 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Subspace Capsule Network
Feb 07, 2020

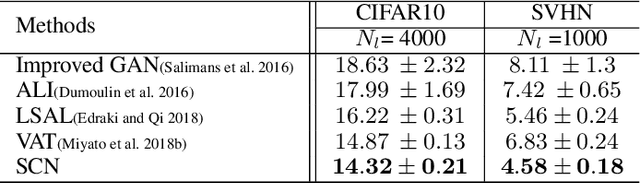
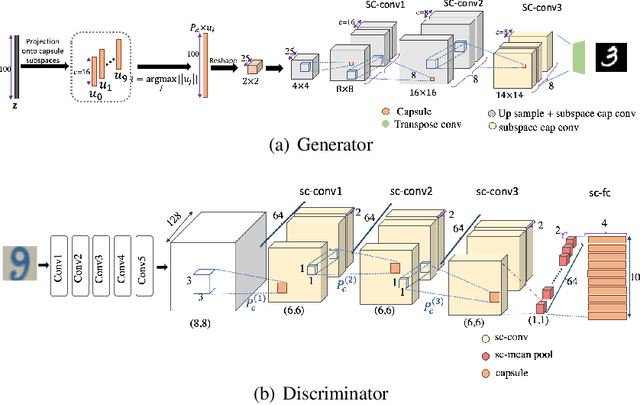

Convolutional neural networks (CNNs) have become a key asset to most of fields in AI. Despite their successful performance, CNNs suffer from a major drawback. They fail to capture the hierarchy of spatial relation among different parts of an entity. As a remedy to this problem, the idea of capsules was proposed by Hinton. In this paper, we propose the SubSpace Capsule Network (SCN) that exploits the idea of capsule networks to model possible variations in the appearance or implicitly defined properties of an entity through a group of capsule subspaces instead of simply grouping neurons to create capsules. A capsule is created by projecting an input feature vector from a lower layer onto the capsule subspace using a learnable transformation. This transformation finds the degree of alignment of the input with the properties modeled by the capsule subspace. We show that SCN is a general capsule network that can successfully be applied to both discriminative and generative models without incurring computational overhead compared to CNN during test time. Effectiveness of SCN is evaluated through a comprehensive set of experiments on supervised image classification, semi-supervised image classification and high-resolution image generation tasks using the generative adversarial network (GAN) framework. SCN significantly improves the performance of the baseline models in all 3 tasks.
Generative Adversarial Networks and Probabilistic Graph Models for Hyperspectral Image Classification
Feb 10, 2018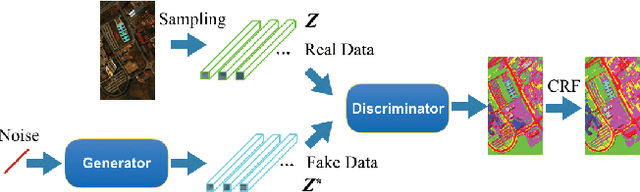
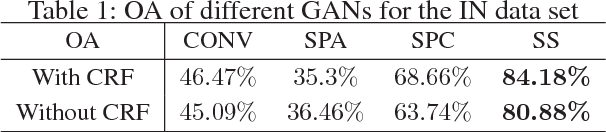

High spectral dimensionality and the shortage of annotations make hyperspectral image (HSI) classification a challenging problem. Recent studies suggest that convolutional neural networks can learn discriminative spatial features, which play a paramount role in HSI interpretation. However, most of these methods ignore the distinctive spectral-spatial characteristic of hyperspectral data. In addition, a large amount of unlabeled data remains an unexploited gold mine for efficient data use. Therefore, we proposed an integration of generative adversarial networks (GANs) and probabilistic graphical models for HSI classification. Specifically, we used a spectral-spatial generator and a discriminator to identify land cover categories of hyperspectral cubes. Moreover, to take advantage of a large amount of unlabeled data, we adopted a conditional random field to refine the preliminary classification results generated by GANs. Experimental results obtained using two commonly studied datasets demonstrate that the proposed framework achieved encouraging classification accuracy using a small number of data for training.
