 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Polyth-Net: Classification of Polythene Bags for Garbage Segregation Using Deep Learning
Aug 12, 2020

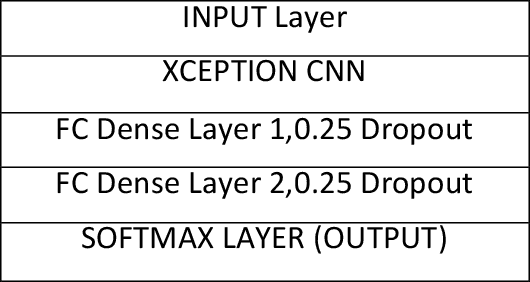
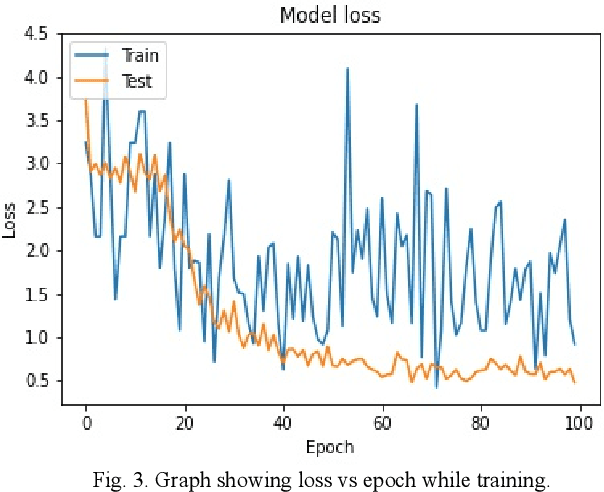
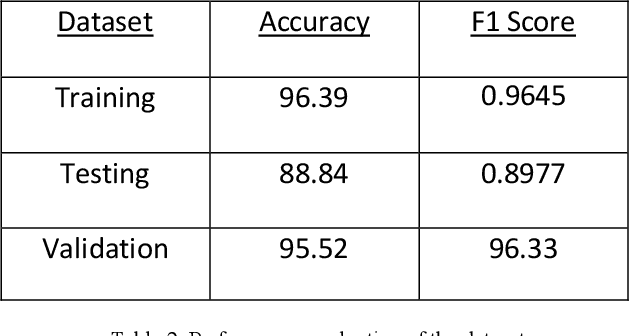
Polythene has always been a threat to the environment since its invention. It is non-biodegradable and very difficult to recycle. Even after many awareness campaigns and practices, Separation of polythene bags from waste has been a challenge for human civilization. The primary method of segregation deployed is manual handpicking, which causes a dangerous health hazards to the workers and is also highly inefficient due to human errors. In this paper I have designed and researched on image-based classification of polythene bags using a deep-learning model and its efficiency. This paper focuses on the architecture and statistical analysis of its performance on the data set as well as problems experienced in the classification. It also suggests a modified loss function to specifically detect polythene irrespective of its individual features. It aims to help the current environment protection endeavours and save countless lives lost to the hazards caused by current methods.
