 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PolyLaneNet: Lane Estimation via Deep Polynomial Regression
Apr 23, 2020
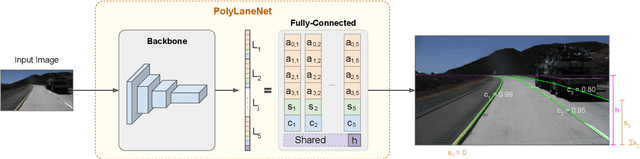


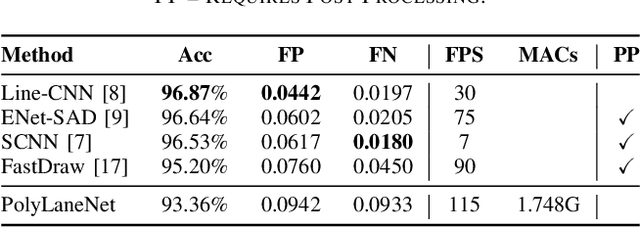
One of the main factors that contributed to the large advances in autonomous driving is the advent of deep learning. For safer self-driving vehicles, one of the problems that has yet to be solved completely is lane detection. Since methods for this task have to work in real time (+30 FPS), they not only have to be effective (i.e., have high accuracy) but they also have to be efficient (i.e., fast). In this work, we present a novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression. The proposed method is shown to be competitive with existing state-of-the-art methods in the TuSimple dataset, while maintaining its efficiency (115 FPS). Additionally, extensive qualitative results on two additional public datasets are presented, alongside with limitations in the evaluation metrics used by recent works for lane detection. Finally, we provide source code and trained models that allow others to replicate all the results shown in this paper, which is surprisingly rare in state-of-the-art lane detection methods.
Image Annotation Incorporating Low-Rankness, Tag and Visual Correlation and Inhomogeneous Errors
Aug 08, 2016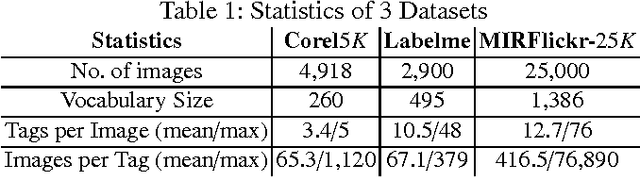
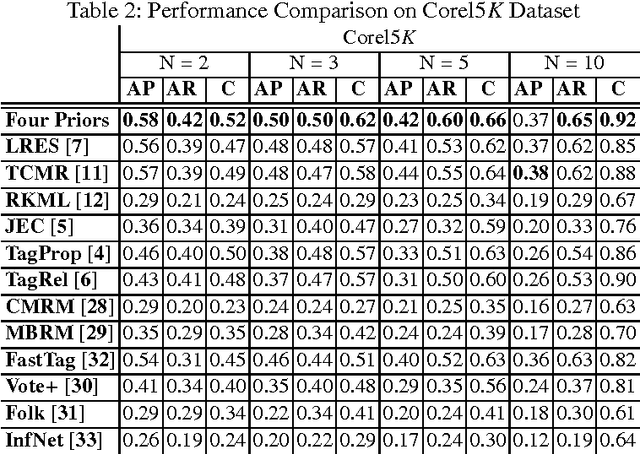
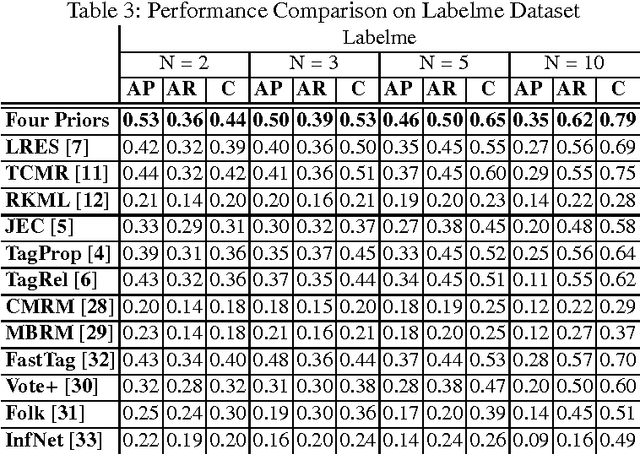
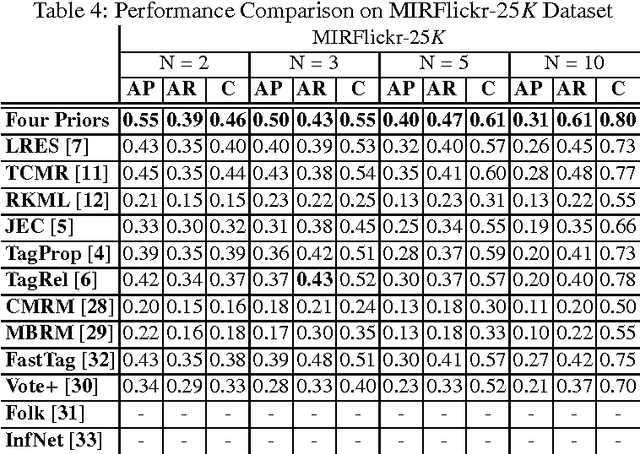
