 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Precise Robot Localization in Architectural 3D Plans
Jun 09, 2020
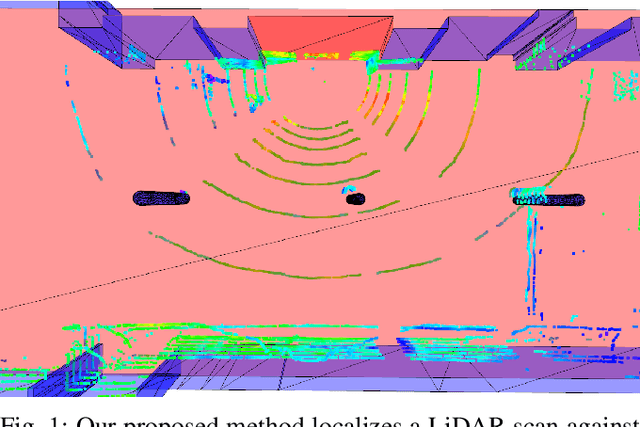

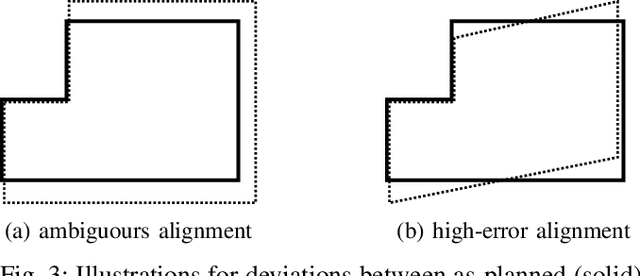

This paper presents a localization system for mobile robots enabling precise localization in inaccurate building models. The approach leverages local referencing to counteract inherent deviations between as-planned and as-built data for locally accurate registration. We further fuse a novel image-based robust outlier detector with LiDAR data to reject a wide range of outlier measurements from clutter, dynamic objects, and sensor failures. We evaluate the proposed approach on a mobile robot in a challenging real world building construction site. It consistently outperforms the traditional ICP-based alingment, reducing localization error by at least 30%.
Supervised mid-level features for word image representation
Nov 14, 2014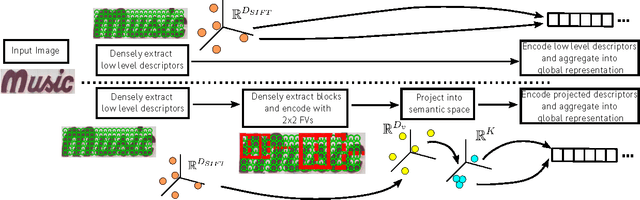

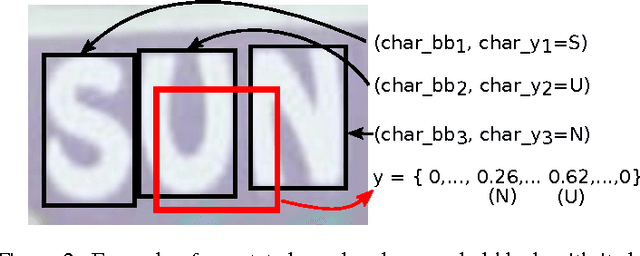
This paper addresses the problem of learning word image representations: given the cropped image of a word, we are interested in finding a descriptive, robust, and compact fixed-length representation. Machine learning techniques can then be supplied with these representations to produce models useful for word retrieval or recognition tasks. Although many works have focused on the machine learning aspect once a global representation has been produced, little work has been devoted to the construction of those base image representations: most works use standard coding and aggregation techniques directly on top of standard computer vision features such as SIFT or HOG. We propose to learn local mid-level features suitable for building word image representations. These features are learnt by leveraging character bounding box annotations on a small set of training images. However, contrary to other approaches that use character bounding box information, our approach does not rely on detecting the individual characters explicitly at testing time. Our local mid-level features can then be aggregated to produce a global word image signature. When pairing these features with the recent word attributes framework of Almaz\'an et al., we obtain results comparable with or better than the state-of-the-art on matching and recognition tasks using global descriptors of only 96 dimensions.