Structure-SLAM: Low-Drift Monocular SLAM in Indoor Environments
Aug 05, 2020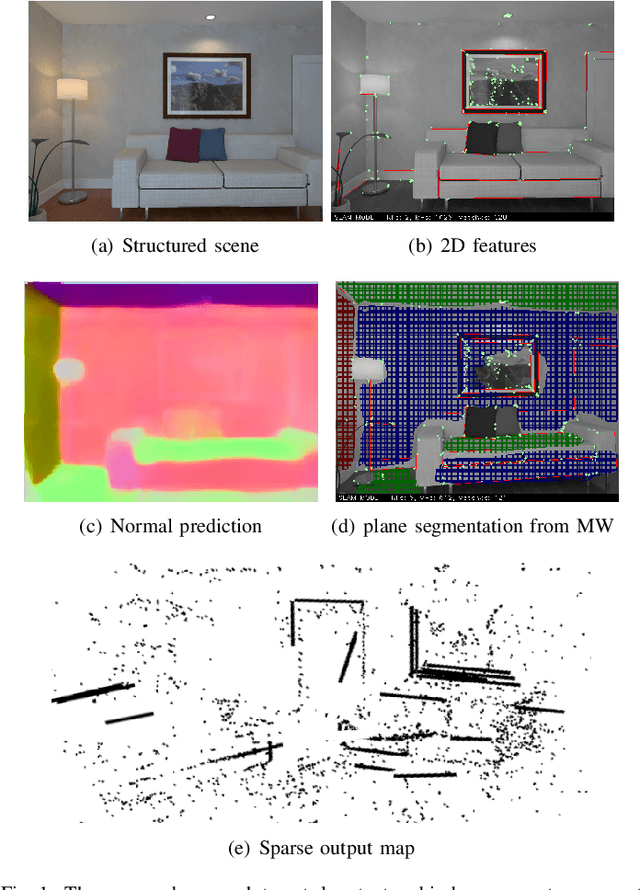
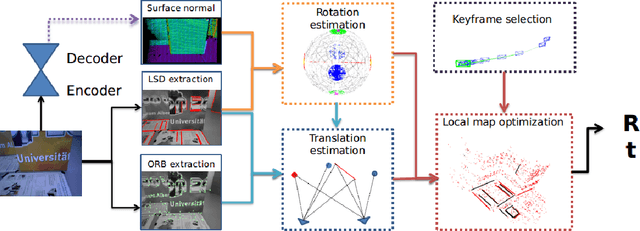
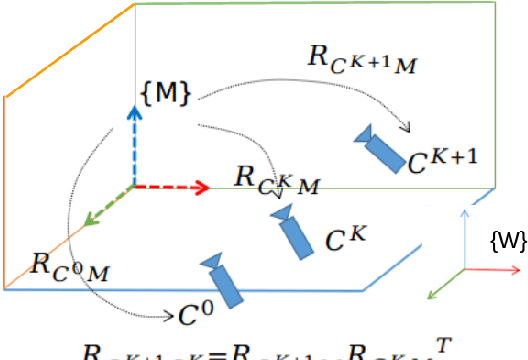
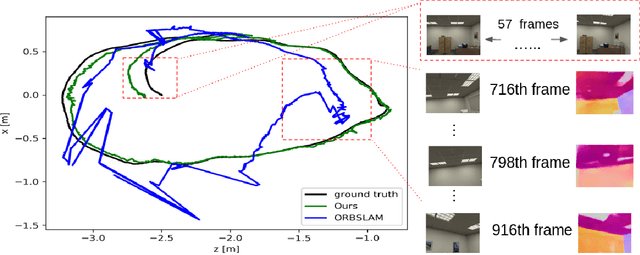
In this paper a low-drift monocular SLAM method is proposed targeting indoor scenarios, where monocular SLAM often fails due to the lack of textured surfaces. Our approach decouples rotation and translation estimation of the tracking process to reduce the long-term drift in indoor environments. In order to take full advantage of the available geometric information in the scene, surface normals are predicted by a convolutional neural network from each input RGB image in real-time. First, a drift-free rotation is estimated based on lines and surface normals using spherical mean-shift clustering, leveraging the weak Manhattan World assumption. Then translation is computed from point and line features. Finally, the estimated poses are refined with a map-to-frame optimization strategy. The proposed method outperforms the state of the art on common SLAM benchmarks such as ICL-NUIM and TUM RGB-D.