Tag-based image retrieval (TBIR) has drawn much attention in recent years due to the explosive amount of digital images and crowdsourcing tags. However, TBIR is still suffering from the incomplete and inaccurate tags provided by users, posing a great challenge for tag-based image management applications. In this work, we proposed a novel method for image annotation, incorporating several priors: Low-Rankness, Tag and Visual Correlation and Inhomogeneous Errors. Highly representative CNN feature vectors are adopt to model the tag-visual correlation and narrow the semantic gap. And we extract word vectors for tags to measure similarity between tags in the semantic level, which is more accurate than traditional frequency-based or graph-based methods. We utilize the accelerated proximal gradient (APG) method to solve our model efficiently. Extensive experiments conducted on multiple benchmark datasets demonstrate the effectiveness and robustness of the proposed method.
Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images
Oct 18, 2019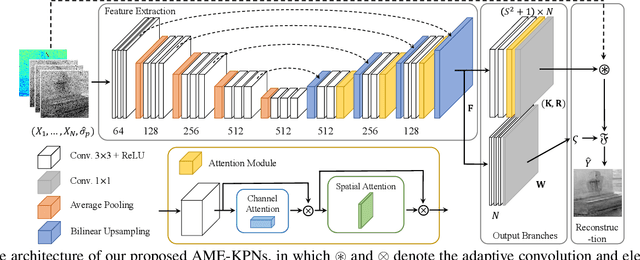
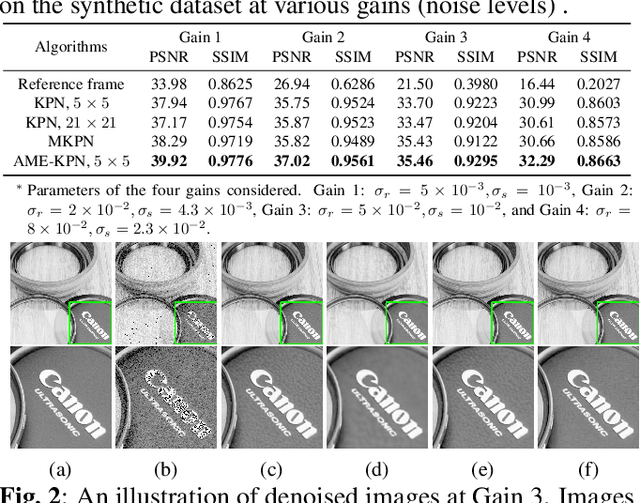
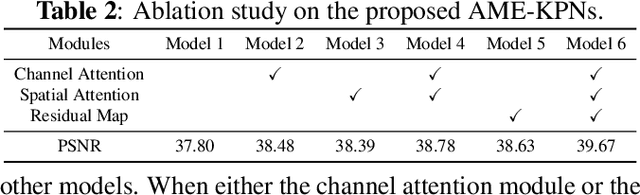
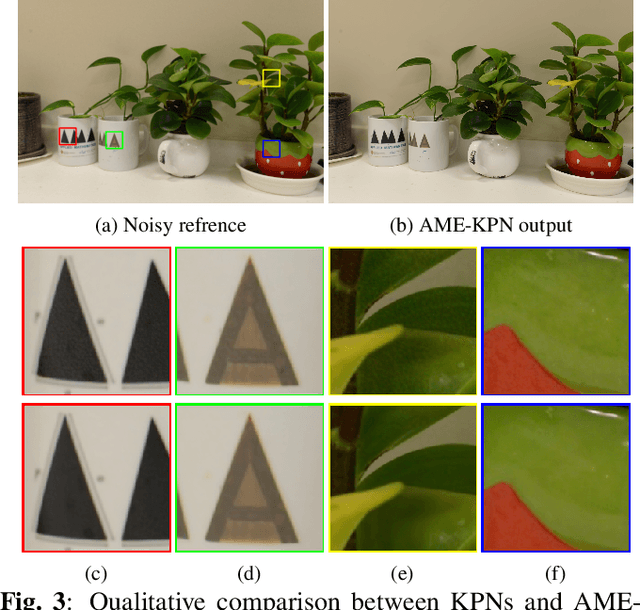
Deep learning based image denoising methods have been extensively investigated. In this paper, attention mechanism enhanced kernel prediction networks (AME-KPNs) are proposed for burst image denoising, in which, nearly cost-free attention modules are adopted to first refine the feature maps and to further make a full use of the inter-frame and intra-frame redundancies within the whole image burst. The proposed AME-KPNs output per-pixel spatially-adaptive kernels, residual maps and corresponding weight maps, in which, the