Frequency-Tuned Universal Adversarial Attacks
Mar 11, 2020
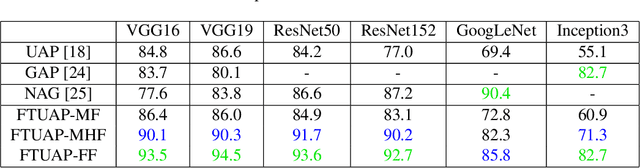
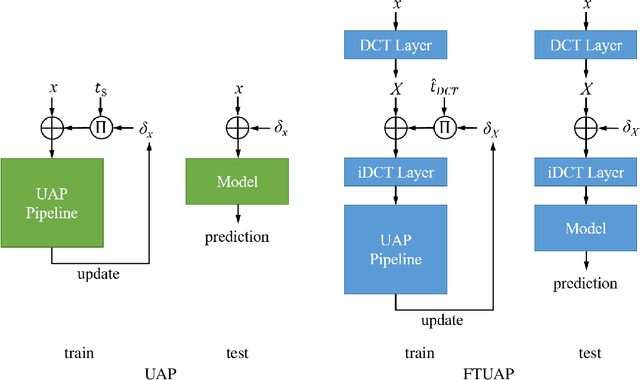

Researchers have shown that the predictions of a convolutional neural network (CNN) for an image set can be severely distorted by one single image-agnostic perturbation, or universal perturbation, usually with an empirically fixed threshold in the spatial domain to restrict its perceivability. However, by considering the human perception, we propose to adopt JND thresholds to guide the perceivability of universal adversarial perturbations. Based on this, we propose a frequency-tuned universal attack method to compute universal perturbations and show that our method can realize a good balance between perceivability and effectiveness in terms of fooling rate by adapting the perturbations to the local frequency content. Compared with existing universal adversarial attack techniques, our frequency-tuned attack method can achieve cutting-edge quantitative results. We demonstrate that our approach can significantly improve the performance of the baseline on both white-box and black-box attacks.
Vision Meets Wireless Positioning: Effective Person Re-identification with Recurrent Context Propagation
Sep 04, 2020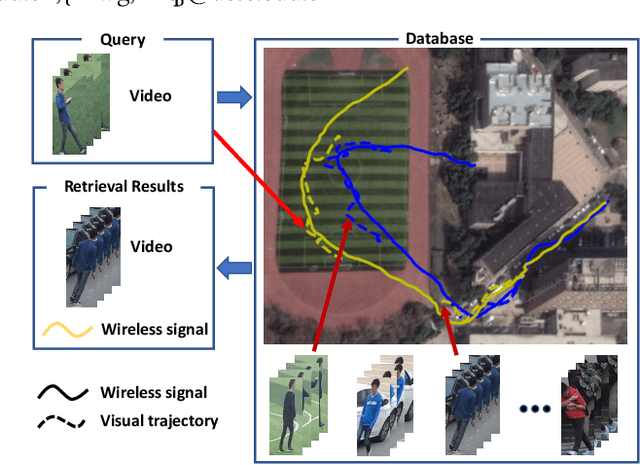


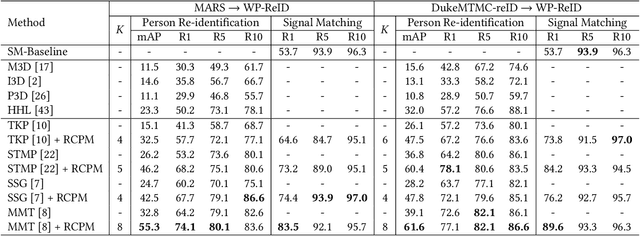
Existing person re-identification methods rely on the visual sensor to capture the pedestrians. The image or video data from visual sensor inevitably suffers the occlusion and dramatic variations of pedestrian postures, which degrades the re-identification performance and further limits its application to the open environment. On the other hand, for most people, one of the most important carry-on items is the mobile phone, which can be sensed by WiFi and cellular networks in the form of a wireless positioning signal. Such signal is robust to the pedestrian occlusion and visual appearance change, but suffers some positioning error. In this work, we approach person re-identification with the sensing data from both vision and wireless positioning. To take advantage of such cross-modality cues, we propose a novel recurrent context propagation module that enables information to propagate between visual data and wireless positioning data and finally improves the matching accuracy. To evaluate our approach, we contribute a new Wireless Positioning Person Re-identification (WP-ReID) dataset. Extensive experiments are conducted and demonstrate the effectiveness of the proposed algorithm. Code will be released at https://github.com/yolomax/WP-ReID.
