 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Dermoscopic Image Segmentation with Enhanced Convolutional-Deconvolutional Networks
Sep 28, 2017
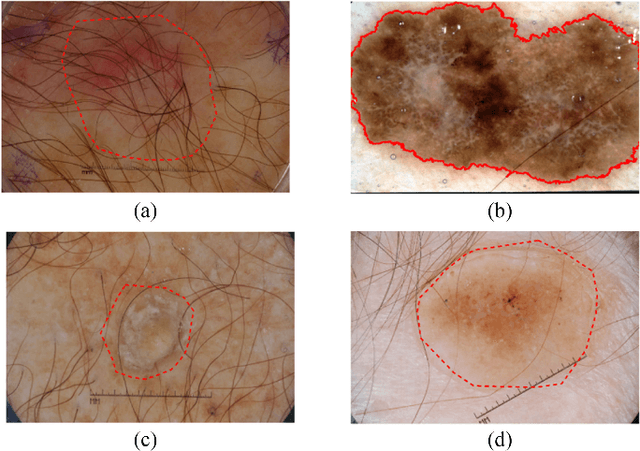
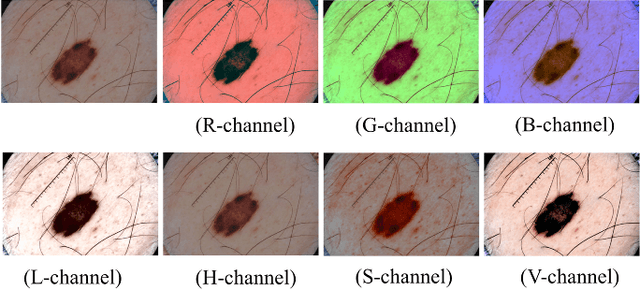
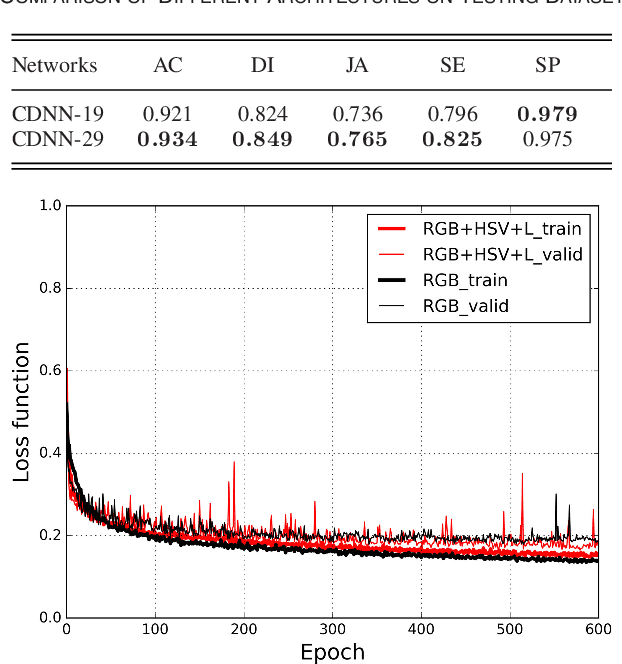
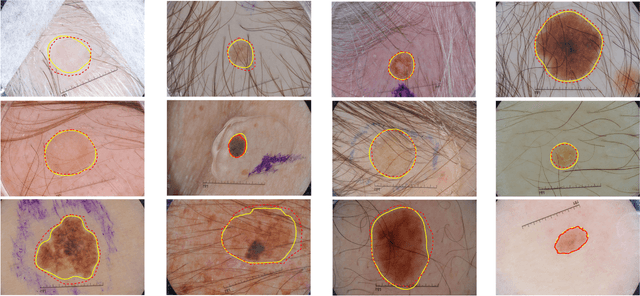
Automatic skin lesion segmentation on dermoscopic images is an essential step in computer-aided diagnosis of melanoma. However, this task is challenging due to significant variations of lesion appearances across different patients. This challenge is further exacerbated when dealing with a large amount of image data. In this paper, we extended our previous work by developing a deeper network architecture with smaller kernels to enhance its discriminant capacity. In addition, we explicitly included color information from multiple color spaces to facilitate network training and thus to further improve the segmentation performance. We extensively evaluated our method on the ISBI 2017 skin lesion segmentation challenge. By training with the 2000 challenge training images, our method achieved an average Jaccard Index (JA) of 0.765 on the 600 challenge testing images, which ranked itself in the first place in the challenge
Line Artefact Quantification in Lung Ultrasound Images of COVID-19 Patients via Non-Convex Regularisation
