constrained hardware environments, in the specific task of soccer ball detection. We train multiple open implementations of MobileNetV2 and MobileNetV3 models with different underlying architectures, as well as YOLOv3, TinyYOLOv3, YOLOv4 and TinyYOLOv4 in an annotated image data set captured using a mobile robot. We then report their mean average precision on a test data set and their inference times in videos of different resolutions, under constrained and unconstrained hardware configurations. Results show that MobileNetV3 models have a good trade-off between mAP and inference time in constrained scenarios only, while MobileNetV2 with high width multipliers are appropriate for server-side inference. YOLO models in their official implementations are not suitable for inference in CPUs.
A Robust Attentional Framework for License Plate Recognition in the Wild
Jun 09, 2020

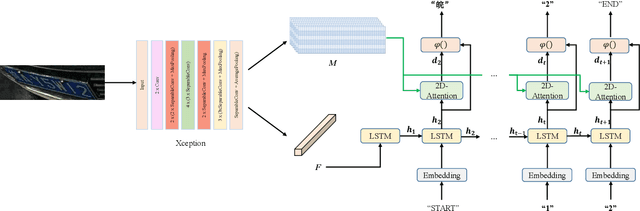
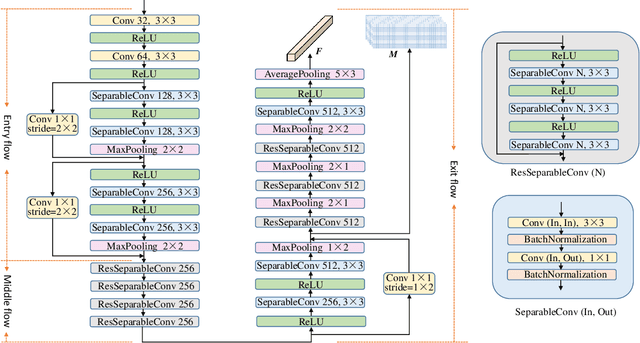
Recognizing car license plates in natural scene images is an important yet still challenging task in realistic applications. Many existing approaches perform well for license plates collected under constrained conditions, eg, shooting in frontal and horizontal view-angles and under good lighting conditions. However, their performance drops significantly in an unconstrained environment that features rotation, distortion, occlusion, blurring, shading or extreme dark or bright conditions. In this work, we propose a robust framework for license plate recognition in the wild. It is composed of a tailored CycleGAN model for license plate image generation and an elaborate designed image-to-sequence network for plate recognition. On one hand, the CycleGAN based plate generation engine alleviates the exhausting human annotation work. Massive amount of training data can be obtained with a more balanced character distribution and various shooting conditions, which helps to boost the recognition accuracy to a large extent. On the other hand, the 2D attentional based license plate recognizer with an Xception-based CNN encoder is capable of recognizing license plates with different patterns under various scenarios accurately and robustly. Without using any heuristics rule or post-processing, our method achieves the state-of-the-art performance on four public datasets, which demonstrates the generality and robustness of our framework. Moreover, we released a new license plate dataset, named "CLPD", with 1200 images from all 31 provinces in mainland China. The dataset can be available from: https://github.com/wangpengnorman/CLPD_dataset.
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017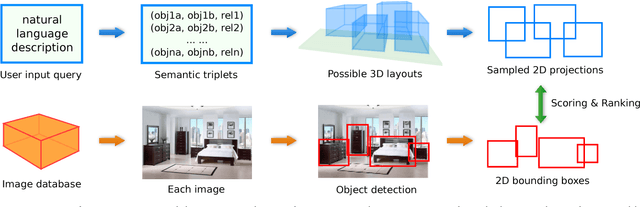

