 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Domain Adaptation via CycleGAN for White Matter Hyperintensity Segmentation in Multicenter MR Images
Sep 10, 2020
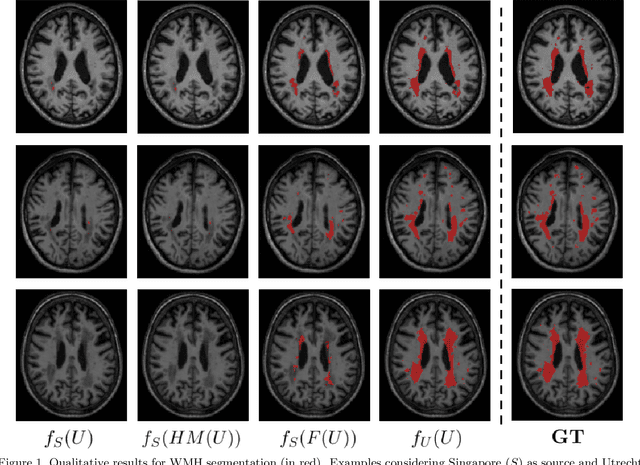
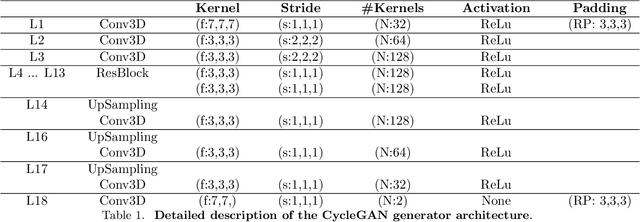

Automatic segmentation of white matter hyperintensities in magnetic resonance images is of paramount clinical and research importance. Quantification of these lesions serve as a predictor for risk of stroke, dementia and mortality. During the last years, convolutional neural networks (CNN) specifically tailored for biomedical image segmentation have outperformed all previous techniques in this task. However, they are extremely data-dependent, and maintain a good performance only when data distribution between training and test datasets remains unchanged. When such distribution changes but we still aim at performing the same task, we incur in a domain adaptation problem (e.g. using a different MR machine or different acquisition parameters for training and test data). In this work, we explore the use of cycle-consistent adversarial networks (CycleGAN) to perform unsupervised domain adaptation on multicenter MR images with brain lesions. We aim at learning a mapping function to transform volumetric MR images between domains, which are characterized by different medical centers and MR machines with varying brand, model and configuration parameters. Our experiments show that CycleGAN allows us to reduce the Jensen-Shannon divergence between MR domains, enabling automatic segmentation with CNN models on domains where no labeled data was available.
Understanding Image and Text Simultaneously: a Dual Vision-Language Machine Comprehension Task
Dec 22, 2016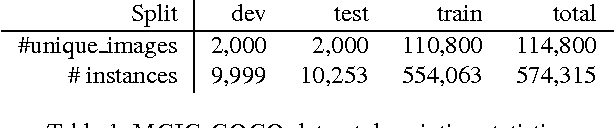

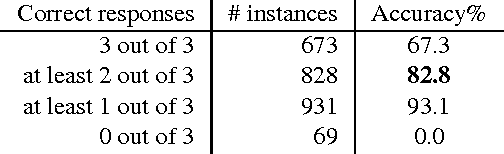

We introduce a new multi-modal task for computer systems, posed as a combined vision-language comprehension challenge: identifying the most suitable text describing a scene, given several similar options. Accomplishing the task entails demonstrating comprehension beyond just recognizing "keywords" (or key-phrases) and their corresponding visual concepts. Instead, it requires an alignment between the representations of the two modalities that achieves a visually-grounded "understanding" of various linguistic elements and their dependencies. This new task also admits an easy-to-compute and well-studied metric: the accuracy in detecting the true target among the decoys. The paper makes several contributions: an effective and extensible mechanism for generating decoys from (human-created) image captions; an instance of applying this mechanism, yielding a large-scale machine comprehension dataset (based on the COCO images and captions) that we make publicly available; human evaluation results on this dataset, informing a performance upper-bound; and several baseline and competitive learning approaches that illustrate the utility of the proposed task and dataset in advancing both image and language comprehension. We also show that, in a multi-task learning setting, the performance on the proposed task is positively correlated with the end-to-end task of image captioning.