May 06, 2020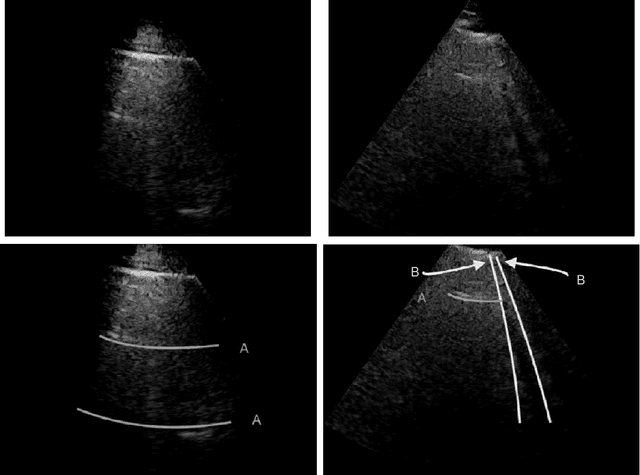
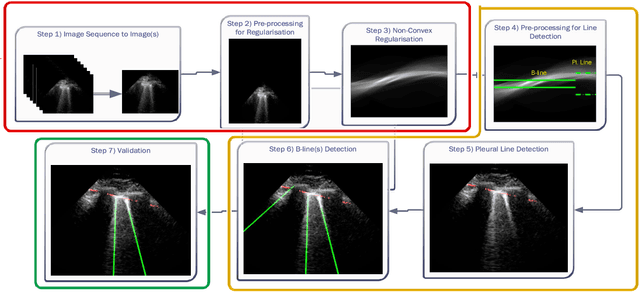

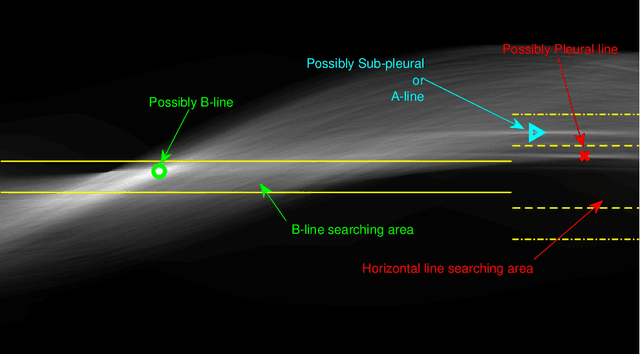
In this paper, we present a novel method for line artefacts quantification in lung ultrasound (LUS) images of COVID-19 patients. We formulate this as a non-convex regularisation problem involving a sparsity-enforcing, Cauchy-based penalty function, and the inverse Radon transform. We employ a simple local maxima detection technique in the Radon transform domain, associated with known clinical definitions of line artefacts. Despite being non-convex, the proposed method has guaranteed convergence via a proximal splitting algorithm and accurately identifies both horizontal and vertical line artefacts in LUS images. In order to reduce the number of false and missed detection, our method includes a two-stage validation mechanism, which is performed in both Radon and image domains. We evaluate the performance of the proposed method in comparison to the current state-of-the-art B-line identification method and show a considerable performance gain with 87% correctly detected B-lines in LUS images of nine COVID-19 patients. In addition, owing to its fast convergence, which takes around 12 seconds for a given frame, our proposed method is readily applicable for processing LUS image sequences.
