 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brain Tumor Segmentation by Cascaded Deep Neural Networks Using Multiple Image Scales
Feb 05, 2020
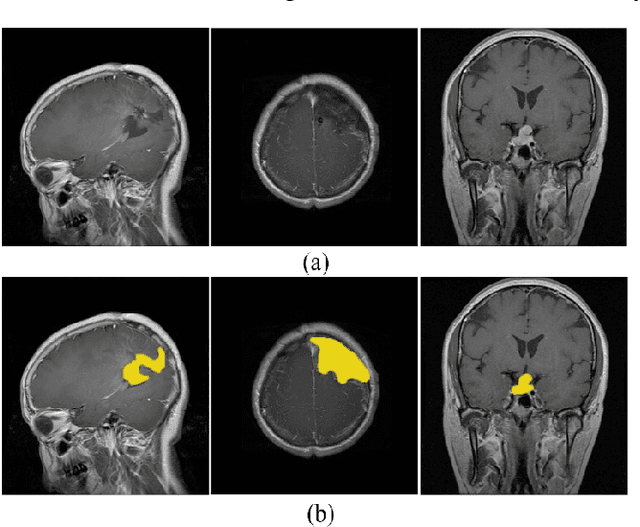
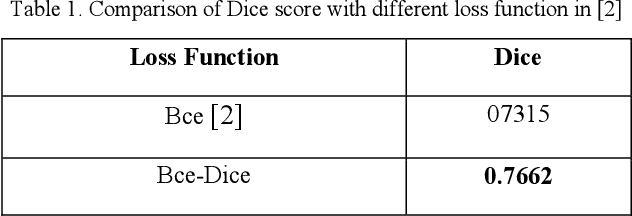
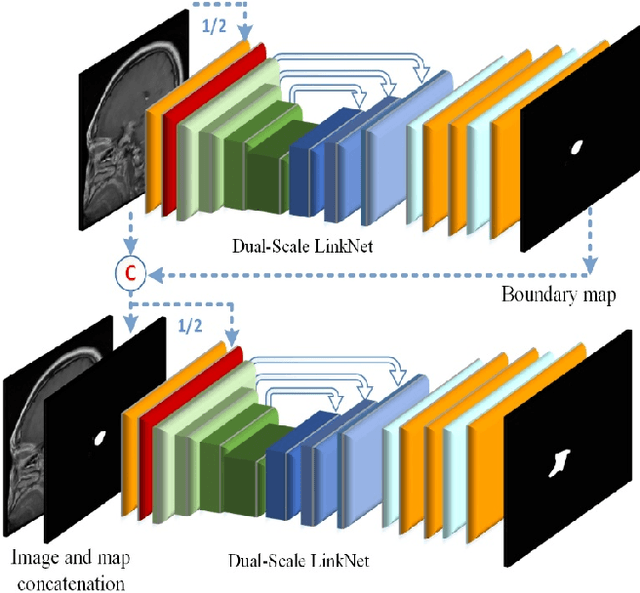
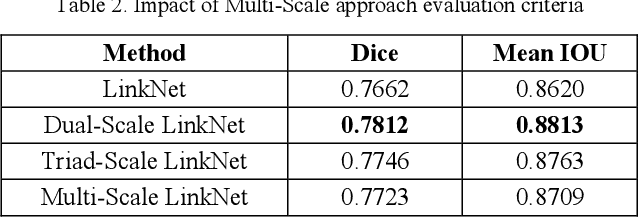
Intracranial tumors are groups of cells that usually grow uncontrollably. One out of four cancer deaths is due to brain tumors. Early detection and evaluation of brain tumors is an essential preventive medical step that is performed by magnetic resonance imaging (MRI). Many segmentation techniques exist for this purpose. Low segmentation accuracy is the main drawback of existing methods. In this paper, we use a deep learning method to boost the accuracy of tumor segmentation in MR images. Cascade approach is used with multiple scales of images to induce both local and global views and help the network to reach higher accuracies. Our experimental results show that using multiple scales and the utilization of two cascade networks is advantageous.