Attention Mechanism Enhanced Kernel Prediction Networks for Denoising of Burst Images
Oct 18, 2019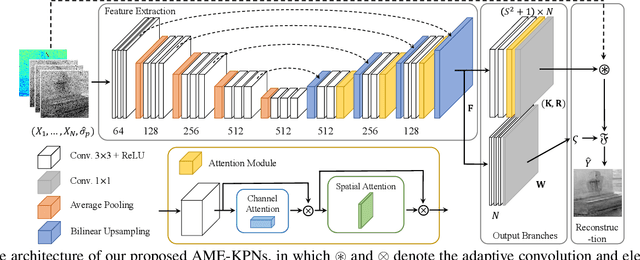
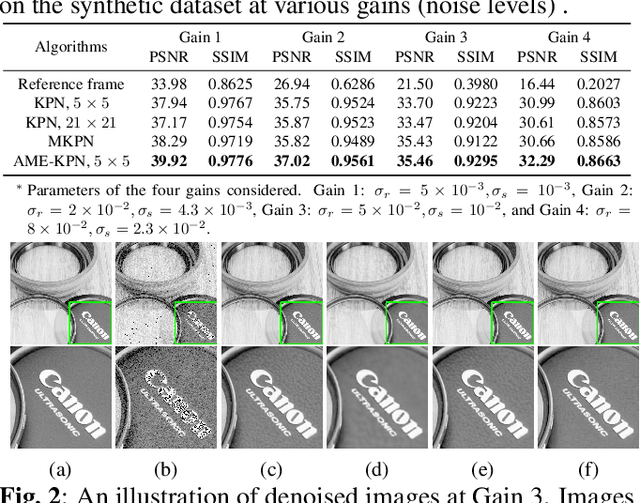
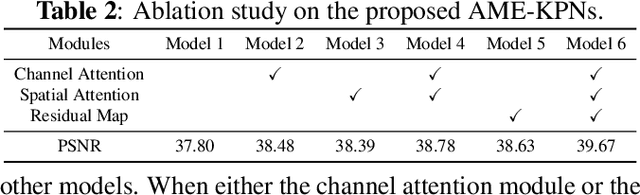
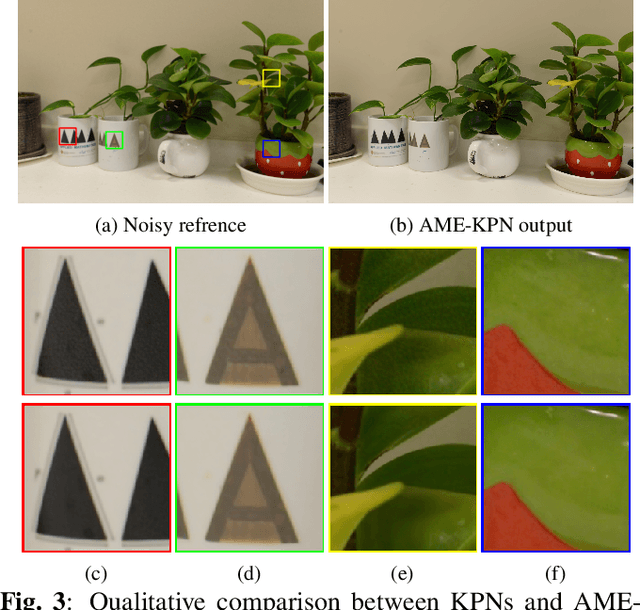
Deep learning based image denoising methods have been extensively investigated. In this paper, attention mechanism enhanced kernel prediction networks (AME-KPNs) are proposed for burst image denoising, in which, nearly cost-free attention modules are adopted to first refine the feature maps and to further make a full use of the inter-frame and intra-frame redundancies within the whole image burst. The proposed AME-KPNs output per-pixel spatially-adaptive kernels, residual maps and corresponding weight maps, in which, the predicted kernels roughly restore clean pixels at their corresponding locations via an adaptive convolution operation, and subsequently, residuals are weighted and summed to compensate the limited receptive field of predicted kernels. Simulations and real-world experiments are conducted to illustrate the robustness of the proposed AME-KPNs in burst image denoising.