FastSal: a Computationally Efficient Network for Visual Saliency Prediction
Aug 25, 2020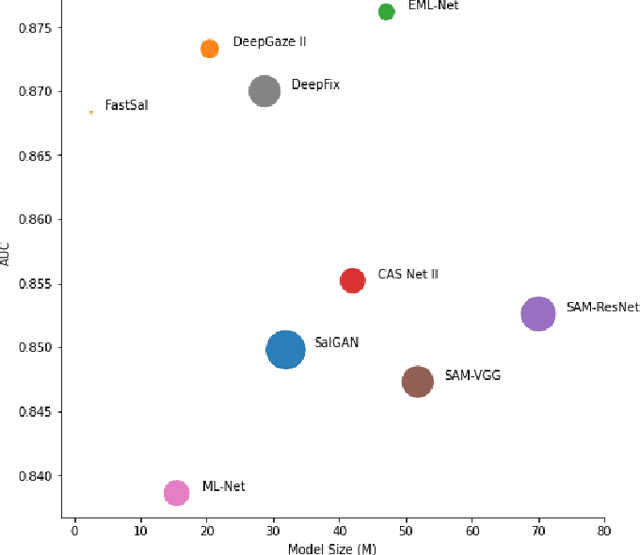
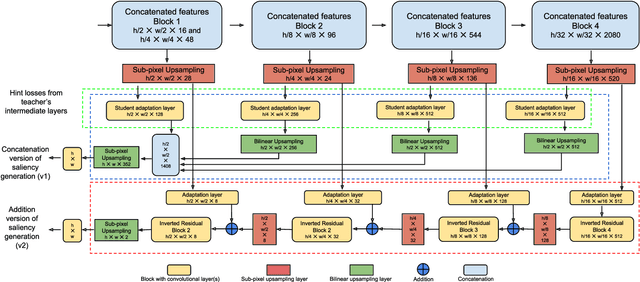
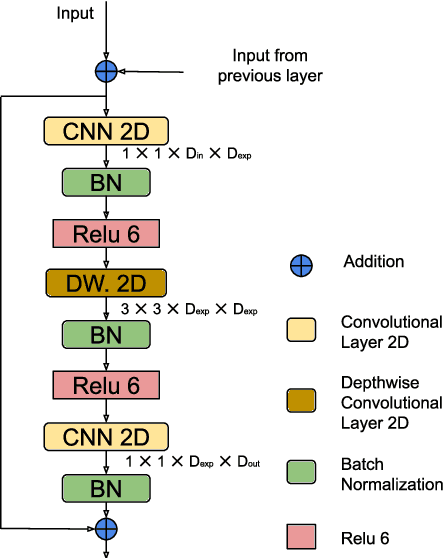
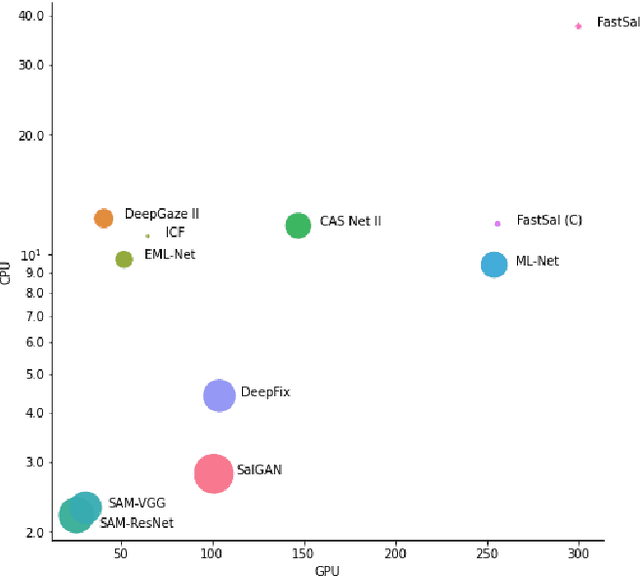
This paper focuses on the problem of visual saliency prediction, predicting regions of an image that tend to attract human visual attention, under a constrained computational budget. We modify and test various recent efficient convolutional neural network architectures like EfficientNet and MobileNetV2 and compare them with existing state-of-the-art saliency models such as SalGAN and DeepGaze II both in terms of standard accuracy metrics like AUC and NSS, and in terms of the computational complexity and model size. We find that MobileNetV2 makes an excellent backbone for a visual saliency model and can be effective even without a complex decoder. We also show that knowledge transfer from a more computationally expensive model like DeepGaze II can be achieved via pseudo-labelling an unlabelled dataset, and that this approach gives result on-par with many state-of-the-art algorithms with a fraction of the computational cost and model size. Source code is available at https://github.com/feiyanhu/FastSal.