Gabor Wavelets in Image Processing
Feb 10, 2016
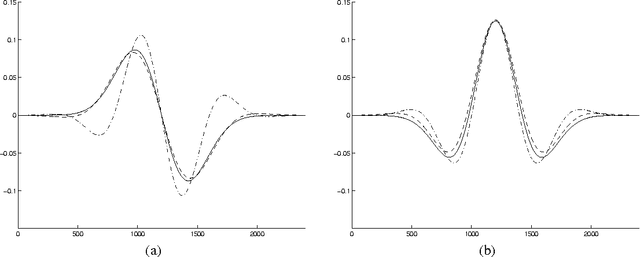

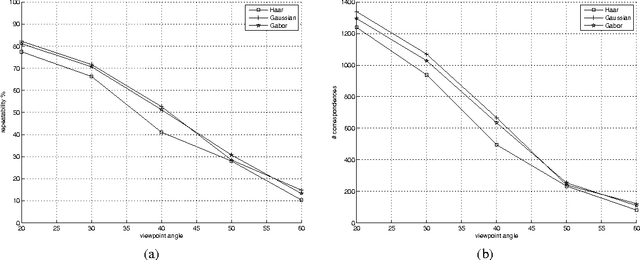
This work shows the use of a two-dimensional Gabor wavelets in image processing. Convolution with such a two-dimensional wavelet can be separated into two series of one-dimensional ones. The key idea of this work is to utilize a Gabor wavelet as a multiscale partial differential operator of a given order. Gabor wavelets are used here to detect edges, corners and blobs. A performance of such an interest point detector is compared to detectors utilizing a Haar wavelet and a derivative of a Gaussian function. The proposed approach may be useful when a fast implementation of the Gabor transform is available or when the transform is already precomputed.
Stable Low-rank Tensor Decomposition for Compression of Convolutional Neural Network
Aug 12, 2020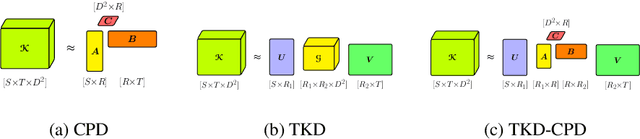
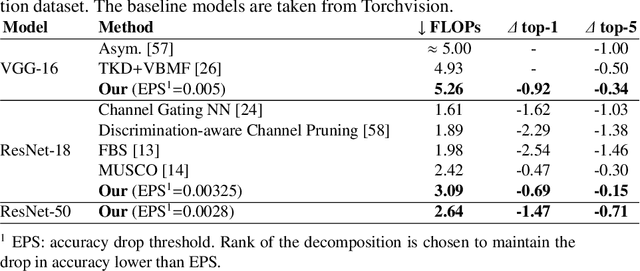
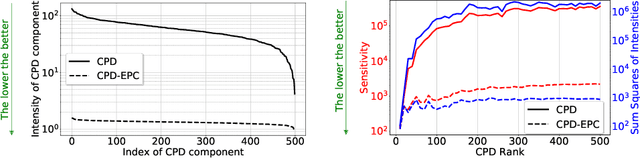
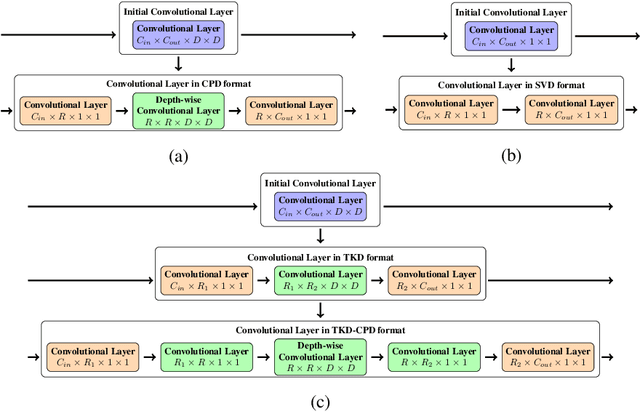
Most state of the art deep neural networks are overparameterized and exhibit a high computational cost. A straightforward approach to this problem is to replace convolutional kernels with its low-rank tensor approximations, whereas the Canonical Polyadic tensor Decomposition is one of the most suited models. However, fitting the convolutional tensors by numerical optimization algorithms often encounters diverging components, i.e., extremely large rank-one tensors but canceling each other. Such degeneracy often causes the non-interpretable result and numerical instability for the neural network fine-tuning. This paper is the first study on degeneracy in the tensor decomposition of convolutional kernels. We present a novel method, which can stabilize the low-rank approximation of convolutional kernels and ensure efficient compression while preserving the high-quality performance of the neural networks. We evaluate our approach on popular CNN architectures for image classification and show that our method results in much lower accuracy degradation and provides consistent performance.