Cross-modal Center Loss
Aug 08, 2020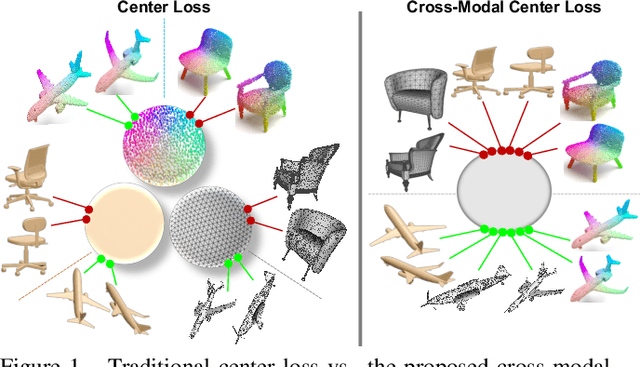
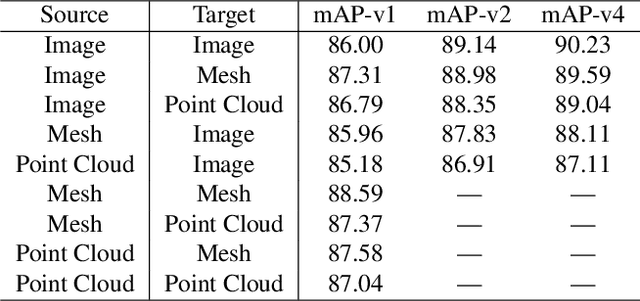
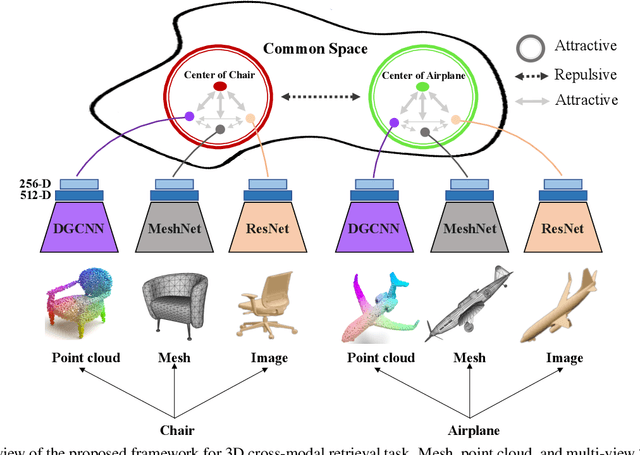
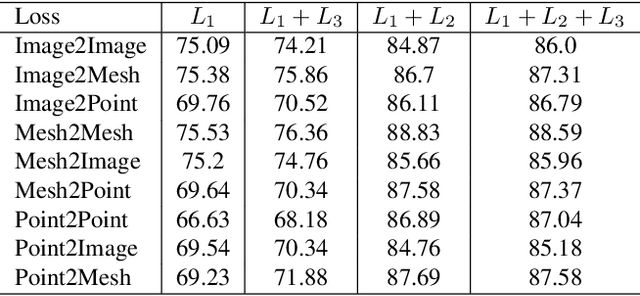
Cross-modal retrieval aims to learn discriminative and modal-invariant features for data from different modalities. Unlike the existing methods which usually learn from the features extracted by offline networks, in this paper, we propose an approach to jointly train the components of cross-modal retrieval framework with metadata, and enable the network to find optimal features. The proposed end-to-end framework is updated with three loss functions: 1) a novel cross-modal center loss to eliminate cross-modal discrepancy, 2) cross-entropy loss to maximize inter-class variations, and 3) mean-square-error loss to reduce modality variations. In particular, our proposed cross-modal center loss minimizes the distances of features from objects belonging to the same class across all modalities. Extensive experiments have been conducted on the retrieval tasks across multi-modalities, including 2D image, 3D point cloud, and mesh data. The proposed framework significantly outperforms the state-of-the-art methods on the ModelNet40 dataset.