TUTOR: Training Neural Networks Using Decision Rules as Model Priors
Oct 13, 2020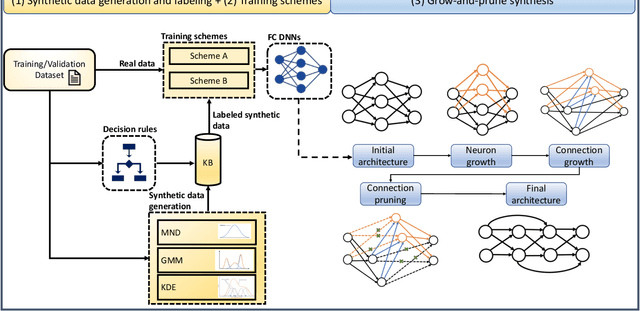

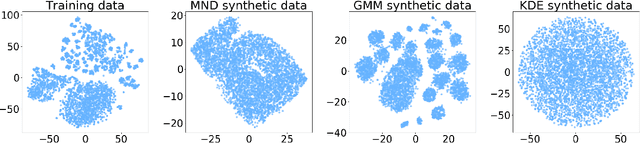

The human brain has the ability to carry out new tasks with limited experience. It utilizes prior learning experiences to adapt the solution strategy to new domains. On the other hand, deep neural networks (DNNs) generally need large amounts of data and computational resources for training. However, this requirement is not met in many settings. To address these challenges, we propose the TUTOR DNN synthesis framework. TUTOR targets non-image datasets. It synthesizes accurate DNN models with limited available data, and reduced memory and computational requirements. It consists of three sequential steps: (1) drawing synthetic data from the same probability distribution as the training data and labeling the synthetic data based on a set of rules extracted from the real dataset, (2) use of two training schemes that combine synthetic data and training data to learn DNN weights, and (3) employing a grow-and-prune synthesis paradigm to learn both the weights and the architecture of the DNN to reduce model size while ensuring its accuracy. We show that in comparison with fully-connected DNNs, on an average TUTOR reduces the need for data by 6.0x (geometric mean), improves accuracy by 3.6%, and reduces the number of parameters (floating-point operations) by 4.7x (4.3x) (geometric mean). Thus, TUTOR is a less data-hungry, accurate, and efficient DNN synthesis framework.
Map-Repair: Deep Cadastre Maps Alignment and Temporal Inconsistencies Fix in Satellite Images
Jul 24, 2020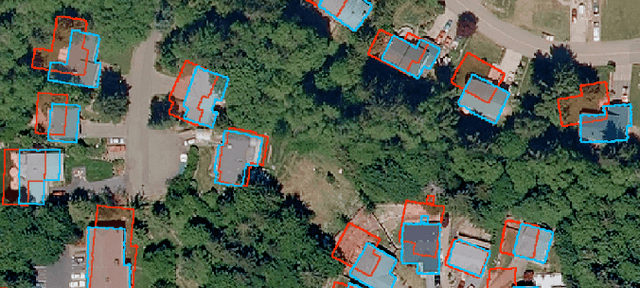
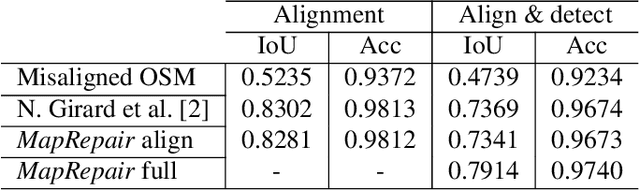
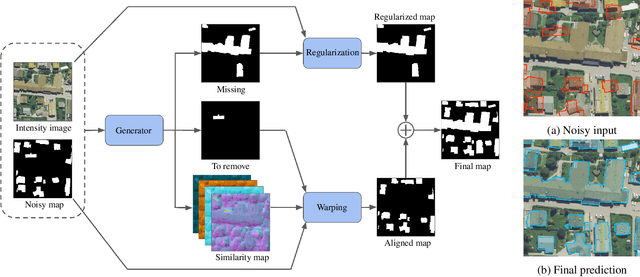
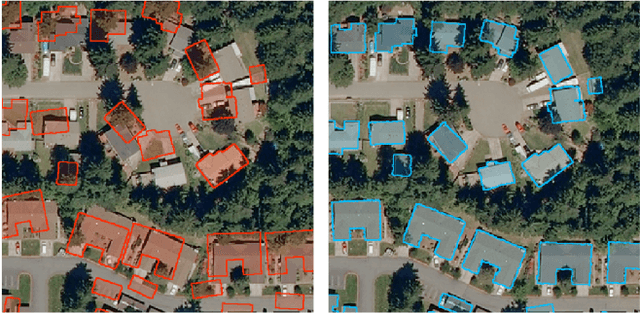
In the fast developing countries it is hard to trace new buildings construction or old structures destruction and, as a result, to keep the up-to-date cadastre maps. Moreover, due to the complexity of urban regions or inconsistency of data used for cadastre maps extraction, the errors in form of misalignment is a common problem. In this work, we propose an end-to-end deep learning approach which is able to solve inconsistencies between the input intensity image and the available building footprints by correcting label noises and, at the same time, misalignments if needed. The obtained results demonstrate the robustness of the proposed method to even severely misaligned examples that makes it potentially suitable for real applications, like OpenStreetMap correction.