Contextual Grounding of Natural Language Entities in Images
Nov 05, 2019
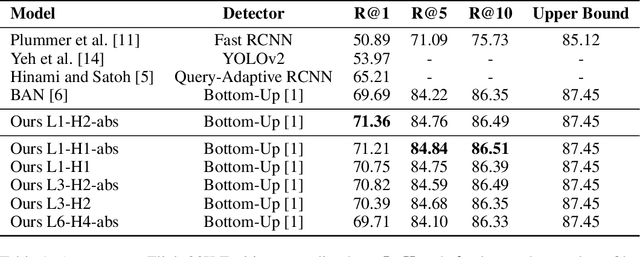
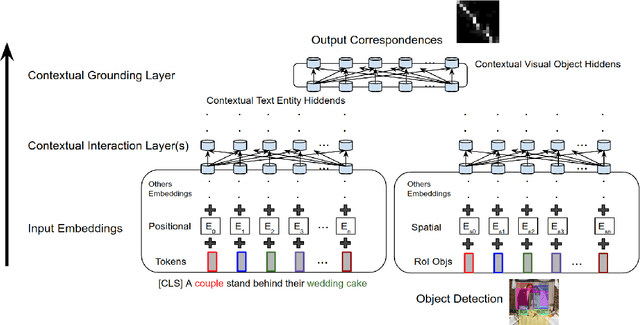
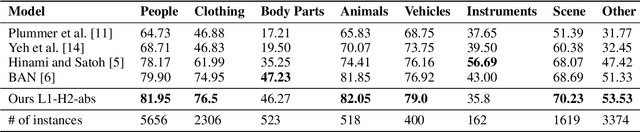
In this paper, we introduce a contextual grounding approach that captures the context in corresponding text entities and image regions to improve the grounding accuracy. Specifically, the proposed architecture accepts pre-trained text token embeddings and image object features from an off-the-shelf object detector as input. Additional encoding to capture the positional and spatial information can be added to enhance the feature quality. There are separate text and image branches facilitating respective architectural refinements for different modalities. The text branch is pre-trained on a large-scale masked language modeling task while the image branch is trained from scratch. Next, the model learns the contextual representations of the text tokens and image objects through layers of high-order interaction respectively. The final grounding head ranks the correspondence between the textual and visual representations through cross-modal interaction. In the evaluation, we show that our model achieves the state-of-the-art grounding accuracy of 71.36% over the Flickr30K Entities dataset. No additional pre-training is necessary to deliver competitive results compared with related work that often requires task-agnostic and task-specific pre-training on cross-modal dadasets. The implementation is publicly available at https://gitlab.com/necla-ml/grounding.