predicted kernels roughly restore clean pixels at their corresponding locations via an adaptive convolution operation, and subsequently, residuals are weighted and summed to compensate the limited receptive field of predicted kernels. Simulations and real-world experiments are conducted to illustrate the robustness of the proposed AME-KPNs in burst image denoising.
Pixel-level Corrosion Detection on Metal Constructions by Fusion of Deep Learning Semantic and Contour Segmentation
Aug 12, 2020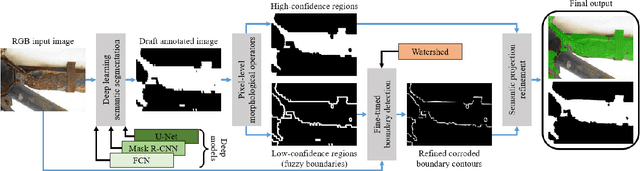
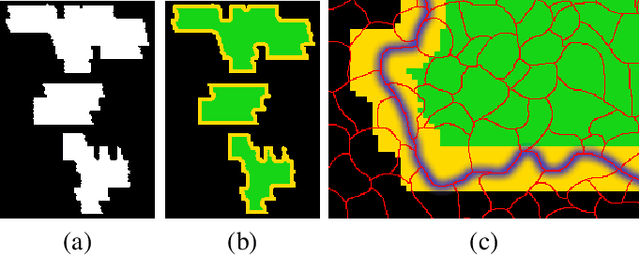

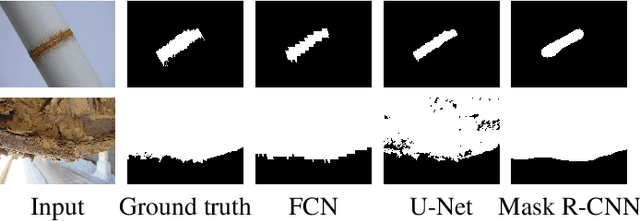
Corrosion detection on metal constructions is a major challenge in civil engineering for quick, safe and effective inspection. Existing image analysis approaches tend to place bounding boxes around the defected region which is not adequate both for structural analysis and pre-fabrication, an innovative construction concept which reduces maintenance cost, time and improves safety. In this paper, we apply three semantic segmentation-oriented deep learning models (FCN, U-Net and Mask R-CNN) for corrosion detection, which perform better in terms of accuracy and time and require a smaller number of annotated samples compared to other deep models, e.g. CNN. However, the final images derived are still not sufficiently accurate for structural analysis and pre-fabrication. Thus, we adopt a novel data projection scheme that fuses the results of color segmentation, yielding accurate but over-segmented contours of a region, with a processed area of the deep masks, resulting in high-confidence corroded pixels.