StereoGAN: Bridging Synthetic-to-Real Domain Gap by Joint Optimization of Domain Translation and Stereo Matching
May 05, 2020
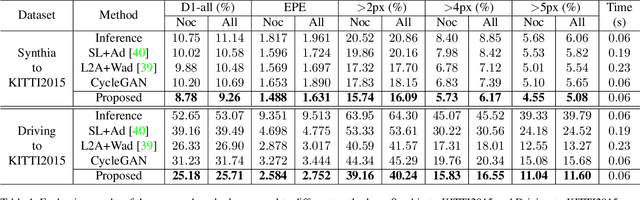

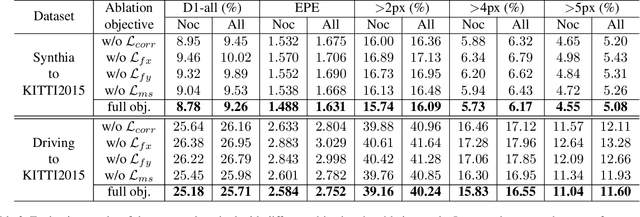
Large-scale synthetic datasets are beneficial to stereo matching but usually introduce known domain bias. Although unsupervised image-to-image translation networks represented by CycleGAN show great potential in dealing with domain gap, it is non-trivial to generalize this method to stereo matching due to the problem of pixel distortion and stereo mismatch after translation. In this paper, we propose an end-to-end training framework with domain translation and stereo matching networks to tackle this challenge. First, joint optimization between domain translation and stereo matching networks in our end-to-end framework makes the former facilitate the latter one to the maximum extent. Second, this framework introduces two novel losses, i.e., bidirectional multi-scale feature re-projection loss and correlation consistency loss, to help translate all synthetic stereo images into realistic ones as well as maintain epipolar constraints. The effective combination of above two contributions leads to impressive stereo-consistent translation and disparity estimation accuracy. In addition, a mode seeking regularization term is added to endow the synthetic-to-real translation results with higher fine-grained diversity. Extensive experiments demonstrate the effectiveness of the proposed framework on bridging the synthetic-to-real domain gap on stereo matching.
Presentation and Analysis of a Multimodal Dataset for Grounded LanguageLearning
Jul 31, 2020
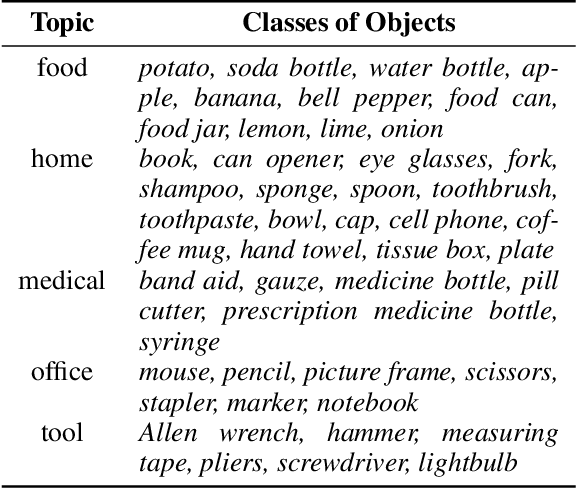


Grounded language acquisition -- learning how language-based interactions refer to the world around them -- is amajor area of research in robotics, NLP, and HCI. In practice the data used for learning consists almost entirely of textual descriptions, which tend to be cleaner, clearer, and more grammatical than actual human interactions. In this work, we present the Grounded Language Dataset (GoLD), a multimodal dataset of common household objects described by people using either spoken or written language. We analyze the differences and present an experiment showing how the different modalities affect language learning from human in-put. This will enable researchers studying the intersection of robotics, NLP, and HCI to better investigate how the multiple modalities of image, text, and speech interact, as well as show differences in the vernacular of these modalities impact results.