Advances in centerline estimation for autonomous lateral control
Feb 28, 2020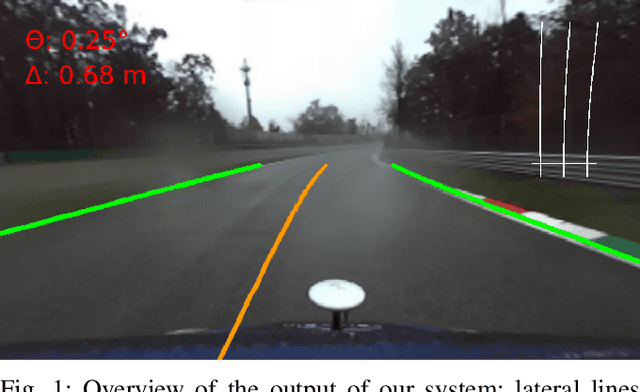
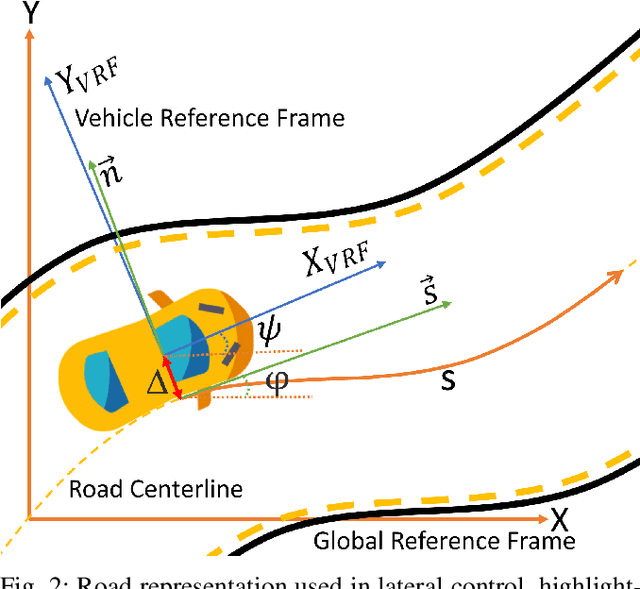

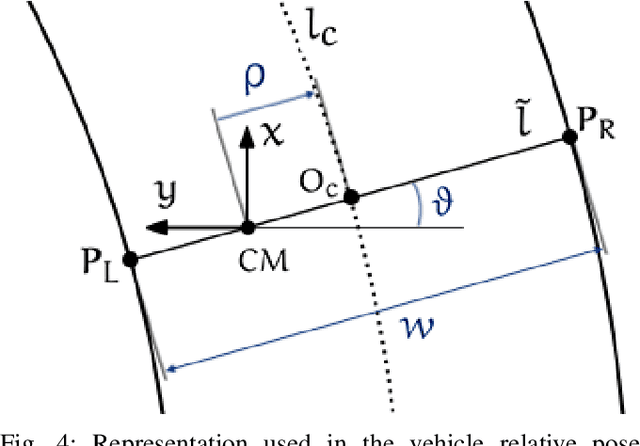
The ability of autonomous vehicles to maintain an accurate trajectory within their road lane is crucial for safe operation. This requires detecting the road lines and estimating the car relative pose within its lane. Lateral lines are usually computed from camera images. Still, most of the works on line detection are limited to image mask retrieval and do not provide a usable representation in world coordinates. What we propose in this paper is a complete perception pipeline able to retrieve, from a single image, all the information required by a vehicle lateral control system: road lines equation, centerline, vehicle heading and lateral displacement. We also evaluate our system by acquiring a new dataset with accurate geometric ground truth, and we make it publicly available to act as a benchmark for further research.
ArchNet: Data Hiding Model in Distributed Machine Learning System
Apr 23, 2020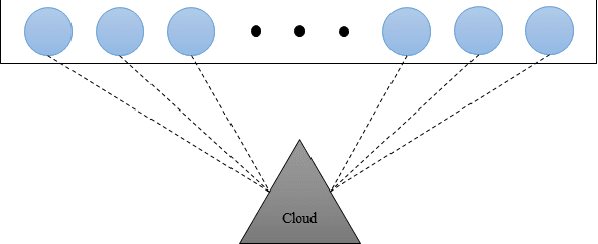
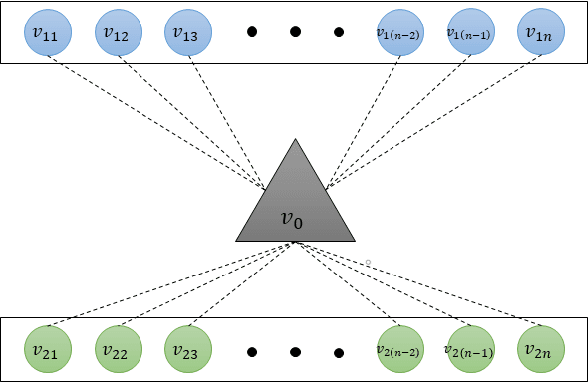
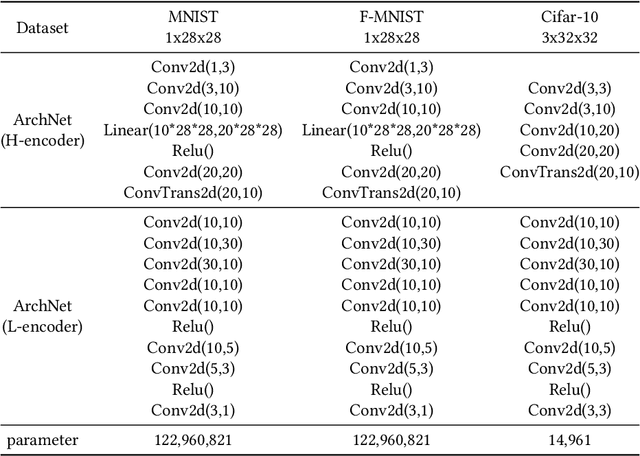
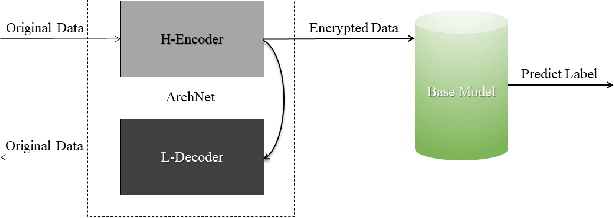