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Mar 21, 2020
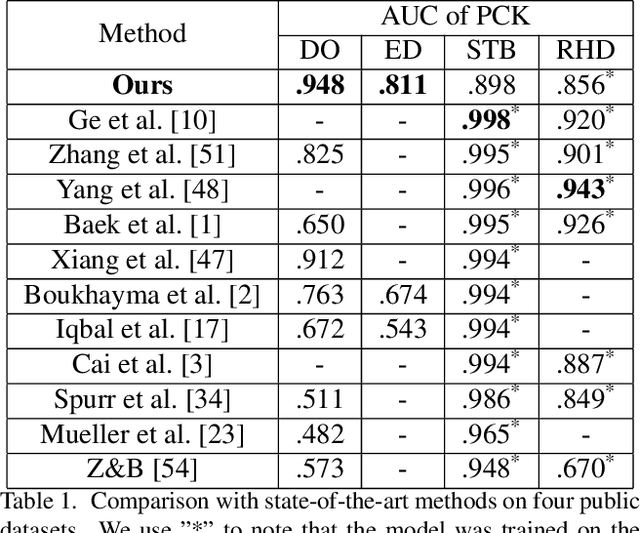
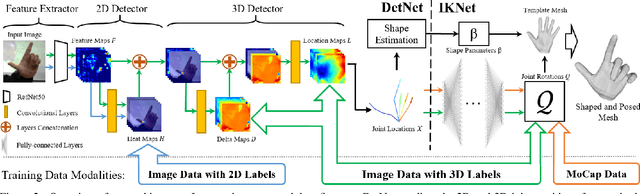
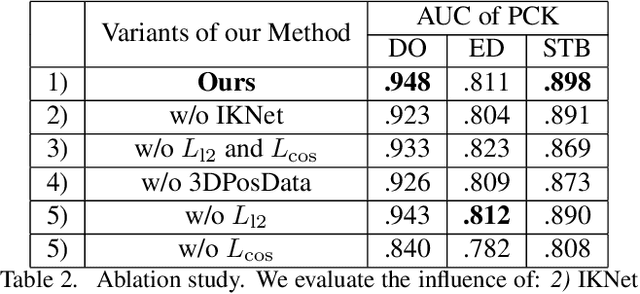
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020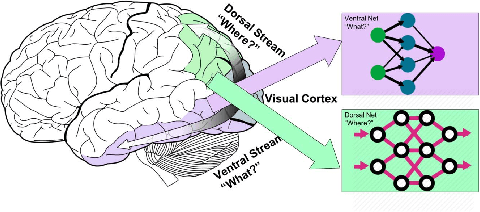
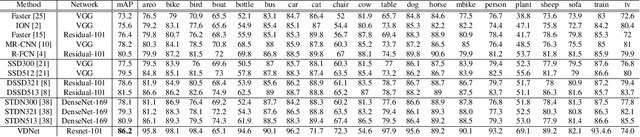
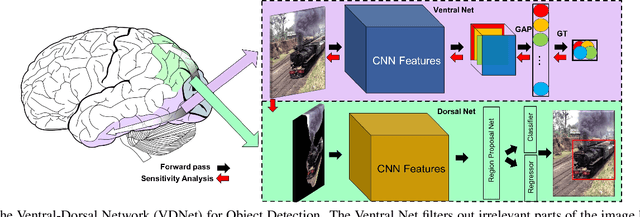

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Oct 05, 2015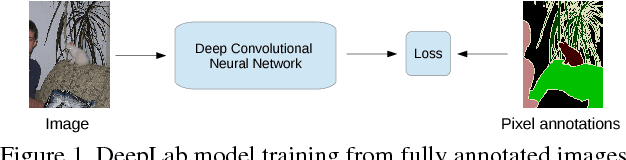
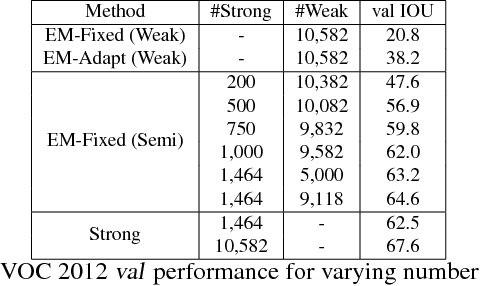
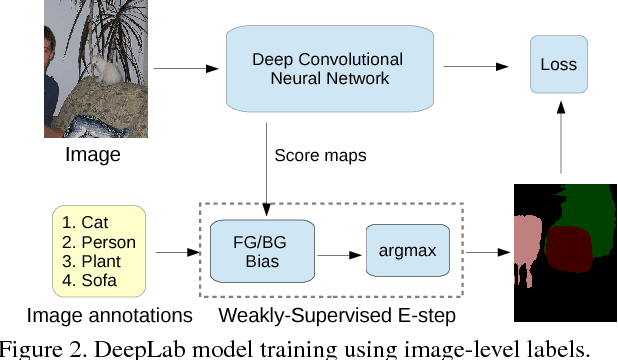
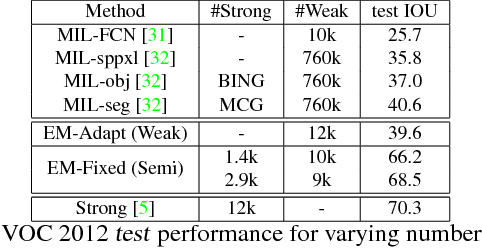
Deep convolutional neural networks (DCNNs) trained on a large number of images with strong pixel-level annotations have recently significantly pushed the state-of-art in semantic image segmentation. We study the more challenging problem of learning DCNNs for semantic image segmentation from either (1) weakly annotated training data such as bounding boxes or image-level labels or (2) a combination of few strongly labeled and many weakly labeled images, sourced from one or multiple datasets. We develop Expectation-Maximization (EM) methods for semantic image segmentation model training under these weakly supervised and semi-supervised settings. Extensive experimental evaluation shows that the proposed techniques can learn models delivering competitive results on the challenging PASCAL VOC 2012 image segmentation benchmark, while requiring significantly less annotation effort. We share source code implementing the proposed system at https://bitbucket.org/deeplab/deeplab-public.