An Ensemble of Simple Convolutional Neural Network Models for MNIST Digit Recognition
Aug 12, 2020
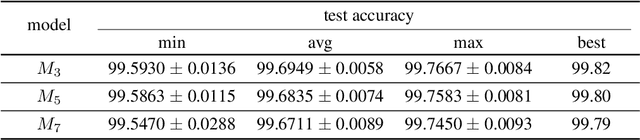
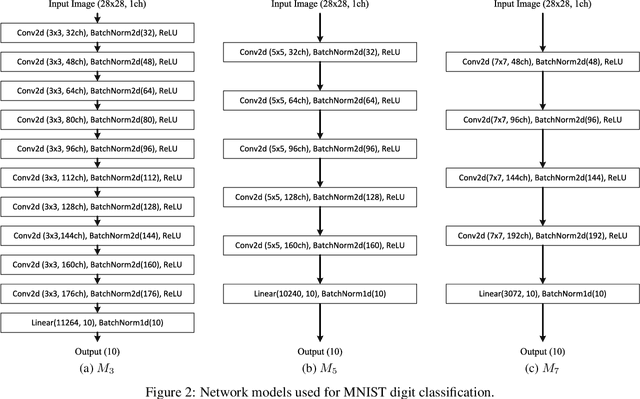
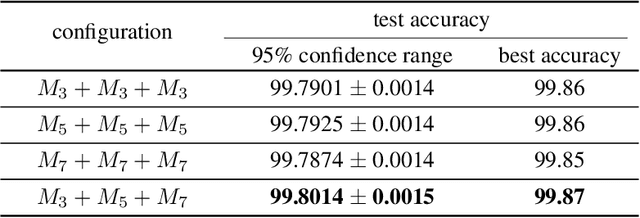
We report that a very high accuracy on the MNIST test set can be achieved by using simple convolutional neural network (CNN) models. We use three different models with 3x3, 5x5, and 7x7 kernel size in the convolution layers. Each model consists of a set of convolution layers followed by a single fully connected layer. Every convolution layer uses batch normalization and ReLU activation, and pooling is not used. Rotation and translation is used to augment training data, which is frequently used in most image classification tasks. A majority voting using the three models independently trained on the training data set can achieve up to 99.87% accuracy on the test set, which is one of the state-of-the-art results. A two-layer ensemble, a heterogeneous ensemble of three homogeneous ensemble networks, can achieve up to 99.91% test accuracy. The results can be reproduced by using the code at: https://github.com/ansh941/MnistSimpleCNN
Sparse Coding with Fast Image Alignment via Large Displacement Optical Flow
Dec 21, 2015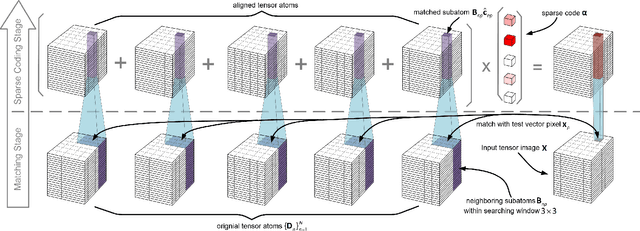
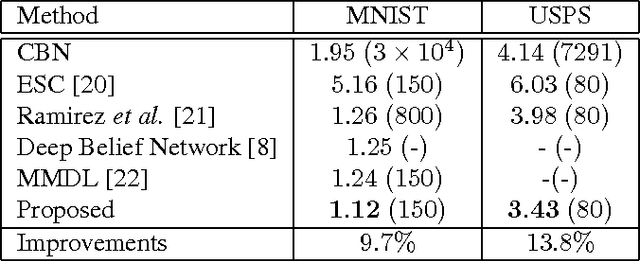
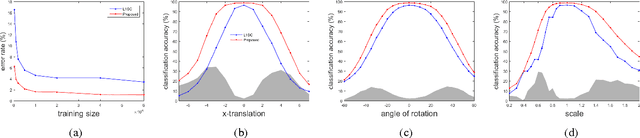
Sparse representation-based classifiers have shown outstanding accuracy and robustness in image classification tasks even with the presence of intense noise and occlusion. However, it has been discovered that the performance degrades significantly either when test image is not aligned with the dictionary