Cloud computing services has become the de facto standard technique for training neural network. However, the computing resources of the cloud servers are limited by hardware and the fixed algorithms of service provider. We observe that this problem can be addressed by a distributed machine learning system, which can utilize the idle devices on the Internet. We further demonstrate that such system can improve the computing flexibility by providing diverse algorithm. For the purpose of the data encryption in the distributed system, we propose Tripartite Asymmetric Encryption theorem and give a mathematical proof. Based on the theorem, we design a universal image encryption model ArchNet. The model has been implemented on MNIST, Fashion-MNIST and Cifar-10 datasets. We use different base models on the encrypted datasets and contrast the results with RC4 algorithm and Difference Privacy policy. The accuracies on the datasets encrypted by ArchNet are 97.26\%, 84.15\% and 79.80\%, and they are 97.31\%, 82.31\% and 80.22\% on the original datasets. Our evaluations show that ArchNet significantly outperforms RC4 on 3 classic image classification datasets at the recognition accuracy and our encrypted dataset sometimes outperforms than the original dataset and the difference privacy policy.
Transfer learning extensions for the probabilistic classification vector machine
Jul 11, 2020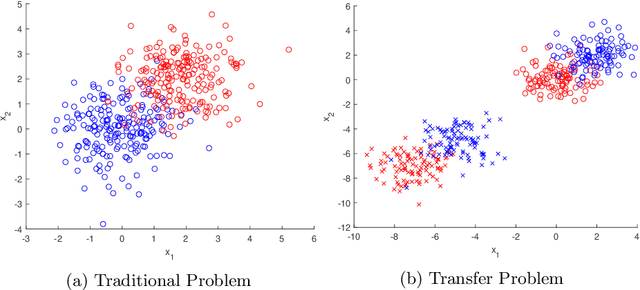
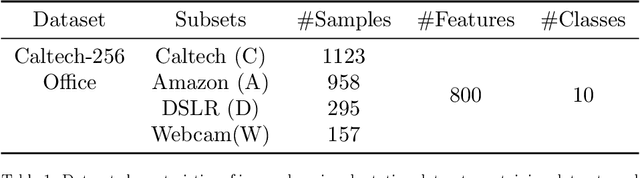
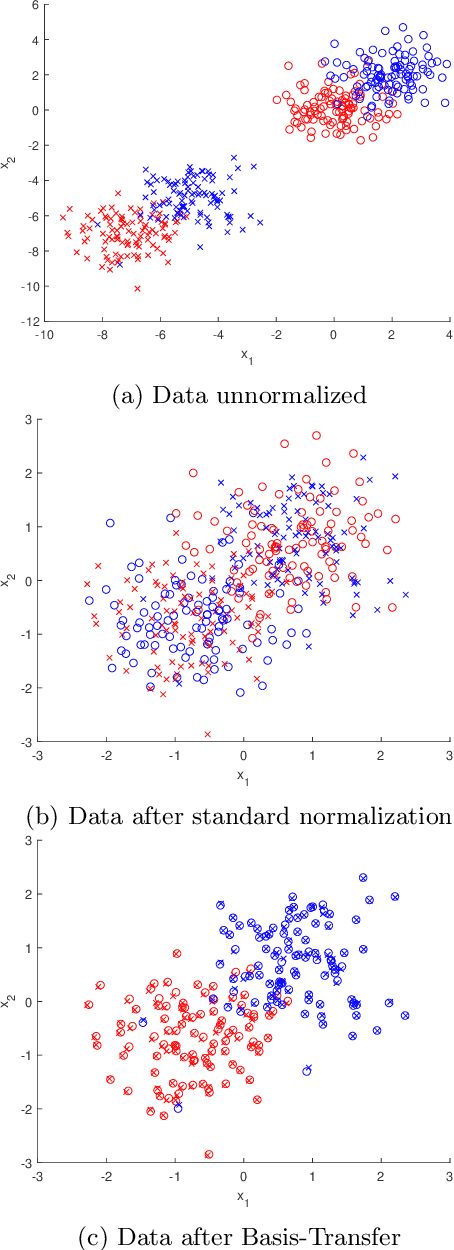
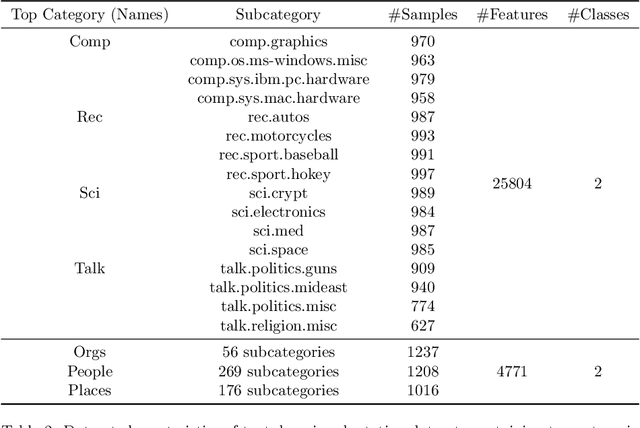