Do Public Datasets Assure Unbiased Comparisons for Registration Evaluation?
Mar 20, 2020

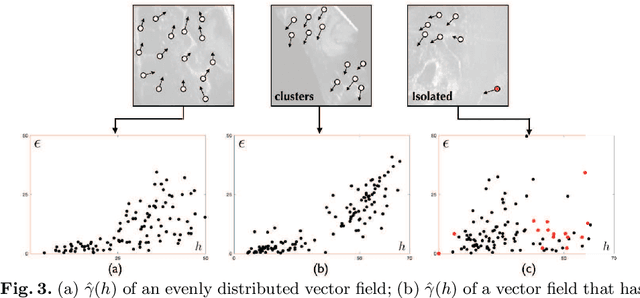
With the increasing availability of new image registration approaches, an unbiased evaluation is becoming more needed so that clinicians can choose the most suitable approaches for their applications. Current evaluations typically use landmarks in manually annotated datasets. As a result, the quality of annotations is crucial for unbiased comparisons. Even though most data providers claim to have quality control over their datasets, an objective third-party screening can be reassuring for intended users. In this study, we use the variogram to screen the manually annotated landmarks in two datasets used to benchmark registration in image-guided neurosurgeries. The variogram provides an intuitive 2D representation of the spatial characteristics of annotated landmarks. Using variograms, we identified potentially problematic cases and had them examined by experienced radiologists. We found that (1) a small number of annotations may have fiducial localization errors; (2) the landmark distribution for some cases is not ideal to offer fair comparisons. If unresolved, both findings could incur bias in registration evaluation.