Discovering beautiful attributes for aesthetic image analysis
Dec 16, 2014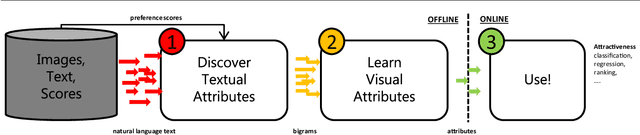
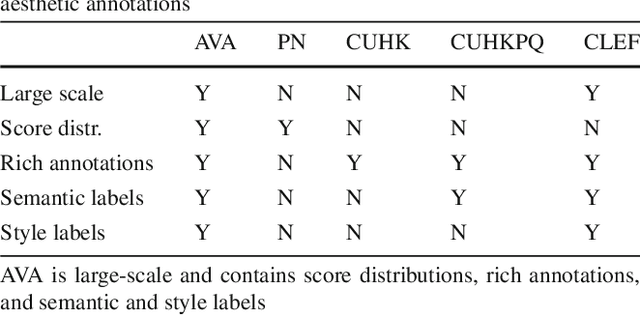

Aesthetic image analysis is the study and assessment of the aesthetic properties of images. Current computational approaches to aesthetic image analysis either provide accurate or interpretable results. To obtain both accuracy and interpretability by humans, we advocate the use of learned and nameable visual attributes as mid-level features. For this purpose, we propose to discover and learn the visual appearance of attributes automatically, using a recently introduced database, called AVA, which contains more than 250,000 images together with their aesthetic scores and textual comments given by photography enthusiasts. We provide a detailed analysis of these annotations as well as the context in which they were given. We then describe how these three key components of AVA - images, scores, and comments - can be effectively leveraged to learn visual attributes. Lastly, we show that these learned attributes can be successfully used in three applications: aesthetic quality prediction, image tagging and retrieval.
A Method of Detecting End-To-End Curves of Limited Curvature
Dec 04, 2019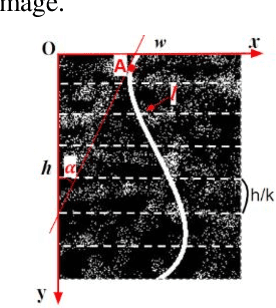

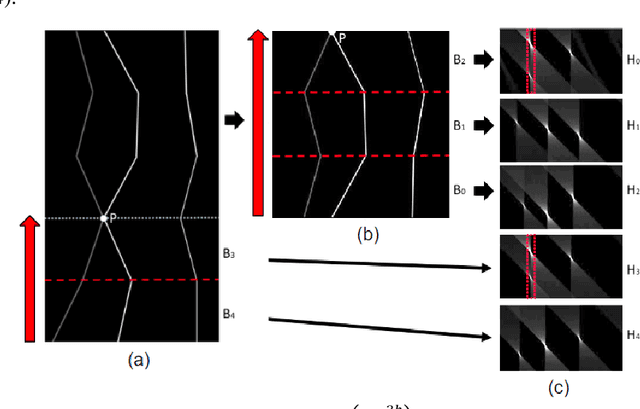
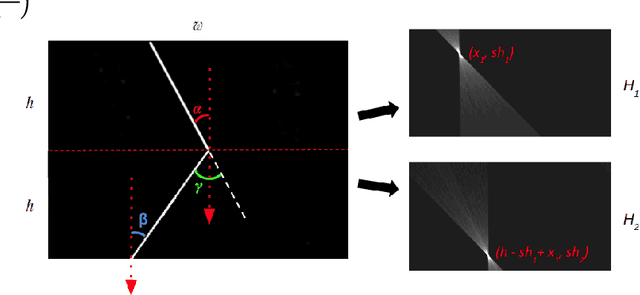
In this paper we consider a method for detecting end-to-end curves of limited curvature like the k-link polylines with bending angle between adjacent segments in a given range. The approximation accuracy is achieved by maximization of the quality function in the image matrix. The method is based on a dynamic programming scheme constructed over Fast Hough Transform calculation results for image bands. The proposed method asymptotic complexity is $O(h \cdot (w+ \frac{h}{k}) \cdot log(\frac{h}{k}))$, where $h$ and $w$ are the image size, and $k$ is the approximating polyline links number, which is an analogue of the complexity of the fast Fourier transform or the fast Hough transform. We also show the results of the proposed method on synthetic and real data.