Transfer learning is focused on the reuse of supervised learning models in a new context. Prominent applications can be found in robotics, image processing or web mining. In these fields, the learning scenarios are naturally changing but often remain related to each other motivating the reuse of existing supervised models. Current transfer learning models are neither sparse nor interpretable. Sparsity is very desirable if the methods have to be used in technically limited environments and interpretability is getting more critical due to privacy regulations. In this work, we propose two transfer learning extensions integrated into the sparse and interpretable probabilistic classification vector machine. They are compared to standard benchmarks in the field and show their relevance either by sparsity or performance improvements.
* arXiv admin note: text overlap with arXiv:1907.01343
Active Depth Estimation: Stability Analysis and its Applications
Mar 16, 2020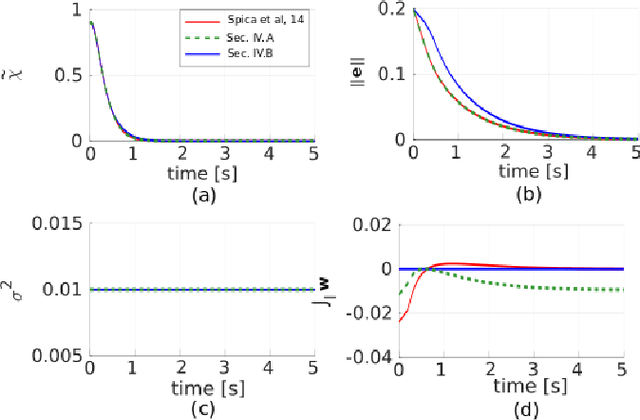
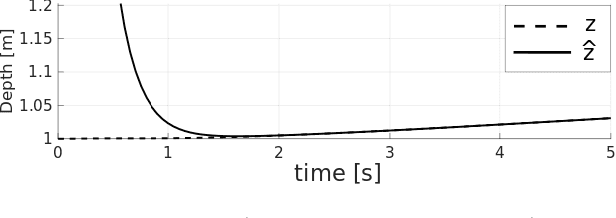
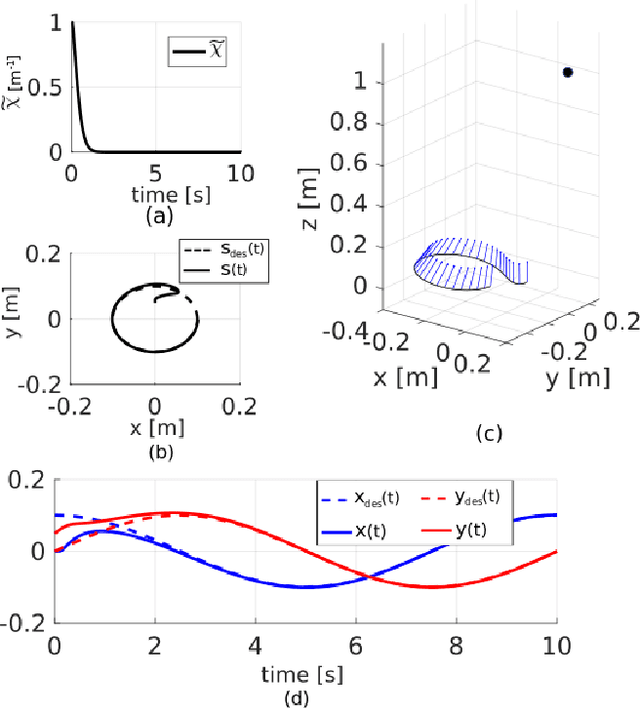
Recovering the 3D structure of the surrounding environment is an essential task in any vision-controlled Structure-from-Motion (SfM) scheme. This paper focuses on the theoretical properties of the SfM, known as the incremental active depth estimation. The term incremental stands for estimating the 3D structure of the scene over a chronological sequence of image frames. Active means that the camera actuation is such that it improves estimation performance. Starting from a known depth estimation filter, this paper presents the stability analysis of the filter in terms of the control inputs of the camera. By analyzing the convergence of the