Funnel Activation for Visual Recognition
Jul 24, 2020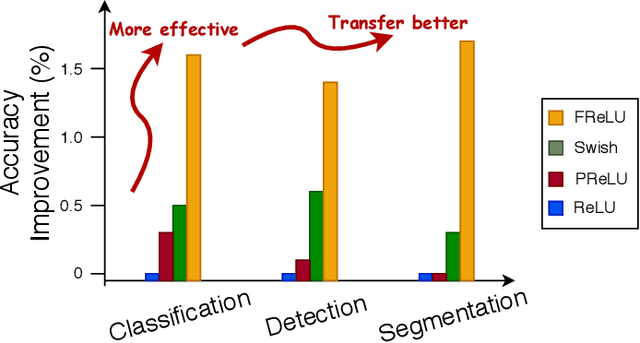
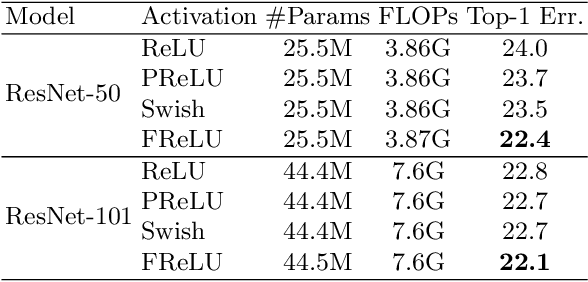
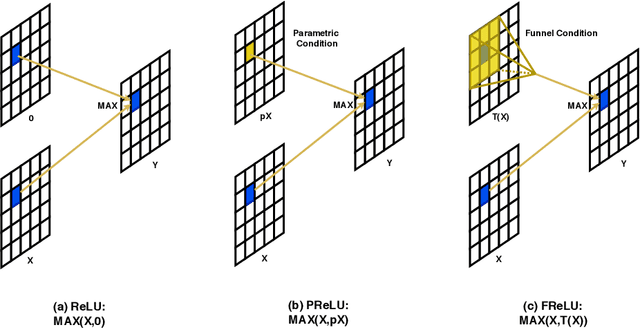
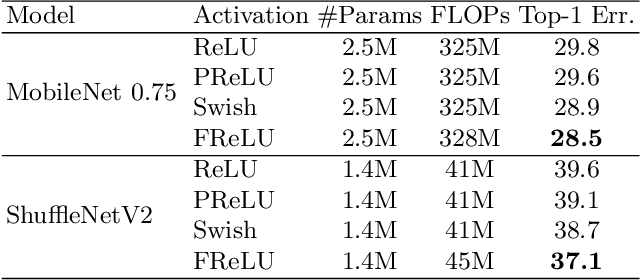
We present a conceptually simple but effective funnel activation for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition. The forms of ReLU and PReLU are y = max(x, 0) and y = max(x, px), respectively, while FReLU is in the form of y = max(x,T(x)), where T(x) is the 2D spatial condition. Moreover, the spatial condition achieves a pixel-wise modeling capacity in a simple way, capturing complicated visual layouts with regular convolutions. We conduct experiments on ImageNet, COCO detection, and semantic segmentation tasks, showing great improvements and robustness of FReLU in the visual recognition tasks. Code is available at https://github.com/megvii-model/FunnelAct.