Deep learning with 4D spatio-temporal data representations for OCT-based force estimation
May 20, 2020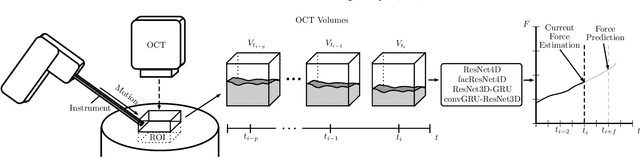
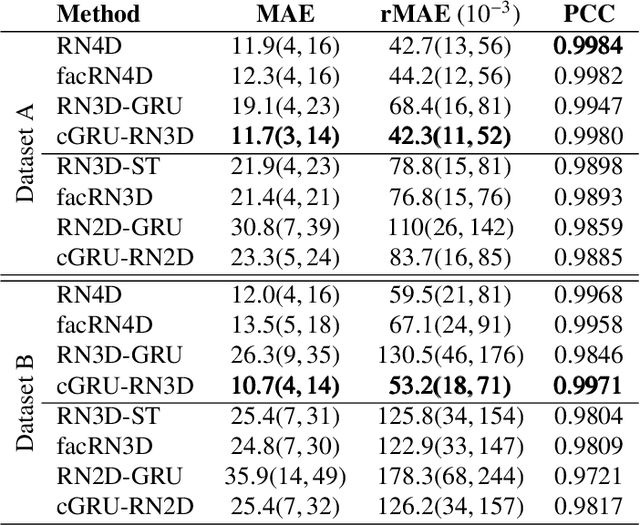
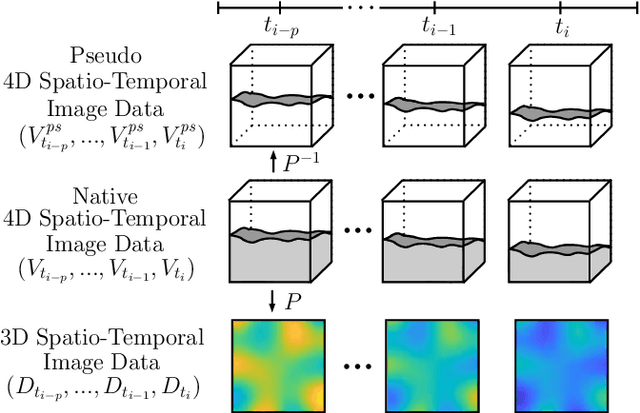
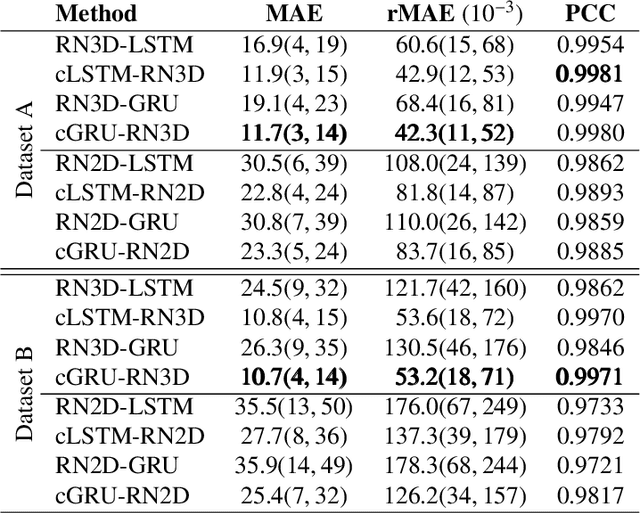
Estimating the forces acting between instruments and tissue is a challenging problem for robot-assisted minimally-invasive surgery. Recently, numerous vision-based methods have been proposed to replace electro-mechanical approaches. Moreover, optical coherence tomography (OCT) and deep learning have been used for estimating forces based on deformation observed in volumetric image data. The method demonstrated the advantage of deep learning with 3D volumetric data over 2D depth images for force estimation. In this work, we extend the problem of deep learning-based force estimation to 4D spatio-temporal data with streams of 3D OCT volumes. For this purpose, we design and evaluate several methods extending spatio-temporal deep learning to 4D which is largely unexplored so far. Furthermore, we provide an in-depth analysis of multi-dimensional image data representations for force estimation, comparing our 4D approach to previous, lower-dimensional methods. Also, we analyze the effect of temporal information and we study the prediction of short-term future force values, which could facilitate safety features. For our 4D force estimation architectures, we find that efficient decoupling of spatial and temporal processing is advantageous. We show that using 4D spatio-temporal data outperforms all previously used data representations with a mean absolute error of 10.7mN. We find that temporal information is valuable for force estimation and we demonstrate the feasibility of force prediction.