Multilayer Dense Connections for Hierarchical Concept Classification
Mar 19, 2020
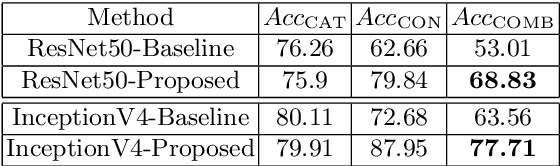
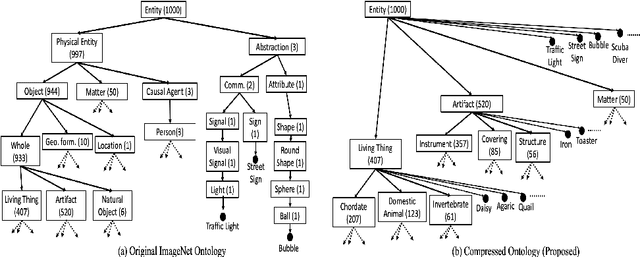
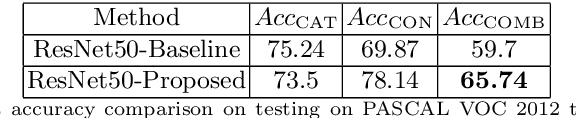
Classification is a pivotal function for many computer vision tasks such as object classification, detection, scene segmentation. Multinomial logistic regression with a single final layer of dense connections has become the ubiquitous technique for CNN-based classification. While these classifiers learn a mapping between the input and a set of output category classes, they do not typically learn a comprehensive knowledge about the category. In particular, when a CNN based image classifier correctly identifies the image of a Chimpanzee, it does not know that it is a member of Primate, Mammal, Chordate families and a living thing. We propose a multilayer dense connectivity for a CNN to simultaneously predict the category and its conceptual superclasses in hierarchical order. We experimentally demonstrate that our proposed dense connections, in conjunction with popular convolutional feature layers, can learn to predict the conceptual classes with minimal increase in network size while maintaining the categorical classification accuracy.