atoms or the dictionary atoms themselves are not aligned with each other, in which cases the sparse linear representation assumption fails. In this paper, having both training and test images misaligned, we introduce a novel sparse coding framework that is able to efficiently adapt the dictionary atoms to the test image via large displacement optical flow. In the proposed algorithm, every dictionary atom is automatically aligned with the input image and the sparse code is then recovered using the adapted dictionary atoms. A corresponding supervised dictionary learning algorithm is also developed for the proposed framework. Experimental results on digit datasets recognition verify the efficacy and robustness of the proposed algorithm.
Conditional Sampling With Monotone GANs
Jun 11, 2020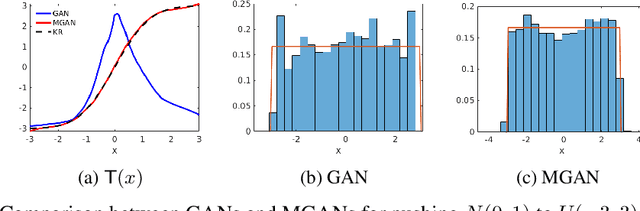
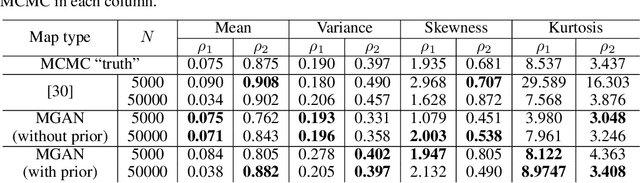
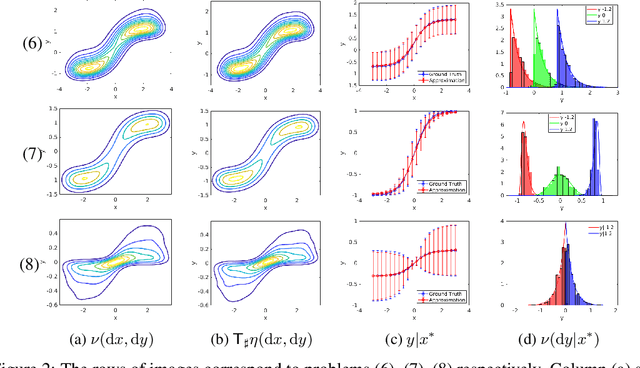
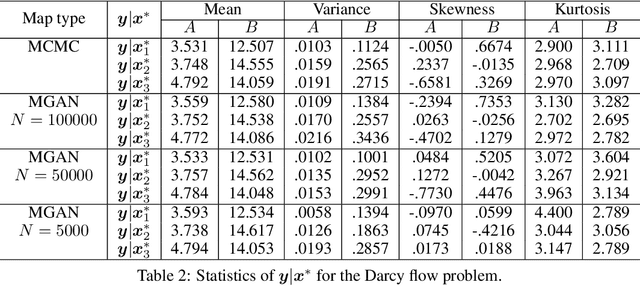
We present a new approach for sampling conditional measures that enables uncertainty quantification in supervised learning tasks. We construct a mapping that transforms a reference measure to the probability measure of the output conditioned on new inputs. The mapping is trained via a modification of generative adversarial networks (GANs), called monotone GANs, that imposes monotonicity constraints and a block triangular structure. We present theoretical results, in an idealized setting, that support our proposed method as well as numerical experiments demonstrating the ability of our method to sample the correct conditional measures in applications ranging from inverse problems to image in-painting.