Histopathological Image Classification using Discriminative Feature-oriented Dictionary Learning
Mar 29, 2016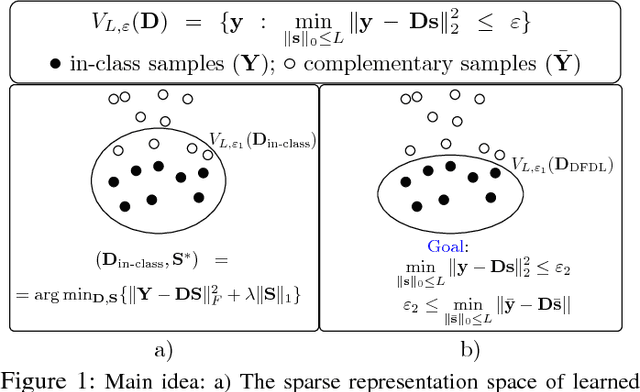
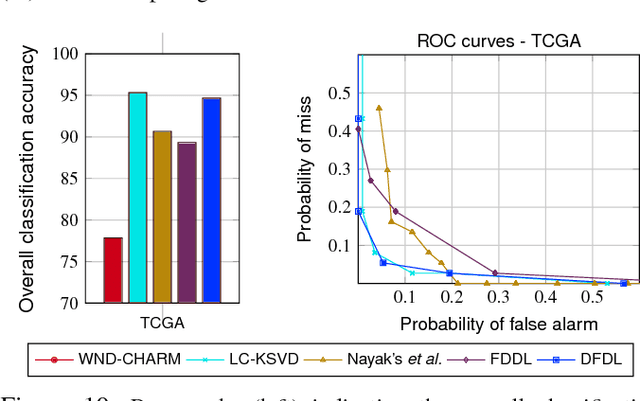
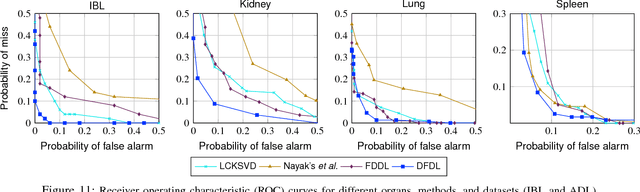
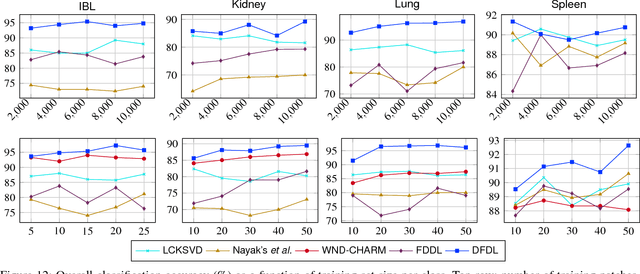
In histopathological image analysis, feature extraction for classification is a challenging task due to the diversity of histology features suitable for each problem as well as presence of rich geometrical structures. In this paper, we propose an automatic feature discovery framework via learning class-specific dictionaries and present a low-complexity method for classification and disease grading in histopathology. Essentially, our Discriminative Feature-oriented Dictionary Learning (DFDL) method learns class-specific dictionaries such that under a sparsity constraint, the learned dictionaries allow representing a new image sample parsimoniously via the dictionary corresponding to the class identity of the sample. At the same time, the dictionary is designed to be poorly capable of representing samples from other classes. Experiments on three challenging real-world image databases: 1) histopathological images of intraductal breast lesions, 2) mammalian kidney, lung and spleen images provided by the Animal Diagnostics Lab (ADL) at Pennsylvania State University, and 3) brain tumor images from The Cancer Genome Atlas (TCGA) database, reveal the merits of our proposal over state-of-the-art alternatives. {Moreover, we demonstrate that DFDL exhibits a more graceful decay in classification accuracy against the number of training images which is highly desirable in practice where generous training is often not available