Effects of GIMP Retinex Filtering Evaluated by the Image Entropy
Dec 16, 2015
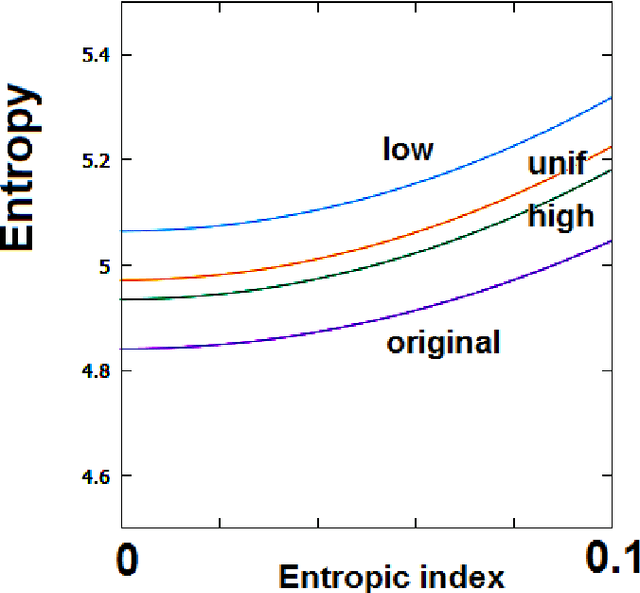

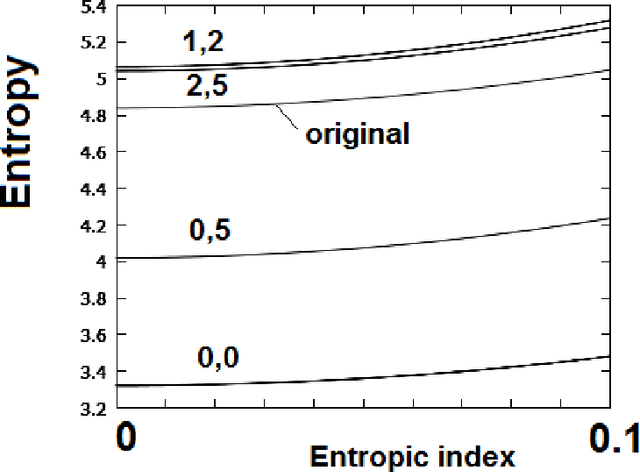
A GIMP Retinex filtering can be used for enhancing images, with good results on foggy images, as recently discussed. Since this filter has some parameters that can be adjusted to optimize the output image, several approaches can be decided according to desired results. Here, as a criterion for optimizing the filtering parameters, we consider the maximization of the image entropy. We use, besides the Shannon entropy, also a generalized entropy.
Skepxels: Spatio-temporal Image Representation of Human Skeleton Joints for Action Recognition
Aug 03, 2018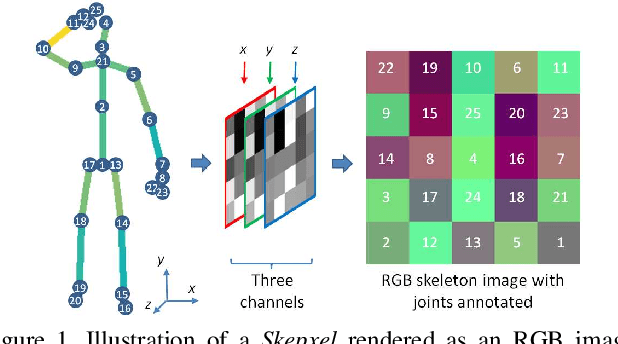
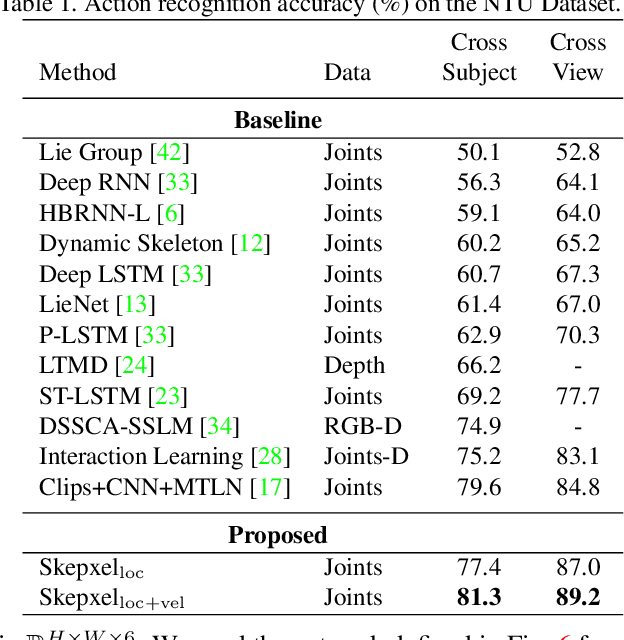

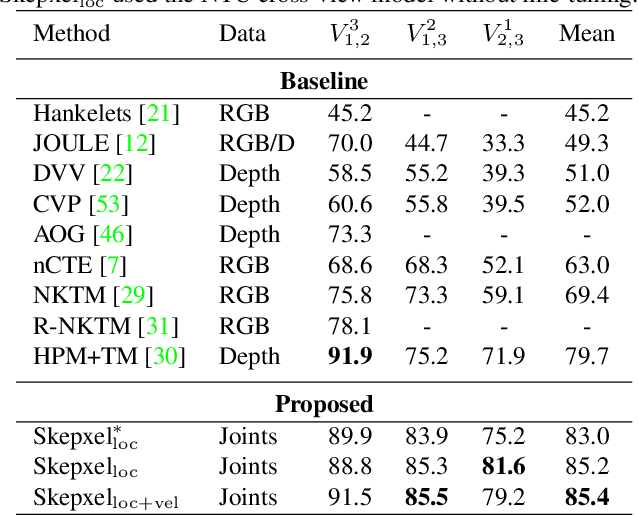
Human skeleton joints are popular for action analysis since they can be easily extracted from videos to discard background noises. However, current skeleton representations do not fully benefit from machine learning with CNNs. We propose "Skepxels" a spatio-temporal representation for skeleton sequences to fully exploit the "local" correlations between joints using the 2D convolution kernels of CNN. We transform skeleton videos into images of flexible dimensions using Skepxels and develop a CNN-based framework for effective human action recognition using the resulting images. Skepxels encode rich spatio-temporal information about the skeleton joints in the frames by maximizing a unique distance metric, defined collaboratively over the distinct joint arrangements used in the skeletal image. Moreover, they are flexible in encoding compound semantic notions such as location and speed of the joints. The