RoadTagger: Robust Road Attribute Inference with Graph Neural Networks
Dec 28, 2019
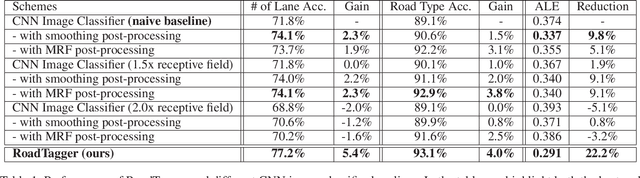
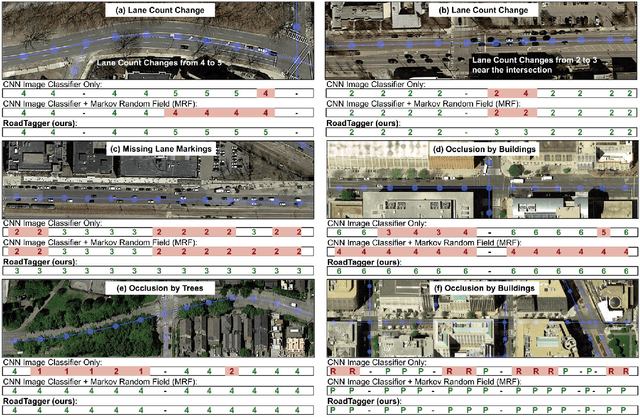
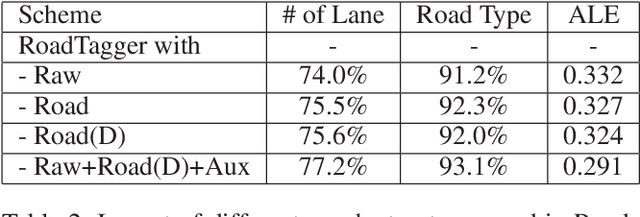
Inferring road attributes such as lane count and road type from satellite imagery is challenging. Often, due to the occlusion in satellite imagery and the spatial correlation of road attributes, a road attribute at one position on a road may only be apparent when considering far-away segments of the road. Thus, to robustly infer road attributes, the model must integrate scattered information and capture the spatial correlation of features along roads. Existing solutions that rely on image classifiers fail to capture this correlation, resulting in poor accuracy. We find this failure is caused by a fundamental limitation -- the limited effective receptive field of image classifiers. To overcome this limitation, we propose RoadTagger, an end-to-end architecture which combines both Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs) to infer road attributes. The usage of graph neural networks allows information propagation on the road network graph and eliminates the receptive field limitation of image classifiers. We evaluate RoadTagger on both a large real-world dataset covering 688 km^2 area in 20 U.S. cities and a synthesized micro-dataset. In the evaluation, RoadTagger improves inference accuracy over the CNN image classifier based approaches. RoadTagger also demonstrates strong robustness against different disruptions in the satellite imagery and the ability to learn complicated inductive rules for aggregating scattered information along the road network.