Exemplary Natural Images Explain CNN Activations Better than Feature Visualizations
Oct 23, 2020

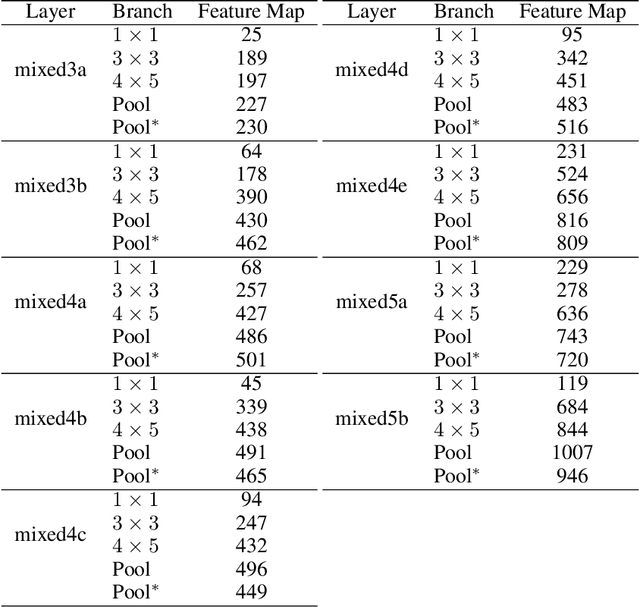
Feature visualizations such as synthetic maximally activating images are a widely used explanation method to better understand the information processing of convolutional neural networks (CNNs). At the same time, there are concerns that these visualizations might not accurately represent CNNs' inner workings. Here, we measure how much extremely activating images help humans to predict CNN activations. Using a well-controlled psychophysical paradigm, we compare the informativeness of synthetic images (Olah et al., 2017) with a simple baseline visualization, namely exemplary natural images that also strongly activate a specific feature map. Given either synthetic or natural reference images, human participants choose which of two query images leads to strong positive activation. The experiment is designed to maximize participants' performance, and is the first to probe intermediate instead of final layer representations. We find that synthetic images indeed provide helpful information about feature map activations (82% accuracy; chance would be 50%). However, natural images-originally intended to be a baseline-outperform synthetic images by a wide margin (92% accuracy). Additionally, participants are faster and more confident for natural images, whereas subjective impressions about the interpretability of feature visualization are mixed. The higher informativeness of natural images holds across most layers, for both expert and lay participants as well as for hand- and randomly-picked feature visualizations. Even if only a single reference image is given, synthetic images provide less information than natural images (65% vs. 73%). In summary, popular synthetic images from feature visualizations are significantly less informative for assessing CNN activations than natural images. We argue that future visualization methods should improve over this simple baseline.
Unsupervised Pansharpening Based on Self-Attention Mechanism
Jun 16, 2020

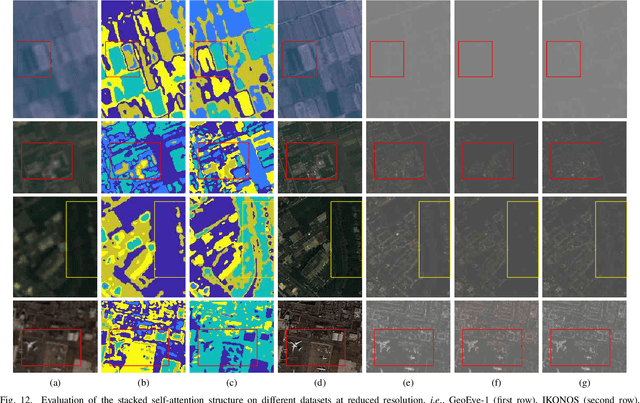

Pansharpening is to fuse a multispectral image (MSI) of low-spatial-resolution (LR) but rich spectral characteristics with a panchromatic image (PAN) of high-spatial-resolution (HR) but poor spectral characteristics. Traditional methods usually inject the extracted high-frequency details from PAN into the up-sampled MSI. Recent deep learning endeavors are mostly supervised assuming the HR MSI is available, which is unrealistic especially for satellite images. Nonetheless, these methods could not fully exploit the rich spectral characteristics in the MSI. Due to the wide existence of mixed pixels in satellite images where each pixel tends to cover more than one constituent material, pansharpening at the subpixel level becomes essential. In this paper, we propose an unsupervised pansharpening (UP) method in a deep-learning framework to address the above challenges based on the self-attention mechanism (SAM), referred to as UP-SAM. The contribution of this paper is three-fold. First, the self-attention mechanism is proposed where the spatial varying detail extraction and injection functions are estimated according to the attention representations indicating spectral characteristics of the MSI with sub-pixel accuracy. Second, such attention representations are derived from mixed pixels with the proposed stacked attention network powered with a stick-breaking structure to meet the physical constraints of mixed pixel formulations. Third, the detail extraction and injection functions are spatial varying based on the attention representations, which largely improves the reconstruction accuracy. Extensive experimental results demonstrate that the proposed approach is able to reconstruct sharper MSI of different types, with more details and less spectral distortion as compared to the state-of-the-art.