Using Segmentation Masks in the ICCV 2019 Learning to Drive Challenge
Oct 23, 2019

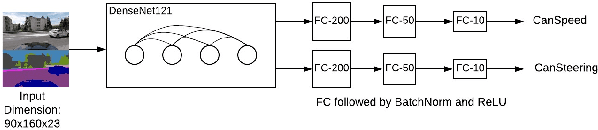
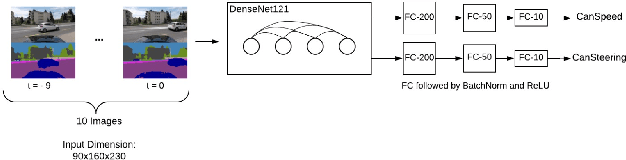
In this work we predict vehicle speed and steering angle given camera image frames. Our key contribution is using an external pre-trained neural network for segmentation. We augment the raw images with their segmentation masks and mirror images. We ensemble three diverse neural network models (i) a CNN using a single image and its segmentation mask, (ii) a stacked CNN taking as input a sequence of images and segmentation masks, and (iii) a bidirectional GRU, extracting image features using a pre-trained ResNet34, DenseNet121 and our own CNN single image model. We achieve the second best performance for MSE angle and second best performance overall, to win 2nd place in the ICCV Learning to Drive challenge. We make our models and code publicly available.
Models Genesis
Apr 09, 2020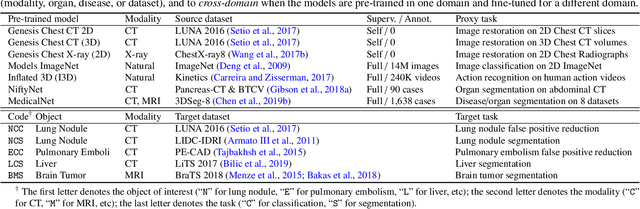
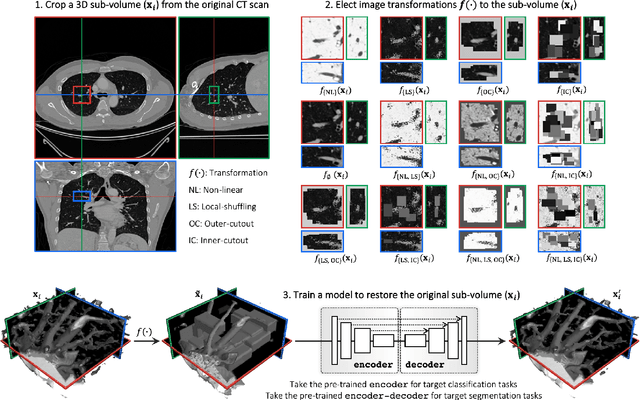
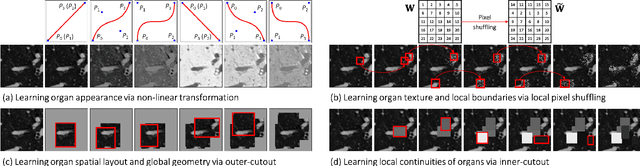
Transfer learning from natural image to medical image has been established as one of the most practical paradigms in deep learning for medical image analysis. To fit this paradigm, however, 3D imaging tasks in the most prominent imaging modalities (e.g., CT and MRI) have to be reformulated and solved in 2D, losing rich 3D anatomical information, thereby inevitably compromising its performance. To overcome this limitation, we have built a set of models, called Generic Autodidactic Models, nicknamed Models Genesis, because they are created ex nihilo (with no manual labeling), self-taught (learnt by self-supervision), and generic (served as source models for generating application-specific target models). Our extensive experiments demonstrate that our Models Genesis significantly outperform learning from scratch in all five target 3D applications covering both segmentation and classification. More importantly, learning a model from scratch simply in 3D may not necessarily yield performance better than transfer learning from ImageNet in 2D, but our Models Genesis consistently top any 2D/2.5D approaches including fine-tuning the models pre-trained from ImageNet as well as fine-tuning the 2D versions of our Models Genesis, confirming the importance of 3D anatomical information and significance of Models Genesis for 3D medical imaging. This performance