Understanding Integrated Gradients with SmoothTaylor for Deep Neural Network Attribution
Apr 22, 2020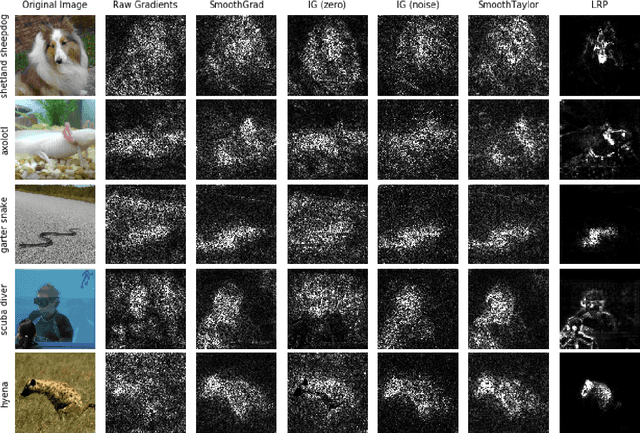
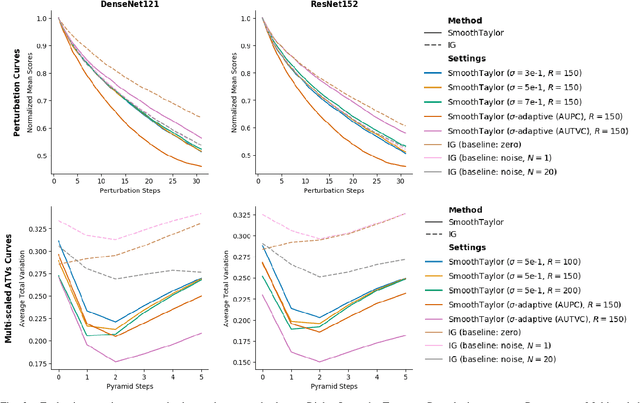
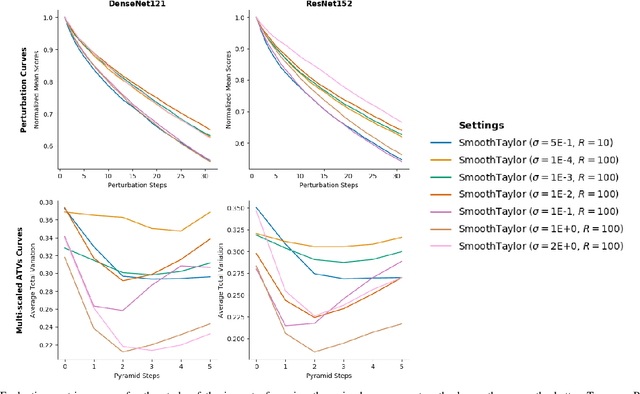
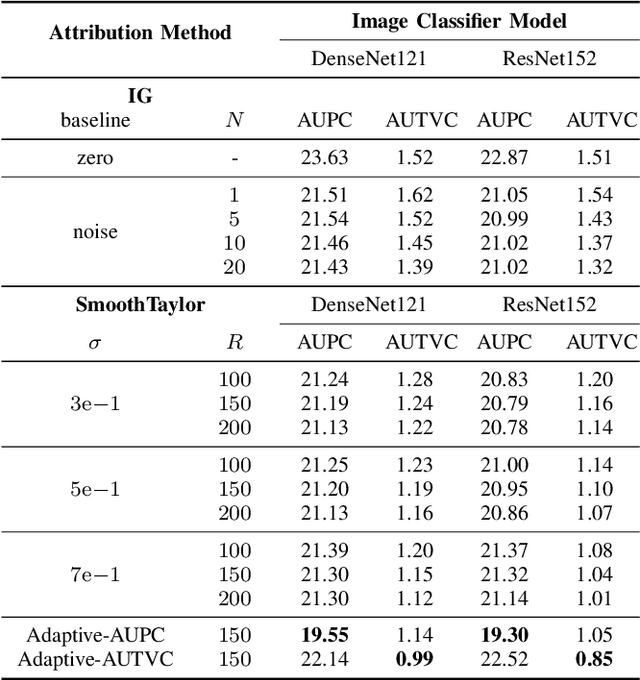
Integrated gradients as an attribution method for deep neural network models offers simple implementability. However, it also suffers from noisiness of explanations, which affects the ease of interpretability. In this paper, we present Smooth Integrated Gradients as a statistically improved attribution method inspired by Taylor's theorem, which does not require a fixed baseline to be chosen. We apply both methods to the image classification problem, using the ILSVRC2012 ImageNet object recognition dataset, and a couple of pretrained image models to generate attribution maps of their predictions. These attribution maps are visualized by saliency maps which can be evaluated qualitatively. We also empirically evaluate them using quantitative metrics such as perturbations-based score drops and multi-scaled total variance. We further propose adaptive noising to optimize for the noise scale hyperparameter value in our proposed method. From our experiments, we find that the Smooth Integrated Gradients approach together with adaptive noising is able to generate better quality saliency maps with lesser noise and higher sensitivity to the relevant points in the input space.