Soliciting Human-in-the-Loop User Feedback for Interactive Machine Learning Reduces User Trust and Impressions of Model Accuracy
Aug 28, 2020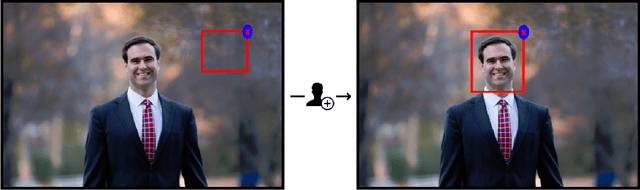
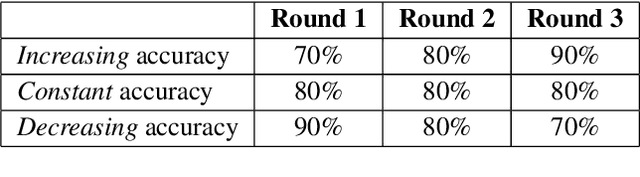
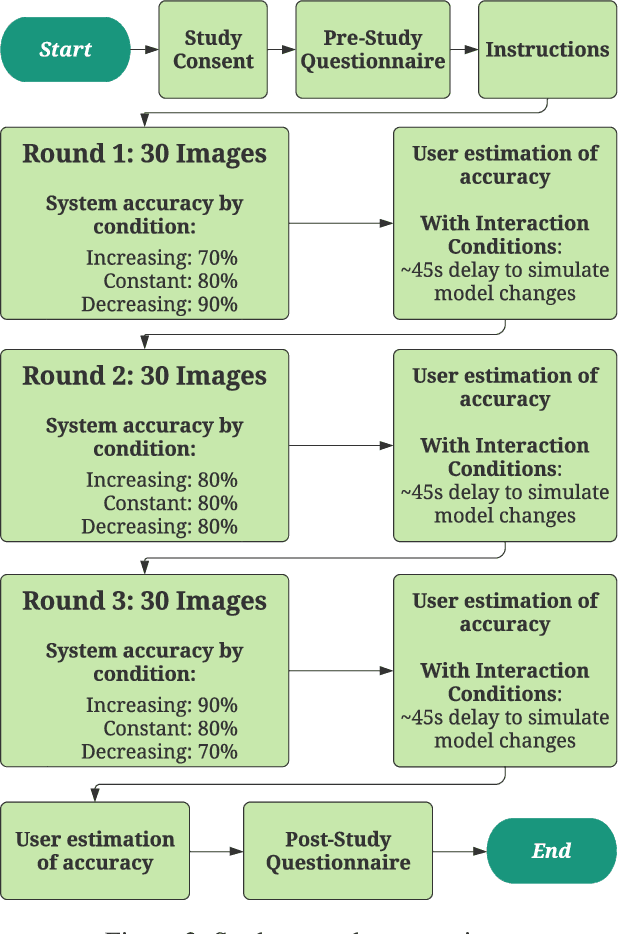
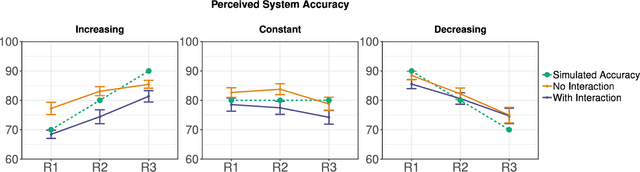
Mixed-initiative systems allow users to interactively provide feedback to potentially improve system performance. Human feedback can correct model errors and update model parameters to dynamically adapt to changing data. Additionally, many users desire the ability to have a greater level of control and fix perceived flaws in systems they rely on. However, how the ability to provide feedback to autonomous systems influences user trust is a largely unexplored area of research. Our research investigates how the act of providing feedback can affect user understanding of an intelligent system and its accuracy. We present a controlled experiment using a simulated object detection system with image data to study the effects of interactive feedback collection on user impressions. The results show that providing human-in-the-loop feedback lowered both participants' trust in the system and their perception of system accuracy, regardless of whether the system accuracy improved in response to their feedback. These results highlight the importance of considering the effects of allowing end-user feedback on user trust when designing intelligent systems.