proposed action recognition exploits the representation in a hierarchical manner by first capturing the micro-temporal relations between the skeleton joints with the Skepxels and then exploiting their macro-temporal relations by computing the Fourier Temporal Pyramids over the CNN features of the skeletal images. We extend the Inception-ResNet CNN architecture with the proposed method and improve the state-of-the-art accuracy by 4.4% on the large scale NTU human activity dataset. On the medium-sized N-UCLA and UTH-MHAD datasets, our method outperforms the existing results by 5.7% and 9.3% respectively.
Structure-Attentioned Memory Network for Monocular Depth Estimation
Sep 10, 2019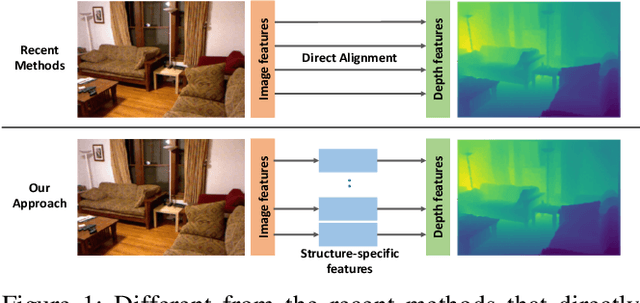
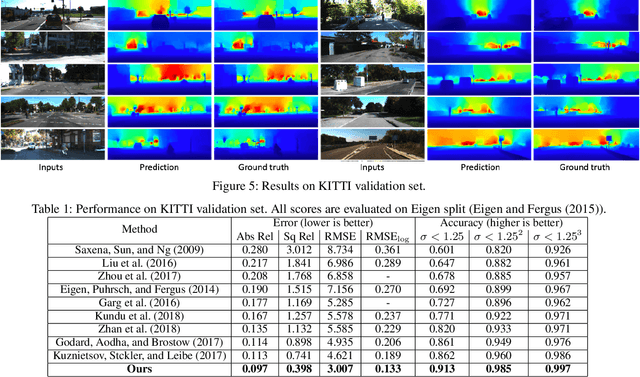
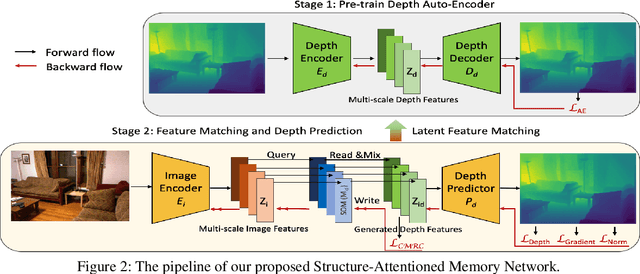
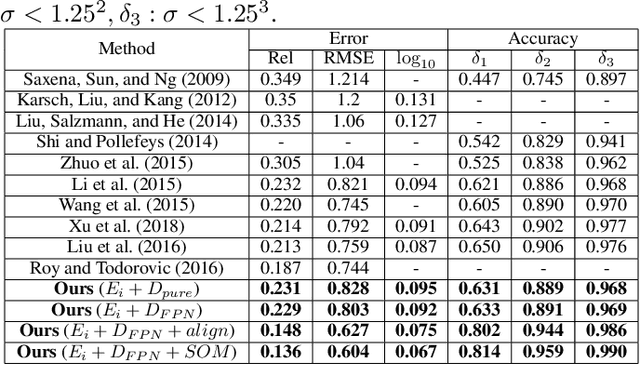
Monocular depth estimation is a challenging task that aims to predict a corresponding depth map from a given single RGB image. Recent deep learning models have been proposed to predict the depth from the image by learning the alignment of deep features between the RGB image and the depth domains. In this paper, we present a novel approach, named Structure-Attentioned Memory Network, to more effectively transfer domain features for monocular depth estimation by taking into account the common structure regularities (e.g., repetitive structure patterns, planar surfaces, symmetries) in domain adaptation. To this end, we introduce a new Structure-Oriented Memory (SOM) module to learn and memorize the structure-specific information between RGB image domain and the depth domain. More specifically, in the SOM module, we develop a Memorable Bank of Filters (MBF) unit to learn a set of filters