is attributed to our unified self-supervised learning framework, built on a simple yet powerful observation: the sophisticated and recurrent anatomy in medical images can serve as strong yet free supervision signals for deep models to learn common anatomical representation automatically via self-supervision. As open science, all codes and pre-trained Models Genesis are available at https://github.com/MrGiovanni/ModelsGenesis
Grading the Severity of Arteriolosclerosis from Retinal Arterio-venous Crossing Patterns
Nov 07, 2020
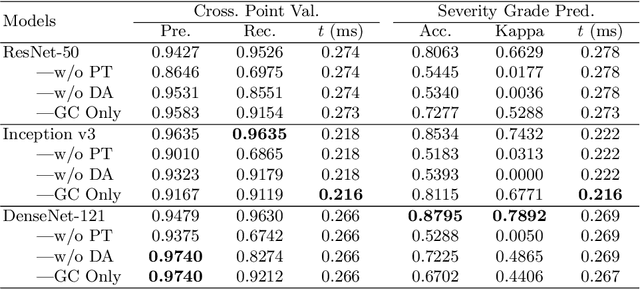
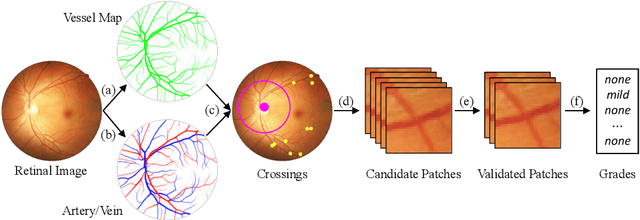
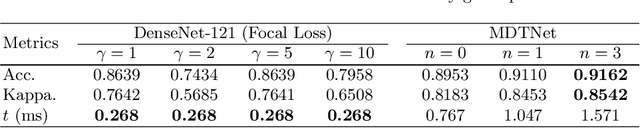
The status of retinal arteriovenous crossing is of great significance for clinical evaluation of arteriolosclerosis and systemic hypertension. As an ophthalmology diagnostic criteria, Scheie's classification has been used to grade the severity of arteriolosclerosis. In this paper, we propose a deep learning approach to support the diagnosis process, which, to the best of our knowledge, is one of the earliest attempts in medical imaging. The proposed pipeline is three-fold. First, we adopt segmentation and classification models to automatically obtain vessels in a retinal image with the corresponding artery/vein labels and find candidate arteriovenous crossing points. Second, we use a classification model to validate the true crossing point. At last, the grade of severity for the vessel crossings is classified. To better address the problem of label ambiguity and imbalanced label distribution, we propose a new model, named multi-diagnosis team network (MDTNet), in which the sub-models with different structures or different loss functions provide different decisions. MDTNet unifies these diverse theories to give the final decision with high accuracy. Our severity grading method was able to validate crossing points with precision and recall of 96.3% and 96.3%, respectively. Among correctly detected crossing points, the kappa value for the agreement between the grading by a retina specialist and the estimated score was 0.85, with an accuracy of 0.92. The numerical results demonstrate that our method can achieve a good performance in both arteriovenous crossing validation and severity grading tasks. By the proposed models, we could build a pipeline reproducing retina specialist's subjective grading without feature extractions. The code is available for reproducibility.