A Framework based on Deep Neural Networks to Extract Anatomy of Mosquitoes from Images
Jul 21, 2020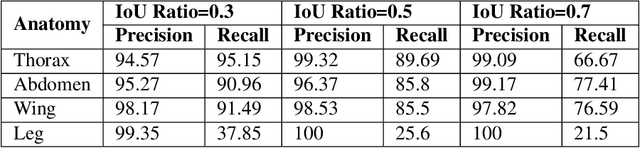
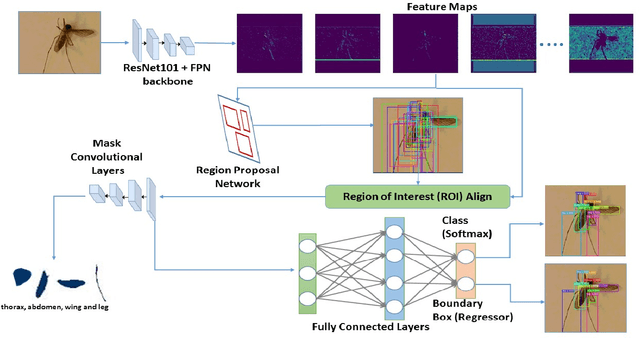
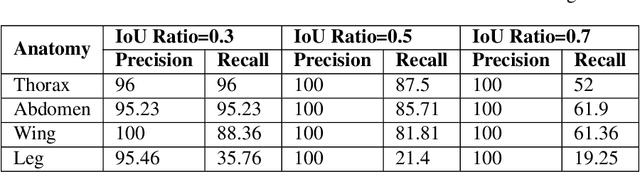

We design a framework based on Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect and separately extract anatomical components of mosquitoes - thorax, wings, abdomen and legs from images. Our training dataset consisted of 1500 smartphone images of nine mosquito species trapped in Florida. In the proposed technique, the first step is to detect anatomical components within a mosquito image. Then, we localize and classify the extracted anatomical components, while simultaneously adding a branch in the neural network architecture to segment pixels containing only the anatomical components. Evaluation results are favorable. To evaluate generality, we test our architecture trained only with mosquito images on bumblebee images. We again reveal favorable results, particularly in extracting wings. Our techniques in this paper have practical applications in public health, taxonomy and citizen-science efforts.
Weakly Supervised PET Tumor Detection Using Class Response
Mar 19, 2020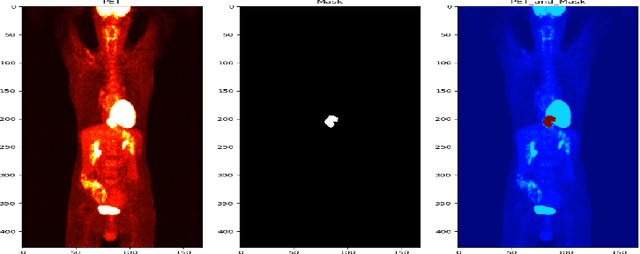
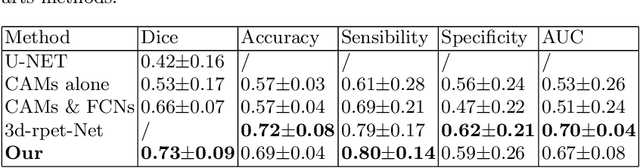
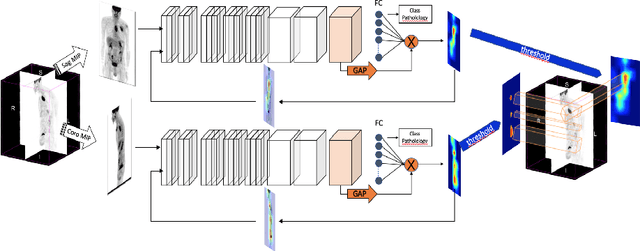
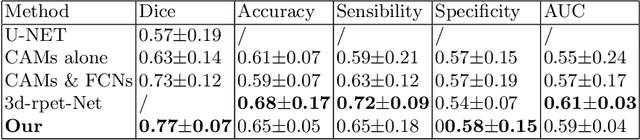
One of the most challenges in medical imaging is the lack of data and annotated data. It is proven that classical segmentation methods such as U-NET are useful but still limited due to the lack of annotated data. Using a weakly supervised learning is a promising way to address this problem, however, it is challenging to train one model to detect and locate efficiently different type of lesions due to the huge variation in images. In this paper, we present a novel approach to locate different type of lesions in positron emission tomography (PET) images using only a class label at the image-level. First, a simple convolutional neural network classifier is trained to predict the type of cancer on two 2D MIP images. Then, a pseudo-localization of the tumor is generated using class activation maps, back-propagated and corrected in a multitask learning approach with prior knowledge, resulting in a tumor detection mask. Finally, we use the mask generated from the two 2D images to detect the tumor in the 3D image. The advantage of our proposed method consists of detecting the whole tumor volume in 3D images, using only two 2D images of PET image, and showing a very promising results. It can be used as a tool to locate very efficiently tumors in a PET scan, which is a time-consuming task for physicians. In addition, we show that our proposed method can be used to conduct a radiomics study with state of the art results.