Improving Lesion Segmentation for Diabetic Retinopathy using Adversarial Learning
Jul 27, 2020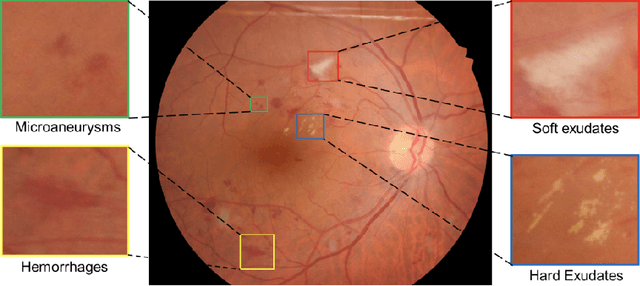
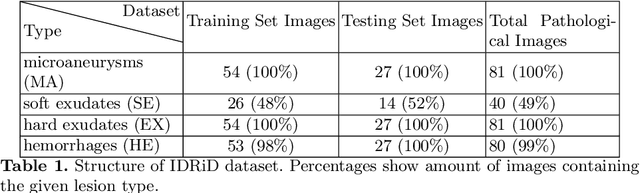
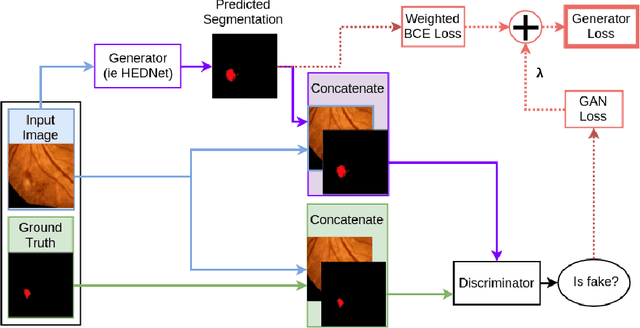
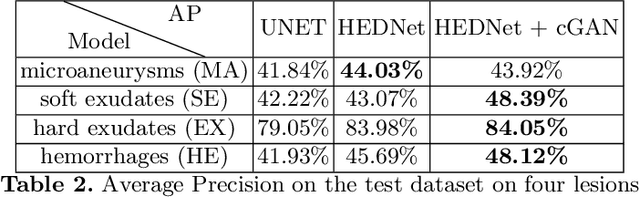
Diabetic Retinopathy (DR) is a leading cause of blindness in working age adults. DR lesions can be challenging to identify in fundus images, and automatic DR detection systems can offer strong clinical value. Of the publicly available labeled datasets for DR, the Indian Diabetic Retinopathy Image Dataset (IDRiD) presents retinal fundus images with pixel-level annotations of four distinct lesions: microaneurysms, hemorrhages, soft exudates and hard exudates. We utilize the HEDNet edge detector to solve a semantic segmentation task on this dataset, and then propose an end-to-end system for pixel-level segmentation of DR lesions by incorporating HEDNet into a Conditional Generative Adversarial Network (cGAN). We design a loss function that adds adversarial loss to segmentation loss. Our experiments show that the addition of the adversarial loss improves the lesion segmentation performance over the baseline.
Deep Efficient End-to-end Reconstruction (DEER) Network for Low-dose Few-view Breast CT from Projection Data
Dec 16, 2019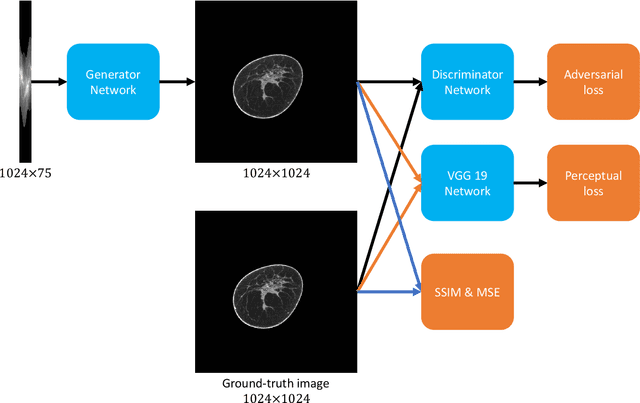