Cosmetic-Aware Makeup Cleanser
Apr 20, 2020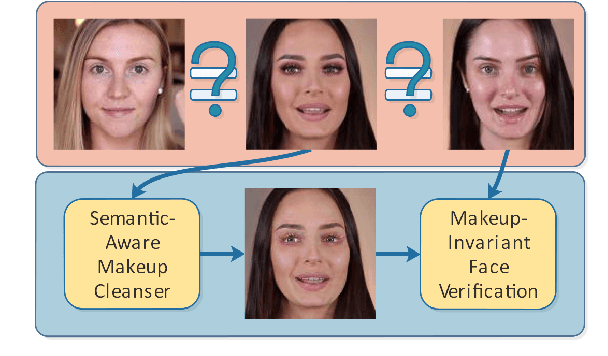
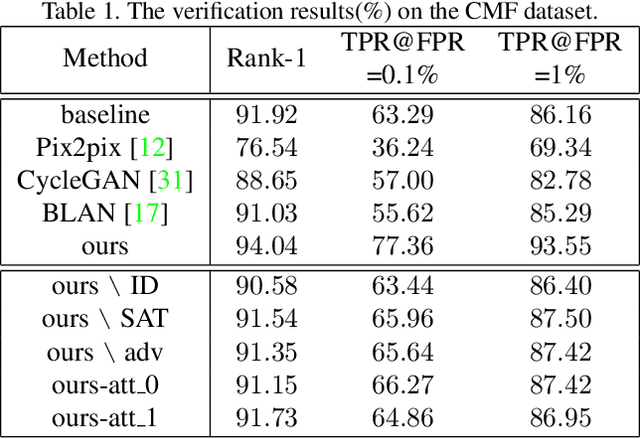
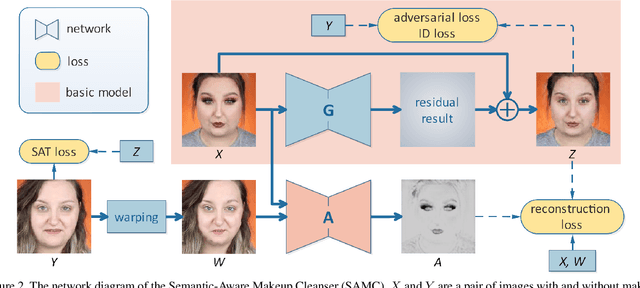

Face verification aims at determining whether a pair of face images belongs to the same identity. Recent studies have revealed the negative impact of facial makeup on the verification performance. With the rapid development of deep generative models, this paper proposes a semanticaware makeup cleanser (SAMC) to remove facial makeup under different poses and expressions and achieve verification via generation. The intuition lies in the fact that makeup is a combined effect of multiple cosmetics and tailored treatments should be imposed on different cosmetic regions. To this end, we present both unsupervised and supervised semantic-aware learning strategies in SAMC. At image level, an unsupervised attention module is jointly learned with the generator to locate cosmetic regions and estimate the degree. At feature level, we resort to the effort of face parsing merely in training phase and design a localized texture loss to serve complements and pursue superior synthetic quality. The experimental results on four makeuprelated datasets verify that SAMC not only produces appealing de-makeup outputs at a resolution of 256*256, but also facilitates makeup-invariant face verification through image generation.