estimator using the Lyapunov theory, we relax the constraints on the projection of the 3D point in the image plane when compared to previous results. Nonetheless, our method is capable of dealing with the cameras' limited field-of-view constraints. The main results are validated through experiments with simulated data.
* 7 pages, 3 figures, conference
PolyLaneNet: Lane Estimation via Deep Polynomial Regression
Apr 23, 2020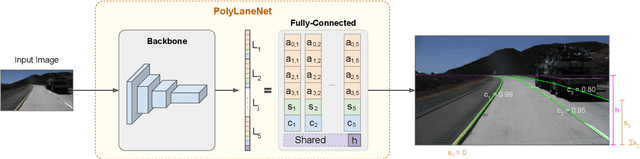


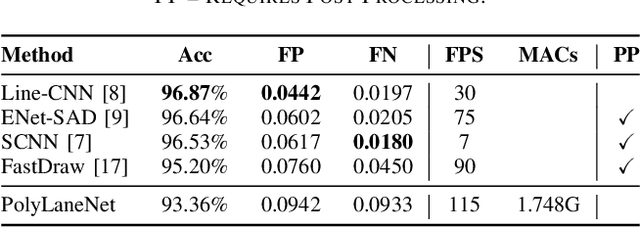
One of the main factors that contributed to the large advances in autonomous driving is the advent of deep learning. For safer self-driving vehicles, one of the problems that has yet to be solved completely is lane detection. Since methods for this task have to work in real time (+30 FPS), they not only have to be effective (i.e., have high accuracy) but they also have to be efficient (i.e., fast). In this work, we present a novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression. The proposed method is shown to be competitive with existing state-of-the-art methods in the TuSimple dataset, while maintaining its efficiency (115 FPS). Additionally, extensive qualitative results on two additional public datasets are presented, alongside with limitations in the evaluation metrics used by recent works for lane detection. Finally, we provide source code and trained models that allow others to replicate all the results shown in this paper, which is surprisingly rare in state-of-the-art lane detection methods.