that memorize the structure-aware image-depth residual pattern, and also an Attention Guided Controller (AGC) unit to control the filter selection in the MBF given image features queries. Given the query image feature, the trained SOM module is able to adaptively select the best customized filters for cross-domain feature transferring with an optimal structural disparity between image and depth. In summary, we focus on addressing this structure-specific domain adaption challenge by proposing a novel end-to-end multi-scale memorable network for monocular depth estimation. The experiments show that our proposed model demonstrates the superior performance compared to the existing supervised monocular depth estimation approaches on the challenging KITTI and NYU Depth V2 benchmarks.
A Method of Detecting End-To-End Curves of Limited Curvature
Dec 04, 2019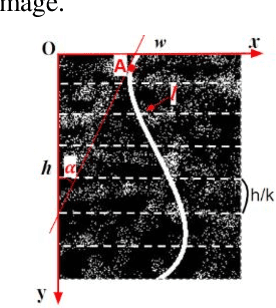

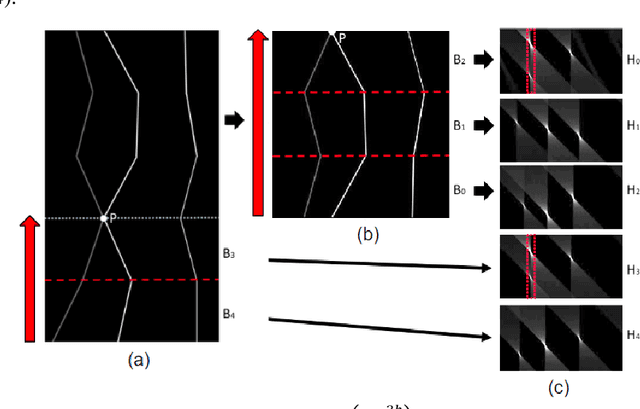
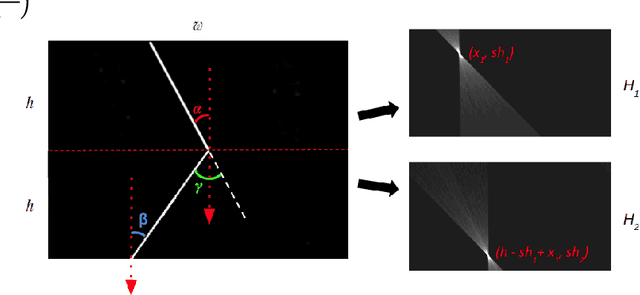
In this paper we consider a method for detecting end-to-end curves of limited curvature like the k-link polylines with bending angle between adjacent segments in a given range. The approximation accuracy is achieved by maximization of the quality function in the image matrix. The method is based on a dynamic programming scheme constructed over Fast Hough Transform calculation results for image bands. The proposed method asymptotic complexity is $O(h \cdot (w+ \frac{h}{k}) \cdot log(\frac{h}{k}))$, where $h$ and $w$ are the image size, and $k$ is the approximating polyline links number, which is an analogue of the complexity of the fast Fourier transform or the fast Hough transform. We also show the results of the proposed method on synthetic and real data.