Cost-efficient segmentation of electron microscopy images using active learning
Nov 13, 2019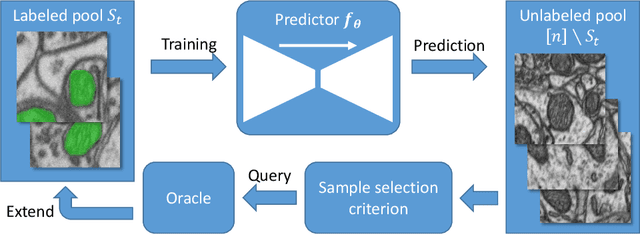
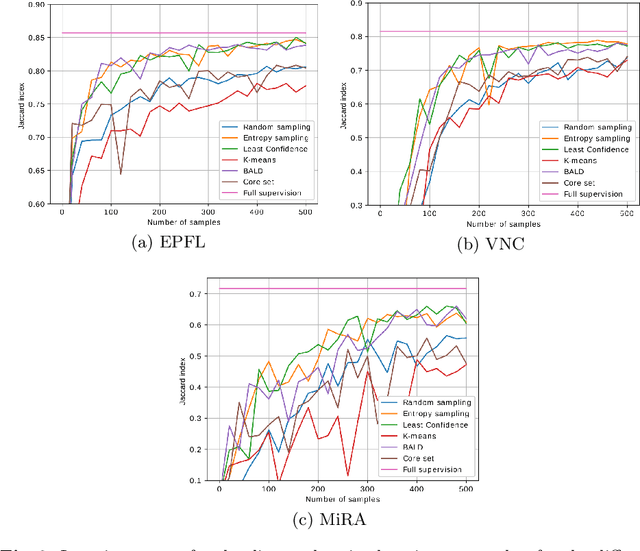

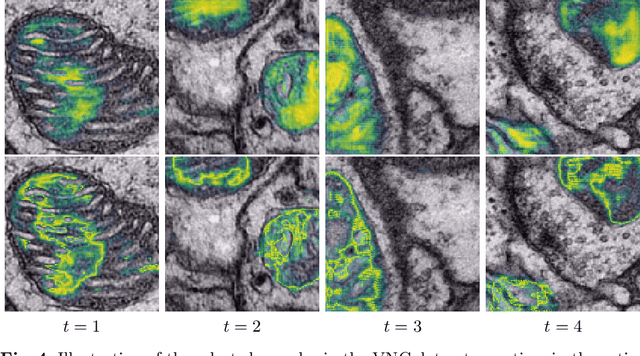
Over the last decade, electron microscopy has improved up to a point that generating high quality gigavoxel sized datasets only requires a few hours. Automated image analysis, particularly image segmentation, however, has not evolved at the same pace. Even though state-of-the-art methods such as U-Net and DeepLab have improved segmentation performance substantially, the required amount of labels remains too expensive. Active learning is the subfield in machine learning that aims to mitigate this burden by selecting the samples that require labeling in a smart way. Many techniques have been proposed, particularly for image classification, to increase the steepness of learning curves. In this work, we extend these techniques to deep CNN based image segmentation. Our experiments on three different electron microscopy datasets show that active learning can improve segmentation quality by 10 to 15% in terms of Jaccard score compared to standard randomized sampling.
Phase recovery and holographic image reconstruction using deep learning in neural networks
May 10, 2017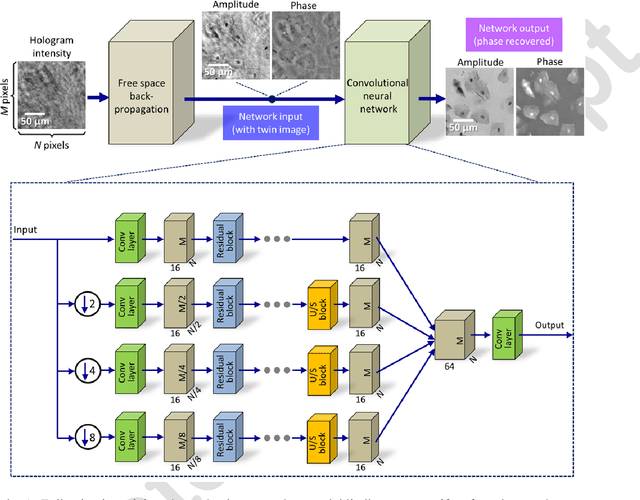

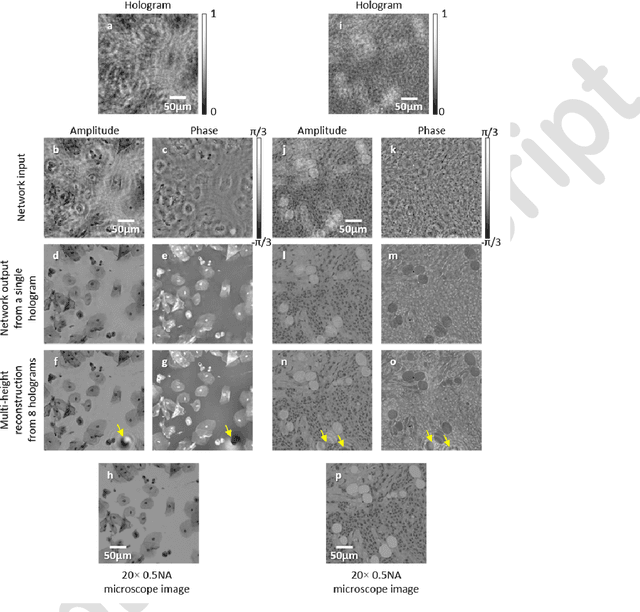