Epitome for Automatic Image Colorization
Oct 08, 2012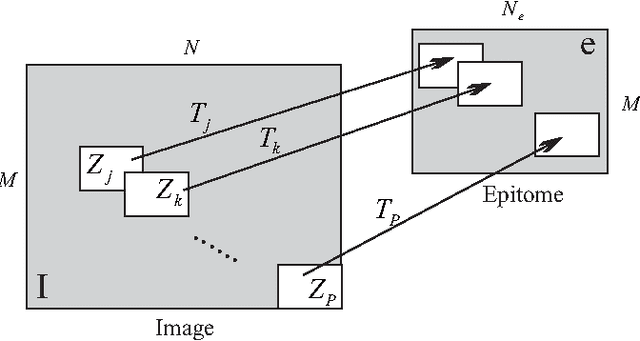
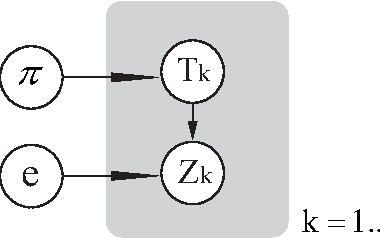


Image colorization adds color to grayscale images. It not only increases the visual appeal of grayscale images, but also enriches the information contained in scientific images that lack color information. Most existing methods of colorization require laborious user interaction for scribbles or image segmentation. To eliminate the need for human labor, we develop an automatic image colorization method using epitome. Built upon a generative graphical model, epitome is a condensed image appearance and shape model which also proves to be an effective summary of color information for the colorization task. We train the epitome from the reference images and perform inference in the epitome to colorize grayscale images, rendering better colorization results than previous method in our experiments.
Supervised Segmentation of Retinal Vessel Structures Using ANN
Jan 15, 2020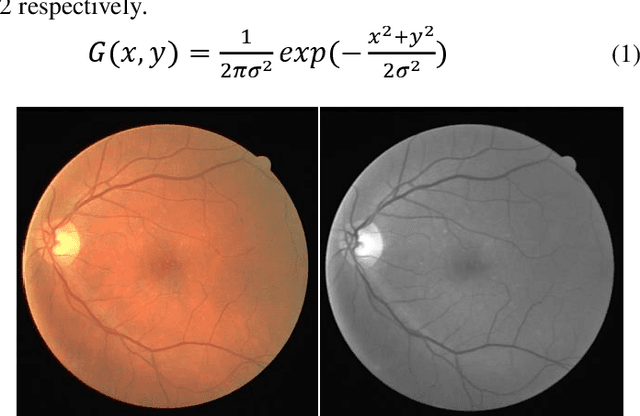
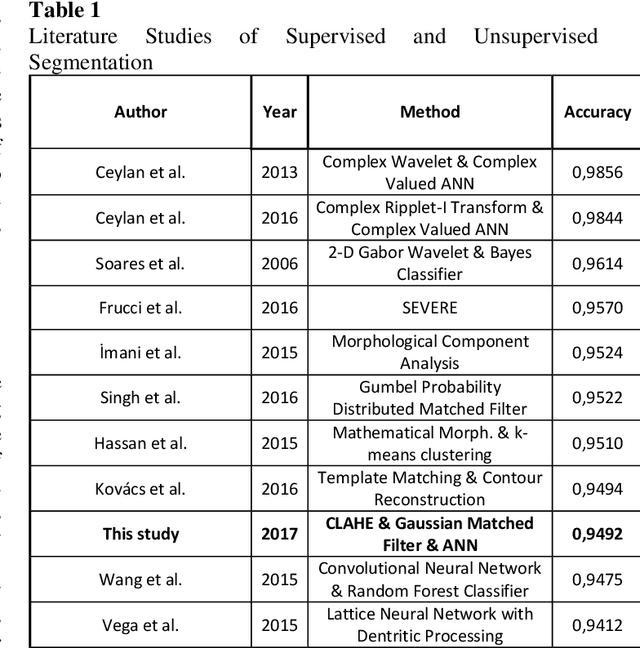
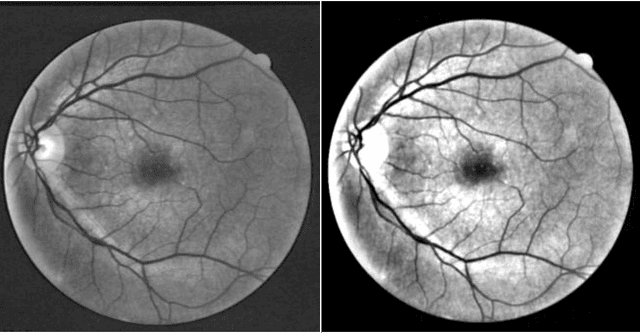
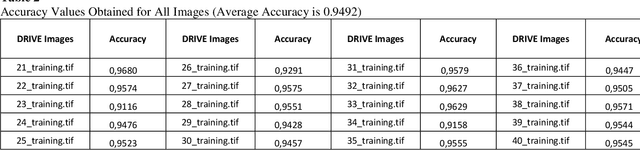
In this study, a supervised retina blood vessel segmentation process was performed on the green channel of the RGB image using artificial neural network (ANN). The green channel is preferred because the retinal vessel structures can be distinguished most clearly from the green channel of the RGB image. The study was performed using 20 images in the DRIVE data set which is one of the most common retina data sets known. The images went through some preprocessing stages like contrastlimited adaptive histogram equalization (CLAHE), color intensity adjustment, morphological operations and median and Gaussian filtering to obtain a good segmentation. Retinal vessel structures were highlighted with top-hat and bot-hat morphological operations and converted to binary image by using global thresholding. Then, the network was trained by the binary version of the images specified as training images in the dataset and the targets are the images segmented manually by a specialist. The average segmentation accuracy for 20 images was found as 0.9492.