Deep Fence Estimation using Stereo Guidance and Adversarial Learning
Jul 03, 2020
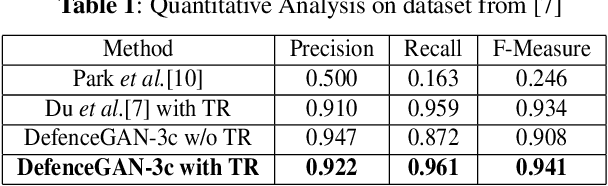
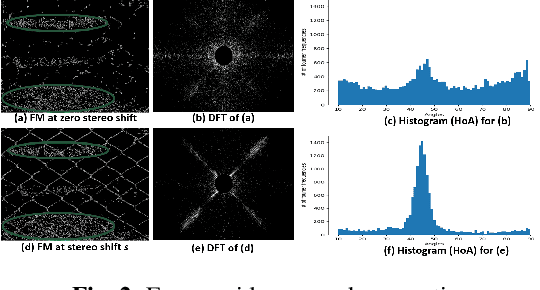
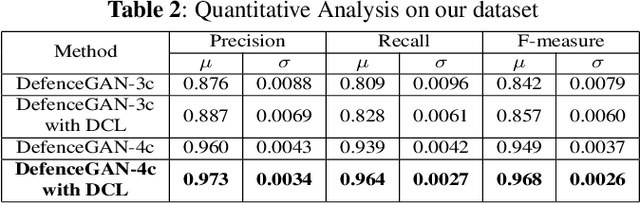
People capture memorable images of events and exhibits that are often occluded by a wire mesh loosely termed as fence. Recent works in removing fence have limited performance due to the difficulty in initial fence segmentation. This work aims to accurately segment fence using a novel fence guidance mask (FM) generated from stereo image pair. This binary guidance mask contains deterministic cues about the structure of fence and is given as additional input to the deep fence estimation model. We also introduce a directional connectivity loss (DCL), which is used alongside adversarial loss to precisely detect thin wires. Experimental results obtained on real world scenarios demonstrate the superiority of proposed method over state-of-the-art techniques.
Beyond Identity: What Information Is Stored in Biometric Face Templates?
Sep 21, 2020
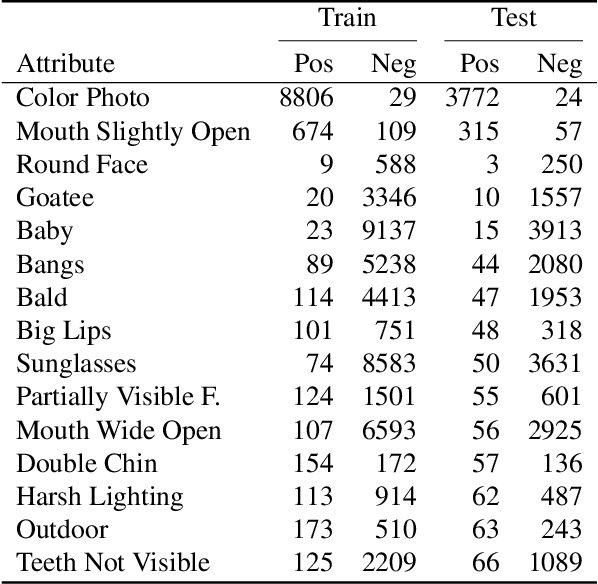
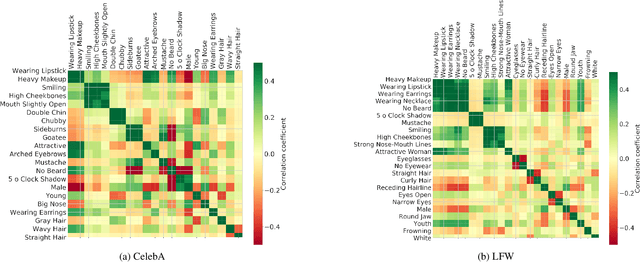
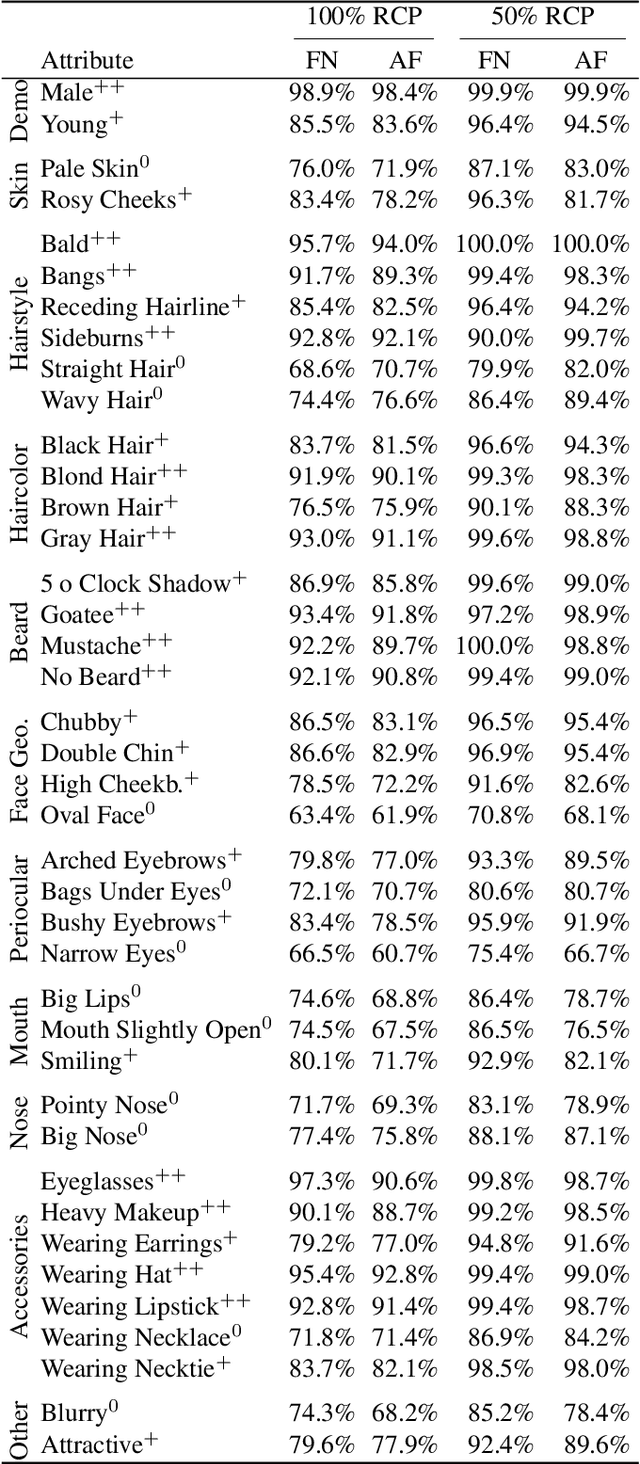
Deeply-learned face representations enable the success of current face recognition systems. Despite the ability of these representations to encode the identity of an individual, recent works have shown that more information is stored within, such as demographics, image characteristics, and social traits. This threatens the user's privacy, since for many applications these templates are expected to be solely used for recognition purposes. Knowing the encoded information in face templates helps to develop bias-mitigating and privacy-preserving face recognition technologies. This work aims to support the development of these two branches by analysing face templates regarding 113 attributes. Experiments were conducted on two publicly available face embeddings. For evaluating the predictability of the attributes, we trained a massive attribute classifier that is additionally able to accurately state its prediction confidence. This allows us to make more sophisticated statements about the attribute predictability. The results demonstrate that up to 74 attributes can be accurately predicted from face templates. Especially non-permanent attributes, such as age, hairstyles, haircolors, beards, and various accessories, found to be easily-predictable. Since face recognition systems aim to be robust against these variations, future research might build on this work to develop more understandable privacy preserving solutions and build robust and fair face templates.