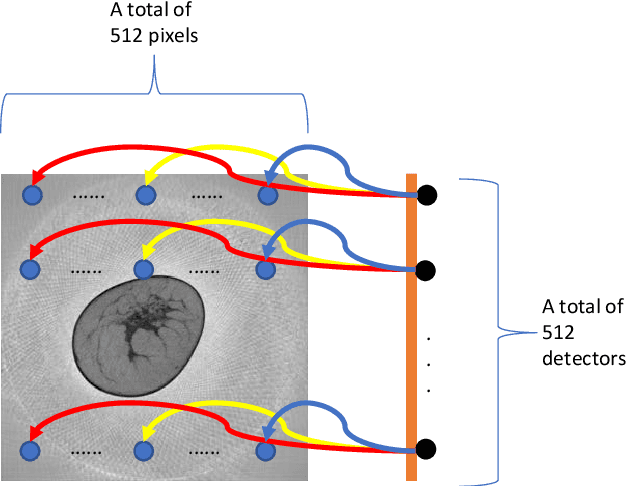
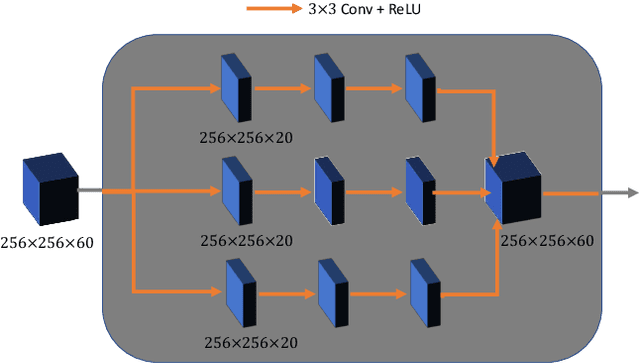
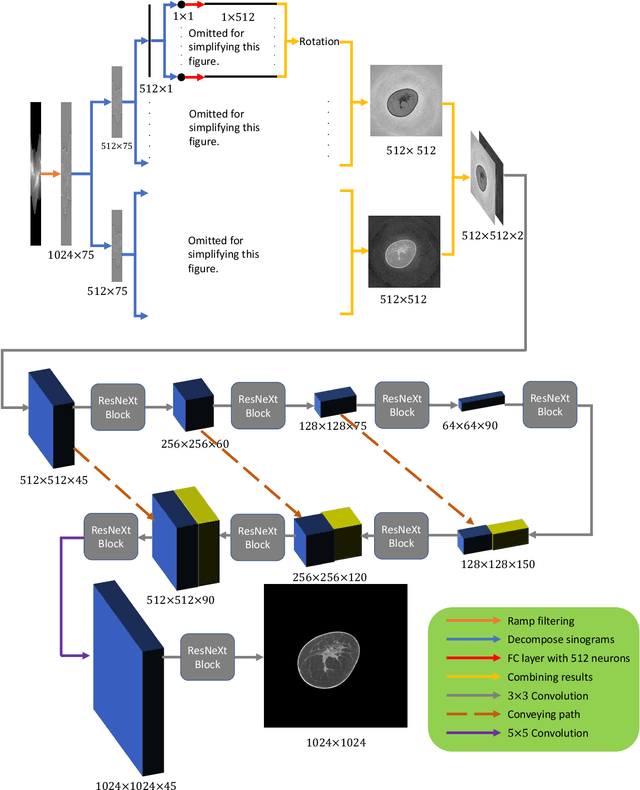
Breast CT provides image volumes with isotropic resolution in high contrast, enabling detection of calcification (down to a few hundred microns in size) and subtle density differences. Since breast is sensitive to x-ray radiation, dose reduction of breast CT is an important topic, and for this purpose low-dose few-view scanning is a main approach. In this article, we propose a Deep Efficient End-to-end Reconstruction (DEER) network for low-dose few-view breast CT. The major merits of our network include high dose efficiency, excellent image quality, and low model complexity. By the design, the proposed network can learn the reconstruction process in terms of as less as O(N) parameters, where N is the size of an image to be reconstructed, which represents orders of magnitude improvements relative to the state-of-the-art deep-learning based reconstruction methods that map projection data to tomographic images directly. As a result, our method does not require expensive GPUs to train and run. Also, validated on a cone-beam breast CT dataset prepared by Koning Corporation on a commercial scanner, our method demonstrates competitive performance over the state-of-the-art reconstruction networks in terms of image quality.