Assessing Lesion Segmentation Bias of Neural Networks on Motion Corrupted Brain MRI
Oct 12, 2020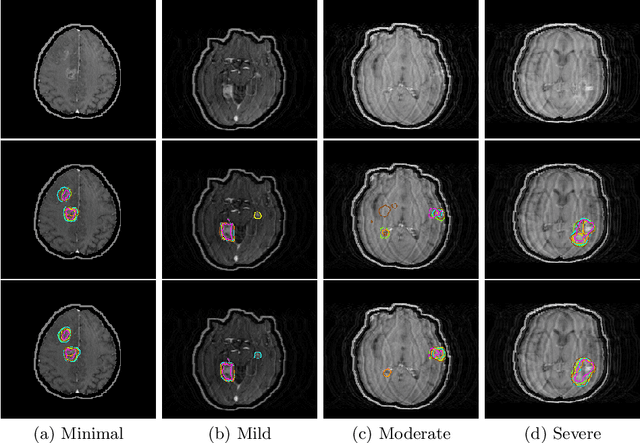
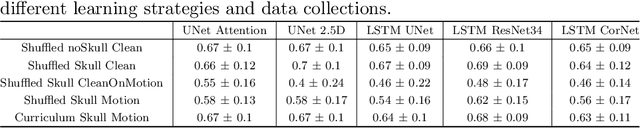
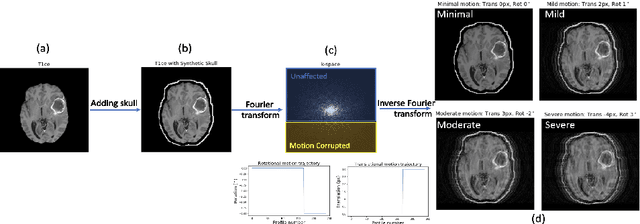

Patient motion during the magnetic resonance imaging (MRI) acquisition process results in motion artifacts, which limits the ability of radiologists to provide a quantitative assessment of a condition visualized. Often times, radiologists either "see through" the artifacts with reduced diagnostic confidence, or the MR scans are rejected and patients are asked to be recalled and re-scanned. Presently, there are many published approaches that focus on MRI artifact detection and correction. However, the key question of the bias exhibited by these algorithms on motion corrupted MRI images is still unanswered. In this paper, we seek to quantify the bias in terms of the impact that different levels of motion artifacts have on the performance of neural networks engaged in a lesion segmentation task. Additionally, we explore the effect of a different learning strategy, curriculum learning, on the segmentation performance. Our results suggest that a network trained using curriculum learning is effective at compensating for different levels of motion artifacts, and improved the segmentation performance by ~9%-15% (p < 0.05) when compared against a conventional shuffled learning strategy on the same motion data. Within each motion category, it either improved or maintained the dice score. To the best of our knowledge, we are the first to quantitatively assess the segmentation bias on various levels of motion artifacts present in a brain MRI image.