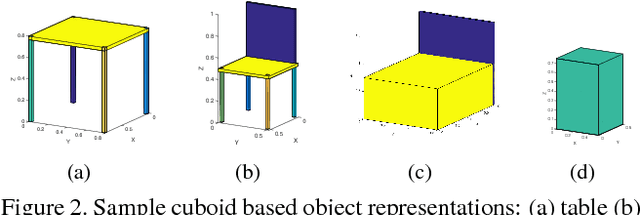
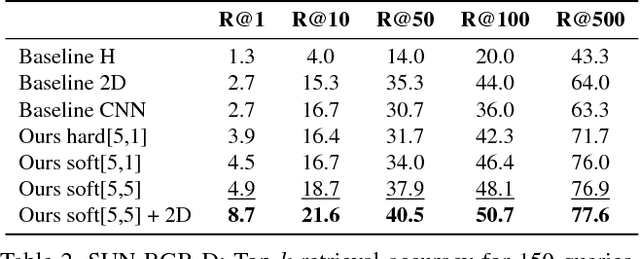
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
Covid-19: Automatic detection from X-Ray images utilizing Transfer Learning with Convolutional Neural Networks
Mar 25, 2020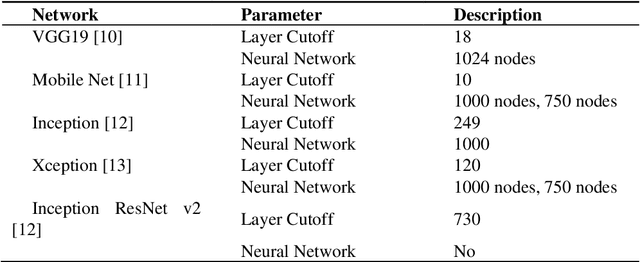
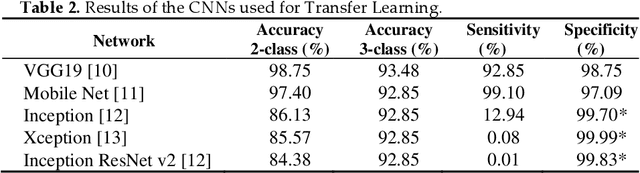

In this study, a dataset of X-Ray images from patients with common pneumonia, Covid-19, and normal incidents was utilized for the automatic detection of the Coronavirus. The aim of the study is to evaluate the performance of state-of-the-art Convolutional Neural Network architectures proposed over recent years for medical image classification. Specifically, the procedure called transfer learning was adopted. With transfer learning, the detection of various abnormalities in small medical image datasets is an achievable target, often yielding remarkable results. The dataset utilized in this experiment is a collection of 1427 X-Ray images. 224 images with confirmed Covid-19, 700 images with confirmed common pneumonia, and 504 images of normal conditions are included. The data was collected from the available X-Ray images on public medical repositories. With transfer learning, an overall accuracy of 97.82% in the detection of Covid-19 is achieved.
Histopathologic Image Processing: A Review
Apr 16, 2019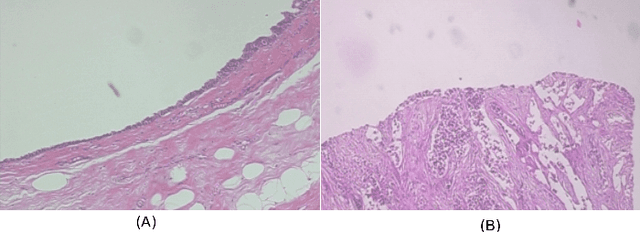
Histopathologic Images (HI) are the gold standard for evaluation of some tumors. However, the analysis of such images is challenging even for experienced pathologists, resulting in problems of inter and intra observer. Besides that, the analysis is time and resource consuming. One of the ways to accelerate such an analysis is by using Computer Aided Diagnosis systems. In this work we present a literature review about the computing techniques to process HI, including shallow and deep methods. We cover the most common tasks for processing HI such as segmentation, feature extraction, unsupervised learning and supervised learning. A dataset section show some datasets found during the literature review. We also bring a study case of breast cancer classification using a mix of deep and shallow machine learning methods. The proposed method obtained an accuracy of 91% in the best case, outperforming the compared baseline of the dataset.
MS and PAN image fusion by combining Brovey and wavelet methods
Jan 08, 2017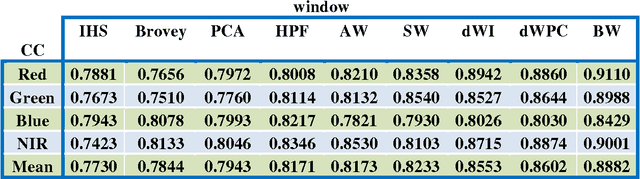


Among the existing fusion algorithms, the wavelet fusion method is the most frequently discussed one in recent publications because the wavelet approach preserves the spectral characteristics of the multispectral image better than other methods. The Brovey is also a popular fusion method used for its ability in preserving the spatial information of the PAN image. This study presents a new fusion approach that integrates the advantages of both the Brovey (which preserves a high degree of spatial information) and the wavelet (which preserves a high degree of spectral information) techniques to reduce the colour distortion of fusion results. Visual and statistical analyzes show that the proposed algorithm clearly improves the merging quality in terms of: correlation coefficient and UIQI; compared to fusion methods including, IHS, Brovey, PCA , HPF, discrete wavelet transform (DWT), and a-trous wavelet.