Phase recovery from intensity-only measurements forms the heart of coherent imaging techniques and holography. Here we demonstrate that a neural network can learn to perform phase recovery and holographic image reconstruction after appropriate training. This deep learning-based approach provides an entirely new framework to conduct holographic imaging by rapidly eliminating twin-image and self-interference related spatial artifacts. Compared to existing approaches, this neural network based method is significantly faster to compute, and reconstructs improved phase and amplitude images of the objects using only one hologram, i.e., requires less number of measurements in addition to being computationally faster. We validated this method by reconstructing phase and amplitude images of various samples, including blood and Pap smears, and tissue sections. These results are broadly applicable to any phase recovery problem, and highlight that through machine learning challenging problems in imaging science can be overcome, providing new avenues to design powerful computational imaging systems.
Loss-rescaling VQA: Revisiting Language Prior Problem from a Class-imbalance View
Oct 30, 2020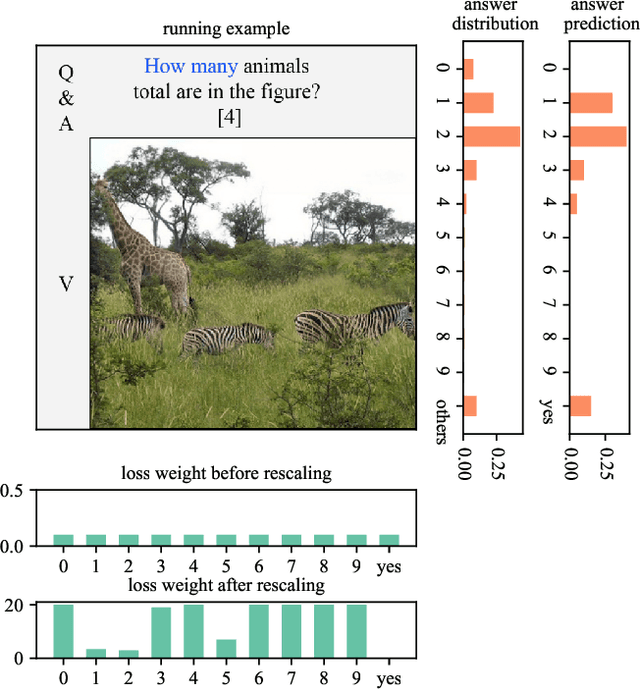
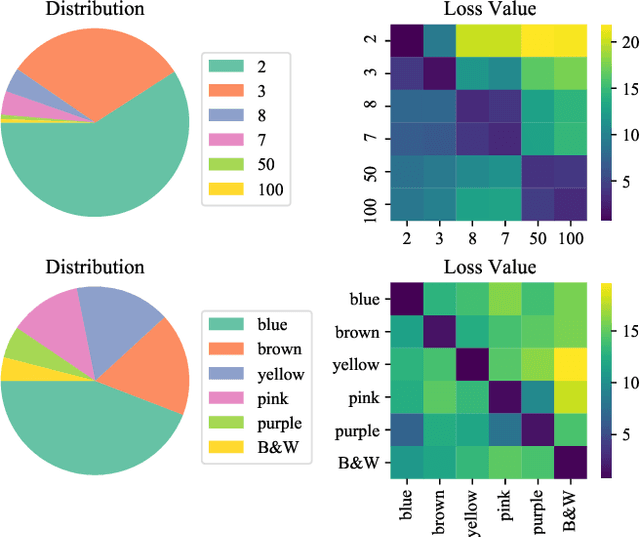
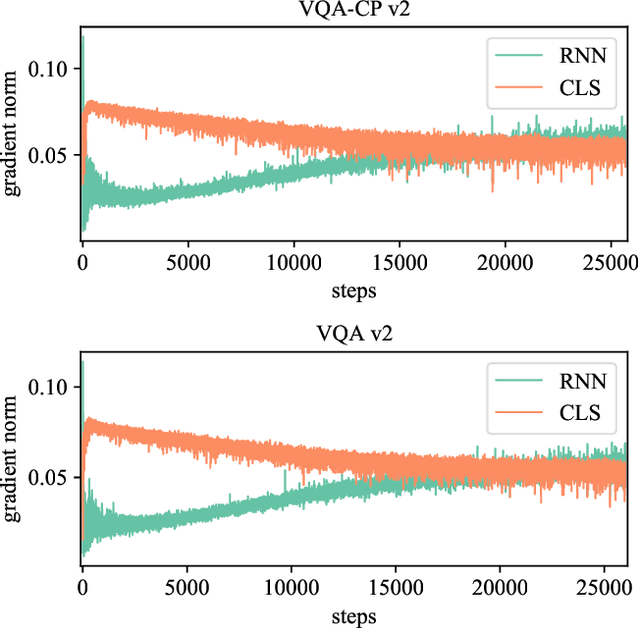
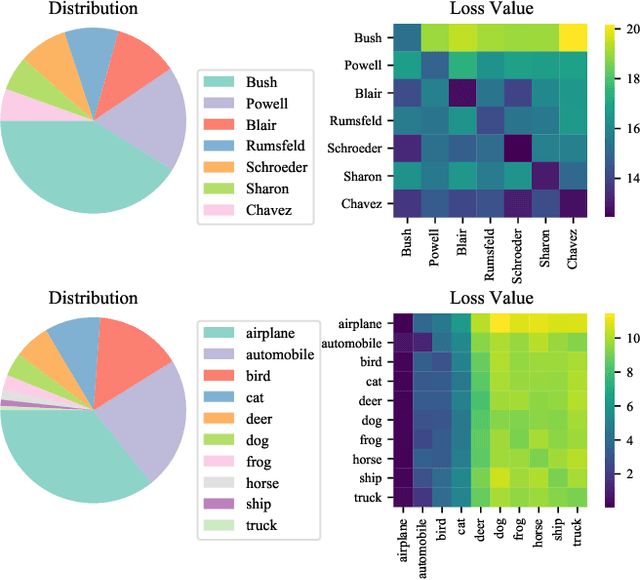
Recent studies have pointed out that many well-developed Visual Question Answering (VQA) models are heavily affected by the language prior problem, which refers to making predictions based on the co-occurrence pattern between textual questions and answers instead of reasoning visual contents. To tackle it, most existing methods focus on enhancing visual feature learning to reduce this superficial textual shortcut influence on VQA model decisions. However, limited effort has been devoted to providing an explicit interpretation for its inherent cause. It thus lacks a good guidance for the research community to move forward in a purposeful way, resulting in model construction perplexity in overcoming this non-trivial problem. In this paper, we propose to interpret the language prior problem in VQA from a class-imbalance view. Concretely, we design a novel interpretation scheme whereby the loss of mis-predicted frequent and sparse answers of the same question type is distinctly exhibited during the late training phase. It explicitly reveals why the VQA model tends to produce a frequent yet obviously wrong answer, to a given question whose right answer is sparse in the training set. Based upon this observation, we further develop a novel loss re-scaling approach to assign different weights to each answer based on the training data statistics for computing the final loss. We apply our approach into three baselines and the experimental results on two VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify the validity of the class imbalance interpretation scheme on other computer vision tasks, such as face recognition and image classification.